Transformer 是一种完全基于注意力机制的神经网络架构,放弃了传统的循环和卷积结构,在机器翻译等序列到序列任务中表现出色,并成为当今大语言模型(如 GPT、BERT)的基石。
我们以最经典的 序列到序列任务(如机器翻译:将英文"I love you"翻译成中文"我爱你")为例,讲解其完整工作流。
核心思想
Transformer 的核心思想是:通过"自注意力"机制,让序列中的每个元素都能直接与序列中的所有其他元素进行交互,从而捕捉全局的上下文依赖关系。
整体架构图景
Transformer 采用 编码器-解码器 架构。
- 编码器:负责理解和抽象化输入序列的信息,将其转化为一组富含上下文信息的"中间表示"。
- 解码器:基于编码器的输出和之前已生成的输出,自回归地(一个接一个)生成目标序列。
一个标准的 Transformer 模型由 N 个(通常 N=6)相同的编码器层堆叠而成 ,和 N 个相同的解码器层堆叠而成。
第一阶段:输入处理与嵌入
1. 词元化与嵌入
-
输入:原始文本序列(如 "I love you")。
-
步骤:
- 分词 :将句子分割成词元(Token),例如
["I", "love", "you"]。 - 嵌入查找 :每个词元通过一个可学习的 嵌入矩阵 被转换成一个固定维度的向量(如 512 维)。这个向量称为 词嵌入,它试图在向量空间中编码该词元的语义信息。
- 分词 :将句子分割成词元(Token),例如
-
输出 :一个向量序列,维度为
[序列长度, 模型维度]。
2. 位置编码
-
问题 :自注意力机制本身是"排列不变"的,它没有内置的顺序概念。
"A 打了 B"和"B 打了 A"的词嵌入是一样的,但含义截然不同。 -
解决方案 :位置编码。
- 为序列中的每个位置(第1个词,第2个词...)计算一个独一无二的、固定或可学习的向量。
- 这个位置向量的维度与词嵌入相同。
- 关键操作 :将 词嵌入向量 和 位置编码向量 逐元素相加。
-
结果:得到的向量既包含了词的语义信息,也包含了其在序列中的绝对和相对位置信息。
至此,输入序列被转换为一个包含语义和位置信息的向量序列,准备送入编码器。
第二阶段:编码器处理
编码器层是 Transformer 的引擎,每个编码器层结构完全相同,包含两个核心子层:
子层 1:多头自注意力机制
这是 Transformer 的灵魂。
-
目的:让序列中的每个词都能"关注"序列中的所有其他词,从而基于整个上下文来更新自己的表示。
-
过程:
-
线性投影 :对于每个位置的输入向量,通过三组不同的权重矩阵,并行地生成三组向量:查询向量 、键向量 、值向量。
-
"多头" :将模型维度分割成多个"头"(例如 8 个头,每个头维度为 64)。在每个头上独立地进行注意力计算。这允许模型在不同的表示子空间中并行地关注不同方面的信息(例如语法、语义、指代关系)。
-
缩放点积注意力计算(在每个头上):
- 匹配 :计算当前词(查询 Q)与序列中所有词(键 K)的相似度得分(点积)。
相似度 = Q · K^T - 缩放:将得分除以键向量维度的平方根,使训练更稳定。
- 归一化:通过 Softmax 函数将相似度得分转换为概率分布(注意力权重),权重之和为 1。
- 加权求和 :用得到的注意力权重对序列中所有词的 值向量 进行加权求和,得到当前词在该注意力头下的新表示。权重高的值向量对结果贡献大。
- 匹配 :计算当前词(查询 Q)与序列中所有词(键 K)的相似度得分(点积)。
-
合并:将所有注意力头的输出拼接起来,并通过一个线性层进行融合。
-
-
输出:每个词的新向量,都融合了序列中所有其他词的相关信息。
子层 2:前馈神经网络
- 目的:对自注意力层的输出进行进一步的非线性变换和空间映射。
- 结构:一个简单的两层全连接网络,通常中间层的维度更大(如 2048 维),使用 ReLU 激活函数。
- 作用:为模型增加非线性能力和表达能力。
残差连接与层归一化
-
每个子层 (自注意力、前馈网络)都被一个 残差连接 和 层归一化 所包裹。
-
流程 :
输出 = LayerNorm(子层输入 + 子层函数(子层输入)) -
作用:
- 残差连接:缓解深层网络中的梯度消失问题,使模型更容易训练。
- 层归一化:稳定每一层的输入分布,加速训练。
经过 N 个编码器层的逐层处理后,输入序列被转化为一组高度精炼、富含全局上下文信息的"记忆"或"上下文向量"。这组向量将传递给解码器。
第三阶段:解码器处理
解码器也是自回归的,它一次生成一个词元。每个解码器层包含 三个 核心子层。
子层 1:掩码多头自注意力
- 目的 :让解码器在生成当前词时,只能"看到"它 之前 已经生成的词(这是自回归生成的要求),而不能看到未来的词。
- 实现 :在计算注意力权重时,使用一个 因果掩码。这是一个上三角矩阵,将未来位置的注意力权重设置为负无穷,这样在 Softmax 之后,未来位置的权重就变成了 0。
子层 2:编码器-解码器注意力(交叉注意力)
-
目的:这是连接编码器和解码器的桥梁。它让解码器在生成当前词时,能够"询问"编码器:"基于我目前生成的上下文,源序列的哪些部分是相关的?"
-
过程:
- Q(查询) 来自解码器上一层的输出。
- K(键)和 V(值) 来自 最后一个编码器层的输出。
- 计算解码器当前状态(Q)与整个编码器输出序列(K)的相似度,得到注意力权重,然后用这些权重对编码器的值向量(V)进行加权求和。
-
结果:解码器将编码器提供的源序列信息,动态地、有选择地整合到自己的生成过程中。
子层 3:前馈神经网络
- 与编码器中的前馈网络完全相同。
同样,每个子层周围都有残差连接和层归一化。
经过 N 个解码器层的处理后,在最后一个解码器层的顶部,会输出一个向量序列(每个目标词位置对应一个向量)。
第四阶段:输出生成
-
线性投影 :将最后一个解码器层输出的每个位置的向量,通过一个可学习的线性层,投影到 目标语言词表大小 的维度。
-
Softmax:对线性层的输出应用 Softmax 函数,将其转换为一个概率分布。这个分布表示在当前位置,生成词表中每个词的概率。
-
自回归生成:
- 训练时 :我们已知完整的目标序列(
"<SOS> 我 爱 你 <EOS>")。解码器会并行地处理整个目标序列(使用掩码),并试图预测下一个词。损失函数(如交叉熵)通过比较预测分布和真实的下一个词来计算。 - 推理时 :
a. 从起始符<SOS>开始。
b. 将当前已生成的序列送入解码器,得到下一个词的概率分布。
c. 通常采用 束搜索 或 贪心采样 等策略,选择下一个词(例如选择概率最高的词"我")。
d. 将新生成的词追加到序列末尾,重复步骤 b-c,直到生成结束符<EOS>。
- 训练时 :我们已知完整的目标序列(
工作流总结
-
输入预处理 :
文本->词元化->词嵌入+位置编码= 带位置的输入向量。 -
编码器堆栈 (N层):每层对输入进行 多头自注意力 (捕捉上下文)和 前馈变换 ,用 残差连接和层归一化 稳定训练。输出 上下文记忆。
-
解码器堆栈(N层,自回归):
- 掩码自注意力:关注已生成的部分。
- 交叉注意力:查询编码器的上下文记忆,获取相关信息。
- 前馈变换:进一步处理信息。
- 每层同样使用 残差连接和层归一化。
-
输出层 :
解码器输出->线性投影->Softmax->下一个词的概率分布->自回归生成完整序列。
关键创新与优势
- 并行化:与 RNN 的串行处理不同,Transformer 对序列所有位置的注意力计算可以完全并行,极大提高了训练速度。
- 长程依赖:自注意力机制允许任意两个位置直接交互,无论距离多远,有效解决了 RNN 的长程依赖衰减问题。
- 可扩展性:模块化的层堆叠结构,使其能够通过增加层数、维度等轻松扩展成超大模型(如 GPT-3、PaLM)。
希望这个详细的流程能帮助你清晰地理解 Transformer 的内部工作机制。
生成md文档
我们按照Transformer的整体工作流程,将上述详细讲解整理成Markdown文档。注意,由于Markdown不支持复杂的图表,我们将用文字描述和简单的代码块来示意关键步骤。对于复杂的数学公式,我们将使用LaTeX格式。
注意:由于内容较长,我们将分章节进行整理。
Transformer 模型完整工作流程详解
概述
Transformer 是一种完全基于注意力机制的神经网络架构,由 Vaswani 等人在 2017 年的论文《Attention Is All You Need》中提出。它放弃了传统的循环神经网络和卷积神经网络,在序列到序列任务中表现出色,并成为当今大语言模型的基石。
核心架构图
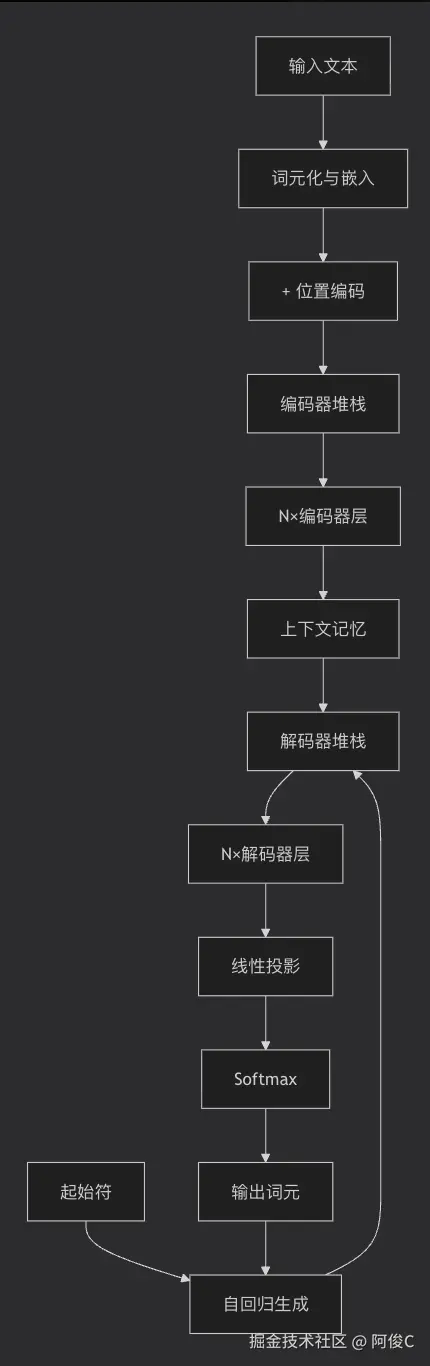
一、输入处理阶段
1.1 词元化与嵌入
流程
text
原始文本 → 分词 → 词嵌入查找 → 词向量序列详细步骤
1. 分词(Tokenization)
- 将输入文本分割成有意义的单元
- 方法:BPE、WordPiece、SentencePiece 等
- 示例:
"I love you"→["I", "love", "you"]
2. 词嵌入(Word Embedding)
-
通过可学习的嵌入矩阵将词元映射为向量
-
维度:通常为 512、768 或 1024 维
-
数学表示:
text
iniE ∈ ℝ^(V×d) # 嵌入矩阵,V=词表大小,d=模型维度 X_embed = E[token_ids] # 形状: [batch_size, seq_len, d_model]
1.2 位置编码
目的
为模型提供序列顺序信息,因为自注意力机制本身是位置无关的。
实现方式
1. 正弦余弦位置编码(原始 Transformer)
python
perl
# 公式
PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
PE(pos, 2i+1) = cos(pos / 10000^(2i+1/d_model))
# 其中:
# - pos: 位置索引(0, 1, 2, ...)
# - i: 维度索引(0 ≤ i < d_model/2)
# - d_model: 模型维度2. 可学习位置编码(如 BERT)
- 为每个位置学习一个独立的嵌入向量
- 适用于固定或有限的最大序列长度
最终输入表示
text
ini
输入 = 词嵌入 + 位置编码
X = X_embed + PE二、编码器架构
编码器由 N 个相同的层堆叠而成(通常 N=6)。
2.1 单编码器层结构
text
sql
输入
↓
多头自注意力层
↓
Add & Norm(残差连接 + 层归一化)
↓
前馈神经网络层
↓
Add & Norm(残差连接 + 层归一化)
↓
输出2.2 多头自注意力机制
计算流程
1. 线性投影生成 Q、K、V
text
ini
Q = X · W_Q # 查询矩阵
K = X · W_K # 键矩阵
V = X · W_V # 值矩阵2. 分割成多个头
text
bash
# 原始维度: [batch_size, seq_len, d_model]
# 分割后: [batch_size, num_heads, seq_len, d_k]
# 其中 d_k = d_model / num_heads3. 缩放点积注意力计算
python
ini
def scaled_dot_product_attention(Q, K, V, mask=None):
# 计算注意力分数
scores = torch.matmul(Q, K.transpose(-2, -1)) / sqrt(d_k)
# 应用掩码(如果需要)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# Softmax 归一化
attention_weights = F.softmax(scores, dim=-1)
# 加权求和
output = torch.matmul(attention_weights, V)
return output, attention_weights4. 多头合并
python
ini
# 1. 每个头独立计算注意力
head_i = attention(Q_i, K_i, V_i)
# 2. 拼接所有头
multi_head = concatenate(head_1, head_2, ..., head_h)
# 3. 线性投影
output = multi_head · W_O2.3 前馈神经网络
结构
text
输入 → 线性层(扩大维度) → ReLU激活 → 线性层(恢复维度) → 输出数学表示
text
scss
FFN(x) = max(0, xW_1 + b_1)W_2 + b_2其中:
W_1 ∈ ℝ^(d_model×d_ff),d_ff通常为4×d_modelW_2 ∈ ℝ^(d_ff×d_model)
2.4 残差连接与层归一化
公式
text
scss
子层输出 = LayerNorm(x + Sublayer(x))作用
- 残差连接:缓解梯度消失,使深层网络易于训练
- 层归一化:稳定激活值分布,加速收敛
三、解码器架构
解码器也由 N 个相同的层堆叠而成。
3.1 单解码器层结构
text
sql
输入
↓
掩码多头自注意力层
↓
Add & Norm
↓
编码器-解码器注意力层
↓
Add & Norm
↓
前馈神经网络层
↓
Add & Norm
↓
输出3.2 三种注意力机制对比
| 类型 | 查询(Q)来源 | 键(K)/值(V)来源 | 作用 |
|---|---|---|---|
| 编码器自注意力 | 编码器输入 | 编码器输入 | 捕捉输入序列内部依赖 |
| 掩码自注意力 | 解码器输入 | 解码器输入 | 防止信息泄露,保证自回归性 |
| 编码器-解码器注意力 | 解码器上层输出 | 编码器输出 | 连接源语言和目标语言信息 |
3.3 掩码机制
因果掩码(Causal Mask)
python
ini
# 上三角矩阵,主对角线及以下为1,以上为0
mask = torch.tril(torch.ones(seq_len, seq_len))
# 形状:[1, 1, seq_len, seq_len]作用
确保在生成第 t 个词时,只能看到前 t-1 个词。
四、输出生成
4.1 线性投影与Softmax
text
解码器输出 → 线性层 → Softmax → 概率分布数学表示
text
ini
logits = DecoderOutput · W_vocab # W_vocab ∈ ℝ^(d_model×vocab_size)
probs = softmax(logits)4.2 训练与推理模式
训练阶段(Teacher Forcing)
text
css
输入: <SOS> 我 爱 你
目标: 我 爱 你 <EOS>
流程:
1. 解码器输入: <SOS> 我 爱 你
2. 预测下一个词: P(我), P(爱), P(你), P(<EOS>)
3. 计算交叉熵损失推理阶段(自回归生成)
python
ini
def generate(input_ids, max_length=50):
# 编码器前向传播
encoder_output = encoder(input_ids)
# 初始化解码器输入
decoder_input = torch.tensor([[SOS_TOKEN_ID]])
for step in range(max_length):
# 解码器前向传播
decoder_output = decoder(decoder_input, encoder_output)
# 获取下一个词的概率分布
next_token_logits = lm_head(decoder_output[:, -1, :])
next_token_probs = F.softmax(next_token_logits, dim=-1)
# 选择下一个词(贪婪采样或束搜索)
next_token_id = torch.argmax(next_token_probs, dim=-1)
# 如果生成了结束符,停止生成
if next_token_id == EOS_TOKEN_ID:
break
# 将新词元添加到输入中
decoder_input = torch.cat([decoder_input, next_token_id.unsqueeze(0)], dim=1)
return decoder_input4.3 生成策略
| 策略 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 贪婪解码 | 每步选择概率最高的词元 | 简单快速 | 容易陷入局部最优,缺乏多样性 |
| 束搜索 | 每步保留 k 个最佳候选序列 | 质量更高 | 计算开销大,可能产生重复 |
| 采样 | 根据概率分布随机采样 | 多样性好 | 可能生成不连贯的文本 |
| 温度采样 | 调整概率分布的平滑度 | 平衡质量与多样性 | 需要调优温度参数 |
| Top-k/p采样 | 限制采样空间 | 减少低质量输出 | 需要选择超参数 |
五、关键数学公式汇总
5.1 注意力机制
缩放点积注意力:
text
scss
Attention(Q, K, V) = softmax(QK^T / √d_k) V多头注意力:
text
scss
MultiHead(Q, K, V) = Concat(head_1, ..., head_h) W^O
head_i = Attention(QW_i^Q, KW_i^K, VW_i^V)5.2 位置编码
正弦余弦编码:
text
scss
PE(pos, 2i) = sin(pos / 10000^(2i/d))
PE(pos, 2i+1) = cos(pos / 10000^(2i/d))5.3 前馈网络
text
scss
FFN(x) = max(0, xW_1 + b_1)W_2 + b_25.4 层归一化
text
scss
LayerNorm(x) = γ ⊙ (x - μ) / √(σ² + ε) + β
其中 μ, σ 为均值和标准差,γ, β 为可学习参数六、变体与扩展
6.1 仅编码器模型(如 BERT)
- 用途:自然语言理解任务
- 结构:仅使用编码器部分
- 预训练任务:掩码语言建模、下一句预测
6.2 仅解码器模型(如 GPT 系列)
- 用途:文本生成任务
- 结构:仅使用解码器部分(移除编码器-解码器注意力)
- 预训练任务:自回归语言建模
6.3 编码器-解码器模型(原始 Transformer)
- 用途:序列到序列任务
- 结构:完整的编码器-解码器架构
- 应用:机器翻译、文本摘要
七、优化技巧
7.1 训练优化
- 梯度累积:模拟大批量训练
- 混合精度训练:减少内存占用,加快计算
- 学习率调度:Warmup + 衰减策略
7.2 内存优化
- 梯度检查点:用时间换空间
- 激活重计算:减少中间激活存储
- 模型并行:将模型分布到多个设备
7.3 推理优化
- 键值缓存:避免重复计算
- 量化:降低权重精度
- 模型剪枝:移除不重要的权重
八、应用场景
- 机器翻译:原始应用场景
- 文本生成:故事创作、代码生成
- 问答系统:阅读理解、开放域问答
- 文本摘要:提取式、生成式摘要
- 语音识别与合成:语音到文本、文本到语音
总结
Transformer 通过完全基于注意力机制的架构,解决了传统序列模型在并行化和长程依赖方面的局限性。其核心创新包括:
- 自注意力机制:允许序列中任意位置直接交互
- 位置编码:为模型注入顺序信息
- 多头注意力:并行捕捉不同子空间的信息
- 残差连接与层归一化:稳定深层网络训练
这种架构不仅成为自然语言处理的基石,也逐渐扩展到计算机视觉、多模态学习等领域,推动了深度学习的发展。