流水线依赖条件
1.代码无法使用内联函数调用
2.迭代之间有依赖关系,如N+1的操作依赖N中的操作
3.不能确定输入核输出缓冲区指针不会指向同一数组
4.处理器外部内存不支持SIMD 访问
5.代码包含 asm 语句:编译器无法知道 asm 语句执行的指令,因此无法自动判断这些指令在 SIMD 模式下是否安全,除非你使用 -annotate-loop-instr 开关告诉编译器某条 asm 语句在 SIMD 模式下是安全的,具体说明见 -asms-safe-in-simd-for-loops。
优化指令
#pragma SIMD_for
这个必须在 for while 或do...while 中
内存对齐
连续迭代中内存不会相互混叠
环形缓存必须是偶数个元素,指针初始值必须对齐
#pragma all_aligned
适用于后续循环,所有指针变量双字节对齐,后面可跟一个参数,代表指定n次迭代后参数对齐
#pragma loop_count (min,max,modulo)
描述循环迭代最小 最大值,并且是 modulo的倍数
#pragma loop_unroll N
将代码循环展开N 次
#pragma no_alias
下面的循环中加载或者存储操作不会引用彼此相同的内存
#pragma vector_for
编译器循环所有迭代可以相互并行运行
#pragma optimize_for_speed
提高代码运行速度高于减少代码大小
#pragma optimize_for_space
优先减少代码大小
#pragma alignment_region (2)
#pragma alignment_region_end

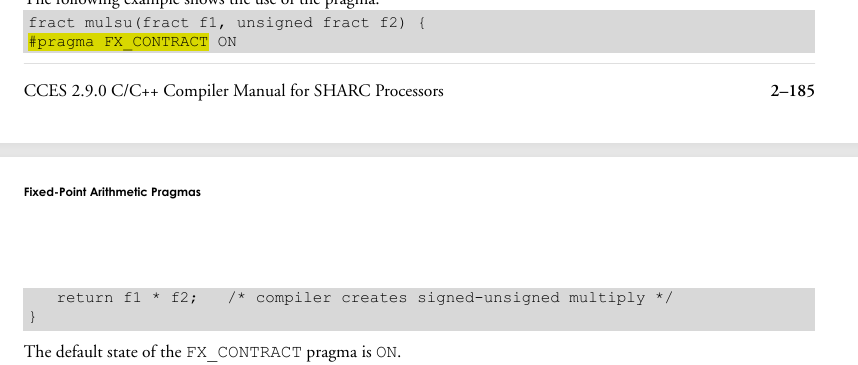
#pragma FX_CONTRACT {ON|OFF}
当开启时,中间结果没有存储回命名变量,编译器会将中间结果保持在比ISO/IEC C 报告18037要求的更高精度,能够生成更高效的代码
#pragma inline
#pragma never_inline
#pragma always_inline

#pragma core
指定代码在那个核

#pragma compatible _pm_dm_params
将pm 和dm 限定的指针视为赋值兼容
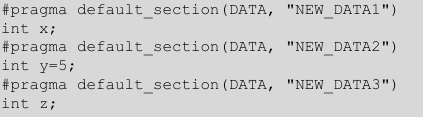
#pragma section/#pragma default_section
指定变量在参数哪个段
下面函数默认是用40bit 精度进行计算的

内存 定义

#pragma generate_exceptions_tables
使用 #pragma generate_exceptions_tables 的替代方法是使用 -eh(启用异常处理)选项编译 C 文件,对于 C 文件来说,这相当于在每个函数定义之前使用该 pragma。
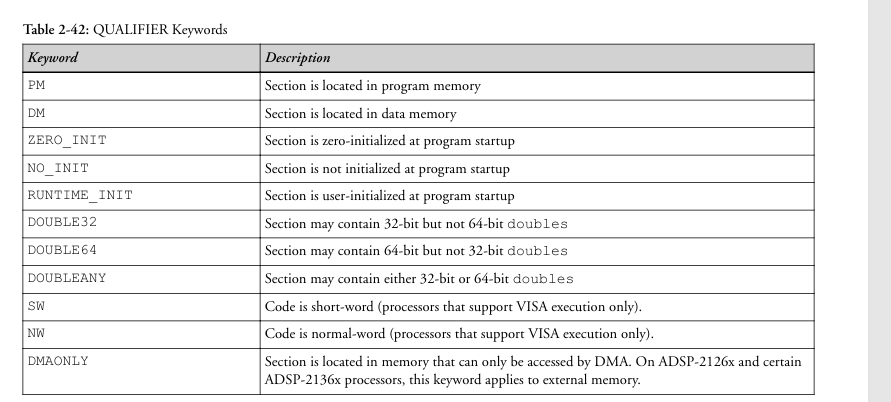
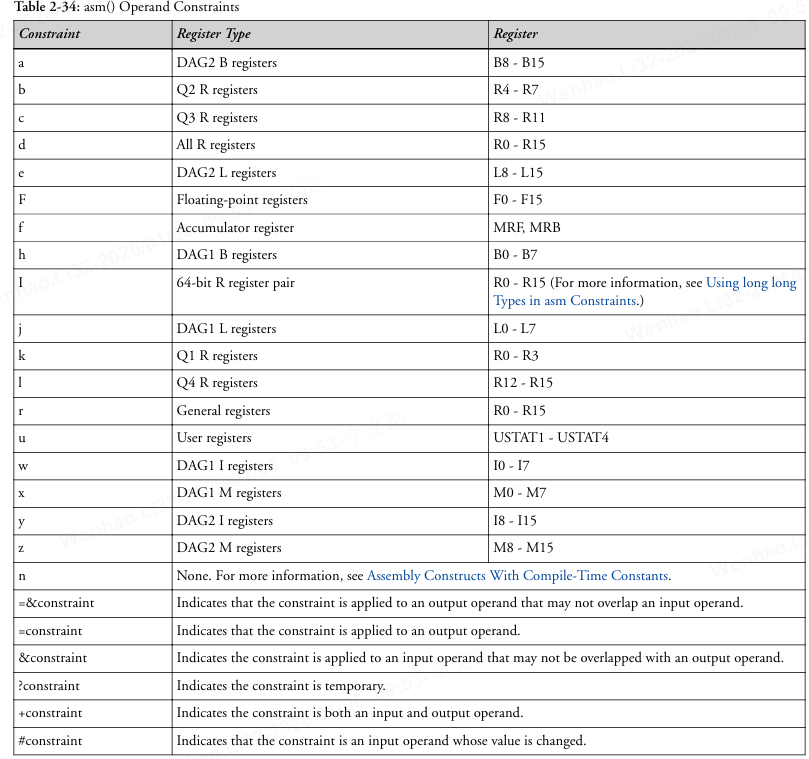
asm()操作数约束表字母和寄存器对应关系
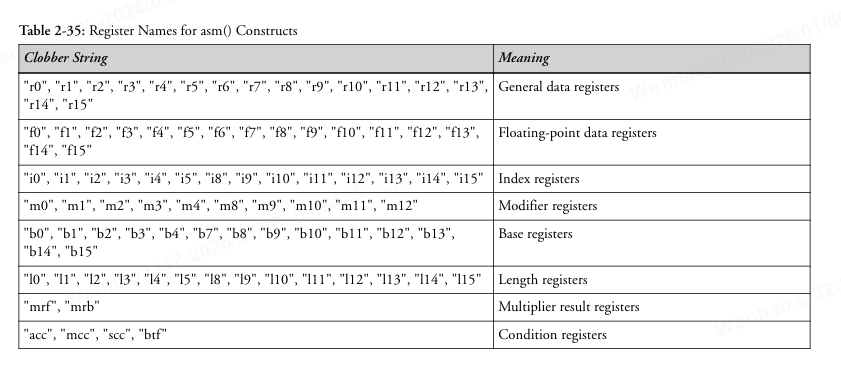

参考