文章目录
-
- 1、资料快车
- 2、preface
- 3、ARM-GPU选型
- 4、从图片渲染流程看GPU的作用
- 5、GPU物理模型概述
- 6、GPU的工作流程
-
- 1)CPU如何与GPU交互?
- 2)GPU的程序片段和数据从哪里获得?
- 3)谁来指挥GPU驱动工作?
- [4)GPU Job的概念](#4)GPU Job的概念)
- 5)GPU驱动编程接口
- 6)小结
- [7、ARM GPU驱动概述](#7、ARM GPU驱动概述)
- 8、panfrost-gpu驱动分析
- 9、使用GL库画一个静态彩色三角形流程
- 10、GPU的内存分配和拷贝
1、资料快车
1、Linux GPU物理模型 : http://joyxu.github.io/2021/05/09/gpu01/
2、Linux GPU工作流程:http://joyxu.github.io/2021/05/10/gpu02/
3、Linux 图像软件栈:http://joyxu.github.io/2021/05/11/gpu03/
4、ARM Mali GPU openGL端到端流程 : http://joyxu.github.io/2021/05/12/gpu04/
5、Linux GPU系列-05-MESA架构 :http://joyxu.github.io/2021/05/13/gpu05/
6、Rockchip MALI_GPU_driver
https://opensource.rock-chips.com/wiki_Graphics#MALI_GPU_driver
7、GPU驱动开发入门------从OpenGL到GPU硬件(以ARM Mali为例)
https://zhuanlan.zhihu.com/p/1930594532157813197
8、Rockchip RK3399-Mali-T860 GPU驱动(mesa+Panfrost)
https://www.cnblogs.com/zyly/p/17459196.html#_label2_0_1
9、Rockchip RK3588 - Mali-G610 GPU驱动(mesa+Panthor)
https://www.cnblogs.com/zyly/p/19188301
2、preface
1)一个图形的构造有哪些工作内容?
1、图形构造:画图,比如矩形、三角形、立方体、长方体等等2D图形;无非就是构造一帧图片(描绘屏幕的像素),工作最为简单;
2、图像渲染:将2D图形画面 变换 成"3D"图形(实际上还是2D图形,只是带有丰富光影效果),涉及像素的算法变换,最为复杂;

三维图形渲染显示的全过程:
https://imgtec.eetrend.com/blog/2020/100046895.html
3、图像质量(PQ) 处理:色温、对比度、锐度、Dither、Demura、gamma、od、lod等调节
色温:

4、图像合成:将多个图层合并成一个,并送显;将各个像素叠加在一起,难度次之;
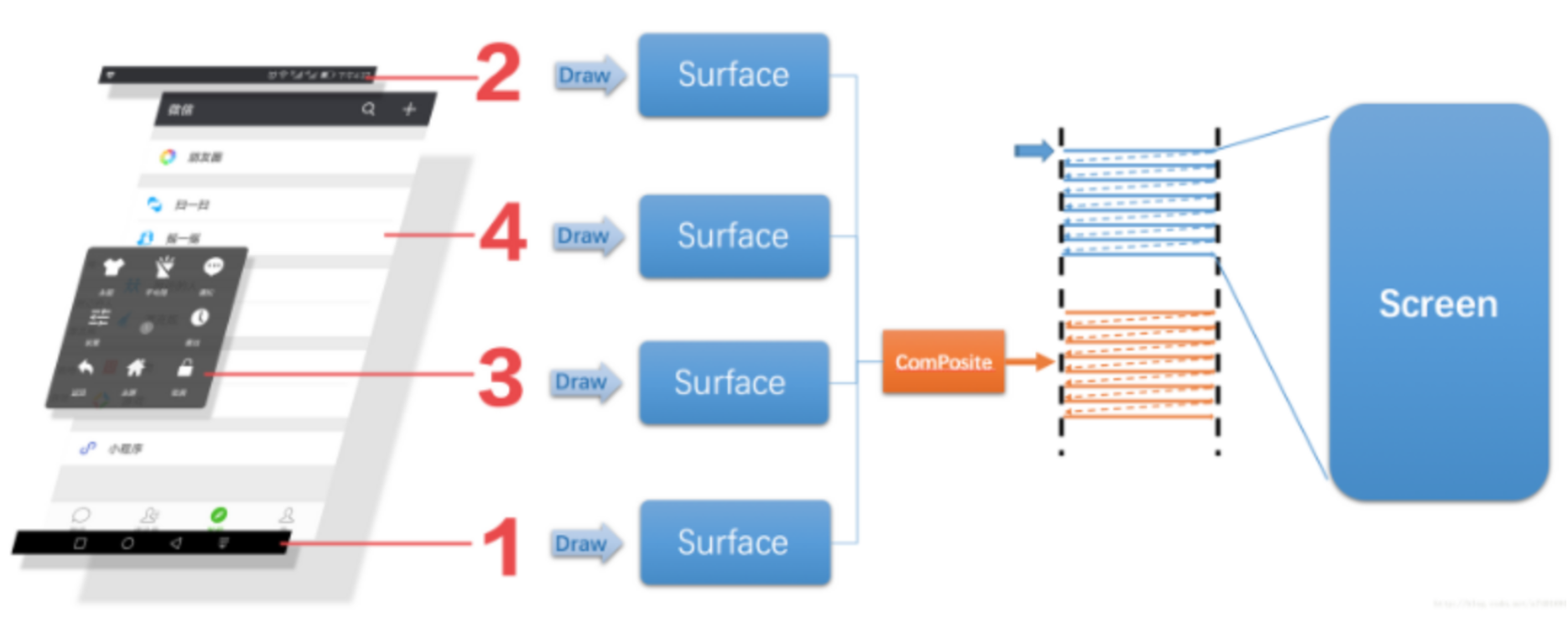
5、小结:
1、经过层层处理,最终呈现出一帧图像(不容易!)难度:图形构造 < 图像合成、图像质量处理 < 图像渲染;
2、GPU可以胜任以上几种工作,但最擅长的是图像渲染,同时它也是为此而设计,那么一个图像完全由GPU承担,这不仅非常消耗GPU资源,拖慢整体的工作时间,同时也让GPU大才小用,作为嵌入式场景,当然不允许这样浪费,实际上都会通过设计其它硬件来分担此部分工作,让GPU专注于渲染工作,比如
1)图形构造 - 2D Graphic Processing
2)合成工作交给HWC;
3)PQ效果由PQ模块处理;
2、面向异构计算CPU+GPU+NPU
随着手机、汽车芯片进入"CPU+GPU+NPU"异构时代,探索多硬件协同渲染------例如,NPU负责图像预处理(如降噪),GPU负责实时绘制,CPU负责逻辑控制,最大化利用硬件资源。3、ARM-GPU选型
1)GPU : Graphics Processing Unit
2)GPU架构复杂程度不亚于CPU,与CPU类似,GPU的选型颇为丰富,这里重点看ARM mali GPU架构;
3)ARM mali GPU四大微架构概述(Utgard / Midgard / Bifrost / Valhall);
https://zhuanlan.zhihu.com/p/107141045
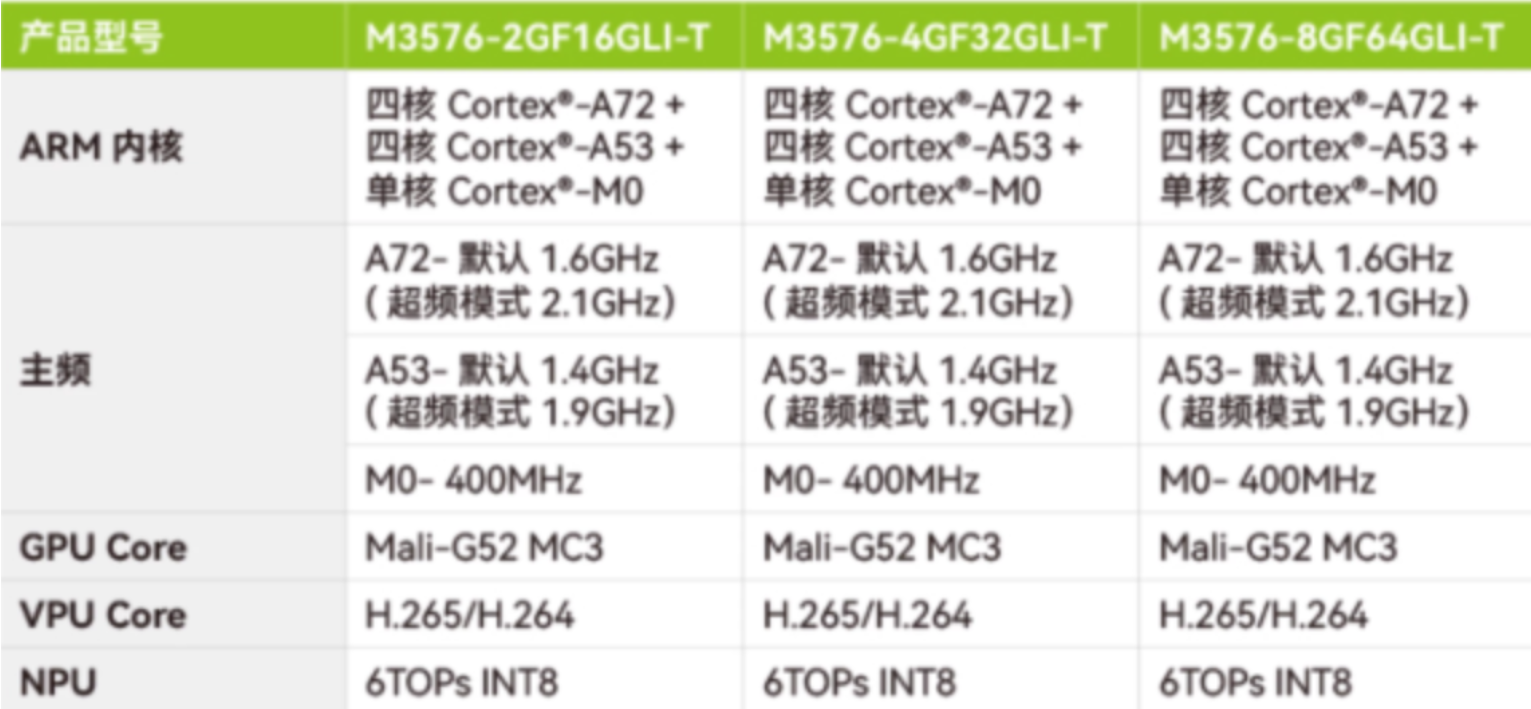
4)选型表
4、从图片渲染流程看GPU的作用
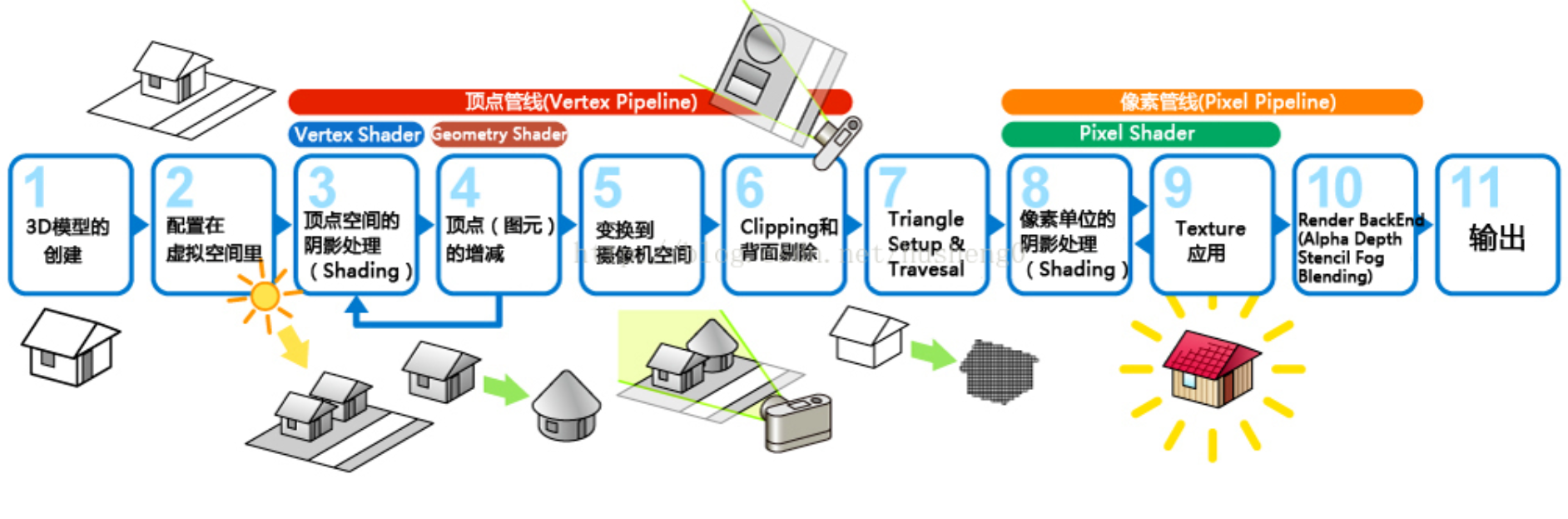
图像渲染大概经过了四个阶段,分别是应用处理阶段、几何处理阶段、光栅化阶段以及像素处理阶段 ,如下图所示,其中应用处理阶段CPU还在处理,CPU需要对图像进行操作和改变,将生成的图元信息交给GPC,之后其他阶段都是交由GPU处理。
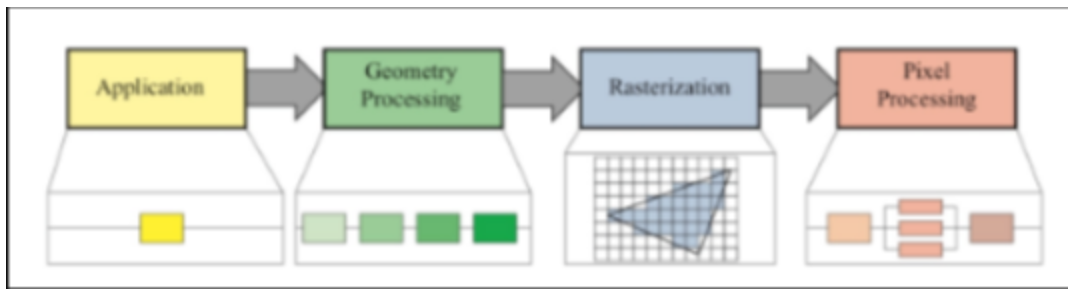
1、CPU阶段
CPU负责将数据准备好,设置好渲染状态,然后输出图元 到 指定位置的"显存"(嵌入式中使用内存充当显存),GPU一帧一帧地渲染完成后再回传到指定内存空间,Display控制器(比如LCD控制器)再取出显示到屏幕
图元是指渲染的基本图形,通俗来讲图元可以是顶点,线段,三角面等,复杂的图形可以通过渲染多个三角形来实现。
2、GPU负责处理的阶段
几何处理阶段、光栅化阶段以及像素处理阶段均由GPU处理
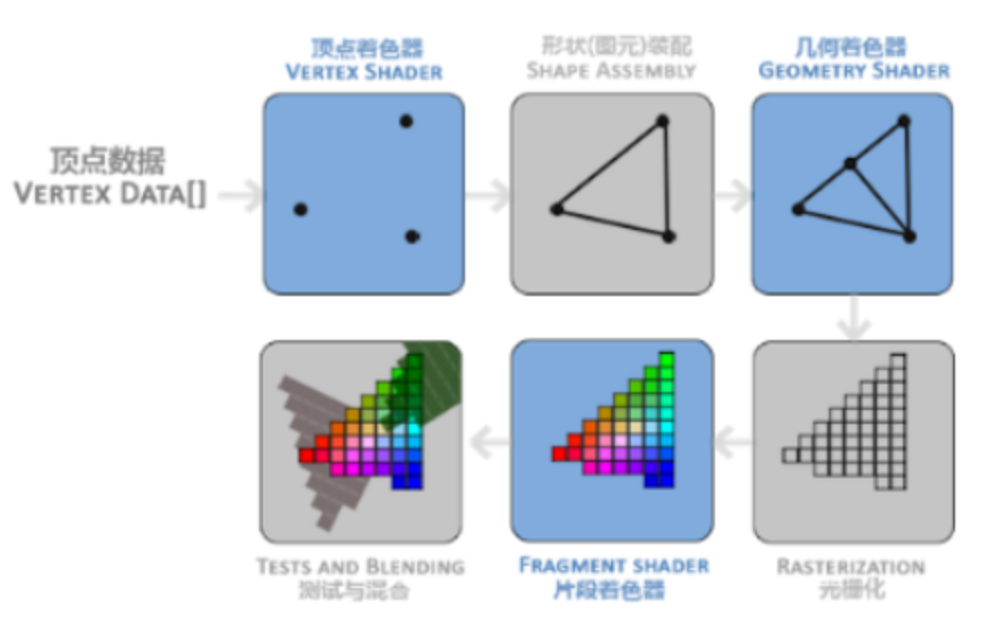
由于图像数据处理量极大,CPU并不适合用来处理图像数据(换言之CPU有强大的综合能力,但图形处理特性是单一且任务量巨大),因此需要专门的器件GPU来处理,嵌入式领域GPU集成到CPU中;
5、GPU物理模型概述
1)GPU/CPU基础知识: https://www.cnblogs.com/tully/p/18379114
2)GPU是一种专门为图像渲染、视频图像编解码的并行计算机任务而设计的芯片;
3)GPU器件形态:
1、在大型机器上,GPU可以是独立的扩展卡(即我们PC机器常说的显卡,显卡会集成大容量内存)

2、在嵌入式领域,也可以集成在SoC(System on a Chip 系统芯片)中
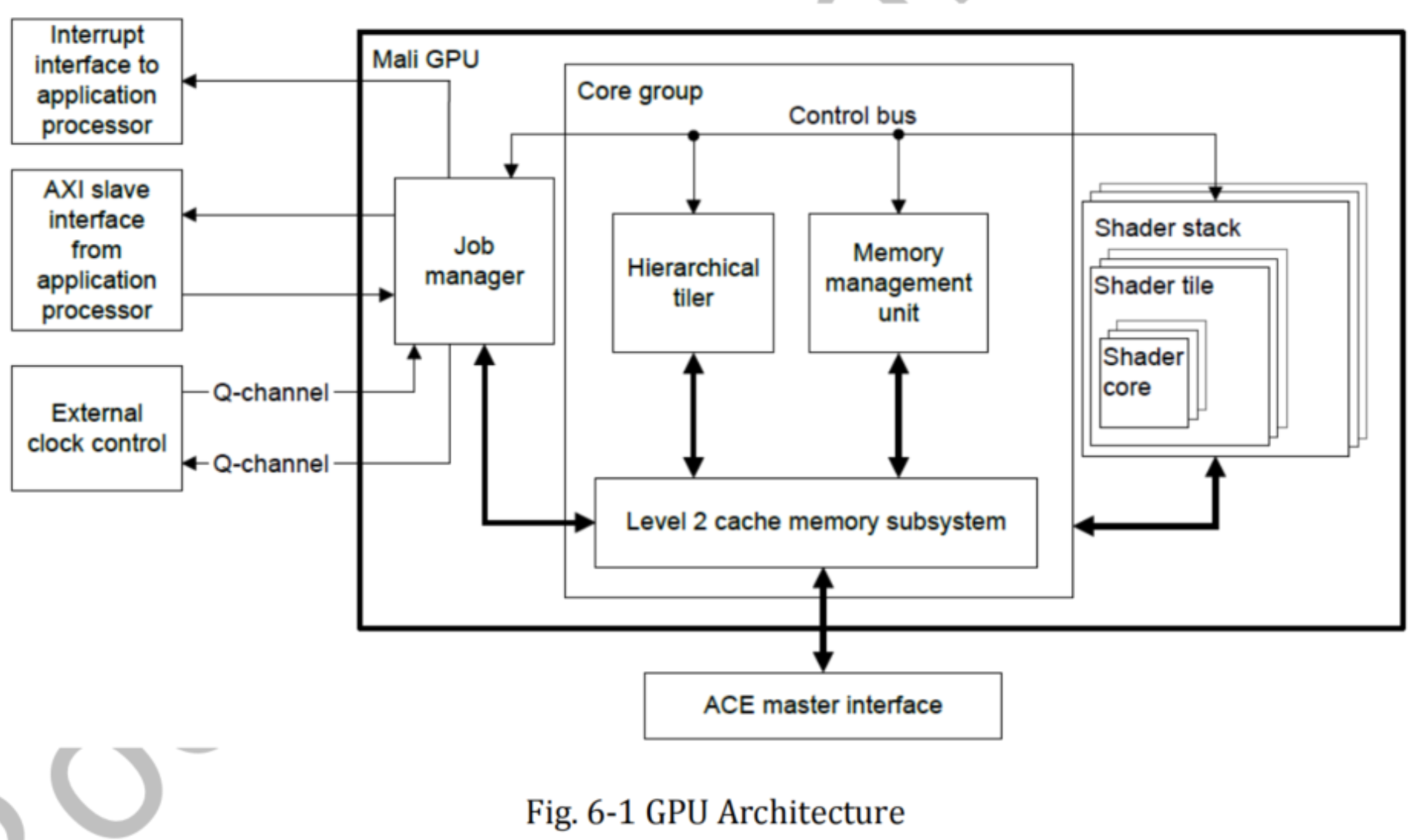
3、ARM T950D4平台GPU架构图
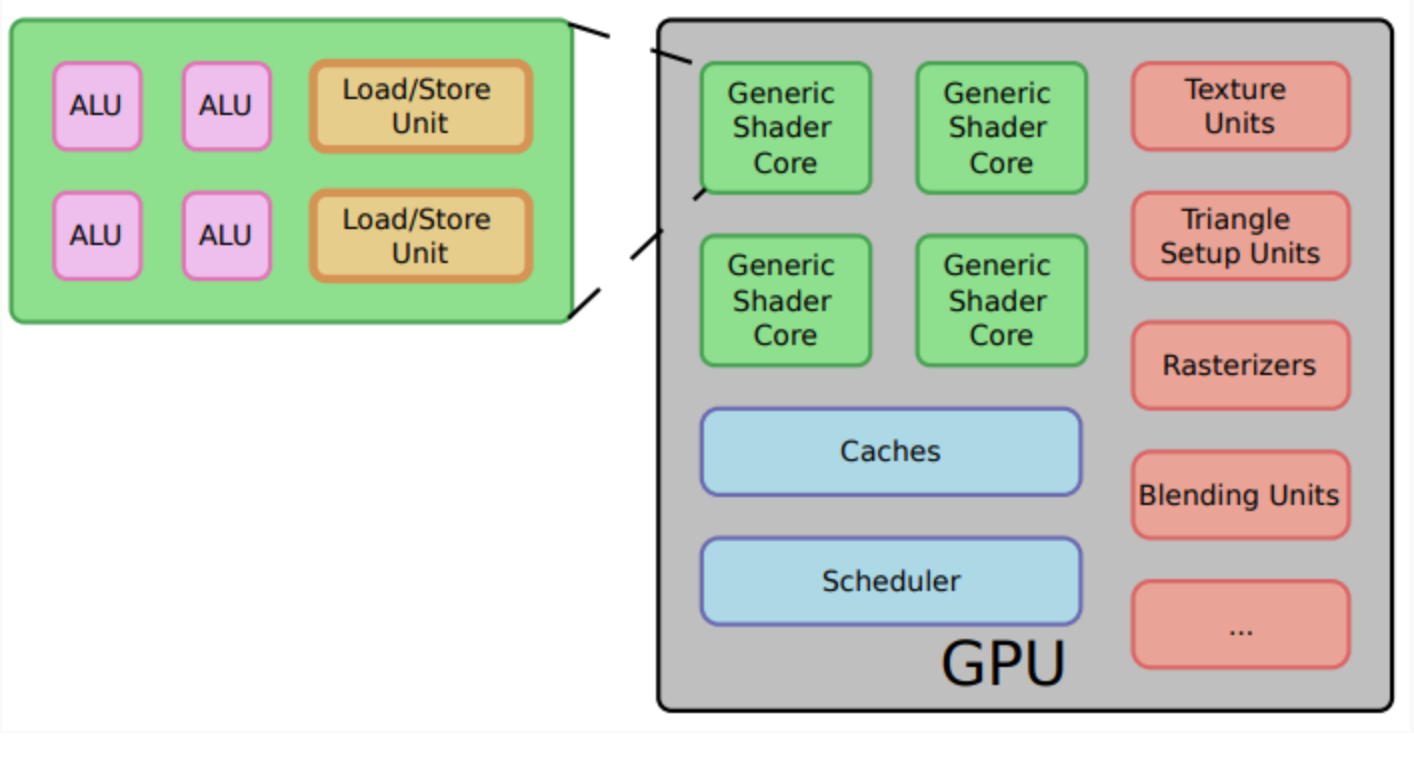
4、GPU逻辑功能框图
6、GPU的工作流程
1)CPU如何与GPU交互?
1)以集成SOC为例,CPU与GPU交互模型如下
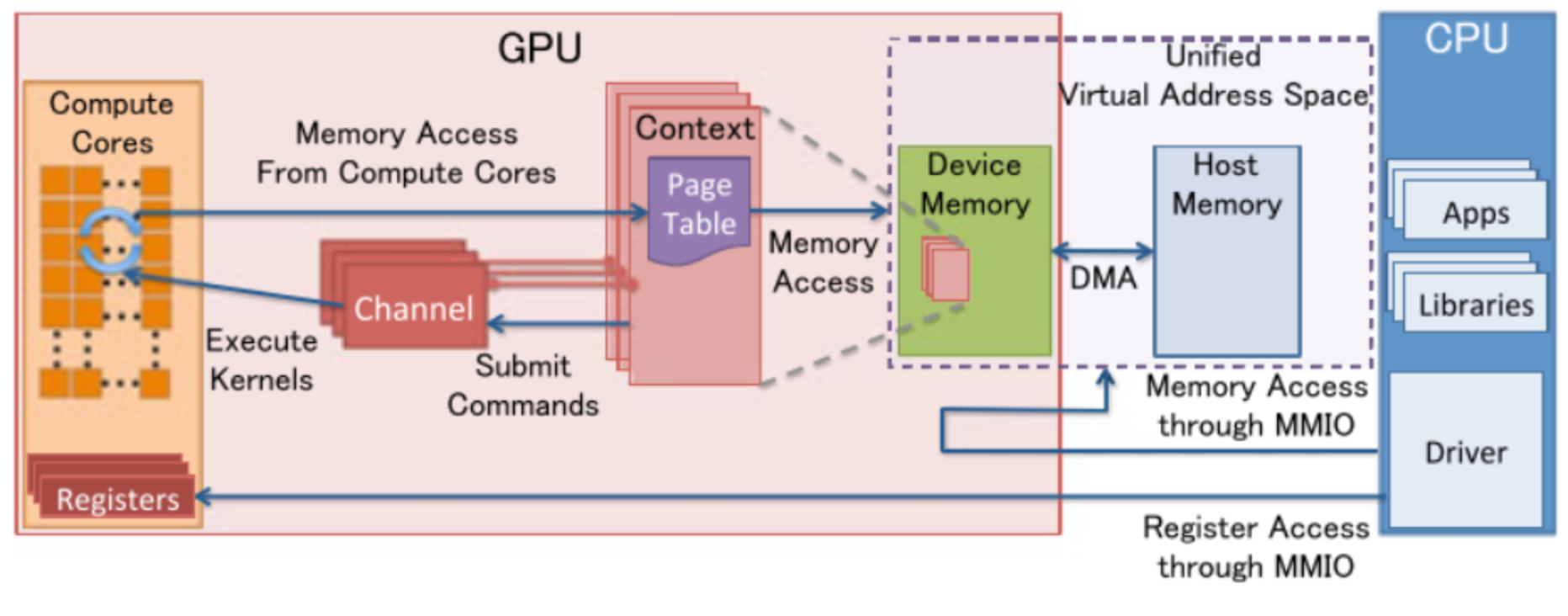
1、与其它集成在SOC的IP模块不同,GPU也是处理器(并行架构),与CPU的架构不同(串行架构),它完全是独立运行的,只是需CPU分配"Job",
2、GPU需要运行程序工作,这里的可执行程序对应的二进制是GPU的机器码,通过CPU端的GPU驱动程序进行传递;
3、注意GPU软件栈编程与其它模块 有较大的差别!
4、GPU有自己独立内存(Device Memory) - GDDR;
5、几个GPU基本概念
1、GPU context
GPU context代表GPU当前状态,每个context有自己的page table,多个context可以同时共存
2、GPU Channel
每个GPU context都有一个或者多个GPU Channel,CPU发给GPU的命令通过GPU Channel传递,一般GPU Channel是一个软件概念,通常是一个ring buffer
3、page table
和CPU的page table功能一样,用于VA到PA的映射,访问GPU的地址空间
4、CPU和GPU通信主要有几下几种方式(以嵌入式SOC集成GPU举例):
通过GPU寄存器
通过GPU的内存映射到CPU的地址空间中
通过GPU的页表把CPU的系统内存映射到GPU的地址空间中
通过MSI中断2)GPU的程序片段和数据从哪里获得?
从交互模型来看,驱动程序有两部分工作:
1、通过寄存器配置GPU;
2、与CPU一样,GPU运行需要指令和数据,驱动负责将指令(也可称为代码片段) 和 图像数据则通过GPU内存和主存 传输;
3)谁来指挥GPU驱动工作?
1)GPU比较特殊,主要的驱动工作是在用户态,内核驱动负责物理层级的配置和传输;
2)而用户态的GL负责 GPU所需要的图形数据/渲染指令的 生成;
3)以OpenGL为例,GL需要遵循GPU的运作模式(称为GPU Pipeline),转化为对应的编程接口,并向应用程序提供封装好的API,OpenGL API主要组织好job所需的数据,为后续的shader core计算做好准备。
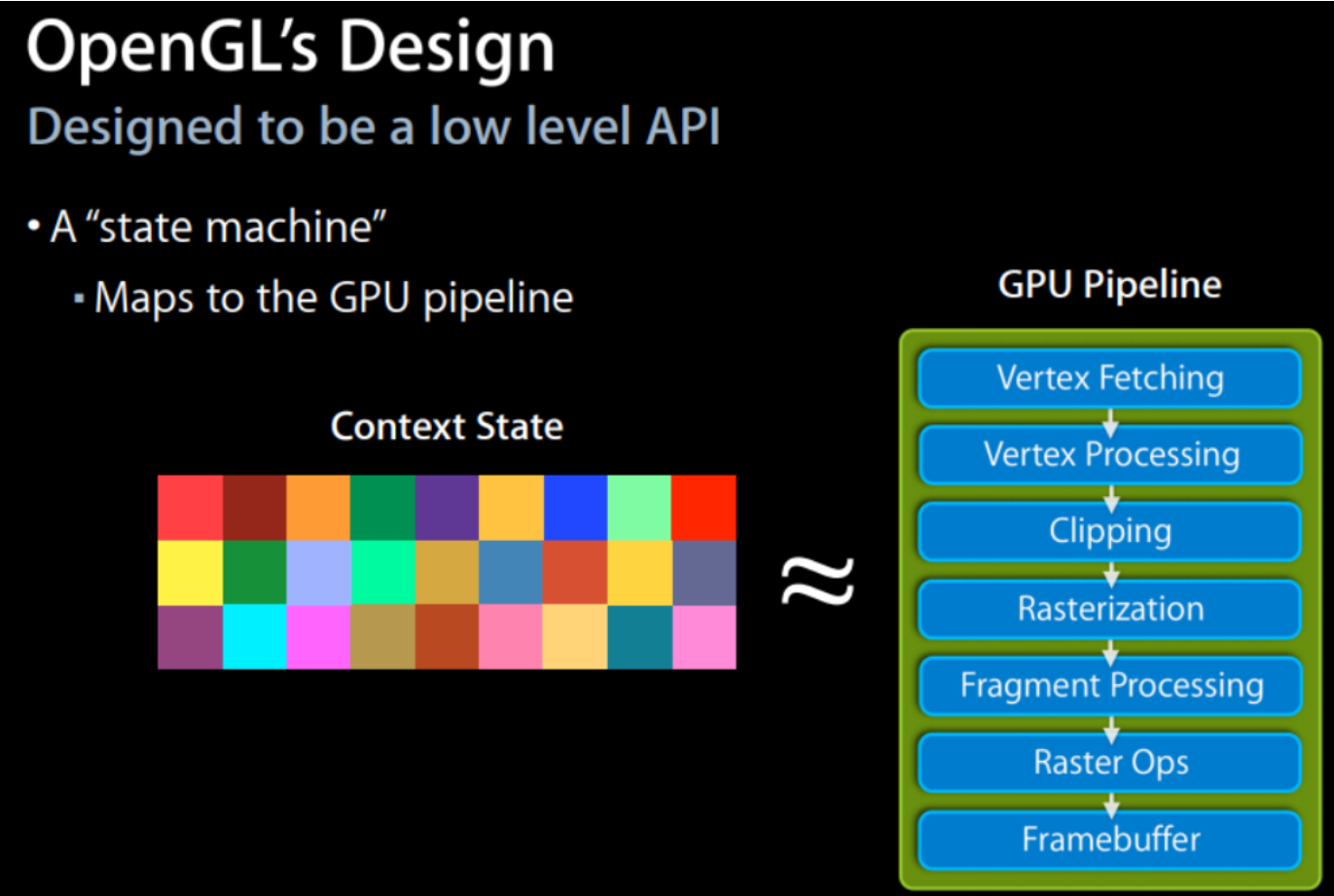
4)OpenGL的编程模型
4)GPU Job的概念
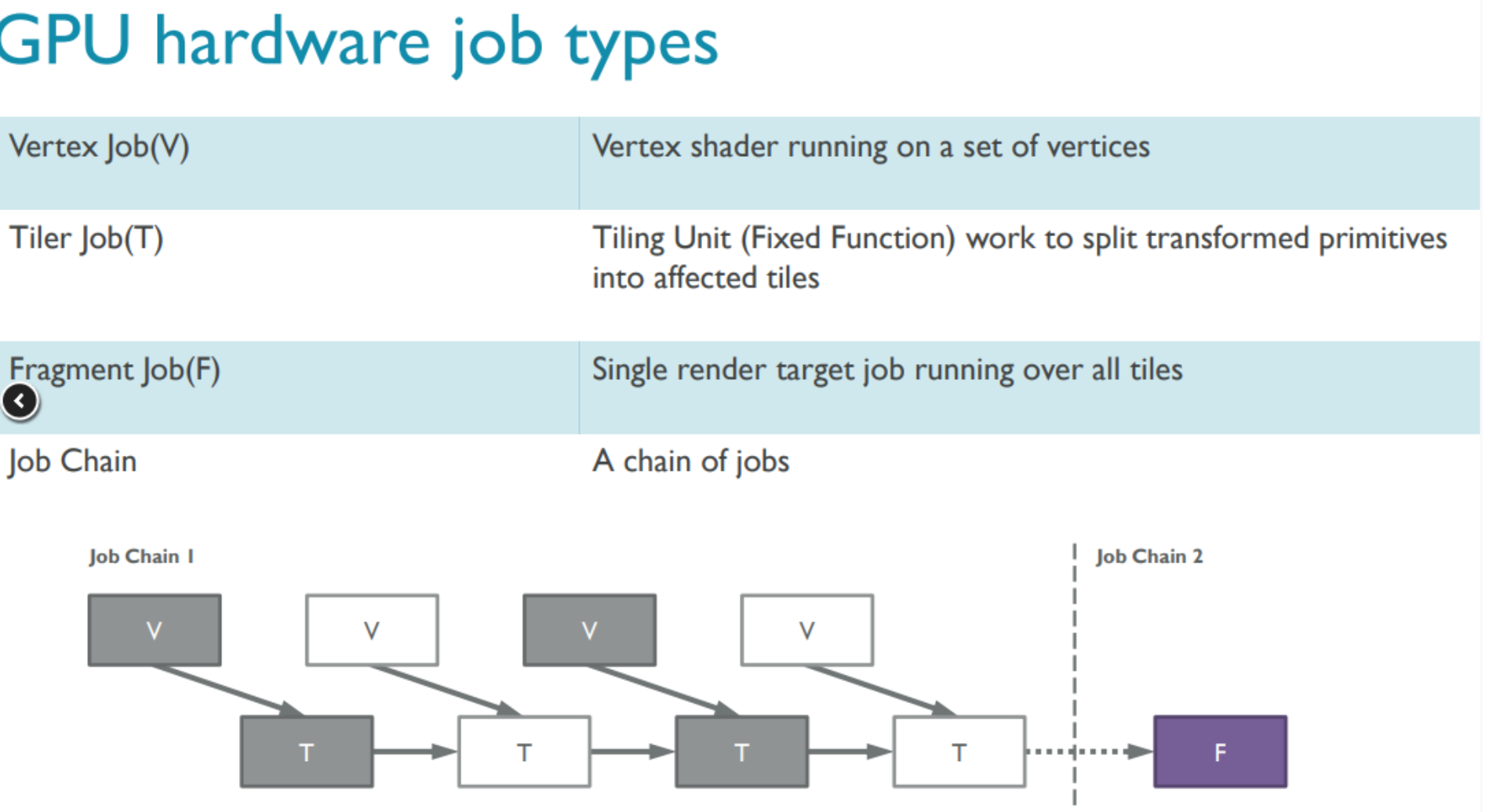
之前提及GPU是并行架构,既然是并行,如何管理各个并行工作任务?
这个也是GPU有较大的编程风格差异的原因,它的工作需要拆分各个Job(驱动以Job为提交单位),Job下有多个Task,GPU内有job Manager硬件模块负责此部分工作,无论是GPU驱动还是用户态的GL库,也要按照此方式进行定制编写代码
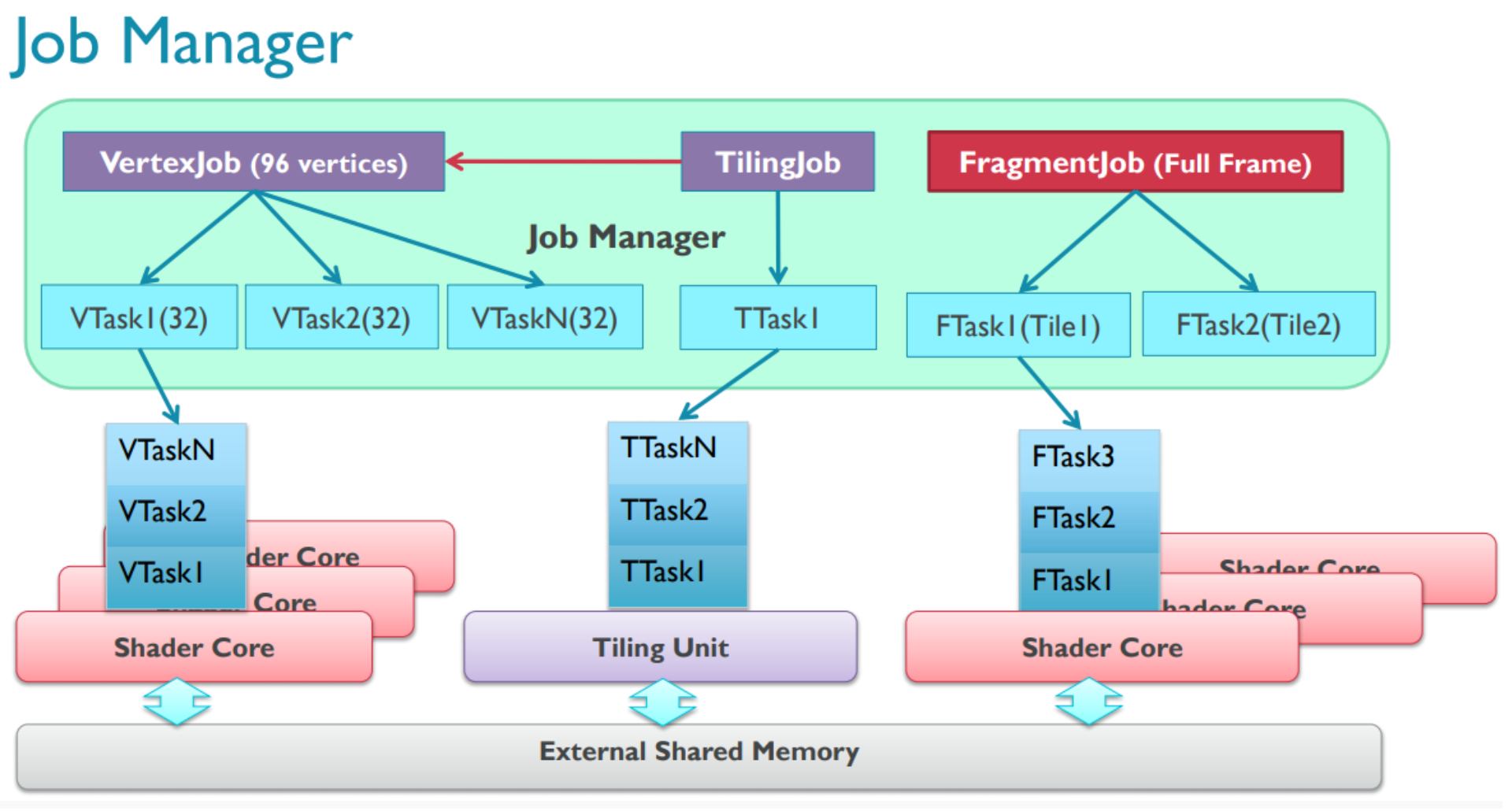
GPU Job类型
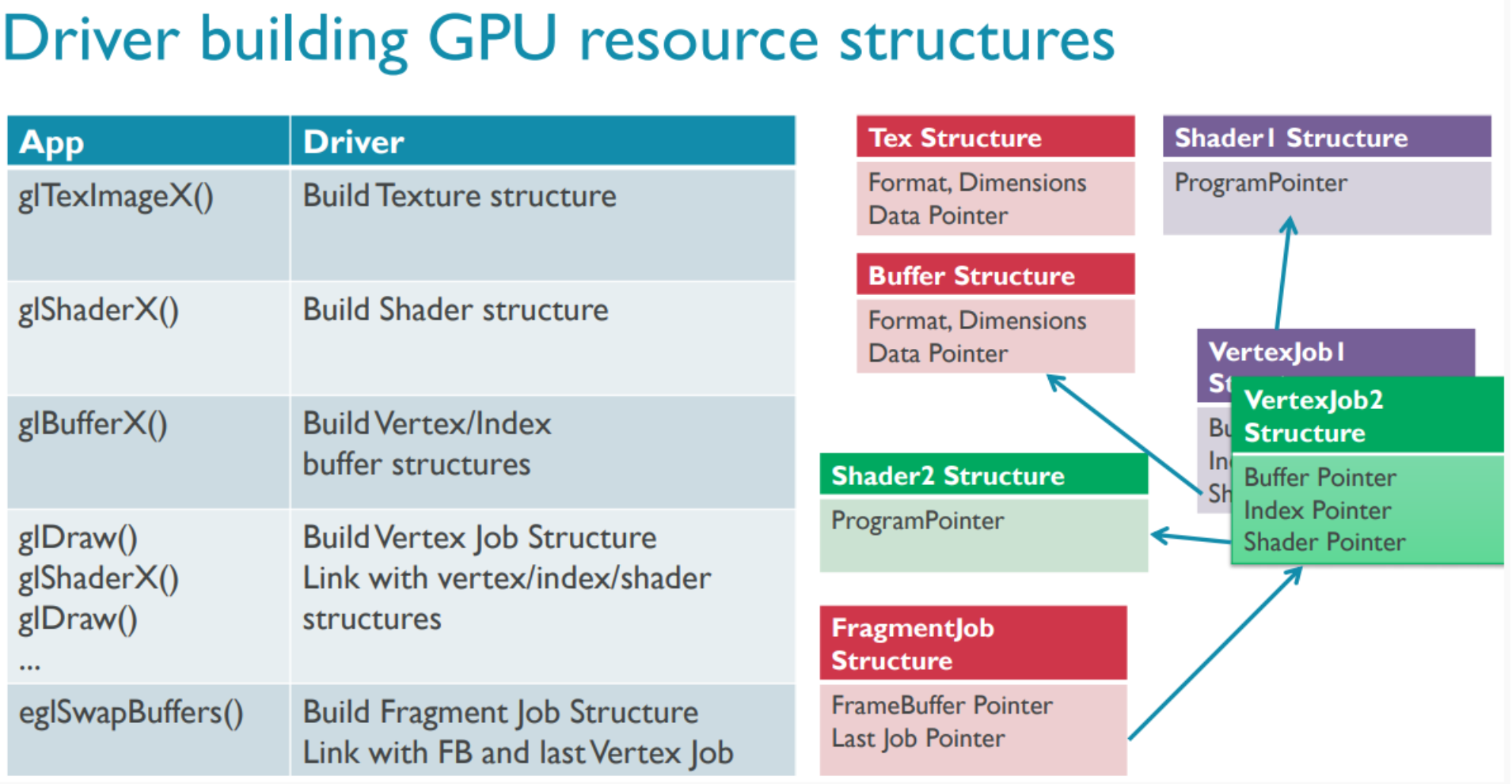
5)GPU驱动编程接口
6)小结
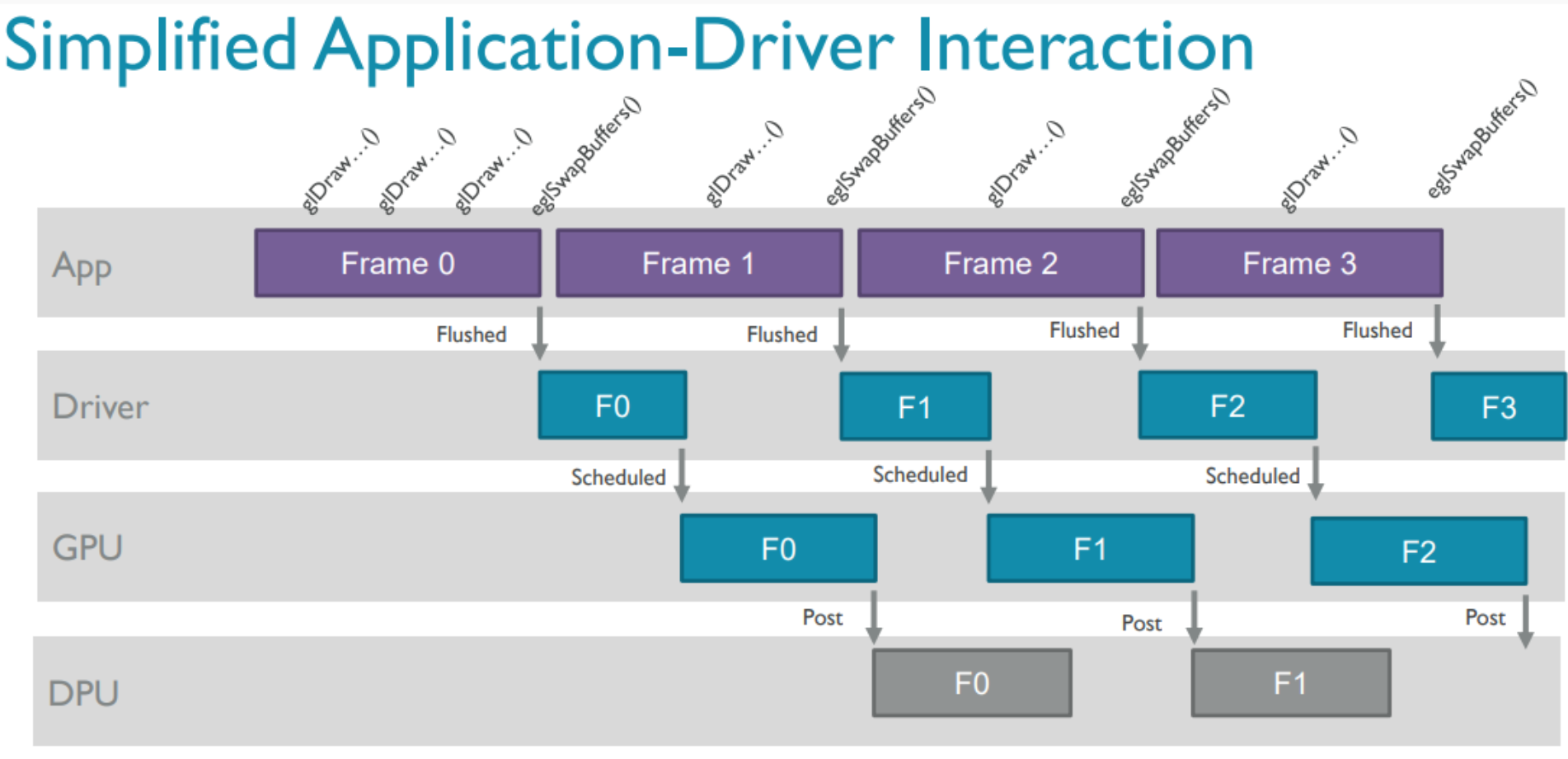
1、GPU渲染一帧画面整体的工作流程如下
2、结合OpenGL api观察连续帧渲染流程
7、ARM GPU驱动概述
1)preface
无论是应用层的GL库、内核态的驱动 还是硬件上的架构设计,不同平台各个厂家的实现五花八门,并且大多数闭源
这里均使用开源软件组合来展示说明,把握核心原理,以不变应万变!
2)整体框架
采用开源组合说明:skia + mesa3D(openGL) + drm + panfrost
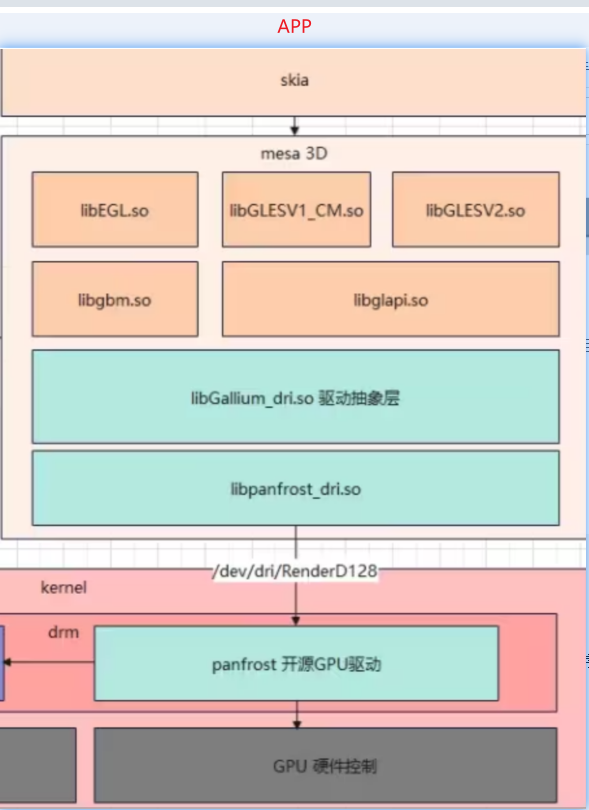
1、在看GPU的驱动相关资料,有几个比较不寻常的点:
1)常常看到GL将用户操作转化为GPU能识别的指令的说法,这难道不是驱动的工作?
2)从APK到GPU内核驱动,要经过复杂的中间件(SKIA,GL),甚至非专业人士都难看懂;
这是因为GPU的驱动工作被放在用户态的GL库上,内核态驱动负责简单的传送工作;
2、与其它设备驱动相比,我们习惯使用寄存器方式去操控设备;在GPU这里,我们不单要配置寄存器,还要给GPU传送可执行程序和数据!
3、由于GPU驱动主要的工作在用户态GL,因此GPU内核态驱动和其他设备驱动其实差异不大,主要就两个面:
控制面:设置state,通过fence做同步等
数据面:把数据从CPU搬到GPU,这里主要涉及到数据格式和数据layout,类似网卡的描述符,以及设备内存的管理。
4、libmali.so 一般厂家提供,闭源
5、ARM Mali架构
1)AML - T950D4 - Mali G31 MP2 - bifrost架构
2)AML - T950S - Mali-450MP2 -Utgard架构
6、ARM开发但不遵循DRM规范的GPU驱动(代码量极大)
android/vendor/amlogic/common/gpu/mali
Mali-GPU驱动-Midgard架构分析:https://blog.csdn.net/weixin_43082062/article/details/139595284
7、遵循DRM框架,且开源的GPU驱动(代码量适中)
1)DRM driver for ARM Mali 400/450 GPUs.
android/vendor/amlogic/common/kernel/common_5.4/drivers/gpu/drm/lima/
2)DRM driver for ARM Mali Midgard (T6xx, T7xx, T8xx) and Bifrost (G3x, G5x, G7x) GPUs.
android/vendor/amlogic/common/kernel/common_5.4/drivers/gpu/drm/panfrost/
8、Mesa 3D + panfrost开源项目官网: https://docs.mesa3d.org/drivers/panfrost.html
9、设备节点
1)950s-an14-基于DRM
/dev/mali
/dev/dri/card0
/dev/dri/renderD128
2)950d4-an13-传统FB架构
/dev/mali0
/dev/graphics/fb0
10、OpenCL
/android/external/ComputeLibrary/src/core/CL/OpenCL.cpp
{ "libOpenCL.so", "libGLES_mali.so", "libmali.so" }8、panfrost-gpu驱动分析
1)数据结构
1、
struct panfrost_device {
struct device *dev;
struct drm_device *ddev;
struct platform_device *pdev;
void __iomem *iomem;
struct clk *clock;
struct clk *bus_clock;
struct regulator *regulator;
struct reset_control *rstc;
struct panfrost_features features;
spinlock_t as_lock;
unsigned long as_in_use_mask;
unsigned long as_alloc_mask;
struct list_head as_lru_list;
struct panfrost_job_slot *js;
struct panfrost_job *jobs[NUM_JOB_SLOTS];
struct list_head scheduled_jobs;
struct panfrost_perfcnt *perfcnt;
struct mutex sched_lock;
struct mutex reset_lock;
struct mutex shrinker_lock;
struct list_head shrinker_list;
struct shrinker shrinker;
struct {
struct devfreq *devfreq;
struct thermal_cooling_device *cooling;
unsigned long cur_freq;
unsigned long cur_volt;
struct panfrost_devfreq_slot slot[NUM_JOB_SLOTS];
} devfreq;
};
2、panfrost_job
struct panfrost_job {
struct drm_sched_job base;
struct kref refcount;
struct panfrost_device *pfdev;
struct panfrost_file_priv *file_priv;
/* Optional fences userspace can pass in for the job to depend on. */
struct dma_fence **in_fences;
u32 in_fence_count;
/* Fence to be signaled by IRQ handler when the job is complete. */
struct dma_fence *done_fence;
__u64 jc;
__u32 requirements;
__u32 flush_id;
/* Exclusive fences we have taken from the BOs to wait for */
struct dma_fence **implicit_fences;
struct panfrost_gem_mapping **mappings;
struct drm_gem_object **bos;
u32 bo_count;
/* Fence to be signaled by drm-sched once its done with the job */
struct dma_fence *render_done_fence;
}2)驱动框架
1、点的目录源码
panfrost/
├── panfrost_drv.c # 驱动主入口,IOCTL 接口
├── panfrost_device.c # 设备初始化和管理
├── panfrost_gpu.c # GPU 硬件操作和特性检测
├── panfrost_job.c # 任务调度系统
├── panfrost_mmu.c # MMU 地址空间管理
├── panfrost_gem.c # GEM 对象管理
├── panfrost_devfreq.c # 动态频率调节
├── panfrost_perfcnt.c # 性能计数器
└── panfrost_features.h # GPU 特性定义
2、支持的GPU设备
static const struct of_device_id dt_match[] = {
{ .compatible = "arm,mali-t604" },
{ .compatible = "arm,mali-t624" },
{ .compatible = "arm,mali-t628" },
{ .compatible = "arm,mali-t720" },
{ .compatible = "arm,mali-t760" },
{ .compatible = "arm,mali-t820" },
{ .compatible = "arm,mali-t830" },
{ .compatible = "arm,mali-t860" },
{ .compatible = "arm,mali-t880" },
{}
};
MODULE_DEVICE_TABLE(of, dt_match);
3、ioctl
static const struct drm_ioctl_desc panfrost_drm_driver_ioctls[] = {
#define PANFROST_IOCTL(n, func, flags) \
DRM_IOCTL_DEF_DRV(PANFROST_##n, panfrost_ioctl_##func, flags)
PANFROST_IOCTL(SUBMIT, submit, DRM_RENDER_ALLOW | DRM_AUTH),
PANFROST_IOCTL(WAIT_BO, wait_bo, DRM_RENDER_ALLOW),
PANFROST_IOCTL(CREATE_BO, create_bo, DRM_RENDER_ALLOW),
PANFROST_IOCTL(MMAP_BO, mmap_bo, DRM_RENDER_ALLOW),
PANFROST_IOCTL(GET_PARAM, get_param, DRM_RENDER_ALLOW),
PANFROST_IOCTL(GET_BO_OFFSET, get_bo_offset, DRM_RENDER_ALLOW),
PANFROST_IOCTL(PERFCNT_ENABLE, perfcnt_enable, DRM_RENDER_ALLOW),
PANFROST_IOCTL(PERFCNT_DUMP, perfcnt_dump, DRM_RENDER_ALLOW),
PANFROST_IOCTL(MADVISE, madvise, DRM_RENDER_ALLOW),
};
drmIoctl(DRM_IOCTL_PANFROST_SUBMIT)
--panfrost_ioctl_submit
4、
android\vendor\amlogic\common\kernel\common_5.4\drivers\gpu\drm\panfrost\panfrost_drv.c
panfrost_probe()
--drm_dev_register(ddev, 0) //调用drm接口创建设备节点/dev/dri/renderD128
5、job提交流程
panfrost_ioctl_submit(strcut drm_device *dev, void *data, struct drm_file *file)
--struct panfrost_job *job = kzmalloc(sizeof(*job), GFP_KERNEL) //创建job对象
--panfrost_copy_in_sync(dev, file, args, job); //解析同步对象
--panfrost_lookup_bos(dev, file, args, job); //查找并引用GEM对象(BOs)
--panfrost_job_push(job); //push
--drm_syncobj_replace_fence(sync_out, job->render_done_fence);
6、gpu硬件操作
android\vendor\amlogic\common\kernel\common_5.4\drivers\gpu\drm\panfrost\panfrost_gpu.c
int panfrost_gpu_init(struct panfrost_device *pfdev)
--panfrost_gpu_soft_reset(pfdev);
--panfrost_gpu_init_features(pfdev);
--devm_request_irq(pfdev->dev, irq, panfrost_gpu_irq_handler,
IRQF_SHARED, "gpu", pfdev);
--panfrost_gpu_power_on(pfdev);
7、寄存器读写接口
gpu_read()
gpu_write()9、使用GL库画一个静态彩色三角形流程
在学习了晦涩的GPU理论知识和驱动之后,回归实际应用,看一个用户程序使用GPU的例子来深化一下
1)CPP代码
Android上的图形库有OpenGL-ES(轻量级应用)、Vulkan(深度定制,未来趋势),这里使用OpenGL-ES举例
1.完整代码
https://github.com/LinuxMadGuy/opengl-misc/blob/master/OpenGL/triangle/triangle.cpp
2.重点代码
void main() {
float vertices[] = {
-0.5f, -0.5f, 0.0f, // left
0.5f, -0.5f, 0.0f, // right
0.0f, 0.5f, 0.0f // top
};
//1.GPU端生成一个顶点数组对象(VAO)和一个顶点缓冲对象(VBO),这是存放和管理顶点数据的基础。
unsigned int VBO, VAO;
glGenVertexArrays(1, &VAO);
glGenBuffers(1, &VBO);
// bind the Vertex Array Object first, then bind and set vertex buffer(s), and then configure vertex attributes(s).
//绑定VAO
glBindVertexArray(VAO);
glBindBuffer(GL_ARRAY_BUFFER, VBO);
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW); //准备Vertext数据
glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)0);
glEnableVertexAttribArray(1);
glBindBuffer(GL_ARRAY_BUFFER, 0);
glBindVertexArray(0);
// render loop
// -----------
while (!glfwWindowShouldClose(window))
{
//2.render
glClearColor(0.2f, 0.3f, 0.3f, 1.0f); //设置清屏背景颜色
glClear(GL_COLOR_BUFFER_BIT);//开始清屏
// draw our first triangle
glUseProgram(shaderProgram);
glBindVertexArray(VAO); // seeing as we only have a single VAO there's no need to bind it every time, but we'll do so to keep things a bit more organized
glDrawArrays(GL_TRIANGLES, 0, 3); //开始GPU进行绘制三角形
//3.glfw: swap buffers and poll IO events (keys pressed/released, mouse moved etc.)
glfwSwapBuffers(window); //交换前后帧缓存区
glfwPollEvents(); //处理IO事件
}
}
3.小结
准备好绘制数据(顶点数据、命令id等) -> GPU工作 -> 显示2)GL库之准备Vertext数据
glBufferData
/android/external/mesa3d/src/mesa/main/bufferobj.c
mesa_BufferData()
--_mesa_buffer_data()
---buffer_data_error()
-----buffer_data()
------ctx->Driver.BufferData()
/android/external/mesa3d/src/mesa/state_tracker/st_cb_bufferobjects.c
--------st_bufferobj_data()
----------bufferobj_data()
/android/external/mesa3d/src/gallium/auxiliary/util/u_inlines.h
------------pipe_buffer_write()
--------------pctx->buffer_subdata()
/android/external/mesa3d/src/gallium/drivers/panfrost/pan_resource.c
----------------u_default_buffer_subdata()
------------------pipe->transfer_map() //各GPU厂商实现,panfrost使用MESA公共函数
/android/external/mesa3d/src/gallium/drivers/panfrost/pan_resource.c
pctx->buffer_subdata = u_default_buffer_subdata;3)GL库之执行绘制
glDrawArrays
/android/external/mesa3d/src/mesa/main/draw.c
--_mesa_DrawArrays()
----_mesa_draw_arrays()
------gl_context.Driver.Draw()
/android/external/mesa3d/src/mesa/state_tracker/st_draw.c
--------st_draw_vbo()
/android/external/mesa3d/src/gallium/auxiliary/cso_cache/cso_context.c
----------cso_draw_vbo(st->cso_context, &info);
/android/external/mesa3d/src/gallium/auxiliary/util/u_vbuf.c
------------u_vbuf_draw_vbo(vbuf, info);
--------------pipe->draw_vbo(pipe, &new_info);
/android/external/mesa3d/src/gallium/drivers/panfrost/pan_context.c
----------------panfrost_draw_emit_vertext()
/android/external/mesa3d/src/gallium/drivers/panfrost/pan_context.c
------------------pan_emit_draw_descs(batch, &cfg, PIPE_SHADER_VERTEX);4)GL库之切换Framebuffer
glfwSwapBuffers
main::_mesa_Flush
gl_context::Driver.Flush
state_tracker::st_glFlush
draw_do_flush
panfrost::panfrost_flush
panfrost::panfrost_batch_submit_jobs
panfrost::panfrost_batch_submit_ioctl
drm::drmIoctl(DRM_IOCTL_PANFROST_SUBMIT)
进入kernel panfrost驱动
/android/vendor/amlogic/common/kernel/common_5.4/drivers/gpu/drm/panfrost/panfrost_drv.c
panfrost_ioctl_submit
panfrost_job_push
drm_sched_entity_push_job
drm_sched_rq_add_entity
panfrost_job_run
panfrost_job_hw_submit
panfrost_job_write_affinity (设置job和core的亲和性)
job_write (写job manager寄存器)10、GPU的内存分配和拷贝
glGenbuffers,glBufferData过程中,涉及到gpu内存的分配和拷贝。
1)panfrost内存分配
基于mali panfrost来分析的话,用户态的代码在mesa的src/panfrost/lib/pan_bo.c中。
panfrost_bo_create
panfrost_bo_alloc
drmIoctl PANFROST_CREATE_BO之后陷入kernel之后的流程:
panfrost_ioctl_create_bo
drm_gem_shmem_create之后再用户态就可以用普通的memcpy来拷贝了。
为了减少和kernel态的交互,mesa panfrost代码中也实现了一个内存pool,详细代码在
src/panfrost/lib/pan_pool.c中,使用最多的函数是panfrost_pool_alloc_aligned。