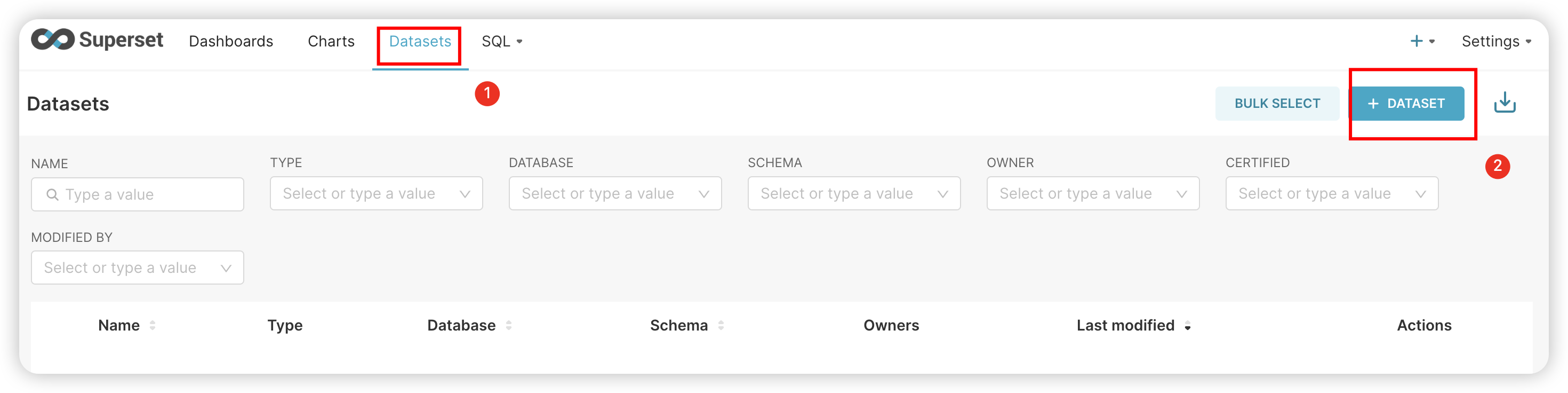
阿里云选购
创建 VPC
专有网络 VPC(Virtual Private Cloud)是云上安全隔离的虚拟网络环境,支持自定义网络配置、部署和访问云产品资源。
VPC提供了类似于传统数据中心的安全和可配置的私有网络空间,同时又具备云计算的弹性和可扩展性。用户能够完全掌控自己的专有网络,包括选择自己的IP地址范围、创建交换机、配置路由表和网关等。
步骤
专有网络->创建专有网络
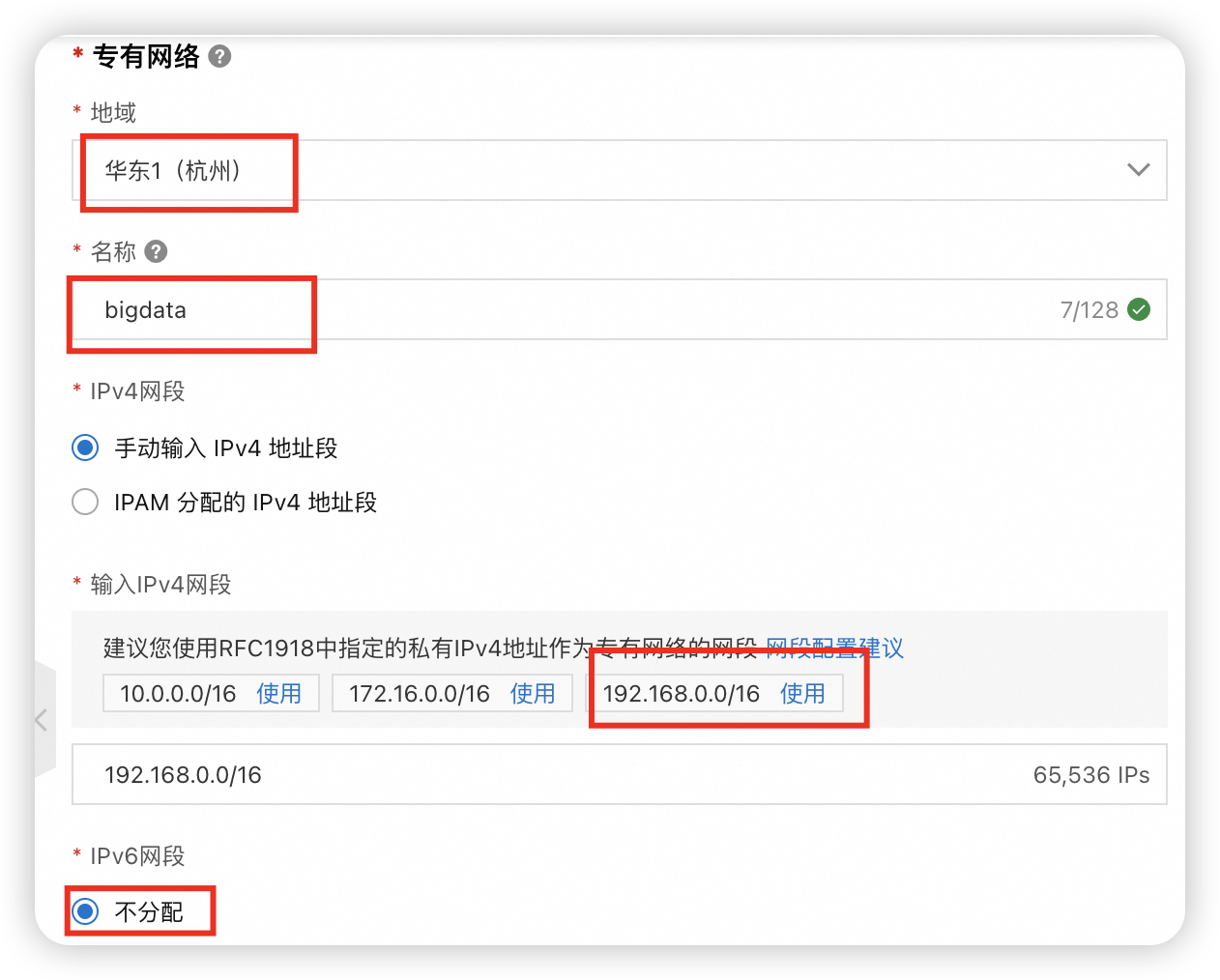
地域选离自己近的,这里选的华东1(杭州)
名称就叫bigdata
ipv4网段手动输入,选192.168.0.0/16
ipv6不分配
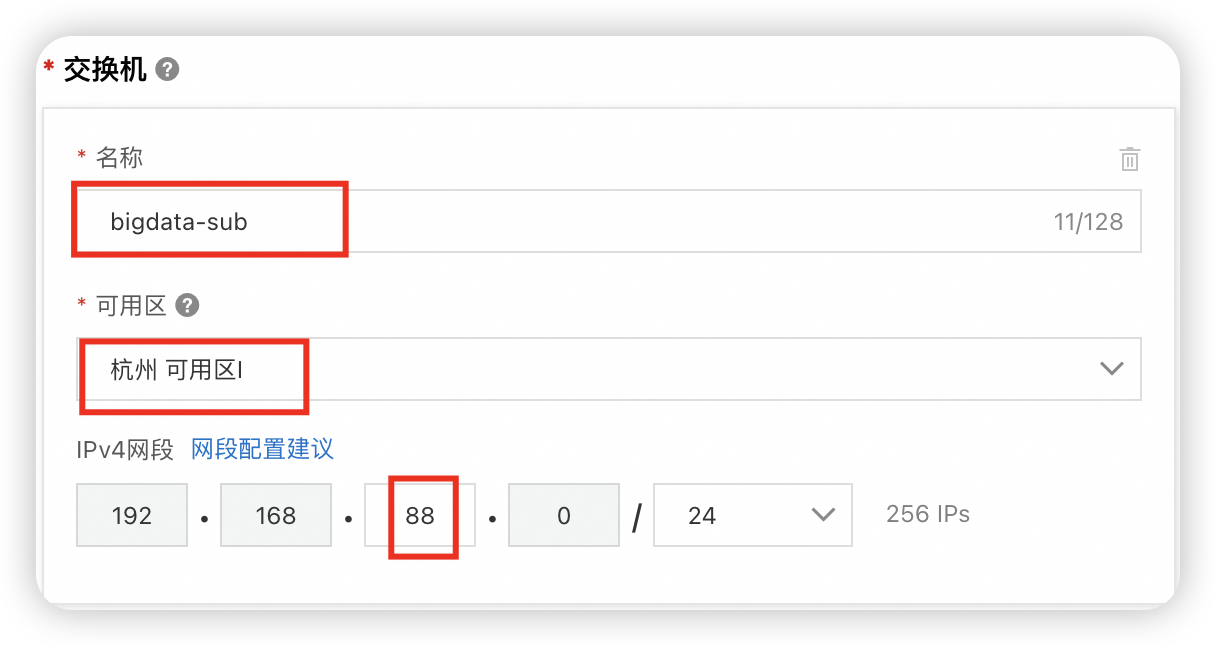
交换机名称bigdata-sub
可用区选杭州
网段192.168.88.0/24
安全组
安全组是一种虚拟防火墙,能够控制ECS实例的出入站流量。您可以将具有相同安全需求并相互信任的ECS实例放入相同的安全组,以划分安全域,保障云上资源的安全。本文介绍安全组的功能、分类、最佳实践和操作指引等。
步骤
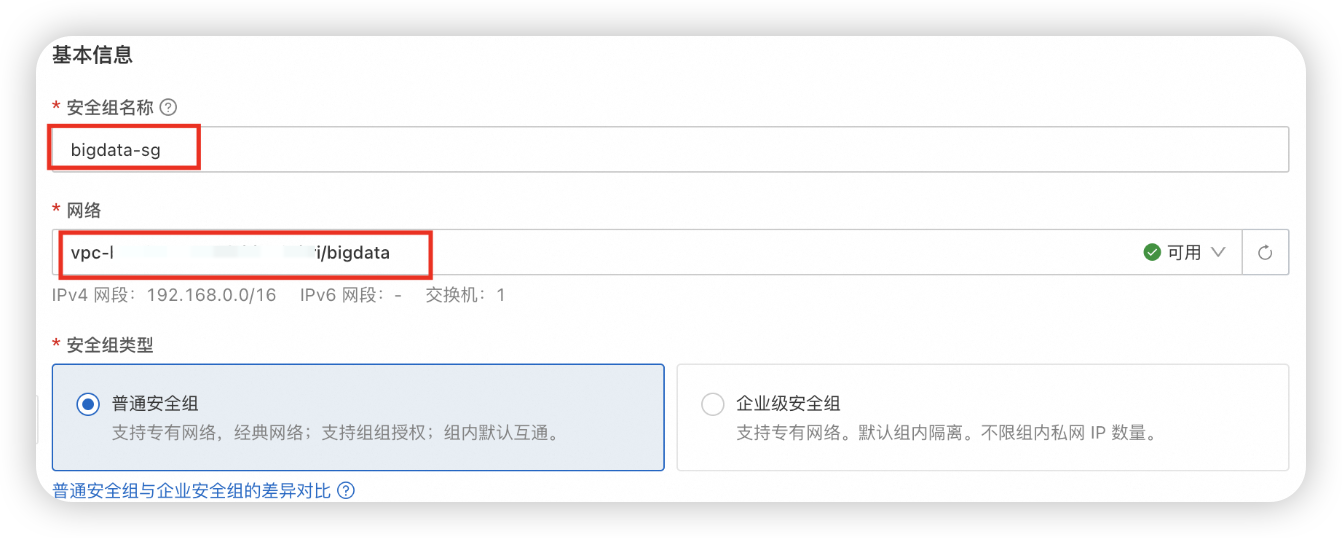
安全组->创建安全组
安全组名称,填bigdata-sg
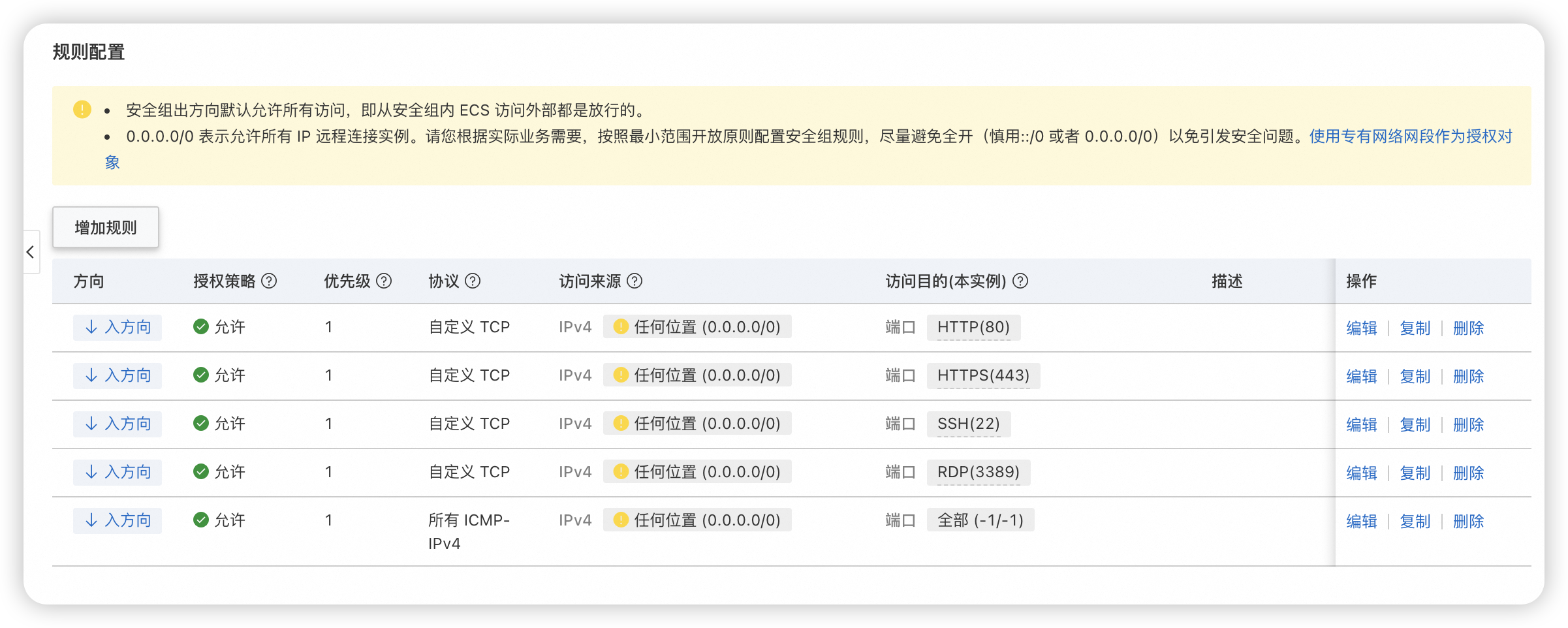
规则配置中建议全删然后只加自己的或者公司的专有网络
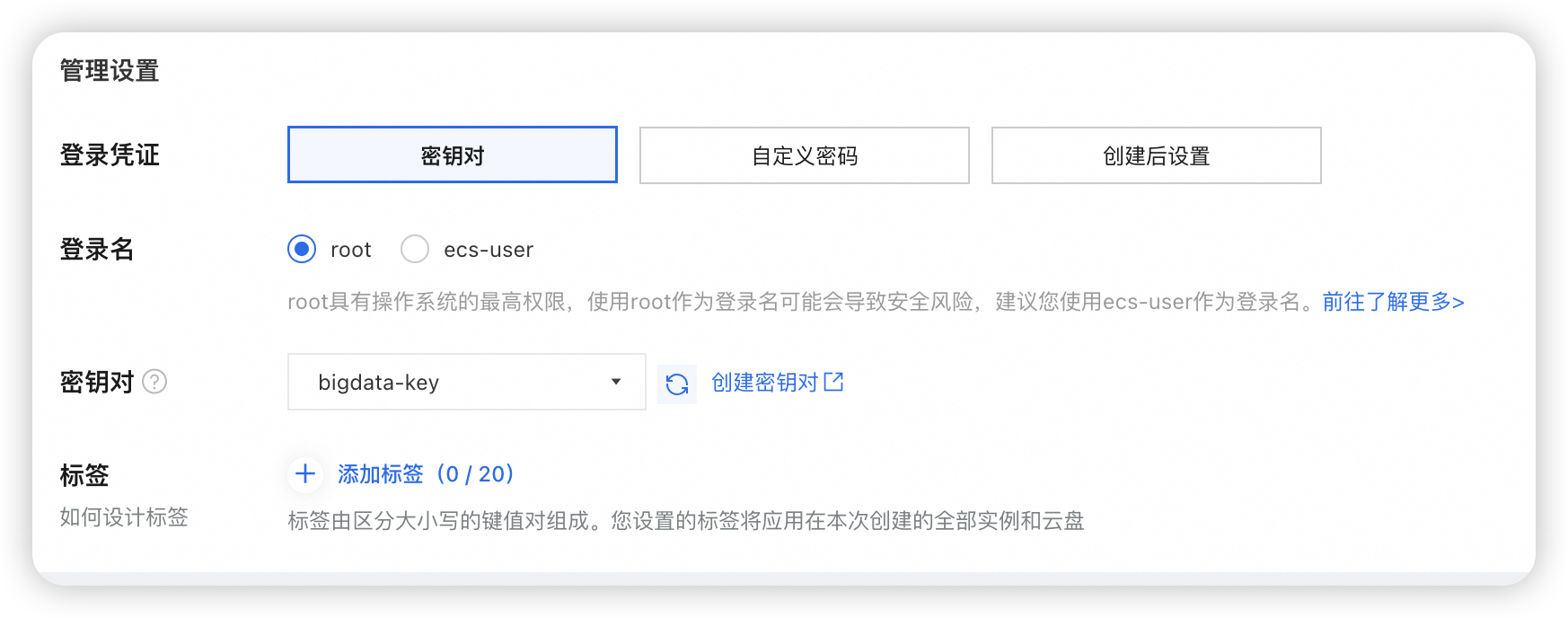
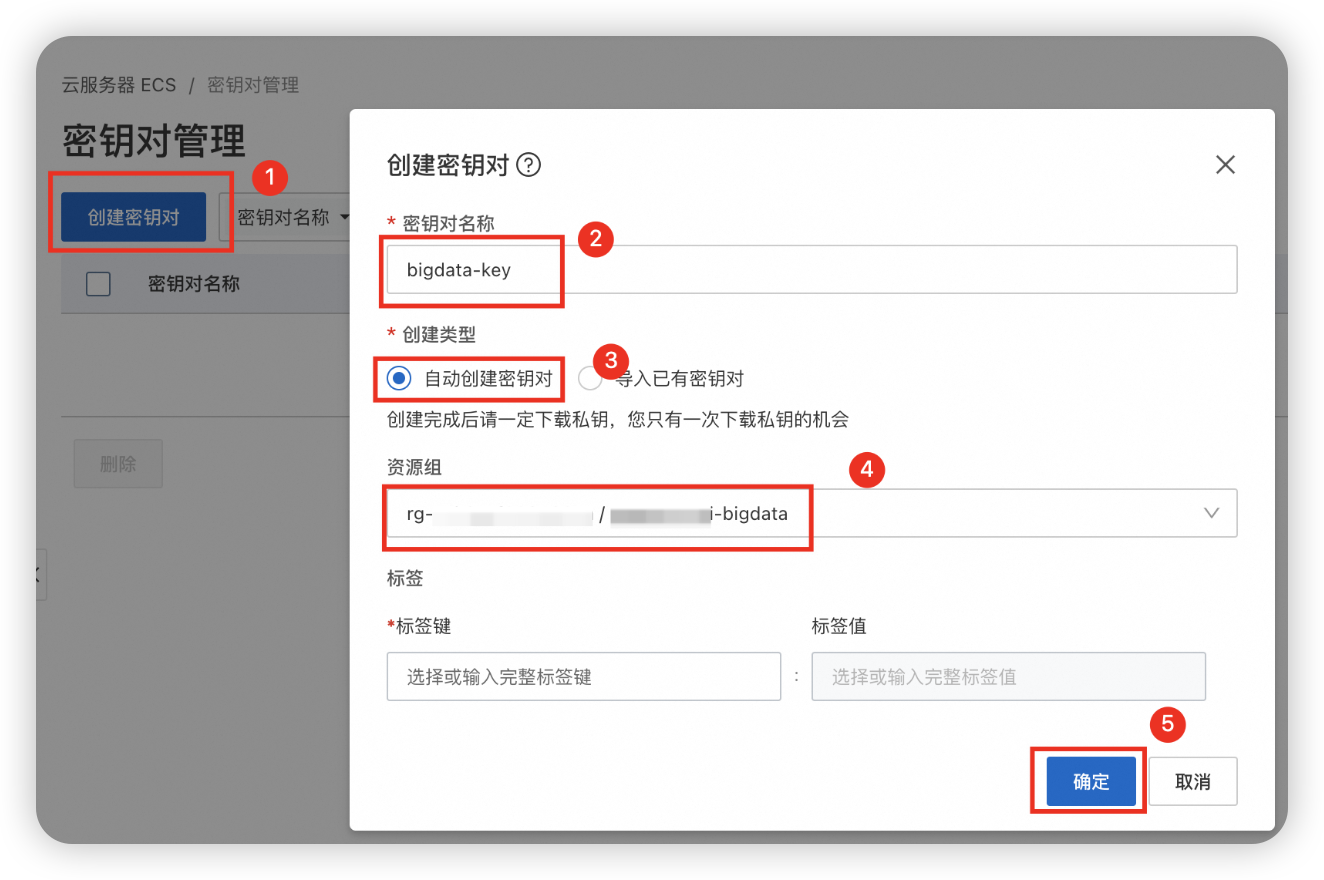
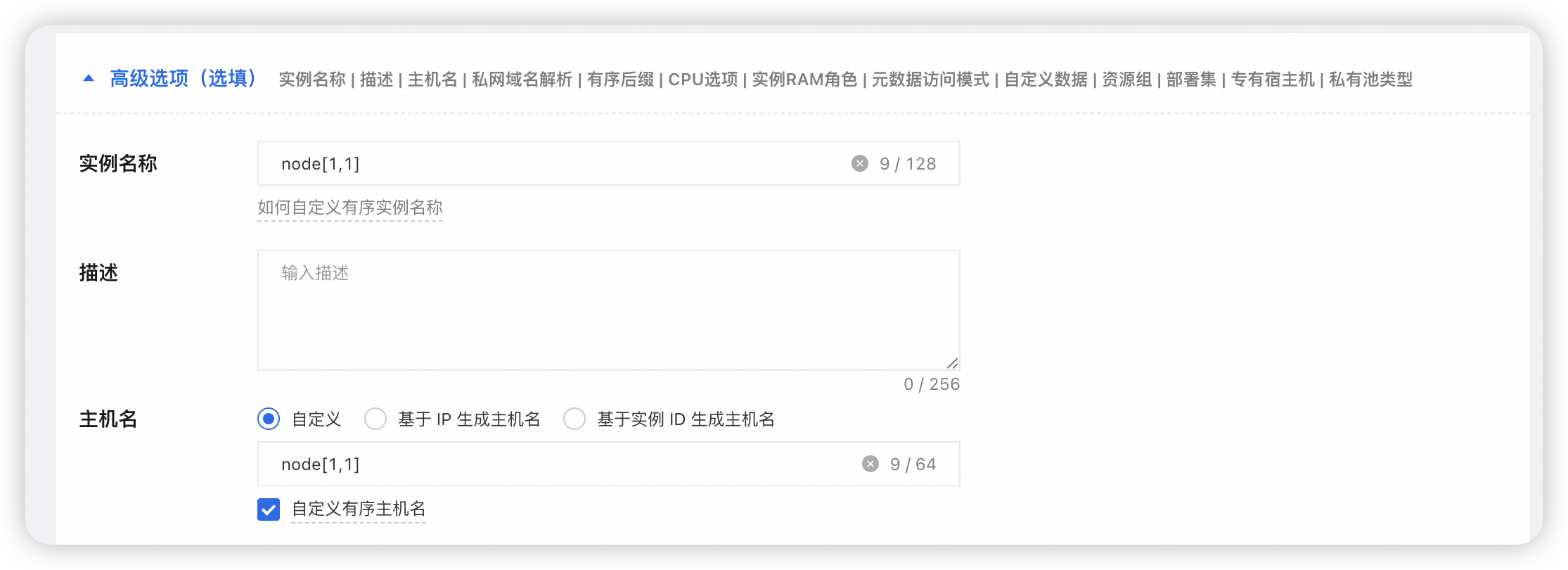
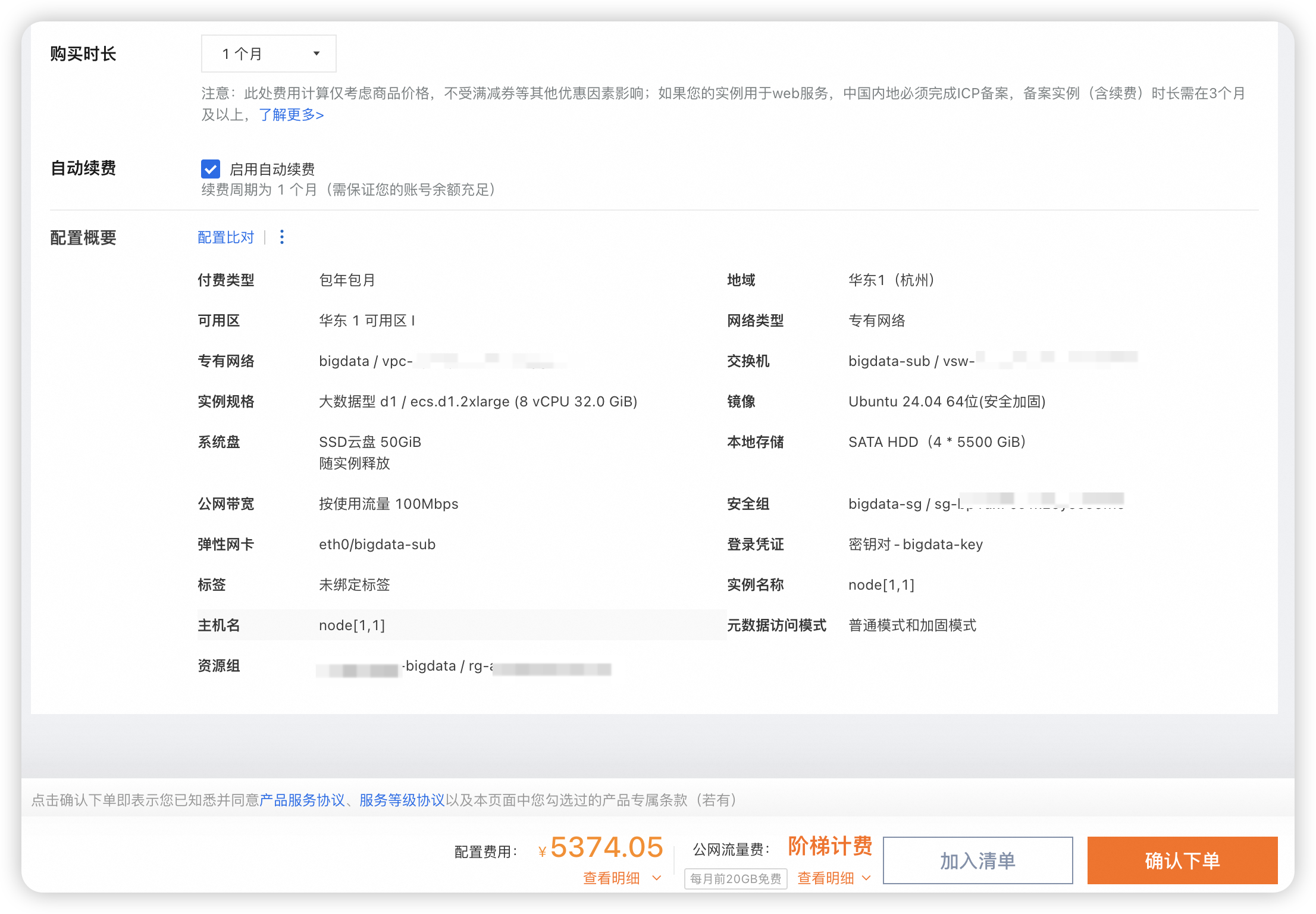
购买云服务器 ECS
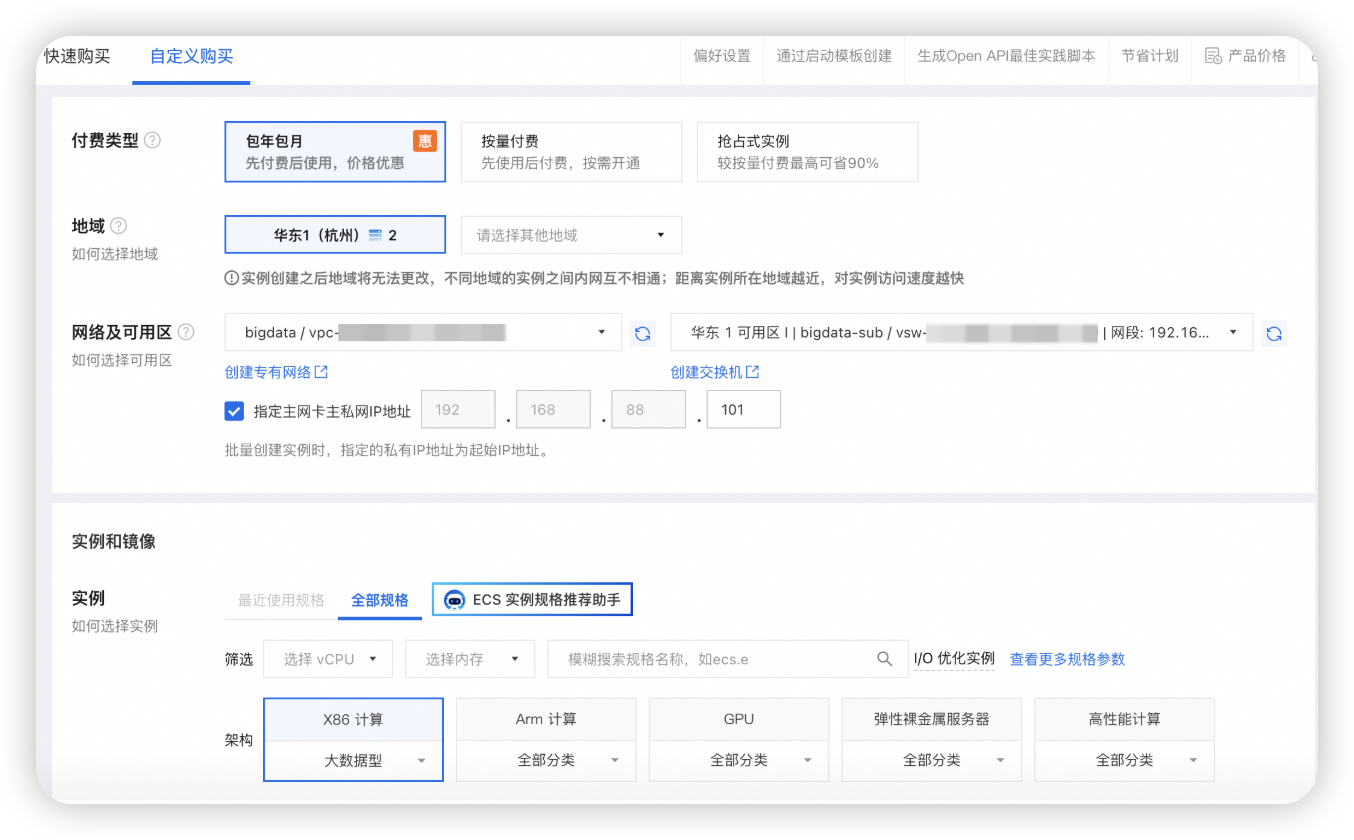

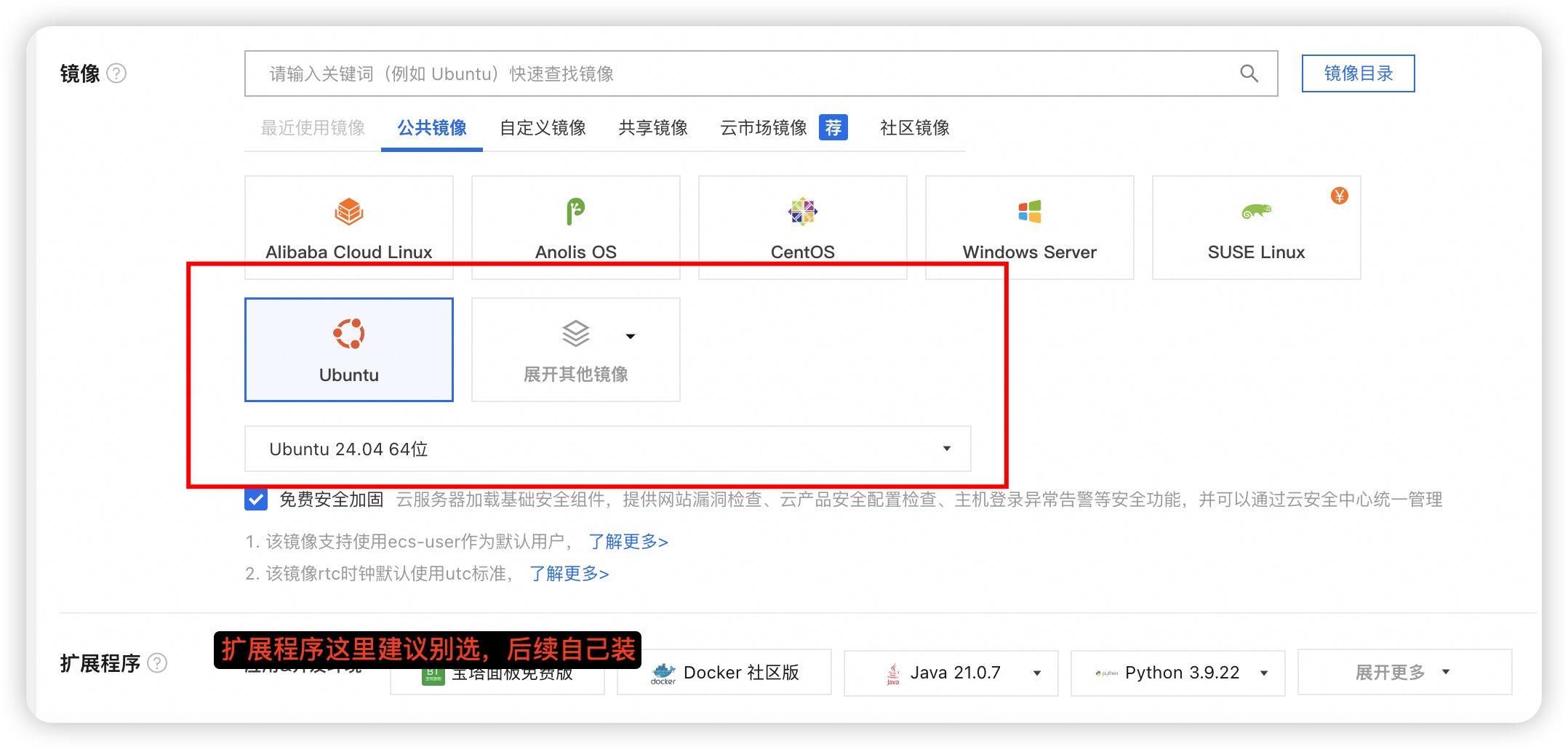
建议node1的系统盘选择100g,其他节点50g,或者先都选50g,后面不够了再单独给node1扩容。
按年付费

按量付费

相关工具准备
这里推荐的ssh终端工具是termius,全平台手机平板都能用,而且性能好、颜值高。(之前用finalshell发现太占内存了)
ssh工具
创建密钥,一次就好。
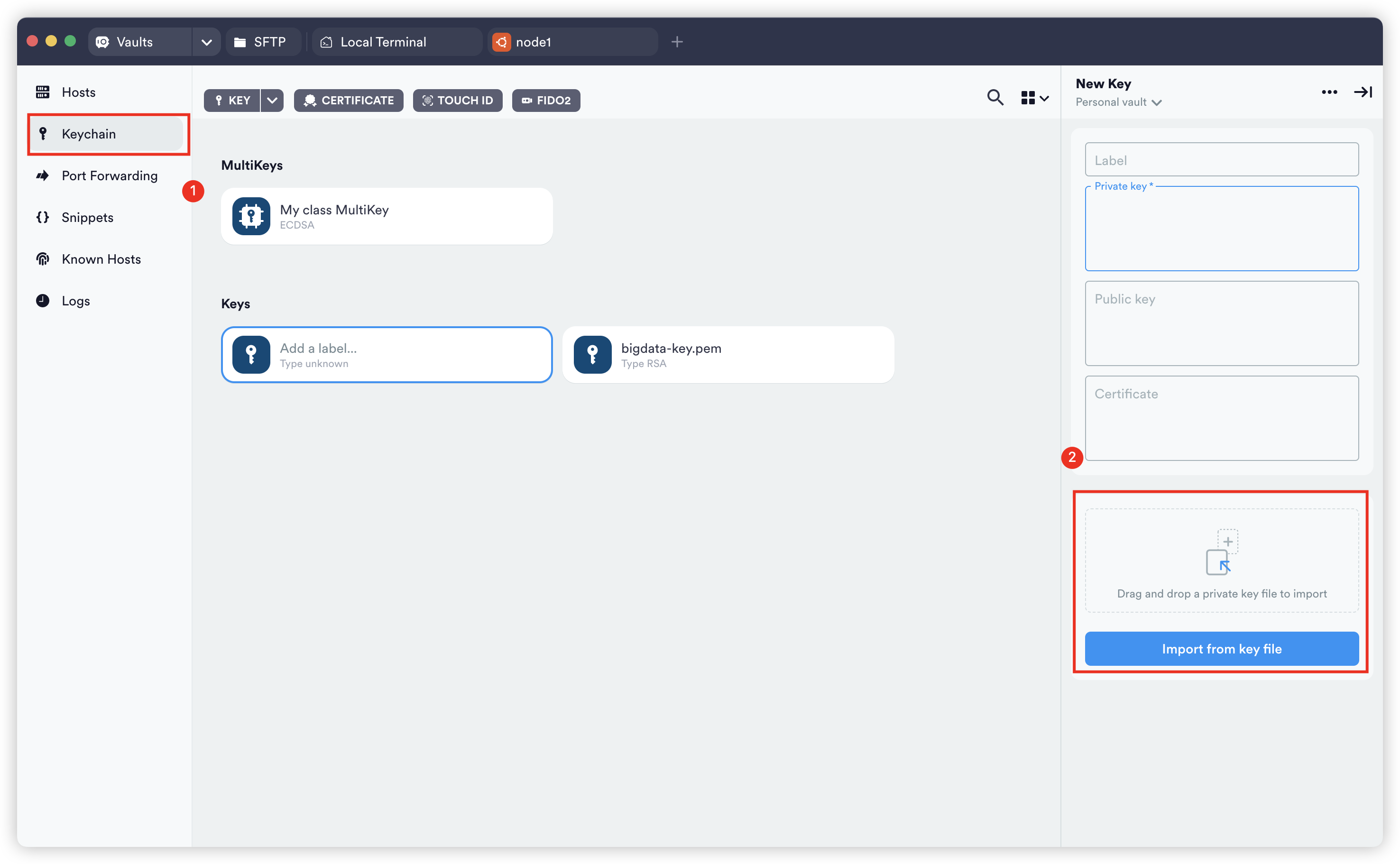
导入之前生成的密钥后,点下右上角的勾即可。
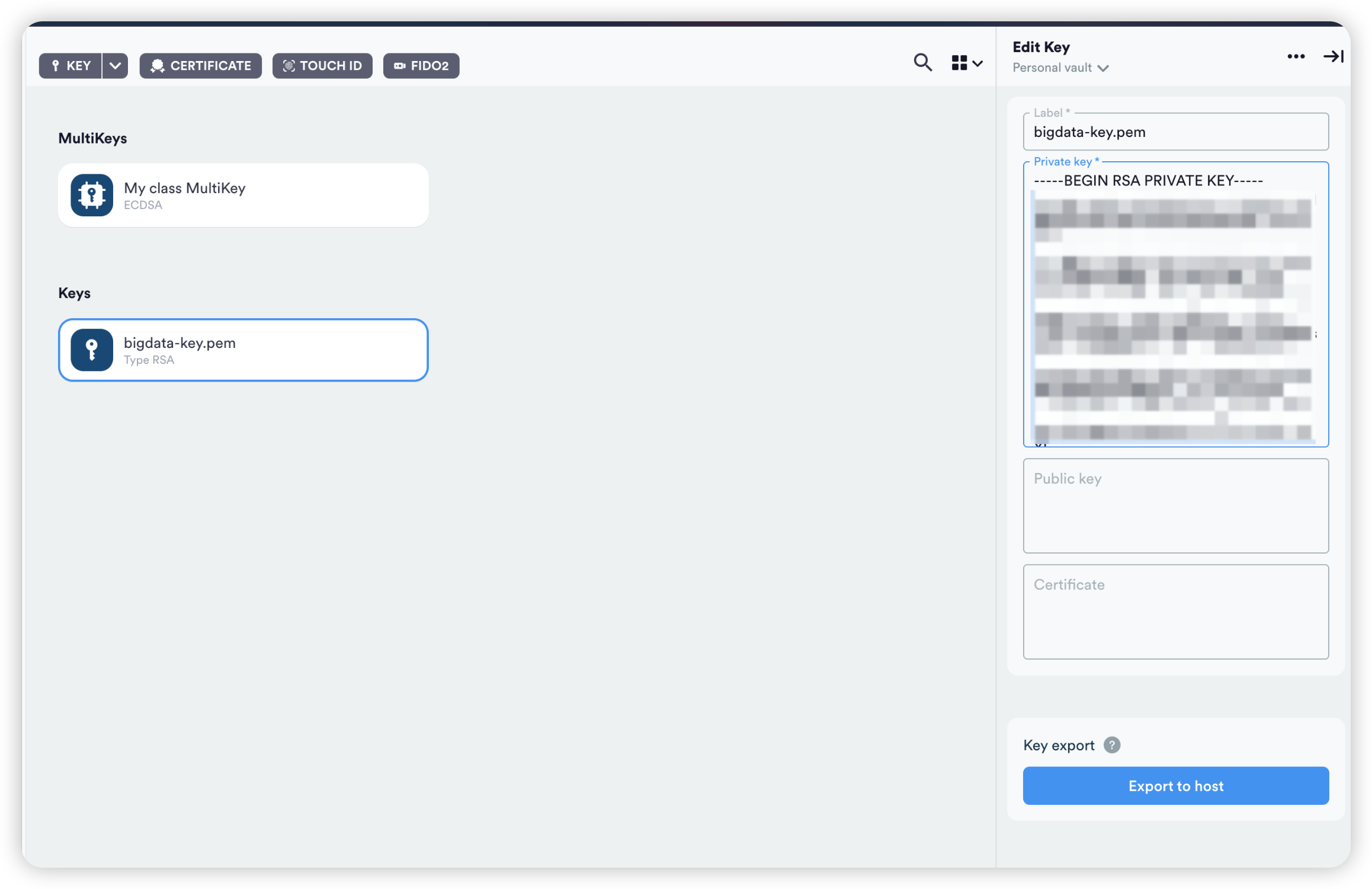
然后就可以创建链接了,共三个节点所以需要设置三次。
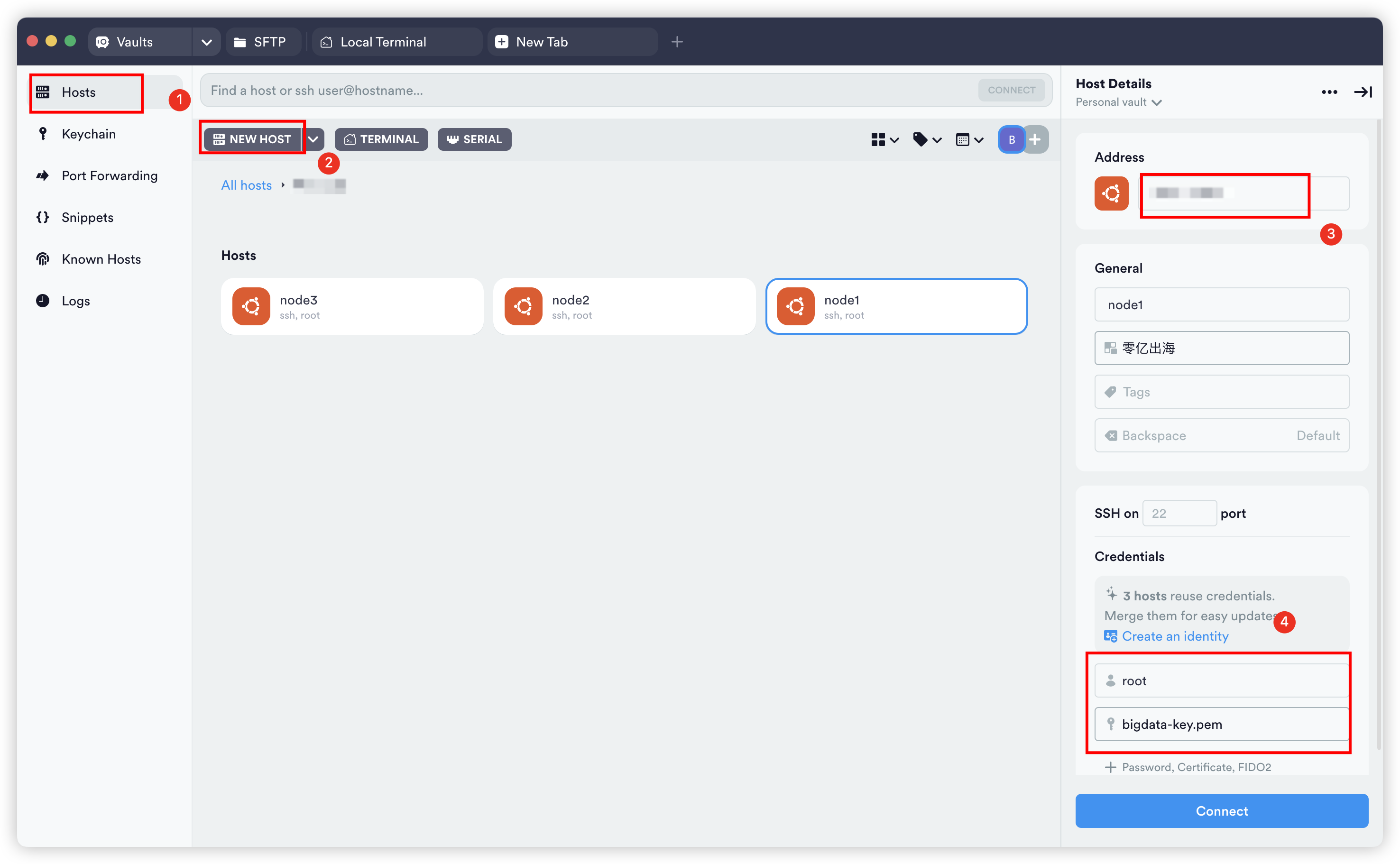
主机名映射
三个节点,每个节点内都要设置一次。
bash
vim /etc/hosts加入下面代码
注意这里用私网ip,否则后面没法启动namenode
bash
# node1的私网IP node1 node1
# node2的私网IP node2 node2
# node3的私网IP node3 node3
192.168.88.247 node1 node1
192.168.88.246 node2 node2
192.168.88.248 node3 node3光这样还不能直接ssh,还需要把密钥文件上传到每个节点上。
点击terminus左上角sftp然后点击左下角select host选择node1(node2、node3都要操作一次,或者只操作node1,等下面批量分发)
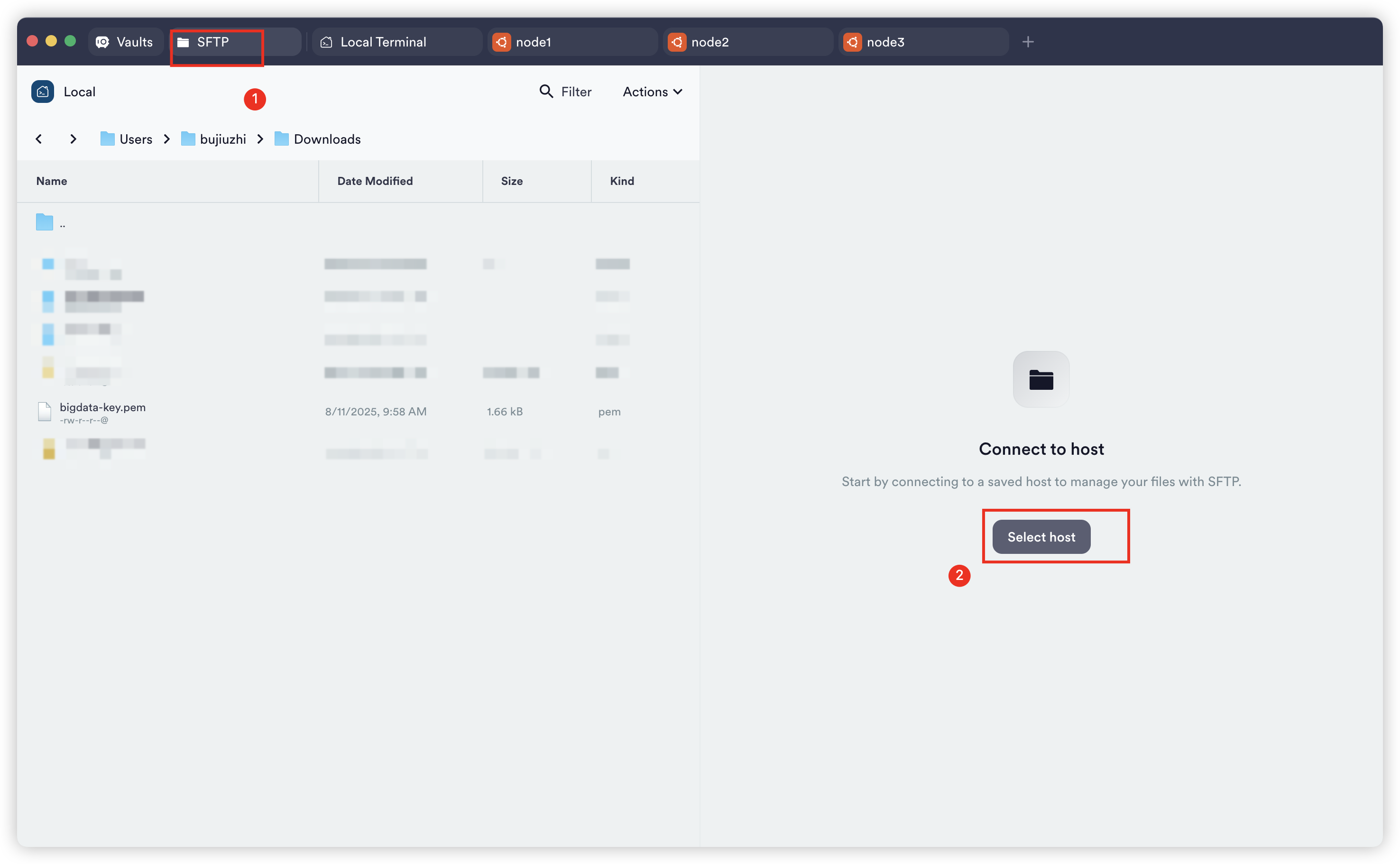
打开隐藏文件的显示
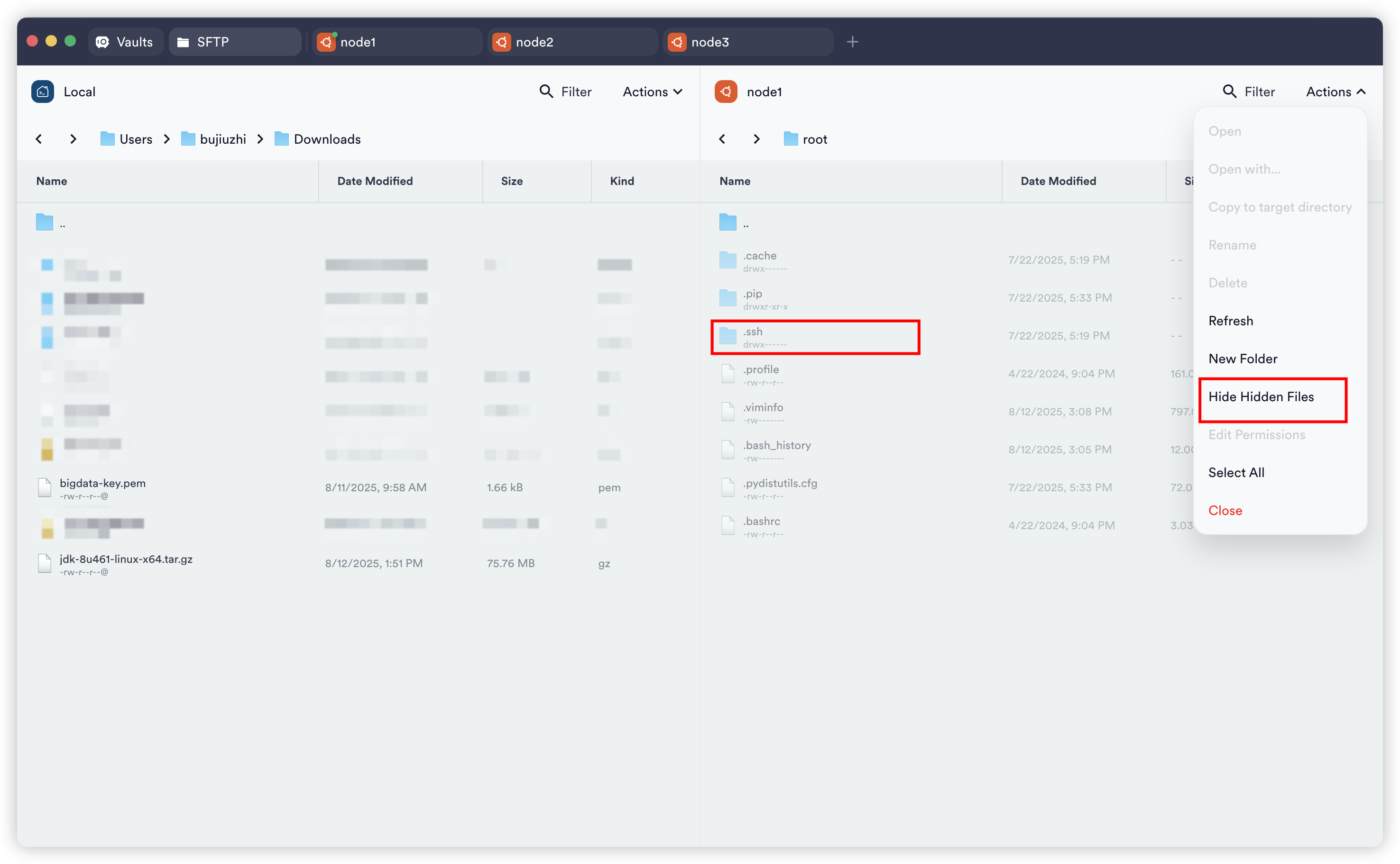
直接把左边的bigdata-key.pem(阿里云当时下载的)给拖拽右边.ssh目录下就行
改名改权限
bash
cd /root/
mv .ssh/bigdata-key.pem .ssh/id_rsa
chmod 400 .ssh/id_rsa
ll .ssh/id_rsa 现在就能ssh到其他节点了,但是如果只设置的一个机子的就只能exit返回本机。
集群批量工具
xsync
编写分发脚本
bash
vim /usr/local/bin/xsync
bash
#!/usr/bin/env bash
#
# 批量分发文件/目录到集群节点(保持原有绝对路径)
# 节点列表:node1 node2 node3
#
# 用法示例:
# xsync 文件1 文件2 文件3 ...
#
# 参数说明:
# 文件1 文件2 文件3 ...
# 一个或多个需要分发到集群所有节点的文件或目录。
# - 文件:将覆盖目标节点相同路径下的同名文件。
# - 目录:将整个目录及内容同步到目标节点相同路径下。
#
# 示例:
# xsync /etc/hosts /home/ecs-user/.bashrc /opt/module/jdk
# ↑ 分发 /etc/hosts、/home/ecs-user/.bashrc 两个文件 和 /opt/module/jdk 整个目录
#
# 注意事项:
# 1. 请提前配置好免密登录(当前节点到所有目标节点)。
# 2. 目录结构会保持一致,目标路径与源路径相同。
# 3. 同步时会覆盖目标节点上的同名文件/目录。
#
set -euo pipefail
# 节点列表
hosts=(node1 node2 node3)
# rsync 参数(可加 --progress 查看传输进度)
RSYNC_OPTS=(-av)
# 1) 参数校验
if [ $# -lt 1 ]; then
echo "用法: $(basename "$0") 文件1 [文件2 ...]"
exit 1
fi
# 2) 遍历节点
for host in "${hosts[@]}"; do
echo "========== 同步至:$host =========="
# 3) 遍历每个要同步的文件/目录
for file in "$@"; do
if [ -e "$file" ]; then
# 绝对父目录路径
pdir="$(cd -P "$(dirname "$file")" && pwd)"
# 文件或目录名称
fname="$(basename "$file")"
# 远端创建父目录
ssh "$host" "mkdir -p '$pdir'"
# 同步到远端
rsync "${RSYNC_OPTS[@]}" "$pdir/$fname" "$host:$pdir/"
echo "✓ 已同步:$pdir/$fname → $host:$pdir/"
else
echo "⚠ 跳过:$file 不存在"
fi
done
done
echo "✅ 全部同步完成"给上权限
bash
chmod 755 /usr/local/bin/xsync测试并分发改脚本到其他节点
bash
xsync /usr/local/bin/xsync
# 刚才的密钥文件也可以用该命令来分发同步
xsync ~/.ssh/id_rsa当集群中所有机子都有id_rsa,就可以随意ssh其他节点了。
xcall
bash
vim /usr/local/bin/xcall
bash
#!/usr/bin/env bash
#
# 批量在集群节点执行命令(加载环境变量,保持当前工作目录)
# 节点列表:node1 node2 node3
#
# 用法示例:
# xcall "jps"
# xcall "hostname && whoami"
# xcall "ls -l"
#
# 说明:
# 1) 使用 bash -lc 让 shell 自行加载登录环境(/etc/profile、~/.bash_profile 等)
# 2) 在远端先 cd 到本地当前目录再执行命令,保证路径一致
# 3) 需要提前配置免密登录
# 4) 首次连接自动接受主机指纹(accept-new),避免 BatchMode 阻塞
# 5) 对本机不走 SSH,直接本地执行,避免"自连"指纹问题
#
set -euo pipefail
# 节点列表
hosts=(node1 node2 node3)
# 参数校验
if [ $# -lt 1 ]; then
echo "用法: $(basename "$0") \"命令\""
exit 1
fi
# 要执行的命令(原样传递给远端)
cmd="$*"
# 本地当前目录(在远端也切到该目录)
workdir="$(pwd)"
# 本机可能的主机名(短名/全名)
local_short="$(hostname -s || true)"
local_full="$(hostname -f || true)"
local_host="$(hostname || true)"
for host in "${hosts[@]}"; do
echo "========== $host =========="
# 本机:不用 SSH,直接本地执行(用 bash -lc 加载登录环境)
if [[ "$host" == "$local_short" || "$host" == "$local_full" || "$host" == "$local_host" ]]; then
# 这里不用手工 source,交给 bash -lc
bash -lc "cd '$workdir' 2>/dev/null || true; $cmd"
continue
fi
# 远端:首次自动接受新指纹;禁交互;设置超时;bash -lc 加载环境
ssh \
-o BatchMode=yes \
-o StrictHostKeyChecking=accept-new \
-o ConnectTimeout=5 \
"$host" "bash -lc \"cd '$workdir' 2>/dev/null || true; $cmd\""
done
bash
chmod 755 /usr/local/bin/xcall
# 也同步下
xsync /usr/local/bin/xcall
xcall ls -l /usr/local/bin/cluster_user_ssh
bash
vim /usr/local/bin/cluster_user_ssh
bash
#!/usr/bin/env bash
#
# 集群批量:创建/查询/轮换/删除 用户及 SSH 免密(主组统一 bigdata)
# 节点列表:node1 node2 node3
#
# 用法示例:
# cluster_user_ssh create # 默认创建 bigdata 用户,密码=bigdata
# cluster_user_ssh status bigdata
# cluster_user_ssh rotate bigdata
# cluster_user_ssh delete bigdata --purge
#
set -euo pipefail
# ========= 节点清单 =========
hosts=(node1 node2 node3)
LOCAL_NODE="${hosts[0]}"
DEFAULT_GROUP="bigdata"
DEFAULT_USER="bigdata"
EXTRA_GROUPS="sudo" # 默认加 sudo 组
# ===========================
die() { echo "[ERR] $*" >&2; exit 1; }
need_cmd() {
for c in "$@"; do
command -v "$c" >/dev/null 2>&1 || die "缺少命令: $c"
done
}
run_remote() {
local host="$1"; shift
ssh -o BatchMode=yes "root@${host}" "$@"
}
copy_to_remote() {
local src="$1" host="$2" dst="$3"
scp -q "$src" "root@${host}:${dst}"
}
usage() {
cat <<EOF
用法:
$(basename "$0") create [username] # 创建用户并分发免密(默认 bigdata,密码同名)
$(basename "$0") status <username> # 查看各节点状态
$(basename "$0") rotate <username> # 轮换该用户密钥
$(basename "$0") delete <username> [--purge] # 删除用户;--purge 删除家目录
说明:
- 创建的用户主组为 bigdata(不存在则自动创建)。
- 默认密码与用户名相同,并自动加入 sudo 组。
- 需要 root 已能免密访问所有节点。
EOF
}
need_cmd ssh scp ssh-keygen adduser id awk grep sed printf getent install chown chmod usermod passwd
user_home() { printf "/home/%s" "$1"; }
ssh_dir() { printf "%s/.ssh" "$(user_home "$1")"; }
pri_key() { printf "%s/id_rsa" "$(ssh_dir "$1")"; }
pub_key() { printf "%s.pub" "$(pri_key "$1")"; }
auth_keys() { printf "%s/authorized_keys" "$(ssh_dir "$1")"; }
ensure_group_local() {
local grp="$1"
getent group "$grp" >/dev/null 2>&1 || { echo "[INFO] 创建组 $grp"; addgroup "$grp"; }
}
ensure_group_remote() {
local host="$1" grp="$2"
run_remote "$host" "getent group '$grp' >/dev/null 2>&1 || addgroup '$grp'"
}
create_user_and_keys_local() {
local user="$1"
local home sdir prik pubk auth
home="$(user_home "$user")"
sdir="$(ssh_dir "$user")"
prik="$(pri_key "$user")"
pubk="$(pub_key "$user")"
auth="$(auth_keys "$user")"
ensure_group_local "$DEFAULT_GROUP"
if ! id -u "$user" >/dev/null 2>&1; then
echo "[INFO] 创建用户 $user (主组=$DEFAULT_GROUP, 密码=$user)"
adduser --disabled-password --gecos "" --ingroup "$DEFAULT_GROUP" "$user"
echo "${user}:${user}" | chpasswd
usermod -aG sudo "$user"
else
echo "[WARN] 用户 $user 已存在,确保属于组 $DEFAULT_GROUP 和 sudo"
usermod -aG "$DEFAULT_GROUP" "$user" || true
usermod -aG sudo "$user" || true
fi
install -d -m 700 -o "$user" -g "$DEFAULT_GROUP" "$sdir"
if [[ ! -f "$pubk" ]]; then
sudo -u "$user" ssh-keygen -t rsa -b 4096 -f "$prik" -N '' >/dev/null
fi
touch "$auth" && chown "$user:$DEFAULT_GROUP" "$auth" && chmod 600 "$auth"
grep -q -F "$(cat "$pubk")" "$auth" || cat "$pubk" >> "$auth"
}
distribute_pubkey_to_all() {
local user="$1" pubk sdir auth
pubk="$(pub_key "$user")"; sdir="$(ssh_dir "$user")"; auth="$(auth_keys "$user")"
for n in "${hosts[@]}"; do
ensure_group_remote "$n" "$DEFAULT_GROUP"
run_remote "$n" "
id -u $user >/dev/null 2>&1 || {
adduser --disabled-password --gecos '' --ingroup '$DEFAULT_GROUP' $user
echo '${user}:${user}' | chpasswd
usermod -aG sudo $user
}
"
copy_to_remote "$pubk" "$n" "/tmp/${user}_id.pub"
run_remote "$n" "
install -d -m 700 -o ${user} -g ${DEFAULT_GROUP} ${sdir};
touch ${auth};
chown ${user}:${DEFAULT_GROUP} ${auth};
chmod 600 ${auth};
grep -q -F \"\$(cat /tmp/${user}_id.pub)\" ${auth} || cat /tmp/${user}_id.pub >> ${auth};
rm -f /tmp/${user}_id.pub
"
done
}
distribute_private_key_to_others() {
local user="$1" prik sdir
prik="$(pri_key "$user")"; sdir="$(ssh_dir "$user")"
for n in "${hosts[@]}"; do
[[ "$n" == "$LOCAL_NODE" ]] && continue
ensure_group_remote "$n" "$DEFAULT_GROUP"
run_remote "$n" "install -d -m 700 -o ${user} -g ${DEFAULT_GROUP} ${sdir}"
copy_to_remote "$prik" "$n" "$prik"
run_remote "$n" "chown ${user}:${DEFAULT_GROUP} ${prik} && chmod 600 ${prik}"
done
}
cmd_create() {
local user="${1:-$DEFAULT_USER}"
echo "[STEP] 创建用户及免密配置 -> $user"
create_user_and_keys_local "$user"
distribute_pubkey_to_all "$user"
distribute_private_key_to_others "$user"
echo "[OK] 用户 $user 创建完成,密码=$user,主组=$DEFAULT_GROUP,已加入sudo"
}
cmd_status() {
local user="${1:-$DEFAULT_USER}"
for n in "${hosts[@]}"; do
echo "---- $n ----"
run_remote "$n" "
if id -u $user >/dev/null 2>&1; then
echo '存在'; id -nG $user | grep -q sudo && echo '具备sudo权限' || echo '无sudo权限'
else
echo '不存在'
fi
"
done
}
cmd_rotate() {
local user="${1:-$DEFAULT_USER}" prik pubk auth sdir
prik="$(pri_key "$user")"; pubk="$(pub_key "$user")"; auth="$(auth_keys "$user")"; sdir="$(ssh_dir "$user")"
sudo -u "$user" ssh-keygen -t rsa -b 4096 -f "$prik" -N '' -q
: > "$auth" && cat "$pubk" >> "$auth"
chown "$user:$DEFAULT_GROUP" "$auth"; chmod 600 "$auth"
for n in "${hosts[@]}"; do
ensure_group_remote "$n" "$DEFAULT_GROUP"
copy_to_remote "$pubk" "$n" "/tmp/${user}.pub"
run_remote "$n" "cat /tmp/${user}.pub > ${auth}; rm -f /tmp/${user}.pub"
copy_to_remote "$prik" "$n" "$prik"
done
echo "[OK] 密钥轮换完成"
}
cmd_delete() {
local user="${1:-$DEFAULT_USER}" purge="${2:-no}"
for n in "${hosts[@]}"; do
run_remote "$n" "
id -u $user >/dev/null 2>&1 && pkill -u $user || true
[[ '$purge' == '--purge' ]] && userdel -r $user 2>/dev/null || userdel $user 2>/dev/null || true
"
done
echo "[OK] 用户 $user 删除完成"
}
main() {
local cmd="${1:-help}"; shift || true
case "$cmd" in
create) cmd_create "$@";;
status) cmd_status "$@";;
rotate) cmd_rotate "$@";;
delete) cmd_delete "$@";;
-h|--help|help|"") usage;;
*) die "未知子命令 $cmd";;
esac
}
main "$@"
bash
chmod 755 /usr/local/bin/cluster_user_ssh
xsync /usr/local/bin/cluster_user_ssh
xcall "cluster_user_ssh -h | sed -n '1,20p'"
bash
# 创建 bigdata 用户(密码=bigdata,主组=bigdata,已在sudo组)
cluster_user_ssh create
# 查看状态
cluster_user_ssh status bigdata
# 轮换密钥
# cluster_user_ssh rotate bigdata
# 删除用户
# cluster_user_ssh delete bigdata --purge
# 任意节点互登验证
su - bigdata
# ssh node2现在普通用户 bigdata 也可以无缝 ssh 了,至于 termius 的普通用户登录则需要和 root 类似
密钥:通过下载服务器节点中的密钥文件/home/<username>/.ssh/id_rsa 并上传到shell工具中即可。
ssh直接从root那复制过来,改用户名为bigdata,密钥为刚才上传并新建的那个即可。
以后都默认用bigdata用户登录。
用 trash 不用 rm
rm 会导致删文件后无法恢复,所以我们用 trash
连上三台机子第一件事先下载trash工具,每个机子都要下载,以后的工作尽量用trash来代替rm
bash
sudo xcall apt update
sudo xcall apt install trash-cli
# trash-put 把文件或目录移动到回收站
# trash-empty 清空回收站
# trash-list 列出回收站文件
# trash-restore 恢复回收站文件
# trash-rm 删除回收站文件换源工具 chsrc
bash
xcall wget https://gitee.com/RubyMetric/chsrc/releases/download/pre/chsrc_latest-1_amd64.deb
sudo xcall apt update
sudo xcall apt install ./chsrc_latest-1_amd64.deb
xcall trash-put chsrc_latest-1_amd64.deb目录工具tree
bash
sudo xcall apt update
sudo xcall apt install tree通用组件
记得确保是在bigdata用户下,后面一直默认bigdata用户
bash
# 若不在则切换
# su - bigdata先准备好目录
bash
sudo xcall trash-put /work
sudo xcall "sudo mkdir -p /work/{job,data,server,temp,conf,pkg,back} && sudo chown -R bigdata:bigdata /work && sudo chmod -R 775 /work"
xcall "ls -ld /work /work/*"
xcall tree -p /work
cd /workMysql
安装
bash
# 1. 更新系统软件包索引
sudo apt update
# 2. 安装 MySQL 服务器(会自动拉取最新可用版本)
sudo apt install -y mysql-server
# 3. 启动并设置开机自启
sudo systemctl enable --now mysql
# 4. 检查 MySQL 状态
sudo systemctl status mysql
# MySQL 提供的安全初始化向导
sudo mysql_secure_installation执行后会有几个步骤(推荐除了密码等级选0,其他皆为Y):
- 设置 root 密码等级→ 0
- 移除匿名用户 → Y
- 禁止 root 远程登录 → Y(我们会用新用户)
- 删除 test 数据库 → Y
- 重新加载权限 → Y
修改监听配置
编辑
bash
sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf修改(允许来自任意 IP 的连接请求)
bash
bind-address = 0.0.0.0重启:
bash
sudo systemctl restart mysql监听放开不等于谁都能连,真正能登录的账号还需要授权。
root 没有远程授权时,即使能到端口也会被拒绝。
新建bigdata用户
bash
sudo mysql -u root -p若提示输入密码,直接回车就行
sql
-- 确保没有同名账号
DROP USER IF EXISTS 'bigdata'@'%';
-- 创建 bigdata 账号并设置密码
CREATE USER 'bigdata'@'%' IDENTIFIED BY 'BigData@888';
-- 授予全局所有权限,包括未来创建的数据库
GRANT ALL PRIVILEGES ON *.* TO 'bigdata'@'%' WITH GRANT OPTION;
-- 立即生效
FLUSH PRIVILEGES;
-- 验证
SELECT user, host, select_priv, insert_priv, update_priv, delete_priv, create_priv, grant_priv
FROM mysql.user
WHERE user='bigdata';miniconda
下载 Miniconda 脚本
bash
mkdir -p /work/server/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh \
-O /work/server/miniconda3/miniconda.sh执行安装
bash
bash /work/server/miniconda3/miniconda.sh -b -u -p /work/server/miniconda3删除安装脚本
bash
trash-put /work/server/miniconda3/miniconda.sh初始化环境
bash
source /work/server/miniconda3/bin/activate
conda init --all换源(推荐一个chsrc)
bash
chsrc set anaconda然后按提示操作
验证一下
bash
conda config --show-sources新建环境
bash
conda create -n bigdata python=3.9 -y
conda activate bigdata
python -Vjdk
首先参考关于Hadoop对jdk的兼容 Hadoop官方说明
还需要参考Hive的兼容要求 Hive官方说明
优先使用jdk8,jdk11可以留着备用,若需切换直接ln -sfnv即可。
(推荐)jdk8官网下载链接,下载 jdk-8u461-linux-x64.tar.gz,然后用sftp的方式上传到/work/pkg目录下
bash
# 解压
tar -zxvf /work/pkg/jdk-8u461-linux-x64.tar.gz -C /work/server/
# 软链(-s 软链,-f 覆盖,-n 当目标是软链名时按普通文件对待,-v 显示详细过程)
ln -sfnv /work/server/jdk1.8.0_461 /work/server/jdk
# 分发
xsync /work/server/jdk /work/server/jdk1.8.0_461/(可选)jdk11官网下载链接,下载 jdk-11.0.28_linux-x64_bin.tar.gz ,然后用sftp的方式上传到/work/pkg目录下
bash
# 解压
tar -zxvf /work/pkg/jdk-11.0.28_linux-x64_bin.tar.gz -C /work/server/
# 软链(-s 软链,-f 覆盖,-n 当目标是软链名时按普通文件对待,-v 显示详细过程)
ln -sfnv /work/server/jdk-11.0.28 /work/server/jdk
# 分发
xsync /work/server/jdk /work/server/jdk-11.0.28/配置环境变量
bash
sudo vim /etc/profile加入下面代码
bash
export JAVA_HOME=/work/server/jdk
export PATH=$PATH:$JAVA_HOME/bin保存退出,也分发一下
bash
sudo xsync /etc/profile每个节点都要
bash
xcall source /etc/profile
xcall java -version && javac -version
# 若有自带的java,记得删除,一般在/usr/bin/java
# 若有异常,就试试重开shell会话窗口Docker
先清理
bash
# 停止服务(容错)
sudo systemctl stop docker 2>/dev/null || true
sudo systemctl stop containerd 2>/dev/null || true
sudo systemctl stop docker.socket 2>/dev/null || true
sudo systemctl stop docker-desktop 2>/dev/null || true
sudo systemctl disable docker-desktop 2>/dev/null || true
# 你机器上当前仍安装的包(来自你的输出)------逐个彻底清除
sudo apt-get remove --purge -y \
docker-ce docker-ce-cli docker-ce-rootless-extras \
docker-buildx-plugin docker-compose-plugin \
containerd.io
# 防止遗漏:把残留配置(dpkg 状态为 rc)也清掉
sudo dpkg -l | awk '/^rc/ && ($2 ~ /(docker|containerd|runc)/){print $2}' | xargs -r sudo dpkg -P
# 删除 Desktop 残留(幂等)
sudo rm -rf \
/usr/local/bin/com.docker.cli \
/usr/local/bin/docker-desktop \
/usr/share/applications/docker-desktop.desktop \
/usr/share/docker-desktop \
/opt/docker-desktop \
/var/lib/docker-desktop \
/var/lib/docker-desktop-data \
~/.docker/desktop-data ~/.docker/desktop ~/.docker/pki
#(已做过也可再来一次)清空 Engine/运行时数据(会删镜像/容器)
sudo rm -rf /var/lib/docker /var/lib/containerd
# 清理遗留套接字与 APT 仓库/密钥
sudo rm -f /var/run/docker.sock
sudo rm -f /etc/apt/sources.list.d/docker.list
sudo rm -f /etc/apt/keyrings/docker.gpg /etc/apt/keyrings/docker.asc
# 系统清理
sudo apt-get autoremove -y
sudo apt-get clean
sudo systemctl daemon-reload验证一下是否清理干净
bash
echo "== 包检查(无输出则干净) =="
dpkg -l | egrep '(^ii\s+)?(docker|containerd|runc)' || echo "OK: 未发现 docker/containerd/runc 包"
echo "== 目录检查 =="
for p in /var/lib/docker /var/lib/containerd /opt/docker-desktop /var/lib/docker-desktop /var/lib/docker-desktop-data; do
if [ -e "$p" ]; then echo "仍存在: $p"; else echo "OK: 不存在 $p"; fi
done
echo "== 套接字检查 =="
[ -S /var/run/docker.sock ] && echo "仍存在 /var/run/docker.sock(异常)" || echo "OK: /var/run/docker.sock 不存在"安装(Engine+Compose、镜像加速、权限与一次性验证)
bash
# 1) 依赖与 keyring 目录
sudo apt-get update
sudo apt-get install -y ca-certificates curl gnupg lsb-release
sudo install -m 0755 -d /etc/apt/keyrings
# 2) 导入 GPG(双源回退:阿里云→官方)
( curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg \
|| curl -fsSL https://download.docker.com/linux/ubuntu/gpg ) \
| sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg
# 3) APT 源(阿里云;若需官方改成 https://download.docker.com/linux/ubuntu)
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] \
https://mirrors.aliyun.com/docker-ce/linux/ubuntu \
$(. /etc/os-release && echo ${UBUNTU_CODENAME:-$VERSION_CODENAME}) stable" \
| sudo tee /etc/apt/sources.list.d/docker.list >/dev/null
# 4) 安装 Engine + CLI + Buildx + Compose
sudo apt-get update
sudo apt-get install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
# 5) 启动并设为开机自启
sudo systemctl enable --now docker
# 6) 账户与权限(确保 docker 组、加入当前用户、校正 socket)
sudo groupadd -f docker
sudo usermod -aG docker "$USER"
if [ -S /var/run/docker.sock ]; then
sudo chown root:docker /var/run/docker.sock
sudo chmod 660 /var/run/docker.sock
fi
# 7) 守护进程配置与镜像加速(阿里云 + DaoCloud + Docker CN)
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json >/dev/null <<'JSON'
{
"registry-mirrors": [
"https://mirror.aliyun.com",
"https://docker.m.daocloud.io",
"https://registry.docker-cn.com"
],
"log-driver": "json-file",
"log-opts": { "max-size": "20m", "max-file": "3" },
"exec-opts": ["native.cgroupdriver=systemd"]
}
JSON
sudo systemctl daemon-reload
sudo systemctl restart docker
# 8) docker-compose 兼容修复(老脚本支持)
sudo apt-get install -y docker-compose-plugin
if [ -x /usr/libexec/docker/cli-plugins/docker-compose ]; then
sudo ln -sf /usr/libexec/docker/cli-plugins/docker-compose /usr/bin/docker-compose
elif [ -x /usr/lib/docker/cli-plugins/docker-compose ]; then
sudo ln -sf /usr/lib/docker/cli-plugins/docker-compose /usr/bin/docker-compose
else
CAND=$(dpkg -L docker-compose-plugin 2>/dev/null | grep 'cli-plugins/docker-compose$' | head -n1)
[ -n "$CAND" ] && sudo ln -sf "$CAND" /usr/bin/docker-compose
fi
sudo chmod +x /usr/bin/docker-compose
echo "== Docker Compose 兼容性检测 =="
docker compose version
/usr/bin/docker-compose version
# 9) 一次性验证(在 docker 组上下文中执行,避免当前会话未刷新组权限)
sg docker -c '
echo "== 组上下文验证 =="
id; groups; echo
echo "== Docker 版本 =="
docker --version; containerd --version; echo
echo "== Hello World 测试 =="
docker run --rm hello-world; echo
echo "== Registry Mirrors =="
docker info | grep -A3 "Registry Mirrors" || true; echo
echo "== BusyBox 测试 =="
docker run --rm busybox:latest echo docker-ok
'DataEase
下载 dataease-offline-installer-v2.10.14-ce.tar.gz ,然后用sftp的方式上传到 /work/pkg 目录下
bash
cd /work
# 解压
tar -zxvf /work/pkg/dataease-offline-installer-v2.10.14-ce.tar.gz -C /work/server/
cd /work/server/dataease-offline-installer-v2.10.14-ce/我们不用 dataease 内建数据库,而是使用阿里云rds作为外部数据库。
好处是即使部署的服务器炸了,也不怕看板数据丢失,因为我们所做的看板保留在rds,和服务器集群是隔离的,我们只需要重新部署下,然后连接上rds就可以无缝使用之前的看板。
先确认参数设置有没有问题,重点是三个参数
bash
character_set_server=utf8
lower_case_table_names=1
group_concat_max_len=1024000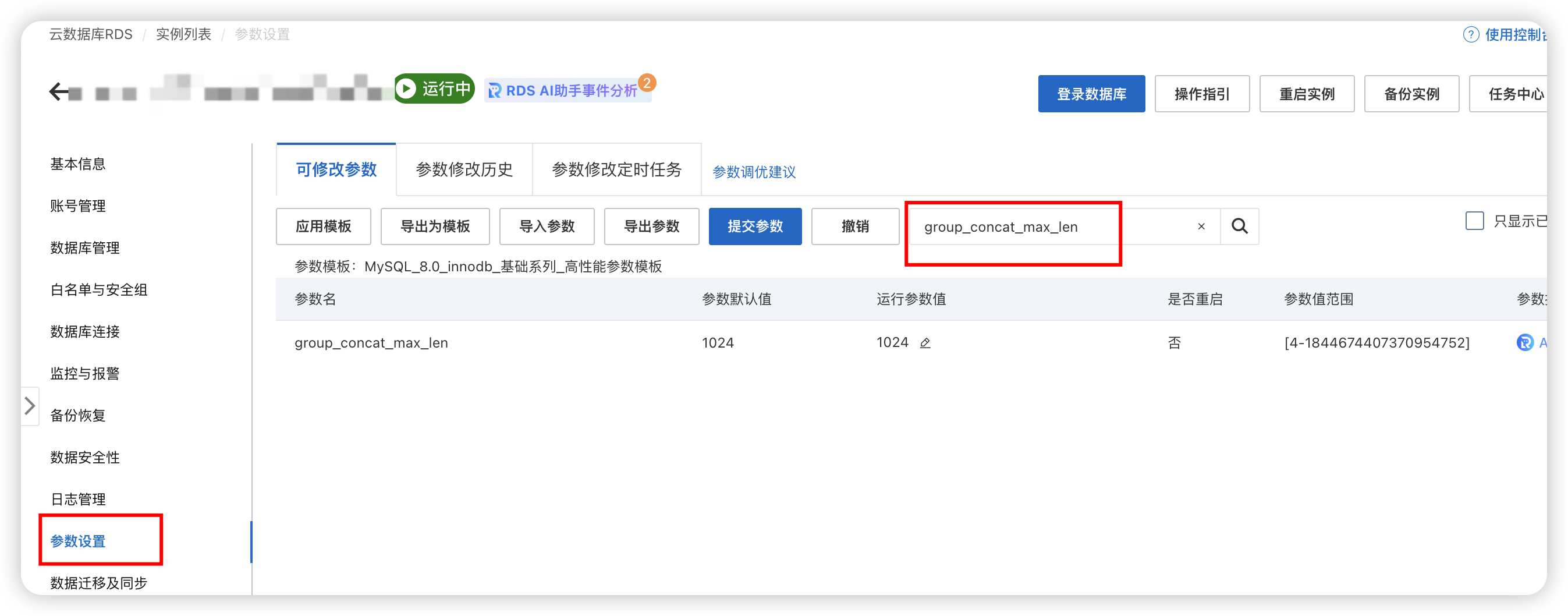
然后创建数据库 dataease
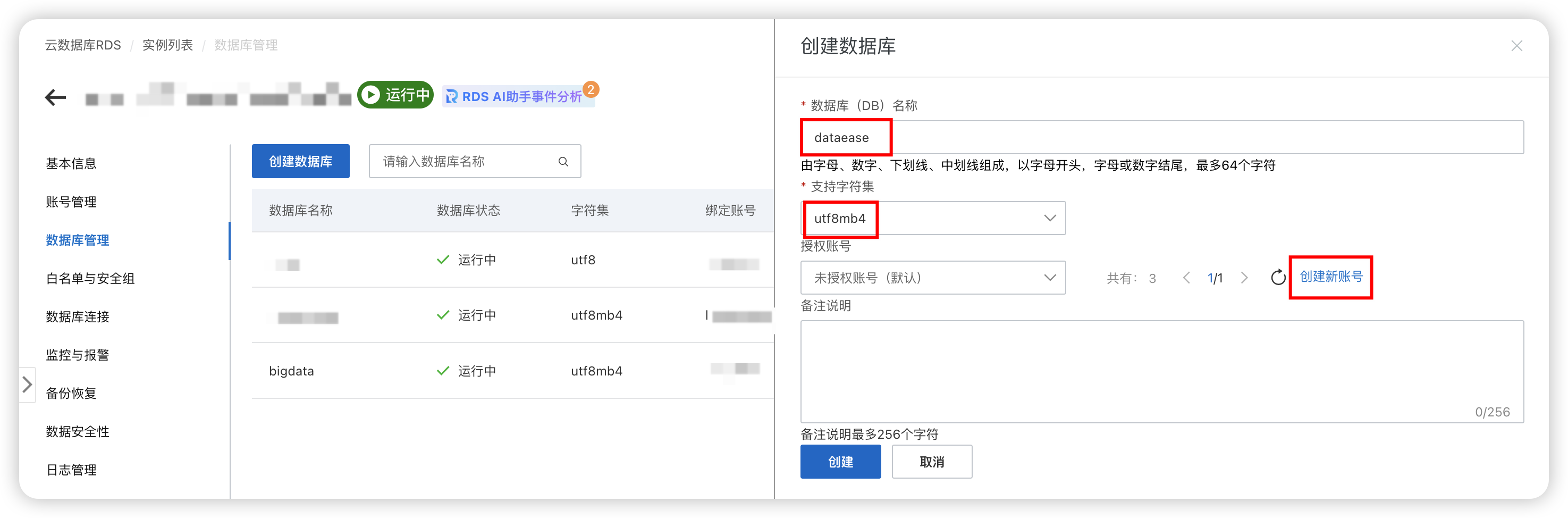
确认字符集的设置
sql
USE dataease;
SELECT DATABASE() AS db,
@@character_set_database AS db_charset,
@@collation_database AS db_collation;
-- 若不是mb4,则修改为utf8mb4
# ALTER DATABASE dataease
# CHARACTER SET utf8mb4
# COLLATE utf8mb4_0900_ai_ci; -- 5.7 改为 utf8mb4_unicode_ci修改配置文件
bash
vim /work/server/dataease-offline-installer-v2.10.14-ce/install.conf需要修改的地方
bash
## 安装目录
DE_BASE=/work/server
## 是否使用外部数据库
DE_EXTERNAL_MYSQL=true
## 数据库地址
DE_MYSQL_HOST=[你的rds地址]
## 数据库用户名
DE_MYSQL_USER=bigdata
## 数据库密码,密码如包含特殊字符,请用双引号引起来,例如 DE_MYSQL_PASSWORD="Test@4&^%*^"
DE_MYSQL_PASSWORD=[密码]安装
bash
sudo /bin/bash /work/server/dataease-offline-installer-v2.10.14-ce/install.sh若失败了,多重试几次,重试前请先清理docker中的内容
bash
# 1. 停止并删除所有 dataease 容器
sudo docker ps -a | grep dataease
sudo docker rm -f dataease || true
# 2. 删除 dataease 相关镜像(可选,如果想强制重新拉取镜像)
sudo docker images | grep dataease
sudo docker rmi registry.cn-qingdao.aliyuncs.com/dataease/dataease:v2.10.14 || true
# 3. 删除 dataease 运行目录(注意:这里是容器内映射到宿主的目录)
sudo rm -rf /work/server/dataease2.0
# 4. 删除安装缓存和命令行工具(可选)
sudo rm -f /usr/local/bin/dectl /usr/bin/dectl安装成功后,通过浏览器访问如下页面登录:
- 访问地址 : http://目标服务器IP地址:服务运行端口
- 登录用户名: admin
- 登录密码: DataEase@123456
大数据组件
Hadoop
因为Hive那边要求 Hive官方说明
- Java 8
- Hadoop 3.3.6
所以我们选择 Hadoop 3.3.6 版本 下载链接 (其他版本选择)
官网下载 hadoop-3.3.6.tar.gz 后,然后用sftp的方式上传(拖拽)到 /work/pkg 目录下
bash
# 解压
tar -zxvf /work/pkg/hadoop-3.3.6.tar.gz -C /work/server/
# 软链
ln -sfnv /work/server/hadoop-3.3.6 /work/server/hadoop
cd /work/server/hadoop
llHDFS
配置文件
配置HDFS集群,我们主要涉及到如下文件的修改:
workers:配置从节点(DataNode)有哪些
hadoop-env.sh:配置Hadoop的相关环境变量
core-site.xml:Hadoop核心配置文件
hdfs-site.xml:HDFS核心配置文件
这些文件均存在与$HADOOP_HOME/etc/hadoop文件夹中。
PS:$HADOOP_HOME是后续我们要设置的环境变量,其指代Hadoop安装文件夹即 /work/server/hadoop
workers
bash
cd /work/server/hadoop/etc/hadoop/
vim /work/server/hadoop/etc/hadoop/workers删除第一行的localhost,添加下面代码
bash
node1
node2
node3hadoop-env.sh
bash
vim /work/server/hadoop/etc/hadoop/hadoop-env.sh在顶部添加下面代码
bash
# ====== 基础路径======
export JAVA_HOME=/work/server/jdk # JDK 安装目录
export HADOOP_HOME=/work/server/hadoop # Hadoop 根目录
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop # Hadoop 配置目录
export HADOOP_LOG_DIR=$HADOOP_HOME/logs # Hadoop 日志目录(确保可写)core-site.xml
bash
vim /work/server/hadoop/etc/hadoop/core-site.xml替换
xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--
fs.defaultFS
指定 Hadoop 文件系统的默认 URI
格式:schema://host:port
例如 hdfs://node1:8020 表示 HDFS 集群,NameNode 在 node1 主机上,RPC 端口为 8020
注意:这里的主机名必须能被集群所有节点解析
-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<!--
io.file.buffer.size
Hadoop 读写文件时使用的缓冲区大小(单位:字节)
默认值为 4096,这里设置为 131072(128KB)以提升大文件的读写效率
值过大可能导致小文件场景下内存浪费
-->
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!-- Hadoop临时文件目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/work/data/hadoop/tmp</value>
<description>Hadoop临时文件目录</description>
</property>
<!-- hive所需要的设置
hadoop.proxyuser.<用户名>.hosts
hadoop.proxyuser.<用户名>.groups
-->
<!-- 允许 bigdata 用户代理访问的主机列表 -->
<property>
<name>hadoop.proxyuser.bigdata.hosts</name>
<value>*</value>
</property>
<!-- 允许 bigdata 用户代理访问的用户组 -->
<property>
<name>hadoop.proxyuser.bigdata.groups</name>
<value>*</value>
</property>
</configuration>hdfs-site.xml
bash
vim /work/server/hadoop/etc/hadoop/hdfs-site.xml替换
xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- DataNode 存储目录的权限设置,700 表示仅属主可读写执行 -->
<property>
<name>dfs.datanode.data.dir.perms</name>
<value>700</value>
</property>
<!-- NameNode 元数据存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/work/data/hadoop/nn</value>
</property>
<!-- 允许连接到 NameNode 的主机列表 -->
<property>
<name>dfs.namenode.hosts</name>
<value>node1,node2,node3</value>
</property>
<!-- HDFS 块大小(单位:字节),此处为 256MB -->
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<!-- NameNode 处理请求的线程数量 -->
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<!-- DataNode 存储数据块的目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/work/data/hadoop/dn</value>
</property>
</configuration>准备hdfs的数据目录
bash
xcall "mkdir -p /work/data/hadoop/{nn,dn,tmp} && ls -ld /work/data/hadoop /work/data/hadoop/{nn,dn,tmp}"分发和环境变量
把hadoop包分发下(首次,必须分发包,后面配置改动可以只分发配置文件)
bash
xsync /work/server/hadoop /work/server/hadoop-3.3.6/
xcall ls -l /work/server/hadoop/设置下系统环境变量,把hadoop添加进去
bash
sudo vim /etc/profile在底部追加
bash
export HADOOP_HOME=/work/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin然后分发下
bash
sudo xsync /etc/profilesource 一下
bash
xcall source /etc/profile验证一下
bash
xcall hadoop version格式化并启动
bash
hadoop namenode -format
# 如只有主节点启动namenode
# xcall trash-put /work/data/hadoop/dn/*平时在部署中有什么问题需要重置集群,先格式化,然后每个节点删除/data/dn/*。
若没有问题,一般情况下只有第一次部署时才需要初始化。
若要更新配置,只需分发配置文件然后重启服务即可。
bash
# 一键启动
start-dfs.sh
# 查看进程
xcall jps
# 一键关闭
stop-dfs.sh启动后webui(http://node1的公网IP:9870)可用,且查看进程应该有如下进程
========== node1 ==========
598984 Jps
598351 NameNode
598499 DataNode
598834 SecondaryNameNode
========== node2 ==========
53606 Jps
53480 DataNode
========== node3 ==========
53974 Jps
53848 DataNode
YARN
配置文件
mapred-env.sh
bash
vim /work/server/hadoop/etc/hadoop/mapred-env.sh顶部添加
bash
# ====== 基础路径 / 日志 ======
export JAVA_HOME=/work/server/jdk
# JobHistoryServer 堆大小(单位 MB)
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000mapred-site.xml
bash
vim /work/server/hadoop/etc/hadoop/mapred-site.xml替换
xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- MapReduce 的运行框架设置为 YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>MapReduce 的运行框架设置为 YARN</description>
</property>
<!-- 历史服务器 RPC 地址(JobHistory Server) -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
<description>历史服务器 RPC 监听地址</description>
</property>
<!-- 历史服务器 Web UI 地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
<description>历史服务器 Web 端口</description>
</property>
<!-- 历史信息在 HDFS 的记录临时路径(注意是 HDFS 路径) -->
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/data/mr-history/tmp</value>
<description>JobHistory 中间结果在 HDFS 的路径</description>
</property>
<!-- 历史信息在 HDFS 的记录完成路径(注意是 HDFS 路径) -->
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/data/mr-history/done</value>
<description>JobHistory 完成结果在 HDFS 的路径</description>
</property>
<!-- ApplicationMaster 环境变量:指定 MapReduce 的 HOME -->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- Map/Reduce 任务环境变量:指定 MapReduce 的 HOME -->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!--
设置 MapReduce 程序在 YARN 容器中运行时的类路径(classpath)
作用:
1. 告诉容器在哪里加载 MapReduce 所需的 jar 包;
2. $HADOOP_CLASSPATH 用于加载自定义依赖(如 JDBC 或外部 jar);
3. 其余两个路径为 Hadoop 自带的 MapReduce 主库和依赖库目录。
-->
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_CLASSPATH:$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*</value>
<description>MapReduce 运行所需的类路径</description>
</property>
</configuration>yarn-env.sh
bash
vim /work/server/hadoop/etc/hadoop/yarn-env.sh顶部添加
bash
# ====== 基础路径 ======
export JAVA_HOME=/work/server/jdk
export HADOOP_HOME=/work/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logsyarn-site.xml
bash
vim /work/server/hadoop/etc/hadoop/yarn-site.xml替换
xml
<?xml version="1.0"?>
<configuration>
<!-- ResourceManager 设置在 node1 节点 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
<description>ResourceManager 主机名</description>
</property>
<!-- NodeManager 中间数据本地存储路径 -->
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/work/data/hadoop/nm-local</value>
<description>NodeManager 中间数据本地存储路径</description>
</property>
<!-- NodeManager 日志本地存储路径 -->
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/work/data/hadoop/nm-log</value>
<description>NodeManager 数据日志本地存储路径</description>
</property>
<!-- 为 MapReduce 程序开启 Shuffle 服务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>为 MapReduce 程序开启 Shuffle 服务</description>
</property>
<!-- 历史服务器日志访问 URL -->
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
<description>历史服务器日志访问 URL</description>
</property>
<!-- Web 代理服务主机和端口 -->
<property>
<name>yarn.web-proxy.address</name>
<value>node1:8089</value>
<description>Web 代理服务主机和端口</description>
</property>
<!-- 开启日志聚合 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>开启日志聚合功能</description>
</property>
<!-- 程序日志在 HDFS 的存储路径 -->
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
<description>程序运行日志在 HDFS 的存储路径</description>
</property>
<!-- 使用公平调度器 -->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
<description>选择公平调度器(Fair Scheduler)</description>
</property>
<!-- ===== 下面为hive官方建议的新增配置 ===== -->
<!-- NodeManager 容器可见环境变量白名单 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
<description>允许透传到容器内的环境变量白名单</description>
</property>
<!-- 每台 NodeManager 可用物理内存(MB) -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
<description>单节点 YARN 可分配的物理内存上限,单位 MB</description>
</property>
<!-- 单个容器的最小内存分配(MB) -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
<description>调度器最小分配粒度:容器最小内存,单位 MB</description>
</property>
<!-- 虚拟内存与物理内存比值上限 -->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
<description>容器 vmem 与 pmem 的比值上限,超限将被杀掉</description>
</property>
<!--修复日志绑定冲突,当 Hive 提交 MapReduce 作业时,让用户的 jar(Hive 的 lib)优先于 Hadoop 自身的类路径,避免重复绑定冲突。-->
<property>
<name>mapreduce.job.user.classpath.first</name>
<value>true</value>
</property>
</configuration>分发配置并启动
bash
xsync /work/server/hadoop/etc/hadoop/
bash
# 启动yarn
start-yarn.sh
# 停止yarn
stop-yarn.sh
# hdfs 和 yarn 一起启动
start-all.sh
# hdfs 和 yarn 一起停止
stop-all.sh
# 启动history
mapred --daemon start historyserver
# 停止history
mapred --daemon stop historyserver
xcall jps启动后YARN webui(http://node1的公网IP:8088)和 JobHistory webui(http://node1的公网IP:19888)可用,且查看进程应该有如下进程
bigdata@node1:/work/server/hadoop/etc/hadoop$ xcall jps
========== node1 ==========
714702 SecondaryNameNode
715454 ResourceManager
716140 JobHistoryServer
714365 DataNode
715616 NodeManager
716215 Jps
714215 NameNode
716053 WebAppProxyServer
========== node2 ==========
59857 NodeManager
59462 DataNode
60024 Jps
========== node3 ==========
59748 NodeManager
59350 DataNode
59915 Jps
备份配置文件
bash
# 先确保目标目录存在
mkdir -p /work/back/hadoop
# 打包并保留原文件
tar -czvf /work/back/hadoop/hadoop_conf_$(date +%F).tar.gz -C /work/server/hadoop/etc/hadoop .
ls /work/back/hadoop/测试
bash
# 在 HDFS 上创建输入数据
hdfs dfs -mkdir -p /data/yarn_test/input
echo "hello yarn test job" > /tmp/yarn_test.txt
hdfs dfs -put -f /tmp/yarn_test.txt /data/yarn_test/input/
# 提交 MapReduce 任务到 YARN
yarn jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount \
/data/yarn_test/input /data/yarn_test/output_$(date +%F_%H%M%S)
# 查看结果
hdfs dfs -cat /data/yarn_test/output_*/part-r-00000
# 删除测试文件
hdfs dfs -rm -r -f /data/yarn_testHive
元数据库
bash
mysql -h node1 -ubigdata -pBigData@888若提示输入密码,直接回车就行
sql
-- 如果已存在旧库,先删除
DROP DATABASE IF EXISTS hive;
-- 重新创建 Hive 元数据库
CREATE DATABASE hive
DEFAULT CHARACTER SET utf8mb4
COLLATE utf8mb4_general_ci;
EXIT;下载
因为 Hive的GitHub主页 写明了和jdk版本的兼容,所以我们选择4.0.1版本。
| Hive 版本 | Java 版本 |
|---|---|
| Hive 4.0.1 | Java 8 |
| Hive 4.1.x | Java 17 |
| Hive 4.2.x | Java 21 |
官网 下载 apache-hive-4.0.1-bin.tar.gz
检查 Hive 的前置要求 Hive官方说明
- Java 8
- Maven 3.6.3 (我们不编译,所以不用管)
- Protobuf 2.5(我们不编译,所以不用管)
- Hadoop 3.3.6(作为准备,以单节点集群、伪分布式模式进行配置)
下载 apache-hive-4.0.1-bin.tar.gz 后,然后用sftp的方式上传(拖拽)到 /work/pkg 目录下
bash
cd /work/server
# 解压
tar -zxvf /work/pkg/apache-hive-4.0.1-bin.tar.gz -C /work/server/
# 软链
ln -sfnv /work/server/apache-hive-4.0.1-bin /work/server/hive
cd /work/server/hive
llmysql driver 包
bash
# 下载
wget -P /work/server/hive/lib/ https://repo1.maven.org/maven2/com/mysql/mysql-connector-j/8.0.33/mysql-connector-j-8.0.33.jar
# 确认,>1m即成功
ls -lh /work/server/hive/lib/mysql-connector-j-8.0.33.jar配置文件
hive-env.sh
bash
cp /work/server/hive/conf/hive-env.sh.template /work/server/hive/conf/hive-env.sh
ll /work/server/hive/conf/
vim /work/server/hive/conf/hive-env.sh顶部添加
bash
# Hadoop 根路径
export HADOOP_HOME=/work/server/hadoop
# Hive 根路径(建议加上,后面引用更清晰)
export HIVE_HOME=/work/server/hive
# Hive 配置目录
export HIVE_CONF_DIR=${HIVE_HOME}/conf
# Hive 的额外依赖 JAR 搜索路径(用于放置 MySQL 驱动等第三方 JAR)
export HIVE_AUX_JARS_PATH=${HIVE_HOME}/lib
# 增大 HS2 堆
export HIVESERVER2_HEAPSIZE=4096
export HADOOP_HEAPSIZE=4096hive-site.xml
bash
vim /work/server/hive/conf/hive-site.xml添加如下内容
xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- Hive Metastore 使用的 JDBC 连接 URL(MySQL 8.x) -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node1:3306/hive?createDatabaseIfNotExist=true&useSSL=false&allowPublicKeyRetrieval=true&useUnicode=true&charsetEncoding=UTF-8&serverTimezone=Asia/Shanghai</value>
<description>Hive Metastore 连接 MySQL 的 JDBC URL;允许自动建库,关闭 SSL,设置时区与字符集</description>
</property>
<!-- MySQL 8.x 驱动类(8.x 必须使用 com.mysql.cj.jdbc.Driver) -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>MySQL Connector/J 8.0.x 对应的 JDBC 驱动类</description>
</property>
<!-- 数据库用户名 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>bigdata</value>
<description>Metastore 数据库用户名</description>
</property>
<!-- 数据库密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>BigData@888</value>
<description>Metastore 数据库密码</description>
</property>
<!-- HiveServer2 绑定主机(可按需修改为具体主机名或 0.0.0.0) -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node1</value>
<description>HiveServer2 绑定主机名</description>
</property>
<!-- Hive Metastore Thrift 服务地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1:9083</value>
<description>Metastore 对外提供的 Thrift 服务地址</description>
</property>
<!-- 事件通知 API 鉴权(很多入门/实验环境会先关闭) -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
<description>是否开启 Metastore 事件通知 API 的鉴权</description>
</property>
<!-- Hive 执行引擎 -->
<property>
<name>hive.execution.engine</name>
<value>mr</value>
<description>
指定 Hive 的计算引擎;
可选值:mr(MapReduce)、tez、spark;
此处设为 mr,表示使用 MapReduce 方式执行 Hive SQL。
</description>
</property>
<!-- MapReduce 框架运行模式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>
告诉 Hive 的 MapReduce 引擎使用 YARN 集群进行任务调度;
若设为 local,则任务在本机 JVM 执行;
设为 yarn 表示分布式运行在 YARN 集群上。
</description>
</property>
<!-- Hive 额外依赖 JAR 路径 -->
<property>
<name>hive.aux.jars.path</name>
<value>${HIVE_HOME}/lib</value>
<description>
指定 Hive 运行时可加载的附加 JAR 依赖目录;
通常为 Hive 安装目录下的 lib;
在 YARN 模式下,这些 JAR 会被分发到每个容器中。
</description>
</property>
</configuration>初始化并启动
若改配置了,请先重置下元数据库然后重新初始化并启动
bash
# 创建日志文件夹
mkdir /work/server/hive/logs
# 初始化元数据库
/work/server/hive/bin/schematool -initSchema -dbType mysql -verbose启动
bash
# 停止 metastore
pkill -f 'hive.*metastore' 2>/dev/null || true
# 先启动 metastore 服务
nohup /work/server/hive/bin/hive --service metastore >> /work/server/hive/logs/metastore.log 2>&1 &
# 等待 3~5 秒,确认 9083 在监听
ss -lntp | grep :9083 || tail -n 200 /work/server/hive/logs/metastore.log
# 停止hiveserver2
pkill -f 'hive.*hiveserver2' 2>/dev/null || true
# 然后启动 hiveserver2 服务
nohup /work/server/hive/bin/hive --service hiveserver2 >> /work/server/hive/logs/hiveserver2.log 2>&1 &
# 等待 3~5 秒,确认 10000 在监听
ss -lntp | grep :10000 || tail -n 200 /work/server/hive/logs/hiveserver2.log然后就能用datagrip等工具直接连接了。
想验证的话
bash
ps -ef|grep 【两个runjar的进程号】若需要beeline的方式写sql
bash
/work/server/hive/bin/beeline -u "jdbc:hive2://node1:10000/default" -n bigdata -p ""然后就能show databases;,愉快写sql了。
备份配置文件
bash
# 1. 创建备份目录
mkdir -p /work/back/hive
# 2. 打包备份配置文件(含 hive-site.xml、hive-env.sh、hive-log4j2.properties 等)
tar -czvf /work/back/hive/hive_conf_$(date +%F).tar.gz -C /work/server/hive/conf .
# 3. 列出备份文件
ls -lh /work/back/hive/测试和连接
本地模式
bash
/work/server/hive/bin/beeline -u "jdbc:hive2://node1:10000/default" -n bigdata -p "" \
-e "SET hive.execution.engine=mr; \
SET mapreduce.framework.name=local; \
CREATE DATABASE IF NOT EXISTS test; \
DROP TABLE IF EXISTS test.t1; \
CREATE TABLE test.t1( \
id INT, \
name STRING, \
run_mode STRING, \
run_time STRING, \
run_tag STRING \
); \
INSERT INTO test.t1 \
SELECT 1, 'local_test', 'local', from_unixtime(unix_timestamp()), \
concat('local_', from_unixtime(unix_timestamp(),'yyyyMMddHHmmss')); \
SELECT * FROM test.t1;"yarn模式
bash
/work/server/hive/bin/beeline -u "jdbc:hive2://node1:10000/default" -n bigdata -p "" \
-e "SET hive.execution.engine=mr; \
SET mapreduce.framework.name=yarn; \
CREATE DATABASE IF NOT EXISTS test; \
DROP TABLE IF EXISTS test.t1; \
CREATE TABLE test.t1( \
id INT, \
name STRING, \
run_mode STRING, \
run_time STRING, \
run_tag STRING \
); \
INSERT INTO test.t1 \
SELECT 2, 'yarn_test', 'yarn', from_unixtime(unix_timestamp()), \
concat('yarn_', from_unixtime(unix_timestamp(),'yyyyMMddHHmmss')); \
SELECT * FROM test.t1;"DataGrip
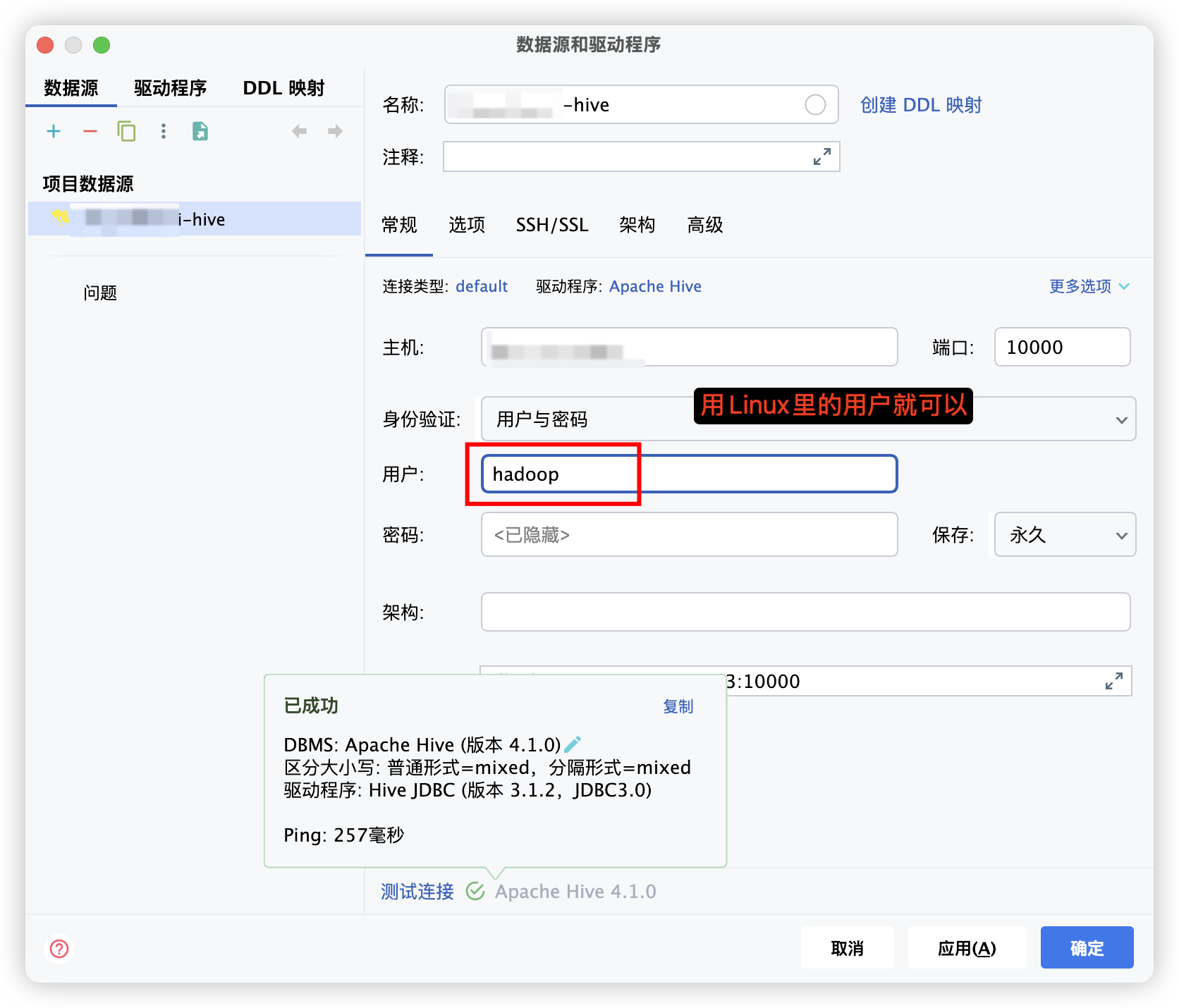
这里用户名其实就是Linux对应的用户,密码可以不用输入测试连接能通过就可以点应用了。
其他组件
SeaTunnel
SeaTunnel
下载
兼容说明
| SeaTunnel Web Version | SeaTunnel Version | Doc |
|---|---|---|
| 1.0.3-SNAPSHOT | 2.3.11 | Docs |
| 1.0.2 | 2.3.8 | Docs |
| 1.0.1 | 2.3.3 | Docs |
| 1.0.0 | 2.3.3 | Docs |
官网下载 apache-seatunnel-2.3.8-bin.tar.gz
然后用sftp的方式上传(拖拽)到 /work/pkg 目录下
bash
cd /work/server
# 解压
tar -zxvf /work/pkg/apache-seatunnel-2.3.8-bin.tar.gz -C /work/server
# 软链
ln -sfnv /work/server/apache-seatunnel-2.3.8 /work/server/seatunnel
cd /work/server/seatunnel
ll环境变量
bash
sudo vim /etc/profile底部添加
bash
export SEATUNNEL_HOME=/work/server/seatunnel
export PATH=$PATH:$SEATUNNEL_HOME/bin保存退出,也分发一下
bash
sudo xsync /etc/profile
xcall source /etc/profile
echo $SEATUNNEL_HOME连接器
bash
# 一定要在/seatunnel下不然脚本执行不了
cd /work/server/seatunnel
sh /work/server/seatunnel/bin/install-plugin.sh需要等待很久,或者参考官网只下载几个想要的。
配置文件
seatunnel.yaml
bash
vim /work/server/seatunnel/config/seatunnel.yaml 替换
bash
seatunnel:
engine:
# IMap 同步备份数:3 节点推荐 1,可容忍 1 台节点故障
backup-count: 1
# 作业与算子指标打印周期(秒),保持适中即可
print-execution-info-interval: 30
print-job-metrics-info-interval: 60
# 队列类型保持默认
queue-type: blockingqueue
# Slot 服务:为容量可控,建议使用静态槽位(每节点 16 个)
slot-service:
dynamic-slot: false
slot-num: 16
# 检查点:5 分钟一次,超时 60 秒;若作业 env 中设置则以作业为准
checkpoint:
interval: 300000
timeout: 60000
storage:
type: hdfs
max-retained: 3
plugin-config:
# ------ 与 Hadoop core-site.xml 的 fs.defaultFS 保持一致 ------
fs.defaultFS: hdfs://node1:8020
storage.type: hdfs
# 建议使用专有目录并确保写权限
namespace: /tmp/seatunnel/checkpoint_snapshot
# 历史作业过期(分钟):默认一天
history-job-expire-minutes: 1440
# 只有在遇到 metaspace 问题时再开启
classloader-cache-mode: false
telemetry:
metric:
enabled: falsehazelcast.yaml
bash
vim /work/server/seatunnel/config/hazelcast.yaml替换
bash
hazelcast:
cluster-name: seatunnel
network:
rest-api:
enabled: true
endpoint-groups:
CLUSTER_WRITE:
enabled: true
DATA:
enabled: true
join:
tcp-ip:
enabled: true
member-list:
- node1
- node2
- node3
port:
auto-increment: false
port: 5801
properties:
# 连接/心跳与日志等基础参数
hazelcast.invocation.max.retry.count: 20
hazelcast.tcp.join.port.try.count: 30
hazelcast.logging.type: log4j2
# 线程与心跳(保持默认或轻微加大均可)
hazelcast.operation.generic.thread.count: 50
hazelcast.heartbeat.failuredetector.type: phi-accrual
hazelcast.heartbeat.interval.seconds: 2
hazelcast.max.no.heartbeat.seconds: 180
hazelcast.heartbeat.phiaccrual.failuredetector.threshold: 10
hazelcast.heartbeat.phiaccrual.failuredetector.sample.size: 200
hazelcast.heartbeat.phiaccrual.failuredetector.min.std.dev.millis: 100
# ------ IMap 持久化(强烈推荐在多节点开启) ------
map:
"engine*":
map-store:
enabled: true
initial-mode: EAGER
factory-class-name: org.apache.seatunnel.engine.server.persistence.FileMapStoreFactory
properties:
# 使用 HDFS 做持久化(与 Hadoop 配置保持一致)
type: hdfs
storage.type: hdfs
# ------ 与 Hadoop core-site.xml 的 fs.defaultFS 保持一致 ------
fs.defaultFS: hdfs://node1:8020
# 业务分隔:不同命名空间互不影响
namespace: /tmp/seatunnel/imap
# 集群隔离名,可自定义;用于区分多套 Engine
clusterName: seatunnel-clusterhazelcast-client.yaml
bash
vim /work/server/seatunnel/config/hazelcast-client.yaml替换
bash
hazelcast-client:
cluster-name: seatunnel
properties:
hazelcast.logging.type: log4j2
connection-strategy:
connection-retry:
cluster-connect-timeout-millis: 3000
network:
# 所有 Engine Server 成员都需要列出(端口与 server 保持一致)
cluster-members:
- node1:5801
- node2:5801
- node3:5801同步外部配置文件
bash
mkdir -p /work/server/seatunnel/externals/hive
mkdir -p /work/server/seatunnel/externals/hadoop
cp -f /work/server/hive/conf/hive-site.xml /work/server/seatunnel/externals/hive/hive-site.xml
cp -f /work/server/hadoop/etc/hadoop/core-site.xml /work/server/seatunnel/externals/hadoop/core-site.xml
cp -f /work/server/hadoop/etc/hadoop/hdfs-site.xml /work/server/seatunnel/externals/hadoop/hdfs-site.xmljar包补全
mysql driver(/plugins/Jdbc/lib)
bash
# 下载 MySQL 8 驱动到 SeaTunnel 的 JDBC 插件目录
wget -P /work/server/seatunnel/plugins/Jdbc/lib/ https://repo1.maven.org/maven2/com/mysql/mysql-connector-j/8.0.33/mysql-connector-j-8.0.33.jar
ls -lh /work/server/seatunnel/plugins/Jdbc/lib/mysql-connector-j-8.0.33.jar其他jar包(/lib)
bash
cd /work/server/seatunnel/lib
# ---------------- Hive3 基础 ----------------
wget -q --show-progress https://repo1.maven.org/maven2/org/apache/hive/hive-exec/3.1.3/hive-exec-3.1.3.jar -O hive-exec-3.1.3.jar
wget -q --show-progress https://repo1.maven.org/maven2/org/apache/hive/hive-storage-api/2.7.1/hive-storage-api-2.7.1.jar -O hive-storage-api-2.7.1.jar
wget -q --show-progress https://repo1.maven.org/maven2/org/apache/thrift/libfb303/0.9.3/libfb303-0.9.3.jar -O libfb303-0.9.3.jar
# ---------------- Parquet 1.12.3 ----------------
wget -q --show-progress https://repo1.maven.org/maven2/org/apache/parquet/parquet-hadoop/1.12.3/parquet-hadoop-1.12.3.jar -O parquet-hadoop-1.12.3.jar
wget -q --show-progress https://repo1.maven.org/maven2/org/apache/parquet/parquet-column/1.12.3/parquet-column-1.12.3.jar -O parquet-column-1.12.3.jar
wget -q --show-progress https://repo1.maven.org/maven2/org/apache/parquet/parquet-encoding/1.12.3/parquet-encoding-1.12.3.jar -O parquet-encoding-1.12.3.jar
wget -q --show-progress https://repo1.maven.org/maven2/org/apache/parquet/parquet-common/1.12.3/parquet-common-1.12.3.jar -O parquet-common-1.12.3.jar
wget -q --show-progress https://repo1.maven.org/maven2/org/apache/parquet/parquet-format-structures/1.12.3/parquet-format-structures-1.12.3.jar -O parquet-format-structures-1.12.3.jar
wget -q --show-progress https://repo1.maven.org/maven2/org/apache/parquet/parquet-format/2.9.0/parquet-format-2.9.0.jar -O parquet-format-2.9.0.jar
# ---------------- 压缩支持 ----------------
wget -q --show-progress https://repo1.maven.org/maven2/org/xerial/snappy/snappy-java/1.1.10.5/snappy-java-1.1.10.5.jar -O snappy-java-1.1.10.5.jar
wget -q --show-progress https://repo1.maven.org/maven2/com/github/luben/zstd-jni/1.5.5-11/zstd-jni-1.5.5-11.jar -O zstd-jni-1.5.5-11.jar
wget -q --show-progress https://repo1.maven.org/maven2/io/airlift/aircompressor/0.21/aircompressor-0.21.jar -O aircompressor-0.21.jar
# ---------------- Http Components ----------------
wget -q --show-progress https://repo1.maven.org/maven2/org/apache/httpcomponents/httpclient/4.5.14/httpclient-4.5.14.jar -O httpclient-4.5.14.jar
wget -q --show-progress https://repo1.maven.org/maven2/org/apache/httpcomponents/httpcore/4.4.16/httpcore-4.4.16.jar -O httpcore-4.4.16.jar
wget -q --show-progress https://repo1.maven.org/maven2/commons-logging/commons-logging/1.2/commons-logging-1.2.jar -O commons-logging-1.2.jar
wget -q --show-progress https://repo1.maven.org/maven2/commons-codec/commons-codec/1.15/commons-codec-1.15.jar -O commons-codec-1.15.jar
# ---------------- MySQL JDBC ----------------
wget -q --show-progress https://repo1.maven.org/maven2/com/mysql/mysql-connector-j/8.0.33/mysql-connector-j-8.0.33.jar -O mysql-connector-j-8.0.33.jarzeta集群启动
bash
# 分发一下
xsync /work/server/seatunnel /work/server/apache-seatunnel-2.3.8
# 停干净
xcall "lsof -nP -iTCP:5801 -sTCP:LISTEN -Fp | sed 's/^p//' | xargs -r kill -9"
xcall "ps -ef | grep seatunnel | grep -v grep | awk '{print \$2}' | xargs -r kill -9"
# 启动
xcall "mkdir -p /work/server/seatunnel/logs && \
/work/server/seatunnel/bin/seatunnel-cluster.sh -d > /work/server/seatunnel/logs/cluster_start.log 2>&1 &"
# 校验端口
xcall "ss -ltnp | grep ':5801' || echo 'port 5801 free'"测试
简单测试(本地)
bash
/work/server/seatunnel/bin/seatunnel.sh --config /work/server/seatunnel/config/v2.batch.config.template -m localMySQL ⇄ Hive 双向验证(Zeta 集群模式)
表结构与数据准备
mysql端
bash
mkdir -p /work/job/mysql
vim /work/job/mysql/test.sql
sql
-- 创建库
CREATE DATABASE IF NOT EXISTS test;
USE test;
-- 源表(MySQL → Hive)
DROP TABLE IF EXISTS test_src;
CREATE TABLE test_src (
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '主键ID',
name VARCHAR(50) NOT NULL COMMENT '姓名',
age INT COMMENT '年龄',
city VARCHAR(50) COMMENT '城市',
create_time DATETIME NOT NULL COMMENT '创建时间',
update_time DATETIME NOT NULL COMMENT '更新时间'
) COMMENT='SeaTunnel 测试源表(MySQL→Hive)';
-- 目标表(Hive → MySQL 回流)
DROP TABLE IF EXISTS test_sink;
CREATE TABLE test_sink (
id INT PRIMARY KEY COMMENT '主键ID',
name VARCHAR(50) NOT NULL COMMENT '姓名',
age INT COMMENT '年龄',
city VARCHAR(50) COMMENT '城市',
create_time DATETIME NOT NULL COMMENT '创建时间',
update_time DATETIME NOT NULL COMMENT '更新时间',
dt DATE COMMENT '分区日期(来自Hive分区)'
) COMMENT='SeaTunnel 回流目标表(Hive→MySQL)';
-- 初始化测试数据(三天分布,便于产生分区)
INSERT INTO test_src (name, age, city, create_time, update_time) VALUES
('张三', 25, '北京', NOW(), NOW()),
('李四', 30, '上海', DATE_SUB(CURDATE(), INTERVAL 1 DAY) + INTERVAL 11 HOUR, NOW()),
('王五', 28, '广州', DATE_SUB(CURDATE(), INTERVAL 2 DAY) + INTERVAL 9 HOUR, NOW()),
('赵六', 35, '深圳', NOW(), NOW());
-- 验证
SELECT * FROM test_src;
SELECT * FROM test_sink;
bash
# MySQL 执行 /work/job/mysql/test.sql
mysql -h node1 -ubigdata -pBigData@888 < /work/job/mysql/test.sqlhive端
bash
mkdir -p /work/job/hive
vim /work/job/hive/test.sql
sql
-- 建库
CREATE DATABASE IF NOT EXISTS test;
-- 作为 MySQL→Hive 的目标表(分区,存 Parquet)
DROP TABLE IF EXISTS test.test_sink;
CREATE TABLE test.test_sink (
id INT COMMENT '主键ID',
name STRING COMMENT '姓名',
age INT COMMENT '年龄',
city STRING COMMENT '城市'
)
PARTITIONED BY (dt STRING COMMENT '分区日期')
STORED AS PARQUET
TBLPROPERTIES ('parquet.compression'='SNAPPY');
-- 作为 Hive→MySQL 的源表(分区,存 Parquet)
DROP TABLE IF EXISTS test.test_src;
CREATE TABLE test.test_src (
id INT COMMENT '主键ID',
name STRING COMMENT '姓名',
age INT COMMENT '年龄',
city STRING COMMENT '城市',
create_time STRING COMMENT '创建时间',
update_time STRING COMMENT '更新时间'
)
PARTITIONED BY (dt STRING COMMENT '分区日期')
STORED AS PARQUET
TBLPROPERTIES ('parquet.compression'='SNAPPY');
-- 使用函数生成时间与分区(今日/昨日/前日),避免写死
WITH base AS (
SELECT
current_timestamp() AS now_ts,
current_date() AS today
)
INSERT INTO test.test_src PARTITION (dt)
SELECT
id,
name,
age,
city,
date_format(create_ts, 'yyyy-MM-dd HH:mm:ss') AS create_time,
date_format(update_ts, 'yyyy-MM-dd HH:mm:ss') AS update_time,
date_format(dt_date, 'yyyy-MM-dd') AS dt
FROM (
-- 今日
SELECT
101 AS id,
'周一' AS name,
24 AS age,
'北京' AS city,
b.now_ts AS create_ts,
b.now_ts AS update_ts,
b.today AS dt_date
FROM base b
UNION ALL
-- 昨日 11:00:00
SELECT
102,
'钱二',
29,
'上海',
(b.now_ts - interval 1 day + interval 11 hour) AS create_ts,
b.now_ts AS update_ts,
(b.today - interval 1 day) AS dt_date
FROM base b
UNION ALL
-- 前日 09:00:00
SELECT
103,
'孙三',
33,
'广州',
(b.now_ts - interval 2 day + interval 9 hour) AS create_ts,
b.now_ts AS update_ts,
(b.today - interval 2 day) AS dt_date
FROM base b
) t
;
-- 验证
SELECT * FROM test.test_src WHERE dt = date_format(current_date(), 'yyyy-MM-dd');
SELECT * FROM test.test_src WHERE dt = date_format(current_date() - interval 1 day, 'yyyy-MM-dd');
SELECT * FROM test.test_sink;
bash
# Hive 执行 /work/job/hive/test.sql
/work/server/hive/bin/beeline -u "jdbc:hive2://node1:10000/default" -n bigdata -p "" -f /work/job/hive/test.sqlMySQL → Hive(分区)
准备conf文件
bash
mkdir -p /work/job/seatunnel/test
vim /work/job/seatunnel/test/mysql_to_hive_partition.conf
bash
env {
parallelism = 2
job.name = "mysql_to_hive_dt_partition"
}
source {
Jdbc {
plugin_output = "jdbc_src"
url = "jdbc:mysql://node1:3306/test?useSSL=false&characterEncoding=utf8&serverTimezone=Asia/Shanghai"
driver = "com.mysql.cj.jdbc.Driver"
user = "bigdata"
password = "BigData@888"
table_path = "test.test_src"
fetch_size = 1000
}
}
transform {
Sql {
plugin_input = "jdbc_src"
plugin_output = "t_with_dt"
query = "select id, name, age, city, create_time, update_time, FORMATDATETIME(create_time, 'yyyy-MM-dd') as dt from jdbc_src"
}
}
sink {
Hive {
plugin_input = "t_with_dt"
# ------ 集中配置路径(每个节点均存在该本地路径) ------
metastore_uri = "thrift://node1:9083"
hive_site_path = "/work/server/seatunnel/externals/hive/hive-site.xml"
core_site_path = "/work/server/seatunnel/externals/hadoop/core-site.xml"
hdfs_site_path = "/work/server/seatunnel/externals/hadoop/hdfs-site.xml"
# 目标:Hive 的 test.test_sink(分区表,Parquet)
table_name = "test.test_sink"
table_path = "/user/hive/warehouse/test.db/test_sink"
file_format = "parquet"
compress_codec = "snappy"
is_partition_table = true
partition_by = ["dt"]
auto_create_table = false
save_mode = "overwrite"
}
}执行并验证
bash
# MySQL → Hive(分区到 test.test_sink)
/work/server/seatunnel/bin/seatunnel.sh --config /work/job/seatunnel/test/mysql_to_hive_partition.conf
/work/server/hive/bin/beeline -u "jdbc:hive2://node1:10000/default" -n bigdata -p "" -e "SELECT * FROM test.test_sink ORDER BY dt, id"hive的test.test_src有数据则成功
Hive → MySQL(分区)
准备conf文件
bash
mkdir -p /work/job/seatunnel/test
vim /work/job/seatunnel/test/hive_to_mysql.conf
bash
env {
parallelism = 2
job.name = "hive_to_mysql_sink"
}
source {
Hive {
plugin_output = "hive_src"
# 集中配置
metastore_uri = "thrift://node1:9083"
hive_site_path = "/work/server/seatunnel/externals/hive/hive-site.xml"
# 源表(Parquet)
table_name = "test.test_src"
# ------ 显式 schema:避免从文件推断 ------
schema = {
fields = {
id = int
name = string
age = int
city = string
create_time = string
update_time = string
dt = string
}
}
# (可选)按需裁剪分区,减少读取范围
# partition_prune = "dt >= '${date -d \"-2 day\" +%Y-%m-%d}'"
}
}
transform {
Sql {
plugin_input = "hive_src"
plugin_output = "t_out"
query = """
select
id,
name,
age,
city,
create_time,
update_time,
CAST(PARSEDATETIME(dt, 'yyyy-MM-dd') AS DATE) as dt
from hive_src
"""
}
}
sink {
Jdbc {
plugin_input = "t_out"
url = "jdbc:mysql://node1:3306/test?useSSL=false&characterEncoding=utf8&serverTimezone=Asia/Shanghai"
driver = "com.mysql.cj.jdbc.Driver"
user = "bigdata"
password = "BigData@888"
database = "test"
table = "test_sink"
generate_sink_sql = true
primary_keys = ["id"]
batch_size = 1000
}
}执行并验证
bash
# Hive → MySQL(回流到 test.test_sink)
/work/server/seatunnel/bin/seatunnel.sh --config /work/job/seatunnel/test/hive_to_mysql.conf
mysql -h node1 -ubigdata -pBigData@888 -e "USE test; SELECT * FROM test_sink ORDER BY dt, id;"mysql的test.test_sink也有数据才对
seatunnel-web(不推荐)
下载
官网下载apache-seatunnel-web-1.0.2-bin.tar.gz
然后用sftp的方式上传(拖拽)到 /work/pkg 目录下
bash
cd /work/server
# 解压
tar -zxvf /work/pkg/apache-seatunnel-web-1.0.2-bin.tar.gz -C /work/server/
# 软链
ln -sfnv /work/server/apache-seatunnel-web-1.0.2-bin /work/server/seatunnel-web
cd /work/server/seatunnel-web
ll初始化数据库
bash
vim /work/server/seatunnel-web/script/seatunnel_server_env.sh确保
bash
export HOSTNAME="node1"
export PORT="3306"
export USERNAME="bigdata"
export PASSWORD="BigData@888"
bash
bash /work/server/seatunnel-web/script/init_sql.sh如果不报错即成功,若不放心也可以去数据查看是否新增了一个seatunnel数据库,且多了若干表
mysql driver
bash
wget -P /work/server/seatunnel-web/libs/ \
https://repo1.maven.org/maven2/com/mysql/mysql-connector-j/8.0.33/mysql-connector-j-8.0.33.jar
ls -lh /work/server/seatunnel-web/libs | grep mysql配置文件
bash
vim /work/server/seatunnel-web/conf/application.yml替换
yaml
server:
port: 8801
address: 0.0.0.0 # 改为 0.0.0.0 对外监听
spring:
application:
name: seatunnel
jackson:
date-format: yyyy-MM-dd HH:mm:ss
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://node1:3306/seatunnel?useSSL=false&useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true&allowPublicKeyRetrieval=true
username: bigdata
password: BigData@888
mvc:
pathmatch:
matching-strategy: ant_path_matcher
jwt:
expireTime: 86400
# 记得自己生成密钥后填写
secretKey:
algorithm: HS256
---
spring:
config:
activate:
on-profile: h2
sql:
init:
schema-locations: classpath*:script/seatunnel_server_h2.sql
datasource:
driver-class-name: org.h2.Driver
url: jdbc:h2:mem:seatunnel;MODE=MySQL;DB_CLOSE_DELAY=-1;DATABASE_TO_LOWER=true
username: sa
password: sa
h2:
console:
enabled: true
path: /h2
settings:
trace: false
web-allow-others: false拷贝配置文件
bash
cp /work/server/seatunnel/config/hazelcast-client.yaml /work/server/seatunnel-web/conf/
cp /work/server/seatunnel/connectors/plugin-mapping.properties /work/server/seatunnel-web/conf/启动
bash
# 启动
bash /work/server/seatunnel-web/bin/seatunnel-backend-daemon.sh start
# 查看当前状态(不推荐,即使启动成功了也提示seatunnel is not running)
bash /work/server/seatunnel-web/bin/seatunnel-backend-daemon.sh status
# 停止
bash /work/server/seatunnel-web/bin/seatunnel-backend-daemon.sh stopwebui(http://node1的公网IP:8801/ui/)
默认用户名和密码为 admin/admin
Hue
准备mysql
bash
mysql -h node1 -ubigdata -pBigData@888
sql
-- 如果已存在旧库,先删除
DROP DATABASE IF EXISTS hue;
-- 重新创建 Hue 元数据库
CREATE DATABASE IF NOT EXISTS hue
DEFAULT CHARACTER SET utf8mb4
COLLATE utf8mb4_general_ci;
EXIT;系统依赖
(Ubuntu)+ Node.js 20
bash
sudo apt-get update -y
# 官方清单(去掉系统 Python 头文件,保留必需的 C/C++/Kerberos/SASL/LDAP/SSL/XML/XSLT/MySQL 等)
sudo apt-get install -y \
git ant gcc g++ make maven pkg-config \
libffi-dev libkrb5-dev libsasl2-dev libsasl2-modules-gssapi-mit \
libsqlite3-dev libssl-dev libxml2-dev libxslt-dev \
libldap2-dev libgmp-dev \
default-libmysqlclient-dev
# 若你的环境是 MariaDB 而不是 MySQL,可替换为:
# sudo apt-get install -y libmariadb-dev
# 安装 Node.js 20(按官方文档方式)
curl -fsSL https://deb.nodesource.com/setup_20.x | sudo -E bash -
sudo apt-get install -y nodejs
# 可选:降低 npm 构建噪音
npm config set fund false
npm config set audit falseconda环境
启用 conda 并创建环境
bash
conda create -n hue python=3.11 -y
conda activate hue安装构建与运行依赖(conda-forge 为主)
bash
conda install -y -c conda-forge \
openjdk nodejs=20 \
make cmake pkg-config \
krb5 cyrus-sasl openldap openssl \
libxml2 libxslt sqlite libffi gmp \
git安装 mysqlclient(优先使用 conda-forge 预编译轮子)
bash
conda install -y -c conda-forge mysqlclient
python - <<'PY'
import MySQLdb
print(">>> mysqlclient 正常工作")
PY软件包
获取 Hue 源码
bash
# 克隆官方 Hue 仓库(带代理示例)
git clone https://ghfast.top/https://github.com/cloudera/hue.git /work/server/hue
# git clone https://github.com/cloudera/hue.git /work/server/hue构建
bash
# 回到 Hue 根目录
cd /work/server/hue
# 清掉未完成的 venv
rm -rf build/env
# 用 git 的 url.rewrite 把 GitHub 指到镜像(你之前用过 ghfast,这里沿用)
git config --global url."https://ghfast.top/https://github.com/".insteadOf "https://github.com/"
# 继续使用国内 PyPI 镜像 & 提高容错
export PIP_INDEX_URL=https://mirrors.aliyun.com/pypi/simple
export PIP_TRUSTED_HOST=mirrors.aliyun.com
export PIP_DEFAULT_TIMEOUT=300
export PIP_RETRIES=10
# Hue 构建所需变量
export PYTHON_VER=python3.11
export PIP_VERSION=25.3
# 重新构建
make apps配置文件
bash
vim /work/server/huedesktop/conf/pseudo-distributed.ini命令模式下输入 /beeswax ,然后回车,即定位成功,修改 hive_server_host hive_server_port thrift_version,使其为
bash
# Host where HiveServer2 is running.
hive_server_host=node1
# Port where HiveServer2 Thrift server runs on.
hive_server_port=10000
thrift_version=11命令模式下输入 /[[hive ,然后回车,即定位成功,修改 name interface,使其为
bash
[[[hive]]]
name=Hive
interface=hiveserver2启动
bash
/work/server/hue/build/env/bin/hue runserver 0.0.0.0:8888webui(node1公网ip:8888)
账号和密码就是第一次输入的。
ZooKeeper
下载
官网下载 apache-zookeeper-3.8.5-bin.tar.gz
然后用sftp的方式上传(拖拽)到 /work/pkg 目录下
bash
cd /work/server
# 解压
tar -zxvf /work/pkg/apache-zookeeper-3.8.5-bin.tar.gz -C /work/server/
# 软链
ln -sfnv /work/server/apache-zookeeper-3.8.5-bin /work/server/zookeeper
cd /work/server/zookeeper
ll配置文件
myid
bash
mkdir /work/server/zookeeper/zkData
vim /work/server/zookeeper/zkData/myid写个数字,node1就写1
zoo.cfg
bash
cp /work/server/zookeeper/conf/zoo_sample.cfg /work/server/zookeeper/conf/zoo.cfg
vim /work/server/zookeeper/conf/zoo.cfg修改dataDir属性为
bash
dataDir=/work/server/zookeeper/zkData并在末尾添加
bash
#########cluster#########
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888然后分发一下
bash
xsync /work/server/zookeeper /work/server/apache-zookeeper-3.8.5-bin然后分别去node2、node3把myid中的数字改成2和3
bash
vim /work/server/zookeeper/zkData/myid启动
bash
xcall /work/server/zookeeper/bin/zkServer.sh start
xcall jps========== node1 ==========
ZooKeeper JMX enabled by default
Using config: /work/server/zookeeper/bin/.../conf/zoo.cfg
Starting zookeeper ... STARTED
========== node2 ==========
ZooKeeper JMX enabled by default
Using config: /work/server/zookeeper/bin/.../conf/zoo.cfg
Starting zookeeper ... STARTED
========== node3 ==========
ZooKeeper JMX enabled by default
Using config: /work/server/zookeeper/bin/.../conf/zoo.cfg
Starting zookeeper ... STARTED
bash
# 查看状态,应该有leader有follower
xcall /work/server/zookeeper/bin/zkServer.sh status
# 停止
xcall /work/server/zookeeper/bin/zkServer.sh stopkafka
配置
bash
mkdir -p /work/server/kafka-docker/{data,logs}
cd /work/server/kafka-docker
vim /work/server/kafka-docker/docker-compose.yml添加
yaml
services:
kafka:
image: apache/kafka:4.1.0
container_name: kafka
restart: unless-stopped
ports:
- "9092:9092"
environment:
KAFKA_PROCESS_ROLES: broker,controller
KAFKA_NODE_ID: 1
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka:9091
KAFKA_LISTENERS: CONTROLLER://0.0.0.0:9091,HOST://0.0.0.0:9092,DOCKER://0.0.0.0:9093
KAFKA_ADVERTISED_LISTENERS: HOST://node1:9092,DOCKER://kafka:9093
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,HOST:PLAINTEXT,DOCKER:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: DOCKER
KAFKA_NUM_PARTITIONS: 1
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_AUTO_CREATE_TOPICS_ENABLE: "true"
KAFKA_LOG_DIRS: /var/lib/kafka/data
KAFKA_HEAP_OPTS: "-Xms256m -Xmx256m"
volumes:
- ./data:/var/lib/kafka/data
- ./logs:/opt/kafka/logs
healthcheck:
test: ["CMD-SHELL", "/opt/kafka/bin/kafka-topics.sh --bootstrap-server localhost:9092 --list >/dev/null 2>&1"]
interval: 10s
timeout: 5s
retries: 12
kafka-ui:
image: provectuslabs/kafka-ui:latest
container_name: kafka-ui
restart: unless-stopped
depends_on:
kafka:
condition: service_healthy
ports:
- "9080:8080" # 改为宿主机 9080,容器仍然 8080
environment:
KAFKA_CLUSTERS_0_NAME: local
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka:9093启动
bash
cd /work/server/kafka-docker
docker compose up -d
docker compose ps
# 看启动日志
# docker logs -f kafkawebui (node1公网ip:9080)
测试
bash
docker exec -it kafka /opt/kafka/bin/kafka-topics.sh \
--bootstrap-server node1:9092 \
--create --topic test-topic --partitions 1 --replication-factor 1生产者 Producer:
bash
docker exec -it kafka /opt/kafka/bin/kafka-console-producer.sh \
--bootstrap-server node1:9092 \
--topic test-topic消费者 Consumer(另开一个窗口):
bash
docker exec -it kafka /opt/kafka/bin/kafka-console-consumer.sh \
--bootstrap-server node1:9092 \
--topic test-topic \
--from-beginning查看主题列表
bash
docker exec -it kafka /opt/kafka/bin/kafka-topics.sh \
--bootstrap-server node1:9092 --listDolphinScheduler
下载
官网 下载 apache-dolphinscheduler-3.2.0-bin.tar.gz
然后用sftp的方式上传(拖拽)到 /work/pkg 目录下
bash
cd /work/server
# 解压
tar -zxvf /work/pkg/apache-dolphinscheduler-3.2.0-bin.tar.gz -C /work/server/
cd /work/server/apache-dolphinscheduler-3.2.0-bin
ll准备mysql
bash
mysql -h node1 -ubigdata -pBigData@888
sql
-- 如果已存在旧库,先删除
DROP DATABASE IF EXISTS dolphinscheduler;
-- 重新创建 Hue 元数据库
CREATE DATABASE IF NOT EXISTS dolphinscheduler
DEFAULT CHARACTER SET utf8mb4
COLLATE utf8mb4_general_ci;
EXIT;配置文件
install_env.sh
bash
vim /work/server/apache-dolphinscheduler-3.2.0-bin/bin/env/install_env.sh确保以下值
bash
ips=${ips:-"node1,node2,node3"}
masters=${masters:-"node1,node2"}
workers=${workers:-"node1:default,node2:default,node3:default"}
alertServer=${alertServer:-"node2"}
apiServers=${apiServers:-"node1"}
installPath=${installPath:-"/work/server/dolphinscheduler"}
deployUser=${deployUser:-"bigdata"}dolphinscheduler_env.sh
plain
vim /work/server/apache-dolphinscheduler-3.2.0-bin/bin/env/dolphinscheduler_env.sh添加
bash
# ============ Java ============
# JAVA_HOME 由 DS 各服务启动脚本读取,用于选择 java 命令
export JAVA_HOME=${JAVA_HOME:-/work/server/jdk}
# ============ Metadata Database ============
# 按官方变量名:DATABASE(用于选择 Spring profile),并以 SPRING_* 提供连接信息
export DATABASE=${DATABASE:-mysql}
export SPRING_PROFILES_ACTIVE=${DATABASE}
export SPRING_DATASOURCE_URL=${SPRING_DATASOURCE_URL:-"jdbc:mysql://node1:3306/dolphinscheduler?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true&nullCatalogMeansCurrent=true"}
export SPRING_DATASOURCE_USERNAME=${SPRING_DATASOURCE_USERNAME:-bigdata}
export SPRING_DATASOURCE_PASSWORD=${SPRING_DATASOURCE_PASSWORD:-BigData@888}
# ============ Server Common ============
export SPRING_CACHE_TYPE=${SPRING_CACHE_TYPE:-none}
export SPRING_JACKSON_TIME_ZONE=${SPRING_JACKSON_TIME_ZONE:-Asia/Shanghai}
export MASTER_FETCH_COMMAND_NUM=${MASTER_FETCH_COMMAND_NUM:-10}
# ============ Registry (ZooKeeper) ============
export REGISTRY_TYPE=${REGISTRY_TYPE:-zookeeper}
export REGISTRY_ZOOKEEPER_CONNECT_STRING=${REGISTRY_ZOOKEEPER_CONNECT_STRING:-"node1:2181,node2:2181,node3:2181"}
# ============ BigData Toolchains ============
# 这些变量仅当你在任务中使用对应组件时才需要
export HADOOP_HOME=${HADOOP_HOME:-/work/server/hadoop}
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-/work/server/hadoop/etc/hadoop}
export SPARK_HOME1=${SPARK_HOME1:-/work/server/spark1}
export SPARK_HOME2=${SPARK_HOME2:-/work/server/spark2}
export HIVE_HOME=${HIVE_HOME:-/work/server/hive}
export FLINK_HOME=${FLINK_HOME:-/work/server/flink}
# ============ Python / DataX / Seatunnel / Chunjun ============
# 按官方识别:PYTHON_HOME 指向解释器;DATAX_HOME 指向 DataX 根目录
# 你已为 DataX 准备了专用 conda 环境:/export/server/miniconda3/envs/datax
export PYTHON_HOME=${PYTHON_HOME:-/work/server/miniconda3/envs/datax}
export DATAX_HOME=${DATAX_HOME:-/work/server/datax}
export SEATUNNEL_HOME=${SEATUNNEL_HOME:-/work/server/seatunnel}
export CHUNJUN_HOME=${CHUNJUN_HOME:-/w/server/chunjun}
# PATH 前置 Python 解释器,确保 Worker 生成的 command 脚本直接可执行 python
export PATH=$PYTHON_HOME/bin:$HADOOP_HOME/bin:$SPARK_HOME1/bin:$SPARK_HOME2/bin:$JAVA_HOME/bin:$HIVE_HOME/bin:$FLINK_HOME/bin:$DATAX_HOME/bin:$SEATUNNEL_HOME/bin:$CHUNJUN_HOME/bin:$PATHmysql driver
bash
# 创建 DolphinScheduler JDBC 缓存目录
mkdir -p /work/server/apache-dolphinscheduler-3.2.0-bin/jar
# 下载 MySQL JDBC 驱动
wget -P /work/server/apache-dolphinscheduler-3.2.0-bin/jar \
https://repo1.maven.org/maven2/com/mysql/mysql-connector-j/8.0.33/mysql-connector-j-8.0.33.jar
# 确认下载成功(文件大于 1M 即正确)
ls -lh /work/server/apache-dolphinscheduler-3.2.0-bin/jar/mysql-connector-j-8.0.33.jar
# 复制 JDBC 驱动到 DolphinScheduler 所有服务 libs 目录
DS_HOME=/work/server/apache-dolphinscheduler-3.2.0-bin
cp $DS_HOME/jar/mysql-connector-j-8.0.33.jar $DS_HOME/tools/libs/
cp $DS_HOME/jar/mysql-connector-j-8.0.33.jar $DS_HOME/api-server/libs/
cp $DS_HOME/jar/mysql-connector-j-8.0.33.jar $DS_HOME/alert-server/libs/
cp $DS_HOME/jar/mysql-connector-j-8.0.33.jar $DS_HOME/master-server/libs/
cp $DS_HOME/jar/mysql-connector-j-8.0.33.jar $DS_HOME/worker-server/libs/
cp $DS_HOME/jar/mysql-connector-j-8.0.33.jar $DS_HOME/standalone-server/libs/ 2>/dev/null || true初始化数据库
bash
bash /work/server/apache-dolphinscheduler-3.2.0-bin/tools/bin/upgrade-schema.sh安装
bash
bash /work/server/apache-dolphinscheduler-3.2.0-bin/bin/install.sh启动
bash
# 启动
bash /work/server/dolphinscheduler/bin/start-all.sh
# 停止
bash /work/server/dolphinscheduler/bin/stop-all.sh浏览器访问地址 http://node1公网ip:12345/dolphinscheduler/ui 即可登录系统UI。
默认的用户名和密码是 admin/dolphinscheduler123
superset(不推荐)
安装
安装必要的系统依赖(防止数据库驱动或加密库报错)
bash
sudo apt update
sudo apt install -y build-essential libssl-dev libffi-dev \
libsasl2-dev libldap2-dev default-libmysqlclient-dev创建名为 superset 的 Conda 环境,指定 Python 3.11
bash
conda create -n superset python=3.11 -y
conda activate superset按conda 源安装 Superset 与关键依赖
以下三者都能在 conda-forge 找到,尽量不走 pip:
superset(当前 conda-forge 提供 4.1.2)
marshmallow=3.26.1(避免 marshmallow 4 引发 minLength 报错)
WTForms=2.3.3(避免登录页 500 的 extra_filters 报错)
bash
# 一次性由 conda 求解并安装(走你已配置的镜像)
conda install -y -c conda-forge superset marshmallow=3.26.1 WTForms=2.3.3 pillow初始化
bash
mkdir -p /export/server/superset/logs密钥最好生成一次,然后长期保存
bash
echo "export SUPERSET_SECRET_KEY=\"$(openssl rand -base64 42)\"" | sudo tee -a /etc/profile
source /etc/profile
echo $SUPERSET_SECRET_KEY
bash
# 初始化数据库
superset db upgrade
# 创建管理员账号(非交互,按你指定的用户名/密码)
superset fab create-admin \
--username superset --firstname superset --lastname user \
--email superset@example.com --password superset
# 示例数据:为避免外网下载不稳定,建议仅加载元数据(可立即用 UI 连接你自己的库)
superset load_examples --only-metadata
# 完成初始化
superset init启动
bash
nohup env FLASK_APP=superset \
conda run -n superset superset run -h 0.0.0.0 -p 8090 --with-threads \
> /export/server/superset/superset.log 2>&1 &配置数据源
hive
安装驱动
bash
conda activate superset
# 用 conda 安装预编译的 SASL 相关依赖
# - sasl=0.3.1:与 pyhive/thrift_sasl 兼容较好
# - cyrus-sasl:系统级依赖(conda 包名)
# - thrift:thrift C 库/头
conda install -y -c conda-forge sasl=0.3.1 cyrus-sasl thrift
# 再用 pip 安装 Python 侧的驱动(这次不会再去编译 sasl)
pip install pyhive[hive] thrift_sasl验证
bash
python - <<'PY'
from pyhive import hive
import thrift_sasl
import sasl
print("PyHive/Thrift SASL/SASL 安装 OK")
PY添加数据源
bash
hive://hadoop:你的密码@node1的公网ip:10000/default?auth=LDAP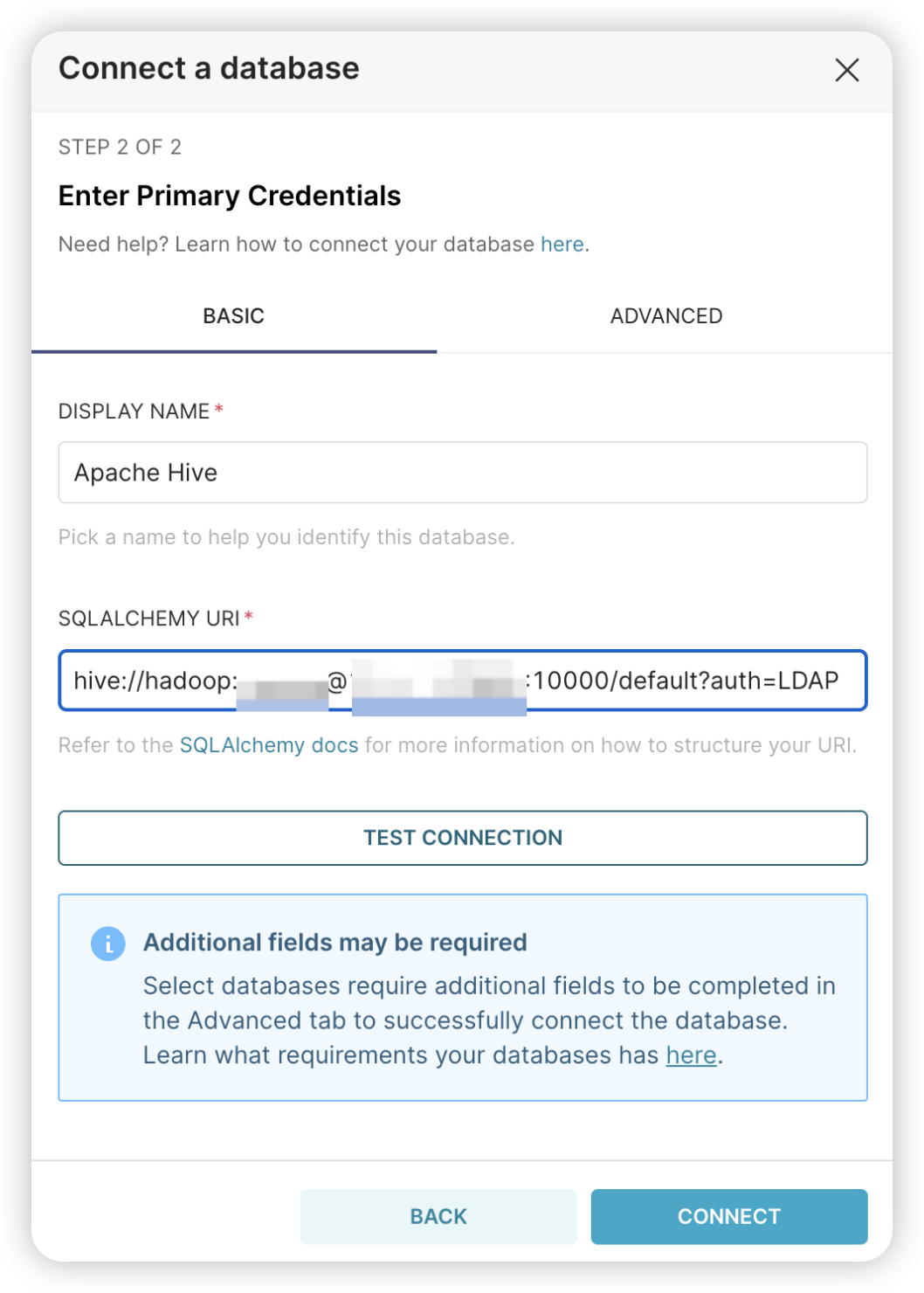
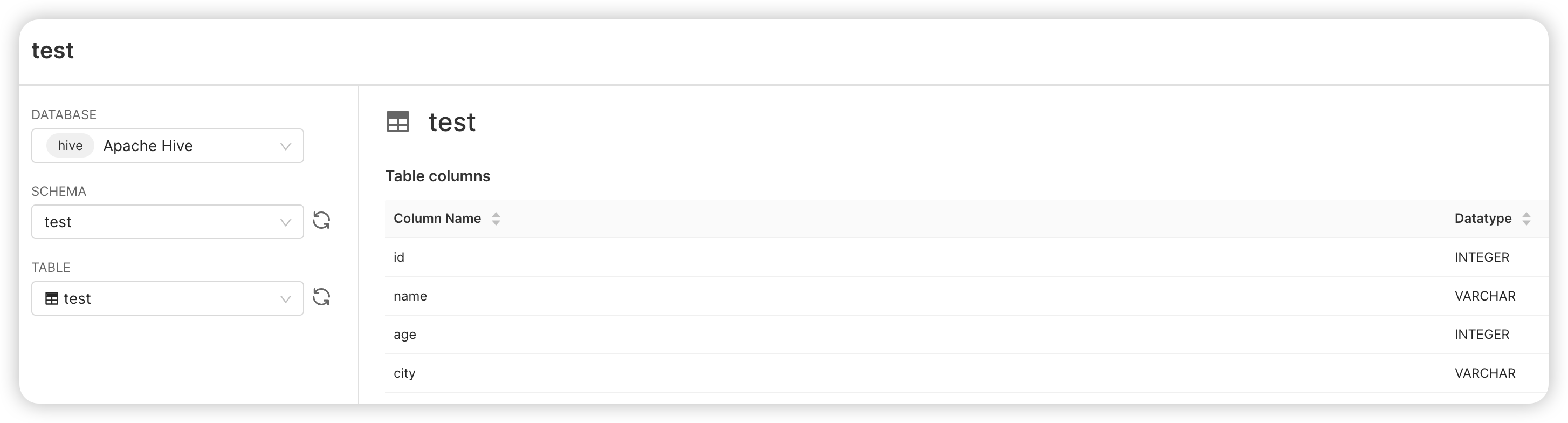
doris(暂不推荐)
前置准备
参考官方文档
安装 Doris
解压 Doris 安装包
bash
tar -zxvf /export/server/apache-doris-3.0.7-bin-x64.tar.gz -C /export/server/
ln -sfn /export/server/apache-doris-3.0.7-bin-x64 /export/server/doris创建独立元数据与数据目录
bash
# FE 元数据
mkdir -p /data/doris/fe/doris-meta
ln -sfn /data/doris/fe/doris-meta /export/server/doris/fe/doris-meta
# BE 元数据
mkdir -p /data/doris/be/doris-meta
ln -sfn /data/doris/be/doris-meta /export/server/doris/be/doris-meta
# BE 数据存储目录
mkdir -p /data/doris/be-storage1配置文件修改
修改 FE 配置文件
定位:vim /export/server/doris/fe/conf/fe.conf
添加/修改:
bash
JAVA_HOME=/export/server/jdk
priority_networks=192.168.88.0/24
lower_case_table_names=1
# 修改端口避免冲突
http_port=18030修改 BE 配置文件
定位:vim /export/server/doris/be/conf/be.conf
添加/修改:
bash
JAVA_HOME=/export/server/jdk
priority_networks=192.168.88.0/24
# 数据目录(可配置多块磁盘,分号分隔)
storage_root_path=/data/doris/be-storage1,medium:HDD
# 修改端口避免冲突
webserver_port=18040分发 Doris 到其他节点
在 node1 执行:
bash
xsync /export/server/doris/
xsync /export/server/apache-doris-3.0.7-bin-x64/在 node2 / node3 上创建目录:
bash
mkdir -p /data/doris/fe/doris-meta
mkdir -p /data/doris/be/doris-meta
mkdir -p /data/doris/be-storage1
ln -sfn /data/doris/fe/doris-meta /export/server/doris/fe/doris-meta
ln -sfn /data/doris/be/doris-meta /export/server/doris/be/doris-meta启动与注册
启动 FE Master(node1)
bash
bash /export/server/doris/fe/bin/start_fe.sh --daemon
mysql -uroot -P9030 -hnode1 -e "show frontends\G"检查 FE 状态:
- Alive = true
- Join = true
- IsMaster = true
注册 FE Follower
bash
mysql -uroot -P9030 -hnode1 -e "ALTER SYSTEM ADD FOLLOWER 'node2:9010';"
mysql -uroot -P9030 -hnode1 -e "ALTER SYSTEM ADD FOLLOWER 'node3:9010';"在 node2 / node3 启动 FE Follower(首次带 helper):
bash
bash /export/server/doris/fe/bin/start_fe.sh --helper node1:9010 --daemon确认 Follower 状态:
- Alive = true
- Join = true
- IsMaster = false
注册 BE 节点
bash
mysql -uroot -P9030 -hnode1 -e "ALTER SYSTEM ADD BACKEND 'node1:9050';"
mysql -uroot -P9030 -hnode1 -e "ALTER SYSTEM ADD BACKEND 'node2:9050';"
mysql -uroot -P9030 -hnode1 -e "ALTER SYSTEM ADD BACKEND 'node3:9050';"在 node1/node2/node3 分别启动 BE:
bash
bash /export/server/doris/be/bin/start_be.sh --daemon检查 BE 状态:
bash
mysql -uroot -P9030 -hnode1 -e "show backends\G"关注:
- Alive = true
- TabletNum 是否均衡
验证集群正确性
- 登录 Doris
bash
mysql -uroot -P9030 -hnode1- 修改 root 密码
sql
SET PASSWORD = PASSWORD('doris_new_passwd');- 创建测试表
sql
create database testdb;
CREATE TABLE testdb.table_hash
(
k1 TINYINT,
k2 DECIMAL(10, 2) DEFAULT "10.5",
k3 VARCHAR(10) COMMENT "string column",
k4 INT NOT NULL DEFAULT "1" COMMENT "int column"
)
COMMENT "my first table"
DISTRIBUTED BY HASH(k1) BUCKETS 32;- 插入测试数据
sql
INSERT INTO testdb.table_hash VALUES
(1, 10.1, 'AAA', 10),
(2, 10.2, 'BBB', 20),
(3, 10.3, 'CCC', 30),
(4, 10.4, 'DDD', 40),
(5, 10.5, 'EEE', 50);
SELECT * from testdb.table_hash;结果正确即表示集群部署完成。