在 iOS 上,App 在启动 / 退出 / 响应系统事件等关键阶段如果长时间卡住,超过系统阈值就会触发保护机制,最终被 Watchdog 以 SIGKILL 强制终止。这类异常的共同特点是:不是进程内异常抛出,而是"进程外指令"直接结束进程,因此传统基于 signal/exception 的崩溃捕获往往覆盖不到,也就导致它在生产环境中经常"只见数据、不见堆栈",长期被忽视。
为了解决这个盲区,我选择站在巨人的肩膀上:本文实践并复现字节跳动团队的文章《iOS 稳定性问题治理:卡死崩溃监控原理及最佳实践》,从 原理 → 代码实现 → 候选文件保存 → dSYM/atos/脚本符号化 + Swift demangle,把一整套卡死(ANR/Watchdog)监控链路完整跑通,并沉淀成一个可复用 Demo。
文末给出完整代码链接
1. 痛点:卡死最难的不是"知道卡",而是"知道卡在哪"
线上卡死/假死常见现象:
- UI 不响应(点击无反应、滑动卡住),几秒后恢复或被系统杀掉
- Crash 日志没有(不是进程内 crash),只剩用户反馈:"刚刚卡住了"
- 拿到的堆栈是一堆
0x00000001....地址:不符号化就等于没有结论
所以要解决这类问题,本质是两件事:
- 卡死当下抓到主线程堆栈(或卡死期间持续采样)
- 自动符号化:把地址变成可读函数名,并尽可能 demangle Swift 符号
2. 原理:RunLoop 心跳 + 超阈值采样 = 还原卡死现场
2.1 监控"主线程卡死"的本质
主线程 RunLoop 正常情况下会不断在这些状态间流转:
BeforeTimersBeforeSourcesBeforeWaitingAfterWaiting
当主线程执行重任务(大解析 / 同步 IO / 复杂布局 / 锁等待等),RunLoop 会长期卡在某个阶段不动,表现为 UI 无响应。
2.2 本 Demo 的检测策略(尽量向"抖音方案"靠拢)
Demo 采用的策略(参数对齐你当前实现):
- 阈值:8 秒 (
hangThreshold = 8) - 检测周期:1 秒窗口 (
tickInterval = 1) - 超过阈值后:每秒采样一次主线程栈 (从 Live Report 中提取
Thread 0) - 最多保留 10 帧样本 (
maxMainThreadSamples = 10,保留最近 10 次)
这套策略的意义是:
先判断"已经卡死到足够严重"(接近 Watchdog 风险),再进入"持续采样",避免把轻微卡顿也当成卡死去抓栈/写文件。
3. Demo 实现结构
3.1 项目目录骨架
text
LagMonitorDemo/
├── LagMonitorDemo.xcodeproj
├── Sources/
│ └── Monitor/
│ ├── HMDANRMonitor.swift
│ ├── HMDLiveReportCapture.swift
│ ├── HMDANRRecord.swift
│ ├── HMDANRCandidateStore.swift
│ └── HMDDebugCacheCleaner.swift
├── Scripts/
│ └── hmd_anr_symbolicate.py
└── Samples/
├── hmd_anr_candidate.json
└── symbolicated.txt3.2 Monitor:HMDANRMonitor.swift(核心监控器)
3.2.1 监控目标
- 主线程装
CFRunLoopObserver,每次回调认为 RunLoop 推进:heartbeat += 1 - 监控线程用 1 秒观察窗口 检查
heartbeat是否变化- 1 秒内有推进:健康/恢复,清理候选
- 1 秒内无推进 :认为卡住,
hangSeconds += 1
- 卡住累计达到 8 秒阈值:创建 candidate
- 超阈值后仍未恢复:每秒采样一次主线程栈,最多 10 帧
3.2.2 为什么看起来"没 sleep 1 秒",却实现了"每秒检查一次"?
核心就在这一句:
swift
_ = wakeSemaphore.wait(timeout: .now() + .seconds(config.tickInterval))它等价于:
- 最多等待 1 秒 (
tickInterval = 1)作为一个观察窗口 - 如果期间 RunLoop 有推进,observer 会
signal()→ 监控线程会提前醒来 - 窗口结束后比较
heartbeat:若 1 秒内完全没变,才算这一秒"卡住"
所以这里不是"固定每秒到点触发一次",而是:
"最多等 1 秒,但只要 RunLoop 一推进就立刻醒来重置状态"
这比 Timer 的"固定周期触发"更贴合我们想观察的对象(RunLoop 推进)。
3.2.3 为什么不用 NSTimer / GCD 定时器,而用信号量?
Timer 触发本身就依赖调度与 RunLoop/线程状态,卡死时最容易抖动或延迟;信号量 + 超时是更稳定的"观察窗口",还能被 RunLoop 推进即时唤醒。
3.3 抓栈:HMDLiveReportCapture.swift(PLCrashReporter Live Report)
抓栈使用 PLCrashReporter 的 Live Report 能力:
generateLiveReportAndReturnError():生成"当下全线程现场"- 再从文本中提取
Thread 0作为主线程样本
swift
import CrashReporter
/// 抓一次"全线程现场报告"
static func captureAllThreadsText() -> String? {
let config = PLCrashReporterConfig(signalHandlerType: .BSD, symbolicationStrategy: .all)
guard let reporter = PLCrashReporter(configuration: config) else { return nil }
do {
let data = try reporter.generateLiveReportAndReturnError()
let report = try PLCrashReport(data: data)
return PLCrashReportTextFormatter.stringValue(for: report, with: PLCrashReportTextFormatiOS)
} catch {
print("[HMDLiveReportCapture] parse report error: \(error)")
return nil
}
}这里的思路就是:
卡死现场抓"全线程",用于兜底;超阈值后持续采"主线程",用于定位稳定卡点。
3.4 保存:HMDANRCandidateStore.swift(hmd_anr_candidate.json)
Demo 保存的核心数据结构是 HMDANRRecord,通过 Codable 编码为 JSON:
swift
public struct HMDANRRecord: Codable {
public let recordID: String
public let timestamp: Date
public var hangSeconds: Int
/// 超过阈值那一刻:全线程现场(PLCrash live report,文本)
public var allThreadsReportText: String?
/// 超阈值后:每秒采样主线程调用栈(最多保留最近 N 条)
public var mainThreadSamples: [String]
}保存到 Caches/hmd_anr_candidate.json 后,大致字段长这样:
json
{
"recordID": "E2D0...-....",
"timestamp": "2026-01-05T12:34:56Z",
"hangSeconds": 9,
"allThreadsReportText": "PLCrashReporter live report text ...",
"mainThreadSamples": [
"Thread 0 ...\n0 LagMonitorDemo 0x...\n1 UIKitCore ...",
"Thread 0 ...\n0 LagMonitorDemo 0x...\n1 UIKitCore ..."
]
}
HMDANRCandidateStore卡住时把记录保存到缓存文件;一旦主线程恢复推进就立刻删除;如果进程被系统强杀来不及上报,这个文件会留到下次启动再读取导出/符号化。
4. 复现场景(Demo 内置)
Demo 里包含几种典型卡死触发方式:
swift
stack.addArrangedSubview(makeButton("主线程 Busy 2s(轻微卡顿)") { [weak self] in self?.busy(seconds: 2) })
stack.addArrangedSubview(makeButton("主线程 Busy 20s(触发 candidate + 采样)") { [weak self] in self?.busy(seconds: 20) })
stack.addArrangedSubview(makeButton("锁竞争:子线程持锁 12s → 主线程尝试加锁") { [weak self] in self?.lockContention() })
stack.addArrangedSubview(makeButton("死锁:串行队列 sync + 主队列 sync(必卡死)") { [weak self] in self?.deadlock() })5. 自动符号化:从 hmd_anr_candidate.json 到"可读堆栈"
我点击 "主线程 Busy 20s(触发 candidate + 采样)" ,在第 10 秒手动杀掉 App,然后导出沙盒里的 hmd_anr_candidate.json。
你会看到类似信息:
hangSeconds = 13(很明确的主线程长时间阻塞)mainThreadSamples有多次采样(证明卡住期间栈稳定)- 但这些堆栈仍然是地址/偏移,无法直接定位业务代码

因此需要做:
- 从
hmd_anr_candidate.json里解析 frame - 用 dSYM + atos 还原符号;并对 Swift 符号 demangle (
$s... → Foundation.Date.init())
本项目用脚本 hmd_anr_symbolicate.py 自动完成批量符号化:
bash
python3 hmd_anr_symbolicate.py --record hmd_anr_candidate.json --app-dsym LagMonitorDemo.app.dSYM --arch arm64 --demangle --out symbolicated.txt符号化后的symbolicated.txt的大致内容如下:
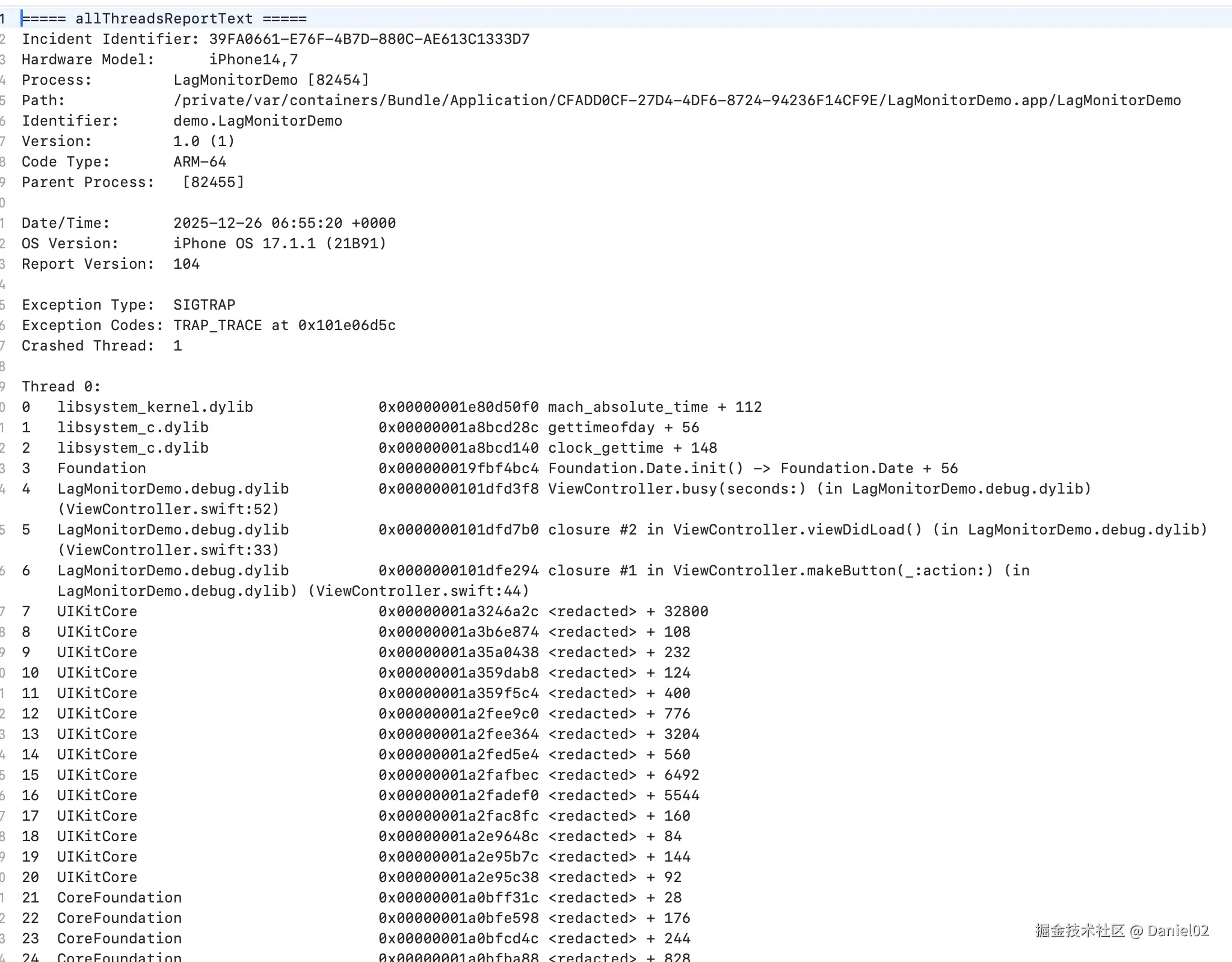
hmd_anr_symbolicate.py在GITHUB项目的Scripts文件夹下,hmd_anr_candidate.json和symbolicated.txt在Samples文件下
5.1 符号化后如何"从栈定位问题"?
从 symbolicated.txt 里抽 mainThreadSamples[0] 的关键几帧(你这次 5 次采样基本一致):
text
1 libsystem_c.dylib gettimeofday
3 Foundation Date.init
4 LagMonitorDemo.debug.dylib ... (ViewController.swift:52)
5 LagMonitorDemo.debug.dylib ... (ViewController.swift:33)
6 LagMonitorDemo.debug.dylib ... (ViewController.swift:44)
7 UIKitCore ...这说明卡死期间主线程一直在跑 ViewController.swift 的某段逻辑,并且频繁调用 Date()(最终落到 gettimeofday/clock_gettime),典型特征就是忙等/死循环式等待。
对应 Demo 中的实现:
swift
private func busy(seconds: Int) {
let end = Date().addingTimeInterval(TimeInterval(seconds))
while Date() < end {
_ = 1 + 1
}
}这类栈顶常见现象就是:看起来"卡在 Date()",其实根因是 while 循环让主线程一直跑 。
采样刚好截在
Date()这一行,于是栈顶表现为Date.init -> gettimeofday。
6. 结语:复刻的意义,是把"文章里的方案"变成"项目里能用的工具"
大厂的稳定性方案往往更深、更体系化,但很多时候只停留在文章层面:看懂了思路,却很难在项目里直接落地。本文的目标就是把它"拆开 + 跑通":
- 把抖音文章里的链路拆成可运行代码(监控、采样、保存、恢复、导出)
- 把最后一公里补齐(dSYM/atos 自动符号化 + Swift demangle)
- 让"卡死问题"从 只有 SIGKILL 数字 ,变成 能指向具体业务函数/代码行 的结论
你真正需要的不是"我们检测到了卡死",而是:
卡死那 8~20 秒内,主线程到底在跑什么?它卡在谁身上?
当你把"采样 + 保存 + 下次启动捞取 + 自动符号化 + demangle"这条链路跑通,线上卡死排查效率会明显提升。