视频讲解1:Bilibili视频讲解
论文下载:https://arxiv.org/abs/2504.16570
代码下载:https://lorebianchi98.github.io/CountingDINO/
https://github.com/KeepTryingTo
基于Zero-Shot的计数算法详解(T2ICount: Enhancing Cross-modal Understanding for Zero-Shot Counting)
统一的人群计数训练框架(PyTorch)------基于主流的密度图模型训练框架
算法VLCount详解(VLCounter: Text-aware Visual Representation for Zero-Shot Object Counting)
人群计数中常用数据集的总结以及使用方式(Python/PyTorch)
基于Zero-Shot的目标计数算法详解(Open-world Text-specified Object Counting)
基于zero-shot目标计数方法详解(Zero-Shot Object Counting)
基于Transformer的目标统计方法(CounTR: Transformer-based Generalised Visual Counting)
基于zero-shot目标统计算法详解(Zero-shot Object Counting with Good Exemplars)
开发词汇的目标计数COUNTGD:Multi-Modal Open-World Counting算法详解
Class-Agnostic Counting类别无关的统计算法讲解
LOCA类别无关的目标统计算法详解(A Low-Shot Object Counting Network With Iterative Prototype Adaptation)
论文提出了一种基于自监督学习的零样本目标计数方法,通过DINO特征提取器和创新相似度图机制实现无需人工标注的开放世界计数。该方法解决了现有类别无关计数(CAC)方法对标注数据的依赖问题,采用ROI-Align提取示例特征,通过卷积生成相似度图并归一化为密度图。通过图像分块处理增强空间分辨率,实验验证了方法的有效性。相关代码已开源,论文可访问arXiv获取。
目录

现有方法存在的局限性
1. 对标注数据的严重依赖
当前最先进的类别无关计数(CAC)方法存在两个根本性限制: 监督式骨干网络:大多数方法使用在大型标注数据集(如ImageNet)上预训练的骨干网络进行特征提取;有监督训练:需要基于包含数千个点标注和边界框的标注数据集进行监督训练
2. 标注成本高昂且可扩展性差
点标注收集困难:在对象中心放置点标注是创建大规模数据集的重大障碍
数据集稀缺:导致可用的CAC数据集数量有限,且现有数据集存在明显局限性
3. 半监督方法的妥协
先前许多方法试图实现无监督计数,但最终仍屈服于: 使用不同数量的真实密度图进行监督微调;依赖需要昂贵标注训练的上游视觉骨干网络或分割模型
提出的方法
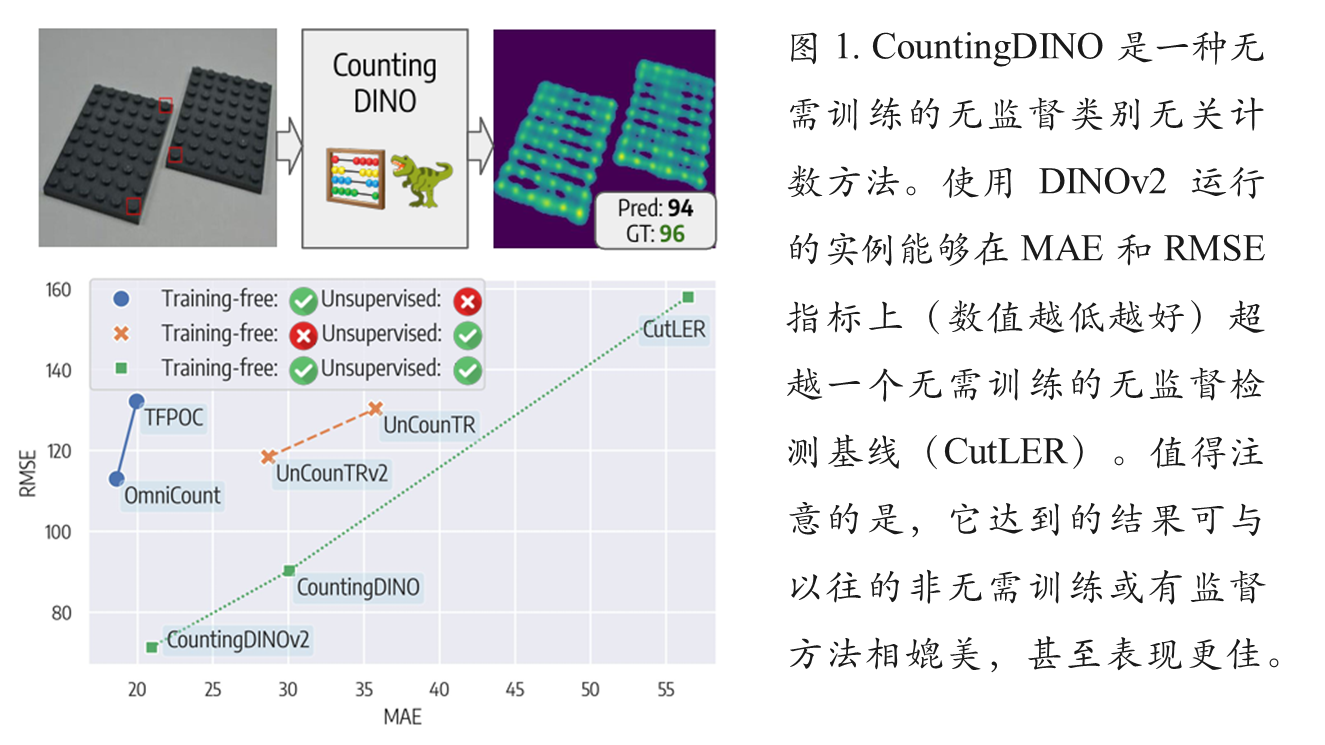
1. 自监督特征提取
使用DINO系列自监督视觉骨干网络提取对象感知特征;完全避免使用任何人工标注数据
2. 相似度图生成机制
推理阶段处理流程: 通过ROI-Align从用户提供的边界框中提取示例特征 ;将示例特征作为深度卷积核在图像特征图上进行卷积 ;生成突出显示与示例匹配区域的相似度图 ;跨示例平均相似度图产生全局响应。
3. 密度图归一化技术
将相似度图通过简单有效的归一化方案转换为密度图 ;确保每个对象实例的相似度响应积分为1.0 ;通过对密度图进行积分获得最终对象计数 。
4. 空间分辨率增强
将图像划分为不重叠的象限独立处理 ;解决DINO空间分辨率对小对象的限制 ;通过拼接象限特征图获得更高分辨率特征表示。
具体方法
我们这里先来看一下有关的类别无关的统计算法,部分算法是我们已经讲过的,并且链接已经在文章的最前面给出来了。
类无关计数(CAC)最近将物体计数范式转向开放世界环境,使模型能够处理训练期间未见的任意类别。在这种设置下,用户不再受限于预定义类别,而是在推理时可以通过提供视觉示例来指定新的物体类别,通常以三个边界框的形式将同一输入图像中的视觉原型包围。开创性的 FamNet将多尺度特征提取与通过内积操作进行示例图像相关结合起来,用于密度图预测。RCAC遵循类似的架构,但引入了一个特征增强模块,通过合成具有不同颜色、形状和尺度的示例来提高多样性。BMNet强调了基于内积相关的局限性,并提出了一种可学习的二次相似性损失,借鉴度量学习,以实现更好的匹配。CounTR 提出了一种在任意语义类别图像中计数元素的方法,通过采用两阶段训练流程:基于 MAE 的自监督阶段,用于学习强大的视觉特征,以及全监督的最终阶段。LOCA引入了一个物体原型提取模块,通过交叉注意力迭代优化示例特征,而 PseCo 则依赖流行的 SAM 用于实例分割。CACViT利用单个预训练的视觉变换器,其注意力机制同时用于特征提取和匹配。DAVE提出了一种两阶段检测与验证框架:先通过密度图识别候选框,然后利用基于示例的聚类进行验证。与这些监督方法相比,UnCounTR通过使用从无监督数据生成的自我拼贴和 DINO 特征进行训练,而无需人工标注。相反,TFPOC和 OmniCount提出了使用 SAM 的无监督训练流水线,尽管 SAM 是经过标签训练的,因此方法并非完全无标签。
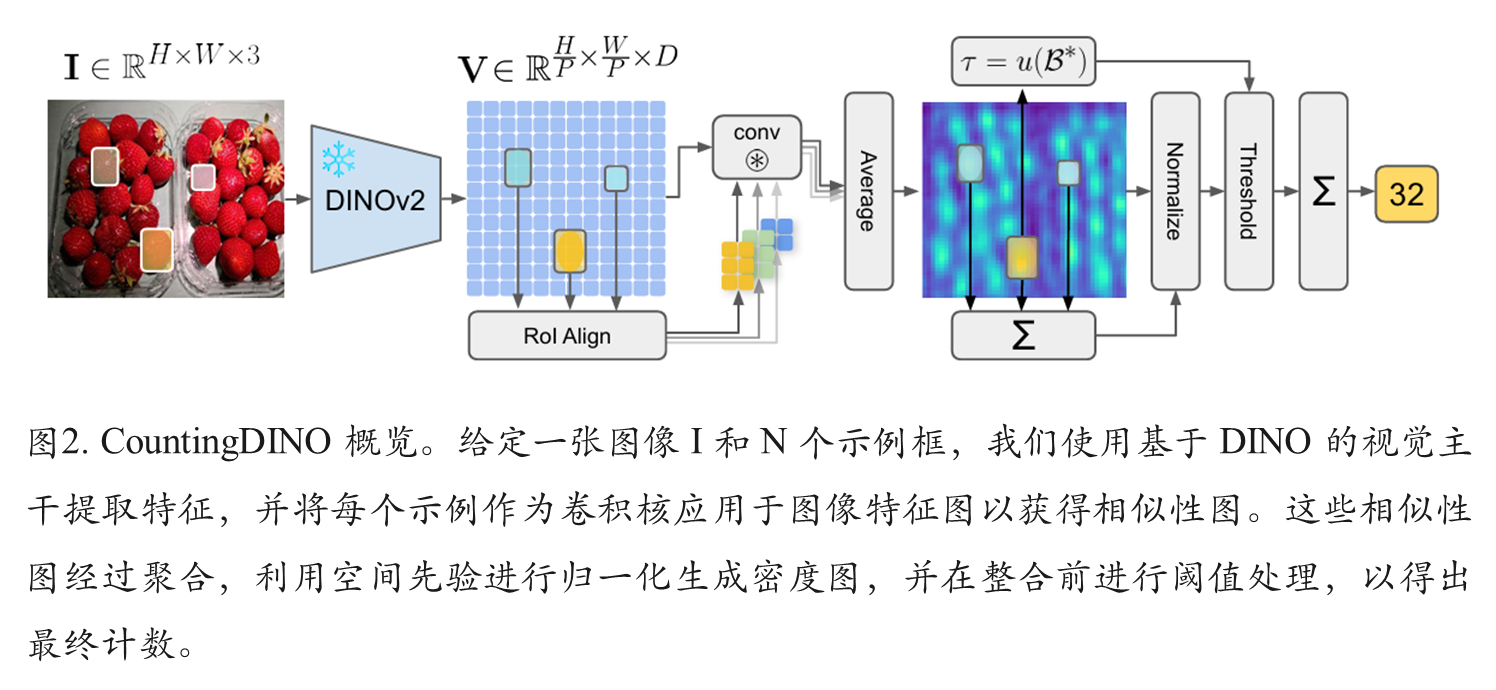
基于DINO的特征提取器

椭圆加权掩码生成:将坐标归一化到 单位圆空间
椭圆方程:( (x−w/2) / (w/2))^2 +( (y−h/2) / (h/2))^2 ≤1
即:中心在 (w/2, h/2),x 半轴长 w/2,y 半轴长 h/2
归一化后:
norm_x ∈ -1, 1
norm_y ∈ -1, 1
若 norm_x² + norm_y² ≤ 1,则点在椭圆内
python
#计算一个 h×w 图像中每个像素被内接椭圆(实际上是内接圆,但按宽高比例拉伸为椭圆)覆盖的比例(coverage),通过在每个像素内进行亚像素采样实现
def ellipse_coverage(h, w, samples_per_pixel=10):
# Create a grid of pixel centers
y = torch.linspace(0.5, h - 0.5, h).view(h, 1).expand(h, w)
x = torch.linspace(0.5, w - 0.5, w).view(1, w).expand(h, w)
# Generate subpixel offsets for sampling
sp = samples_per_pixel
sub = torch.linspace(-0.5 + 1/(2*sp), 0.5 - 1/(2*sp), sp)
dy, dx = torch.meshgrid(sub, sub, indexing='ij')
offsets = torch.stack([dy.reshape(-1), dx.reshape(-1)], dim=1) # (sp*sp, 2)
# Expand pixel grid to sample subpixel points
total_samples = sp * sp
x_samples = x.unsqueeze(-1) + offsets[:, 1].view(1, 1, -1)
y_samples = y.unsqueeze(-1) + offsets[:, 0].view(1, 1, -1)
# Normalize coordinates to ellipse space
norm_x = (x_samples - w / 2) / (w / 2)
norm_y = (y_samples - h / 2) / (h / 2)
inside = (norm_x ** 2 + norm_y ** 2) <= 1.0
coverage = inside.float().mean(dim=2) # average over samples
return coverage比如这里的w = 10, h = 10,生成的椭圆加权掩码如下:

相似密度图生成

python
# 从一个特征图(feats)中根据给定的边界框(bbox)提取一个固定空间尺寸的特征区域
pooled = ops.roi_align(
feats, [bbox_tensor.unsqueeze(0).float().to(device)],
output_size=output_size, spatial_scale=1.0
)
# 默认为false
if config.ellipse_kernel_cleaning:
ellipse = ellipse_coverage(pooled.shape[-2], pooled.shape[-1]).unsqueeze(0).unsqueeze(0).to(device)
pooled *= ellipse
pooled_features_list.append(pooled)
if config.exemplar_avg:
continue
conv_weights = pooled.view(feats.shape[1], 1, *output_size)
conv_layer = nn.Conv2d(
in_channels=feats.shape[1],
out_channels=1 if config.cosine_similarity else feats.shape[1],
kernel_size=output_size,
padding=0,
groups=1 if config.cosine_similarity else feats.shape[1],
bias=False
)
# 使用提取的特征来初始化当前卷积的权重
conv_layer.weight = nn.Parameter(pooled if config.cosine_similarity else conv_weights)
with torch.no_grad():
# 对当前的特征进行卷积(也就是使用样例初始化的权重卷积来计算)
output = conv_layer(feats[0])密度图归一化

python
if config.use_roi_norm and config.roi_norm_after_mean:
# 将所有的特征图缩放至统一大小以及计算每一个特征图的高宽比
output, resize_ratios = resize_conv_maps(conv_maps)
# 在同一个维度计算所有密度图的均值
output = output.mean(dim=0)
# 默认为true
if config.use_minmax_norm:
output = rescale_tensor(output)
pooled_vals = []
for bbox, ratio in zip(bboxes, resize_ratios):
scaled_bbox = torch.tensor([
bbox[0] * ratio[1], bbox[1] * ratio[0],
bbox[2] * ratio[1], bbox[3] * ratio[0]
]).int()
# scaled_bbox = torch.tensor(bboxes_tointeger(scaled_bbox.unsqueeze(0), config.remove_bbox_intersection)[0])
output_size = (
int(scaled_bbox[3] - scaled_bbox[1]),
int(scaled_bbox[2] - scaled_bbox[0])
)
pooled = ops.roi_align(
output.unsqueeze(0).unsqueeze(0),
[scaled_bbox.unsqueeze(0).float().to(device)],
output_size=output_size, spatial_scale=1.0
)
pooled_vals.append(pooled)
# 默认为true
if config.ellipse_normalization:
norm_coeff = sum(
[(p[0, 0] * ellipse_coverage(p.shape[-2], p.shape[-1]).to(device)).sum() for p in pooled_vals]) / (
len(pooled_vals) * config.scaling_coeff)
else:
norm_coeff = sum([p.sum() for p in pooled_vals]) / (len(pooled_vals) * config.scaling_coeff)
if config.fixed_norm_coeff is not None:
norm_coeff = config.fixed_norm_coeff
output = output / norm_coeff阈值密度图过滤

python
if config.filter_background is True:
thresh = max([f.shape[-2] * f.shape[-1] for f in pooled_feats])
thresh = (1 / thresh) * 1.0
output[output < thresh] = 0增加空间分辨率

实验结果
综合比较
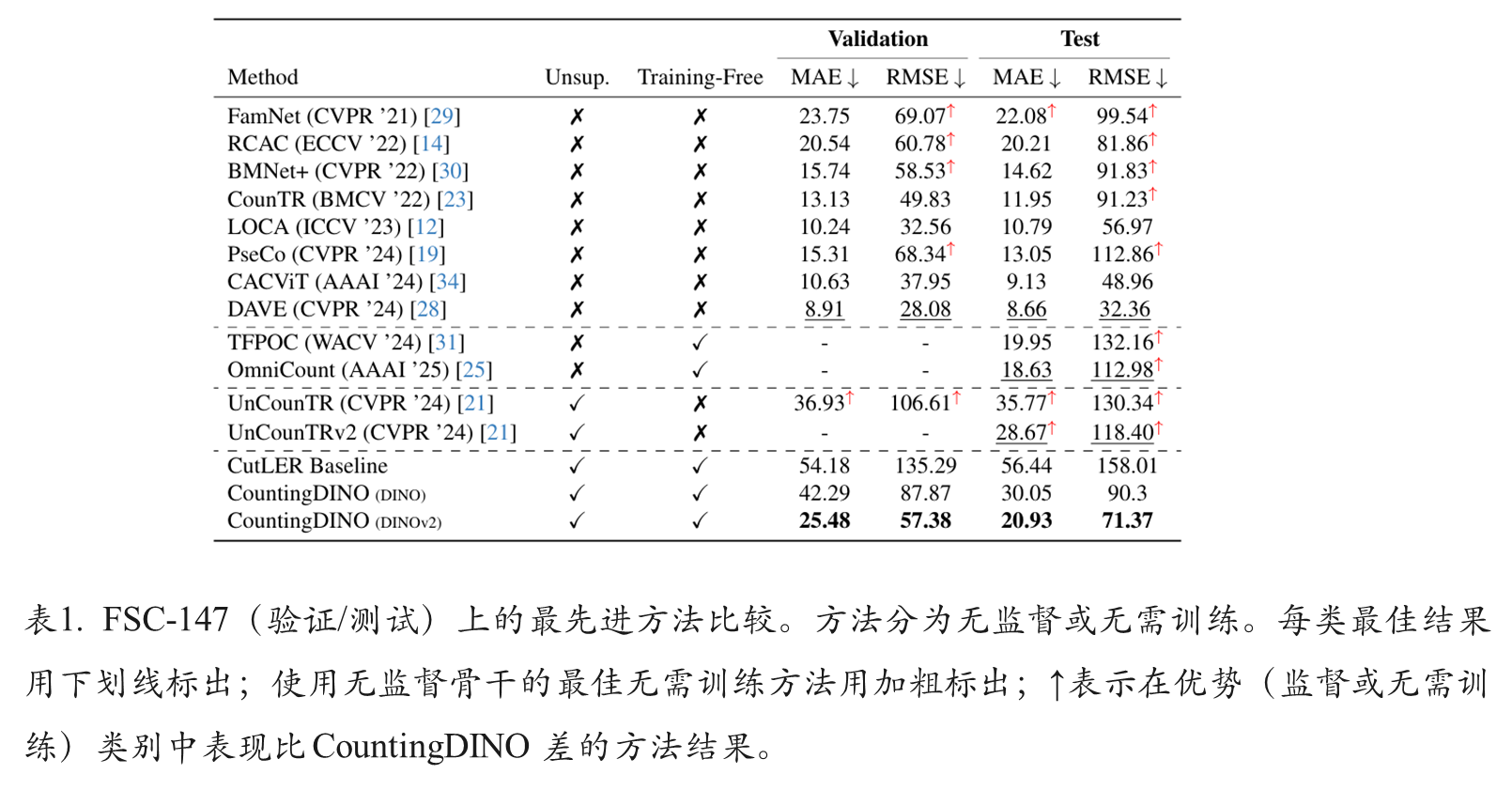
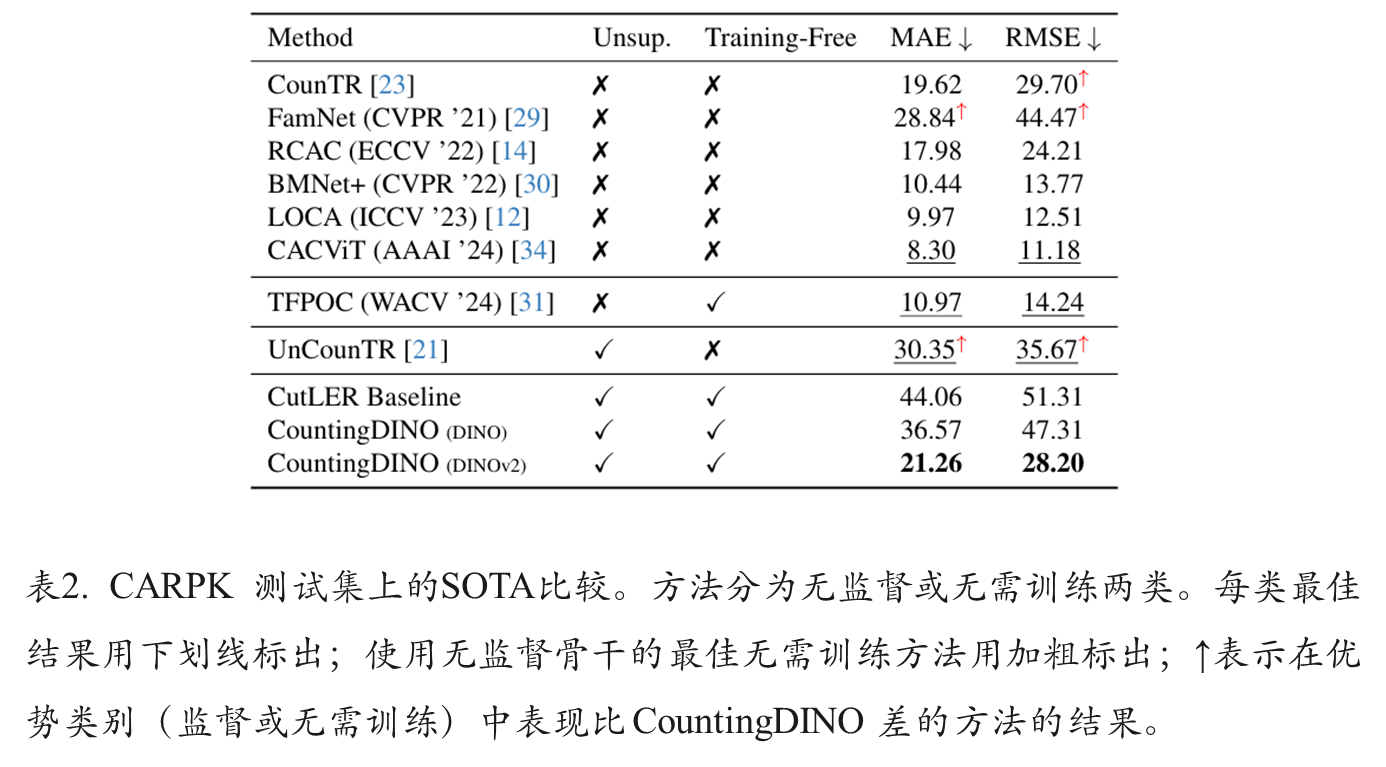
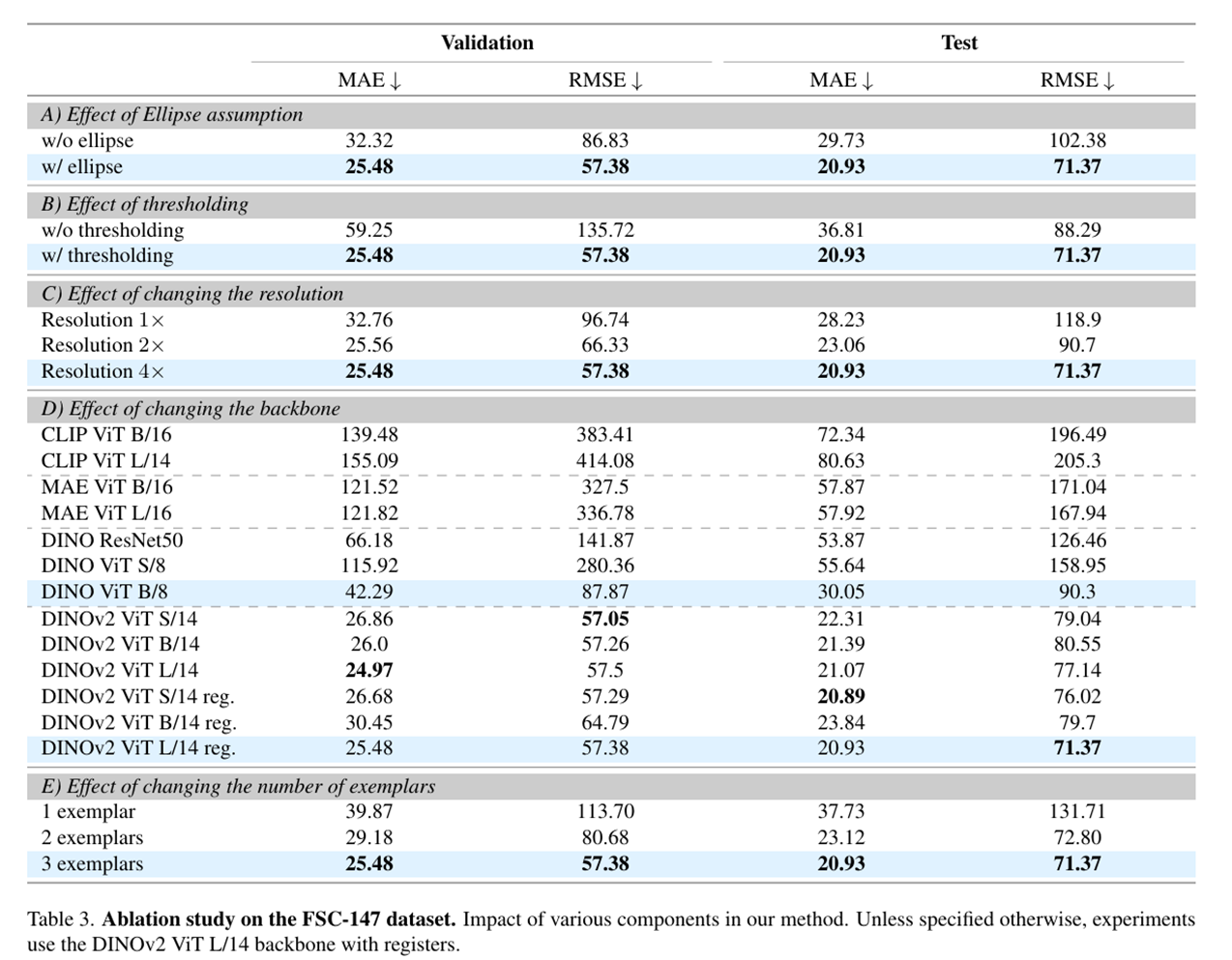
消融实验
可视化结果
