文章目录
- [1. 创建数据库](#1. 创建数据库)
- [2. 删除数据库](#2. 删除数据库)
- [3. 编码集和校验规则](#3. 编码集和校验规则)
-
- [3.1 概念理解](#3.1 概念理解)
- [3.2 查看系统默认编码集以及校验规则](#3.2 查看系统默认编码集以及校验规则)
- [3.3 查看数据库支持的所有字符集和校验规则](#3.3 查看数据库支持的所有字符集和校验规则)
- [4. 创建指定编码集和校验规则的数据库](#4. 创建指定编码集和校验规则的数据库)
- [5. 验证不同校验规则的影响](#5. 验证不同校验规则的影响)
-
- [5.1 大小写](#5.1 大小写)
- [5.2 排序](#5.2 排序)
- [6. 库的其它操作](#6. 库的其它操作)
-
- [6.1 查看数据库](#6.1 查看数据库)
- [6.2 显示创建语句](#6.2 显示创建语句)
- [6.3 修改数据库](#6.3 修改数据库)
- [6.4 库的备份与恢复](#6.4 库的备份与恢复)
-
- [6.4.1 数据库的备份](#6.4.1 数据库的备份)
- [6.4.2 数据库的恢复](#6.4.2 数据库的恢复)
- [6.4.3 注意事项](#6.4.3 注意事项)
- [7. 查看连接情况](#7. 查看连接情况)
1. 创建数据库
语法:
sql
CREATE DATABASE [IF NOT EXISTS] db_name;大写的表示关键字(SQL 关键字不区分大小写)
创建数据库:create database 数据库名;
中括号里面的是可选项
IF NOT EXISTS 的意思就是如果数据库不存在,我才创建,如果已经存在,那就不会再创建了
下面我们来练习一下:
首先我们进入到我们上篇文章提到的数据库对应的数据目录(datadir)下,同时登录MySQL
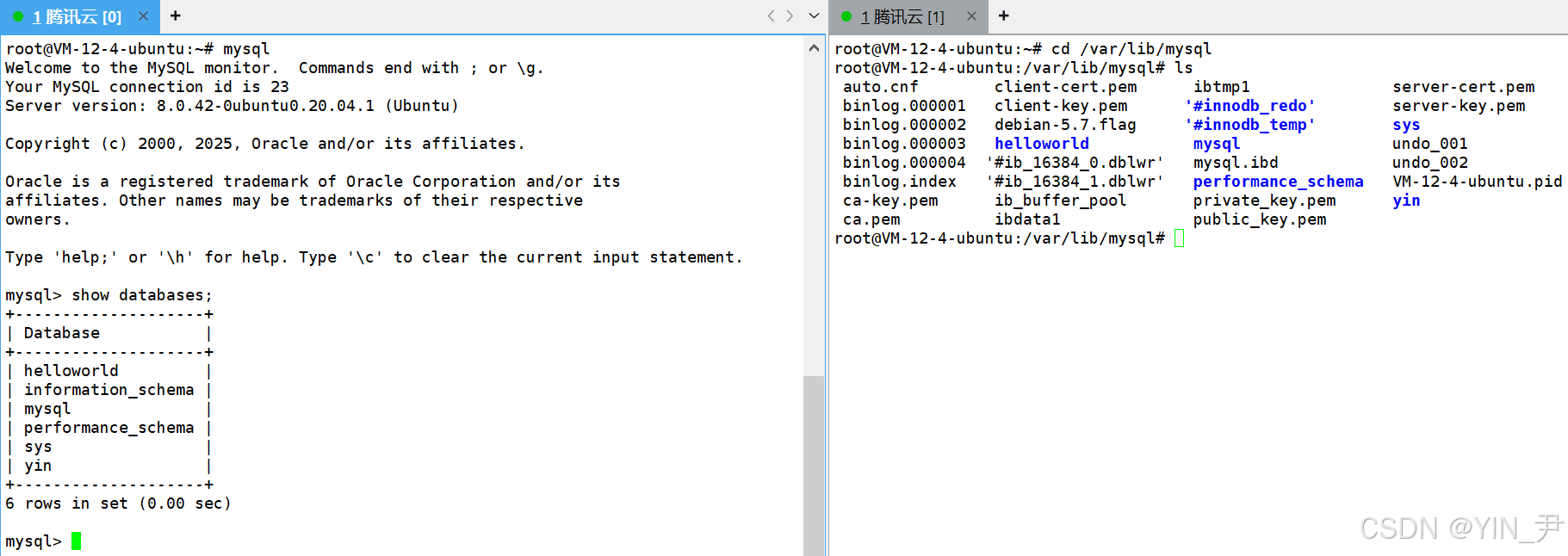
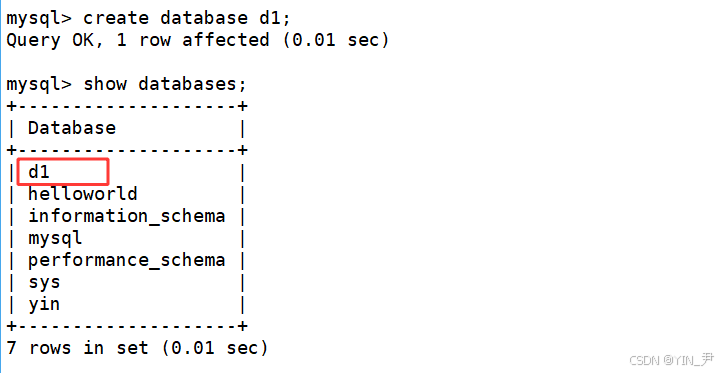
来创建一个数据库比如名字叫d1
create database d1;
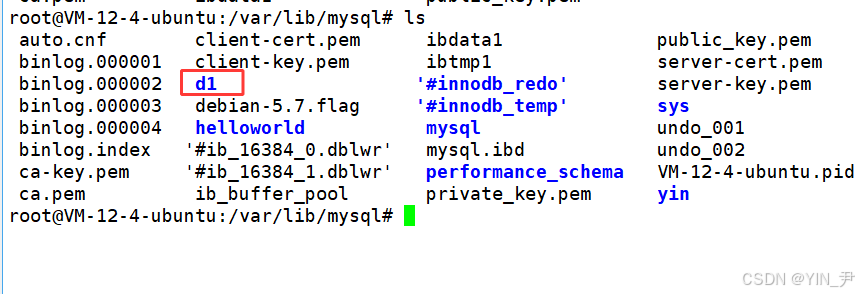
同时,datadir目录下肯定也会多一个名为d1的目录
2. 删除数据库
现在d1我不想用了,想把它删掉
删除数据库语法:
sql
DROP DATABASE [IF EXISTS] db_ name;drop database 数据库名;
IF EXISTS 的意思就是如果该数据库存在我就删,如果不存在,那也不用删了,因为本来就没有
执行删除之后的结果:
数据库内部看不到对应的数据库
对应的数据库文件夹被删除,级联删除,里面的数据表全部被删
注意:不要随意删除数据库
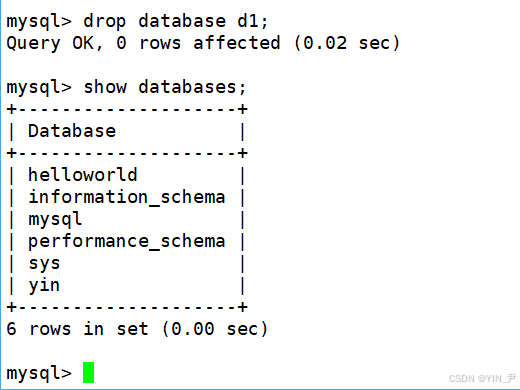
演示一下,删除d1
drop database d1;
就把它删掉了(MySQL层面)
同时我们看到datadir目录下对应d1目录也被删了(文件系统层面)

3. 编码集和校验规则
3.1 概念理解
数据的存取必然会涉及到编码格式的问题:
编码必须是一致的,即数据存的时候用的什么编码,那将来取数据的时候就也要用相同的编码取出。
就好比我用汉语写了一篇文章,那将来读文章的人必然也要使用汉语去读,如果让一个不会汉语的美国人、韩国人用他们的语言去读,那他肯定读不懂。
那编码集和校验规则:
编码集即数据库存数据时所采用的编码。
校验规则是什么意思呢?数据存储之后,未来我们会进行各种查找或匹配操作,那肯定要进行比较 ,比较肯定要先读取出来,那读取时也要保证使用的编码是一致的。所以校验规则(校验集)其实就是数据库进行字段比较时所采用的编码解释方式,以及具体的比较算法 + 排序算法。
所以不论数据库做什么操作,都必须保证编码一致,这样才能避免进行各种操作时,出现乱码。
3.2 查看系统默认编码集以及校验规则
查看默认字符集(编码集):
show variables like 'character_set_database';
可以看到当前系统的默认字符集是utf8mb4

查看默认校验规则:
show variables like 'collation_database';
是utf8mb4_0900_ai_ci

3.3 查看数据库支持的所有字符集和校验规则
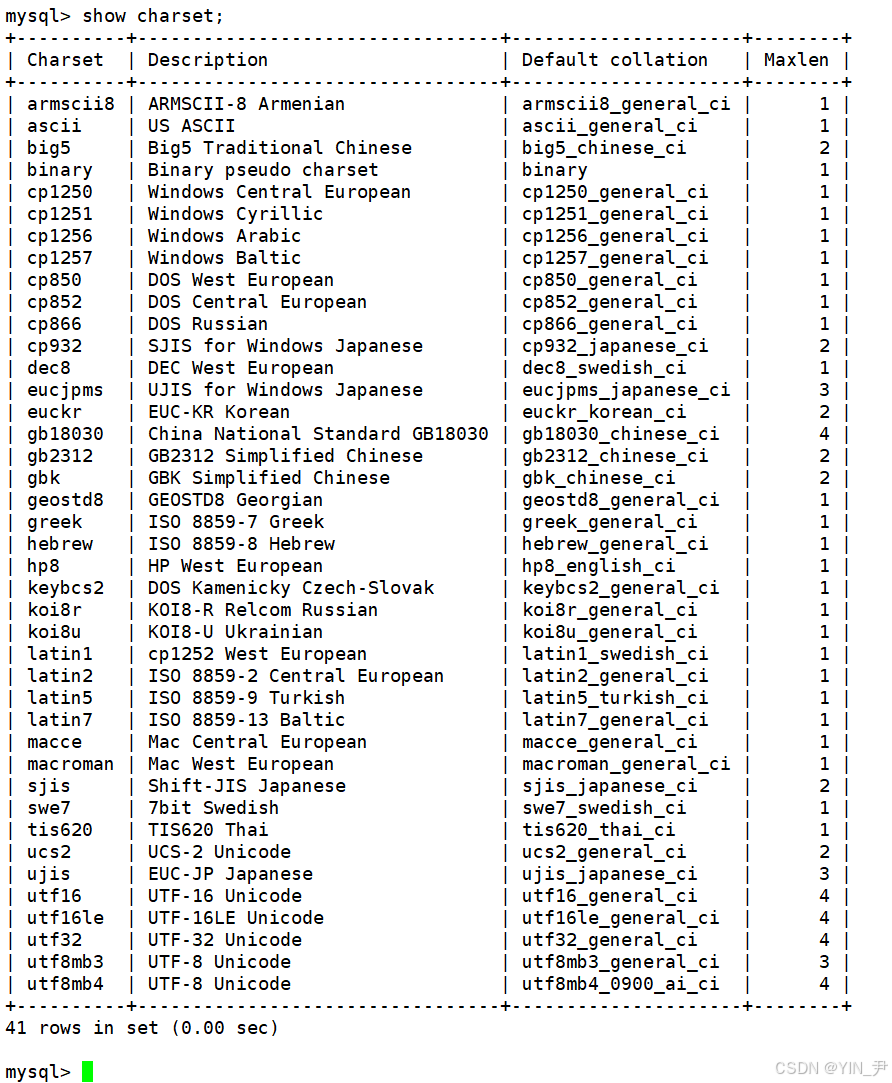
查看数据库支持的字符集
show charset;
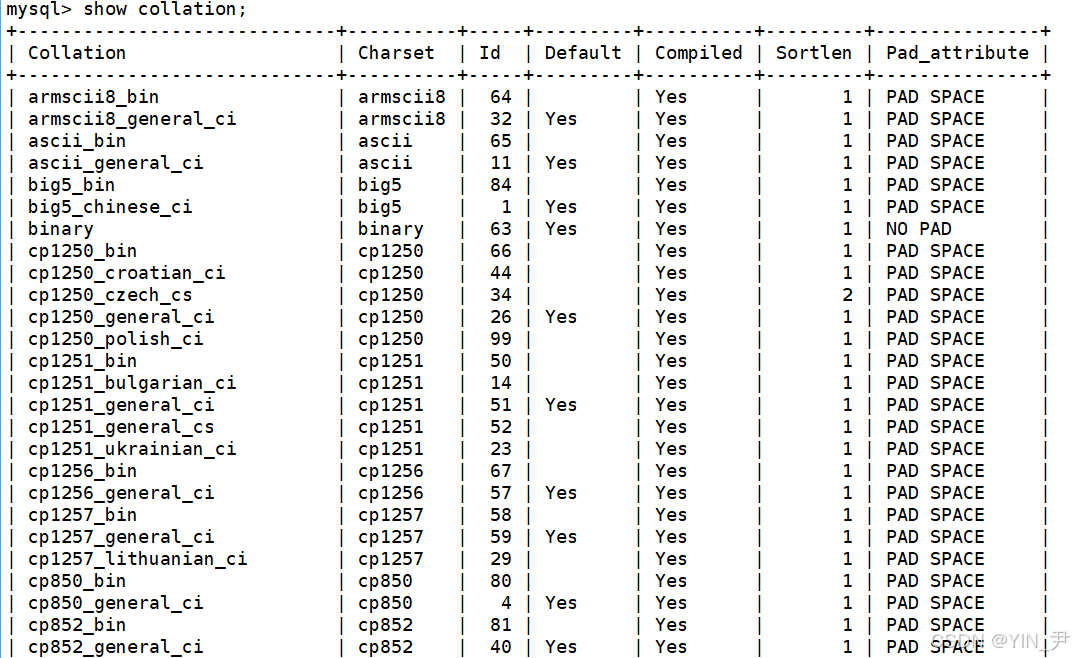
查看数据库支持的字符集校验规则
show collation;
非常多,后面还有,就不全截了
4. 创建指定编码集和校验规则的数据库
创建一个使用utf8字符集的 db2 数据库:
sql
create database db2 charset=utf8;或者:
sql
create database db2 character set utf8;创建一个使用utf8字符集,校验规则为utf8_general_ci的 db3 数据库:
sql
create database db3 charset=utf8 collate utf8_general_ci;说明:
当我们创建数据库没有指定字符集和校验规则时,使用系统默认的字符集和校验规则(当然我们在数据库中建的表,默认就使用其所在库的对应编码)
5. 验证不同校验规则的影响
5.1 大小写
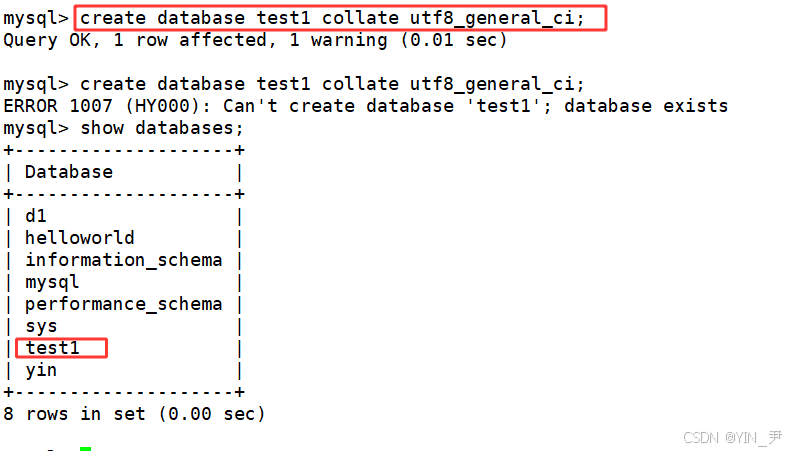
创建一个数据库,校验规则使用utf8_ general_ ci不区分大小写:
create database test1 collate utf8_general_ci;(编码集我们没有指定那就用默认的)
然后我们在这个数据库下创建一个表
use test1;(首先选中这个数据库)
create table person(name varchar(20));
创建一张表,只有一列,名为person(表的操作我们后面也会专门讲,大家先简单了解一下,知道我们在干什么就行了)
然后我们插入一些数据
查看一下
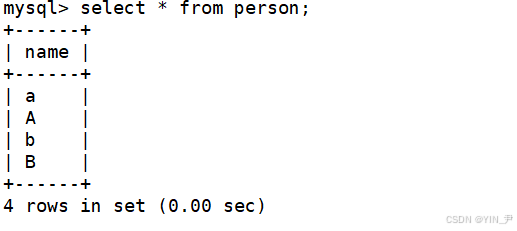
select * from person;查看表person中的所有数据
没毛病,插入进去了
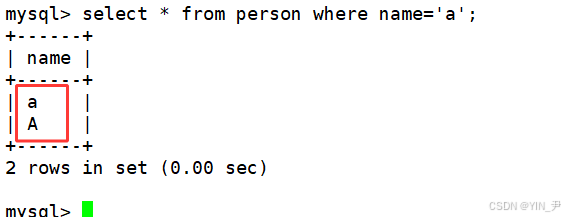
然后我想查找一些name为'a'的所有数据(肯定要进行比较,这时候使用的就是校验规则)
select * from person where name='a';
从结果可以得知,校验规则utf8_ general_ ci是不区分大小写的


接下来,我们换一种校验规则,新建一个数据库,进行同样的操作。
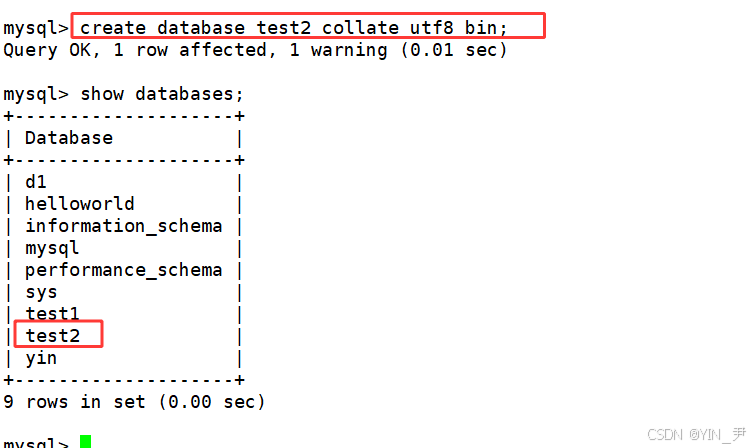
创建一个数据库,校验规则使用utf8_ bin区分大小写:
create database test2 collate utf8_bin;
use test2;
create table person(name varchar(20));
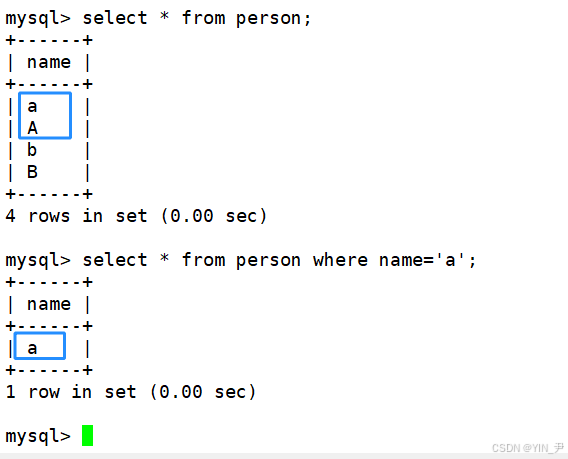
插入一些数据
然后我们也来查找一下name为'a'的数据
select * from person where name='a';
从结果可以看出,校验规则utf8_ bin区分大小写
相信这些例子可以进一步加深我们对校验规则的理解


5.2 排序
下面再做一个实验:
select * from person order by name;显示所有的数据,并按照name排序
分别对两个数据库中的person 表进行该操作
先看test2
可以看出来默认是一个升序排序(小写字母ASCII码值比大写字母大)
再看test1
不区分大小写(认为a和A是一样的),所以是这样


6. 库的其它操作
6.1 查看数据库
sql
show databases;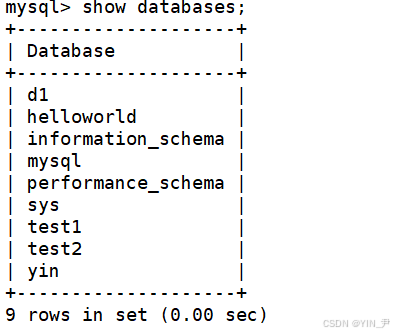
上面我们已经用过很多次了。
想再补充的一些就是:
上面我们提到过我们想再某个数据库里面建表,首先要use 这个数据库
如果你进行了一堆操作之后想不起来自己现在在哪个数据库里面,怎么查看一下呢?
select database();

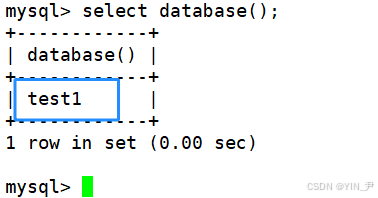
6.2 显示创建语句
sql
show create database 数据库名;比如:
show create database test1;
可以看到后面显示的,创建语句就是CREATE DATABASE test1
说明:
MySQL 建议我们关键字使用大写,但是不是必须的。
数据库名字的反引号``,是为了防止使用的数据库名刚好是关键字。
/*!40100 default.... */这个不是注释,表示当前mysql版本大于4.01版本,就执行这句话

6.3 修改数据库
说明:
对数据库的修改主要指的是修改数据库的字符集,校验规则
语法:
sql
ALTER DATABASE db_name
[alter_spacification ,alter_spacification]...]举个栗子:
把数据库test1的字符集改为gbk
alter database test1 charset=gbk;
把校验规则修改为gbk_chinese_ci
alter database test1 collate gbk_chinese_ci;


6.4 库的备份与恢复
6.4.1 数据库的备份
现在有一个数据库比如我们的test1,里面有一个表person,表里面我们也插入了一些数据
那现在我想对这个数据库进行一个备份,怎么做呢?
比如把它备份到/home/yhq/mysql目录下
我们要使用的工具是mysqldump
语法:
mysqldump -P3306 -u root -p -B 数据库名 > 数据库备份存储的文件路径
-P3306 -u root -p 这几个选项我们上一篇文章都介绍过了
然后-B后面跟我们要备份的数据库名,然后 >(重定向,我们之前Linux指令的文章里介绍过) ,接着跟上要备份的路径
来试一下
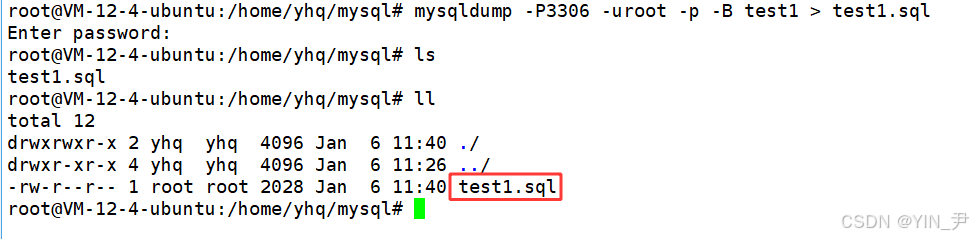
把数据库test1备份到/home/yhq/mysql目录下的test1.sql文件中(当前已经进入这个目录了):
mysqldump -P3306 -uroot -p -B test1 > test1.sql
因为目前我们是免密码登录的,所以提示我们输入密码不用输直接回车就完成了
然后,我们发现:
当前目录下就生成了test1.sql这个文件
那它当然就是我们的数据库备份文件了
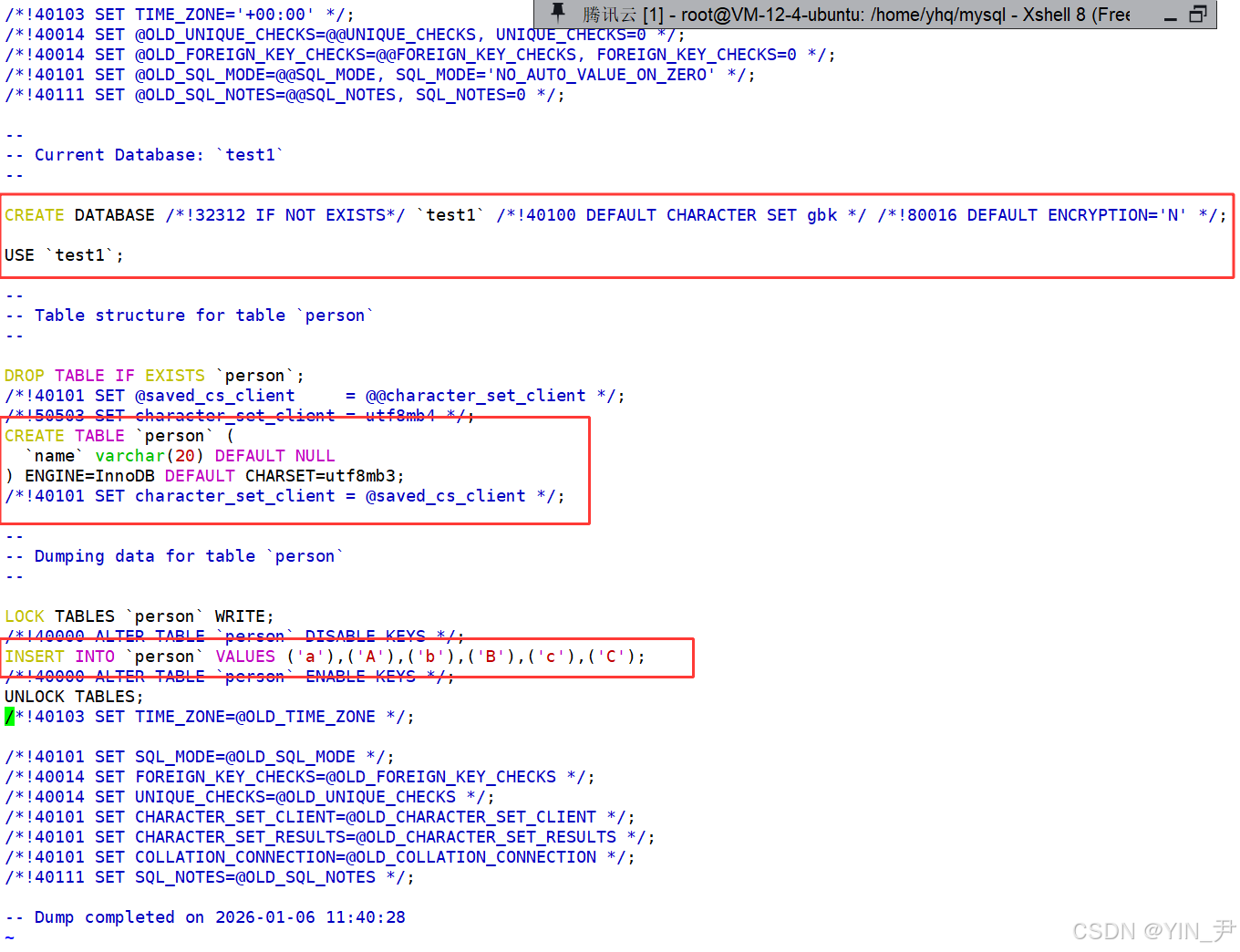
打开看一下
其实就是把我们整个创建数据库,建表,插入数据的语句都装载到了这个文件中。
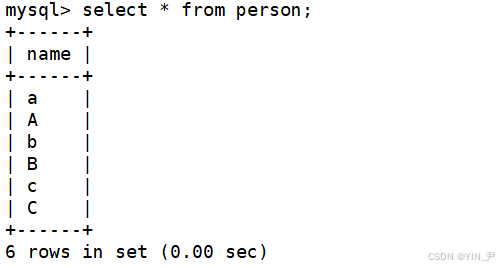
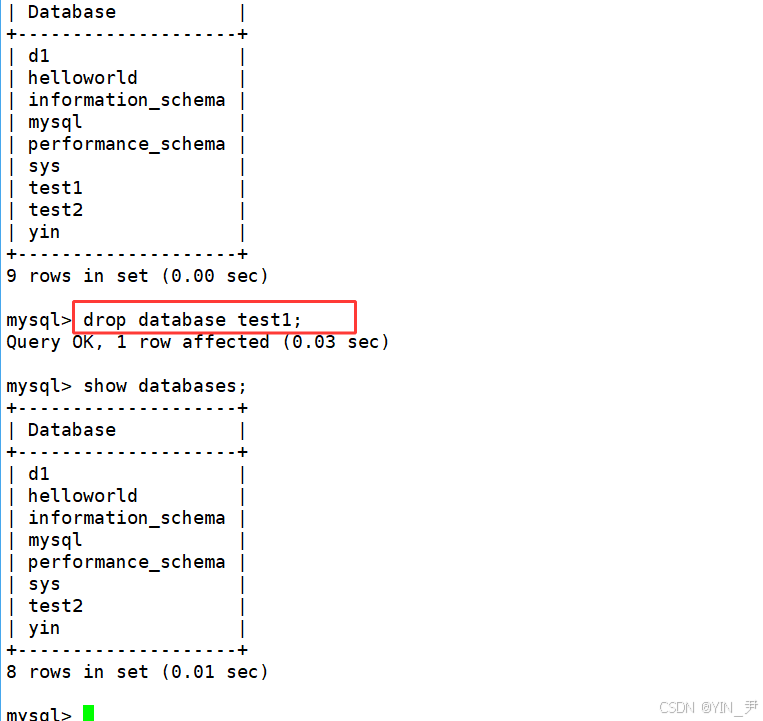
那现在有备份了,我来尝试把原数据库直接删掉:
drop database test1;
现在就没了

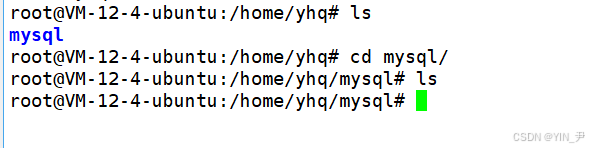

那然后呢,假设我把test1的备份文件拷贝到了我远方的朋友的另一台机器上,她的机器上是没有test1这个数据库,那现在她想利用test1.sql把数据库test1恢复出来,怎么做呢?
6.4.2 数据库的恢复
语法:
source 对应的数据库备份文件路径
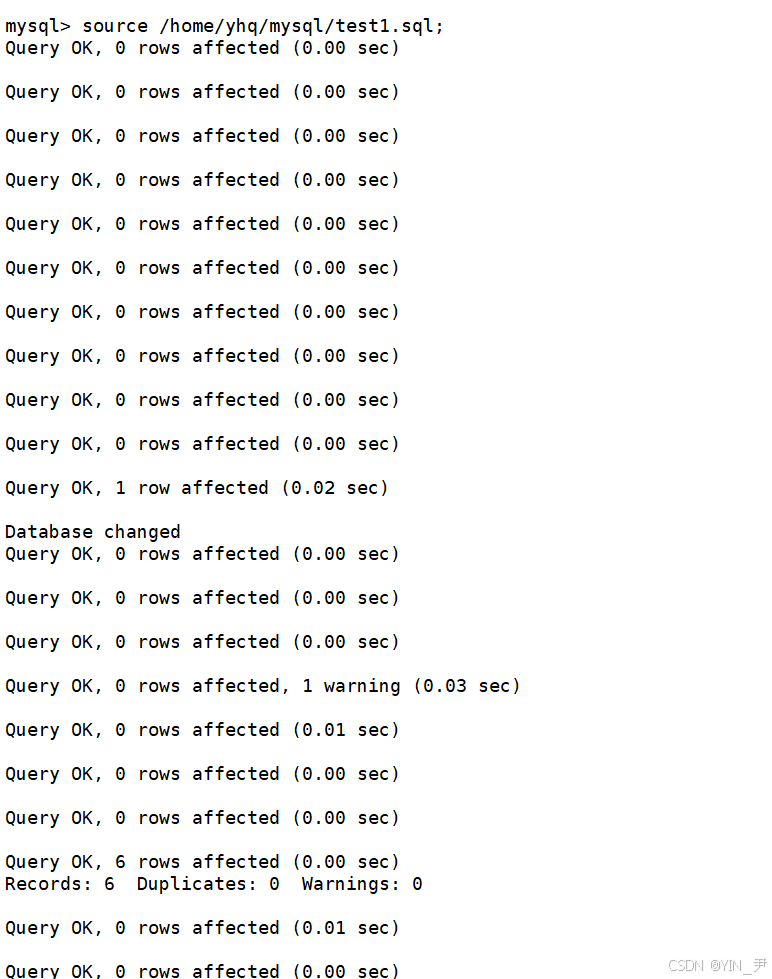
试一下:
source /home/yhq/mysql/test1.sql;
然后,我们看到
这个数据库就被成功恢复了(其实就是把里面存的所有的SQL语句重新执行一次)

6.4.3 注意事项
如果备份的不是整个数据库,而是其中的一张表,怎么做?
mysqldump -u root -p 数据库名 表名1 表名2 > D:/mytest.sql
还是一样的,只需要在数据库名后面 直接指定要备份的表名即可,可以多个
同时备份多个数据库
mysqldump -u root -p -B 数据库名1 数据库名2 ... > 数据库存放路径
另外:
如果备份一个数据库时,没有带上-B参数,即:
mysqldump -P3306 -u root -p 数据库名 > 数据库备份存储的文件路径
那么在恢复数据库时,需要先创建空数据库,然后use这个数据库,再使用source来还原 。(所以可以利用这种方式重命名数据库)
(没有带-B参数对应的备份文件里面就没有创建数据库对应的sql语句)
7. 查看连接情况
语法:
sql
show processlist示例:
可以告诉我们当前有哪些用户连接到我们的MySQL,如果查出某个用户不是你正常登陆的,很有可能你
的数据库被人入侵了。以后大家发现自己数据库比较慢时,可以用这个指令来查看数据库连接情况。

库的操作,讲解完毕!