案例1:隐式转换
1、创建普通索引B+树
sql
CREATE TABLE `user_test` (
`id` int NOT NULL AUTO_INCREMENT,
`userId` varchar(32) NOT NULL,
`age` varchar(16) NOT NULL,
`name` varchar(255) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_userid` (`userId`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb32、创建唯一索引,B+树
sql
CREATE TABLE `device_shift_info` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键',
`workshop_code` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '车间编码',
`workshop_name` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '车间名称',
`line_code` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '线别编码',
`line_name` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '线别名称',
`device_code` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '设备编码',
`device_name` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '设备名称',
`shift_code` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '班次编码',
`shift_name` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '班次名称',
`shift_date` date DEFAULT NULL COMMENT '班次日期',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `device_shift_date` (`workshop_code`,`line_code`,`device_code`,`shift_date`,`shift_name`)
) ENGINE=InnoDB AUTO_INCREMENT=27 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='设备班次数据信息'userId字段为字串类型,是B+树的普通索引,如果查询条件传了一个数字过去,会导致索引失效。如下:
sql
explain select * from user_test WHERE userId =123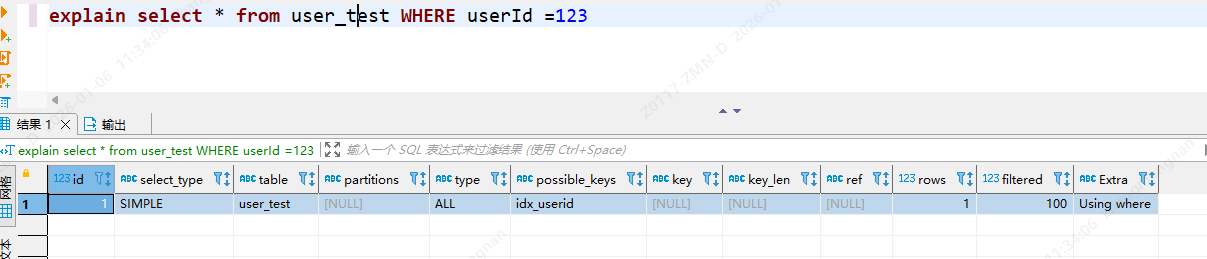
如果给数字加上'',也就是说,传的是一个字符串呢,当然是走索引,如下图:
sql
explain select * from user_test WHERE userId ='123'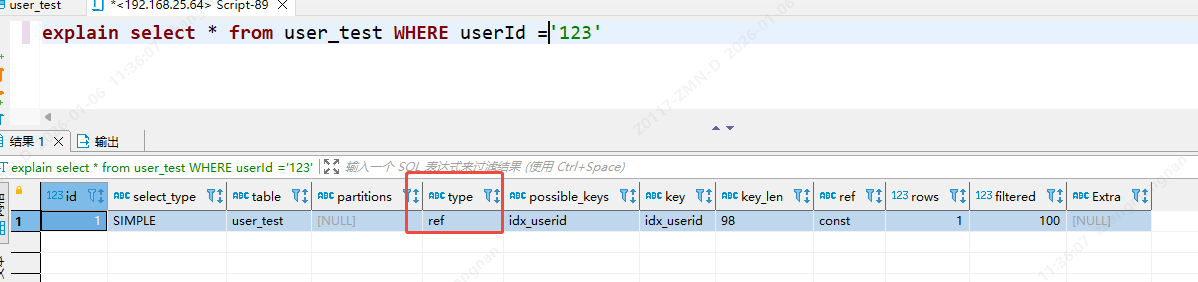
为什么第一条语句未加单引号就不走索引了呢?这是因为不加单引号时,是字符串跟数字的比较,它们类型不匹配,MySQL会做隐式的类型转换,把它们转换为浮点数再做比较。隐式的类型转换,索引会失效
案例2:最左匹配
联合索引
sql
CREATE TABLE `user_test` (
`id` int NOT NULL AUTO_INCREMENT,
`user_id` varchar(32) NOT NULL,
`age` varchar(16) NOT NULL,
`name` varchar(255) NOT NULL,
`remark` varchar(255) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_userid_name_age` (`user_id`,`name`,`age`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3
sql
explain select * from user_test WHERE 1=1 and user_id ='1' and age ='123' and name ='1' -- 索引ref
explain select * from user_test WHERE 1=1 and age ='123' and name ='1' and user_id ='1' -- 索引ref
explain select * from user_test WHERE 1=1 and user_id ='1' and age ='123' -- 索引ref
explain select * from user_test WHERE 1=1 and name ='1' and age ='123' -- 索引index
explain select * from user_test WHERE age ='123' -- 索引index
explain select * from user_test WHERE remark ='123' -- 索引失效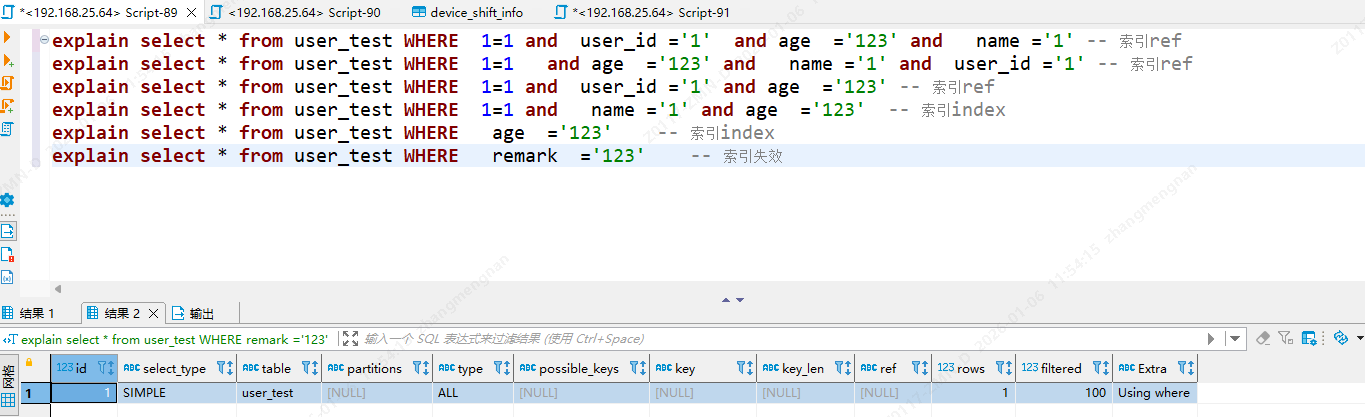
案例3:深分页问题
当数量特别大的时候分页取数据
sql
explain select id,name,balance from account where create_time> '2020-09-19' limit 100000,10;limit语句会先扫描offset+n行,然后再丢弃掉前offset行,返回后n行数据。也就是说limit 100000,10,就会扫描100010行,而limit 0,10,只扫描10行。
limit 100000,10 扫描更多的行数,也意味着回表更多的次数
如何优化深分页问题? 一般采用标签记录法和延迟关联法
标签记录法:记录上次扫描的id(必须有自增的字段)
sql
select id,name,balance FROM account where id > 100000 limit 10;延迟关联法
就是把条件转移到主键索引树
sql
select acct1.id,acct1.name,acct1.balance
FROM account acct1 INNER JOIN (SELECT a.id FROM account a WHERE a.create_time > '2020-09-19' limit 100000, 10) AS acct2 on acct1.id= acct2.id;优化思路就是,先通过idx_create_time二级索引树查询到满足条件的主键ID,再与原表通过主键ID内连接,这样后面直接走了主键索引了,同时也减少了回表
案例4:in元素过多
sql
select * from user where user_id in (select author_id from artilce where type = 1);
当in 后面是一个子查询时候不确定有多少,般建议不要超过200个,如果超过了,建议分组,每次200一组进行