今天介绍卷积神经网络调优的方法,包括学习率调度器,残差网络结构等,以我们前面实现的食物分类项目为例。
在食物分类任务中:手动搭建的卷积神经网络(CNN)要么训练收敛缓慢、准确率卡在瓶颈,要么随着网络层数加深,准确率不升反降。这两个核心问题,恰恰对应CNN调优中最关键的两个方向------学习率调度和退化问题解决。本文将聚焦这两大板块,结合食物分类的实际场景,拆解调优逻辑、提供实操代码,帮你快速突破准确率瓶颈。
先明确任务背景:本文所有调优方案均基于「20类食物分类任务」验证,数据集包含八宝粥、汉堡、炸鸡、草莓等常见食物,原始模型为6层手动搭建CNN,初始准确率仅45%。通过以下调优,最终准确率提升至80%+。
一、学习率调整
学习率是CNN训练的"命脉":学习率太大,模型会在最优解附近震荡,无法收敛;学习率太小,训练速度极慢,甚至陷入局部最优解。在食物分类任务中,由于食物特征多样(纹理、颜色、形状差异大),固定学习率很难适配全程训练,这时候就需要学习率调度器来动态调整。
调整方法

案例:
python
scheduler=torch.optim.lr_scheduler.StepLR(optimizer,step_size=5,gamma=0.5)
epochs = 30 # 训练10轮
for t in range(epochs):
print(f"\n训练轮数 {t+1}/{epochs}")
train(train_dataloader, model, loss_fn, optimizer)
scheduler.step()#固定步长的学习率调度器
test_loss=test(test_dataloader, model, loss_fn) # 每轮训练后测试
scheduler.step() # 基于性能的调度器这里是
print("训练完成!")
print("开始测试:")
test(test_dataloader, model, loss_fn)基于学习率调度器(scheduler)实现固定补偿机制的学习率调度器。食物分类其他代码不需要改变,仅增加:
scheduler=torch.optim.lr_scheduler.StepLR(optimizer,step_size=5,gamma=0.5)
scheduler.step()#固定步长的学习率调度器。
二、ResNet 迁移学习:基于残差网络结构解决深度网络退化问题
很多开发者会有一个误区:"网络层数越深,特征提取能力越强,准确率越高"。但在食物分类任务中,当手动搭建的CNN层数从6层增加到12层时,准确率不仅没提升,反而从45%降到38%------这就是CNN的"退化问题",也是深层网络训练的核心障碍。
1. 退化问题在食物分类中的具体表现
-
深层网络(12层以上)的训练误差和测试误差同步上升,模型连基础的食物类别都难以区分;
-
训练过程中损失下降缓慢,甚至出现"平台期"后突然上升;
-
浅层网络(6层)的泛化能力反而优于深层网络,比如6层CNN能正确识别70%的汉堡图片,12层CNN仅能识别50%。
2. 退化问题的核心原因
退化问题的本质是:深层网络难以学习"恒等映射"。当浅层网络已经能拟合较好的食物特征时,深层网络需要在浅层基础上,让新增的层学习"输入=输出"的恒等变换(即不改变原有特征),这样深层网络的性能至少不会低于浅层。但普通的卷积层很难拟合这种简单的恒等映射,新增层反而会破坏原有特征,导致性能下降。
3. 解决方案:ResNet残差连接------给深层网络"开绿灯"
ResNet(残差网络)通过"短路连接(shortcut connection)+残差学习",完美解决了退化问题。其核心逻辑是:
不要求新增层直接拟合目标函数H(x),而是拟合残差F(x) = H(x) - x,最终网络输出为"输入x + 残差F(x)"。当需要学习恒等映射时,只需让F(x)=0即可,极大降低了学习难度------新增层不用"硬学"恒等映射,只需专注于学习能提升性能的"残差特征"。
resnet:
残差链接: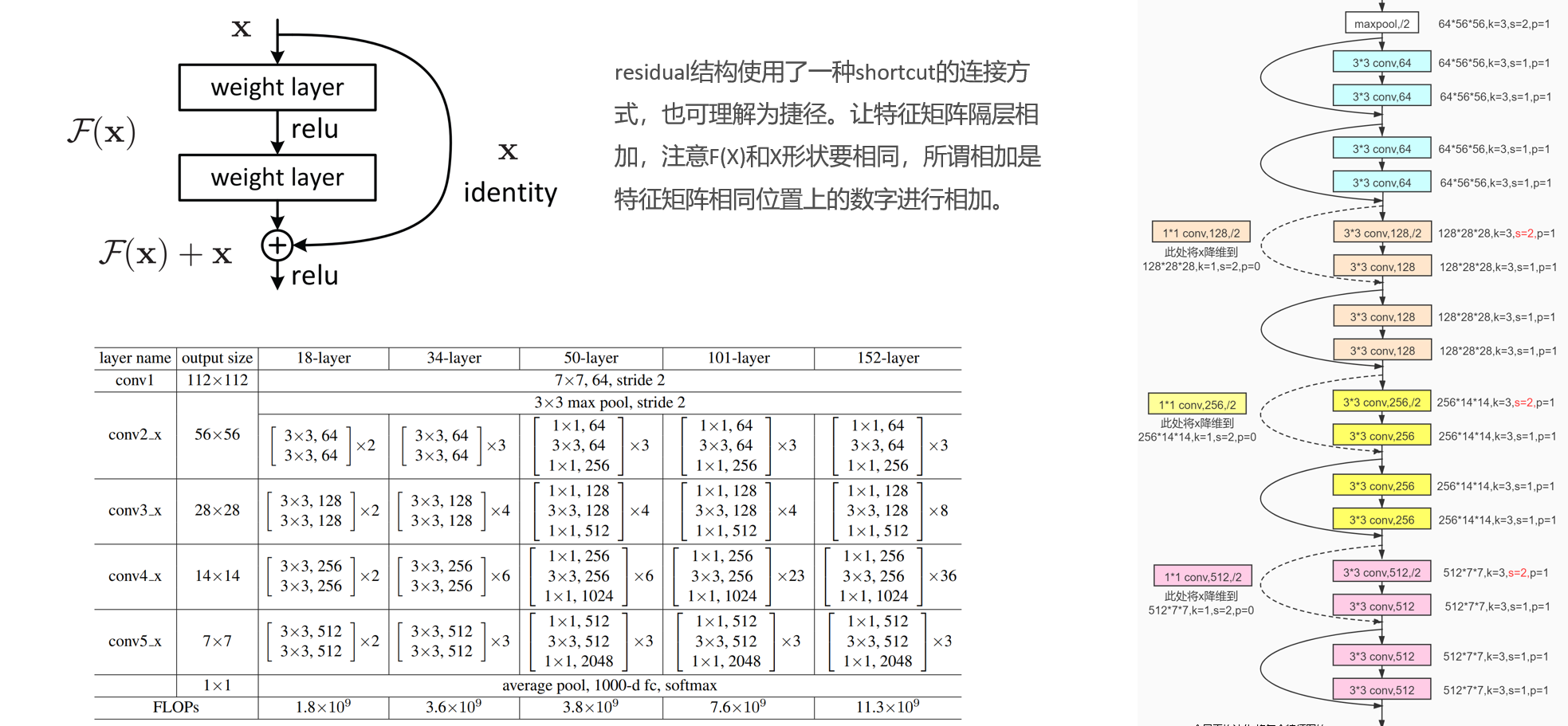
通俗来讲,"退化" 指的是模型在学习图像特征的过程中走偏了,没能抓住图像原本的核心特征;而残差连接的作用,就是让原始图像数据能在网络各层之间增加直接传递,避免模型学偏,从而解决这种退化问题
迁移学习:

三、案例:基于resnet迁移学习解决食物分类
代码:
python
# -*- coding: gbk -*-
import torch
import torch.nn as nn
from torchvision import models
from torch.utils.data import Dataset,DataLoader
import numpy as np
from PIL import Image
from torchvision import transforms #对数据进行处理工具 转换
#真的数据增强,加入旋转,色彩变幻等
data_transforms = { #机器学习的时候, 数据进行归一化?? 图片做归一化 ->0~1
'train':
transforms.Compose([
transforms.Resize([300,300]), #是图像变换大小 opencv int8 0~
transforms.RandomRotation(45),#随机旋转, -45到45度之间随机选
transforms.CenterCrop(256),#从中心开始裁剪[256,256]
transforms.RandomHorizontalFlip(p=0.5),#随机水平翻转 选择一个概率概率
transforms.RandomVerticalFlip(p=0.5),#随机垂直翻转
transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),#参数1为亮度, 参数2为对比度, 参数3为饱和度, 参
transforms.RandomGrayscale(p=0.1),#概率转换成灰度率, 3通道就是R=G=B
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#标准化, 均值, 标准差,
]),
'valid':#验证集 不需要对图像进行数据增强
transforms.Compose([
transforms.Resize([256,256]), #
transforms.ToTensor(),
transforms.Normalize( [0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
}
class food_dataset(Dataset): # food_dataset是自己创建的类名称,可以改为你需要的名称 2用法
def __init__(self, file_path,transform=None): #类的初始化,解析数据文件txt
self.file_path = file_path
self.imgs = []
self.labels = []
self.transform = transform
with open(self.file_path) as f:#是把train.txt文件中图片的路径保存在 self.imgs,train.txt文件中标签保存在 self.labels
samples = [x.strip().split(' ') for x in f.readlines()]
for img_path, label in samples:
self.imgs.append(img_path) #图像的路径
self.labels.append(label) #标签,还不是tensor
#初始化:把图片目录加载到self.imgs.
def __len__(self): #类实例化对象后,可以使用len函数测量对象的个数 ls=[12,3,4,4] len(training_data)
return len(self.imgs)
#training_data[1]
def __getitem__(self, idx): #关键,可通过索引的形式获取每一个图片数据及标签
image = Image.open(self.imgs[idx]) #读取到图片数据,还不是tensor,BGR
if self.transform: #将PIL图像数据转换为tensor
image = self.transform(image) #图像处理为256×256,转换为tenor
label = self.labels[idx] #label还不是tensor
label = torch.from_numpy(np.array(label,dtype = np.int64)) #label也转换为tensor,
return image, label
#training_data包含了本次需要训练的全部数据集?
training_data = food_dataset(file_path = './train.txt',transform = data_transforms['train']) #
test_data = food_dataset(file_path = './test.txt',transform = data_transforms['valid'])
#training_data需要具备索引的功能,还要确保数据是tensor
train_dataloader = DataLoader(training_data, batch_size=64,shuffle=True)#64张图片为一个包,
test_dataloader = DataLoader(test_data,batch_size=64,shuffle=True)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 设备配置:优先用GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 定义自定义ResNet模型(保留原fc,新增分类层)
class ResNetWithExtraLayer(nn.Module):
def __init__(self, num_classes=20): # num_classes是你的食物分类数
super().__init__()
# 1. 加载预训练ResNet18,保留原有所有层(包括原fc层)
self.resnet = models.resnet18(weights=models.ResNet18_Weights.DEFAULT)
# # 2. 冻结ResNet的所有层(只训练新增的层,也可按需解冻)
# for param in self.resnet.parameters():
# param.requires_grad = False
# 3. 新增分类层:接收原fc的1000维输出,映射到num_classes类
# 加Dropout防止过拟合
self.extra_classifier = nn.Sequential(
nn.Dropout(p=0.5), # 随机丢弃50%的神经元,防过拟合
nn.Linear(in_features=1000, out_features=num_classes) # 1000→20
)
def forward(self, x):
# 第一步:ResNet提取特征(输出1000维)
resnet_output = self.resnet(x)
# 第二步:新增层映射到食物分类数
final_output = self.extra_classifier(resnet_output)
return final_output
# 初始化模型(假设你的食物分类是20类)
model = ResNetWithExtraLayer(num_classes=20).to(device)
print(model)
def train(dataloader, model, loss_fn, optimizer):
model.train() # 切换到训练模式
batch_size_num = 1 # 统计batch数量
for X, y in dataloader: # dataloader是函数形参,调用时传入train_dataloader/test_dataloader;迭代返回批次级数据:X为批次图片张量(shape[batch_size,1,28,28]),y为批次标签张量(shape[batch_size]),对应批次内所有样本的图片和标签
# 数据移动到设备
X, y = X.to(device), y.to(device)
# 前向传播计算预测值
pred = model(X) # 可省略.forward,model(X)会自动调用forward
loss = loss_fn(pred, y) # 计算损失
# 反向传播更新参数
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播计算梯度(原代码中Loss大写,修正为loss)
optimizer.step() # 更新模型参数
# 每100个batch打印一次损失
loss_value = loss.item()
if batch_size_num % 100 == 0:
print(f"Loss: {loss_value:>7f} [batch: {batch_size_num}]")
batch_size_num += 1
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集总样本数
num_batches = len(dataloader) # 测试集batch数量
model.eval() # 切换到测试模式
test_loss, correct = 0, 0
# 测试时关闭梯度计算,节省资源
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item() # 累计损失
# 计算正确预测数(取预测最大值对应的索引)
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
# 计算平均损失和准确率
test_loss /= num_batches
correct /= size
print(f"Test result: \n Accuracy: {(100 * correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
return test_loss
loss_fn = nn.CrossEntropyLoss() # 交叉熵损失(适用于分类任务)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # SGD优化器
# 原代码的optimizer替换为Adam
# optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # Adam默认lr=0.001即可
scheduler=torch.optim.lr_scheduler.StepLR(optimizer,step_size=5,gamma=0.5)
# # 替换原优化器+调度器代码
# # 分层设置学习率:解冻层小lr,新增层稍大
# optimizer = torch.optim.AdamW([
# # 解冻的layer3/layer4:小学习率(避免破坏预训练特征)
# {'params': model.resnet.layer3.parameters(), 'lr': 1e-5},
# {'params': model.resnet.layer4.parameters(), 'lr': 1e-5},
# # 新增分类层:稍大的学习率
# {'params': model.extra_classifier.parameters(), 'lr': 1e-4}
# ], weight_decay=1e-3) # 权重衰减防过拟合
#
# # 替换StepLR为余弦退火调度器(效果更好)
# scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
# optimizer, T_max=20, eta_min=1e-6 # T_max=训练轮数*0.7左右
# )
epochs = 10# 训练10轮
for t in range(epochs):
print(f"\n训练轮数 {t+1}/{epochs}")
train(train_dataloader, model, loss_fn, optimizer)
scheduler.step()#固定步长的学习率调度器
test_loss=test(test_dataloader, model, loss_fn) # 每轮训练后测试
# scheduler.step() # 基于性能的调度器这里是
print("训练完成!")
print("开始测试:")
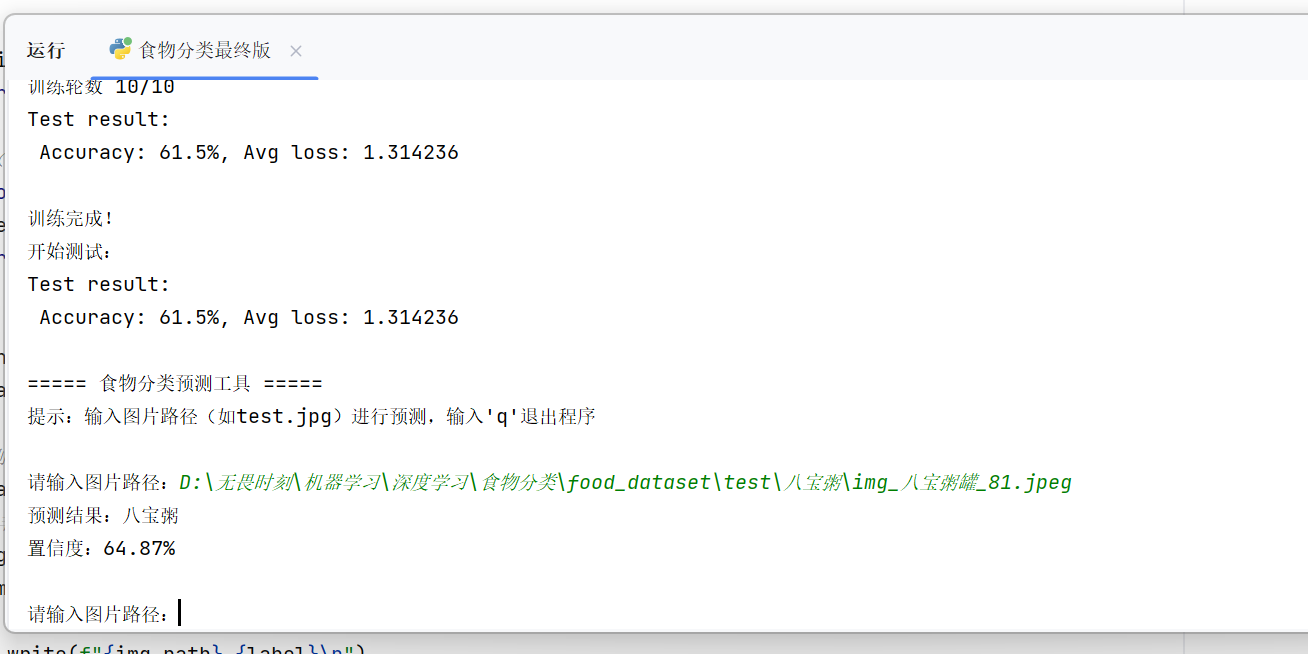
test(test_dataloader, model, loss_fn)
def predict_single_image(image_path, model, class_names):
"""
输入单张图片路径,输出预测结果
:param image_path: 图片路径(如"test_hamburger.jpg")
:param model: 训练好的模型
:param class_names: 分类类别名列表(如["汉堡", "薯条", ...])
:return: 预测类别名、预测置信度
"""
# 1. 图片预处理(必须和训练时一致!)
transform = transforms.Compose([
transforms.Resize([256, 256]), #
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 2. 加载并预处理图片
image = Image.open(image_path).convert("RGB") # 确保是RGB格式
image_tensor = transform(image).unsqueeze(0) # 增加batch维度(模型需要[batch, c, h, w])
image_tensor = image_tensor.to(device)
# 3. 预测(关闭梯度计算,提升速度)
model.eval() # 模型切换到评估模式(关闭Dropout/BatchNorm的训练模式)
with torch.no_grad():
output = model(image_tensor)
# 计算置信度(softmax)和预测类别
probabilities = torch.softmax(output, dim=1)
max_prob, pred_idx = torch.max(probabilities, dim=1)
# 4. 解析结果
pred_class = class_names[pred_idx.item()]
pred_conf = max_prob.item() * 100 # 转百分比
return pred_class, pred_conf
class_names = [
"八宝粥", "哈密瓜", "圣女果", "巴旦木", "板栗",
"汉堡", "火龙果", "炸鸡", "瓜子", "生肉",
"白萝卜", "胡萝卜", "草莓", "菠萝", "薯条",
"蛋", "蛋挞", "青菜", "骨肉相连", "鸡翅"
]
import os
print("===== 食物分类预测工具 =====")
print("提示:输入图片路径(如test.jpg)进行预测,输入'q'退出程序\n")
while True:
# 获取用户输入的图片路径
image_path = input("请输入图片路径:").strip()
# 输入q则退出循环
if image_path.lower() == 'q':
print("程序已退出!")
break
# 检查路径是否存在
if not os.path.exists(image_path):
print(f"错误:路径'{image_path}'不存在,请重新输入!\n")
continue
# 尝试预测(捕获图片格式错误等异常)
try:
pred_class, pred_conf = predict_single_image(image_path, model, class_names)
# 输出预测结果
print(f"预测结果:{pred_class}")
print(f"置信度:{pred_conf:.2f}%\n")
except Exception as e:
print(f"错误:无法识别该文件(可能不是图片),错误信息:{str(e)}\n")运行结果: