一、什么是 RAG?
检索增强生成(Retrieval-Augmented Generation,RAG)是大语言模型应用的核心技术之一,它通过「检索外部知识库 + 大模型生成回答」的方式,解决了大模型「知识过时」「事实性错误」「幻觉」等问题。简单来说,RAG 的核心逻辑是:先找答案相关的资料,再让大模型基于资料回答问题,而非让大模型凭空生成。
本文将手把手教你搭建一个轻量级 RAG 系统,核心技术栈包括:
- LangChain:一站式 LLM 应用开发框架,负责流程编排;
- FAISS:Facebook 开源的高效向量检索库,用于构建本地向量数据库;
- BCE 嵌入模型:中文轻量级文本嵌入模型,将文本转为可检索的向量;
- 通义千问(qwen-plus):阿里云开源大模型,负责最终的自然语言回答。
二、核心开发思路
本次实战的 RAG 系统流程可总结为 4 步:
- 文本向量化:用 BCE 嵌入模型将本地文本转为向量;
- 向量存储与检索:用 FAISS 构建向量库,根据用户问题检索最相关的文本;
- Prompt 构建:将检索到的文本作为「上下文」,拼接用户问题生成 Prompt;
- 大模型生成:调用通义千问 API,基于上下文生成精准回答。
三、完整实战代码与解析
3.1 环境准备
首先安装所需依赖,执行以下命令:
# 核心依赖:LangChain全家桶
pip install langchain langchain-community langchain-core langchain-huggingface
# 向量库:FAISS(CPU版本)
pip install faiss-cpu
# 模型下载与加载:ModelScope
pip install modelscope
# 环境变量管理:python-dotenv
pip install python-dotenv
# OpenAI兼容接口:调用通义千问
pip install openai同时需要准备两个关键资源:
-
阿里云 DashScope API Key:前往「阿里云百炼控制台」申请(免费额度足够测试);
-
BCE 嵌入模型:通过 ModelScope 下载到本地(也可直接使用线上模型)。
导入必要的库
from langchain_community.vectorstores import FAISS
from langchain_core.prompts import ChatPromptTemplate
from modelscope import snapshot_download
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from dotenv import load_dotenv
import os
from langchain_openai import ChatOpenAI
from pydantic import SecretStr加载环境变量(用于读取 API Key)
load_dotenv()
--------------------------
1. 下载/加载本地嵌入模型(可选:如果已下载可注释)
--------------------------
如果你还没下载模型,取消下面注释,下载到指定目录
model_dir = snapshot_download(
'maidalun/bce-embedding-base_v1',
cache_dir="D:\本地模型"
)
--------------------------
2. 初始化嵌入模型
--------------------------
替换为你实际的模型本地路径
model_name = r'D:\本地模型\maidalun\bce-embedding-base_v1'
嵌入模型配置:归一化向量(提升检索精度)
encode_kwargs = {'normalize_embeddings': True}
embeddings = HuggingFaceEmbeddings(
model_name=model_name,
encode_kwargs=encode_kwargs,
# 可选:指定设备,如 CPU 或 GPU
model_kwargs={'device': 'cpu'}
)--------------------------
3. 构建 FAISS 向量库并检索
--------------------------
初始化向量库(3条示例文本)
vectorstore = FAISS.from_texts(
["兔子喜欢吃萝卜", "小明在华为工作", "熊喜欢吃蜂蜜"],
embedding=embeddings
)转为检索器(默认返回最相关的1条结果)
retriever = vectorstore.as_retriever(search_kwargs={"k": 1})
测试检索功能
vectorresult = retriever.invoke("熊喜欢吃什么")
print("检索结果:", vectorresult)预期输出:[Document(page_content='熊喜欢吃蜂蜜', metadata={})]
--------------------------
4. 配置 Prompt 模板和大模型
--------------------------
定义 Prompt 模板(限定只基于检索内容回答)
template = """
只根据以下文档回答问题,不要使用文档外的信息:{context}
问题:{question}
"""
prompt = ChatPromptTemplate.from_template(template)初始化输出解析器(将大模型输出转为字符串)
output_parser = StrOutputParser()
初始化通义千问大模型(通过阿里云 DashScope)
方式1:从环境变量读取 API Key(推荐)
确保 .env 文件中有 DASHSCOPE_API_KEY="你的API密钥"
api_key = os.getenv("DASHSCOPE_API_KEY")
if not api_key:
# 方式2:直接填写(测试用,不推荐)
api_key = "你的DashScope API Key"llm = ChatOpenAI(
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model="qwen-plus",
api_key=SecretStr(api_key),
temperature=0.1 # 降低随机性,让回答更精准
)--------------------------
5. 构建 RAG 链并运行
--------------------------
并行执行:检索上下文 + 透传问题
setup_and_retriev = RunnableParallel(
{
"context": retriever,
"question": RunnablePassthrough()
}
)拼接 RAG 链:检索 → 构建 Prompt → 调用大模型 → 解析输出
chain = setup_and_retriev | prompt | llm | output_parser
调用链并输出结果
try:
result = chain.invoke("熊喜欢吃什么?")
print("\n最终回答:", result)
except Exception as e:
print(f"\n运行出错:{e}")
多个参数的传入
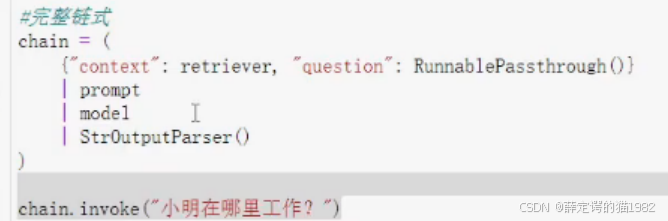
多个参数的传入
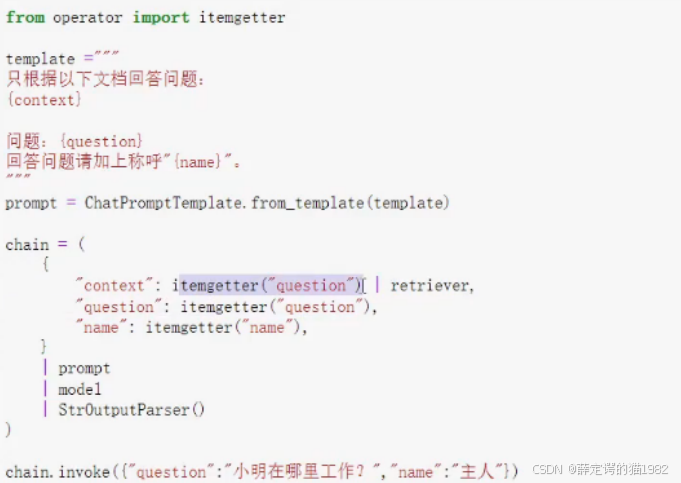
3.3 关键代码解析
-
嵌入模型初始化 :
HuggingFaceEmbeddings加载本地 BCE 模型,normalize_embeddings=True对生成的向量做归一化处理,能显著提升 FAISS 的检索准确率。 -
FAISS 向量库构建 :
FAISS.from_texts()直接将文本列表转为向量库,as_retriever()转为检索器,search_kwargs={"k": 1}指定返回 1 条最相关结果(可根据需求调整 k 值)。 -
RAG 链编排 :LangChain 的
RunnableParallel实现「检索上下文」和「透传问题」的并行执行,再通过管道符|串联「Prompt 构建→大模型调用→输出解析」,实现端到端的 RAG 流程。 -
通义千问调用 :阿里云 DashScope 提供了兼容 OpenAI 的接口,因此可以直接用
ChatOpenAI类调用通义千问,只需指定base_url和model参数即可。
四、运行结果与扩展方向
4.1 预期运行结果
检索到的相关文本: [Document(page_content='熊喜欢吃蜂蜜', metadata={})]
最终回答: 熊喜欢吃蜂蜜。4.2 扩展方向
- 知识库扩展 :将示例文本替换为本地文档(如 PDF、Word),通过 LangChain 的文档加载器(如
PyPDFLoader)读取; - 批量检索 :调整
search_kwargs={"k": 3},返回多条相关文本,提升回答丰富性; - 本地大模型:将通义千问替换为本地部署的大模型(如 Llama、Qwen-7B),摆脱 API 调用限制;
- 优化检索 :使用
BM25混合检索,或对嵌入模型做微调,提升检索精准度; - 界面封装:结合 Gradio/Streamlit 搭建可视化界面,降低使用门槛。
五、核心总结
- RAG 的核心是「先检索后生成」,通过 LangChain 可快速编排检索、Prompt、大模型调用的全流程;
- 本地嵌入模型(BCE)+ FAISS 向量库实现了轻量化的离线检索,无需依赖第三方向量数据库;
- 通义千问的 OpenAI 兼容接口降低了大模型调用的开发成本,新手也能快速上手。
这一轻量级 RAG 系统可作为基础框架,适配知识库问答、文档助手、智能客服等各类场景,是入门大模型应用开发的绝佳实践案例。