DNN深度神经网络:结构、训练与优化全指南
导读:
深度神经网络(DNN)作为深度学习的核心基础,是图像分类、自然语言处理、时序预测等众多AI任务的核心驱动力。从基础的层结构设计到复杂的训练调参,再到工程化的优化部署,每个环节都直接决定模型的性能与落地效果。本文将结合实战案例,全面拆解DNN的结构设计要点、训练关键技术与优化核心方案,助力开发者快速掌握DNN从搭建到落地的全流程技巧。


一、结构篇:搭建高效DNN的核心要素
DNN的结构设计是模型性能的基础,合理的层结构、激活函数与初始化策略,能让模型在训练初期就具备良好的收敛潜力。很多开发者在入门时容易陷入"堆深度"的误区,实则高效的DNN结构需要兼顾合理性与针对性。
- 层结构设计:输入、隐藏、输出层的核心逻辑
DNN的层结构遵循"输入-隐藏-输出"的三段式架构,但各层的设计需结合任务场景灵活调整。输入层需根据数据类型做适配处理:结构化数据可直接将特征维度作为输入节点数,图像数据需先展平为一维向量(如28×28的MNIST图像展平为784个节点);隐藏层的数量与节点数是结构设计的核心,过少易导致欠拟合,过多则会增加训练成本并引发过拟合,通常建议采用"逐步递减"的节点设计(如输入层784节点→隐藏层256节点→隐藏层128节点);输出层需匹配任务类型,分类任务采用与类别数一致的节点数并搭配Softmax激活,回归任务采用1个节点且不使用激活函数。
- 激活函数选择:Sigmoid、ReLU、Tanh的适用场景
激活函数是DNN引入非线性的关键,不同函数的特性直接影响模型收敛效率。Sigmoid函数输出范围为(0,1),适合二分类任务的输出层,但存在梯度消失问题,不建议在隐藏层使用;Tanh函数输出范围为(-1,1),相比Sigmoid解决了零均值偏移问题,但梯度消失问题仍未得到根本改善;ReLU函数(f(x)=max(0,x))有效缓解了梯度消失问题,计算效率高,是目前隐藏层的首选,但在负区间存在"死亡ReLU"问题,可通过Leaky ReLU(f(x)=max(αx,x),α通常取0.01)进行优化。实际开发中,隐藏层优先选择ReLU,二分类输出层用Sigmoid,多分类输出层用Softmax。
- 权重初始化与过拟合防治:从源头提升模型稳定性
权重初始化不当会导致模型训练停滞,常用的Xavier初始化与He初始化需根据激活函数匹配使用:Xavier初始化适用于Sigmoid、Tanh等对称激活函数,通过使输入输出方差一致缓解梯度消失;He初始化适用于ReLU系列激活函数,在Xavier基础上增加了2倍的缩放系数,适配ReLU的非对称输出特性。代码实现上,PyTorch已内置相关函数,如nn.init.xavier_uniform_()、nn.init.kaiming_normal_()。
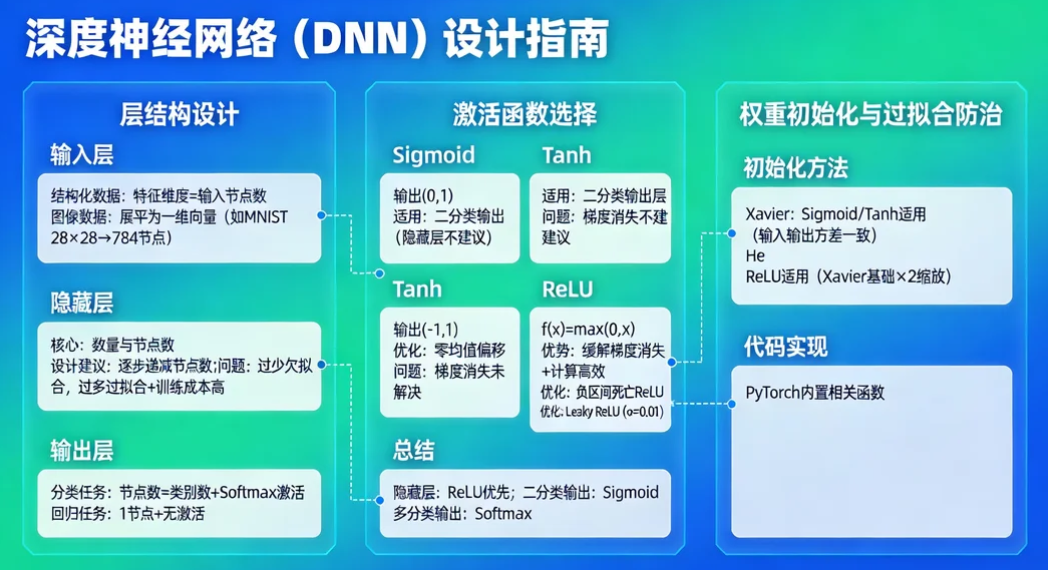
过拟合是DNN训练中的常见问题,Dropout与Batch Normalization(BN)是实战中最有效的解决方案。Dropout通过在训练时随机丢弃部分隐藏层节点(如dropout_rate=0.5),强制模型学习更鲁棒的特征,测试时需恢复所有节点并对输出进行缩放;BN通过对每批数据进行标准化处理(均值为0、方差为1),加速模型收敛并提升稳定性,通常放在卷积层或全连接层之后、激活函数之前。
二、训练篇:高效收敛的关键技术与调参策略
如果说结构设计是DNN的"骨架",那么训练过程就是为其注入"灵魂"的核心环节。损失函数、优化器、学习率等参数的选择,直接决定模型能否快速收敛到最优解。
- 损失函数:分类与回归的差异化选择
损失函数的核心作用是衡量模型预测值与真实值的差距,需根据任务类型精准匹配。分类任务中,二分类问题常用二元交叉熵损失(Binary Cross-Entropy),多分类问题常用 categorical 交叉熵损失(Categorical Cross-Entropy),若标签为整数形式(如0,1,2),可使用稀疏 categorical 交叉熵损失(Sparse Categorical Cross-Entropy)避免独热编码;回归任务中,均方误差(MSE)是最常用的损失函数,适用于连续值预测(如房价、股票价格),若存在异常值,可选用平均绝对误差(MAE)提升鲁棒性。
- 优化器对比:SGD、Adam、RMSprop怎么选?
优化器的核心作用是更新模型参数以最小化损失函数,不同优化器在收敛速度与稳定性上各有优劣。SGD(随机梯度下降)是最基础的优化器,通过随机选取单个样本更新参数,虽训练速度慢,但泛化能力较强,适合数据量较大的场景,配合动量(Momentum)可缓解收敛震荡;RMSprop通过自适应调整学习率,解决了SGD学习率单一的问题,适合非平稳目标函数;Adam结合了Momentum与RMSprop的优点,既具备动量的加速收敛特性,又能自适应调整学习率,是目前大多数DNN任务的首选优化器。实战建议:入门场景优先用Adam,追求极致泛化性可尝试SGD+动量。
- 学习率调度与批量大小:训练效率的核心调参点
学习率是影响模型收敛的最关键超参数,过大易导致不收敛,过小则训练过慢。固定学习率难以适配全训练过程,因此需要采用学习率调度策略:Step调度(每隔一定epoch降低学习率,如每10个epoch乘以0.1)、Cosine调度(学习率随epoch呈余弦曲线变化,适合后期精细收敛)、Warm-up调度(训练初期用小学习率预热,避免初始梯度震荡)。PyTorch的torch.optim.lr_scheduler模块已实现多种调度策略,可直接调用。
批量大小的选择需平衡训练效率与模型性能:小批量(如32、64)训练时梯度波动大,泛化能力较强,但训练速度慢;全批量训练时梯度稳定,训练速度快,但易陷入局部最优且内存消耗大。实际开发中,建议根据显卡内存选择32或64的批量大小,若内存充足可尝试128,同时配合学习率调整(批量增大时学习率可适当放大)。此外,训练过程中通过TensorBoard可视化损失与准确率曲线,能及时发现过拟合、不收敛等问题,具体实现可通过torch.utils.tensorboard.SummaryWriter完成。
三、优化篇:解决核心痛点,实现模型高效落地
DNN训练完成后,还需解决梯度消失、模型过大、部署困难等问题,才能实现工程化落地。这一阶段的优化核心是"保性能、降成本、提效率"。
- 梯度消失与爆炸:成因与解决方案
梯度消失与爆炸是深层DNN的典型问题,本质是梯度在反向传播过程中被不断放大或衰减。检测方法可通过打印各层梯度的绝对值均值,若梯度趋近于0则为消失,若远大于1则为爆炸。解决方案主要有两种:一是采用ResNet的残差连接结构,通过shortcut路径直接传递梯度,有效缓解梯度消失;二是使用梯度裁剪(Gradient Clipping),对梯度的范数设置阈值,超过阈值则进行缩放,避免梯度爆炸。PyTorch中可通过torch.nn.utils.clip_grad_norm_()实现梯度裁剪。
- 超参数调优与模型压缩:平衡性能与成本
超参数调优是提升模型性能的关键步骤,常用方法有三种:网格搜索(遍历所有参数组合,效果稳定但效率低)、随机搜索(随机选取参数组合,效率高于网格搜索,适合初步调优)、贝叶斯优化(基于历史调参结果预测最优参数,效率最高,适合精细调优)。实战中可采用"先粗后细"的策略:先用随机搜索快速锁定参数范围,再用贝叶斯优化精细调优。
模型压缩与加速则是为了解决DNN部署时的内存与速度问题,核心技术包括:剪枝(移除冗余的权重参数,分为结构化剪枝与非结构化剪枝,前者更适合工程落地)、量化(将32位浮点数权重转换为16位或8位整数,降低内存消耗与计算量)、知识蒸馏(用复杂的教师模型指导简单的学生模型训练,在保证性能损失较小的前提下简化模型)。
- 部署优化:从模型到边缘设备的全流程适配
DNN模型的部署优化需兼顾不同硬件场景,核心步骤包括:模型格式转换与硬件加速。ONNX(Open Neural Network Exchange)是跨框架的模型格式标准,可将PyTorch、TensorFlow等框架训练的模型转换为ONNX格式,实现跨平台部署;TensorRT是NVIDIA推出的硬件加速引擎,可对ONNX模型进行优化(如层融合、量化),大幅提升在NVIDIA显卡上的推理速度。对于边缘设备(如手机、嵌入式设备),可采用TensorFlow Lite或PyTorch Mobile框架,对模型进行轻量化处理后部署。

四、实战案例:DNN在图像分类中的应用
理论结合实践才能快速掌握DNN的核心技术,下面以CIFAR-10图像分类任务为例,展示DNN的完整实现流程。
- 数据准备:使用PyTorch的torchvision.datasets.CIFAR10加载数据集,进行归一化、随机裁剪、翻转等数据增强操作;2. 模型搭建:设计输入层(3×32×32展平为3072节点)、隐藏层(256节点+ReLU+Dropout(0.5)、128节点+ReLU+Dropout(0.5))、输出层(10节点+Softmax);3. 训练配置:选用Adam优化器,学习率0.001,Step调度(每10epoch×0.1),批量大小64,损失函数为交叉熵损失;4. 训练与可视化:训练20个epoch,通过TensorBoard监控损失曲线,最终测试集准确率可达75%左右;5. 优化提升:加入BN层、调整学习率调度策略,准确率可提升至80%以上。
以下是完整的PyTorch实战代码,可直接运行:
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim.lr_scheduler import StepLR
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from torch.utils.tensorboard import SummaryWriter
import time
# 1. 数据预处理与加载
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4), # 随机裁剪
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)) # CIFAR-10标准归一化
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
# 加载数据集
train_dataset = datasets.CIFAR10(
root='./data', train=True, download=True, transform=transform_train
)
test_dataset = datasets.CIFAR10(
root='./data', train=False, download=True, transform=transform_test
)
# 构建数据加载器
train_loader = DataLoader(
train_dataset, batch_size=64, shuffle=True, num_workers=2
)
test_loader = DataLoader(
test_dataset, batch_size=64, shuffle=False, num_workers=2
)
# 2. 定义DNN模型
class DNNModel(nn.Module):
def __init__(self):
super(DNNModel, self).__init__()
self.flatten = nn.Flatten() # 展平层:3×32×32 → 3072
self.fc1 = nn.Linear(32*32*3, 256) # 输入层→隐藏层1
self.relu1 = nn.ReLU()
self.dropout1 = nn.Dropout(0.5)
self.fc2 = nn.Linear(256, 128) # 隐藏层1→隐藏层2
self.relu2 = nn.ReLU()
self.dropout2 = nn.Dropout(0.5)
self.fc3 = nn.Linear(128, 10) # 隐藏层2→输出层(10个类别)
def forward(self, x):
x = self.flatten(x)
x = self.dropout1(self.relu1(self.fc1(x)))
x = self.dropout2(self.relu2(self.fc2(x)))
x = self.fc3(x)
return x
# 初始化模型、损失函数、优化器
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = DNNModel().to(device)
criterion = nn.CrossEntropyLoss() # 交叉熵损失(适配多分类)
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = StepLR(optimizer, step_size=10, gamma=0.1) # Step学习率调度
# 3. 训练函数
def train(model, train_loader, criterion, optimizer, epoch, writer):
model.train()
running_loss = 0.0
correct = 0
total = 0
start_time = time.time()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
# 前向传播
outputs = model(data)
loss = criterion(outputs, target)
# 反向传播与参数更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 统计损失与准确率
running_loss += loss.item()
_, predicted = outputs.max(1)
total += target.size(0)
correct += predicted.eq(target).sum().item()
# 每100个batch记录一次训练信息
if batch_idx % 100 == 99:
avg_loss = running_loss / 100
train_acc = 100. * correct / total
writer.add_scalar('Train/Loss', avg_loss, epoch * len(train_loader) + batch_idx)
writer.add_scalar('Train/Accuracy', train_acc, epoch * len(train_loader) + batch_idx)
print(f'Epoch: {epoch}, Batch: {batch_idx+1}, Loss: {avg_loss:.4f}, Acc: {train_acc:.2f}%')
running_loss = 0.0
train_time = time.time() - start_time
epoch_train_acc = 100. * correct / total
writer.add_scalar('Train/Epoch_Accuracy', epoch_train_acc, epoch)
print(f'Epoch {epoch} Train Accuracy: {epoch_train_acc:.2f}%, Time: {train_time:.2f}s')
# 4. 测试函数
def test(model, test_loader, criterion, epoch, writer):
model.eval()
test_loss = 0.0
correct = 0
total = 0
with torch.no_grad(): # 测试阶段不计算梯度
for data, target in test_loader:
data, target = data.to(device), target.to(device)
outputs = model(data)
loss = criterion(outputs, target)
test_loss += loss.item()
_, predicted = outputs.max(1)
total += target.size(0)
correct += predicted.eq(target).sum().item()
avg_test_loss = test_loss / len(test_loader)
test_acc = 100. * correct / total
writer.add_scalar('Test/Loss', avg_test_loss, epoch)
writer.add_scalar('Test/Accuracy', test_acc, epoch)
print(f'Epoch {epoch} Test Loss: {avg_test_loss:.4f}, Test Accuracy: {test_acc:.2f}%\n')
# 5. 启动训练与可视化
if __name__ == "__main__":
writer = SummaryWriter('./runs/dnn_cifar10') # TensorBoard日志保存路径
epochs = 20
for epoch in range(epochs):
train(model, train_loader, criterion, optimizer, epoch, writer)
test(model, test_loader, criterion, epoch, writer)
scheduler.step() # 更新学习率
# 保存模型
torch.save(model.state_dict(), './dnn_cifar10_model.pth')
writer.close()
print("训练完成!模型已保存至 ./dnn_cifar10_model.pth")
# 6. 优化提升:加入BN层的模型(准确率可提升至80%+)
class DNNModelWithBN(nn.Module):
def __init__(self):
super(DNNModelWithBN, self).__init__()
self.flatten = nn.Flatten()
self.fc1 = nn.Linear(32*32*3, 256)
self.bn1 = nn.BatchNorm1d(256) # 批量归一化层
self.relu1 = nn.ReLU()
self.dropout1 = nn.Dropout(0.5)
self.fc2 = nn.Linear(256, 128)
self.bn2 = nn.BatchNorm1d(128) # 批量归一化层
self.relu2 = nn.ReLU()
self.dropout2 = nn.Dropout(0.5)
self.fc3 = nn.Linear(128, 10)
def forward(self, x):
x = self.flatten(x)
x = self.dropout1(self.relu1(self.bn1(self.fc1(x)))) # BN层在全连接层后、激活前
x = self.dropout2(self.relu2(self.bn2(self.fc2(x))))
x = self.fc3(x)
return x代码说明:① 数据预处理部分采用随机裁剪、水平翻转增强泛化能力,使用CIFAR-10标准归一化参数;② 基础DNN模型包含两层隐藏层,加入Dropout防止过拟合;③ 训练过程中通过TensorBoard记录损失与准确率,便于监控训练状态;④ 补充了加入BN层的优化模型,通过批量归一化加速收敛并提升准确率;⑤ 代码兼容CPU与GPU,可根据硬件环境自动适配。
五、进阶延伸:DNN的未来发展趋势
DNN作为深度学习的基础,正不断与其他技术融合发展。自编码器、生成对抗网络(GAN)等生成式DNN模型,拓展了无监督学习的应用场景;可解释性AI技术的发展,让DNN的决策过程更加透明,推动其在医疗、金融等关键领域的落地;联邦学习与DNN的结合,实现了隐私保护下的分布式训练,解决了数据孤岛问题;此外,DNN与Transformer、图神经网络(GNN)的融合,正催生更高效的模型架构,有望在更多复杂任务中实现突破。
✨ 坚持用 清晰的图解 +易懂的硬件架构 + 硬件解析, 让每个知识点都 简单明了 !
🚀 个人主页 :一只大侠的侠 · CSDN
💬 座右铭 : "所谓成功就是以自己的方式度过一生。"
