文章目录
Human In Loop 人在环中
概念介绍
在LangGraph 是个"有状态图(state graph)"的工作流框架,每个节点可以是:
- 模型调用(LLM、工具调用)
- 程序逻辑
- 人类反馈(HITL)
HITL 就是把"人类操作"当作图里的一个节点(step),在运行时需要停下来等待人类确认、输入或决策,然后再继续执行。
典型场景
- 确认操作:比如智能体打算删除数据或执行危险操作 → 先让人确认(Yes/No)。
- 信息补充:模型缺少必要参数时,提示人类补全,比如填写 API Key、选择文件。
- 审核 / 修改:模型生成的回答需要人审查、修改,再提交给用户。
- 主动决策分支:工作流里分叉走向不确定 → 由人来选择接下来走哪条分支。
实现要点
- 必须指定一个checkpoint短期记忆,否则无法保存任务状态。
- 在执行Graph任务时,必须指定一个带有thread_id的配置项,指定线程ID。之后才能通过线程ID,指定恢复线程。
- 在任务执行过程中,通过interrupt()方法,中断任务,等待确认。
- 在人类确认之后,使用Graph提交一个resume=True的Command指令,恢复任务,并继续进行。
示例代码
python
from typing import TypedDict, Annotated,Literal
from langchain_ollama import ChatOllama
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.constants import START, END
from langgraph.graph import add_messages, StateGraph
from langgraph.types import interrupt, Command
# 定义 Agent 的状态结构,包含消息列表
class AgentState(TypedDict):
messages: Annotated[list, add_messages]
# 初始化本地大语言模型,配置模型名称和推理模式
llm = ChatOllama(base_url="http://localhost:11434", model="qwen3:8b", reasoning=False)
# 聊天机器人函数,用于处理对话状态并生成回复
def chatbot(state: AgentState):
return {"messages": [llm.invoke(state['messages'])]}
def human_approval(state: AgentState) -> Command[Literal["chatbot", END]]:
question = "是否同意调用大语言模型?(y/n): "
while True:
response = input(question).strip().lower()
if response in ("y", "yes"):
return Command(goto="chatbot")
elif response in ("n", "no"):
print("❌ 已拒绝,流程结束。")
return Command(goto=END)
else:
print("⚠️ 请输入 y 或 n。")
# 构建状态图结构
graph_builder = StateGraph(AgentState)
# 每个节点都与对应的处理函数进行绑定,构成工作流的基本单元
graph_builder.add_node("human_approval", human_approval)
graph_builder.add_node("chatbot", chatbot)
# 添加边:从 START 到 chatbot,然后到 END
graph_builder.add_edge(START, "human_approval")
checkpointer=InMemorySaver()
# 编译图结构,并绘制可视化图表
graph = graph_builder.compile(checkpointer=checkpointer)
graph.get_graph().draw_png('./graph.png')
config = {"configurable": {"thread_id": "chat-1"}}
response1 = graph.invoke({"messages": ["北京天气怎么样"]},config)
print(response1["messages"][-1].content)
# 确认执行
final_result = graph.invoke(Command(resume=True),config)
print(final_result["messages"][-1].content)
# 取消执行
# final_result = graph.invoke(Command(resume=False),config)
# print(final_result["messages"][-1].content)Time Travel 时间回溯
概念介绍
在 LangGraph 中,Time Travel 是一个允许你"回到对话的某个历史状态点,并从那里重新执行"的功能。
它依赖 Checkpointer(检查点系统),比如 MemorySaver、数据库持久化 saver 等,把每一步执行的 状态(state) 保存下来。
可以类比成:
- 普通对话:只能按顺序走下去
- 有时间回溯:可以跳到某一步(比如第 3 次工具调用前),从那个状态继续,甚至尝试不同的分支
使用场景
- 调试:想看 agent 在某个历史状态下会如何响应
- 修复:发现某一步错误,可以回到那一步,重新走另一条路径
- 探索分支:从同一个历史状态,分叉出多个可能的结果,做 what-if 实验
- 人类在环 (HITL):如果用户拒绝了工具调用,可以退回到之前状态,重新走对话
实现要点
- 在运行 Graph 时,需要提供初始的输入消息。
- 运行时,指定 thread_id 线程 ID。并且要基于这个线程 ID,再指定一个 checkpoint 检查点。执行后将在每一个 Node 执行后,生成一个 check_point_id
- 指定 thread_id 和 check_point_id,进行任务重演。重演前,可以选择更新 state,当然,如果没问题,也可以不指定。
综合实践
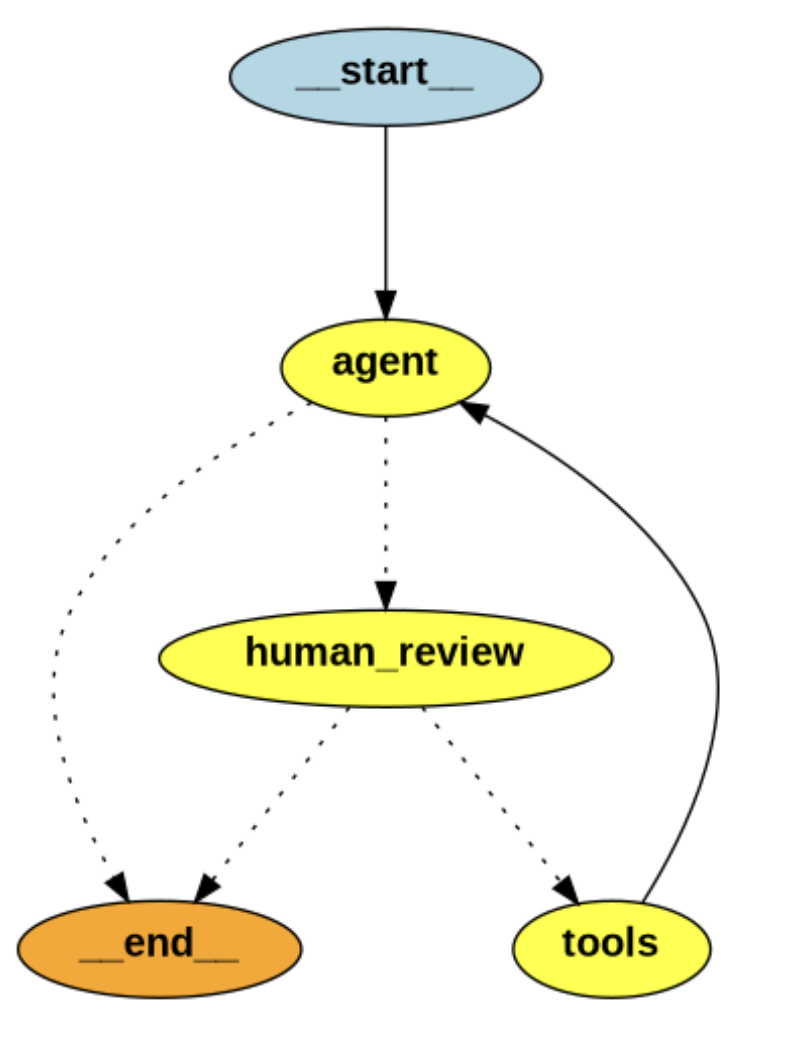
终极目标是使用LangGraph 底层 API 复现高级API create_react_agent 预构建ReACT图。
实现一个带人工审核的AI助手工作流。主要功能包括:
- 调用模型:call_model 函数使用绑定工具的语言模型生成回复。
- 人工审核:human_review 函数在执行工具前请求用户确认,若拒绝则终止流程。
- 工具执行:通过 ToolNode 执行如天气查询等工具调用。
- 状态管理:利用 StateGraph 构建节点流程,支持对话状态保存与恢复。
整体流程如下:
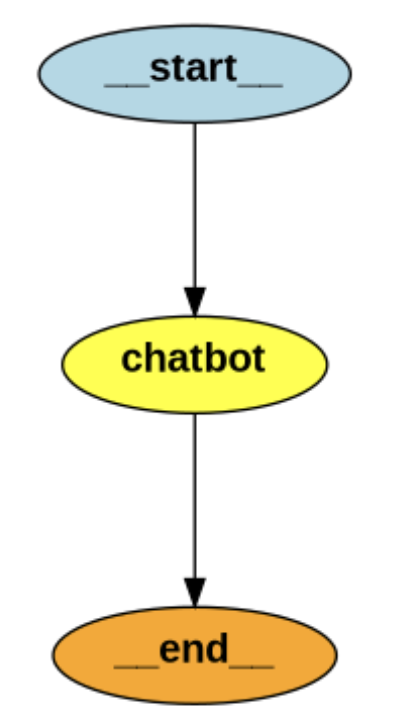
最简单的聊天机器人
我们先定义一个基于本地大语言模型的聊天机器人。chatbot 函数接收当前对话状态,调用 llm.invoke() 生成回复,并返回新消息。整体通过 StateGraph 构建工作流,实现从开始到结束的自动对话处理。
代码如下
python
from typing import TypedDict, Annotated
from langchain_ollama import ChatOllama
from langgraph.constants import START, END
from langgraph.graph import add_messages, StateGraph
# 定义 Agent 的状态结构,包含消息列表
class AgentState(TypedDict):
messages: Annotated[list, add_messages]
# 初始化本地大语言模型,配置模型名称和推理模式
llm = ChatOllama(base_url="http://localhost:11434", model="qwen3:14b", reasoning=False)
# 聊天机器人函数,用于处理对话状态并生成回复
def chatbot(state: AgentState):
return {"messages": [llm.invoke(state['messages'])]}
# 构建状态图结构
graph_builder = StateGraph(AgentState)
# 每个节点都与对应的处理函数进行绑定,构成工作流的基本单元
graph_builder.add_node("chatbot", chatbot)
# 添加边:从 START 到 chatbot,然后到 END
graph_builder.add_edge(START, "chatbot")
graph_builder.add_edge("chatbot",END)
# 编译图结构,并绘制可视化图表
graph = graph_builder.compile()
graph.get_graph().draw_png('./graph.png')
response1 = graph.invoke({"messages": ["北京天气怎么样"]})
print(response1["messages"][-1].content)整体流程如下
添加提示词与工具
定义工具函数
python
import json
import os
import httpx
import dotenv
from loguru import logger
from pydantic import Field, BaseModel
from langchain_core.tools import tool
# 加载环境变量配置
dotenv.load_dotenv()
class WeatherQuery(BaseModel):
"""
天气查询参数模型类,用于定义天气查询工具的输入参数结构。
:param city: 城市名称,字符串类型,表示要查询天气的城市
"""
city: str = Field(description="城市名称")
class WriteQuery(BaseModel):
"""
写入查询模型类
用于定义需要写入文档的内容结构,继承自BaseModel基类
属性:
content (str): 需要写入文档的具体内容,包含详细的描述信息
"""
content: str = Field(description="需要写入文档的具体内容")
@tool(args_schema=WeatherQuery)
def get_weather(city):
"""
查询指定城市的即时天气信息。
:param city: 必要参数,字符串类型,表示要查询天气的城市名称。
注意:中国城市需使用其英文名称,如 "Beijing" 表示北京。
:return: 返回 OpenWeather API 的响应结果,URL 为
https://api.openweathermap.org/data/2.5/weather。
响应内容为 JSON 格式的字符串,包含详细的天气数据。
"""
# 构建请求 URL
url = "https://api.openweathermap.org/data/2.5/weather"
# 设置查询参数
params = {
"q": city, # 城市名称
"appid": os.getenv("OPENWEATHER_API_KEY"), # 从环境变量中读取 API Key
"units": "metric", # 使用摄氏度作为温度单位
"lang": "zh_cn" # 返回简体中文的天气描述
}
# 发送 GET 请求并获取响应
response = httpx.get(url, params=params)
# 将响应解析为 JSON 并序列化为字符串返回
data = response.json()
logger.info(f"查询天气结果:{json.dumps(data)}")
return json.dumps(data)
@tool(args_schema=WriteQuery)
def write_file(content):
"""
将指定内容写入本地文件
参数:
content (str): 要写入文件的文本内容
返回值:
str: 表示写入操作成功完成的提示信息
"""
# 将内容写入res.txt文件,使用utf-8编码确保中文字符正确保存
with open('res.txt', 'w', encoding='utf-8') as f:
f.write(content)
logger.info(f"已成功写入本地文件,写入内容:{content}")
return "已成功写入本地文件。"agent 代码如下
python
from typing import TypedDict, Annotated
from langchain_core.messages import SystemMessage
from langchain_ollama import ChatOllama
from langgraph.constants import START, END
from langgraph.graph import add_messages, StateGraph
from langgraph.prebuilt import ToolNode
from tools import get_weather, write_file
# 定义 Agent 的状态结构,包含消息列表
class AgentState(TypedDict):
messages: Annotated[list, add_messages]
# 初始化本地大语言模型,配置模型名称和推理模式
llm = ChatOllama(model="qwen3:14b", reasoning=False)
tools = [get_weather, write_file]
llm_with_tools = llm.bind_tools(tools)
# 聊天机器人节点,用于处理对话状态并生成回复,并告诉模型可以调用哪些工具
def chat_node(state: AgentState):
messages = state["messages"]
system_prompt = """你是一个智能助手,具备以下能力:
1. 查询天气信息
2. 结果写入文件
请根据用户的需求,选择合适的工具来完成任务。回答要准确、友好、专业。"""
# 构建完整的消息列表(系统提示词 + 用户消息),如果第一条消息不是系统消息,则添加系统提示词
if not any(isinstance(msg, SystemMessage) for msg in messages):
messages = [SystemMessage(
content=system_prompt)] + messages
result = llm_with_tools.invoke(messages)
return {"messages": [result]}
# 定义工具节点(系统预置 ToolNode 会自动解析 tool_calls)
tool_node = ToolNode(tools=tools)
# 动态路由:chat_node → tool_node 或 END
def route_after_chat(state: AgentState):
"""判断是否需要进入工具节点"""
last_message = state["messages"][-1]
if hasattr(last_message, "tool_calls") and last_message.tool_calls:
return "tool_node"
return END
# 构建状态图结构
graph_builder = StateGraph(AgentState)
# 每个节点都与对应的处理函数进行绑定,构成工作流的基本单元
graph_builder.add_node("chat_node", chat_node)
graph_builder.add_node("tool_node", tool_node)
# 添加边:从 START 到 chatbot,然后到 END
graph_builder.add_edge(START, "chat_node")
# 添加条件边:根据是否有工具调用来判断是否需要进入工具节点
graph_builder.add_conditional_edges("chat_node", route_after_chat, ["tool_node", END])
# 工具节点执行完后回到 chat_node,继续多轮对话
graph_builder.add_edge("tool_node", "chat_node")
# 编译图结构,并绘制可视化图表
graph = graph_builder.compile()
graph.get_graph().draw_png('./graph.png')
response1 = graph.invoke({"messages": ["北京天气怎么样"]})
print(response1["messages"][-1].content)执行结果如下
python
2025-10-18 13:32:41.965 | INFO | tools:get_weather:61 - 查询天气结果:{"coord": {"lon": 116.3972, "lat": 39.9075}, "weather": [{"id": 501, "main": "Rain", "description": "\u4e2d\u96e8", "icon": "10d"}], "base": "stations", "main": {"temp": 12.91, "feels_like": 11.48, "temp_min": 12.91, "temp_max": 12.91, "pressure": 1026, "humidity": 47, "sea_level": 1026, "grnd_level": 1021}, "visibility": 10000, "wind": {"speed": 1.67, "deg": 47, "gust": 3.99}, "rain": {"1h": 2.05}, "clouds": {"all": 100}, "dt": 1759896063, "sys": {"country": "CN", "sunrise": 1759875426, "sunset": 1759916800}, "timezone": 28800, "id": 1816670, "name": "Beijing", "cod": 200}
北京当前天气为中雨,温度为12.91摄氏度,湿度为47%,风速为1.67米/秒。此时项目图结构为
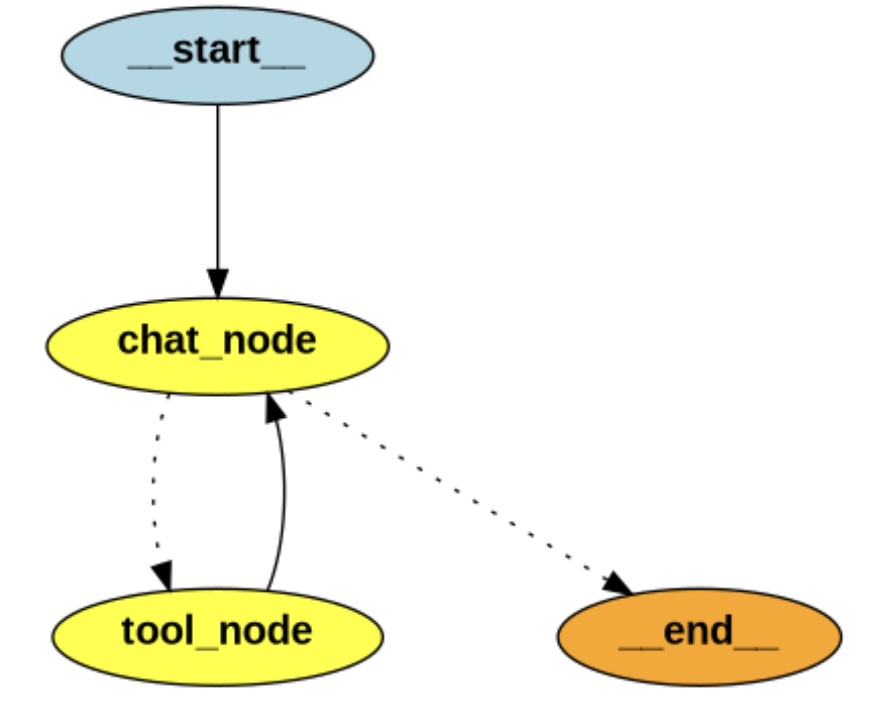
添加 HITL 环节
代码如下
python
from typing import TypedDict, Annotated
import json
from langchain_core.messages import SystemMessage, ToolMessage
from langchain_ollama import ChatOllama
from langgraph.constants import START, END
from langgraph.graph import add_messages, StateGraph
from langgraph.prebuilt import ToolNode
from langgraph.checkpoint.memory import MemorySaver
from tools import get_weather, write_file
# 定义 Agent 的状态结构
class AgentState(TypedDict):
messages: Annotated[list, add_messages]
# 初始化本地大语言模型
llm = ChatOllama(model="qwen3:8b", reasoning=False)
tools = [get_weather, write_file]
llm_with_tools = llm.bind_tools(tools)
# 聊天机器人节点
def chat_node(state: AgentState):
messages = state["messages"]
system_prompt = """你是一个智能助手,具备以下能力:
1. 查询天气信息
2. 结果写入文件
请根据用户的需求,选择合适的工具来完成任务。回答要准确、友好、专业。"""
if not any(isinstance(msg, SystemMessage) for msg in messages):
messages = [SystemMessage(content=system_prompt)] + messages
result = llm_with_tools.invoke(messages)
return {"messages": [result]}
# 定义工具节点
tool_node = ToolNode(tools=tools)
# 动态路由:chat_node 之后
def route_after_chat(state: AgentState):
"""判断是否需要调用工具"""
last_message = state["messages"][-1]
if hasattr(last_message, "tool_calls") and last_message.tool_calls:
return "tool_node"
return END
# 构建状态图
graph_builder = StateGraph(AgentState)
# 添加节点
graph_builder.add_node("chat_node", chat_node)
graph_builder.add_node("tool_node", tool_node)
# 添加边
graph_builder.add_edge(START, "chat_node")
graph_builder.add_conditional_edges("chat_node", route_after_chat, ["tool_node", END])
graph_builder.add_edge("tool_node", "chat_node")
# 编译图结构 - 关键:使用 interrupt_before 在工具节点前中断
memory = MemorySaver()
graph = graph_builder.compile(
checkpointer=memory,
interrupt_before=["tool_node"] # 在执行工具前中断,等待人工确认
)
# 绘制可视化图表
graph.get_graph().draw_png('./graph.png')
def run_with_approval():
"""运行带人工确认的工作流"""
config = {"configurable": {"thread_id": "1"}}
# 第一步:发送用户消息,执行到中断点
print("【用户】北京天气怎么样\n")
result = graph.invoke({"messages": ["北京天气怎么样"]}, config)
# 检查是否中断(等待人工确认)
snapshot = graph.get_state(config)
if snapshot.next: # 如果有下一个节点,说明被中断了
print("工具调用需要人工确认")
# 获取待执行的工具调用信息
last_message = snapshot.values["messages"][-1]
if hasattr(last_message, "tool_calls") and last_message.tool_calls:
for idx, tool_call in enumerate(last_message.tool_calls, 1):
print(f"\n[{idx}] 工具名称: {tool_call['name']}")
print(f" 调用参数: {json.dumps(tool_call['args'], ensure_ascii=False, indent=4)}")
approval = input("是否批准执行?(yes/no): ").strip().lower()
if approval in ['yes', 'y']:
print("工具调用已批准,继续执行...\n")
# 继续执行(resume)
result = graph.invoke(None, config)
elif approval in ['no', 'n']:
print("工具调用已被拒绝\n")
# 手动添加拒绝消息,然后继续
tool_messages = []
for tool_call in last_message.tool_calls:
tool_messages.append(
ToolMessage(
content="工具调用被用户拒绝,请询问用户是否需要调整方案或提供更多信息。",
tool_call_id=tool_call["id"]
)
)
# 更新状态并跳过工具节点
graph.update_state(config, {"messages": tool_messages})
result = graph.invoke(None, config)
# 输出最终结果
print("最终回复:")
final_message = result["messages"][-1]
print(final_message.content if hasattr(final_message, 'content') else str(final_message))
# 测试运行
if __name__ == "__main__":
run_with_approval()代码执行结果如下
python
【用户】北京天气怎么样
工具调用需要人工确认
[1] 工具名称: get_weather
调用参数: {
"city": "Beijing"
}
是否批准执行?(yes/no): yes
工具调用已批准,继续执行...
2025-10-18 09:35:54.071 | INFO | tools:get_weather:61 - 查询天气结果:{"coord": {"lon": 116.3972, "lat": 39.9075}, "weather": [{"id": 804, "main": "Clouds", "description": "\u9634\uff0c\u591a\u4e91", "icon": "04d"}], "base": "stations", "main": {"temp": 14.94, "feels_like": 14.08, "temp_min": 14.94, "temp_max": 14.94, "pressure": 1020, "humidity": 61, "sea_level": 1020, "grnd_level": 1015}, "visibility": 10000, "wind": {"speed": 1.59, "deg": 36, "gust": 2.05}, "clouds": {"all": 100}, "dt": 1760491544, "sys": {"type": 1, "id": 9609, "country": "CN", "sunrise": 1760480655, "sunset": 1760520954}, "timezone": 28800, "id": 1816670, "name": "Beijing", "cod": 200}
最终回复:
北京的天气情况如下:
- **天气状况**:多云(Clouds)
- **温度**:当前温度为 14.94°C,体感温度为 14.08°C
- **湿度**:61%
- **风速**:1.59 m/s,风向为 36 度(东北方向)
- **能见度**:10,000 米
- **日出时间**:1760480655(UTC+8)
- **日落时间**:1760520954(UTC+8)
如需进一步的信息或操作,请告诉我!添加时间回溯
代码如下
python
from typing import TypedDict, Annotated
from langchain_core.messages import SystemMessage, AIMessage
from langchain_ollama import ChatOllama
from langgraph.checkpoint.memory import MemorySaver
from langgraph.constants import START, END
from langgraph.graph import add_messages, StateGraph
from langgraph.prebuilt import ToolNode
from tools import get_weather
# 定义 Agent 的状态结构,包含消息列表和审核状态
class AgentState(TypedDict):
"""
描述 Agent 当前状态的数据结构。
属性:
messages (Annotated[list, add_messages]): 包含历史交互信息的消息列表,
使用 `add_messages` 合并新旧消息。
user_approved (bool): 标记用户是否同意执行工具调用
"""
messages: Annotated[list, add_messages]
user_approved: bool
# 初始化本地大语言模型,配置基础URL、模型名称和推理模式
llm = ChatOllama(base_url="http://localhost:11434", model="qwen3:14b", reasoning=False)
tools = [get_weather]
model = llm.bind_tools(tools)
def call_model(state: AgentState):
"""
调用绑定工具的大语言模型以生成响应。
参数:
state (AgentState): 包含当前会话中所有消息的状态对象。
返回:
dict: 新增模型响应后的更新状态(仅追加最新一条回复)。
"""
system_prompt = SystemMessage("你是一个AI助手,可以依据用户提问产生回答,你还具备调用天气函数的能力")
response = model.invoke([system_prompt] + state["messages"])
return {"messages": [response]}
# --- 人在闭环 (HITL) 节点 ---
def human_review(state: AgentState):
"""
在执行工具调用之前请求人工审核确认。
如果最后一条消息包含待执行的工具调用,则提示用户进行确认。
若用户拒绝,则终止流程;否则允许进入工具执行阶段。
参数:
state (AgentState): 包含当前会话状态的对象。
返回:
dict: 根据用户选择决定下一步操作:
- 用户拒绝时返回系统提示消息并标记为未批准;
- 允许继续则标记为已批准。
"""
last_message = state["messages"][-1]
if hasattr(last_message, "tool_calls") and last_message.tool_calls:
call = last_message.tool_calls[0]
tool_name = call["name"]
tool_args = call["args"]
print(f"[HITL] 模型计划调用工具 `{tool_name}`,参数:{tool_args}")
confirm = input("[HITL] 是否确认执行?(y/n): ")
if confirm.lower() != "y":
# 用户拒绝,返回提示消息并标记为未批准
return {
"messages": [AIMessage(content="用户拒绝了工具调用,无法获取相关信息。")],
"user_approved": False
}
# 用户同意,标记为已批准
return {"user_approved": True}
# 没有工具调用,直接标记为已批准
return {"user_approved": True}
def should_review(state: AgentState):
"""
判断是否需要进行人工审核。
参数:
state (AgentState): 当前状态
返回:
str: 下一个节点名称
"""
last_message = state["messages"][-1]
if hasattr(last_message, "tool_calls") and last_message.tool_calls:
return "human_review"
return END
def should_execute_tools(state: AgentState):
"""
判断是否应该执行工具。
参数:
state (AgentState): 当前状态
返回:
str: 下一个节点名称
"""
if state.get("user_approved", False):
return "tools"
return END
# 创建工具节点,用于执行工具调用
tool_node = ToolNode(tools)
# 构建状态图结构
graph_builder = StateGraph(AgentState)
# 每个节点都与对应的处理函数进行绑定,构成工作流的基本单元
graph_builder.add_node("agent", call_model)
graph_builder.add_node("human_review", human_review)
graph_builder.add_node("tools", tool_node)
# 添加边:从 START 到 agent
graph_builder.add_edge(START, "agent")
# 添加条件边:根据是否有工具调用来判断是否需要人工审核
graph_builder.add_conditional_edges(
"agent",
should_review,
{"human_review": "human_review", END: END}
)
# 添加条件边:根据用户是否同意来决定是否执行工具或结束
graph_builder.add_conditional_edges(
"human_review",
should_execute_tools,
{"tools": "tools", END: END}
)
# 工具执行完成后重新回到 agent 继续对话循环
graph_builder.add_edge("tools", "agent")
# 创建内存保存器
memory = MemorySaver()
# 编译图结构,并绘制可视化图表
graph = graph_builder.compile(checkpointer=memory)
graph.get_graph().draw_png('./graph.png')
# 配置对话线程ID
config = {"configurable": {"thread_id": "chat-1"}}
# 运行第一轮:问北京天气
print("\n" + "=" * 50)
print("第一轮对话:询问北京天气")
print("=" * 50)
response1 = graph.invoke({"messages": ["北京天气怎么样"]}, config=config)
print("\n=== 第一次结果 ===")
print(response1["messages"][-1].content)
# 打印已保存的检查点
print("\n" + "=" * 50)
print("检查点历史")
print("=" * 50)
states = list(graph.get_state_history(config))
for i, state in enumerate(states):
print(f"\n=== 检查点 {i} (next: {state.next}) ===")
print(f"Checkpoint ID: {state.config['configurable']['checkpoint_id']}")
if state.values.get("messages"):
print(f"Messages count: {len(state.values['messages'])}")
# 从第二个检查点恢复并注入新问题
print("\n" + "=" * 50)
print("第二轮对话:从检查点恢复并询问上海天气")
print("=" * 50)
new_config = graph.update_state(
states[1].config,
values={"messages": [{"role": "user", "content": "上海天气怎么样"}]}
)
response2 = graph.invoke(None, config=new_config)
print("\n=== 第二次结果 ===")
print(response2["messages"][-1].content)执行结果如下
python
==================================================
第一轮对话:询问北京天气
==================================================
[HITL] 模型计划调用工具 `get_weather`,参数:{'city': 'Beijing'}
[HITL] 是否确认执行?(y/n): y
2025-10-18 19:05:19.651 | INFO | tools:get_weather:61 - 查询天气结果:{"coord": {"lon": 116.3972, "lat": 39.9075}, "weather": [{"id": 804, "main": "Clouds", "description": "\u9634\uff0c\u591a\u4e91", "icon": "04n"}], "base": "stations", "main": {"temp": 17.38, "feels_like": 16.01, "temp_min": 17.38, "temp_max": 17.38, "pressure": 1019, "humidity": 32, "sea_level": 1019, "grnd_level": 1014}, "visibility": 10000, "wind": {"speed": 2.49, "deg": 140, "gust": 4.15}, "clouds": {"all": 100}, "dt": 1759662186, "sys": {"country": "CN", "sunrise": 1759616047, "sunset": 1759657887}, "timezone": 28800, "id": 1816670, "name": "Beijing", "cod": 200}
=== 第一次结果 ===
北京当前天气为多云,温度为17.38°C,体感温度为16.01°C。风速为2.49 m/s,湿度为32%。整体天气状况较为舒适。
==================================================
检查点历史
==================================================
=== 检查点 0 (next: ()) ===
Checkpoint ID: 1f0a1db2-f468-6602-8004-fde620773f92
Messages count: 4
=== 检查点 1 (next: ('agent',)) ===
Checkpoint ID: 1f0a1db2-e616-6e9c-8003-5dce54983b16
Messages count: 3
=== 检查点 2 (next: ('tools',)) ===
Checkpoint ID: 1f0a1db2-dfab-6beb-8002-022fa30c6f85
Messages count: 2
=== 检查点 3 (next: ('human_review',)) ===
Checkpoint ID: 1f0a1db2-c2dd-64c8-8001-25523b18653a
Messages count: 2
=== 检查点 4 (next: ('agent',)) ===
Checkpoint ID: 1f0a1db2-bd6d-6051-8000-d31656b995c0
Messages count: 1
=== 检查点 5 (next: ('__start__',)) ===
Checkpoint ID: 1f0a1db2-bd6b-6c22-bfff-655ead490034
==================================================
第二轮对话:从检查点恢复并询问上海天气
==================================================
[HITL] 模型计划调用工具 `get_weather`,参数:{'city': 'Shanghai'}
[HITL] 是否确认执行?(y/n): n
=== 第二次结果 ===
用户拒绝了工具调用,无法获取相关信息。