博主介绍:java高级开发,从事互联网行业六年,熟悉各种主流语言,精通java、python、php、爬虫、web开发,已经做了多年的设计程序开发,开发过上千套设计程序,没有什么华丽的语言,只有实实在在的写点程序。
🍅文末点击卡片获取联系🍅
技术:python+yolov5
1 设计目标
本系统针对人脸图像进行检测,从中提取特征来预测人脸是否佩戴口罩。
(1)人脸图像中各类预识别对象的标注和数据增强;
(2)yolov5算法的实现;
(3)基于yolov5进行人脸图像的训练和预测;
(4)将识别出的数据保存为矢量数据;
(5)图形用户界面的实现。
2. 需求分析
2.1 项目需求
本系统采用了yolov5模型,Darknet深度学习框架,操作系统为Windows 10,环境为Pytorch。这些技术目前都已经很成熟,而且技术含量很高,使用起来很方便,安全性也有较大保障。目前高性能的网络组建大量涌现,他们速度快、用量大、可靠性高、价格低,完全可以满足本系统的需要。
在使用本系统时,用户首先需要选择本地图片或视频并传入系统,系统对图片进行预处理后再对目标人脸的区域进行定位,然后对定位后的人脸区域进行是否佩戴口罩的识别,最后将识别结果输出。
根据上述描述,本系统应具备以下四个功能:
(1)图片选择:提供从本地文件夹中选择待识别图片的功能。用户可以从本地文件夹中获取想要识别的图片并传入系统。
(2)图像预处理:提供对传入的图片进行预处理的功能。该功能可以对传入的图片进行灰度校正和平滑处理,为之后对图像进行进一步分析和识别做准备。
(3)图像识别:该功能是对已经预计处理的图像进行再一次进一步的分析,并通过如此方式对于图像特征提取,对于目标进行定位以及预处理之后的图像进行进一步分析,对图像进行特征提取、目标定位和目标识别。
(4)结果输出:该功能可以将已经完成识别的图像的结果进行输出。 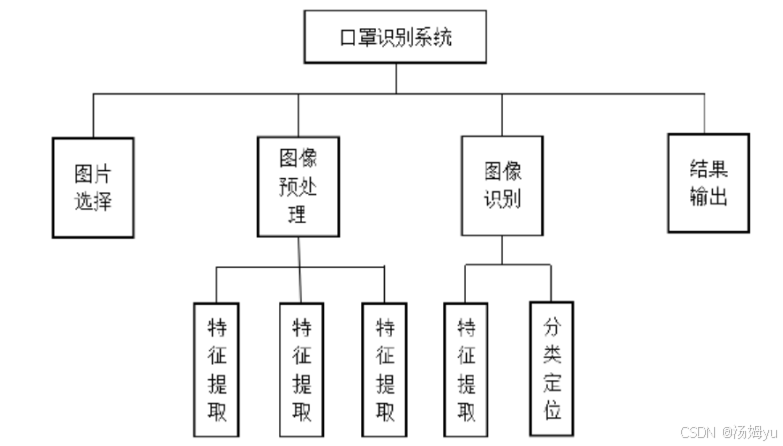
图2-1 系统功能结构图
2.2 项目业务要求
数据格式要求:支持png、jpg、jpeg、tiff等多种格式类型、多种大小的图片数据的读入和预测;界面要求:运行流畅,响应快,交互性良好,能够在有限的时间内对目标数据进行识别并保存结果。
2.3 项目环境要求
2.3 . 1 硬件环境
本项目使用cpu解决复杂的计算问题。
2.3 . 2 软件环境
使用Anaconda来构建Python环境;其中各软件库环境要求如下表2.1所示。
表2.1 各软件环境对应表
|---------------------|------------|--------------------------------------------------------------------------------------------|
| python环境 | 版本要求 | 目的 |
| torch | >= 1.8.0 | 搭建、训练网络并进行预测 |
| torchvision | >= 0.9.0 | 用来生成图片数据集和加载一些预训练模型 |
| torchsummary | >= 1.5.1 | 输出、可视化网络结果 |
| TensorboardX | >= 2.5.1 | 网络结构、训练过程参数可视化 |
| PyQt | >= 5.15.7 | 构建软件界面 |
| Matplotlib | >=3.2.2 | 数据可视化,二维、三维绘图 |
| numpy | >=1.18.5 | 提供数据结构以及相应高效的处理函数 |
| Opencv-python | >=4.1.2 | 基于开源发行的跨平台计算机视觉库 |
| pillow | ==8.4.0 | 用于图像的基本处理 |
| pyyaml | >=5.3.1 | Python的YAML解析器和生成器。 |
| requests | >=2.23.0 | 用作发送网络请求 |
| scipy | >=1.4.1 | 高级的科学计算库 |
| tqdm | >=4.41.0 | 方便且易于扩展的Python进度条 |
| Tensorboard | >=2.11.1 | 用于数据可视化的工具 |
| pandas | >=1.1.4 | 用于管理数据集,数据分析和探索工具 |
| seaborn | >=0.11.0 | 用于生成统计图形 |
| pycocotools-windows | >=2.0.0 | 大型的图像数据集 |
3. 数据获取与增强
3.1 数据来源
此次作业本人使用的是mask_data数据集。mask_data是一个自定义数据集,在网上爬取了大约850张佩戴口罩、未正确佩戴口罩和未佩戴口罩的人脸图片,(由于无英伟达显卡,所以只查找了850张图片)。然后使用labeling标注图片,将图片分为了三类,其中标签0表示mask佩戴口罩,标签1表示mask_incorrect未正确佩戴口罩,标签2表示未佩戴口罩。再利用代码将VOC格式(xml格式)转为yolo格式(txt格式),并按80%的比例划分为训练集和验证集,即850张图片中680张为训练图片、170张为测试图片。在每一次同时数据之中,存在着许许多多的不同,口罩角度,颜色各不相同,这样的训练有利于提升我们的检测佩戴情况的准确性。数据集样张如图3.1所示。转化为txt格式如图3.2所示。

3.2 数据增强
本项目涉及到的数据增强方法主要有以下几种:
1.对原图做数据增强
①像素级:HSV增强、旋转、缩放、平移、剪切、透视、翻转等
②图片级:MixUp、Cutout、CutMix、Mosaic、Copy-Paste(Segment)等
2.对标签做同样的增强
①变换后的坐标偏移量
②防止标签坐标越界
除了上述最基本的数据增强方法外,还使用了 Mosaic 数据增强方法,其主要思想就是将4张图片进行随机裁剪、缩放后,再随机排列拼接形成一张图片,实现丰富数据集的同时,增加了小样本目标,提升网络的训练速度。在进行归一化操作时会一次性计算4张图片的数据,因此模型对内存的需求降低。Mosaic数据增强的流程如图所示。
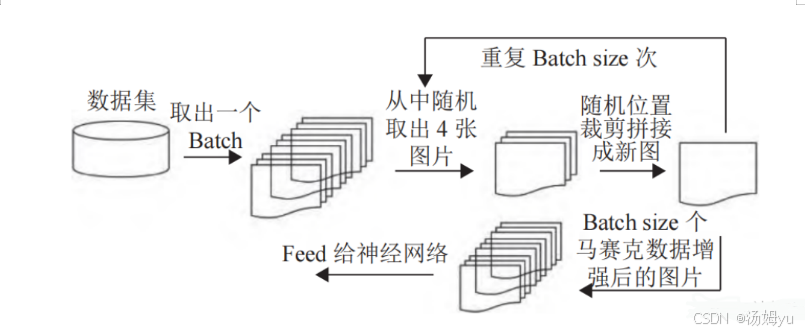
Mosaic数据增强的代码主要流程如下:
①假设模型输入尺寸为s,首先初始化一幅尺寸为2s*2s的灰色大图
②在大图中从点A(s/2, s/2)和点B(3s/2, 3s/2)限定的矩形内随机选择一点作为拼接点
③随机选择四张图,取其部分拼入大图,超出的部分将被舍弃
④根据原图坐标的偏移量,重新计算GT框的坐标,并使用np.clip防止更新后的标签坐标越界
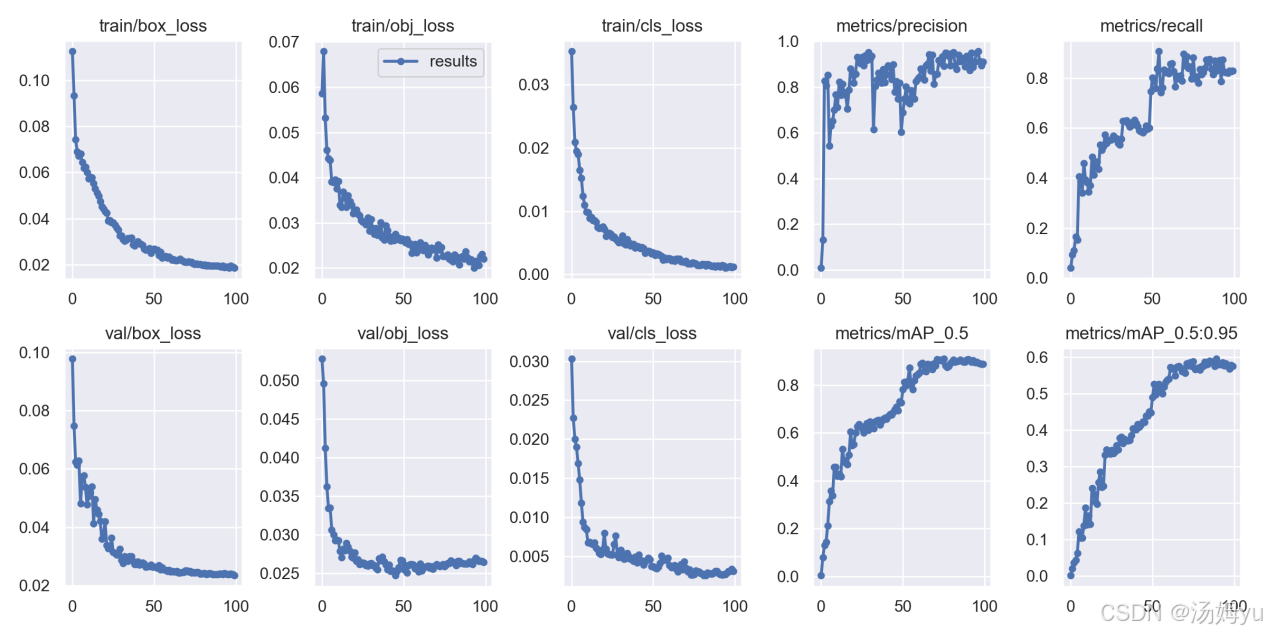
4. 软件设计结果展示

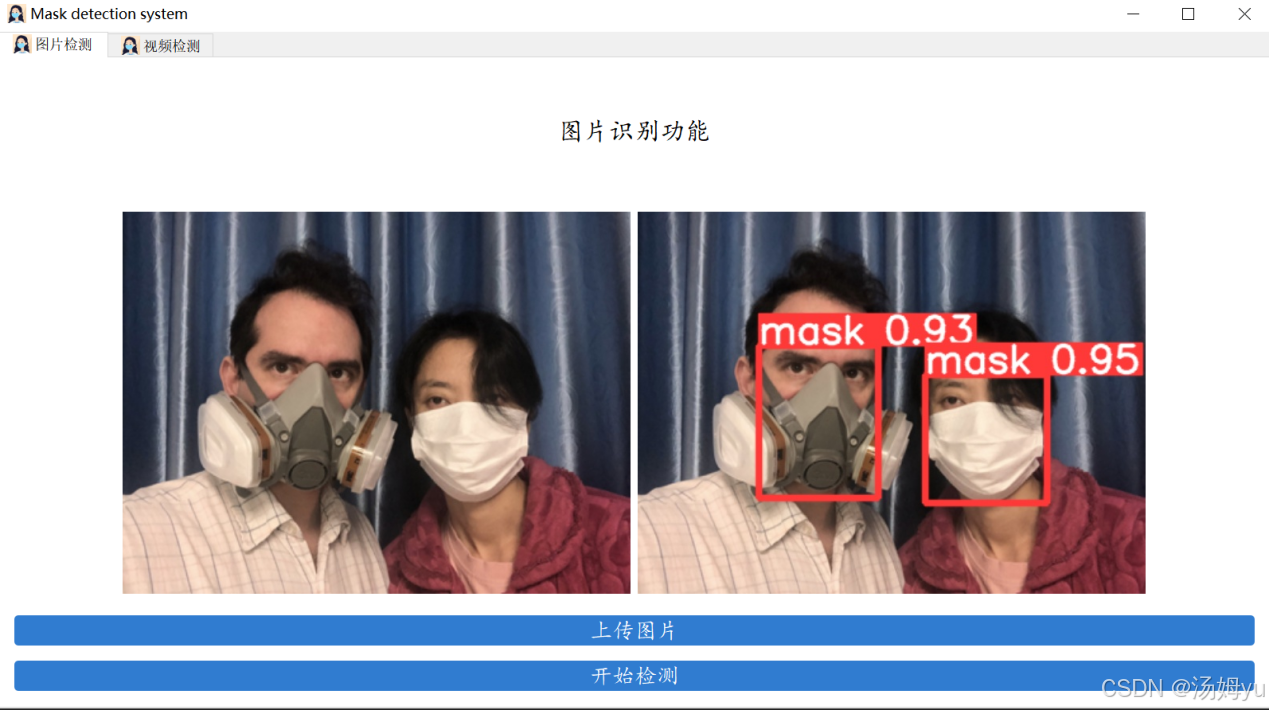

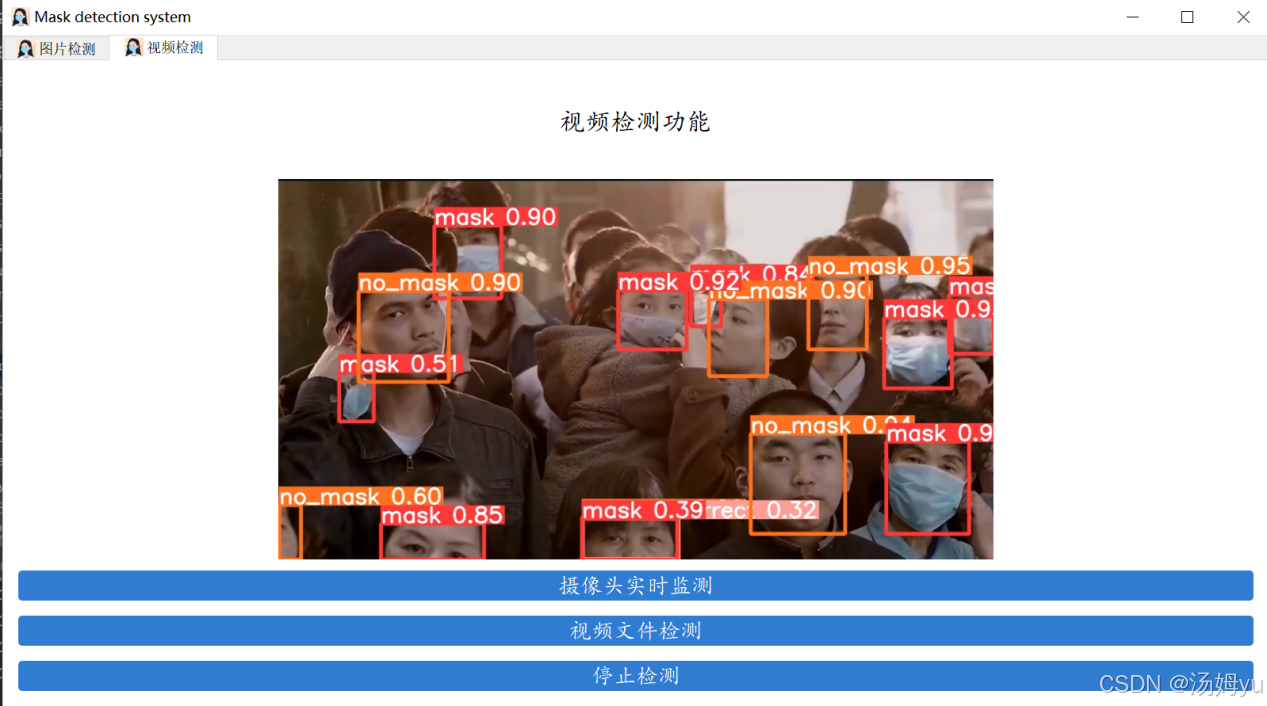
5. 心得体会
随着深度学习和计算机视觉的快读发展,与此有关的技术设备已经被大幅度的使用,并且不仅仅在这两个方面,更在许许多多的领域都有使用。众所周知,图像理解之中的最重要的一个步骤即为目标检测,和为目标检测,其实很简单,在捕获的大量图像信息之中,选取最为感兴趣的目标,并且进一步确定它们的各类信息,如位置大小等等,如此的工作正是机器视觉这一领域之中的关键核心之一。目标检测是计算机视觉领域中的基础,因为其关于着物体的分类任务,还有物体的定位任务,所以该项技术对于图像理解的重要程度不言而喻。
本系统通过对对传入的图片进行一系列预处理,通过不断减弱外界的因素来对于口罩佩戴的影响,我们采用了yolov5深度卷积网络对爬虫爬取到的口罩佩戴检测数据集来进行数据处理训练,并在数据集上多次训练,最终实现了对于口罩佩戴情况的检测取得了较为理想的效果,这说明该次实验是有价值的,证明该方法是有价值的,但是期间仍存在部分问题,例如图片中人脸遮挡过多或者非常不清晰的情况下,本模型有可能会误识别,这种情况下对于口罩佩戴的检测却并不理想,之后的改进可以从这点出发,来进一步改善网络设计,提升检测精确度,提高检测效率与成绩。
我认为,这次实验,不仅培养了独立思考、动手操作的能力,在各种其它能力上也都有了提高。更重要的是,在实验课上,我们学会了很多学习的方法。而这是日后最实用的,真的是受益匪浅。要面对社会的挑战,只有不断的学习、实践,再学习、再实践。这对于我们的将来也有很大的帮助。以后,不管有多苦,我想我们都能变苦为乐,找寻有趣的事情,发现其中珍贵的事情
回顾起此课程设计,至今我仍感慨颇多,从理论到实践,在这段日子里,可以说得是苦多于甜,但是可以学到很多很多的东西,同时不仅可以巩固了以前所学过的知识,而且学到了很多在书本上所没有学到过的知识。通过这次课程设计使我懂得了理论与实际相结合是很重要的,只有理论知识是远远不够的,只有把所学的理论知识与实践相结合起来,从理论中得出结论,才能真正为社会服务,从而提高自己的实际动手能力和独立思考的能力。在设计的过程中遇到问题,可以说得是困难重重,但可喜的是最终都得到了解决。