模型如何适配于你的业务场景
模型的原理大概是
模型有哪些参数?表示什么意义?你是怎么调参的?
集成学习是什么?
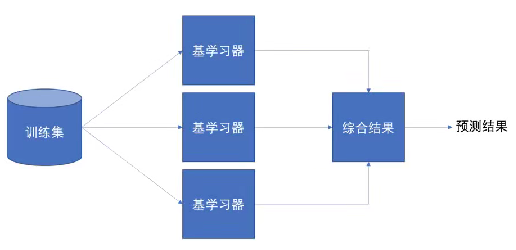
集成学习是机器学习中的一种思想,它通过多个模型的组合形成一个精度更高的模型,参与组合的模型称为弱学习器(基学习器)
训练时,使用训练集依次训练出这些弱学习器,对未知样本进行预测时,使用这些弱学习器联合进行预测。
三个臭皮匠,顶个诸葛亮
随机森林
AdaBoost
GBDT
XGBoost
集成学习的两大分类
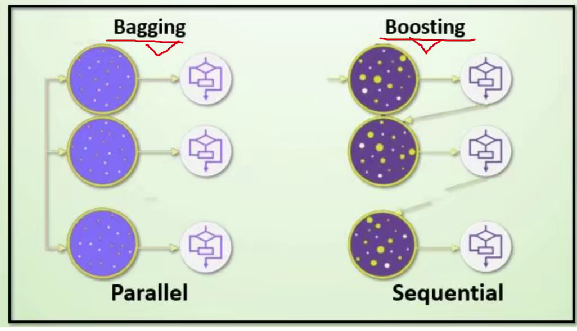
Bagging 装袋法:并行训练,取最好的一个
Boosting 提升法:第一个先去学习,针对第一个的学习做一些优化,然后在此基础上让第二个学习,
Bagging:随机森林
Boosting:Adaboost、GBDT、XGBoost(用的最多)、LightGBM
Bagging
有放回的抽样(booststrap抽样)产生不同的训练集,从而训练不同的学习器。
数据集中抽样出来,用这一部分的数据训练一个模型。然后把抽样出来的这些东西放回原数据集,原数据集重新进行随机抽样,循环往复。
通过平权投票、多数表决的方式决定预测结果在分类问题中,会使用多数投票统计结果在回归问题中,会使用求均值统计结果弱学习器可以并行训练
基本的弱学习器算法模型,如:Linear、Ridge(L2正则化,抑制过拟合)、Lasso(L1正则化)、Logistic、Softmax、ID3、C4.5、CART、SVM、KNN均可
Boosting
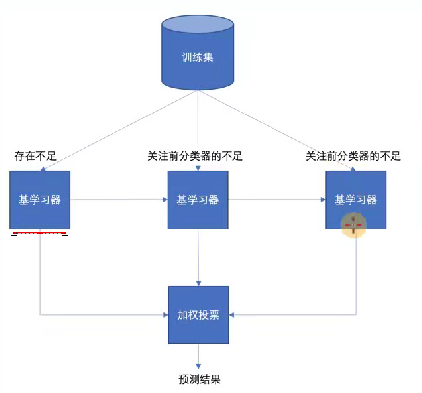
每一个训练器重点关注前一个训练器不足的地方进行训练
通过加权投票的方式,得出预测结果
串行的训练方式
每个子模型的训练都使用全量数据进行训练
随着学习的积累从弱到强
每新加入一个弱学习器,整体能力就会得到提升
代表算法:Adaboost(Adaptive自适应的),GBDT,XGBoost,LightGBM
Bagging
Random Forest
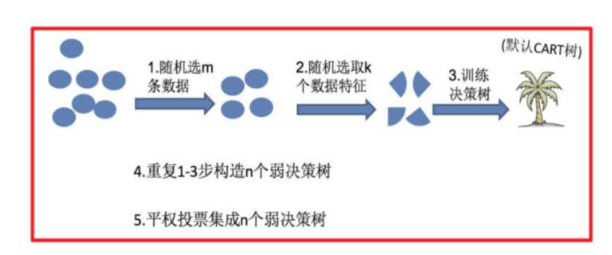
随机森林是基于 Bagging 思想实现的一种集成学习算法,采用决策树模型作为每一个弱学习器
训练:
(1)有放回的产生训练样本
(2)随机挑选n个特征(n小于总特征数量)
预测:平权投票,多数表决输出预测结果
为什么要随机抽样训练集?
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样。
保证每次抽样的公平性,没办法区分是不是因为数据集的好坏导致了模型表现的好坏
思考题2:为什么要有放回地抽样?
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是"有偏的",(每棵树的决策都是片面的,树与树之间缺乏共识),也 就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决。
•
综上:弱学习器的训练样本既有交集也有差异数据,更容易发挥投票表决效果

python
"""
## 随机森林
# 1.导入依赖包
# 2.读取数据
# 3.数据处理
# 4.模型训练
# 4.1 决策树
# 4.2 随机森林
# 4.3 网格搜索交叉验证
# 5.模型评估
# 5.1 决策树
# 5.2 随机森林
# 5.3 网格搜索交叉验证
"""
# 1.导入依赖包
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
# 2.读取数据
data = pd.read_csv('./data/titanic/train.csv')
print(data.head())
print(data.info)
# 3.数据处理
x = data[['Pclass', 'Sex', 'Age']].copy()
y = data['Survived'].copy()
print(x.head(10))
x['Age'].fillna(x['Age'].mean(), inplace=True)
print(x.head(10))
x = pd.get_dummies(x)
print(x.head(10))
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
# 4.模型训练
# 4.1 决策树
tree = DecisionTreeClassifier()
tree.fit(x_train, y_train)
# 4.2 随机森林
rf = RandomForestClassifier()
rf.fit(x_train, y_train)
# 4.3 网格搜索交叉验证
params = {'n_estimators': [10, 20], 'max_depth': [2, 3, 4, 5]}
model = GridSearchCV(estimator=rf, param_grid=params, cv=3)
model.fit(x_train, y_train)
print(model.best_estimator_)
rfs = RandomForestClassifier(max_depth=4, n_estimators=10)
rfs.fit(x_train, y_train)
# 5.模型评估
# 5.1 决策树
print(tree.score(x_test, y_test))
# 5.2 随机森林
print(rf.score(x_test, y_test))
# 5.3 网格搜索交叉验证
print(rfs.score(x_test, y_test))
sqBoosting
Adaptive Boosting(自适应提升)基于 Boosting思想实现的一种集成学习算法
核心思想是通过逐步提高那些被前一步分类错误的样本的权重来训练一个强分类器
上一个班学的不好的,这一个班着重去学。