目录
文章目录
- 目录
- 经典优化方向
- 显存优化技术
- 计算优化技术
-
- [降低计算精度(Precision Reduction)](#降低计算精度(Precision Reduction))
- [算子融合(Kernel Fusion)](#算子融合(Kernel Fusion))
- [重计算/激活检查点(Recomputation/Activation Checkpointing)](#重计算/激活检查点(Recomputation/Activation Checkpointing))
- [内存访问合并(Memory Coalescing)](#内存访问合并(Memory Coalescing))
- 分块计算(Tiling)
经典优化方向
GPU 的操作可以分为 3 类:
- 计算类(COMP):执行矩阵乘法等数值计算;负责模型的所有数值运算处理。
- 通信类(COMM):负责 GPU 设备间的数据交换与同步;通常使用 NCCL 库。
- 访存类(MEM):管理 GPU 内存分配与释放;处理主机与设备间的数据传输 H2D/D2D/D2H 等等。
理想的状态下,我们需要 GPU 的计算类工作始终在执行。但计算收到通信和访存的制约,所以如何权衡 3 者之间的协同工作就是性能优化的主要目的。
显存优化技术
显存优化技术,包括 ZeRO(Distributed Optimizer)、Checkpoint Activations、混合精度训练、Kernel Fusion 和 Flash Attention 等。
训练优化器
在 AI/ML 中,梯度下降(Gradient Descent)是一种关键的 loss 损失函数极值优化方法,根据使用的数据量不同,梯度下降可以分为 3 种不同的变体:
- Batched 梯度下降(Batch Gradient Descent) :每次更新权重时,使用整个训练集来计算损失函数的梯度。假设有 N 个样本,则每个 Weight 在反向传播后都有 N 个梯度,会先计算 N 个梯度的平均,然后使用平均值更新 Weight。
- 优点:由于使用所有的训练数据,梯度估计非常准确,收敛过程稳定。
- 缺点:当训练数据集很大时,每次计算梯度都非常耗时,而且内存需求高,不适合处理大规模数据。
- 随机梯度下降(Stochastic Gradient Descent,SGD) :每次更新模型参数时,只使用单个训练样本来计算梯度。每个 Weight 在反向传播后都只有 1 个梯度,直接使用这 1 个梯度更新 Weight。
- 优点:只用一个样本进行更新,所以计算速度快,适合大规模数据集,且内存占用较小。
- 缺点:由于梯度是基于单个样本计算的,梯度估计不准确,容易导致梯度更新过程中的 "噪声",使得收敛过程不稳定,并可能在接近最优解时出现振荡。
- Mini-batch 梯度下降(Mini-batch Gradient Descent) :介于 Batched 梯度下降和随机梯度下降之间。每次更新模型参数时,使用一小部分训练数据(即 Mini-batch)来计算梯度。
- 优点:Mini-batch 梯度下降结合了全量梯度下降和随机梯度下降的优点,计算速度比全量梯度下降快,同时比随机梯度下降更加稳定,减少了更新中的"噪声"。
- 缺点:虽然它比 SGD 更稳定,但仍然可能面临一个 mini-batch 中样本不够多,导致梯度估计仍有一定的偏差。
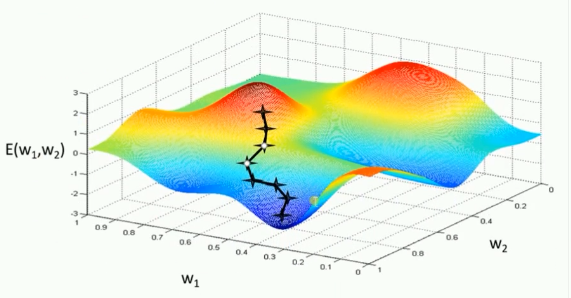
但实际上,上述传统的梯度下降优化算法在 DL 实践中非常低效且复杂。因为每个参数都有自己的 "梯度方向" 和 "学习率步长",有些参数可能需要更快地更新,而另一些则需要更慢、更稳定,如下图所示。
而训练优化器就是一种专用于高效更新 Weight、优化 loss 损失函数的自适应学习率的优化算法,其核心目标是:自适应学习率,即为每个参数自动计算其独特的学习率。
常见的有 Adam(Adaptive Moment estimation,自适应矩估计)优化器,它是一个结合了动量(Momentum)和自适应学习率(RMSprop)技术的优化算法,其旨在让模型训练得更快、更稳,减少人为调参的工作量,广泛用于 DL 的训练场景。
- 动量(Momentum)机制:管理 "梯度方向",在正确的方向加速,而在不稳定方向减速,能够有效缓解局部极小值问题。
- 自适应学习率(RMSprop)机制:管理 "学习率步长",根据历史梯度的大小,为每个参数自适应地调整学习率。例如:如果一个参数的历史梯度一直很大,说明它很不稳定,则应该给它一个很小的学习率,避免它 "跳过头"。
多种优化算法的比较如下图所示。
Adam 优化器的核心优势在于能够根据参数的更新历史自适应调整每个参数的学习率,这有助于加快收敛速度并提高训练稳定性。为了实现这一点,Adam 优化器会在 GPU 显存中维护 2 份额外的状态数据(参数矩阵)m_t 和 v_t 直到权重参数更新完成。并且这 2 份状态数据的大小和权重参数量一致,所以在计算 GPU 显存资源时需要乘以优化器的份数。
- 一阶矩(m_t,Momentum):作用于动量机制,是梯度的一阶指数移动平均,它记住了梯度的主要方向,起到了平滑噪声、正确方向加速的作用。
- 二阶矩(v_t,Variance):作用于 RMSProp 机制,是梯度平方的二阶指数移动平均,它记住了梯度的变化幅度,起到了在陡坡小步走、缓坡大步走的作用。
对应的,Adam 优化器有几个关键的超参数可以被调节:
- β₁(Beta1):一阶矩的衰减率,默认为 0.9。控制着"速度"的记忆周期。
- β₂(Beta2):二阶矩的衰减率,通常设置为 0.999。这个值非常接近 1,意味着它对历史梯度平方的记忆很长,这使得学习率调整非常平滑。
- ε(Epsilon):一个非常小的数(如 1e-8),主要是为了防止除以零的错误。
Pytorch 的 Adam 优化器实现:https://docs.pytorch.org/docs/stable/generated/torch.optim.Adam.html
虽然 Adam 优化算法相较 SGD 算法效果更好也更稳定,但 是对计算设备内存的占用显著增大。
ZeRO
零冗余优化器(Zero Redundancy Data Parallelism,ZeRO)的目标是针对模型状态的存储进行去除冗余的优化。
ZeRO 使用分区的方法,即将模型状态量分割成多个分区,每个计算设备只保存其中的一部分。这样整个训练系统内只需要维护一份模型状态,减少了内存消耗和通信开 销。
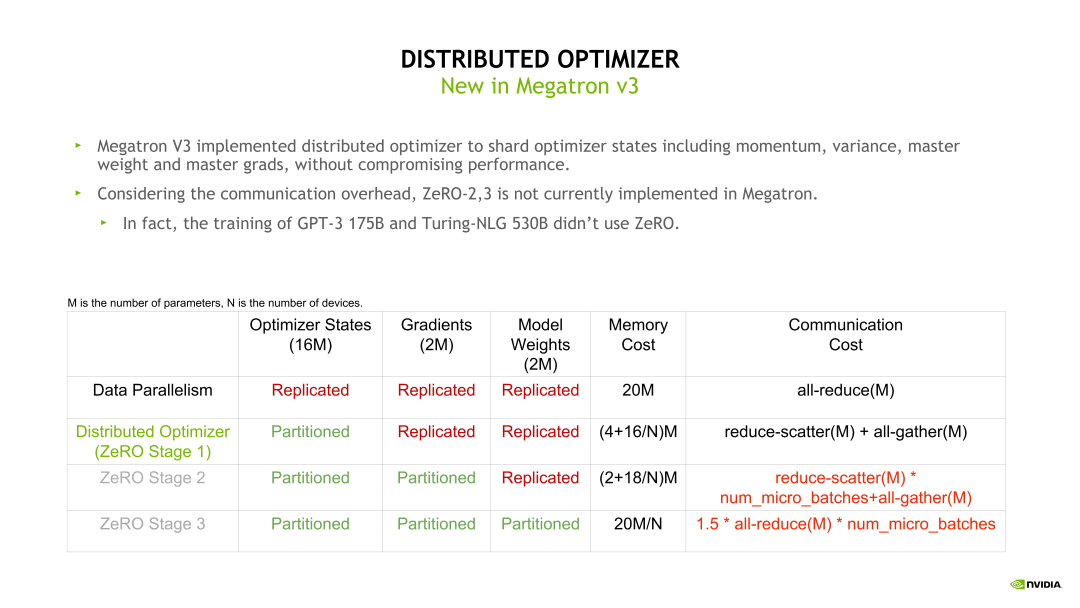
在模型训练时,Optimizer 状态是模型固定占用显存的主要部分。假如模型参数量是 m,则 Optimizer 的显存开销是 16*m 字节。Zero-1 的思想是在不同的 DP rank 上对 Optimizer 状态做拆分,所以 Distributed Optimizer(Zero-1)在每个 DP rank 占用的显存是 16 * m 除以 DP size,明显降低了显存开销,同时也带来了通信模式的改变。
例如,我们可以直接对梯度做 Reduce-scatter,之后再对自己的那一部分参数做Optimizer 相关的状态更新,Optimizer 状态更新完毕后再用一个 All-gather 操作收集模型权重。这样由 DP 并行的一个 All-reduce 变成了一个 Reduce-scatter 加上一个 All-gather。根据前面的介绍,这个 All-reduce 的通信量是 Reduce-scatter 或 All-gather 的两倍,所以整体的通信量是没有变化的,但通信的次数变多了。
其次,使用比较多的是 Zero-2 和Zero-3。Zero-2 和 Zero-3 需要每次进行额外的 forward 和 backward 计算,并且每次都需要做通信,但是流水线并行会将一个大的 batch 拆分成很多个小的 forward 和 backward,也就会造成大的通信量。所以当同时使用 Zero-2 或 Zero-3 加上流水线并行时,通信量会大幅上升,因此这里不推荐大家同时使用流水线并行和 Zero-2 或 Zero-3,但流水线并行可以和 Zero-1 同时使用。
DP 是最常用的并行策略,因为它与其他并行策略正交,实现简单并且通信量相对不是很大,很容易扩展训练的规模。但是 DP 也存在一个比较明显的问题:在每个 DP Group 内都有完整的模型、优化器状态和梯度副本,导致内存开销比较大。
为了解决内存开销大的问题,微软提出了 ZeRO,可以根据不同的程度充分将优化器状态(os)、梯度(g)和模型参数(p)切分到所有的 GPU 中,也就是不同的 DP Group 中会存储不同的优化器状态、梯度和参数切片。
- ZeRO-0:禁用所有类型的分片,仅做存粹的 DP。
- ZeRO-1(P_os):对优化器状态进行分片,占用内存为原始的 1/4,通信容量与数据并行性相同。将优化器状态切分到所有 GPU,每块 GPU 还有全量的模型参数和梯度。先切分优化器状态是因为其占用内存更多,并且与 Forward 和 Backward 的反向传播无关,只影响 Backward 的权重参数更新阶段。由于 ZeRO-1 中每个 GPU 只需要对应部分的平均梯度,而不像传统 DP 那样需要梯度的 all-gather,因此总的通信量不变。也就是说,在极大降低显存开销的情况下并不会增加通信量,所以常见的并行方案中基本都会默认采用 ZeRO-1。
- ZeRO-2(P_os+g):对优化器状态和梯度进行分片,占用内存为原始的 1/8,通信容量与数据并行性相同。在 ZeRO-1 的基础上进一步切分梯度,切分梯度不影响 Forward 过程。
- ZeRO-3(P_os+g+p):对优化器状 态、梯度及模型参数进行分片,内存减少与数据并行度和复杂度成线性关系,同时通信容量是数 据并行性的 1.5 倍。在 ZeRO-2 的基础上进一步切分模型参数,会影响 Forward 阶段,需要 all-gather 所有参数才能计算,会引入更多通信。采用 ZeRO-3 几乎可以将内存需求降低到 1/N,其中 N 表示 GPU 数量。
- ZeRO-Infinity:是 ZeRO-3 的拓展,允许通过使用 NVMe 固态硬盘扩展 GPU 和 CPU 内存来训练大语言模型。
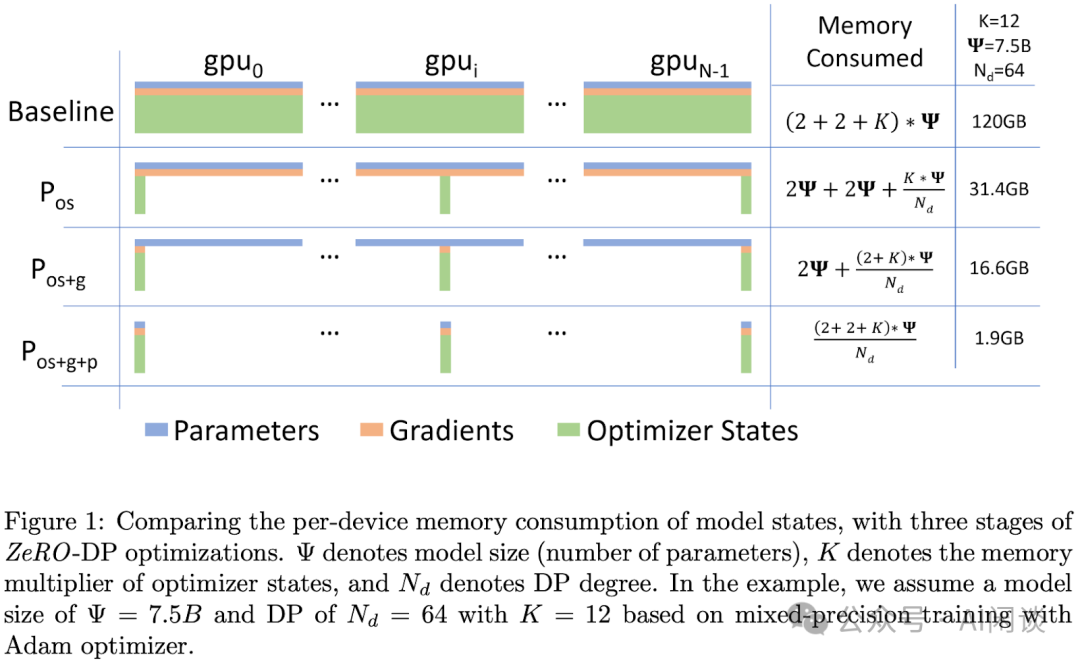
- 对 Adam 优化器状态进行分区,图中的 Pos 部分。模型参数和梯度依然是每个计算设备保存一份。此时,每个计算设备所需内存是 4Φ + 12Φ/N 字节,其中 N 是计算设备总数。当 N 比较大时,每个计算设备占用内存趋向于 4ΦB,也就是 16ΦB 的 1/4。
- 对模型梯度进行分区,图中的 Pos+g 部分。模型参数依然是每个计算设备保存一份。此时,每个计算设备所需内存是 2Φ + (2Φ+12Φ)/N 字节。当 N 比较大时,每个计算设备占用内存趋向于 2ΦB,也就是 16ΦB 的 1/8。
- 对模型参数进行分区,图4.17 中的 Pos+g+p 部分。此时,每个计算设备所需内存是 16Φ/N B。当 N 比较大时,每个计算设备占用内存趋向于 0。
Zero-1 和 Zero-2 对整体通信量没 有影响,虽然对通信有一定延迟影响,但是整体性能受到的影响很小。Zero-3 所需的通信量则是 正常通信量的 1.5 倍。
Checkpointing activation
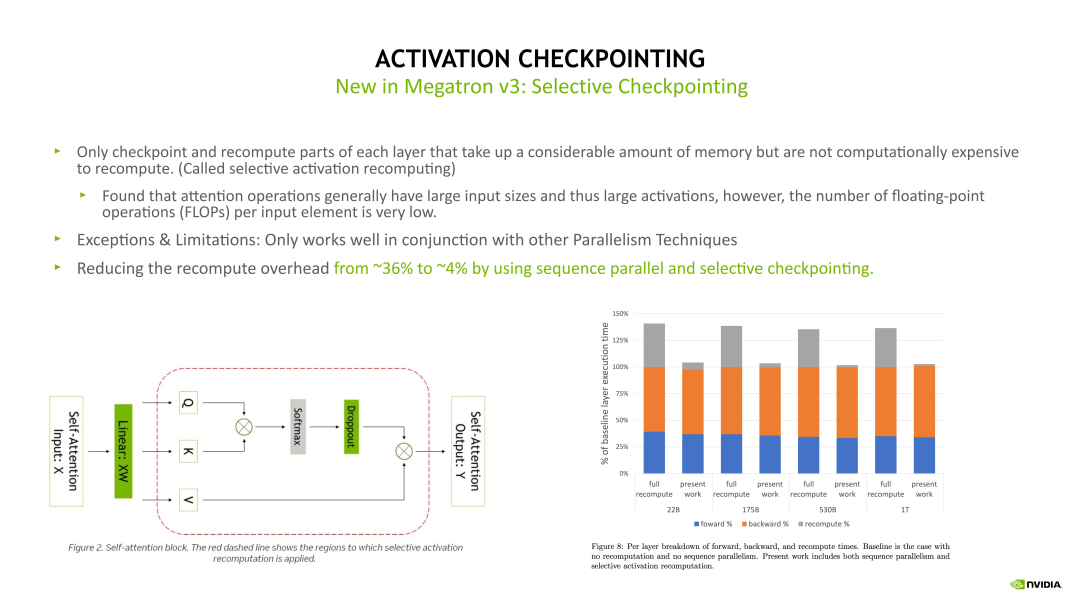
其中 Selective Activation Checkpoint 是目前 Megatron 中用的比较多的,也是比较高效的一个 Checkpoint 技术。Checkpointing activation 就是做重新计算。例如在 Forward 计算时得到的 Activation 不再保留,做 Backward 计算时,对这些 Activation 进行重新计算,这样可以极大程度上减少对 GPU 显存的开销。Checkpointing activation 的实现方式有下边示意图列出来的几种。
其中一种比较 Native 的实现是 Full checkpointing,也即对 Transformer 的每个层都进行重新计算。例如在最后一层做 Backward 计算时,需要这个 Transformer layer 在 Backward 计算之前重新执行一次 Forward 计算,当重新计算 Forward 后再开始这个层的 Backward 计算。Full checkpointing 对每个 Transformer layer 都打了一个重算点。所以 Full checkpointing 的好处在于将显存开销降低到 O(n) 的复杂度,而不足在于对每个 Transformer layer 都要重新计算一遍,从而带来了近 36% 的额外计算开销。

另一个优化 Activation 的方式是 Sequence Parallelism 加上 Selective checkpointing,将这个重算的开销从 36% 降低到 4%。Selective checkpointing 会选择一些重算性价比高的 OP,对一些计算时间比较小但产生 Activation 占用的显存很大的 OP 进行重算。例如下边示例图左边的 Self-attention 模块,通过对比分析后得出,对 Self-attention 这块做重算的收益是非常高的,因为它的计算量相对会少一点,但它的一些中间结果输出占用的显存开销非常大。因此我们就可以只对这块做重算。对其他的层,例如 Linear 和 Layernorm 层,可以采用其他的优化方法对 Activation 进行优化。
Selective checkpointing 的核心思想是对一些性价比高的 OP 做重算,并与其他的并行优化方法联合使用,达到 1+1>2 的效果。
混合精度训练
混合精度训练(Mixed PrecisionTraining)方式,即同时存在F P3 与 FP16 或者 BF16 格式。
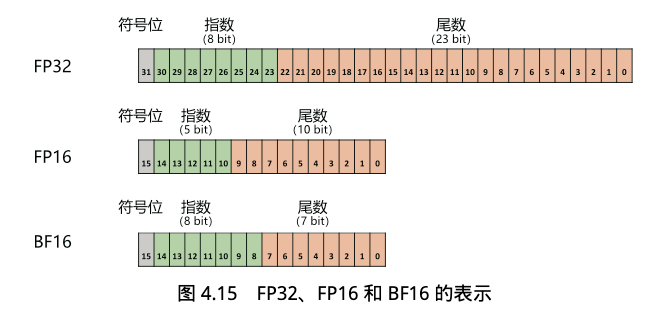
- FP32 中第 31 位为符号位,第 30 位∼第 23 位用于表示指数,第 22 位∼第 0 位用于表示尾数。
- FP16 中第 15 位为符号位,第 14 位∼第 10 位用于表示指数,第 9 位∼第 0 位用于表示尾数。
- BF16 中第 15 位为符号位,第 14 位∼第 7 位用 于表示指数,第 6 位∼第 0 位用于表示尾数。
由于 FP16 的值区间比 FP32 的值区间小很多,所以 在计算过程中很容易出现上溢出和下溢出。BF16 相较于 FP16 以精度换取更大的值区间范围。
由 于 FP16 和 BF16 相较 FP32 精度低,训练过程中可能会出现梯度消失和模型不稳定的问题,因此, 需要使用一些技术解决这些问题,例如动态损失缩放(Dynamic Loss Scaling)和混合精度优化器(Mixed Precision Optimizer)等。
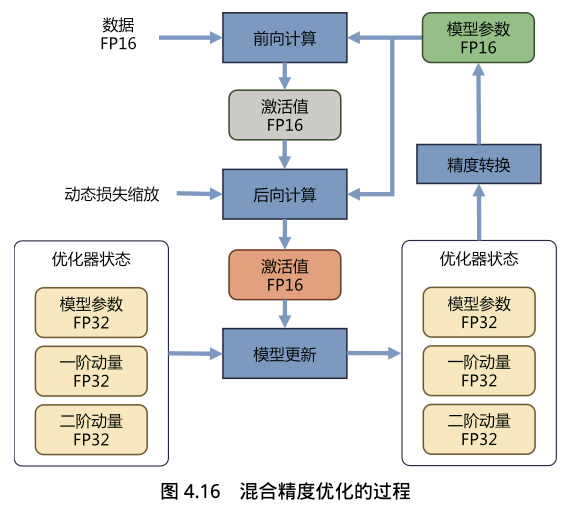
混合精度优化的过程如下图所示。Adam 优化器状态包括采用 FP32 保存的模型参数备份, 一阶动量和二阶动量也都采用 FP32 格式存储。假设模型参数量为 Φ,模型参数和梯度都是用 FP16 格式存储,则共需要 2Φ + 2Φ + (4Φ + 4Φ + 4Φ) = 16Φ 字节存储。其中,Adam 状态占比 75%。动态损失缩放在反向传播前,将损失变化(dLoss)手动增大 2K 倍,因此反向传播时得到的激活函数梯度不会溢出;反向传播后,将权重梯度缩小 2K 倍,恢复正常值。
举例来说,有 75 亿个参数 的模型,如果用 FP16 格式,只需要 15GB 计算设备内存,但是在训练阶段,模型状态实际上需要耗费 120GB 内存。计算卡内存占用中除了模型状态,还有剩余状态(Residual States),包括激活值(Activation)、各种临时缓冲区(Buffer)及无法使用的显存碎片(Fragmentation)等。
可以使用激活值检查点(Activation Checkpointing)方式使激活值内存占用大幅减少,因此如何减少模型状态尤其是 Adam 优化器状态是解决内存占用问题的关键。
计算优化技术
降低计算精度(Precision Reduction)
使用更低精度的数据类型(FP16, BF16, INT8)是最高效的 GPU 优化手段之一。其核心优势体现在两个方面:
- 减少内存带宽压力
- 利用专用计算单元
更低的数据精度意味着每个参数占用的比特数更少。在计算密集型任务中,这意味着在计算量(FLOPs)不变的情况下,需要从内存中读取和写入的数据量(Bytes)成比例减少。这直接降低了对内存带宽的压力,对于内存瓶颈(Memory-Bound)的算子尤其有效。
识别 memory bound 类型并做出针对性优化是关键。
- 横轴(计算强度):代表每字节内存访问平均发生了多少次计算(FLOPs/Byte)。
- 纵轴(性能):代表实际达到的计算性能(GFLOPs/s)。
Roofline 模型是一种直观的性能分析模型。高效利用 GPU 的关键在于让计算任务处于计算瓶颈(Compute-Bound)区域,而非内存瓶颈(Memory-Bound)区域。优化工作的核心就是通过各种手段将应用性能推向屋顶线。
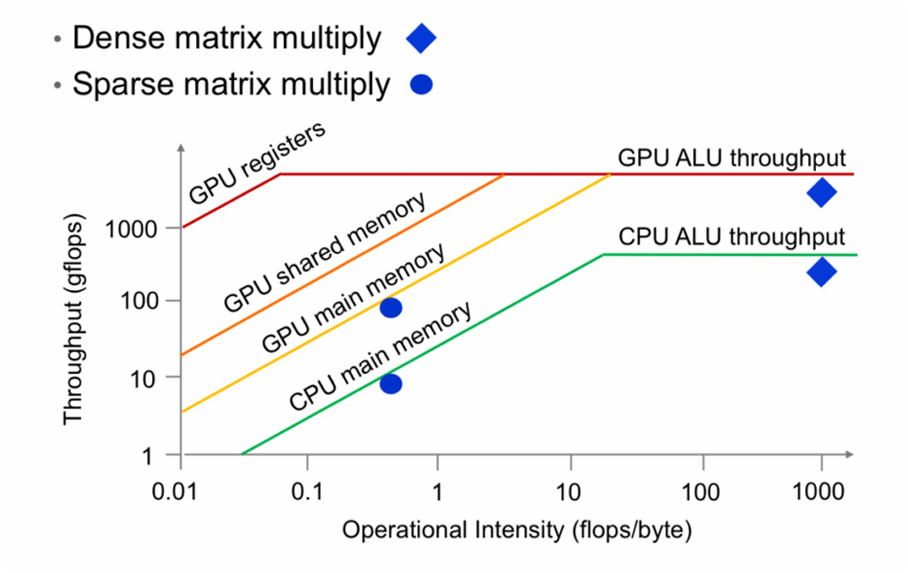
以一个简单的 ReLU 操作为例,我们可以量化其计算强度(Arithmetic Intensity),即每字节内存访问对应的计算次数。
- FP32:每次操作需要读写 8 字节数据,执行 1 次浮点运算,计算强度为 1⁄8 FLOPs/Byte。
- FP16:每次操作需要读写 4 字节数据,执行 1 次浮点运算,计算强度为 1⁄4 FLOPs/Byte。
如此,精度减半,计算强度翻倍,程序更不容易受到内存带宽的限制。

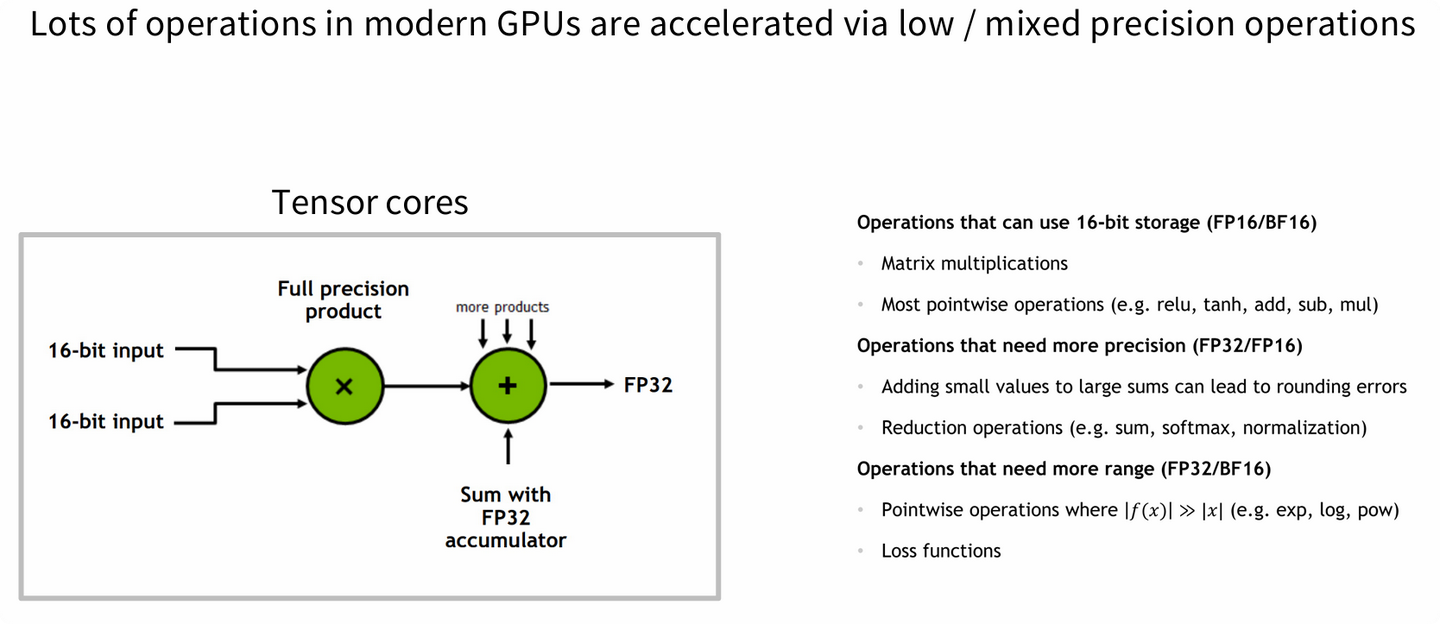
GPU Tensor Cores 旨在极大地加速特定精度的矩阵乘加(MMA)运算。它们采用混合精度计算模式:以低精度(如 FP16, BF16, INT8)输入进行乘法,但在高精度(FP32)累加器中进行求和,从而在保证速度的同时,最大限度地减少了精度损失。
Tensor Core 接收两个 16-bit 的输入,执行乘法后,将结果与一个 32-bit 的累加值相加,最终输出一个 32-bit 结果。这种设计使得 GPU 能够以远超通用计算单元(CUDA Cores)的速度执行矩阵运算。
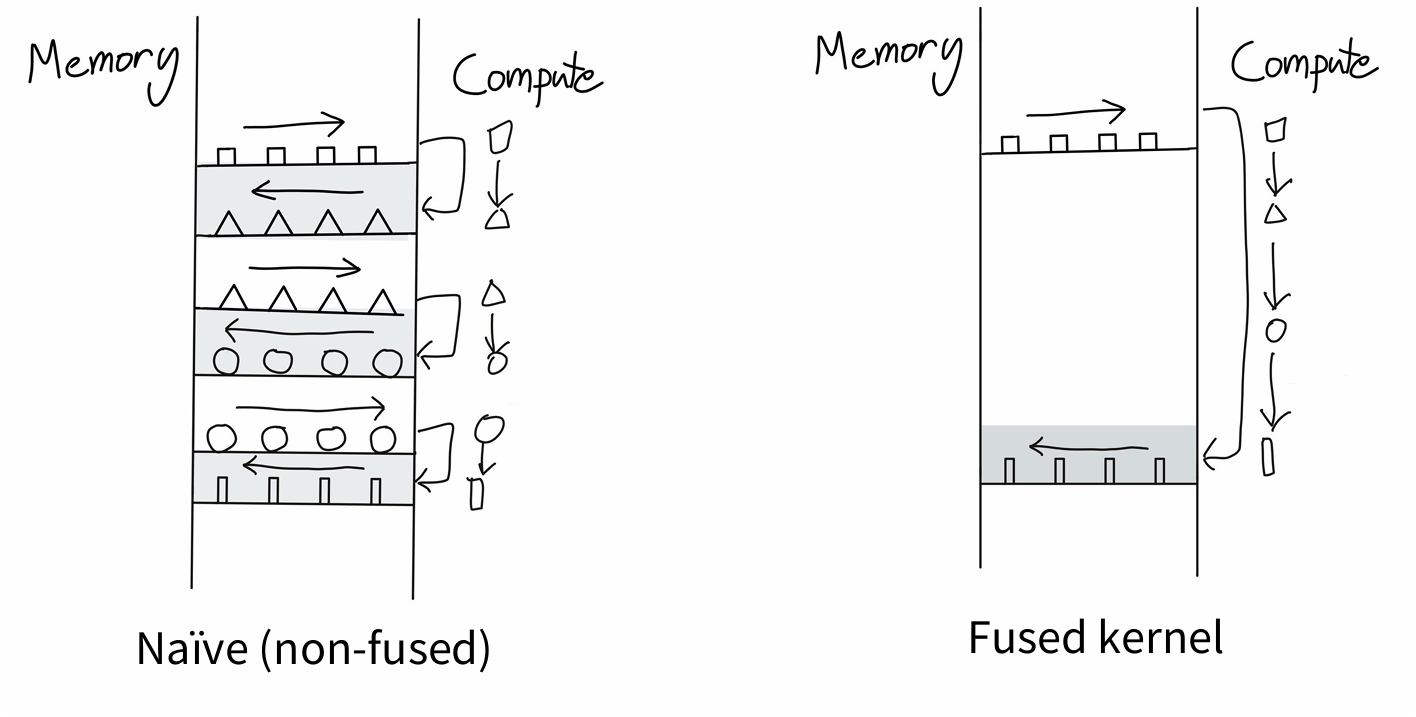
算子融合(Kernel Fusion)
将多个连续执行的核函数(Kernel)合并为一个核函数。优势:
- 减少启动多个小核函数的开销。
- 避免中间结果写回和读取慢速的全局内存,直接在快速的寄存器或共享内存中进行数据传递。
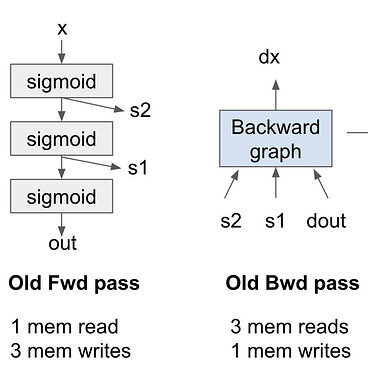
重计算/激活检查点(Recomputation/Activation Checkpointing)
不保存 Forward Pass 中的中间激活值(节省显存),而是在 Backward Pass 的时候重新计算它们。这是一种用算力换显存的策略。
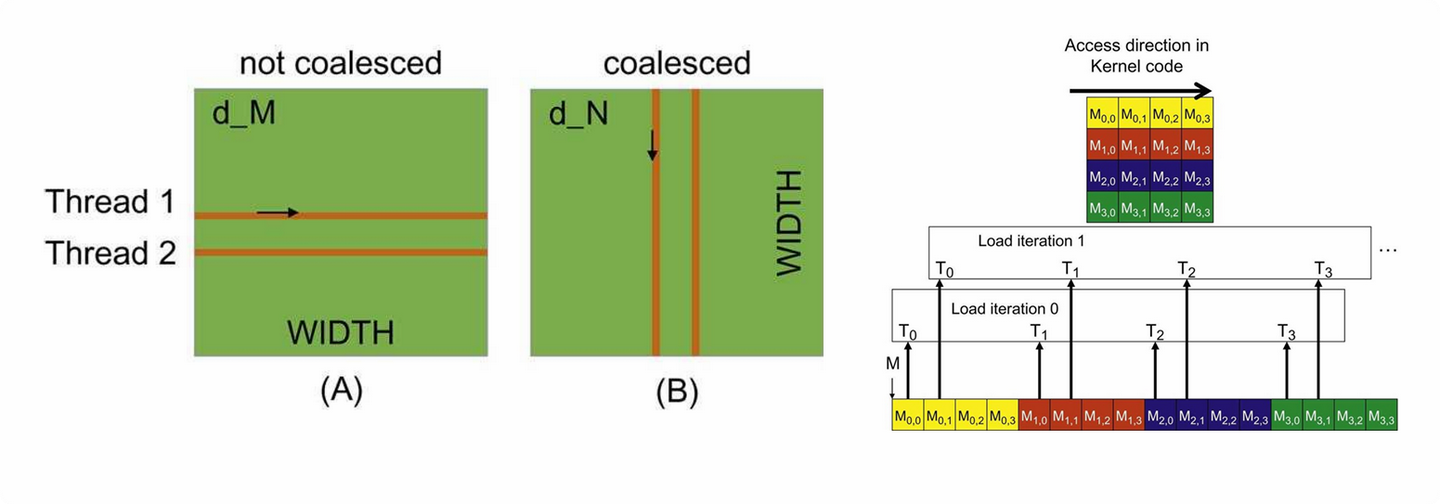
内存访问合并(Memory Coalescing)
组织线程的内存访问模式,使得同一个线程束(Warp)中的线程访问全局内存中连续对齐的内存地址。这样多个内存请求可以被合并成一个大的事务,极大提高内存带宽利用率。
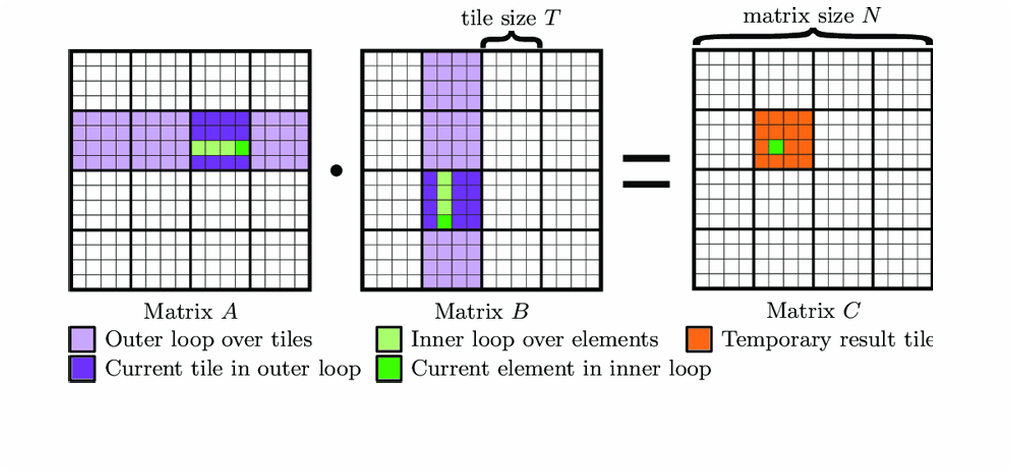
分块计算(Tiling)
将大型数据集的计算分解为更小的 "块" 或 "瓦片 (Tile)",使其能够放入高速的共享内存或寄存器中进行计算。这是充分利用内存层次结构、减少低速全局内存访问的关键技术。