阶跃星辰重磅发布:32B参数模型如何实现"深度研究"自动化?Step-DeepResearch技术全解析
当你需要写一份行业调研报告,可能要花几天时间搜索资料、整理信息、交叉验证。现在,一个32B参数的AI模型就能帮你完成这一切,而且成本不到5毛钱!
引言:AI研究助手的新纪元
想象一下这样的场景:你需要撰写一份关于"新能源汽车电池技术发展趋势"的深度报告。传统方式下,你可能需要:
- 花数小时在Google、知网上搜索相关论文和新闻
- 阅读几十篇文章,筛选有价值的信息
- 交叉验证不同来源的数据
- 整理成逻辑清晰的报告
这个过程可能需要几天甚至一周。但现在,阶跃星辰(StepFun)团队发布的Step-DeepResearch系统,可以在几分钟内自动完成这一切!
今天我们要解读的这篇技术报告《Step-DeepResearch Technical Report》,详细介绍了这个系统背后的技术原理。让我们一起来看看,AI是如何学会"做研究"的。
一、什么是"深度研究"(Deep Research)?
1.1 从"搜索"到"研究"的跨越
我们日常使用的搜索引擎,本质上是"问答式"的------你问一个问题,它给你一个答案。但深度研究完全不同,它需要:
- 开放性探索:没有标准答案,需要从多个角度分析
- 信息整合:综合几十甚至上百个信息源
- 逻辑推理:不是简单罗列,而是建立因果关系
- 报告生成:输出结构化、可读性强的专业报告
举个例子:
- 搜索问题:"特斯拉2024年销量是多少?" → 答案:xxx万辆
- 研究问题:"分析特斯拉在中国市场的竞争策略及未来趋势" → 需要一份完整的分析报告
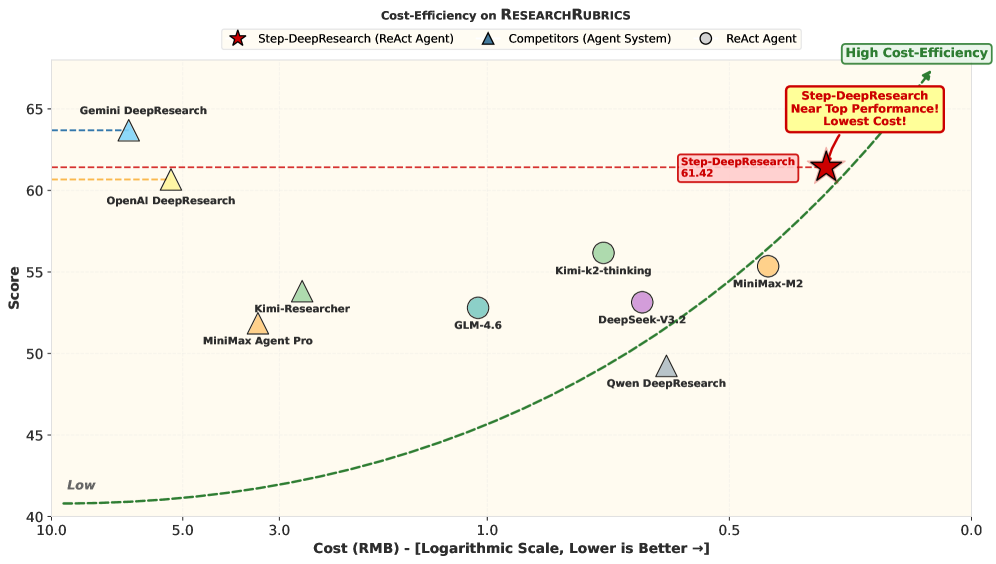 图1:Step-DeepResearch的性能与成本对比
图1:Step-DeepResearch的性能与成本对比
图1:Step-DeepResearch在成本效益和专家评估中的表现。左图显示成本与性能的关系,右图显示与OpenAI DeepResearch的人工对比评估结果。可以看到,Step-DeepResearch以极低的成本(<0.50元/次)实现了与顶级商业系统相当的性能。
1.2 现有方案的局限性
目前市面上的深度研究系统主要有两类:
第一类:基于工作流的系统
- 代表:OpenAI DeepResearch、Gemini DeepResearch、Claude Research
- 特点:依赖复杂的外部工作流编排,系统复杂度高
- 问题:像"搭积木"一样拼凑各种模块,灵活性差
第二类:端到端优化的系统
- 代表:DeepResearcher、Kimi-Researcher
- 特点:直接训练模型完成整个研究流程
- 问题:缺乏对"原子能力"的系统性构建
Step-DeepResearch的创新之处在于:将深度研究分解为可训练的"原子能力",然后通过渐进式训练让模型掌握这些能力。
二、核心创新:原子能力数据合成策略
2.1 什么是"原子能力"?
论文提出了一个非常精妙的思路:**与其让模型学习"预测下一个词",不如让它学习"决定下一个动作"**。
这就像教一个人做研究:
- 传统方式:给他看100篇研究报告,让他模仿
- 原子能力方式:分别教他"如何制定计划"、"如何搜索信息"、"如何验证事实"、"如何撰写报告"
论文将深度研究分解为四大原子能力:
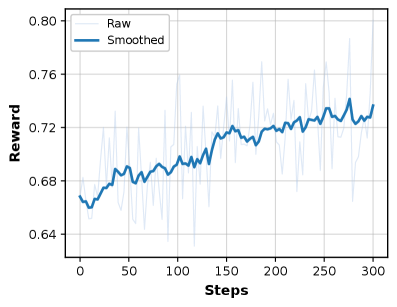 图4:Step-DeepResearch系统架构
图4:Step-DeepResearch系统架构
图4:Step-DeepResearch的系统架构图。展示了基于ReAct循环的规划-执行-反思流程,以及丰富的工具集(网页浏览、代码执行、知识管理等)。
2.2 能力一:规划与任务分解
核心问题:如何让AI学会"制定研究计划"?
解决方案:逆向工程合成
这是一个非常聪明的方法:
- 收集大量高质量的研究报告(技术报告、金融分析报告等)
- 让AI"逆向推导":这份报告是为了回答什么问题?作者做了哪些步骤?
- 生成"任务→计划→执行轨迹"的训练数据
举个例子:
原始报告:《2024年中国新能源汽车市场分析》
逆向生成:
- 任务:分析中国新能源汽车市场现状和趋势
- 计划:
1. 收集2024年销量数据
2. 分析主要厂商市场份额
3. 研究政策环境变化
4. 预测未来发展趋势
- 执行轨迹:搜索→阅读→整理→验证→撰写轨迹一致性过滤:为了保证数据质量,论文还设计了过滤机制,确保生成的执行轨迹与预设计划高度一致。
2.3 能力二:深度信息检索
核心问题:如何让AI学会"多跳搜索"?
什么是多跳搜索?举个例子:
- 问题:"谁是马斯克妻子的前男友?"
- 第一跳:搜索"马斯克妻子是谁" → Grimes
- 第二跳:搜索"Grimes前男友是谁" → 答案
解决方案:图合成与多文档合成
论文使用了两种方法生成训练数据:
方法一:知识图谱采样
- 在Wikidata5m等大型知识图谱上采样子图
- 根据子图结构生成多跳问题
- 例如:A→B→C的关系链 → "A的B的C是什么?"
方法二:超链接拓扑游走
- 从维基百科等网站出发
- 沿着超链接"游走",收集关联页面
- 生成需要跨多个页面才能回答的问题
2.4 能力三:反思与验证
核心问题:如何让AI学会"自我纠错"?
这是深度研究中最关键的能力之一。互联网上充斥着错误信息,AI必须学会:
- 识别信息冲突
- 交叉验证事实
- 在发现错误时调整策略
解决方案:错误反思循环
论文设计了一个多轮反思机制:
- 专家模型生成初始研究轨迹
- 验证模型检查轨迹中的错误
- 反思模型分析错误原因并提出修正
- 重复步骤2-3,直到结果满意
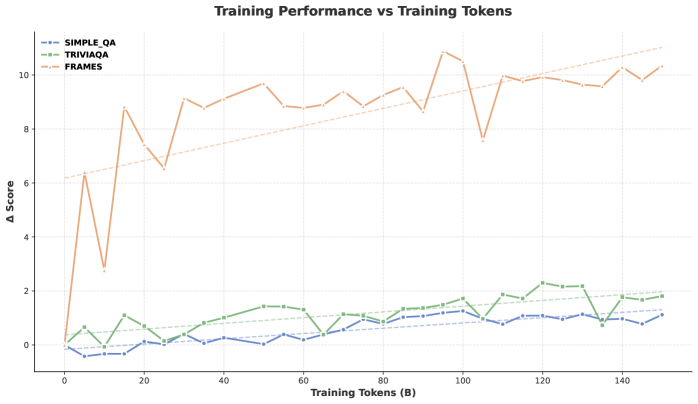 图3:强化学习训练过程中的奖励曲线
图3:强化学习训练过程中的奖励曲线
图3:RL训练过程中的奖励曲线。可以看到,随着训练的进行,模型的奖励值持续上升,说明模型在不断学习如何更好地完成深度研究任务。
深度验证工作流:论文还设计了一个多代理协作的验证系统:
- Extract Agent:提取报告中的关键声明
- Plan Agent:制定验证计划
- Verify Agent:执行验证
- Replan Agent:根据验证结果调整
- Report Agent:生成最终验证报告
2.5 能力四:报告生成
核心问题:如何让AI写出高质量的研究报告?
这不仅仅是"把信息堆在一起",而是需要:
- 逻辑清晰的结构
- 恰当的领域风格
- 准确的引用标注
- 适当的内容深度
解决方案:两阶段训练
第一阶段(中训练):学习领域风格和内容深度
- 让模型阅读大量专业报告
- 学习不同领域的写作风格(金融报告vs技术报告)
第二阶段(SFT):学习格式规范
- 严格遵循预设的报告结构
- 正确引用信息来源
- 保持内容与计划的一致性
三、渐进式训练流程
论文提出了一个三阶段训练流程,这是让32B参数模型具备深度研究能力的关键。
3.1 第一阶段:中训练(Mid-training)
目标:为模型注入基础的原子能力
这个阶段分为两个子阶段:
32K上下文阶段:
- 注入规划、信息检索等基础能力
- 数据包括:百科知识、学术论文、合成的推理数据
128K上下文阶段:
- 引入工具调用能力
- 学习长时程推理(处理超长文档)
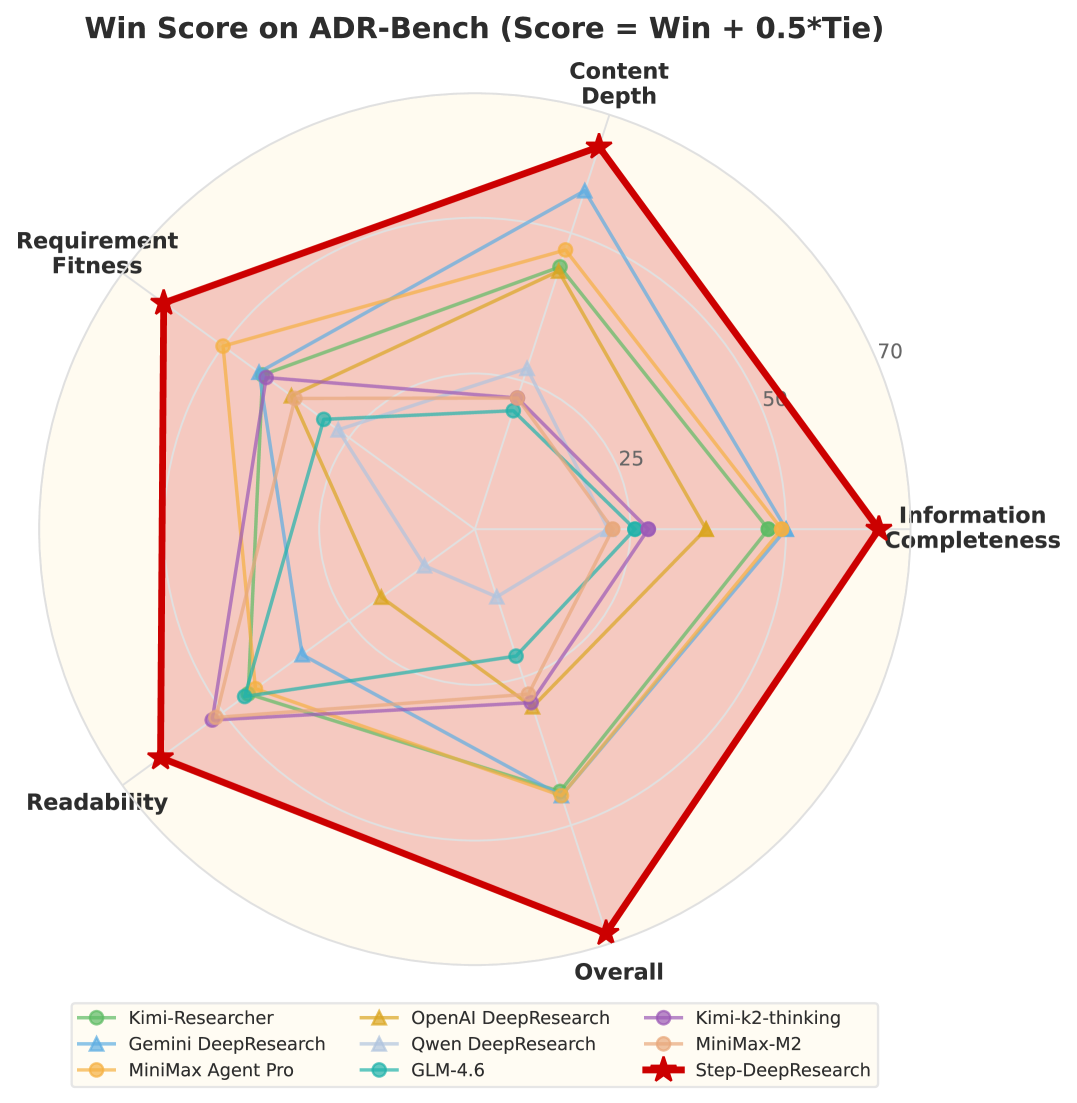 图2:中训练期间的性能变化
图2:中训练期间的性能变化
图2:中训练期间在不同任务上的性能趋势。可以看到,在FRAMES任务上提升了10.88%,说明模型的多跳推理能力得到了显著增强。
数据组成(表1-2):
数据类型 比例 说明 百科/学术数据 30% 维基百科、学术论文 合成知识 25% 知识图谱生成的QA 摘要数据 20% 长文档摘要 推理数据 15% 多步推理任务 工具调用 10% 搜索、代码执行等
3.2 第二阶段:监督微调(SFT)
目标:让模型学会完整的深度研究流程
这个阶段使用两类数据:
Deep Search数据:
- 多跳搜索任务
- 强调信息检索的准确性
Deep Research数据:
- 开放性研究任务
- 强调报告的完整性和深度
数据清洗策略:
- 轨迹效率优化:去除冗余的搜索步骤
- 鲁棒性控制:保留一些"走弯路"的轨迹,增强模型的容错能力
- 认知去重:避免相似任务的重复训练
3.3 第三阶段:强化学习(RL)
目标:在真实环境中优化策略
这是最关键的阶段。论文使用PPO算法在真实的多工具环境中训练模型。
奖励设计 : 论文训练了一个专门的Rubrics Judge模型来评估研究报告的质量:
- 信息完整性(是否覆盖了所有关键点)
- 内容深度(分析是否深入)
- 引用质量(来源是否可靠)
- 逻辑连贯性(论述是否清晰)
每个维度都有细粒度的评分标准,确保奖励信号的准确性。
四、系统架构设计
4.1 ReAct循环
Step-DeepResearch采用了经典的**ReAct(Reasoning + Acting)**架构:
循环开始
↓
思考(Reasoning):分析当前状态,决定下一步
↓
行动(Acting):调用工具执行操作
↓
观察(Observation):获取执行结果
↓
反思(Reflection):评估是否需要调整计划
↓
循环继续或结束4.2 工具集
系统配备了丰富的工具:
工具名称 功能 说明 batch_web_surfer 批量网页浏览 同时访问多个网页 todo 任务管理 跟踪研究进度 shell 代码执行 运行Python等代码 knowledge_base 知识管理 存储和检索已获取的信息
4.3 关键设计亮点
1. 权威信息获取
- 建立了600+权威站点索引
- 支持段落级精准检索
- 优先从可信来源获取信息
2. 知识管理优化
- 基于补丁的编辑机制,节省70%的token消耗
- 隐式上下文管理,避免信息过载
3. 交互执行环境
- 沙箱环境保证安全性
- 视觉冗余消除策略,提高效率
五、ADR-Bench:首个中文深度研究评测基准
5.1 为什么需要新的评测基准?
现有的评测基准(如ResearchRubrics、BrowseComp)主要面向英文场景,缺乏对中文深度研究的覆盖。
论文提出了ADR-Bench(Agent Deep Research Benchmark),专门针对中文场景设计。
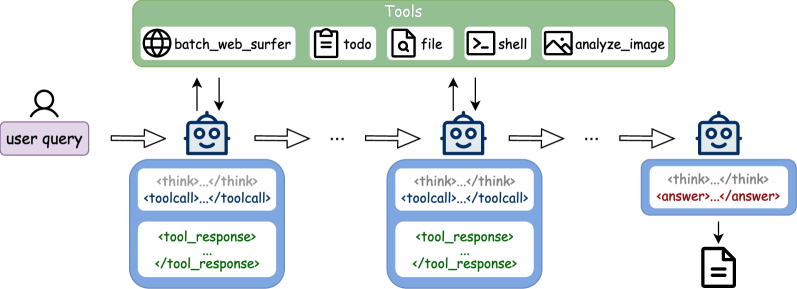 图5:ADR-Bench查询分布
图5:ADR-Bench查询分布
图5:ADR-Bench的查询分布,覆盖9大领域:法律、金融、计算机、教育、医疗、社会生活、科学工程、政治、哲学。
5.2 评测设计
双轨评估机制:
通用领域评估:
- 采用人工盲审比较
- 评估维度:信息完整性、内容深度、逻辑连贯性、引用质量
专业领域评估:
- 专家设计细粒度Rubrics
- 每个领域有特定的评分标准
- 强调原子性(每个标准独立)和可验证性(可客观判断)
六、实验结果分析
6.1 主要结果
ResearchRubrics评测(英文):
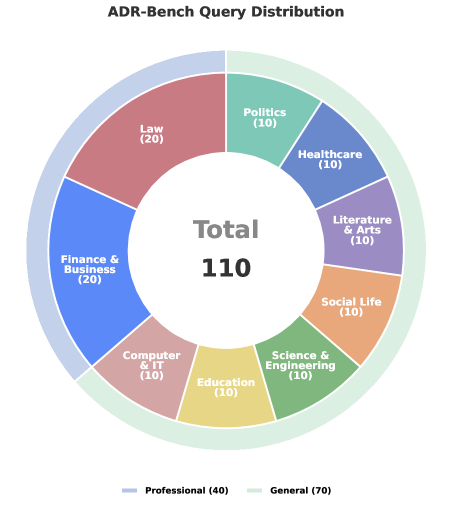 图6:ResearchRubrics评测结果
图6:ResearchRubrics评测结果
图6:在ResearchRubrics基准上的评测结果。Step-DeepResearch得分61.42,仅次于Gemini DeepResearch(63.69),超越了OpenAI DeepResearch。
模型 得分 成本(每次) Gemini DeepResearch 63.69 ~5元 Step-DeepResearch 61.42 <0.50元 OpenAI DeepResearch 60.8 ~3元 Kimi-Researcher 55.2 ~1元
关键发现:Step-DeepResearch以不到Gemini 1/10的成本,实现了相近的性能!
ADR-Bench评测(中文):
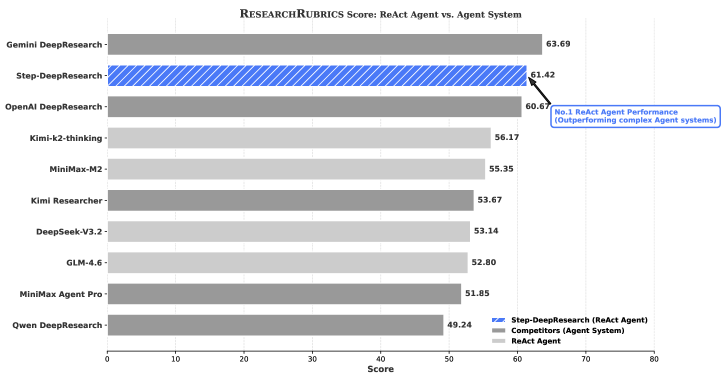 图7:ADR-Bench人工评估结果
图7:ADR-Bench人工评估结果
图7:ADR-Bench人工评估结果(胜-平-负统计)。Step-DeepResearch以30胜21负的成绩超越OpenAI DeepResearch。
6.2 细粒度分析
优势领域:
 图8:ResearchRubrics分维度得分
图8:ResearchRubrics分维度得分
图8:在ResearchRubrics各维度上的得分对比。Step-DeepResearch在隐式标准(54.5)、引用质量(57.0)、沟通质量(58.2)等维度表现出色。
- 隐式标准:54.5分(理解用户未明确表达的需求)
- 引用质量:57.0分(信息来源可靠性)
- 沟通质量:58.2分(报告可读性)
待改进领域:
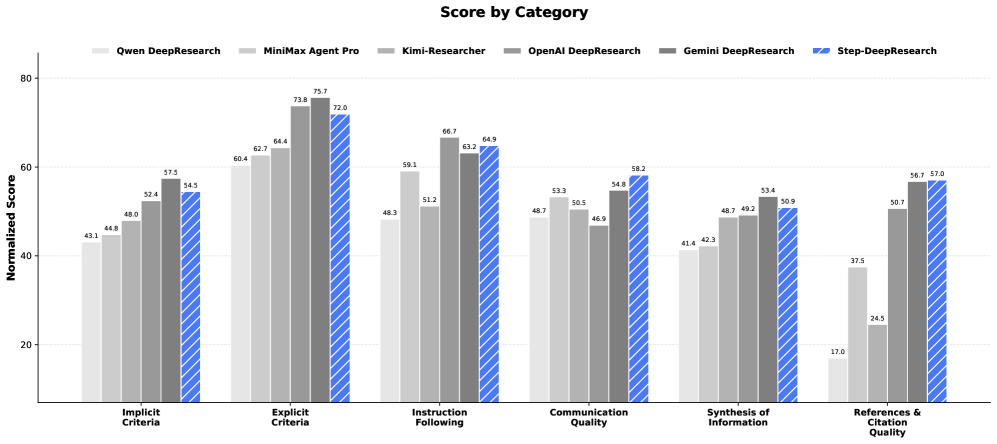 图9:ResearchRubrics分领域得分
图9:ResearchRubrics分领域得分
图9:在不同研究领域的得分对比。Step-DeepResearch在STEM(64.7)和哲学(46.1)领域的表现落后于Gemini。
- STEM领域:64.7分(需要更强的科学推理能力)
- 哲学领域:46.1分(需要更深的抽象思维能力)
6.3 ADR-Bench细粒度评估
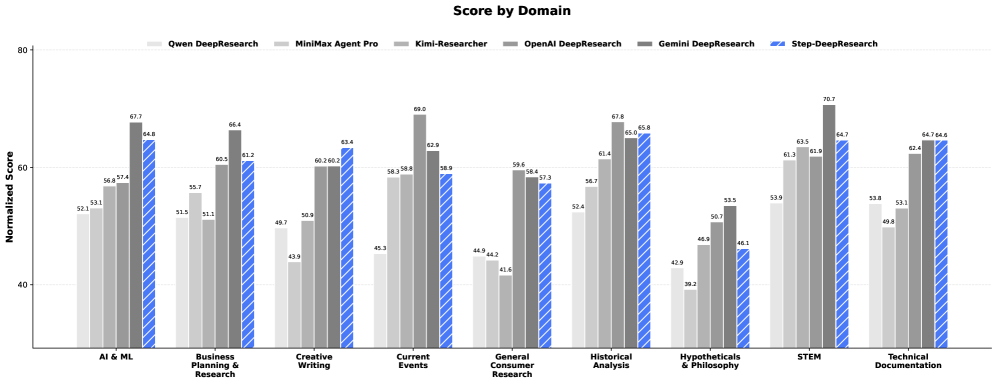 图10:ADR-Bench细粒度评估结果
图10:ADR-Bench细粒度评估结果
图10:ADR-Bench在各评估维度上的细粒度结果,包括信息完整性、内容深度、逻辑连贯性、引用质量等。
七、技术启示与未来展望
7.1 核心技术启示
1. 原子能力分解是关键
- 不要试图让模型"一步到位"学会复杂任务
- 将任务分解为可训练的原子能力
- 分别优化,再整合
2. 数据质量比数量更重要
- 逆向工程合成保证了数据的高质量
- 轨迹一致性过滤避免了噪声数据
- 认知去重提高了训练效率
3. 渐进式训练的有效性
- 中训练→SFT→RL的路径经过验证
- 每个阶段有明确的目标
- 避免了"一锅炖"的训练方式
7.2 现有挑战
论文也坦诚地指出了当前系统的不足:
1. 工具使用鲁棒性
- 在复杂场景下,工具调用可能失败
- 需要更好的错误处理机制
2. 高噪声环境下的事实一致性
- 互联网信息质量参差不齐
- 模型有时会被错误信息误导
3. 长时程任务的稳定性
- 超长研究任务中可能出现"迷失方向"
- 需要更强的全局规划能力
7.3 未来方向
论文提出了几个有前景的研究方向:
1. 多代理协作
- 专门的规划者、检索者、验证者
- 分工协作,各司其职
2. 环境适应性
- 根据任务类型动态调整策略
- 更好地处理不同领域的研究任务
3. 可追溯性优化
- 让用户能够追踪每个结论的来源
- 增强报告的可信度
八、总结
Step-DeepResearch是一个里程碑式的工作,它证明了:
- 32B参数的模型可以实现专家级深度研究能力
- 原子能力分解+渐进式训练是有效的技术路径
- 低成本高质量的AI研究助手是可行的
对于普通用户来说,这意味着未来我们可以用极低的成本,获得专业级的研究支持。无论是写行业报告、做市场调研,还是学术文献综述,AI都能成为我们的得力助手。
对于AI研究者来说,这篇论文提供了宝贵的技术参考:
- 如何设计原子能力
- 如何合成高质量训练数据
- 如何进行渐进式训练
- 如何评估深度研究系统
论文信息:
- 标题:Step-DeepResearch Technical Report
- 作者:Agent-Team, StepFun(65位作者)
- arXiv:2512.20491v4
- GitHub:https://github.com/stepfun-ai/StepDeepResearch
如果你对深度研究AI感兴趣,欢迎关注我们,获取更多前沿技术解读!