拉链表是一种用于存储历史数据的技术,通常用于记录某个维度表的状态变化。每条记录包含以下字段:
主键:唯一标识一条记录。
开始时间( start_date ):记录生效的时间。
结束时间( end_date ):记录失效的时间,通常用一个特殊值(如 9999-12-31 )表示当前有效。
其他字段:记录的具体属性。
例如,一个用户表的拉链表可能如下所示:
|-------------|-----------|----------------|----------------|
| user_id | name | start_date | end_date |
| 1 | Alice | 2023-01-01 | 2023-06-30 |
| 1 | Alice | 2023-07-01 | 9999-12-31 |
| 2 | Bob | 2023-01-01 | 9999-12-31 |
一、 Hive 中如何实现拉链表的更新?
在 Hive 中,可以通过以下步骤实现拉链表的更新:
1. 准备数据
假设我们有一个增量数据表 incremental_data 和一个现有的拉链表 dim_user 。
增量数据表 incremental_data :
|-------------|-----------|-----------------|
| user_id | name | update_time |
| 1 | Alice | 2023-08-01 |
| 2 | Bob | 2023-08-01 |
| 3 | Carol | 2023-08-01 |
现有拉链表 dim_user :
|-------------|-----------|----------------|----------------|
| user_id | name | start_date | end_date |
| 1 | Alice | 2023-01-01 | 2023-06-30 |
| 1 | Alice | 2023-07-01 | 9999-12-31 |
| 2 | Bob | 2023-01-01 | 9999-12-31 |
2. 更新逻辑
我们需要实现以下操作:
关闭旧记录:对于增量数据中更新的记录,将现有拉链表中对应的记录的 end_date 设置为增量数据的 update_time - 1 。
插入新记录:将增量数据中的记录插入到拉链表中,并设置其 start_date 为 update_time , end_date 为 9999-12-31 。
3. 实现步骤
(1) 关闭旧记录
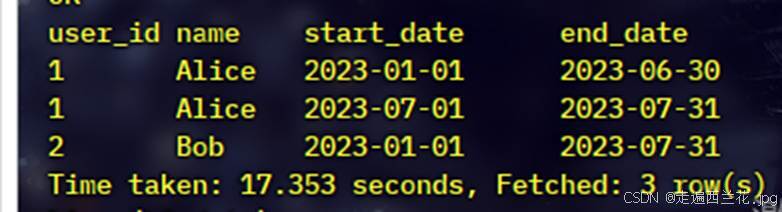
使用 LEFT JOIN 将增量数据与现有拉链表进行匹配,并更新 end_date 。
INSERT OVERWRITE TABLE dim_user
SELECT t1.user_id,
t1.name,
t1.start_date,
CASE
WHEN t2.user_id IS NOT NULL THEN
DATE_SUB(t2.update_time, 1)
ELSE
t1.end_date
END AS end_date
FROM dim_user t1
LEFT JOIN incremental_data t2
ON t1.user_id = t2.user_id
AND t1.end_date = '9999-12-31';原始:
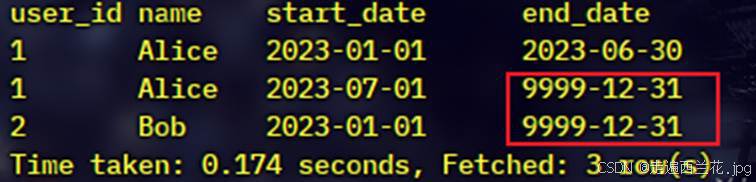
闭链后:
(2) 插入新记录
将增量数据中的记录插入到拉链表中。
INSERT INTO TABLE dim_user
SELECT
user_id,
name,
update_time AS start_date,
'9999-12-31' AS end_date
FROM incremental_data;插入的内容:
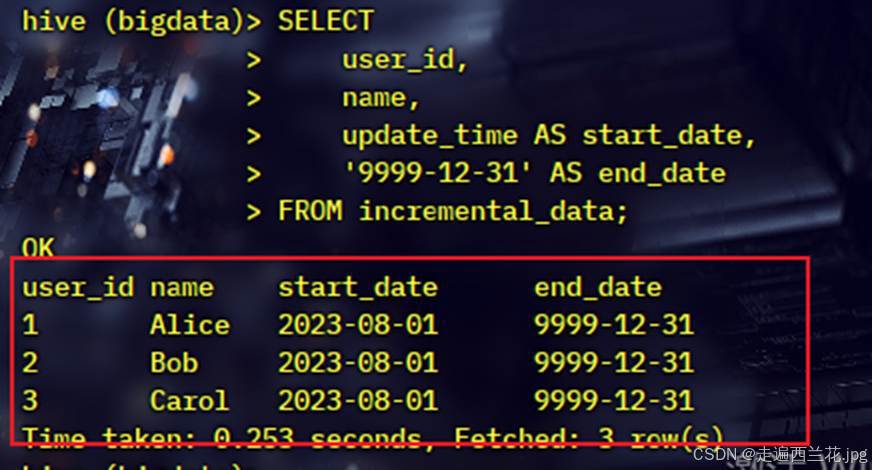
插入后:
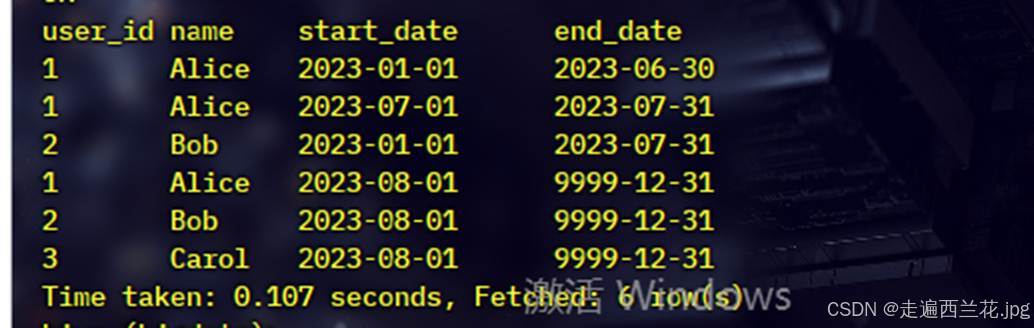
拉链表就更新好了.
二、 Hive 中的 MERGE INTO 替代方案
虽然 Hive 不支持标准 SQL 的 MERGE INTO 语法,但可以通过 UNION ALL 和 INSERT OVERWRITE 来模拟 MERGE INTO 的功能。
如果数据存在,就进行update,如果不存在就进行insert.
可以按照以下步骤操作
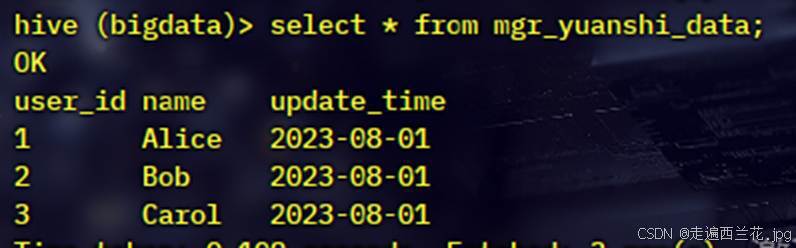
原始表 也就是需要更新的目标表(mgr_yuanshi_data):
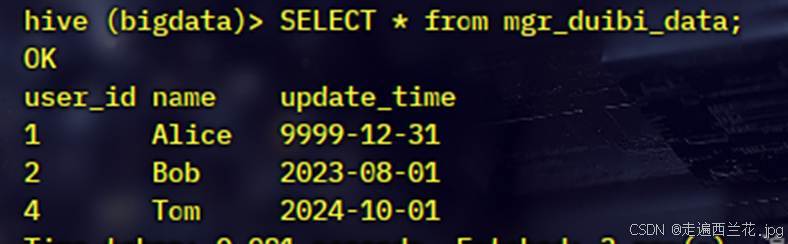
新的表 也就是数据的对比来源表 (mgr_duibi_data):
(1) 创建临时表
创建一个临时表,用于存储更新后的数据。
CREATE TABLE temp_table AS
SELECT * FROM mgr_yuanshi_data WHERE 1=0;-
插入对比表中的所有数据(更新和新增) :
INSERT INTO temp_table
SELECT s.*
FROM mgr_duibi_data s;
(3) 保留原始表中多余的对比表中没有的数据(看具体需求如果不保留就是全量,保留就是对比了):
INSERT INTO temp_table
SELECT t.*
FROM mgr_yuanshi_data t
LEFT JOIN mgr_duibi_data s ON t.user_id = s.user_id
WHERE s.user_id IS NULL;(4) 替换原表
将临时表的数据覆盖到原始表:
INSERT OVERWRITE TABLE mgr_yuanshi_data
SELECT * FROM temp_table;