文章目录
摘要
本周阅读了清华大学的论文《TurboDiffusion: Accelerating Video Diffusion Models by 100--200 Times》,了解了扩散模型新的加速框架和恐怖的加速能力。
Abstract
This week, I read the Tsinghua University paper 'TurboDiffusion: Accelerating Video Diffusion Models by 100--200 Times' and learned about a new acceleration framework for diffusion models and its astonishing speed-up capabilities.
1.TurboDiffusion
在视频生成领域,扩散模型的推理延迟很高很高,清华大学、生数科技和UC Berkeley联合发布了TurboDiffusion,实现端到端的系统优化,视频生成的速度提升了一百到二百倍,质量却几乎没有损失。
多重注意力机制加速:结合低比特 SageAttention 与可训练的 Sparse-Linear Attention (SLA),大幅降低注意力计算开销。
高效步数蒸馏:采用最新的 rCM 蒸馏技术,将采样步数从上百步压缩至 3-4 步。
全链路量化方案:引入 W8A8 (INT8) 权重与激活值量化,优化线性层执行效率。
极致工程优化:基于 Triton 和 CUDA 重写 LayerNorm 等关键算子,消除系统瓶颈。
1.1 注意力改进
(1) SageAttention (低比特加速)
SageAttention 是一种针对 8-bit 量化设计的注意力加速算子。它在保证精度的前提下,充分利用 Tensor Core 的算力。
(2) Sparse-Linear Attention (SLA)
SLA 通过引入稀疏性来打破平方复杂度的瓶颈。其核心思想是只计算部分关键权重的注意力。
A t t e n t i o n ( Q , K , V ) = S o f t m a x ( Q K T d × M ) V Attention(Q,K,V)=Softmax(\frac{QK^T}{\sqrt d} \times M )V Attention(Q,K,V)=Softmax(d QKT×M)V
M M M是稀疏掩码矩阵,由Top-K策略生成。
× \times ×代表逐元素生成。
由于稀疏计算与低比特 Tensor Core 加速是正交的,TurboDiffusion 将两者结合为 SageSLA,实现了累加的性能提升。
1.2蒸馏模型
基于 rCM 的步数蒸馏,为了减少推理步数,TurboDiffusion 采用了 rCM (Score-regularized Continuous-time Consistency) 蒸馏技术。rCM 属于一致性模型(Consistency Models)的进阶版,通过引入分数正则化,使得学生模型在极少步数下(如 3-4 步)仍能保持极高的生成质量。
1.3权重量化
在扩散模型中有大量的线性层,如nn.Linear(in_channel,d_model),这些操作的权重以及激活函数的激活值占据了大量的内存,加载权重都花费了大量的时间也增加了显存,所以采用W8A8,粒度128 x 128的全量化方式,128 x 128就是把权重矩阵切成128行x128列的小块,每个小块肚子量化;W8A8,权重和激活值都用INT8的数据类型保存。
2 训练和推理
2.1 训练阶段
稀疏适配:将原预训练模型中的 Full Attention 替换为 SLA,通过微调(Fine-tuning)让模型适应稀疏计算。
并行蒸馏:同时利用 rCM 技术将模型蒸馏为少步数模型。
权重融合:将 SLA 微调和 rCM 训练得到的权重更新合并,形成最终的加速版模型。
2.2 推理阶段
算子替换:SLA 升级为高性能的 SageSLA CUDA 实现。
采样压缩:设置步数为 3 或 4。
动态量化:在推理运行过程中对激活值进行实时 INT8 量化。
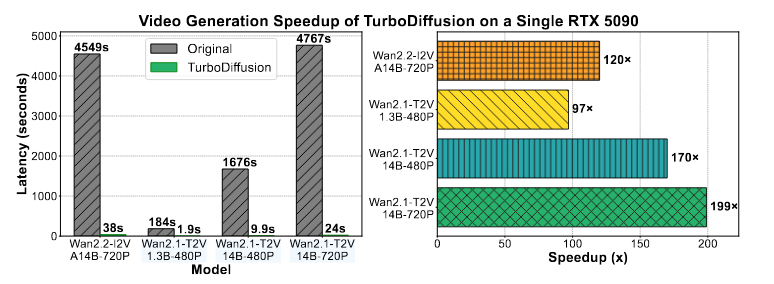
在Wan2.1-T2V小参数量的模型下,生成480p的视频只需要1.9s,对14B的模型的加速效果达到了199倍,而且只需要在单张5090就可以进行推理。
3 Make It Count
CVPR2025的论文《Make It Count: Text-to-Image Generation with an Accurate Number of Objects》,论文针对的是生成模型生成的物体数量和提示词的不一致的问题,他们提出了一种叫做CountGen的架构。
文章的摘要:
尽管文本到图像的扩散模型取得了前所未有的成功,但使用文本来控制描述对象的数量是非常困难的。这对于从技术文件、儿童读物到烹饪食谱的各种应用都很重要。生成对象正确的计数在本质上是具有挑战性的,因为生成模型需要对对象的每个实例保持单独的身份感,即使几个对象看起来相同或重叠,然后在生成过程中隐式地执行全局计算。这种表象是否存在,目前还不得而知。为了解决计数正确的生成问题,我们首先在扩散模型中识别能够携带物体身份信息的特征。 然后使用它们在去噪过程中分离和统计对象的实例,并检测过生成和欠生成。我们通过训练一个模型来修复后者,该模型可以根据现有物体的布局来预测丢失物体的形状和位置,并展示了它如何使用正确的物体计数来指导去噪。我们的方法CountGen并不依赖于外部来源来确定对象布局,而是利用了来自扩散模型本身的先验,创建了依赖提示和依赖种子的布局。在两个基准数据集上进行评估,我们发现CountGen明显优于现有基线的计数精度。
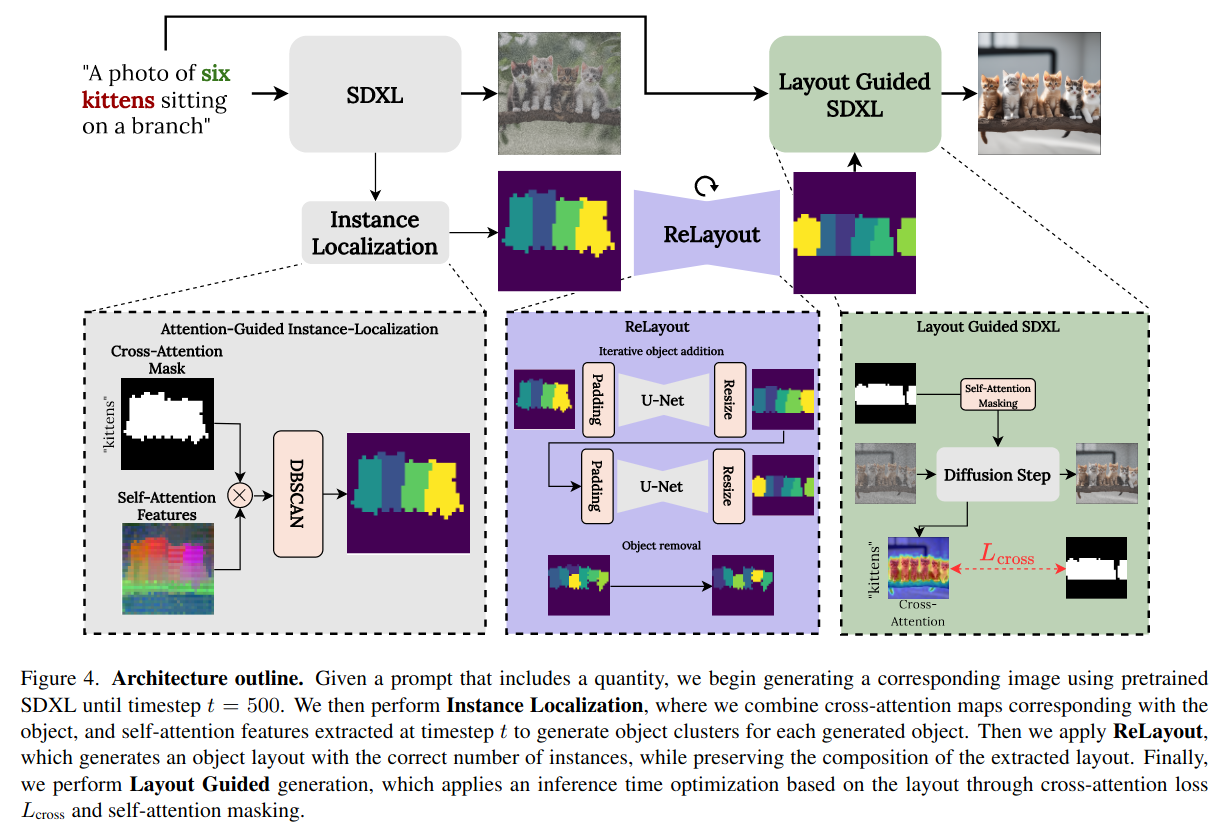
然后看到论文的第三章,描述了他们的主要做法:
1)输入提示词,借助SDXL模型生成图片,但是在生成过程中(t=500)打断模型,得到一个模糊的图像,进行物体定位,提取模糊的布局图。
2)训练一个ReLayout模型,对原本的k个物体的布局图生成k+1个无图的布局图,迭代到正确的数量,得到修正的布局图。
3)得到修正布局图,回到扩散模型生成过程,在文本提示的指导下继续生成,得到正确物体数量的图片。
3.1数据集
模型训练需要k到k+1的布局对的数据集,作者发现提示词中除了指定物体的计数有变化,其他的噪声之类的超参数都一致的情况下,得到的生成图片布局类似,就可以通过这个步骤生成布局数据集。
3.2损失函数
在掩码修正部分使用的是DCIE和Overlap掩码,描述掩码之间的差异。
L ( c , m ) = − Σ i ω i ( m i l o g c i + ( 1 − m i ) l o g ( 1 − c i ) ) L(c,m)=-\Sigma_i \omega_i(m_ilog c_i + (1-m_i)log(1-c_i)) L(c,m)=−Σiωi(milogci+(1−mi)log(1−ci))
论文定义了一个加权的二元交叉熵损失,m是二值掩码, m i = 1 m_i=1 mi=1代表像素i属于物体, m i = 0 m_i=0 mi=0代表物体属于背景。c是从扩散模型提取的关于目标词的聚合交叉注意力分数, c i c_i ci越高,代表像素i属于物体概率越大。
损失函数奖励m为1,交叉注意力分数c越高的地方,惩罚m为0,出现高c值的位置。
总结
本周联系之前的内容,在扩散模型的速度问题和计数问题上进行学习。