1. 引言与背景
在自动驾驶、机器人导航等现实世界场景中,如何从单目RGB视频流中高效、准确地感知三维环境,是三维视觉领域长期未解的核心难题。与室内小场景的三维重建不同,自动驾驶等户外场景往往涉及数公里的长轨迹、稀疏的帧间对应关系、动态物体干扰以及复杂的光照和天气条件。这些因素极大地挑战了现有的三维视觉基础模型和传统SLAM/SfM系统。
近年来,基于Transformer架构的三维视觉基础模型(如DUSt3R、MASt3R、CUT3R、Fast3R、VGGT等)在小规模场景下展现了强大的端到端三维重建能力。这些模型通过大规模数据集训练,将相机位姿估计、内参回归和三维点云生成集成于统一的深度学习框架中,极大地简化了传统多模块系统的复杂性。然而,这类模型在面对长序列、无标定、无深度监督的户外场景时,依然面临着显存/内存瓶颈和累积误差失控等关键挑战。
以VGGT为代表的最新基础模型,虽然在局部重建精度上已达到业界领先水平,但其巨大的计算和内存需求严重限制了在大规模场景下的应用。例如,单张24GB显存的RTX 4090显卡仅能处理60-80帧图像,若要处理KITTI Seq 00(约4600帧),理论上需要高达1800GB显存,这远超当前主流硬件的能力。因此,如何突破基础模型的可扩展性瓶颈,实现公里级、无界户外环境下的高精度单目三维重建,成为推动三维视觉基础模型走向实际应用的关键。
针对上述难题,VGGT-Long提出了一种极简高效的系统框架,通过分块处理、重叠对齐和轻量级回环优化,将VGGT模型的强大局部能力无缝扩展到长序列、公里级场景,极大地降低了系统复杂度和工程门槛。本文将结合项目源码、论文理论与实际应用,系统性剖析VGGT-Long的设计理念、核心技术与工程实现,帮助读者全面理解其背后的科学原理与工程价值。
2. 设计哲学与整体架构
2.1 极简主义驱动的系统设计
VGGT-Long的核心设计理念是"极简主义":在不牺牲精度的前提下,最大限度地降低系统复杂度,充分释放基础模型的潜力。与主流的多模块SLAM系统(如MASt3R-SLAM、传统SfM/SLAM)不同,VGGT-Long拒绝引入冗余的后端优化、繁琐的图优化流程和复杂的多传感器融合。其目标是让基础模型(VGGT)成为系统的唯一"引擎",通过巧妙的分块、对齐和轻量级全局优化,实现端到端的公里级三维重建。
这种设计哲学带来了诸多优势:
- 工程实现简单:极大降低了开发和维护成本,便于快速迭代和迁移。
- 系统鲁棒性高:减少了依赖链和模块间耦合,降低了出错概率。
- 易于扩展和下游应用:为后续的三维理解、场景语义分割等任务提供了简洁的接口。
2.2 系统整体流程图
下面是VGGT-Long的系统流程图,展示了从输入到输出的全链路处理过程:
输入:长序列RGB图像流
分块处理(重叠滑窗)
VGGT模型推理(深度+位姿+置信度)
块间重叠区域点云置信度加权对齐
循环检测(VPR/DBoW2/DNIO v2)
循环块Sim3对齐
全局Sim3 LM优化
点云/轨迹合成与导出
可视化与下游应用
2.3 与传统SLAM系统的对比
| 传统SLAM/SfM系统 | VGGT-Long | |
|---|---|---|
| 系统结构 | 多模块(特征提取、匹配、BA、PGO等) | 单一深度模型+极简对齐优化 |
| 依赖 | 需相机标定/多传感器/复杂后端 | 无需标定,纯RGB输入,轻量后端 |
| 可扩展性 | 难以处理长序列,易累积误差 | 分块+对齐+回环,支持公里级场景 |
| 工程复杂度 | 高,维护难 | 低,易于部署和迁移 |
| 下游接口 | 多格式、强依赖 | 统一点云/轨迹输出,便于集成 |
VGGT-Long以最小的系统工程量,实现了与传统方法媲美甚至超越的三维重建精度,为基础模型在真实场景下的落地应用提供了全新范式。
3. 分块处理与内存管理机制详解
3.1 重叠分块算法原理
VGGT-Long采用滑动窗口式的重叠分块策略,将长序列I={I1,...,IN}划分为K个重叠块。每个块长度为L,重叠区域为O。第k个块的帧索引为:
( k − 1 ) ⋅ ( L − O ) → ( k − 1 ) ⋅ ( L − O ) + L (k-1)\cdot(L-O) ~\to~ (k-1)\cdot(L-O)+L (k−1)⋅(L−O) → (k−1)⋅(L−O)+L
这种设计保证了:
- 每个块可独立送入VGGT模型推理,避免内存溢出
- 块间重叠区域为后续对齐提供了充足的空间几何约束
- 支持任意长度序列的线性扩展
代码实现片段
在vggt_long.py中,分块逻辑如下:
python
if len(self.img_list) <= self.chunk_size:
num_chunks = 1
self.chunk_indices = [(0, len(self.img_list))]
else:
step = self.chunk_size - self.overlap
num_chunks = (len(self.img_list) - self.overlap + step - 1) // step
self.chunk_indices = []
for i in range(num_chunks):
start_idx = i * step
end_idx = min(start_idx + self.chunk_size, len(self.img_list))
self.chunk_indices.append((start_idx, end_idx))其中chunk_size和overlap均可在configs/base_config.yaml中灵活配置。例如:
yaml
Model:
chunk_size: 60
overlap: 303.2 内存优化与中间结果落盘
分块推理后,每个子块的推理结果(深度、位姿、点云等)会被立即保存到磁盘,而不是长时间驻留在内存中。这一策略极大降低了CPU内存峰值,避免了大规模场景下的OOM风险。只有在后续对齐、全局优化等阶段,才会按需加载对应块的数据。
3.2.1 代码实现片段
python
def process_single_chunk(self, range_1, chunk_idx=None, range_2=None, is_loop=False):
"""
处理单个图像块
Args:
range_1 (tuple): 第一个图像范围 (start_idx, end_idx)
chunk_idx (int, optional): 块索引,用于常规处理
range_2 (tuple, optional): 第二个图像范围,用于循环检测
is_loop (bool): 是否是循环检测处理
Returns:
dict or None: 如果是循环处理或有range_2,返回预测结果;否则返回None
功能说明:
- 加载指定范围的图像
- 使用VGGT模型进行推理
- 将位姿编码转换为外参和内参矩阵
- 保存结果到磁盘以节省内存
"""
start_idx, end_idx = range_1
chunk_image_paths = self.img_list[start_idx:end_idx]
# 如果有第二个范围,合并图像路径(用于循环检测)
if range_2 is not None:
start_idx, end_idx = range_2
chunk_image_paths += self.img_list[start_idx:end_idx]
# 加载和预处理图像
images = load_and_preprocess_images(chunk_image_paths).to(self.device)
print(f"Loaded {len(images)} images")
# 验证图像格式: [B, 3, H, W]
assert len(images.shape) == 4
assert images.shape[1] == 3
# 清理GPU缓存
torch.cuda.empty_cache()
# 使用VGGT模型进行推理
with torch.no_grad():
with torch.cuda.amp.autocast(dtype=self.dtype):
predictions = self.model(images)
torch.cuda.empty_cache()
print("Converting pose encoding to extrinsic and intrinsic matrices...")
# 将位姿编码转换为外参和内参矩阵
extrinsic, intrinsic = pose_encoding_to_extri_intri(predictions["pose_enc"], images.shape[-2:])
predictions["extrinsic"] = extrinsic
predictions["intrinsic"] = intrinsic
print("Processing model outputs...")
# 将GPU张量转换为CPU numpy数组
for key in predictions.keys():
if isinstance(predictions[key], torch.Tensor):
predictions[key] = predictions[key].cpu().numpy().squeeze(0)
# 确定保存路径和文件名
if is_loop:
save_dir = self.result_loop_dir
filename = f"loop_{range_1[0]}_{range_1[1]}_{range_2[0]}_{range_2[1]}.npy"
else:
if chunk_idx is None:
raise ValueError("chunk_idx must be provided when is_loop is False")
save_dir = self.result_unaligned_dir
filename = f"chunk_{chunk_idx}.npy"
save_path = os.path.join(save_dir, filename)
# 存储相机位姿信息(仅对常规块处理)
if not is_loop and range_2 is None:
extrinsics = predictions['extrinsic']
chunk_range = self.chunk_indices[chunk_idx]
self.all_camera_poses.append((chunk_range, extrinsics))
# 压缩深度图维度
predictions['depth'] = np.squeeze(predictions['depth'])
# 保存预测结果到磁盘
np.save(save_path, predictions)
# 根据处理类型返回结果
return predictions if is_loop or range_2 is not None else None此外,系统支持自动清理临时文件,释放磁盘空间:
python
def close(self):
"""
清理临时文件并计算回收的磁盘空间
该方法删除处理过程中生成的所有临时文件,包括三个目录:
- 未对齐结果目录
- 已对齐结果目录
- 循环检测结果目录
性能说明:
- 每个子地图通常占用约350 MiB的磁盘空间
- 对于4000张图像的输入流,临时文件总计可消耗60-90 GiB存储空间
- 处理完成后进行清理对于防止不必要的磁盘空间占用至关重要
Returns:
无返回值,但会打印回收的磁盘空间大小
"""
# 如果配置为不删除临时文件,则直接返回
if not self.delete_temp_files:
return
total_space = 0
# 删除未对齐结果目录中的文件
print(f'Deleting the temp files under {self.result_unaligned_dir}')
for filename in os.listdir(self.result_unaligned_dir):
file_path = os.path.join(self.result_unaligned_dir, filename)
if os.path.isfile(file_path):
total_space += os.path.getsize(file_path)
os.remove(file_path)
# 删除已对齐结果目录中的文件
print(f'Deleting the temp files under {self.result_aligned_dir}')
for filename in os.listdir(self.result_aligned_dir):
file_path = os.path.join(self.result_aligned_dir, filename)
if os.path.isfile(file_path):
total_space += os.path.getsize(file_path)
os.remove(file_path)
# 删除循环检测结果目录中的文件
print(f'Deleting the temp files under {self.result_loop_dir}')
for filename in os.listdir(self.result_loop_dir):
file_path = os.path.join(self.result_loop_dir, filename)
if os.path.isfile(file_path):
total_space += os.path.getsize(file_path)
os.remove(file_path)
print('Deleting temp files done.')
# 显示回收的磁盘空间(以GiB为单位)
print(f"Saved disk space: {total_space/1024/1024/1024:.4f} GiB")3.3 分块策略的优势与工程价值
- 线性扩展性:无论输入序列多长,显存/内存消耗始终受控
- 高效I/O管理:中间结果落盘,支持断点续算与分布式处理
- 灵活参数配置:可根据硬件能力和场景需求自定义分块粒度
- 为后续对齐与全局优化提供基础:重叠区域为Sim3对齐和回环优化提供了充足的空间约束
通过分块与内存优化,VGGT-Long实现了基础模型在公里级、无界场景下的高效运行,为后续的对齐、优化和点云合成打下坚实基础。
4. VGGT推理引擎:加载、推理流程与优化
4.1 模型加载与权重管理
VGGT-Long的核心引擎是VGGT基础模型。系统启动时会自动加载本地预训练权重,并根据硬件环境(如GPU架构)自动选择最优的数据类型(float16/bfloat16),以兼顾推理速度与显存占用。
代码实现片段
python
# 加载VGGT模型
self.model = VGGT()
# 从本地文件加载预训练权重
_URL = self.config['Weights']['VGGT']
state_dict = torch.load(_URL, map_location='cuda')
self.model.load_state_dict(state_dict, strict=False)
self.model.eval() # 评估模式
self.model = self.model.to(self.device) # 移动到GPU/CPU4.2 图像批量预处理与输入
每个分块的图像会被批量加载、归一化、调整尺寸,并转换为PyTorch张量,送入VGGT模型。预处理流程保证了输入数据的统一性和高效性。
python
images = load_and_preprocess_images(chunk_image_paths).to(self.device)4.3 推理主流程与多精度加速
推理阶段采用PyTorch的自动混合精度(AMP),在A100等新一代GPU上可自动切换bfloat16,显著提升推理速度并降低显存消耗。
python
with torch.no_grad():
with torch.cuda.amp.autocast(dtype=self.dtype):
predictions = self.model(images)
torch.cuda.empty_cache()4.4 结果解码与结构化输出
VGGT模型输出包括:
- 位姿编码(pose_enc)
- 深度图(depth)
- 置信度(confidence)
- 图像特征等
系统会将位姿编码解码为外参/内参矩阵,并将所有张量转为numpy格式,便于后续处理。
python
extrinsic, intrinsic = pose_encoding_to_extri_intri(predictions["pose_enc"], images.shape[-2:])
predictions["extrinsic"] = extrinsic
predictions["intrinsic"] = intrinsic
# 张量转numpy
for key in predictions.keys():
if isinstance(predictions[key], torch.Tensor):
predictions[key] = predictions[key].cpu().numpy().squeeze(0)4.5 推理流程小结与工程优化
- 自动释放显存:每次推理后主动清理GPU缓存,防止显存碎片化。
- 批量推理与分块结合:最大化GPU利用率,兼顾速度与内存安全。
- 灵活的输入适配:支持jpg/png等多种格式,自动适配灰度/彩色图像。
- 高效的结构化输出:为后续Sim3对齐、点云生成等模块提供标准化数据接口。
通过上述推理引擎设计,VGGT-Long不仅保证了基础模型的高效运行,还为大规模三维重建任务提供了坚实的算力与数据基础。
5. 置信度感知对齐与IRLS鲁棒Sim3估计
5.1 问题背景与动机
在分块处理后,不同子块的点云和相机轨迹存在尺度、旋转、平移的不一致,尤其在动态场景、天空区域或低纹理区域,传统点云对齐方法易受噪声和异常值影响。VGGT-Long创新性地引入置信度感知对齐,利用VGGT输出的点云置信度信息,结合IRLS(迭代加权最小二乘)鲁棒Sim3估计,实现高精度、抗干扰的块间对齐。
5.2 数学原理与优化目标
对于每对相邻块 C k C_k Ck和 C k + 1 C_{k+1} Ck+1,在重叠区域内选取点云对 { ( p i k , p i k + 1 ) } \{(p_i^k, p_i^{k+1})\} {(pik,pik+1)}及其置信度 { ( c i k , c i k + 1 ) } \{(c_i^k, c_i^{k+1})\} {(cik,cik+1)},目标是估计Sim(3)变换 S k , k + 1 S_{k,k+1} Sk,k+1(含尺度、旋转、平移),使得:
S k , k + 1 ∗ = arg min S ∈ S i m ( 3 ) ∑ i ρ ( ∥ p k i − S p k + 1 i ∥ 2 ) S^*{k,k+1} = \arg\min{S\in Sim(3)} \sum_i \rho\left(\|p^i_k - S p^i_{k+1}\|_2\right) Sk,k+1∗=argS∈Sim(3)mini∑ρ(∥pki−Spk+1i∥2)
其中 ρ ( ⋅ ) \rho(\cdot) ρ(⋅)为Huber损失,抑制异常值影响。IRLS优化每步的加权最小二乘目标为:
S ( t + 1 ) = arg min S ∈ S i m ( 3 ) ∑ i w i ( t ) ∥ p k i − S p k + 1 i ∥ 2 2 S^{(t+1)} = \arg\min_{S\in Sim(3)} \sum_i w_i^{(t)} \|p^i_k - S p^i_{k+1}\|^2_2 S(t+1)=argS∈Sim(3)mini∑wi(t)∥pki−Spk+1i∥22
权重 w i ( t ) w_i^{(t)} wi(t)由置信度和残差共同决定:
w i ( t ) = c i ⋅ ρ ′ ( r i ( t ) ) r i ( t ) w_i^{(t)} = c_i \cdot \frac{\rho'(r_i^{(t)})}{r_i^{(t)}} wi(t)=ci⋅ri(t)ρ′(ri(t))
其中 r i ( t ) = ∥ p i k − S ( t ) p i k + 1 ∥ r_i^{(t)} = \|p_i^k - S^{(t)} p_i^{k+1}\| ri(t)=∥pik−S(t)pik+1∥。
5.3 工程实现与关键代码
VGGT-Long采用加权Umeyama算法高效求解Sim3,低置信度点(如天空、动态物体)自动被降权或剔除。
python
# 置信度阈值过滤
conf_threshold = min(np.median(conf1), np.median(conf2)) * 0.1
# 加权点云对齐
s, R, t = weighted_align_point_maps(point_map1, conf1, point_map2, conf2, conf_threshold=conf_threshold, config=self.config)IRLS主循环伪代码如下:
python
def weighted_align_point_maps(...):
for iter in range(max_iters):
# 计算残差和权重
weights = confidence * huber_weight(residuals)
# 加权Umeyama求解Sim3
s, R, t = weighted_umeyama(src, tgt, weights)
# 检查收敛
if ...: break
return s, R, t5.4 效果可视化与鲁棒性分析
下图展示了置信度感知对齐在动态场景下的优势。高置信度点(如建筑物、静态地面)主导对齐,低置信度点(如车辆、天空)被自动抑制,有效提升了对齐精度和全局一致性。
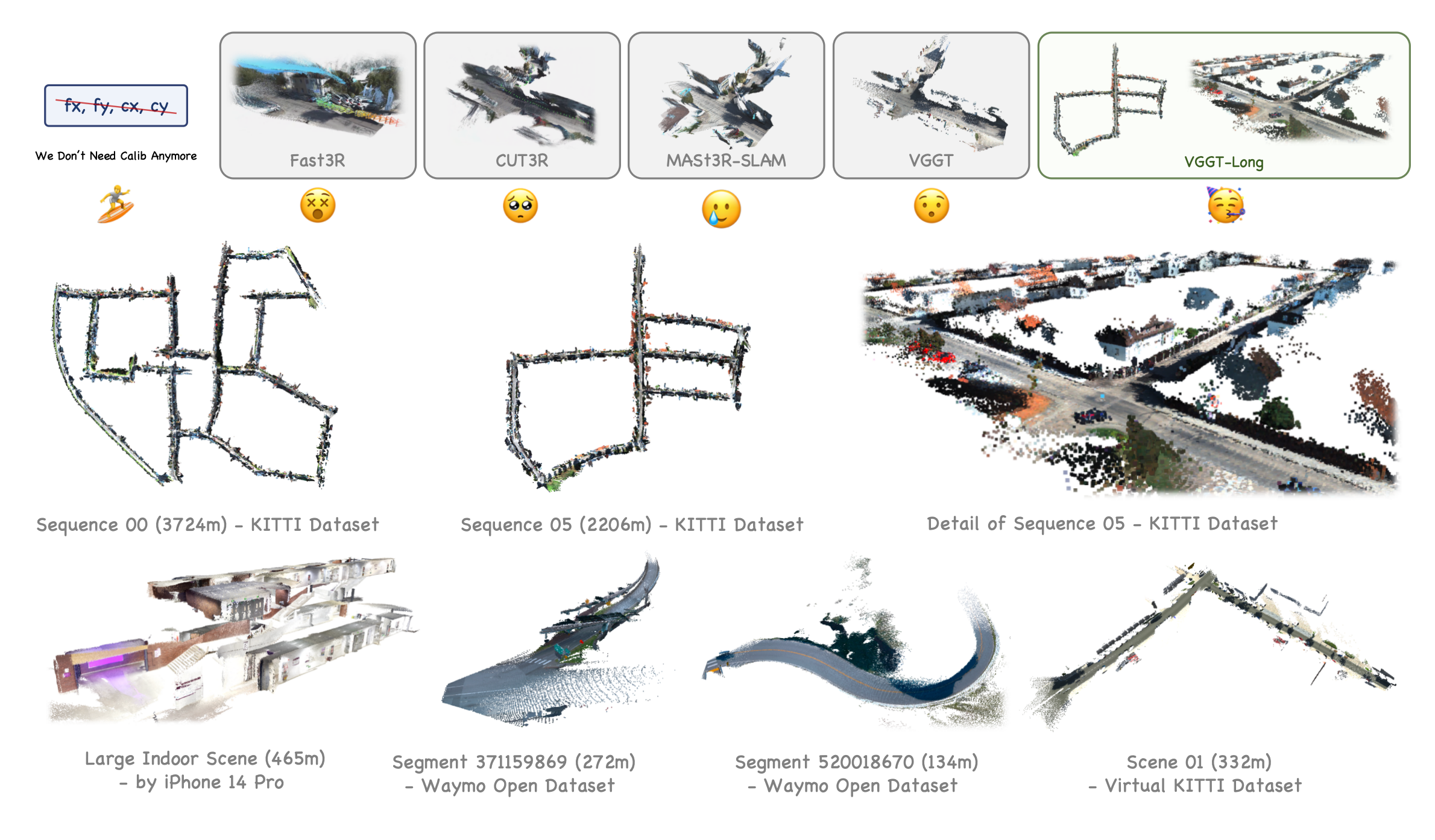
图:VGGT-Long在城市道路场景下的点云对齐效果。高置信度区域(蓝色)主导对齐,动态物体和天空区域(低置信度)被自动降权。
5.5 工程价值与创新点
- 极强的鲁棒性:动态物体、天空等异常区域自动降权,显著提升对齐精度
- 高效收敛:IRLS+加权Umeyama算法,3-5次迭代即可收敛,毫秒级运行速度
- 无须人工干预:完全端到端,适应各种复杂户外场景
置信度感知对齐是VGGT-Long实现公里级高精度重建的关键创新,为后续的回环优化和全局一致性奠定了坚实基础。
6. 循环检测系统:DBoW2与DNIO v2对比与实现
6.1 回环检测的意义
在长序列三维重建中,累积误差(漂移)是影响全局一致性的主要难题。回环检测(Loop Closure)通过识别序列中"走回原地"的时刻,为全局Sim3优化提供强约束,有效抑制误差积累,实现大范围场景的闭环一致性。
6.2 DBoW2方法原理与流程
DBoW2(Bag of Binary Words)是一种基于ORB等局部特征的图像检索方法。其核心流程包括:
- 提取每帧图像的ORB特征
- 构建视觉词袋数据库
- 检索相似帧,计算相似度分数
- 通过阈值和NMS筛选高置信度回环对
代码实现片段
python
# DBoW2回环检测主流程
for frame_id, img_path in tqdm(enumerate(self.img_list)):
image_ori = np.array(Image.open(img_path))
if len(image_ori.shape) == 2:
image_ori = cv2.cvtColor(image_ori, cv2.COLOR_GRAY2RGB)
frame = cv2.resize(image_ori, None, fx=0.5, fy=0.5, interpolation=cv2.INTER_AREA)
self.retrieval(frame, frame_id)
cands = self.retrieval.detect_loop(thresh=..., num_repeat=...)
if cands is not None:
self.retrieval.confirm_loop(*cands)
self.loop_list.append(cands)DBoW2优点是实现简单、速度快、对光照/视角变化有一定鲁棒性,缺点是对动态场景、纹理稀疏区域易误检或漏检。
6.3 DNIO v2方法原理与流程
DNIO v2是一种基于深度学习的视觉位置识别(VPR)方法,采用DINOv2等大模型提取全局特征,流程如下:
- 用DINOv2等ViT模型提取每帧全局描述子
- 计算所有帧间的特征相似度(如余弦相似度)
- 通过阈值和NMS筛选高置信度回环对
- 支持大尺度、语义丰富的场景
代码实现片段
python
# DNIO v2回环检测主流程
self.loop_detector.run()
self.loop_list = self.loop_detector.get_loop_list()DNIO v2优点是对大尺度、语义丰富、动态场景有更强鲁棒性,缺点是推理速度略慢,对显存有一定要求。
6.4 LoopModels模块结构与扩展性
VGGT-Long通过LoopModels和LoopModelDBoW模块实现了两种回环检测方案的无缝切换。配置文件中useDBoW参数可灵活选择:
yaml
Model:
useDBoW: False # True为DBoW2,False为DNIO v2LoopModels模块结构如下:
LoopModels.LoopModel.LoopDetector:DNIO v2主类,负责特征提取与回环筛选LoopModelDBoW.retrieval.retrieval_dbow.RetrievalDBOW:DBoW2主类,负责词袋构建与检索
6.5 两种方法对比与工程建议
| 方法 | 特征类型 | 速度 | 动态鲁棒性 | 适用场景 |
|---|---|---|---|---|
| DBoW2 | ORB等局部特征 | 快 | 一般 | 纹理丰富、静态场景 |
| DNIO v2 | DINOv2等全局特征 | 较慢 | 强 | 大尺度、动态/语义场景 |
实际工程中,推荐优先使用DNIO v2,特殊场景下可切换DBoW2以提升速度。
6.6 回环检测的工程价值
- 全局一致性保障:为Sim3优化提供强约束,消除长序列漂移
- 端到端集成:与VGGT-Long主流程无缝衔接,支持大规模场景
- 灵活可扩展:支持多种VPR模型,便于后续算法升级
回环检测系统是VGGT-Long实现公里级高精度重建的又一核心模块,为全局优化和实际应用提供了坚实保障。
7. 全局Sim3 LM优化算法:理论、实现与效果
7.1 问题背景与目标
即使有分块对齐和回环检测,长序列中仍会因局部误差积累导致全局轨迹漂移。为实现全局一致性,VGGT-Long引入了基于Sim(3)的全局Levenberg-Marquardt(LM)优化,将所有块间的相对变换和回环约束统一纳入非线性最小二乘框架,联合优化所有Sim(3)变量。
7.2 数学原理与优化目标
设 { S k } \{S_k\} {Sk}为每个块的Sim(3)变换, S k , k + 1 S_{k,k+1} Sk,k+1为相邻块间的相对Sim(3), S i j S_{ij} Sij为回环块间的Sim(3)。优化目标为:
{ S k ∗ } = arg min { S k } ∑ k = 1 K − 1 ∥ log S i m ( 3 ) ( S k , k + 1 − 1 S k − 1 S k + 1 ) ∥ 2 + ∑ ( i , j ) ∈ L ∥ log S i m ( 3 ) ( S i j − 1 S i − 1 S j ) ∥ 2 \{S^*k\} = \arg\min{\{S_k\}} \sum_{k=1}^{K-1} \|\log_{Sim(3)}(S_{k,k+1}^{-1} S_k^{-1} S_{k+1})\|^2 + \sum_{(i,j)\in L} \|\log_{Sim(3)}(S_{ij}^{-1} S_i^{-1} S_j)\|^2 {Sk∗}=arg{Sk}mink=1∑K−1∥logSim(3)(Sk,k+1−1Sk−1Sk+1)∥2+(i,j)∈L∑∥logSim(3)(Sij−1Si−1Sj)∥2
其中 L L L为所有回环对, log S i m ( 3 ) ( ⋅ ) \log_{Sim(3)}(\cdot) logSim(3)(⋅)为Sim(3)李群到李代数的对数映射,便于在欧氏空间内优化。
7.3 LM优化流程与工程实现
VGGT-Long采用LM算法高效求解上述非线性最小二乘问题,变量量级远小于传统BA/PGO,收敛速度极快。
关键代码片段
python
# 构造初始Sim3序列
input_abs_poses = self.loop_optimizer.sequential_to_absolute_poses(self.sim3_list)
# 全局LM优化
self.sim3_list = self.loop_optimizer.optimize(self.sim3_list, self.loop_sim3_list)
# 优化后Sim3序列
optimized_abs_poses = self.loop_optimizer.sequential_to_absolute_poses(self.sim3_list)优化主循环伪代码如下:
python
def optimize(sim3_list, loop_sim3_list):
for iter in range(max_iters):
# 构建残差和雅可比矩阵
residuals, jacobian = build_residuals_and_jacobian(...)
# LM步长更新
delta = solve_lm(residuals, jacobian)
# 更新Sim3变量
update_sim3_vars(sim3_list, delta)
if converged(...): break
return sim3_list8. 项目结构与核心模块分析
8.1 目录结构总览
VGGT-Long项目采用模块化设计,核心目录结构如下:
VGGT-Long/
├── vggt_long.py # 主程序入口,整体流程调度
├── configs/ # 配置文件(模型、分块、回环等参数)
├── vggt/ # VGGT模型及其工具集
│ ├── models/ # VGGT主干网络实现
│ ├── utils/ # 图像、几何、加载等工具
│ └── layers/ # 网络层实现
├── LoopModels/ # 回环检测(DNIO v2等)
│ └── LoopModel.py # 回环检测主类
├── LoopModelDBoW/ # 回环检测(DBoW2)
│ └── retrieval/retrieval_dbow.py # DBoW2主类
├── loop_utils/ # Sim3对齐、全局优化、可视化等工具
│ ├── sim3utils.py # 置信度加权对齐
│ ├── sim3loop.py # 全局Sim3 LM优化
│ └── visual_util.py # 点云/轨迹导出与可视化
├── read_ply.py # 点云读取与可视化脚本
├── export_glb.py # glb模型导出脚本
└── exps/ # 实验输出目录8.2 核心模块关系图
VGGT-Long主程序 (vggt_long.py)
分块与内存管理
VGGT推理引擎
置信度感知对齐
循环检测系统
全局Sim3 LM优化
configs/base_config.yaml
vggt/models/vggt.py
loop_utils/sim3utils.py
LoopModels/LoopModel.py
LoopModelDBoW/retrieval/retrieval_dbow.py
loop_utils/sim3loop.py
点云/轨迹导出与可视化
loop_utils/visual_util.py
read_ply.py, export_glb.py
8.3 主要模块职责说明
- vggt_long.py:主控流程,负责分块、推理、对齐、回环、全局优化、结果导出等全链路调度。
- configs/base_config.yaml:集中管理所有参数,支持灵活实验配置。
- vggt/models/vggt.py:VGGT基础模型实现,负责深度、位姿、置信度等核心推理。
- LoopModels/LoopModel.py:基于DINOv2等的回环检测主类,适用于大尺度、动态场景。
- LoopModelDBoW/retrieval/retrieval_dbow.py:DBoW2回环检测主类,适用于静态、纹理丰富场景。
- loop_utils/sim3utils.py:置信度加权Sim3对齐算法实现。
- loop_utils/sim3loop.py:全局Sim3 LM优化算法实现。
- loop_utils/visual_util.py:点云、轨迹等结果的导出与可视化。
- read_ply.py / export_glb.py:点云/模型的读取、可视化与导出脚本。
8.4 工程设计亮点
- 高内聚低耦合:各模块职责清晰,便于维护和扩展
- 配置驱动:所有参数集中管理,实验复现与调优便捷
- 可视化与导出友好:支持多种格式的点云/轨迹/模型导出,便于下游分析与展示
通过模块化与清晰的工程结构,VGGT-Long不仅便于开发者理解和二次开发,也为大规模三维重建任务的工程落地提供了坚实基础。
9. VGGT-Long使用教程(安装与运行全流程)
本节将结合项目README.md,详细介绍VGGT-Long的环境搭建、依赖安装、权重下载、可选模块编译、运行方法、结果可视化与导出等全流程,适合新手和进阶用户参考。
9.1 硬件与系统环境建议
- 推荐GPU:NVIDIA RTX 4090(24GB显存)及以上,支持A100/H100等数据中心级GPU
- 操作系统:Ubuntu 22.04及以上
- CUDA版本:11.8
- Python版本:3.10
- 内存建议:>64GB,磁盘空间>100GB
实测环境如下:
- CPU: Intel Xeon® Gold 6128 CPU @ 3.40GHz × 12
- GPU: NVIDIA RTX 4090 (24 GiB VRAM)
- 内存: 67.0 GiB (DDR4, 2666 MT/s)
- 硬盘: Dell 8TB 7200RPM HDD (Seq. Read 220 MiB/s)
9.2 环境搭建与依赖安装
1. 创建Python虚拟环境
推荐使用conda/miniconda:
bash
conda create -n vggt-long python=3.10
conda activate vggt-long2. 安装PyTorch(CUDA 11.8)
bash
pip install torch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 --index-url https://download.pytorch.org/whl/cu118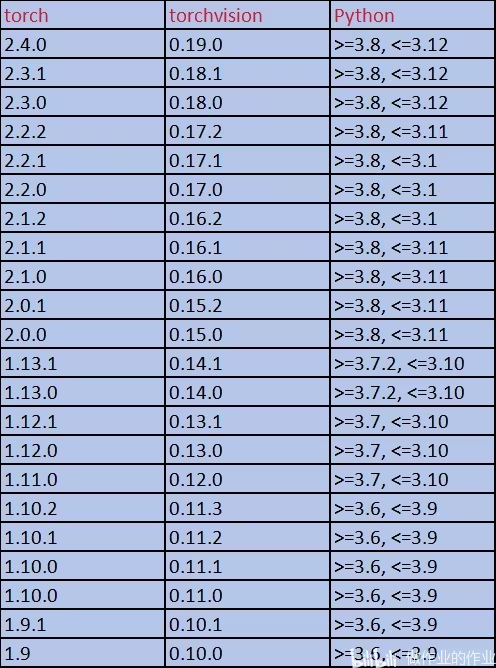
3. 安装其他依赖
bash
pip install -r requirements.txt
pip install trimesh pypose