Python 虚拟环境的 "环境隔离" 作用
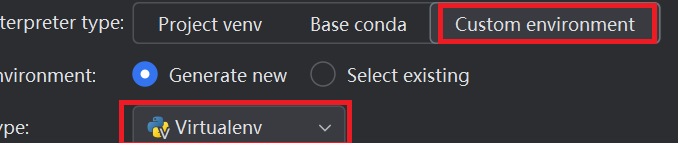
核心逻辑:
每个项目(比如test01、test02)可以有自己独立的 "虚拟环境",不同项目的依赖包(比如requests这类库)互不干扰。
对应图里的内容:
- 左边的
python框:代表全局环境(如果不搞虚拟环境,所有项目都会共用这里的包)。 - 中间
test01框:是项目 1 的独立虚拟环境 ,里面装了a、b、c这些包(只给 test01 用)。 - 右边
test02框:是项目 2 的独立虚拟环境 ,里面装了d、e、f这些包(只给 test02 用)。
为什么要隔离?
比如:
- 项目 A 需要
requests=2.31.0,项目 B 需要requests=3.0.0 - 如果不用虚拟环境,两个版本会冲突;用了虚拟环境,每个项目装自己需要的版本就行。
简单说:虚拟环境就是给每个项目 "单独开个小房间",里面的包自己用自己的,互不打扰
一、接口自动化测试
1.1第⼀个简单的接⼝⾃动化
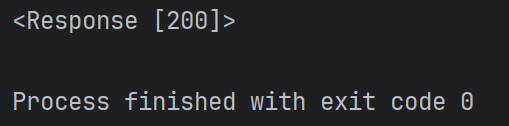
⽰例:对百度接⼝发起请求

返回值:
1.2requests模块
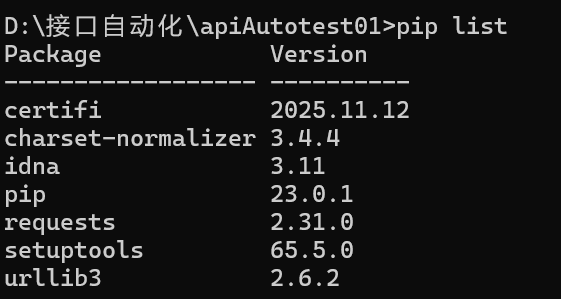
命令⾏通过pip⼯具进⾏安装,命令:
pip install requests==2.31.0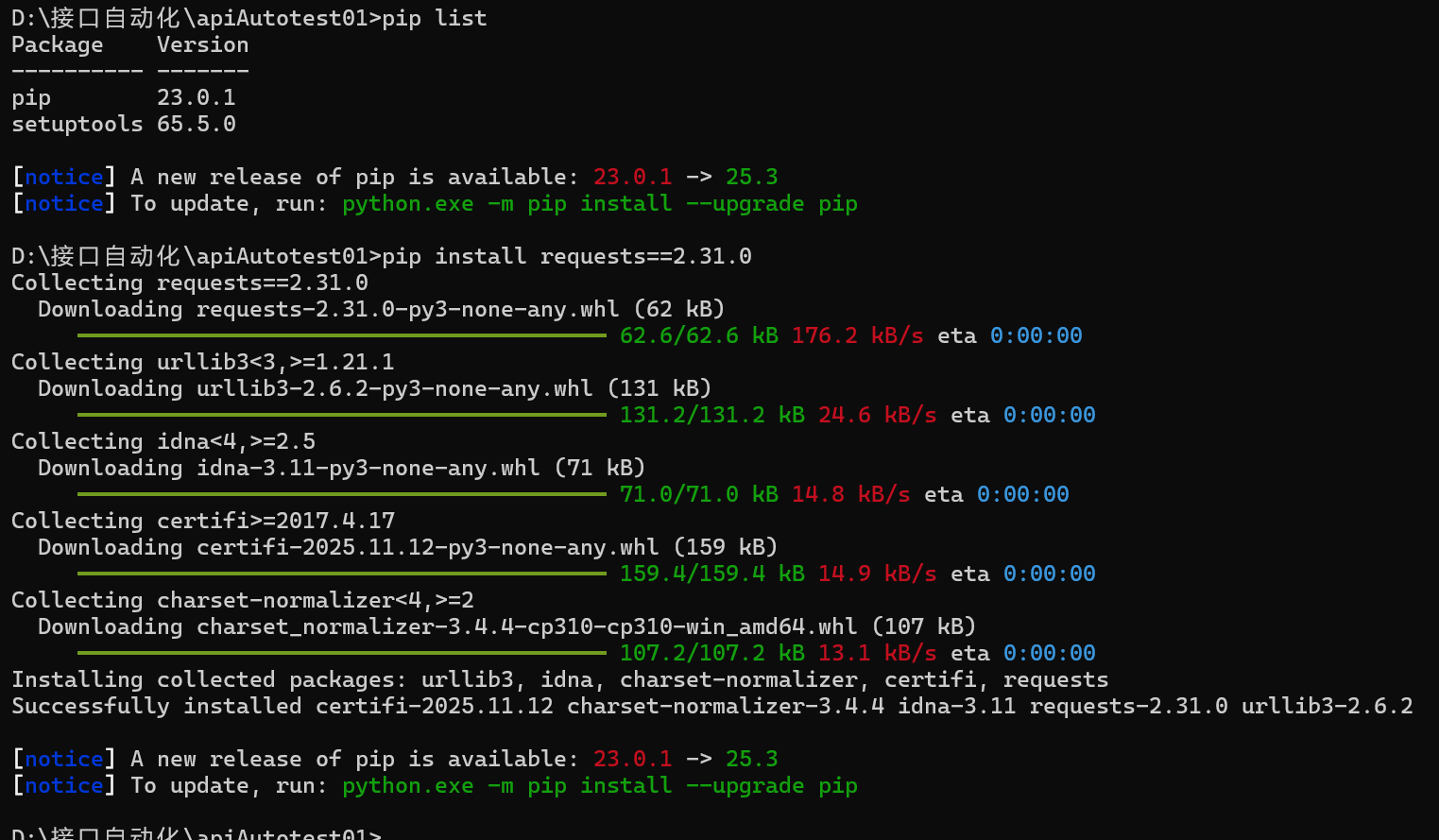
检查当前项目包下是否更新:
1.2.3requests 库介绍
先回顾基础:requests.get()与 Response 对象
requests.get("URL"):发送GET 请求 到指定网址,返回一个Response对象(你可以理解为 "服务器的回信")。Response对象包含了服务器返回的所有信息,比如状态码、内容、响应头等等
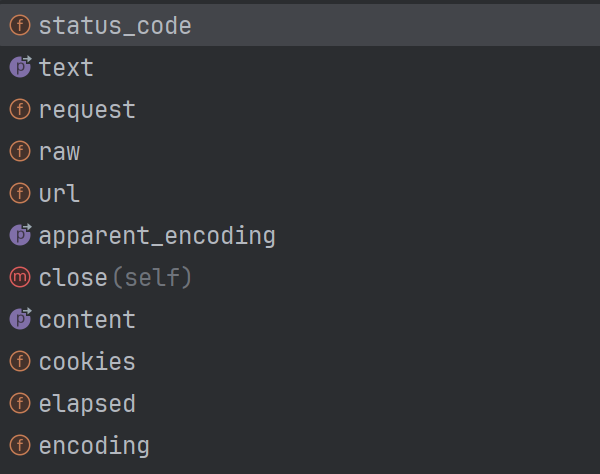
Response 对象的常用属性 / 方法(重点记这几个)
| 属性 / 方法 | 作用(大白话) |
|---|---|
r.status_code |
看请求成功没(200 = 成功,404 = 找不到页面,500 = 服务器出错) |
r.text |
把响应内容转成字符串(比如百度首页的 HTML 代码,直接打印就能看) |
r.content |
响应内容的原始字节(比如下载图片 / 文件时用) |
r.json() |
如果响应是 JSON 格式(接口常用),直接转成 Python 字典 / 列表 |
r.headers |
服务器返回的 "响应头"(比如告诉你内容类型、编码方式) |
1.2.4常⻅请求⽅法
requests支持 HTTP 的所有请求方式,这里讲了 3 个核心用法:
1. requests.get():发 GET 请求
- 用途:从服务器获取数据(比如查新闻、搜内容)。
- 示例:
get_r = requests.get("https://www.baidu.com")
2. requests.post():发 POST 请求
- 用途:向服务器提交数据(比如登录、提交表单、上传文件)。
- 传参:可以用
data(表单格式)或json(JSON 格式)传数据,示例:

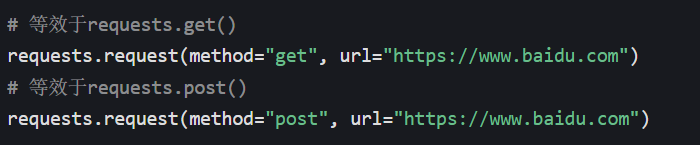
3. requests.request():万能请求方法
- 用途:可以指定任意请求方式(GET/POST/PUT/DELETE 等),是
get()/post()的 "底层方法"。 - 传参:用
method参数指定请求类型,示例:
1.2.5添加请求信息
requests库的get()、post()方法底层都基于request()实现,因此这三个方法的传参规则基本一致,可传递的参数主要用于配置请求的各类信息。
| 参数名 | 描述 |
|---|---|
| url | 请求的接口 |
| headers | 一个字典,包含要发送的 HTTP 头。 |
| cookies | 一个字典、列表或者 RequestsCookieJar 对象,包含要发送的 cookies。 |
| files | 一个字典,包含要上传的文件。 |
| data | 一个字典、列表或者字节串,包含要发送的请求体数据。 |
| json | 一个字典,将被转换为 JSON 格式并发送。 |
| params | 一个字典、列表或者字节串,将作为查询字符串附加到 URL 上。 |
| auth | 一个元组,包含用户名和密码,用于 HTTP 认证。 |
| timeout | 一个浮点数或元组,指定请求的超时时间。 |
| proxies | 一个字典,包含代理服务器的信息。 |
| verify | 一个布尔值或字符串,指定是否验证 SSL 证书。 |
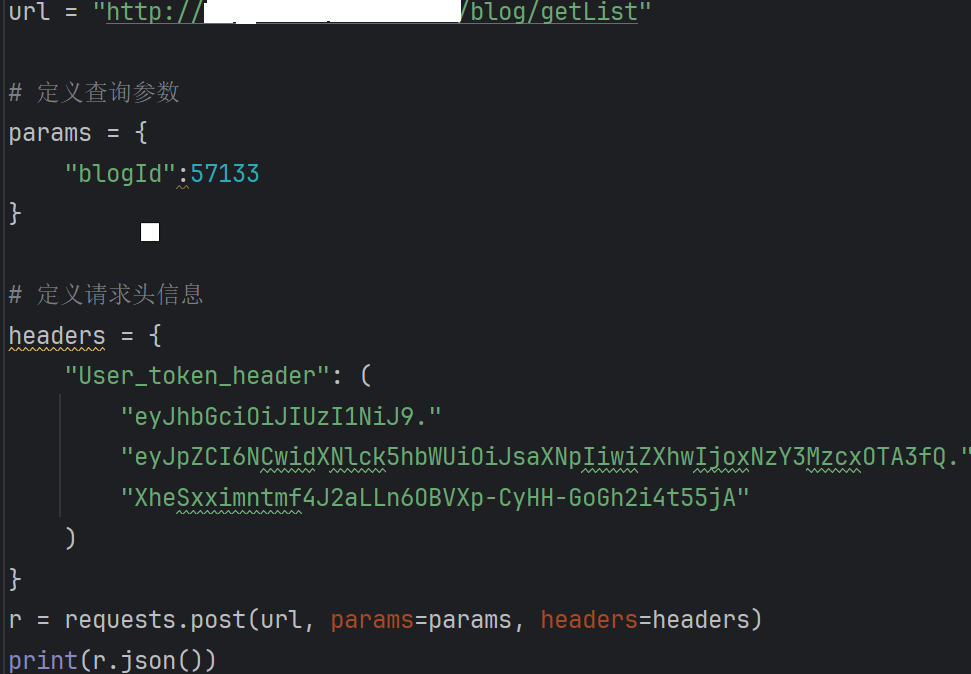
⽰例1:博客详情接⼝

示例2:博客登录接口:
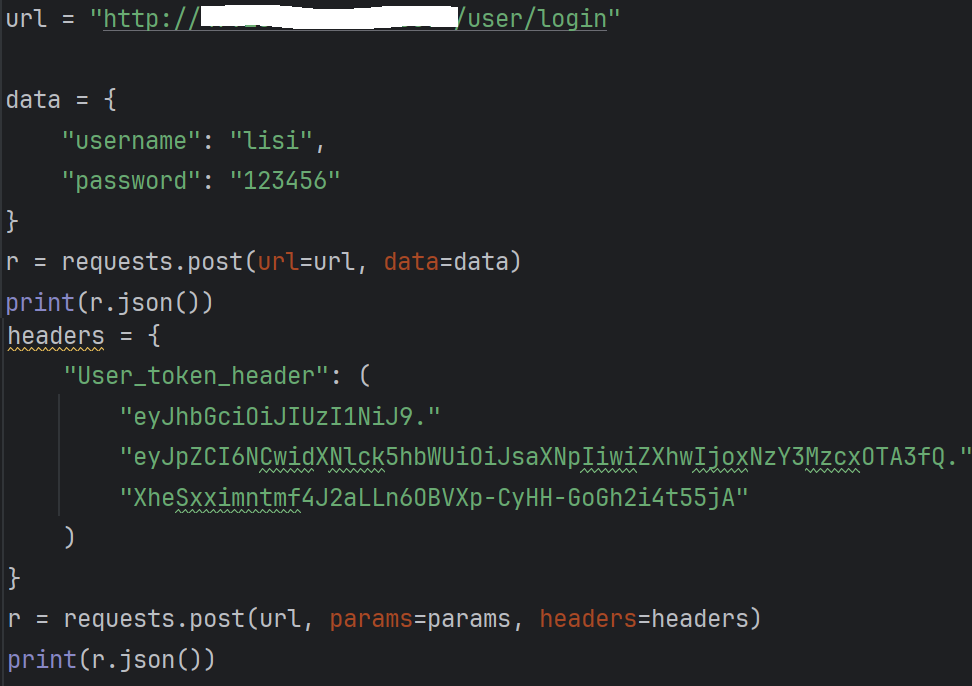
| 传参方式 | 实际位置 | 通俗理解 | 常用请求方法 |
|---|---|---|---|
params |
URL 末尾拼接 | 跟在网址后面的 "明文参数" | GET(核心) |
data |
请求体(Body) | 藏在请求 "肚子里" 的参数 | POST(核心) |
为什么登录接口不用params?
- 安全问题:登录的账号密码拼在 URL 里,会被浏览器记录、服务器日志留存,极易泄露;
- 后端设计:登录接口几乎都是 POST 请求,后端会从 "请求体(Body)" 读取参数,用
params传根本收不到。
requests库的 3 种传参方式(核心区别)
| 传参参数 | 传递位置 | 数据格式 | 常用请求方法 | 自动设置的 Content-Type |
|---|---|---|---|---|
params |
URL 查询参数 | 键值对(明文) | GET | -(无需设置) |
json |
请求体(Body) | JSON 格式 | POST/PUT | application/json |
data |
请求体(Body) | 表单格式 | POST/PUT | application/x-www-form-urlencoded |
requests与pytest的分工(接口自动化测试场景)
requests:专注于发送 HTTP 请求(如调用接口、传递参数);pytest:负责测试用例的组织、执行、管理(如批量运行用例、生成报告、断言结果)。
这两个工具是接口自动化测试的基础组合:用requests实现接口调用,用pytest实现测试流程的规范化管理。
2.1自动化框架pytest
⽀持Python语⾔的接⼝⾃动化框架有很多,以下是⽀持Python的接⼝⾃动化主流框架对⽐分析:
主流框架对⽐表:
| 维度 | unittest(Python 内置) | pytest | Robot Framework |
|---|---|---|---|
| 安装方式 | 无需安装(Python 标准库) | pip install pytest | pip install robotframework |
| 语法风格 | 基于类(需继承 TestCase) | 函数式或面向对象(无需样板代码) | 关键字驱动(表格化用例) |
| 断言方法 | self.assertEqual () 等 | 原生 assert 表达式 | 关键字断言(如 Should Be Equal) |
| 参数化支持 | 需 subTest 或第三方库 | 内置 @pytest.mark.parametrize | 数据驱动(Test Template) |
| 插件生态 | 少(依赖扩展库如 HTMLTestRunner) | 丰富(如 pytest-html、pytest-xdist、allure-pytest) | 一般(需安装额外库如 RequestsLibrary) |
| 测试报告 | 需插件生成报告 | 支持多格式报告(HTML、Allure 等) | 自带详细日志和报告 |
| 学习曲线 | 中等(需熟悉 xUnit 模式) | 低(语法简洁) | 高(需掌握关键字和语法) |
| BDD 支持 | 不支持 | 支持(通过 pytest-bdd 插件) | 支持(通过 robotframework-bdd) |
| 适用场景 | 简单项目或遗留系统维护 | 复杂项目、高扩展性需求 | 团队协作、非技术人员参与 |
2.1.1pytest介绍
pytest官⽅⽂档:https://docs.pytest.org/en/stable/getting-started.html
pytest 的定位
是一款流行且高效的 Python 测试框架,核心作用是简化测试用例的编写与执行。
核心优势(选择 pytest 的原因)
| 优势分类 | 具体说明 |
|---|---|
| 简单易用 | 语法简洁,上手门槛低,可快速编写测试用例。 |
| 断言库强大 | 内置丰富断言能力,便于判断测试结果是否符合预期。 |
| 支持参数化测试 | 可通过不同参数多次运行同一测试函数,提升测试效率。 |
| 插件生态丰富 | 可通过插件扩展功能(如pytest-html生成 HTML 报告、pytest-rerunfailures重跑失败用例);同时支持与 selenium、requests 等工具结合,实现 Web / 接口 / App 自动化测试。 |
| 测试控制灵活 | 支持跳过指定用例、标记预期失败用例,还可重复执行失败用例。 |
2.1.2安装
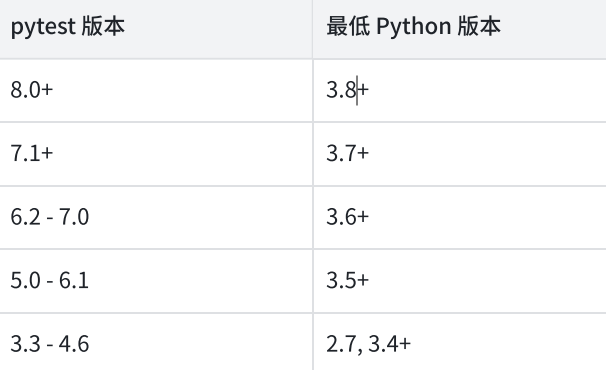
安装 pytest8.3.2 要求 python 版本在3.8及以上。

安装成功:

安装好 pytest 后,确认pycharm中python解释器已经更新,来看⼀下有 pytest 框架和没有 pytest 框架编写代码的区别:
未安装pytest:

安装pytest:
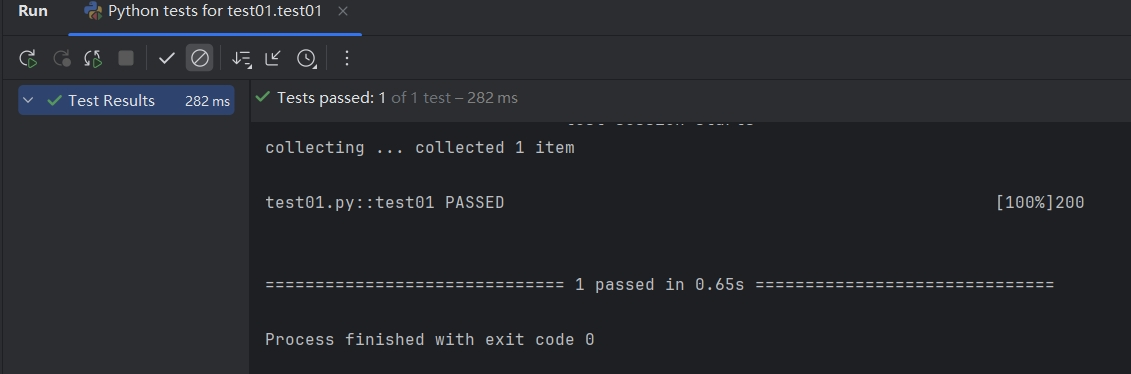
测试方式的差异(pytest vs 无框架)
| 场景 | 测试用例执行方式 |
|---|---|
| 未安装 pytest 框架 | 需编写main函数,手动在main中调用测试用例(如test01) |
| 安装 pytest 框架后 | 测试方法前会出现直接运行标志,无需手动写main函数调用 |
2.1.3用例运行规则的

| 规则项 | 具体要求 |
|---|---|
| 文件名 | 必须以test_开头,或以_test结尾(如test_01.py) |
| 测试类 | 必须以Test开头,且不能包含__init__方法(pytest 会自动实例化测试类) |
| 测试方法 | 必须以test开头(如test01(self)) |
当满⾜以上要求后,可通过命令⾏参数 pytest 直接运⾏符合条件的⽤例:
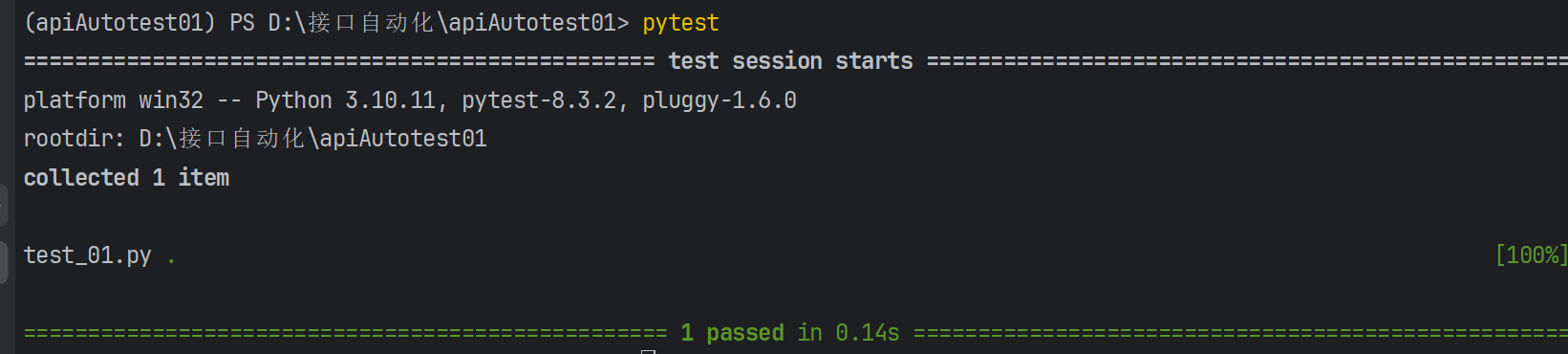
**注意:**Python类中不可以添加init⽅法
class Test():
def __init__(self):
print("-----init-------")
def test_a(self):
print("-----test_a----")pytest通过自动发现机制 收集测试用例:它会自动实例化测试类,并将类中以test开头的方法作为测试用例执行。若测试类定义__init__(类的构造方法),pytest实例化类时会调用该方法,这会:
- 覆盖测试类的默认初始化逻辑;
- 引入额外副作用,干扰测试用例的执行,影响结果准确性。
为实现初始化逻辑(如初始化数据、连接资源),可采用以下方案替代__init__:
| 方案 | 说明 |
|---|---|
setUp()/tearDown() |
兼容 unittest 的前置 / 后置方法:setUp()在每个测试方法执行前运行,tearDown()在每个测试方法执行后运行。 |
| 类属性 | 将初始化数据定义为测试类的类属性(如class TestDemo: data = [1,2,3]),测试方法可直接调用。 |
fixture函数 |
pytest的核心功能之一,可灵活定义前置 / 后置逻辑,支持跨用例、跨类复用 |
注意:
- 一个
class TestXXX(以 Test 开头的类)是「测试类」,不是「一个测试用例」; - 测试类里的
test_xxx()方法才是「测试用例」 (比如test_login()、test_get_data()); - 一个测试类里可以写多个测试方法(多个用例),不用为每个用例单独写一个测试类。
关于__init__的补充:
- pytest会自动实例化测试类 (不用你手动
TestBlog()),实例化时默认走「空的初始化逻辑」; - 若你在测试类里写了
__init__方法,pytest 实例化类时会执行这个__init__,不是 "覆盖逻辑",而是 "干扰逻辑" :比如__init__里要求传参数(def __init__(self, token):),pytest 自动实例化时没传参,直接报错;即使没参数,__init__里的代码(如改数据、连数据库)也会在每个用例执行前额外运行,破坏测试独立性。
关于 "全部执行":
pytest 执行时,会扫描所有符合规则的测试类 + 测试方法:
- 扫描范围:当前目录下所有
test_*.py/*_test.py文件; - 收集规则:文件里以
Test开头的类 → 类里以test开头的方法; - 执行逻辑:不管有多少个测试类、多少个测试方法,pytest 会自动收集并全部执行(也可指定执行某一个 / 某一类)。
| 概念 | 正确定义 |
|---|---|
| 测试文件 | test_xxx.py(pytest 扫描的单位) |
| 测试类 | class TestXXX:(存放多个用例) |
| 测试用例 | 测试类里的def test_xxx(self): |
__init__问题 |
不是 "覆盖逻辑",是 "干扰自动实例化" |
2.1.4pytest命令参数的内容:
| 命令 | 描述 | 备注 |
|---|---|---|
pytest |
在当前目录及其子目录中搜索并运行测试。 | - |
pytest -v |
增加输出的详细程度。 | - |
pytest -s |
显示测试中的print语句。 |
- |
pytest test_module.py |
运行指定的测试模块。 | - |
pytest test_dir/ |
运行指定目录下的所有测试。 | - |
pytest -k <keyword> |
只运行测试名包含指定关键字的测试。 | - |
pytest -m <marker> |
只运行标记为指定标记的测试。 | - |
pytest -q |
减少输出的详细程度。 | - |
pytest --html=report.html |
生成 HTML 格式的测试报告。 | 需要安装pytest-html插件 |
pytest --cov |
测量测试覆盖率 | 需要安装pytest-cov插件 |
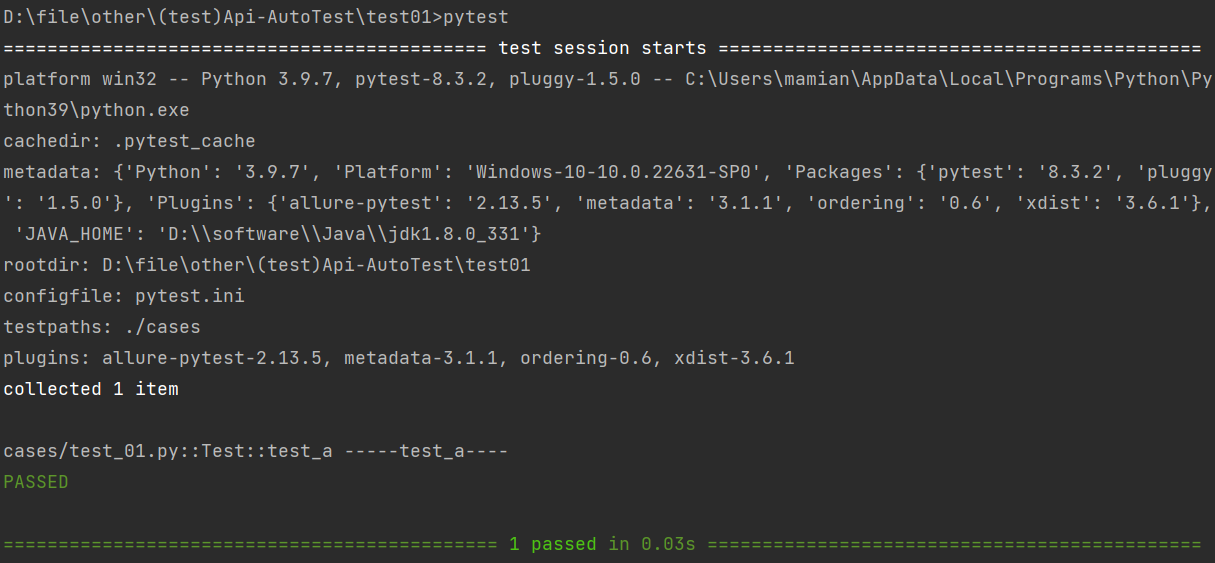
⽰例1:运⾏符合运⾏规则的⽤例
pytest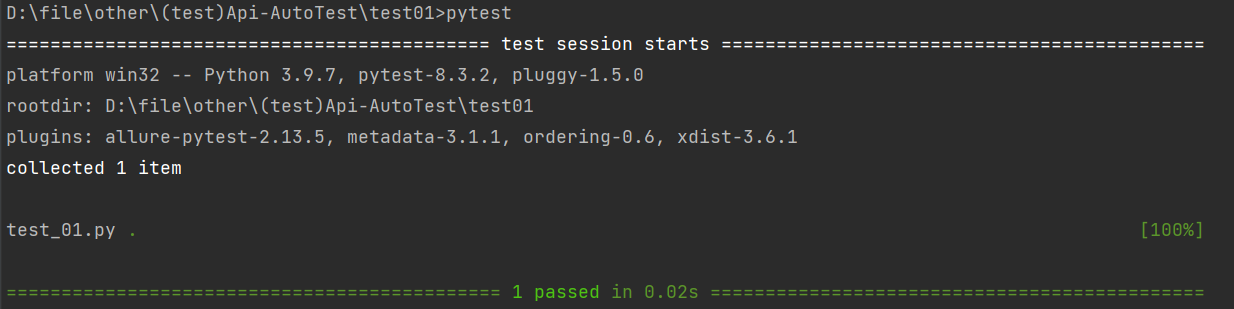
注意:这⾥不会输出测试⽤例中printf内容
**⽰例2:**详细打印,并输⼊print内容
pytest -s -v 或者 pytest -sv (可以连写)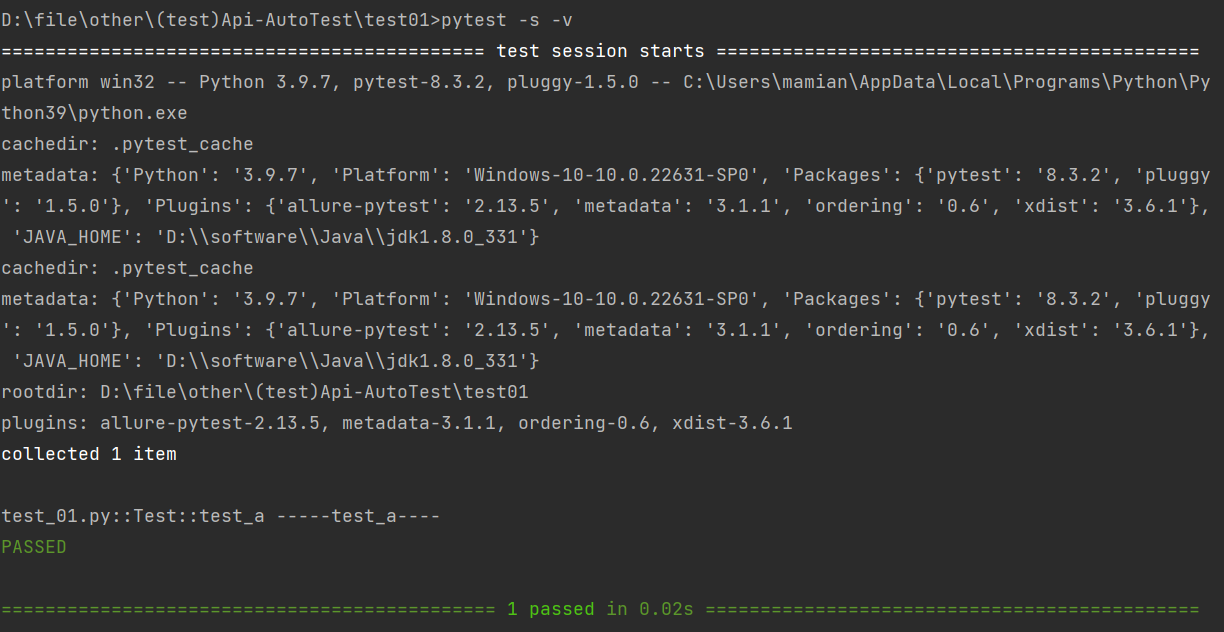
**⽰例3:**指定⽂件/测试⽤例
#指定⽂件:pytest 包名/⽂件名
pytest cases/test_01.py
#指定测试⽤例: pytest 包名/⽂件名::类名::⽅法名
pytest cases/test_01.py::Test::test_a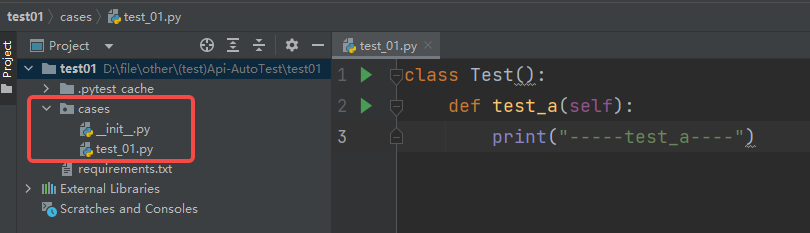
问题: 当我们既要详细输出 ,⼜要指定⽂件 时,命令会⼜臭⼜⻓,⽽且每次运⾏都需要⼿动输⼊命 令,如何解决? 将需要的相关配置参数统⼀放到 pytest 配置⽂件中。
2.1.5pytest配置⽂件
在当前项⽬下创建 pytest.ini ⽂件,该⽂件为 pytest 的配置⽂件,以下为常⻅的配置选项:
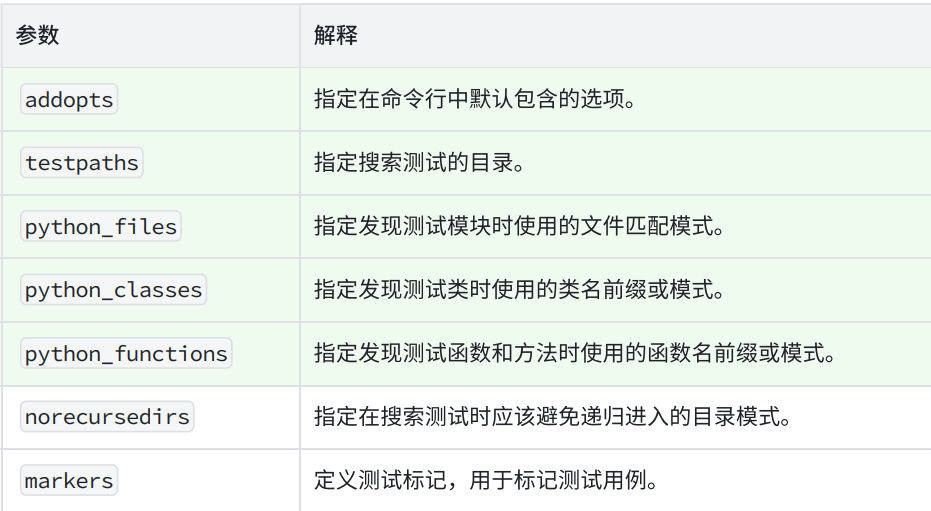
⽰例:详细输出 cases 包下⽂件名以 test_ 开头且⽅法名以 Test 开头的所有⽤例
[pytest]
addopts = -vs
testpaths = ./cases
python_files = test_*.py
python_classes = Test*配置好 pytest.ini ⽂件后,命令⾏执⾏ pytest 命令即可,⽆需再额外指定其他参数:
pytest.ini ⽂件通常位于项⽬的根⽬录下。通过在pytest.ini 中定义配置项,可以覆盖 pytest 的默认⾏为,以满⾜项⽬的需求。
2.1.6前后置
解决 "测试类中不能用__init__()做初始化" 的问题
pytest 提供的 3 种前后置方案
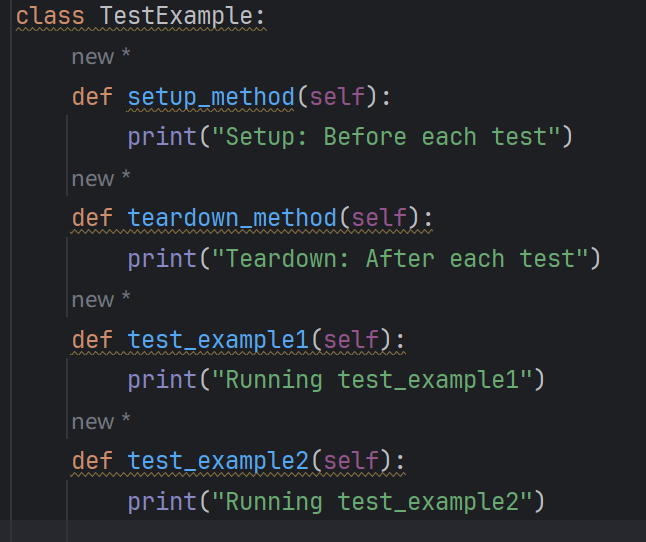
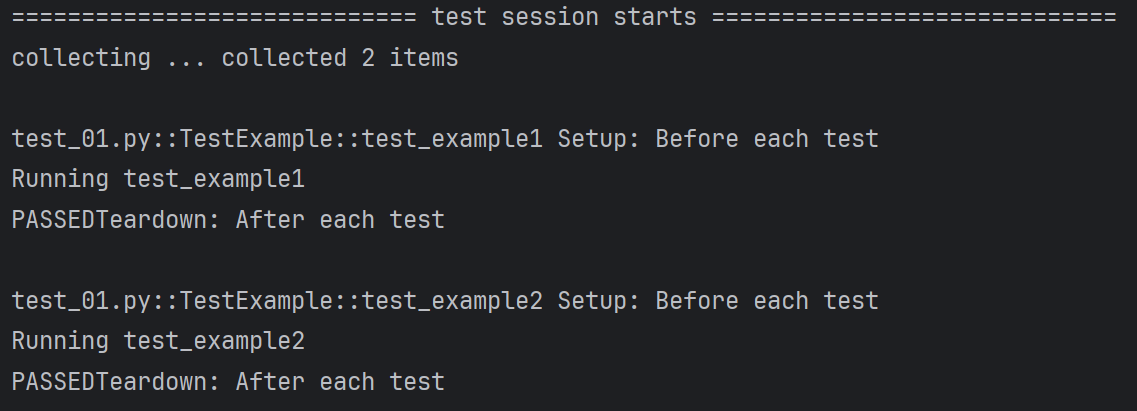
setup_method&teardown_method:每个测试方法的前后置
- 作用 :在类中每个测试方法执行前 / 后分别触发(即每个测试方法都会执行一次前置 + 后置)。
- 示例逻辑:
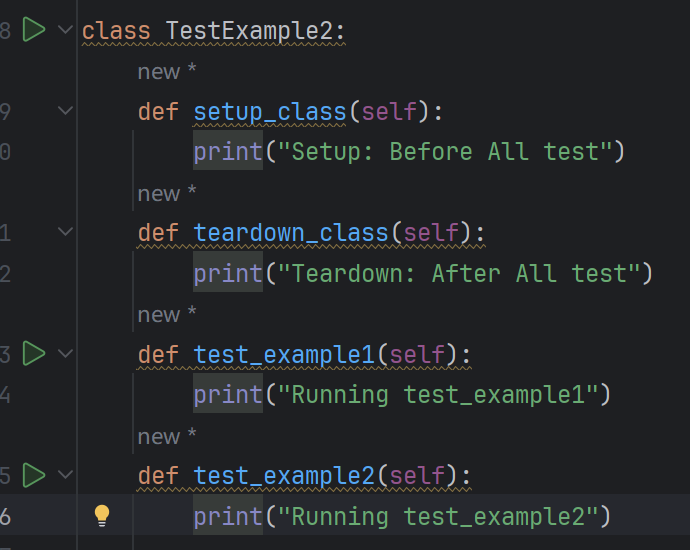
⽰例2:setup_class 和 teardown_class
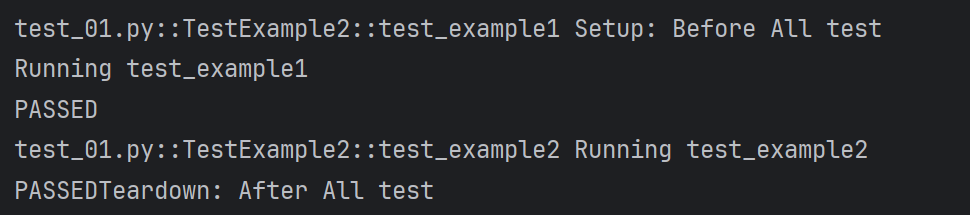
2.1.7断⾔(assert)
pytest 直接使用 Python 原生的assert语句,无需额外引入库。其核心逻辑是:
- 当
assert后的条件为 True:测试通过; - 当条件为 False:抛出
AssertionError,测试失败(可自定义错误信息)。
基本语法:
assert 条件, "错误信息(可选)"- 条件 :必须是⼀个布尔表达式。
- 错误信息 :当条件为假时显⽰的错误信息,可选。
免费学习API资源:http://jsonplaceholder.typicode.com/
⽰例1:基本数据类型的断⾔
用于验证数字、字符串等基础类型的匹配:
#断言数据类型
class TestNumAssert:
def test_num_assert(self):
a = 1
b = 2
assert a == b
#断言字符串
class TestStringAssert:
def test_str_assert(self):
str = "hello"
assert "hello" == str示例2:数据结构断言:
#数据结构断言
class TestListAssert:
def test_list_assert(self):
# 断言列表
expect_list = [1,'apple',3.14]
actual_list = [1,"apple",3.14]
# 断言数组
expect_tuple = (1,"apple",3.14)
actual_tuple = (1,"apple",3.14)
# 断言字典
expect_dict = {'name': 'jack','age': 18}
actual_dict = {'name': 'jack','age': 18}
#断言集合
expect_set = {1,2,3,'apple'}
actual_set = {1,2,3,'apple'}
assert expect_list == actual_list
assert expect_tuple == actual_tuple
assert expect_dict == actual_dict
assert expect_set == actual_set示例3:函数断⾔
问题讲解1.:
1.类方法带参数讲解:
| 场景 | self | 其他参数 | 示例 |
|---|---|---|---|
| 类的普通方法 | ✅必须加(第一个参数) | ✅可以加(self 之后加) | def test_add(self, a, b): |
| 类的静态方法(@staticmethod) | ❌不用加 | ✅可以加 | @staticmethod def add(a, b): |
| 独立普通函数(不在类里) | ❌不用加 | ✅可以加 | def add(a, b): |
2.类方法的参数规则
类里的方法不是 "只能用 self、不能传参数",而是:
self是类实例方法的第一个必选参数(代表类的实例本身);self后面可以加任意多个自定义参数(比如 a、b、num 等)。
示例:类方法既用 self,也传参数

这个例子中:
divide(self, a, b)既保留了 self(类方法必备),又传了 a、b 参数;- 调用时
self.divide(10, 2),self 不用手动传(Python 自动传),只需传 a=10、b=2。
3.什么时候把方法拿出类?
只有一种情况需要把方法拿出类:这个方法和类的实例无关,是通用工具函数(比如通用的除法、加法)。
比如你的divide(a, b)如果是通用工具,就可以做成独立函数;如果是和测试类绑定的(比如测试接口返回值的除法逻辑),就留在类里,加 self + 自定义参数。
4.一句话总结
- 类里的方法:先写 self(第一个参数),再写需要的自定义参数(a、b 等);
- 独立函数:不用写 self,直接写自定义参数;
- self 和 "传其他参数" 不冲突,只是类方法的 "固定格式要求"。
问题讲解2:
非测试代码(工具函数 / 辅助逻辑)是 "被调用方",不用遵守 pytest 的命名规则;但想要执行这些工具函数并验证结果,必须把调用逻辑封装到符合 pytest 规则的测试用例中。
举个 "工具函数→测试用例调用" 的示例
1. 非测试代码(工具函数:无需遵守 pytest 规则)
比如封装接口请求、数据计算、文件读写等通用逻辑:
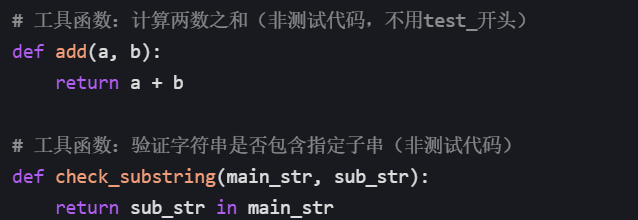
2. 测试用例(必须遵守 pytest 规则,调用工具函数)
把 "调用工具函数 + 断言验证结果" 的逻辑,封装到test_开头的函数 / 方法中:
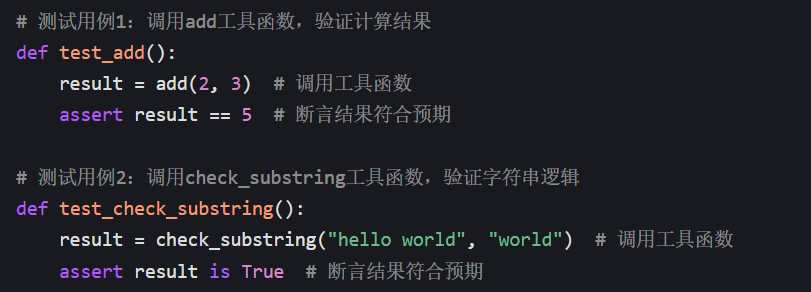
反面例子(无断言的测试用例):

运行后 pytest 会显示 "passed",但你无法确认add(2,3)的结果是不是 5,相当于白跑了。
简单说:工具函数是 "干活的",测试用例是 "验收的"------ 验收的流程必须按 pytest 的规则来,干活的逻辑随便写,只要能被验收流程调用就行。
3. 运行效果
执行pytest -s时:
- pytest 只识别
test_add、test_check_substring这 2 个测试用例; - 每个测试用例内部调用工具函数,完成逻辑验证;
- 工具函数本身不会被 pytest 当作 "测试用例",但能被测试用例复用。
细节
-
工具函数可以放在任意位置 :既可以和测试用例写在同一个文件,也可以单独放在
utils.py等文件中,测试用例通过import调用即可(比如from utils import add)。 -
测试用例的核心是 "验证" :不要只调用工具函数,一定要加
assert断言 ------ 没有断言的测试用例毫无意义(pytest 会认为 "通过",但无法验证逻辑是否正确)。
问题讲解3:
把测试用例放到测试类 里,核心是为了分组管理、复用前后置逻辑、统一维护,并非必须,但以下场景下用测试类会更高效:
核心原则:这些场景优先用测试类
| 场景 | 举例 | 为什么用测试类? |
|---|---|---|
| 测试逻辑属于 "同一模块" | 测试用户模块的登录 / 注册 / 退出接口 | 按模块分组,代码结构更清晰 |
| 需要复用类级前后置逻辑 | 所有用例执行前初始化一次数据库连接 | setup_class/teardown_class 只执行 1 次 |
| 需要共享测试数据 / 属性 | 多个用例共用同一个用户 ID、接口基础 URL | 类的属性可被所有方法共享 |
| 团队规范要求类式管理 | 公司规定测试用例必须按类组织 | 符合团队协作的统一规范 |
- 单 / 零散用例 → 直接写
test_函数; - 同模块 / 需复用前后置 / 需共享数据 → 套
Test开头的测试类。
2.1.8参数化
1.核心作用
参数化是为了解决 "同一逻辑要测试多组数据" 的重复问题 ------ 比如测试 "加法计算",需要验证1+2=3、3+4=7等多组数据,不用写多个test_add1、test_add2,而是用参数化让一个函数自动跑多组数据。
2.不同场景的参数化用法
场景 1:在测试函数上用参数化(最常用)
核心是给单个测试函数传多组参数,让函数自动执行多次。
@parametrize 装饰器定义了三个不同的 (test_input,expected) 元组,也可以在类或模块上使⽤ parametrize 标记,这将使⽤参数集调⽤多个函数

pytest 会自动把每组 (test_input, expected) 传给函数,逐行执行 assert eval(test_input) == expected,拆解:
第 1 组数据:("3+5", 8)
test_input = "3+5",expected = 8- 执行
eval("3+5")→ 计算得8 - 断言
8 == 8→ 结果为True→ 测试通过。
eval() 是 Python 内置函数,作用是执行字符串形式的表达式并返回结果
场景 2:在测试类上用参数化
类内多个方法 "复用同一组测试数据"

场景 3:在模块全局用参数化
模块全局变量赋值",给整个.py文件的所有测试用例传参数(类、函数都会生效)。
pytestmark = pytest.mark.parametrize("n,expected", [(1, 2), (3, 4)])
class TestClass:
def test_simple_case(self, n, expected):
assert n + 1 == expected
def test_weird_simple_case(self, n, expected):
assert (n * 1) + 1 == expected场景 4:自定义参数化数据源
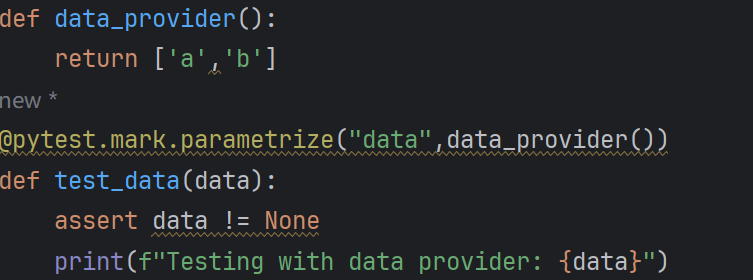
2.1.9fixture
1.基本使⽤
fixture 是用@pytest.fixture装饰的函数,作用是:
- 封装重复的操作(比如登录、数据库连接);
- 提供测试资源(比如返回一个初始化好的对象、测试数据);
- 测试用例只需把 fixture 名称作为参数,pytest 会自动先执行 fixture,再执行测试用例。
场景 1:基本使用(替代重复的函数调用)
未标记 fixture 的写法(传统方式)

- 问题:每个测试用例都要手动写
fixture_01(),重复代码多。
标记 fixture 的写法(pytest 推荐)
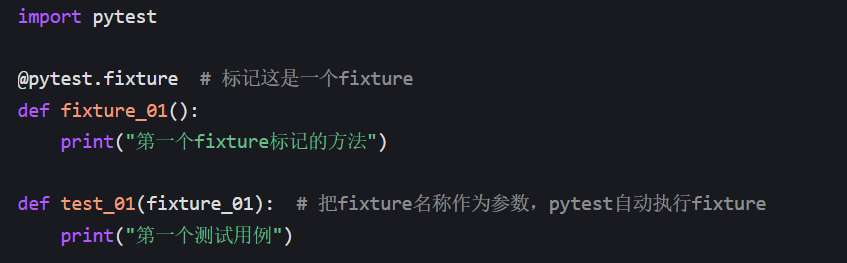
- 逻辑:运行
test_01时,pytest 会先执行fixture_01,再执行测试用例的代码; - 优势:不用手动调用,测试用例更简洁,fixture 可被多个用例复用。
场景 2:多测试用例复用同一 fixture(核心价值)
比如 "访问列表页 / 详情页前都需要登录",用 fixture 封装登录操作:
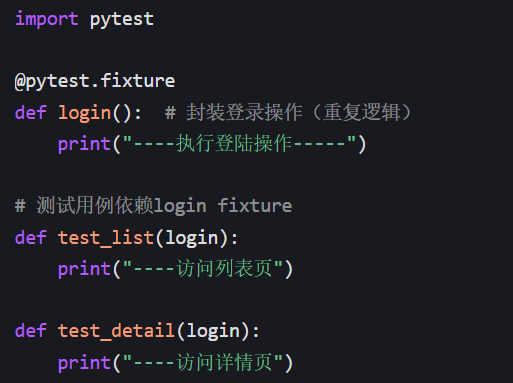
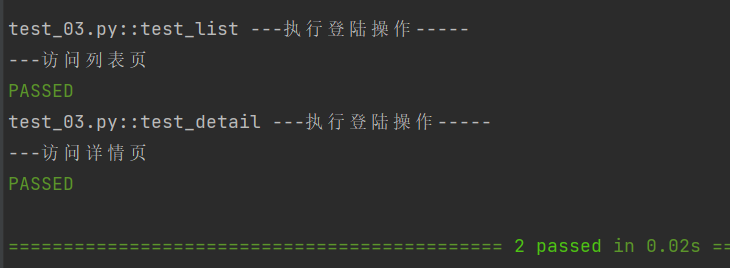
- 运行结果:
test_list和test_detail执行前,都会自动先执行login; - 价值:如果有 10 个测试用例需要登录,只需写 1 次
loginfixture,所有用例依赖它即可,不用写 10 次登录代码。
2.fixture嵌套
fixture 可以依赖其他 fixture,实现复杂资源的分层复用:
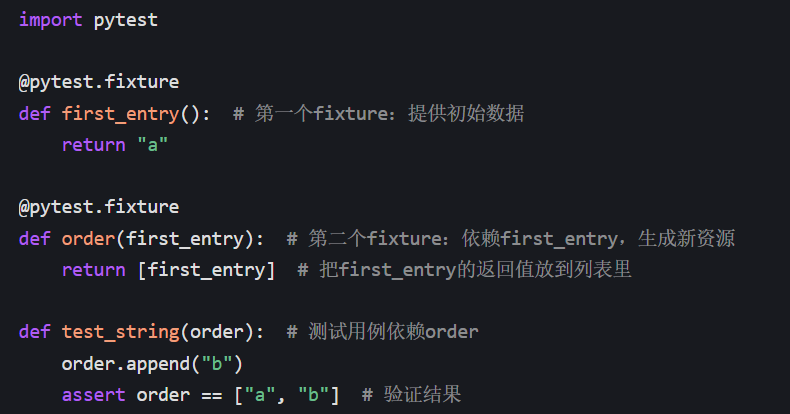
- 执行顺序:pytest 先执行
first_entry→ 再执行order(拿到first_entry的返回值) → 最后执行test_string; - 优势:把复杂的资源准备逻辑拆分成多个小 fixture,分层管理,更易维护。
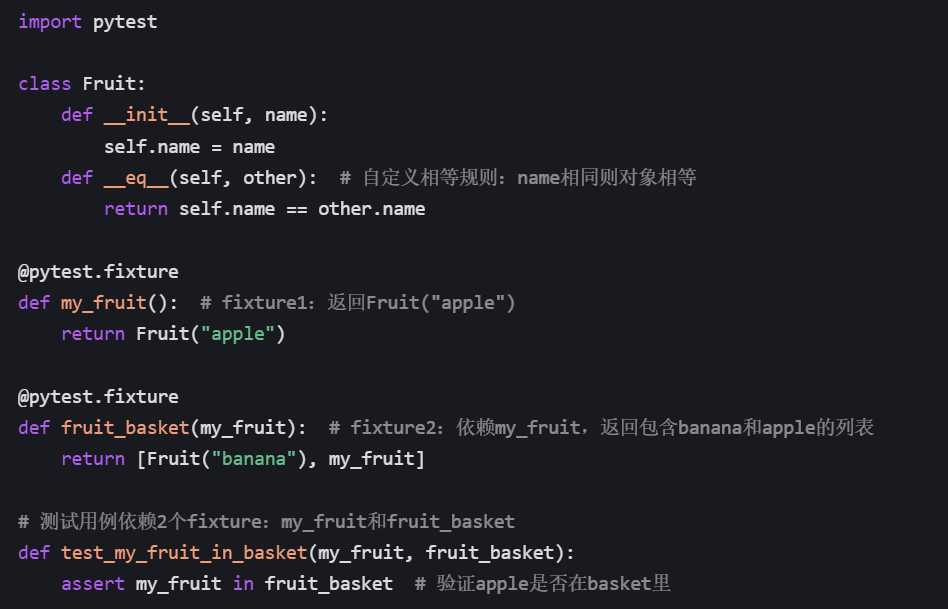
3.请求多个fixture
核心逻辑是:测试用例或 fixture 的参数可以写多个 fixture 名称,pytest 会自动按依赖顺序执行这些 fixture,再把返回值传给参数。
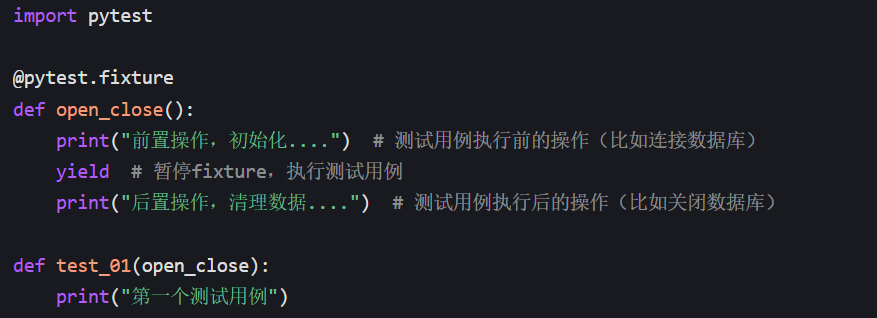
4.yieldfixture
yield是 fixture 中 "分隔前置操作和后置操作 " 的固定语法 ------ 只要你需要 fixture 实现「测试前做准备、测试后做清理」,就用yield替代return,
测试用例的执行时机,由 pytest 的依赖规则决定
| 写法 | 适用场景 | 执行逻辑 |
|---|---|---|
return |
仅需要 "前置准备 + 返回资源" | 执行完 fixture 代码 → 返回资源 → fixture 结束 |
yield |
需要 "前置 + 后置(清理)" | 执行 yield 前代码 → 暂停 → 执行测试用例 → 执行 yield 后代码 |
5.带参数的fixture
fixture 的核心参数:控制 fixture 的 "生命周期、自动执行、参数化"
pytest.fixture(scope='', params='', autouse='', ids='', name='')参数讲解:
1. scope:控制 fixture 的作用范围(生命周期)
决定 fixture 会被执行多少次,是 fixture 最常用的参数之一,常见取值:
scope取值 |
作用范围 | 执行时机(以 yield fixture 为例) |
|---|---|---|
function |
每个测试函数(默认) | 每个测试函数执行前→执行 fixture 前置;测试后→执行 fixture 后置 |
class |
每个测试类 | 测试类中第一个用例执行前→前置;最后一个用例执行后→后置 |
module |
每个测试模块(.py 文件) | 模块中第一个用例执行前→前置;模块中最后一个用例执行后→后置 |
session |
整个测试会话(所有用例) | 所有用例执行前→前置;所有用例执行后→后置 |
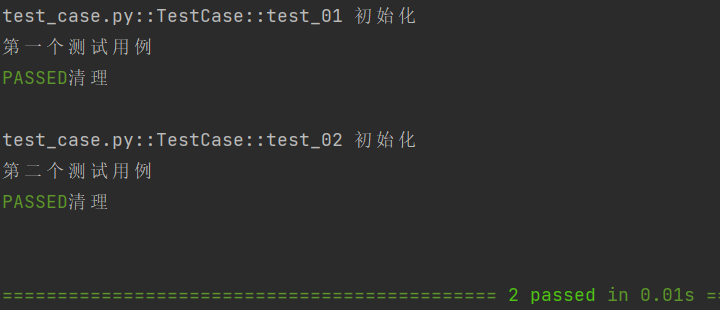
⽰例1: scope 的使⽤
scope="function"

scope="class"

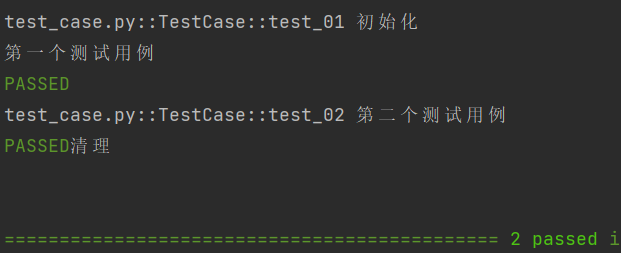
⽰例2: scope="moudle" 、 scope="session" 实现全局的前后置应⽤
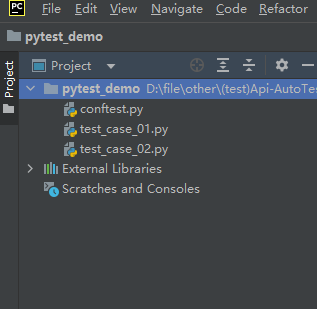

test_case_01.py

test_case_02.py

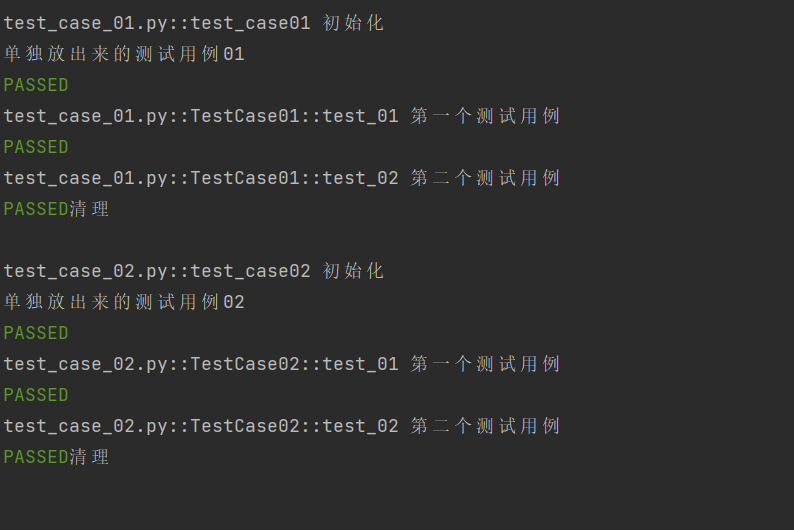
把 "初始化 + 清理" 的重复逻辑提取到 conftest.py 中,让所有测试模块(.py)自动复用;且每个 .py 文件仅执行一次初始化(模块第一个用例前)和一次清理(模块最后一个用例后),无需在测试用例中手动调用,大幅减少重复代码且提升执行效率。
示例3:当 scope="session" 时:
test_case_01.py

test_case_02.py

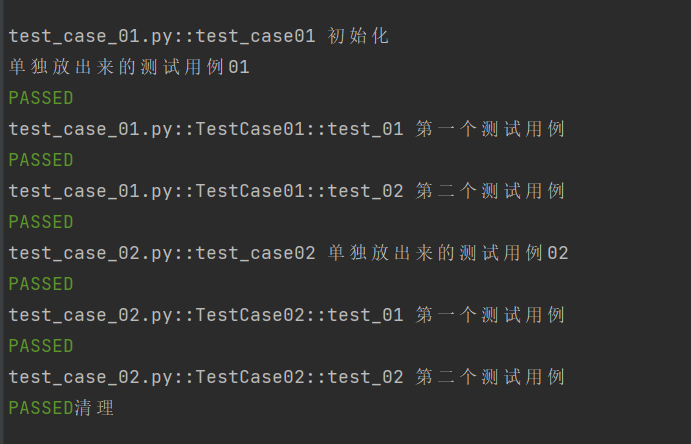
2.autouse:控制 fixture 是否自动执行
- 默认
autouse=False:需要在测试用例参数中显式写 fixture 名,才会执行; - 设置
autouse=True:不需要写参数 ,fixture 会自动在对应scope范围内执行。
autouse=True:控制 "是否自动复用"
- 若没写
autouse=True,需要在测试用例参数中显式写fixture_01才会执行(比如def test_a(fixture_01):); - 写了
autouse=True:不用写参数,自动执行 → 彻底不用在测试用例中写任何额外代码,真正的 "无感复用"。
3.params:实现 fixture 的参数化
给 fixture 传多组参数,fixture 会按参数数量执行多次,测试用例也会跟着执行多次(每组参数对应一次用例)。
用法步骤:
- 在
@pytest.fixture中传params=[参数1, 参数2, ...]; - fixture 函数需接收
request参数,通过request.param获取当前组的参数; - 测试用例依赖这个 fixture,会自动按参数组执行多次。

4.其他参数(ids/name)
ids:配合params使用,给每组参数起 "别名",方便在测试报告中区分不同参数组;name:给 fixture 起别名,测试用例依赖时需用别名(而非原函数名)。
@pytest.mark.parametrize vs fixtureparams:怎么选?
| 场景 | 选@pytest.mark.parametrize |
选 fixtureparams |
|---|---|---|
| 需求 | 简单的参数传递(比如多组输入输出) | 需要动态加载数据 / 管理资源(比如从文件读参数 + 初始化数据库) |
| 优势 | 写法简单直接,专注参数本身 | 可结合 fixture 的前置 / 后置逻辑,适合复杂资源 + 参数的场景 |