想起在很久之前,曾经学习机器学习的时候,手写过梯度求导来拟合一个散点的函数参数
https://blog.csdn.net/m0_72678953/article/details/133291795
现在准备下定决心系统性学习下torch,我发现torch可以自动求导,适用于给定散点x序列,在自行指定拟合目标y = 5x + 3的情况下,定义参数w、b,可以让torch使用自动反向传播 + 梯度更新。
这是原先的代码,拟合目标是y = x (虽然现在看也不知道为什么当时随机的y轴会有b=1的偏差,但是结果应该是没问题的)
python
import numpy #发现直接用List就行了
import random
import matplotlib.pyplot as plt
# random.random()
# random.randint(start,stop)
#################全局数据定义区
# 数组大小
listSize=10
# 定义学习率 取尽量小0.001
learningRate=0.0001
#定义初始直线的 斜率k 和 截距b 45° 1单位距离
# 现在设置 k=0.5 检验程序
k,b=0.5,1
#定义迭代次数
bfsNums=9999
#################全局数据定义区END
# 生成随机数
def generateRandomInteger(start, end):
# [1-100]
return random.randint(start, end)
# 打印本次随机生成的X,Y 便于快速粘贴复现
def printXYArray(XData,YData):
# 打印X
print("[", ",".join([str(i) for i in XData]), "]")
# 打印Y
print("[", ",".join([str(i) for i in YData]), "]")
# 最小二乘法定义损失函数 并计算
#参考链接:https://blog.csdn.net/zy_505775013/article/details/88683460
# 求最小二乘法的最小值 最终结果应当是在learningRate一定情况下 这个最小的sum
def calcLoseFunction(k,b,XData,YData):
sum=0
for i in range(0,listSize):
# 使用偏离值的平方进行累和
sum+=(YData[i]-(k*XData[i]+b))**2
return sum
#梯度下降法
def calcGradientCorrection(b, k, XData, YData, learningRate, bfsNums):
for i in range(0, bfsNums):
sumk, sumb = 0, 0
for j in range(0, listSize):
# 定义预测值Y'
normalNum = k * XData[j] + b
# 计算逆梯度累和 注意这里求偏导应当是两倍 不知道为什么写成1了
# 求MSE的偏导
sumk += -(2 / listSize) * (normalNum - YData[j]) * XData[j]
sumb += -(2 / listSize) * (normalNum - YData[j])
# 在逆梯度的方向上进行下一步搜索
k += learningRate * sumk
b += learningRate * sumb
return k, b
# 随机生成横坐标
XData=[generateRandomInteger(1,100) for i in range(listSize) ]
# 随机生成纵坐标
YData=[XData[i]+generateRandomInteger(-10,10) for i in range(listSize) ]
# 纯随机生成 但是可视化效果不直观
# YData=[generateRandomInteger(1,100) for i in range(listSize) ]
# 死值替换区
# XData=testArrayX
# YData=testArrayY
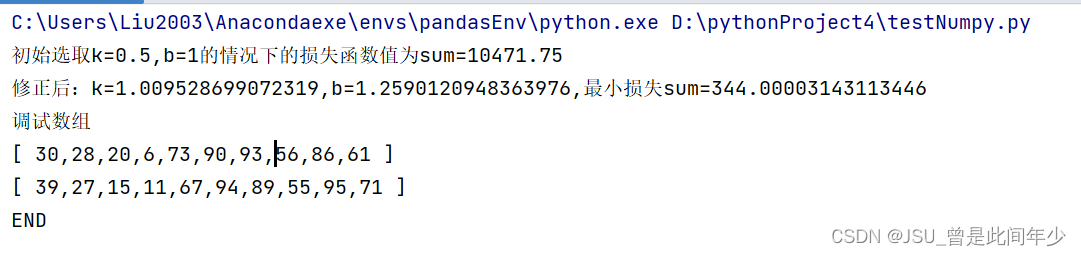
print("初始选取k={},b={}的情况下的损失函数值为sum={}".format(k,b,calcLoseFunction(k,b,XData,YData)))
# 对k,b进行梯度修正
k,b=calcGradientCorrection(b,k,XData,YData,learningRate,bfsNums)
print("修正后:k={},b={},最小损失sum={}".format(k,b,calcLoseFunction(k,b, XData, YData)))
print("调试数组")
printXYArray(XData,YData)
#画图
plt.plot(XData, YData, 'b.')
plt.plot(XData, k*numpy.array(XData)+b, 'r')
plt.show()
print("END")下面是使用torch编写的代码:
python
import torch
# 输入数据(不需要梯度),目标是使用一次函数拟合x
x = torch.tensor([1.0, 2.0, 3.0])
# 真实值
y_true = 5 * x + 3 # tensor([8., 13., 18.])
# 要学习的参数(叶子节点,需要梯度)
w = torch.tensor([0.], requires_grad=True)
b = torch.tensor([0.], requires_grad=True)
# 定义一个优化器,并告诉它要优化哪些参数
optimizer = torch.optim.SGD([w, b], lr=0.01)
# 模拟训练过程
for epoch in range(9999):
# 前向传播: y_pred = w * x
y_pred = w * x + b # 这是一个关于x的复杂函数,但关于w是线性的
# 计算损失
loss = ((y_pred - y_true) ** 2).sum()
# 反向传播
loss.backward()
# 打印梯度。这个梯度是 loss 相对于 w 的导数,即 d(loss)/dw
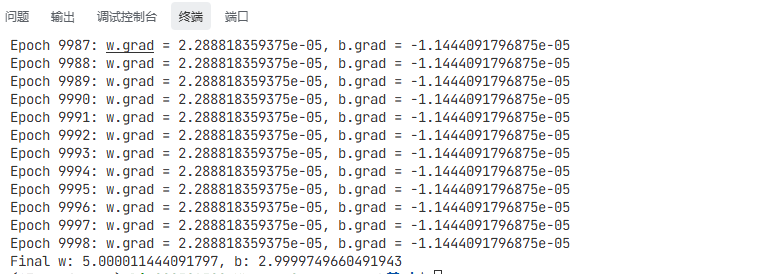
print(f"Epoch {epoch}: w.grad = {w.grad.item()}, b.grad = {b.grad.item()}")
# 自动参数更新
optimizer.step() # 优化器根据梯度更新参数(内部已经处理了no_grad逻辑)
# 手动更新参数(通常用优化器,这里为了演示)
# with torch.no_grad():
# w -= 0.01 * w.grad
# b -= 0.01 * b.grad
# # 清零梯度!!!非常重要
# torch的梯度累加特性,可以让大量数据按照小批次分批训练,
# 一定批次后再调用参数清空,这样就能实现小显存训练大批次的效果
w.grad.zero_()
b.grad.zero_()
print(f"Final w: {w.item()}, b: {b.item()}")可以看到torch编写的代码非常优雅,定义一个优化器,指定学习率和参数,然后嗲用反向传播和参数自动更新,依赖广播机制就能替代之前一长串的循环和参数更新了。非常方便