论文:CLEAR-KGQA: Clarification-Enhanced Ambiguity Resolution for Knowledge Graph Question Answering
arXiv 2025 Apr
作者:Liqiang et al. (北京大学 Peking University)
核心关键词:KGQA | clarification | disambiguation | Agent
一、动机 & 问题背景
该工作聚焦于解决知识图谱问答(KGQA)中的歧义问题。
尽管近年来KGQA系统取得了显著进展,尤其是在集成大型语言模型(LLM)方面,但它们通常假设用户问题是明确的 ,而这一假设在实际应用中很少成立。用户问题常存在实体歧义(如同名实体)和意图歧义(如对关系/属性的不同理解),导致模型难以生成正确的SPARQL查询。
- 传统方法(如DeCAF、Interactive-KBQA)依赖LLM直接生成查询,未主动处理歧义;
- 多轮交互中,LLM对澄清时机和内容的判断依赖自身能力,缺乏可解释的量化机制。
为了克服这些局限性,本文提出了CLEAR-KBQA 框架,通过交互式澄清动态处理实体歧义(例如 区分名称相似的实体)和意图歧义(例如 澄清用户查询的不同解释)。
CLEAR-KBQA采用贝叶斯推理机制量化查询歧义,并指导LLM在多轮对话框架内确定向用户请求澄清的时机与内容。
此外,本文贡献了一个已消除歧义的查询数据集。
二、CLEAR-KBQA 总体框架概述
CLEAR-KBQA框架使用Question Answering Agent(问答代理) 以及 Dummy User Agent(虚拟用户代理) 这两个Agent模块,通过自然对话来协作解决歧义。 Question Answering Agent生成下一步动作( a t a_t at),Dummy User Agent生成澄清反馈( c t c_t ct),共同构建多轮交互历史 H u H_u Hu,使代理能够迭代优化SPARQL查询。
CLEAR-KBQA 框架 设计了四类工具供 Agent 在多轮交互中调用,并以 Question Answering Agent(问答代理) 作为核心推理主体,负责基于当前上下文生成下一步动作。
在 SearchNodes 与 SearchGraphPattern 等关键工具调用的执行动作后,本文引入 Clarification Plugin(澄清插件),其通过基于贝叶斯推断与信息熵的歧义度量,对实体与意图层面的不确定性进行量化,并以提示信号的形式引导 Agent 决定是否发起澄清交互。
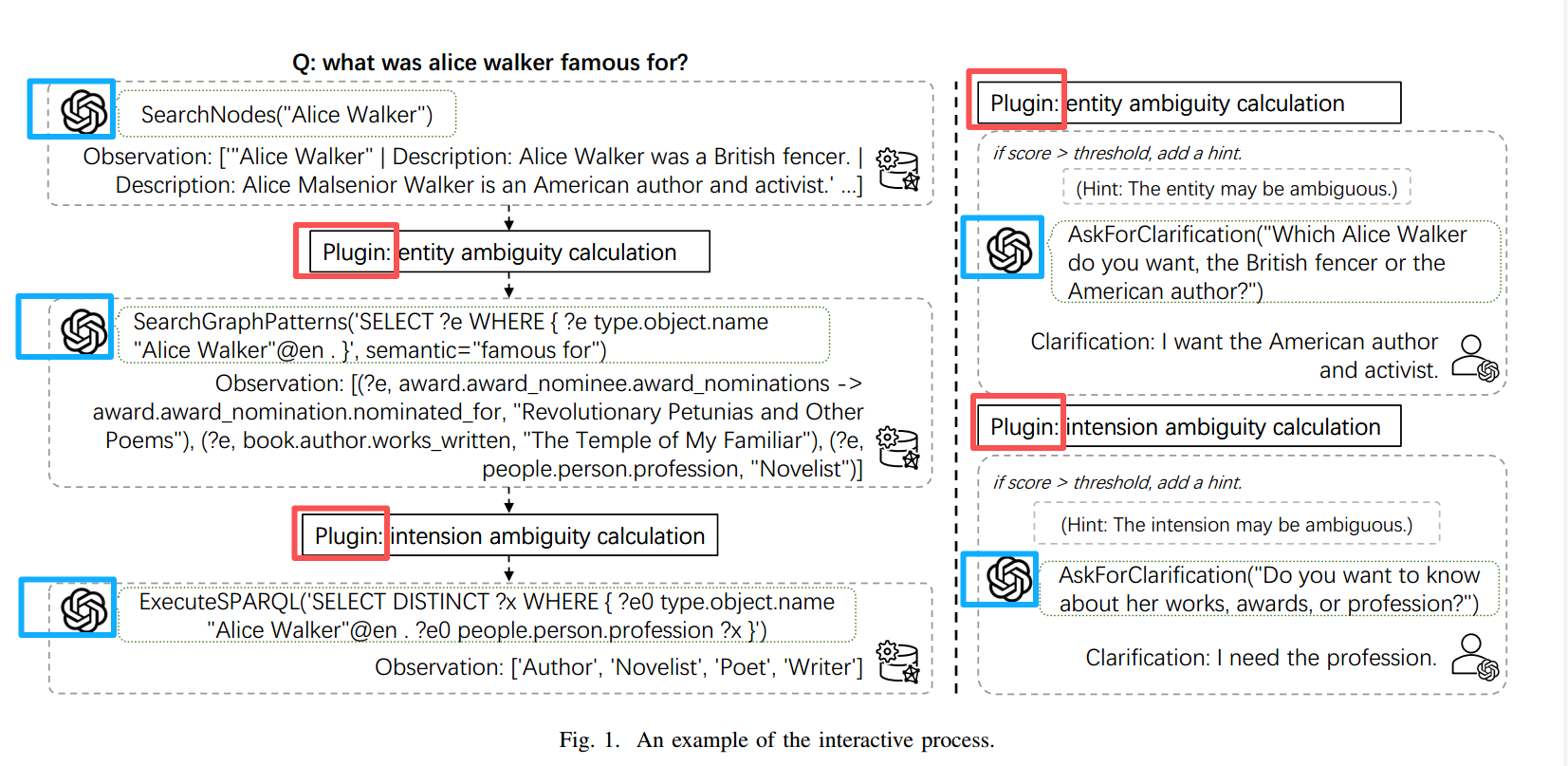
图中蓝框是Agent,左边的蓝框是Question Answering Agent(问答代理),右边的蓝框是Dummy User Agent(虚拟用户代理);红框是Clarification Plugin(澄清插件)。
三、工具设计
本框架设计了SearchNodes、SearchGraphPattern、ExecuteSPARQL、AskForClarification 四个工具,待Agent调用。
SearchNodes(name): 该工具通过使用给定的实体名称在知识图谱中搜索节点来执行实体链接,返回正式的实体名称及其区别特征,如描述和类型。
SearchGraphPattern(sparql,semantic): 该工具通过查询指定实体周围的单跳子图来识别和排名相关的关系,优化语义相关性并处理CVT节点等复杂结构。
ExecuteSPARQL(sparql): 该工具直接针对知识图谱执行SPARQL查询,提供基本的查询功能。
AskForClarification(text): 该工具通过在检测到歧义时,生成自然语言澄清请求来管理交互式消歧。该工具中断交互过程并在继续之前等待用户输入。
四、Question Answering Agent(问答代理)
Question Answering Agent 负责通过多轮交互与知识图谱(KG)协作,决定下一步的动作(包括生成并执行 SPARQL 查询)。其设计目标是动态处理实体歧义与意图歧义,实现上下文感知的推理与澄清。
问答代理的核心循环 :动作生成 → 工具执行,具体步骤如下:
1. 动作生成
- 公式 :
a T = LLM ( { Prompt q a , H } ) (2) a_T = \text{LLM}(\{\text{Prompt}_{qa}, H\}) \tag{2} aT=LLM({Promptqa,H})(2)
其中:- Prompt q a \text{Prompt}_{qa} Promptqa:预定义的提示词,包含工具描述、交互格式和示例(如"你是问答代理,需调用工具并生成 SPARQL 查询")。
- H H H:交互历史,包含之前的动作 a 0 . . . a T − 1 a_0...a_{T-1} a0...aT−1、观察结果 o 0 . . . o T − 1 o_0...o_{T-1} o0...oT−1 和用户澄清反馈 c 0 . . . c T − 1 c_0...c_{T-1} c0...cT−1(公式3)。
交互历史结构 :
H = { a 0 , o 0 , c 0 , . . . , a T − 1 , o T − 1 , c T − 1 } H = \{a_0, o_0, c_0, ..., a_{T-1}, o_{T-1}, c_{T-1}\} H={a0,o0,c0,...,aT−1,oT−1,cT−1}
其中:
- a t a_t at:第 t t t 轮的动作(如"调用SearchNodes('Alice Walker')");
- o t o_t ot:工具返回的观察结果(如"实体列表:英国击剑运动员、美国作家");
- c t c_t ct:用户对澄清请求的反馈(如"选择美国作家")。
动作类型 :
工具调用: SearchNodes(name)(检索实体)、SearchGraphPattern(sparql, semantic)(检索关系)、ExecuteSPARQL(sparql)(执行查询)。
2. 终止条件
- 成功终止:SPARQL 查询执行后返回有效答案,代理输出最终结果。
- 迭代终止:若澄清请求后仍无法消除歧义(如用户多次反馈无效),代理生成最可能的查询并执行。
五、Dummy User Agent(虚拟用户代理)
Dummy User Agent 用于在多轮交互中生成自然语言澄清回答。
反馈生成公式 :
c t = LLM ( { Prompt u , S ′ , a t } ) c_t = \text{LLM}\left(\left\{\text{Prompt}_u, S', a_t\right\}\right) ct=LLM({Promptu,S′,at})
-
输入 :
-
Prompt u \text{Prompt}_u Promptu:引导LLM生成合理用户反馈的提示词。
-
S ′ S' S′(黄金SPARQL查询)真实答案对应的正确SPARQL,用于指导反馈生成。
-
a t a_t at :Question Answering Agent在第 t t t 轮生成的澄清请求。
-
-
输出 :
- 用户的自然语言反馈 c t c_t ct(如"我想了解美国作家Alice Walker的职业。")。
六、Clarification Plugin(澄清插件)
Clarification Plugin 是CLEAR-KBQA框架中负责量化实体与意图歧义 、动态触发澄清请求 的核心组件。其目标是通过贝叶斯概率与熵的计算,为问答代理(Question Answering Agent)提供客观的澄清时机与澄清内容的决策依据。
6.1 Plugin核心目标
- 歧义量化:将实体识别和意图解析中的模糊性转化为可计算的数值指标(歧义分数)。
- 澄清决策:当歧义分数超过预设阈值时,自动生成自然语言澄清问题,引导用户提供关键信息,消除歧义。
- 闭环优化:结合用户反馈迭代修正KG查询,提升最终答案的准确性。
6.2 实体歧义计算
针对KG中候选实体的识别歧义,插件通过贝叶斯后验概率 与熵量化不确定性,公式如下:
6.2.1. 先验概率(实体流行度)
用数据集中的实体出现频率 作为先验,即越流行的实体,越可能是用户想指的那个。
- 定义:实体在KG中的出现频率(基于的数据集的某实体出现次数)。
- 公式 :
P ( e i ) = u e i ∑ j = 1 N u e j P(e_i) = \frac{u_{e_i}}{\sum_{j=1}^N u_{e_j}} P(ei)=∑j=1Nuejuei
其中, u e i u_{e_i} uei 为实体 e i e_i ei 的流行度, N N N 为候选实体总数。
6.2.2. 后验概率(语义相关性)
困惑度衡量的是一个语言模型看到某段文本时的惊讶程度;PPL 越低 说明 Q 和 Desc 语义一致。
- 定义:实体描述文本与用户问题的语义匹配度(通过LLM的困惑度(PPL)计算)。
- 公式 :
P ( e i ∣ Q ) ∝ 1 PPL ( Q , Desc ( e i ) ) P(e_i | Q) \propto \frac{1}{\text{PPL}(Q, \text{Desc}(e_i))} P(ei∣Q)∝PPL(Q,Desc(ei))1
其中, Desc ( e i ) \text{Desc}(e_i) Desc(ei) 为实体 e i e_i ei 的描述文本(如"Alice Walker: British fencer"或"American author"), PPL ( Q , Desc ( e i ) ) \text{PPL}(Q, \text{Desc}(e_i)) PPL(Q,Desc(ei)) 为问题 Q Q Q 与实体描述的困惑度(越低表示相关性越高)。 PPL(·)表示的困惑函数使用softmax函数进行归一化以确保有效的概率分布。
6.2.3. 实体歧义分数
这里使用不确定性度量函数Entropy来进行 实体歧义的打分;不确定性越高即歧义越严重。
- 定义:候选实体集合的概率分布熵,反映选择多个实体时的不确定性。
- 公式 :
H = − ∑ i = 1 N P ~ ( e i ∣ Q ) log P ~ ( e i ∣ Q ) H = -\sum_{i=1}^N \tilde{P}(e_i | Q) \log \tilde{P}(e_i | Q) H=−i=1∑NP~(ei∣Q)logP~(ei∣Q)
Ambiguity E ( Q , E obs ) = H log N \text{Ambiguity}E(Q, E{\text{obs}}) = \frac{H}{\log N} AmbiguityE(Q,Eobs)=logNH
其中, P ~ ( e i ∣ Q ) \tilde{P}(e_i | Q) P~(ei∣Q) 为后验概率的归一化结果(softmax), H H H 为熵值, log N \log N logN 为最大可能熵(当所有实体概率均等时)。分数范围为 0 , 1 0,1 0,1,越接近1表示歧义越严重。
6.3 意图歧义计算
针对KG中谓词/关系的选择歧义,插件通过联合概率 与关系文本匹配度量化不确定性:
6.3.1. 先验概率(谓词-实体联合概率)
- 定义 :KG中谓词 r i r_i ri 与尾实体 e i ′ e'_i ei′ 的联合出现频率(三元组 ( e h , r i , e i ′ ) (e_h, r_i, e'_i) (eh,ri,ei′) 的计数)。
- 公式 :
P ( r i , e i ′ ) = count ( e h , r i , e i ′ ) ∑ j = 1 M count ( e h , r j , e j ′ ) P(r_i, e'_i) = \frac{\text{count}(e_h, r_i, e'i)}{\sum{j=1}^M \text{count}(e_h, r_j, e'_j)} P(ri,ei′)=∑j=1Mcount(eh,rj,ej′)count(eh,ri,ei′)
其中, M M M 为候选谓词-实体对总数。
6.3.2 后验概率(谓词语义相关性)
- 定义 :问题 Q Q Q 与谓词-实体对 ( r i , e i ′ ) (r_i, e'_i) (ri,ei′) 描述的语义匹配度(通过LLM计算PPL)。
- 公式 :
P ( r i ∣ Q ) ∝ 1 PPL ( Q , Desc ( r i , e i ′ ) ) P(r_i | Q) \propto \frac{1}{\text{PPL}(Q, \text{Desc}(r_i, e'_i))} P(ri∣Q)∝PPL(Q,Desc(ri,ei′))1
其中, Desc ( r i , e i ′ ) \text{Desc}(r_i, e'_i) Desc(ri,ei′) 为谓词 r i r_i ri 与尾实体 e i ′ e'_i ei′ 的组合描述(如"famous for"与"Alice Walker"的关系)。
6.3.3 意图歧义分数
- 定义:候选谓词集合的概率分布熵,反映关系选择的不确定性。
- 公式 :
Ambiguity I ( Q , R obs ) = − ∑ i = 1 M P ~ ( r i ∣ Q ) log P ~ ( r i ∣ Q ) \text{Ambiguity}I(Q, R{\text{obs}}) = -\sum_{i=1}^M \tilde{P}(r_i | Q) \log \tilde{P}(r_i | Q) AmbiguityI(Q,Robs)=−i=1∑MP~(ri∣Q)logP~(ri∣Q)
其中, P ~ ( r i ∣ Q ) \tilde{P}(r_i | Q) P~(ri∣Q) 为后验概率的归一化结果,分数范围同样为 0 , 1 0,1 0,1,越高表示意图越模糊。
6.4 触发机制与阈值优化
6.4.1 澄清触发条件
- 当任一歧义分数超过对应阈值时,触发澄清请求:
- 实体歧义 : Ambiguity E > 0.6 \text{Ambiguity}_E > 0.6 AmbiguityE>0.6
- 意图歧义 : Ambiguity I > 0.8 \text{Ambiguity}_I > 0.8 AmbiguityI>0.8
6.4.2 阈值选择实验
通过网格搜索(阈值范围 0.5 , 0.9 0.5, 0.9 0.5,0.9)确定最优阈值:
- 实验数据:在WebQSP+CWQ数据集上,实体阈值0.6、意图阈值0.8时,F1分数最高(约提升11.98%~23.41%)。
- 结论:低阈值(如0.5)会增加澄清频率但降低准确率,高阈值(如0.8)可能遗漏歧义,0.6/0.8为平衡点。
Clarification Plugin通过贝叶斯概率+熵量化歧义 、动态触发澄清,使问答代理能够在KGQA中主动处理模糊性,实验证明其显著提升了实体识别和关系选择的准确性,是CLEAR-KBQA框架中解决歧义的核心技术。