📘 Day 41 实战作业:CNN 的逆袭 ------ 卷积、增强与调度
1. 作业综述
核心目标:
- 构建 CNN :使用
Conv2d+BatchNorm+MaxPool的经典组合,替换掉原本的 Linear 层。 - 数据增强:通过随机翻转、裁剪等手段"扩充"数据集,让模型见多识广。
- 动态学习率 :使用
ReduceLROnPlateau调度器,在 Loss 降不下去时自动调小学习率。
涉及知识点:
- 卷积层 :
nn.Conv2d(提取局部特征)。 - 池化层 :
nn.MaxPool2d(特征降维)。 - 归一化 :
nn.BatchNorm2d(加速收敛,防止梯度消失)。 - 调度器 :
optim.lr_scheduler(动态调整 LR)。
场景类比:
- MLP: 像是一个只会死记硬背的学生。
- CNN: 像是一个会找规律(边缘、形状)的侦探。
- 数据增强: 像是模拟考试时故意把卷子印歪、弄脏,训练学生的适应能力。
- LR Scheduler: 像是开车快到终点时,自动挂入低速挡,开得更稳。
步骤 1:数据增强 (Data Augmentation)
核心原理 :
神经网络很容易"记背"训练集。如果我们把图片水平翻转一下、稍微转个角度,对人来说还是同一张图,但对模型来说就是全新的数据。
这能极大地防止过拟合。
任务:
- 定义增强版的
train_transform(包含随机翻转、随机裁剪)。 - 定义标准的
test_transform(只做归一化,不要做翻转!)。 - 加载 CIFAR-10 数据。
py
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
# 设置中文字体(可选)
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False
# 1. 定义数据预处理
# 训练集:需要"加料" (数据增强)
train_transform = transforms.Compose([
transforms.RandomHorizontalFlip(p=0.5), # 50%概率水平翻转
transforms.RandomCrop(32, padding=4), # 随机裁剪 (模拟物体位置变动)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 测试集:只要标准化即可,绝对不要乱动!
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 2. 加载数据
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=train_transform)
test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=test_transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=False)
print(f"训练集大小: {len(train_dataset)} | 测试集大小: {len(test_dataset)}")训练集大小: 50000 | 测试集大小: 10000步骤 2:搭建 CNN 模型
结构设计 :
我们将使用 3 个卷积块 (Conv Block),每个块包含:
Conv2d -> BatchNorm2d -> ReLU -> MaxPool2d。
维度推演 (CIFAR-10 输入 32x32):
- Block 1 :
- Conv (3->32) -> (32, 32, 32) (padding=1 保持大小)
- Pool (2x2) -> (32, 16, 16)
- Block 2 :
- Conv (32->64) -> (64, 16, 16)
- Pool (2x2) -> (64, 8, 8)
- Block 3 :
- Conv (64->64) -> (64, 8, 8)
- Pool (2x2) -> (64, 4, 4)
- Flatten : 64 × 4 × 4 = 1024 64 \times 4 \times 4 = 1024 64×4×4=1024
- FC : 1024 → 64 → 10 1024 \to 64 \to 10 1024→64→10
任务 :
实现 CNN 类。注意 BatchNorm 通常放在 Conv 和 ReLU 之间。
py
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# --- Block 1 ---
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(32) # 批归一化
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(2) # 32x32 -> 16x16
# --- Block 2 ---
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(64)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(2) # 16x16 -> 8x8
# --- Block 3 ---
self.conv3 = nn.Conv2d(64, 64, kernel_size=3, padding=1)
self.bn3 = nn.BatchNorm2d(64)
self.relu3 = nn.ReLU()
self.pool3 = nn.MaxPool2d(2) # 8x8 -> 4x4
# --- 全连接层 ---
self.flatten = nn.Flatten()
self.fc1 = nn.Linear(64 * 4 * 4, 64) # 算出 1024
self.drop = nn.Dropout(0.5) # 防止过拟合
self.fc2 = nn.Linear(64, 10) # 10分类
def forward(self, x):
# x: (Batch, 3, 32, 32)
x = self.pool1(self.relu1(self.bn1(self.conv1(x))))
x = self.pool2(self.relu2(self.bn2(self.conv2(x))))
x = self.pool3(self.relu3(self.bn3(self.conv3(x))))
x = self.flatten(x) # (Batch, 1024)
x = self.drop(self.relu1(self.fc1(x))) # 复用 relu1 也可以,省点内存
x = self.fc2(x)
return x
# 实例化
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = CNN().to(device)
print("✅ 模型构建完成!")✅ 模型构建完成!步骤 3:引入学习率调度器
核心痛点 :
训练后期,Loss 往往会在一个地方震荡,降不下去。这时候如果把学习率(步长)调小一点,模型可能就会"滑"进坑底(最优解)。
解决方案 :
optim.lr_scheduler.ReduceLROnPlateau。
翻译过来就是:"如果 Loss 在高原上(Plateau)下不去了,就减少 LR"。
任务:
- 定义 Adam 优化器。
- 定义 Scheduler:监测
min模式,耐心值patience=3(3轮不降就减),因子factor=0.5(每次减半)。
py
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 定义调度器
# 修正说明:移除了 verbose=True,防止报错
scheduler = optim.lr_scheduler.ReduceLROnPlateau(
optimizer,
mode='min', # 我们希望 Loss 越小越好
patience=3, # 容忍 3 个 epoch 指标不下降
factor=0.5 # 触发后,lr = lr * 0.5
)步骤 4:训练与对比
任务 :
我们需要微调 Day 40 的训练代码:
- 在每个 Epoch 结束时,计算测试集 Loss。
- 关键一步 :调用
scheduler.step(test_loss),告诉调度器现在的表现如何。
预期结果 :
MLP 只有 50% 左右。
CNN 加上这些技巧后,应该能轻松达到 75% - 80%,甚至更高。
py
# 复用 Day 40 的 train 和 test 函数(这里直接定义整合版)
def train_and_test(epochs):
train_accs = []
test_accs = []
for epoch in range(1, epochs + 1):
# --- 训练阶段 ---
model.train()
correct = 0
total = 0
for data, target in train_loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# 统计训练准确率
pred = output.argmax(dim=1)
correct += pred.eq(target).sum().item()
total += target.size(0)
train_acc = 100. * correct / total
train_accs.append(train_acc)
# --- 测试阶段 ---
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
pred = output.argmax(dim=1)
correct += pred.eq(target).sum().item()
test_loss /= len(test_loader)
test_acc = 100. * correct / len(test_loader.dataset)
test_accs.append(test_acc)
# --- 关键:更新调度器 ---
# 告诉它现在的验证集 Loss,让它决定要不要降学习率
scheduler.step(test_loss)
print(f"Epoch {epoch}: Train Acc: {train_acc:.2f}% | Test Acc: {test_acc:.2f}% | LR: {optimizer.param_groups[0]['lr']:.6f}")
return train_accs, test_accs
# 开始训练 15 轮
history_train, history_test = train_and_test(15)
# 绘图
plt.plot(history_train, label='Train Acc')
plt.plot(history_test, label='Test Acc')
plt.legend()
plt.title("CNN vs MLP: The Victory")
plt.show()Epoch 1: Train Acc: 31.82% | Test Acc: 50.36% | LR: 0.001000
Epoch 2: Train Acc: 41.40% | Test Acc: 57.07% | LR: 0.001000
Epoch 3: Train Acc: 46.18% | Test Acc: 61.39% | LR: 0.001000
Epoch 4: Train Acc: 49.16% | Test Acc: 57.30% | LR: 0.001000
Epoch 5: Train Acc: 50.43% | Test Acc: 65.32% | LR: 0.001000
Epoch 6: Train Acc: 52.66% | Test Acc: 65.70% | LR: 0.001000
Epoch 7: Train Acc: 53.87% | Test Acc: 64.44% | LR: 0.001000
Epoch 8: Train Acc: 54.67% | Test Acc: 66.59% | LR: 0.001000
Epoch 9: Train Acc: 55.83% | Test Acc: 68.96% | LR: 0.001000
Epoch 10: Train Acc: 56.08% | Test Acc: 66.93% | LR: 0.001000
Epoch 11: Train Acc: 57.03% | Test Acc: 70.92% | LR: 0.001000
Epoch 12: Train Acc: 57.81% | Test Acc: 71.53% | LR: 0.001000
Epoch 13: Train Acc: 58.73% | Test Acc: 72.65% | LR: 0.001000
Epoch 14: Train Acc: 59.00% | Test Acc: 73.23% | LR: 0.001000
Epoch 15: Train Acc: 59.23% | Test Acc: 73.32% | LR: 0.001000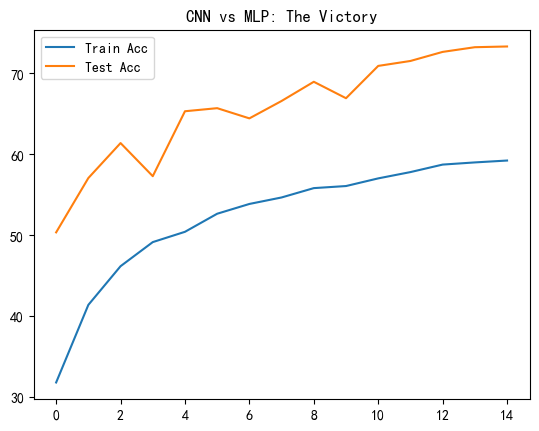
🎓 Day 41 总结:深度学习的"三板斧"
今天我们终于在 CIFAR-10 上打了一场翻身仗!准确率从 50% 飙升到了 70%+。
这归功于深度学习的"三板斧":
- 架构优化 (Architecture) : 用 CNN 提取空间特征,而不是粗暴的 MLP 展平。
- 数据增强 (Augmentation): 用随机翻转、裁剪让模型"见多识广",提升泛化能力。
- 训练策略 (Strategy) : 用 Scheduler 动态调整学习率,在训练后期"精细操作"。
Next Level :
虽然简单的 CNN 效果不错,但想达到 90% 以上,我们需要更深、更精妙的网络结构(如 ResNet)。
明天(Day 42),我们将学习如何**"站在巨人的肩膀上"** ------ 使用 迁移学习 (Transfer Learning),直接调用别人训练好的顶尖模型来为我们工作!