**【本节概要】**在当今时代,人们已不再满足于单纯呈现原始的文档, 而是需要更加精炼的知识表达与更加直观的需求解决。从查询条件的扩展,到查询内容的拓展,用户希望实现一次查询,多重服务的信息关联。因此,本节主要结合知识图谱讲解如何从文档中总结并关联知识。
目录
[3.1 知识图谱的符号表示](#3.1 知识图谱的符号表示)
[3.2 知识图谱的相关应用](#3.2 知识图谱的相关应用)
[3.3 更多类型的知识图谱](#3.3 更多类型的知识图谱)
一、知识组织形式的发展
知识图谱是从语义网络和本体论衍生而来。
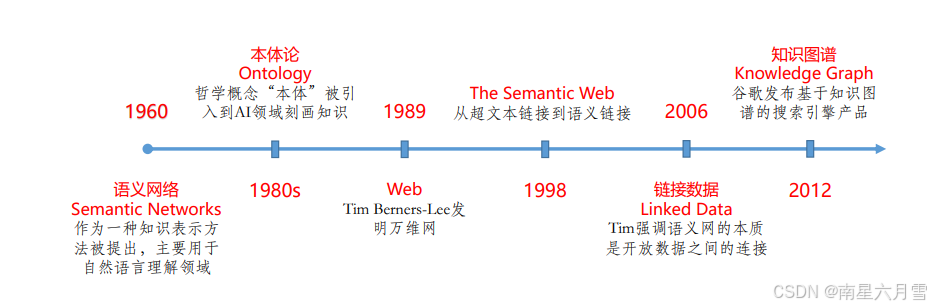
最早的语义网络,指的是以有向图结构表达人类知识构造的形式,如下图所示。
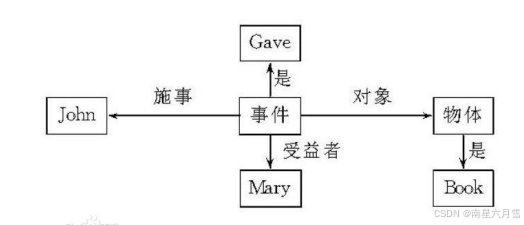
到了1980s,本体论的概念逐渐被人们认可。本体是指一种形式化的,对于共享概念体系的明确而又详细的说明,也可以说是指特定领域之中存在的对象类型或概念,及其属性和相互关系。
本体论中的五元组表示法:O = {C, R, F, A, I }
- C -- Concept,概念集合,通常以术语形式组织,如"中科大学生"
- R -- Relations,描述概念或实例间语义关系,如"同班同学"
- F -- Functions,一组特殊关系,其中第N个元素由其他n-1个元素决定
- A -- Axioms,公理,例如A是B的父亲,B是C的父亲,得到A与C的关系
- I -- Instances,具体的个体,如"助教"是"中科大学生"的实例
在 1998 年,Tim Berners-Lee 提出了语义网的概念。它的核心思想是通过给万维网上的文档 (如HTML、XML文档)添加能够被计算机所理解的语义"元数据"(Meta data),从而使整个互联网成为一个通用的信息交换媒介。
这里最重要的理念在于,信息应以图的形式组织,图中节点表达任何事物,链接表达事物之间的关联。以图为中心的信息组织方式可以有效提升检索效率,并在开放网络环境中快速增长。
**基本的万维网(WWW)和语义网络的区别?**核心区别:服务对象不同
万维网在组织信息资源时主要面向"人"的信 息发布和获取,侧重于可视效果,即信息的显 示格式和样式(如HTML)。
而语义网必须侧重于信息的语义内容,并考虑计算机对文本内容的"理解"以及它们之间的相互交流和沟通。
二、信息抽取任务概述
从语料中抽取指定的事件、事实等信息, 形成结构化的数据,这个过程叫做信息抽取。被抽取的信息以预先定义的、结构化的形式描述,为后续的情报分析、自动文摘、问答系 统等一系列应用提供服务。
信息抽取和信息检索两者密切相关,却又存在鲜明的差异。首先,两者的功能不同。检索是从文档集合中找文档子集,而抽取是从文本中获取用户感兴趣的事实信息。其次,两者的处理技术不同。检索可以采用统计与关键词等技术,抽取需要借助自然语言处理技术。另外还有使用领域不同。检索与通常领域无关,而抽取则与通常领域相关。
概括来说,信息抽取的核心就是"抽取实体,确定关系"。在MUC-7(1998年)上,定义了5类基本的信息抽取任务,分别是命名实体NE、模板元素TE、共指关系CR、模板关系TR、背景模板ST。
- 命名实体NE(实体抽取):命名实体抽取是信息抽取最重要的任务。命名实体是文本中基本的信息元素,是正确理解文本的基础。狭义来说,指现实世界中具体或抽象的实体,如人、组织、地点等,广义来说,还可以包含日期和时间、数量表达式等。
- 模板元素TE(属性抽取):模板元素又称为实体的属性,目的在于更加清楚、完整地描述命名实体。通过槽(Slots)描述了命名实体的基本信息,槽指的是名称、类别、种类等,例如:郝哥表示,这都是大棚的瓜,你嫌贵我还嫌贵呢。TE:瓜是大棚里产的(属性)。
- 共指关系CR:如果不同的命名实体表达了相同的含义,即为共指关系,也称为等价概念。共指关系的抽取任务在于抽取关于共指表达的信息,包括那些已在命名实体和模板元素任务中作了标记的,对于某个命名实体的所有表述。
- 模板关系TR(关系抽取):实体之间的各种关系,又称为事实。通过关系抽取,将实体关联起来,并为推理奠定基础。
- 场景模板ST(事件抽取):又称事件,是指实体发生的事件,例如:会议 (Time, Spot, Convener, Topic)。常见的新闻事件描述模板 5W1H,Who 、When 、Where 、What 、Why 、How。
我们用一个具体的例子来说明信息抽取的过程:



三、知识图谱的基本概念
2012年5月16日,Google知识图谱(Knowledge Graph,KG)正式发布。除了显示网页文档的连接列 表外,还提供结构化的、详细的有关主题的信息。其目标是,用户可以使用此功能直接解决查询的问题, 而不必导航到其他网站并自行汇总信息。
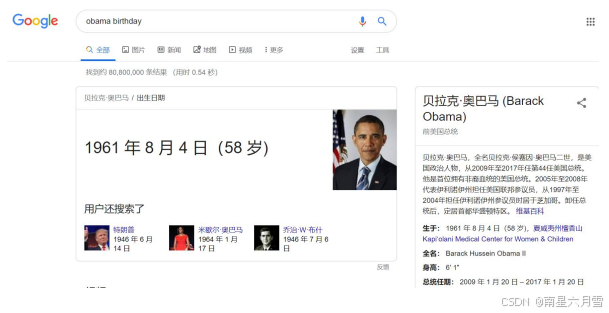
一个好的知识图谱至少可从以下三个层面提升搜索的效果:1. 找到最想要的信息:不再需要用户自行浏览、阅读和总结,而将信息直接呈现;2. 提供最全面的摘要:对搜索对象进行总结, 使得用户获得更完整的信息和关联;3. 让搜索更有深度和广度:构建完整知识体系, 使用户获得意想不到的新发现。
3.1 知识图谱的符号表示
知识图谱由前述各种网络衍生而来,由结点和结点之间的边组成, 结点表示概念(或实体), 边表示关系(或属性)。在数学上,知识图谱表现为一个有向图,方向表示主被动关系,表达相互关系将使用双向图。

一般而言,知识图谱中的节点用来表示概念 (Concept)和实体。 知识图谱中的边用来表示关系(Relation)和属性(Attribute)。关系:侧重实体(Entity)之间的关联,例如"高于":姚明高于小四;而属性:用于描述实体的特征,例如尺寸,颜色、组成等等。点和边组成知识图谱的基本单位:三元组(头实体-关系-尾实体)
3.2 知识图谱的相关应用
这里我们列举一些知识图谱常见的应用场景。
| 应用场景 | 描述 |
|---|---|
| 语义搜索 | 通过建立事物之间的联系,实现更准确、更直接、更完整的搜索。 |
| 问答系统 | 在理解用户意图的基础上,将知识图谱作为大脑,基于推理能力提升交互体验。 |
| 推荐系统 | 利用知识图谱提高推荐系统的推荐多样性和可解释性,提升推荐性能。 |
3.3 更多类型的知识图谱
本节我们介绍两种比较特殊的知识图谱,分别是事理图谱和多模态知识图谱。
事理图谱所要描绘的是一个逻辑社会, 研究对象是谓词性事件及其内外联系。事理图谱与知识图谱的组织形式相仿,实体通过头尾相连,形成有向图的组织性质。借助图谱中的事理逻辑链接,可以形成对于事件的推理。
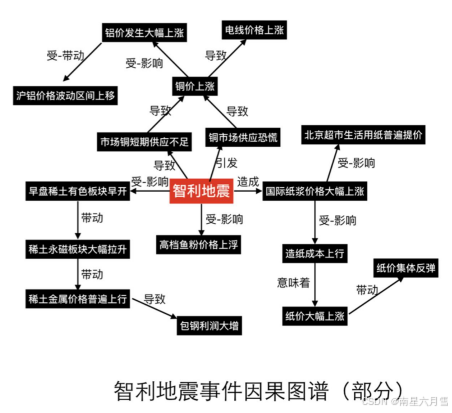
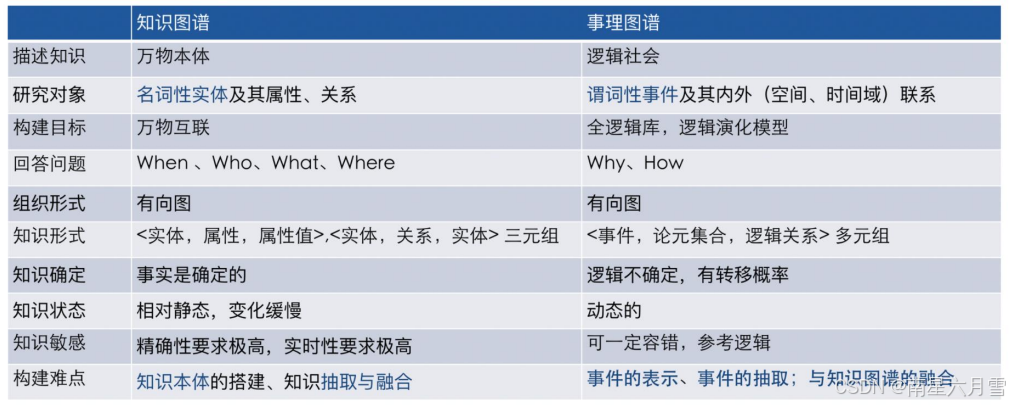
事理图谱 = 事件 + 逻辑。其本质是一个事理逻辑知识库,不仅呈现了事件本身的发生,还要揭示它们之间潜在的发展关系和影响链条。这里用一张表格展示普通的知识图谱和事理图谱之间的区别:
同时为了便于理解,再举一个具体例子,说明事理图谱的构建过程:
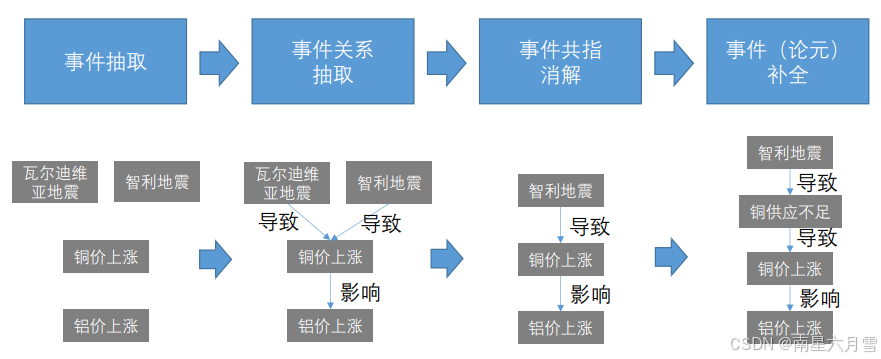
常见的一些事件之间的关系包括:因果、条件、反转、顺承、上下位、组成、并发。
模态: 某种类型的信息或者存储信息的表示形式。传统图谱以文本模态为主,难以描述复杂的现实世界信息。现实世界语义模态日益丰富,有效表示与整合多模态知识成为趋势。多模态知识图谱可笼统分为属性多模态与实体多模态两大类: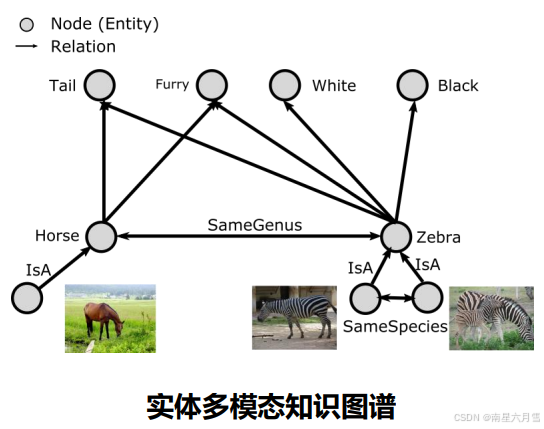
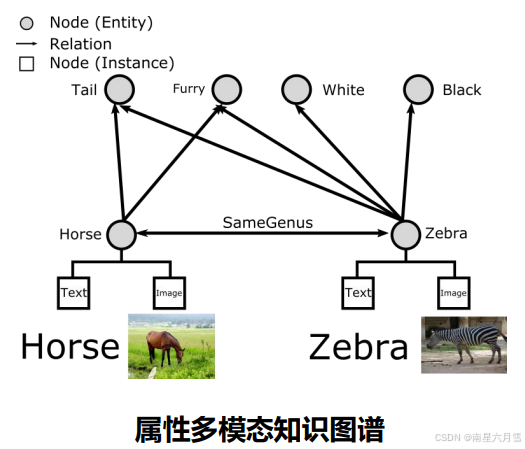
多模态知识图谱可以以不同模态作为信息的入口,不同的模态协作帮助对实体的理解。