目录
摘要
本周学习了推荐系统中的均值归一化方法及其重要性,该方法通过减去每部电影的平均评分来提升算法效率,并为未评分的新用户提供更合理的初始预测。同时,初步接触了使用 TensorFlow 实现协同过滤算法,了解了如何利用其自动求导功能简化模型优化过程,减少手动计算导数的工作量。
Abstract
This week, I studied mean normalization in recommendation systems and its role in improving algorithm performance by centering movie ratings around their averages. This approach also enables better predictions for new users who have not yet rated any movies. Additionally, I explored the implementation of collaborative filtering using TensorFlow, learning how its automatic differentiation feature simplifies gradient calculation and model optimization.
一、均值归一化
特征均值归一化可以帮助算法运行的更快,在构建一个算法广泛的推荐系统时,例如电影评分从1到5或0到5星,事实证明,如果我们首先进行均值归一化,我们的算法将运行得更加高效,性能也会有所提升,也就说,如果我们将电影评分归一化到一个一致的平均值,这是我们一直在使用的数据集,下面是我们用来学习模型的代价函数
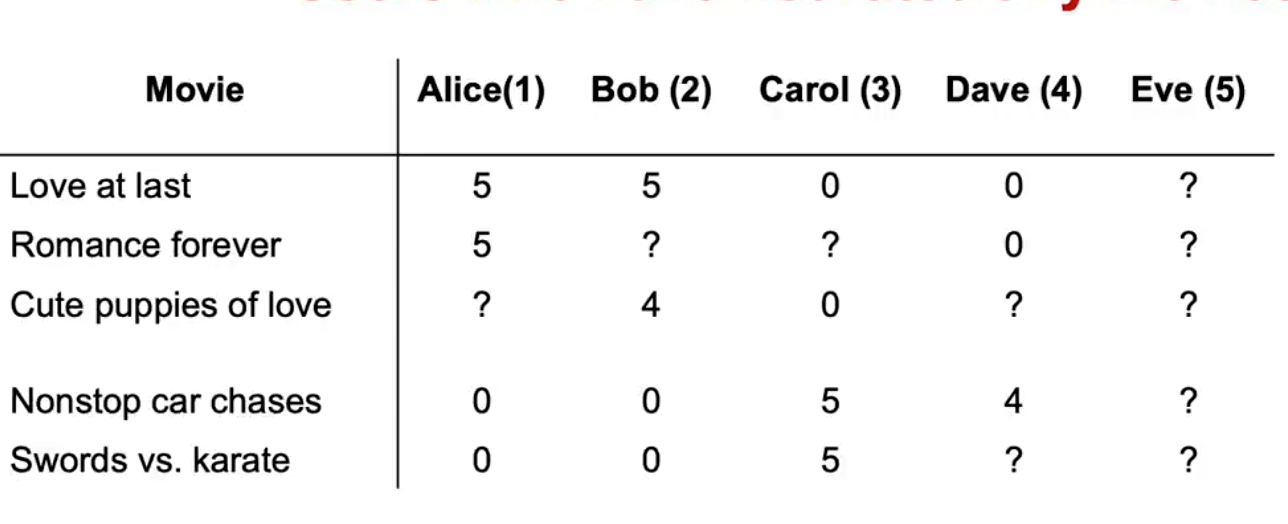
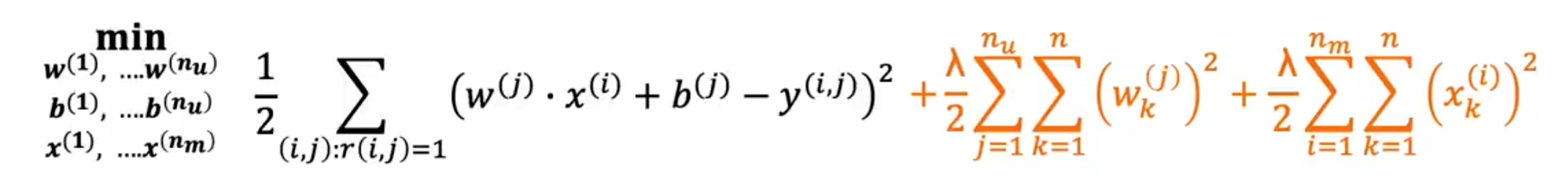
为了解释均值归一化,我们实际会添加一个第五位用户,Eve她还没有对任何电影进行评分,我们稍后会看到,加入均值归一化将帮助算法为用户Eve更好的预测,那么因为我们试图通过这个正则化使参数w1变小,我们最终会得到第五位用户的参数w,对于用户Eve来说,b5可能为0,因为Eve还没对任何电影进行评分,参数w和b不会影响代价函数中的第一项,因为Eve的电影评分在这个平方误差代价函数中不起作用,所以,最小化这个项意味着使参数w尽可能小,我们还没有真正对b进行正则化,我们最终也会得到b5等于0,但是如果这些用户5的参数,也就是Eve的参数,那么算法最终会预测Eve对所有电影的评分将是w5点乘x,加上b5,而这个等于0
所以这个算法将预测如果有一个尚未评分的新用户,所以在这个小节中,我们会看到均值归一化将帮助这个算法更好地预测新用户尚未评分的电影评分,为了描述均值归一化,包括Eve的所有问号,并把它们放在一个二维矩阵,包括问号

以一种更简洁或者更紧凑的方式,我们要做的就是取所有的这些评分,并针对每部电影,计算给出的平均评分,平均评分2.5,电影3平均是2,电影4平均是2.5,电影五的平均是1.25,所以我们将这五个数字汇集成一个向量,我们称这为μ,因为这是每部电影的平均评分向量,仅针对评分过该电影的用户求平均值,而不是使用这里原来的0到5星评分,我们将每个评分减去它的平均分

针对所有现在的五个用户,包括新用户Eve,然后右边的这些新值会成为我们的新值,我们假设用户1给了电影1一个2.5的评分,给电影4一个-2.25的评分,使用这个,我们可以学习wj,和以前一样,对于电影i的用户j,但是因为我们在这个平均标准化的步骤减去了电影的i的μi,这是不可能的,如果用户评分在0星到5星之间,就是我们减去的值,对于新用户Eve,算法可能会学习到参数w5 = 0,然后b5 = 0,所以如果我们看看电影1的评分,我们将预测Eve会给它评分w5.x1加上b5,但这是0,再加上μ1,所以认为Eve可能会给这部电影打2.5分似乎更合理,而不是认为Eve会给所有电影打0分,仅仅因为她还没有评分任何电影,事实上,这种算法的效果是让新用户Eve的初始猜测等于其他用户对这五部电影的平均评分,而且相比猜测Eve所有的评分都是0,取电影的平均评分更合理,事实证明,通过将不同电影评分的平均值归一化为0,推荐系统的优化算法运行速度也会稍微快一点,但这确实使得该算法对没有评分或评分很少的用户表现良好,预测也会变得更加合理,我们看到这对于尚未评分很多电影的新用户有所帮助
二、协同过滤的TensorFlow实现
在本节中,我们将了解如何使用TensorFlow实现协同过滤算法,我们可能习惯将TensorFlow视为构建神经网络的工具,事实证明,TensorFlow在构建其他类型的学习算法也非常有用,TensorFlow处理这类问题是非常在行的,对于许多应用来说,比如,我们需要找到成本函数的导数,TensorFlow可以自动帮我们找出成本函数的导数,我们只需要实现成本函数,无需自己求导,只需几行代码,就可以用TensorFlow计算出可以用来优化,我们可能还能记得第一课的图
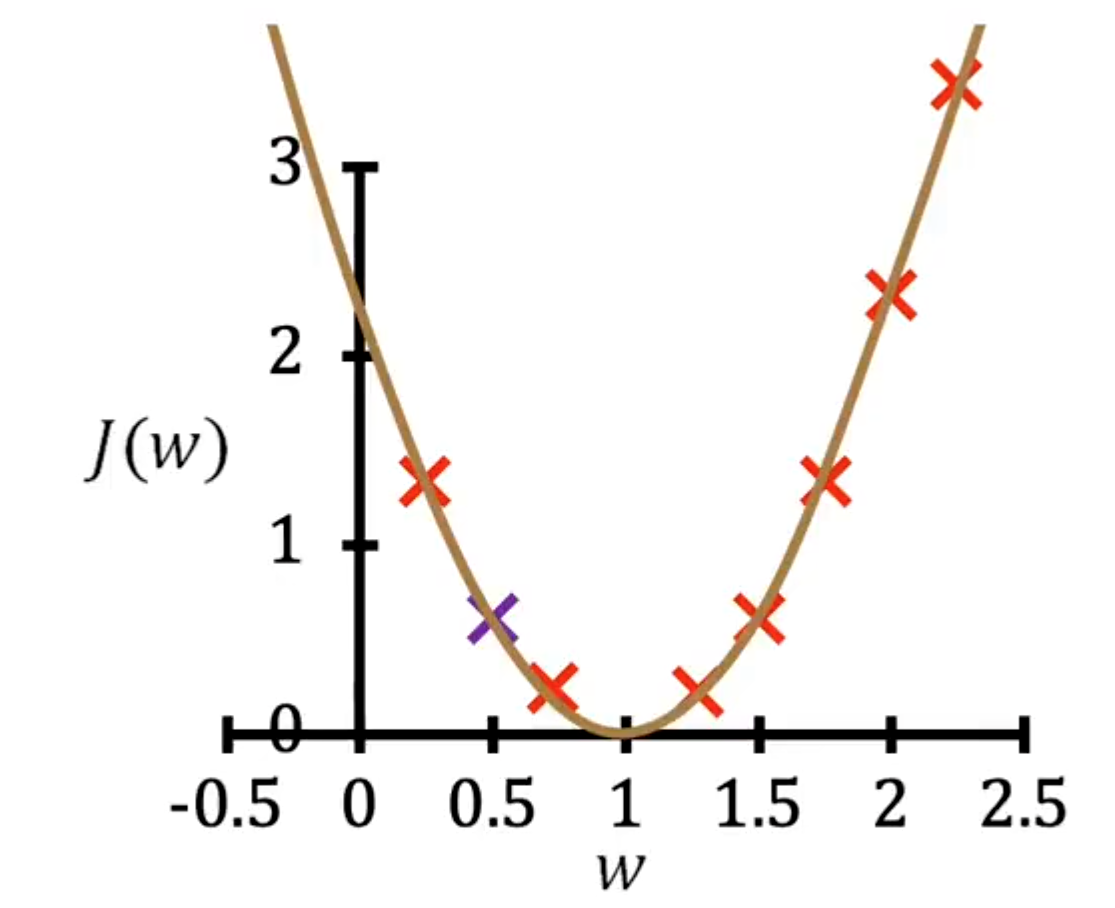
这正是我们在讲述如何优化w时看过的示意图,当时我们在处理我们的,那时候我们让b = 0,我们采用的方式是通过梯度下降更新,反复更新w,作为w减去学习率α乘以导数项,但如果我们选择b = 0,我们只需要放弃第二次更新,继续执行这个梯度下降更新直到收敛,有时计算这个导数或偏导数项可能很困难,事实证明,TensorFlow可以在这方面提供帮助,我们将使用这个函数
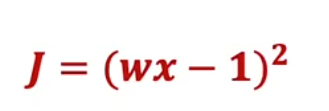
代码如下
python
w = tf.Variabale(3,0)
x = 1.0
y = 1.0 # target value
alpha = 0.01
iterations = 30
for iter in range (iterations):
with tf.GradientTape() as tape:
fwb = w*x
costJ = (fwb - y)**2
[djdw] = tape.gradient(costJ, [w])
w.assign_add(-alpha * djdw)由此可见,TensorFlow可以自动帮我们计算导数,避免了很多没有复杂的计算
总结
一是理解了均值归一化的作用,它通过调整评分数据来加速算法运行,并让新用户的预测更贴近电影的平均评分,而非默认零值。二是学习了用 TensorFlow 实现协同过滤的基本方法,体会到框架自动求导的优势,可以更专注于模型构建而减少繁琐的数学计算。整体上,对推荐系统的基础处理技术和工具使用有了更直观的认识。