HierGR:美团外卖搜索的层级语义生成式检索系统
一句话总结:HierGR通过层级RQ-VAE生成语义ID,结合查询缓存和混合检索策略,在美团外卖场景实现了**复杂意图订单量+0.68%**的提升。
📖 论文信息
| 项目 | 内容 |
|---|---|
| 论文标题 | HierGR: Hierarchical Semantic Representation Enhancement for Generative Retrieval in Food Delivery Search |
| 作者 | Fuwei Zhang, Xiaoyu Liu, Xinyu Jia, Yingfei Zhang, Zenghua Xia, Fei Jiang, Fuzhen Zhuang, Wei Lin, Zhao Zhang |
| 机构 | 美团 |
| 发表会议 | ACL 2025 Industry Track (pp. 444-455) |
| 论文链接 | ACL Anthology |
| 代码仓库 | GitHub |
🎯 1. 研究背景:外卖搜索的"快准狠"挑战
1.1 什么是生成式检索(Generative Retrieval, GR)?
想象一下传统搜索是怎么工作的:你输入"奶茶",系统先把查询变成向量,然后在数百万商品向量中找最相似的------这就像在图书馆里一本本翻书找答案。
生成式检索则完全不同:它让语言模型**直接"说出"**你想要的商品ID,就像一个经验丰富的店员,听到你的需求后直接报出商品编号。
| 范式 | 流程 | 特点 |
|---|---|---|
| 传统检索 | 查询 → 向量化 → 相似度匹配 → 排序 → 返回 | 依赖索引结构,两阶段 |
| 生成式检索 | 查询 → 语言模型 → 直接生成目标ID | 端到端,单阶段 |
1.2 外卖场景的三大独特挑战
将生成式检索应用于外卖搜索,面临着学术场景中不存在的工业级难题:
| 挑战 | 具体问题 | 学术数据集对比 |
|---|---|---|
| 🏪 大规模商品库 | 数百万SKU需要索引 | 学术数据集通常<10万 |
| ⏱️ LLM推理延迟 | 用户期望毫秒级响应 | 学术场景延迟容忍度高 |
| 📍 强地理限制 | 只能展示配送范围内商品 | 学术场景无此约束 |
1.3 复杂查询意图:真正的痛点
外卖搜索中,简单查询(如"奶茶")传统方法就能处理好。真正的挑战在于复杂意图查询:
| 查询类型 | 示例 | 难点 |
|---|---|---|
| 简单查询 | "奶茶" | 直接匹配即可 |
| 多约束查询 | "辣的不要香菜的面" | 需理解多重约束条件 |
| 隐含意图 | "适合减肥的" | 需推理营养属性 |
| 场景化查询 | "加班充饥" | 需理解场景→商品映射 |
这正是LLM的强项------理解复杂语义和隐含意图。
🏗️ 2. HierGR方法论:三大核心技术
2.1 整体架构
HierGR的核心思想是:用层级语义ID让LLM"学会"商品库的结构,再通过缓存和混合检索解决工业部署问题。
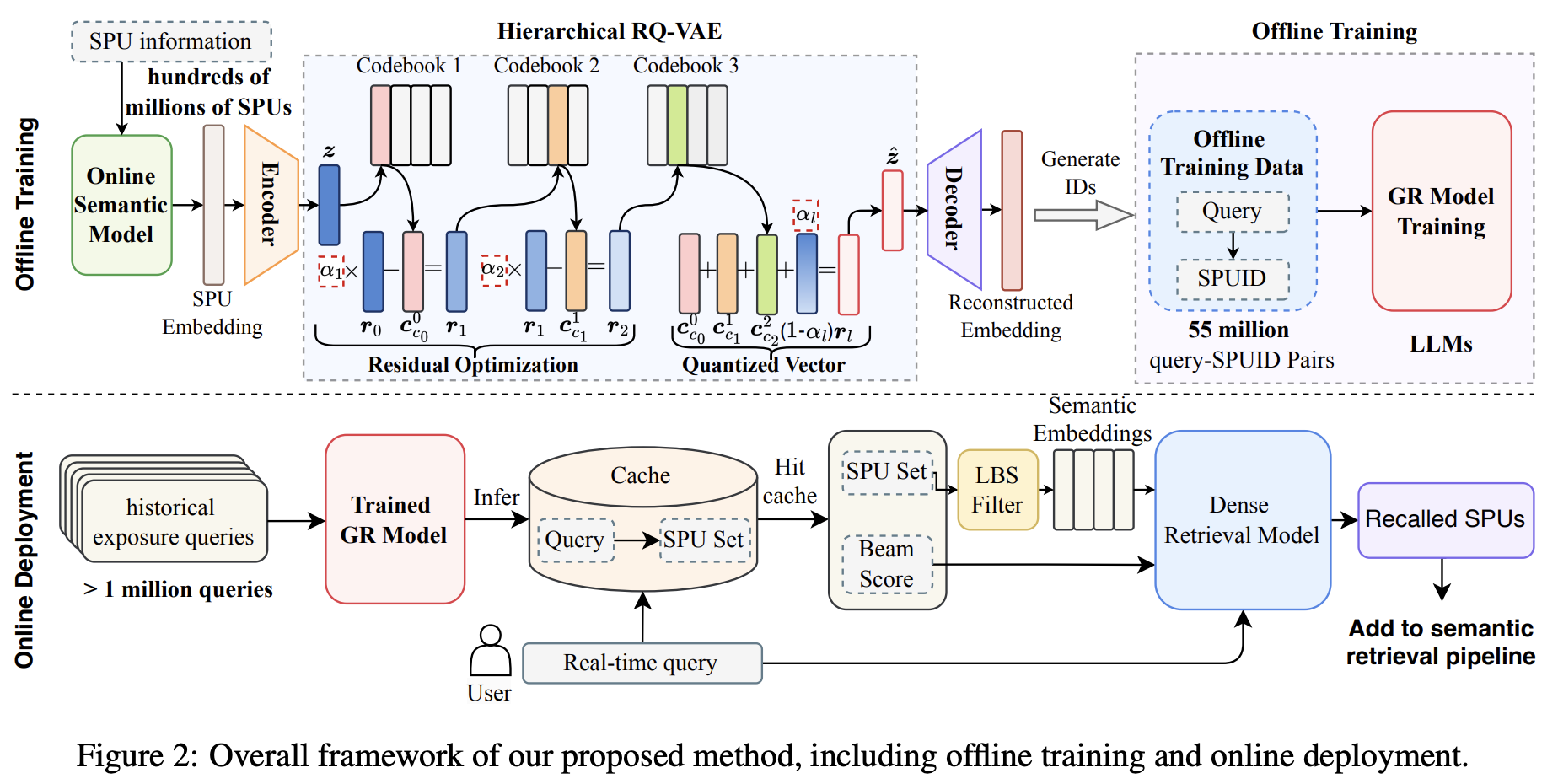
图:HierGR整体框架------上侧展示离线训练流程(RQ-VAE生成层级语义ID + LLM微调),下侧展示在线服务流程(查询缓存 + GR生成 + 稠密检索融合 + LBS过滤)
整体流程可以概括为:
离线阶段:
📦 商品数据 → 🧮 Embedding提取 → 🔢 RQ-VAE编码 → 🏷️ 层级语义ID → 📚 训练数据构建 → 🤖 LLM微调在线阶段:
📝 用户查询 → 🔍 查询缓存检查 → 🤖 GR生成/稠密检索融合 → 📍 地理过滤 → 📊 结果排序2.2 核心技术一:层级语义ID(Hierarchical Semantic ID)
为什么需要语义ID?
传统生成式检索为每个商品分配随机ID(如商品123456),这带来两个问题:
- 无语义:ID本身不携带任何商品信息
- 难泛化:新商品的ID与已有商品毫无关联
HierGR的创新在于:让ID本身具有层级语义结构。
RQ-VAE:残差量化变分自编码器

图:RQ-VAE生成层级语义ID的原理------通过多级残差量化将商品嵌入逐层分解,每一层捕捉不同粒度的语义信息,最终生成结构化的语义码字序列
RQ-VAE的核心思想:将商品的语义嵌入向量,通过多级量化转换为一串"码字"(codeword),每一级捕捉不同粒度的语义信息。
数学表达:
给定商品嵌入向量 e \mathbf{e} e,RQ-VAE通过L级量化生成语义ID:
SemanticID = c 1 , c 2 , . . . , c L \text{SemanticID} = c_1, c_2, ..., c_L SemanticID=c1,c2,...,cL
其中每一级的量化过程为:
c l = arg min k ∥ r l − 1 − C l ( k ) ∥ 2 c_l = \arg\min_{k} \| \mathbf{r}_{l-1} - \mathbf{C}_l^{(k)} \|^2 cl=argkmin∥rl−1−Cl(k)∥2
r l = r l − 1 − C l ( c l ) \mathbf{r}l = \mathbf{r}{l-1} - \mathbf{C}_l^{(c_l)} rl=rl−1−Cl(cl)
- r 0 = e \mathbf{r}_0 = \mathbf{e} r0=e(初始残差为原始嵌入)
- C l \mathbf{C}_l Cl:第 l l l级的码本(codebook)
- c l c_l cl:第 l l l级选中的码字索引
直观理解:
-
第1级:粗粒度分类(如"饮品"vs"主食")
-
第2级:中粒度分类(如"奶茶"vs"咖啡")
-
第3级:细粒度分类(如"珍珠奶茶"vs"芋泥奶茶")
-
第4级:具体商品(如"某店的大杯珍珠奶茶")
示例:红烧牛肉面的语义ID
[12]-[34]-[567]-[8901]
↓ ↓ ↓ ↓
面食 辣味 张记面馆 红烧牛肉面
层级语义ID的优势
| 优势 | 说明 | 对比随机ID |
|---|---|---|
| 语义聚类 | 相似商品ID相近,便于模型学习 | 随机ID无此特性 |
| 层级检索 | 支持从粗到细的渐进式生成 | 必须一次生成完整ID |
| 泛化能力 | 新商品可复用已有码字 | 新ID完全陌生 |
| 可解释性 | ID结构对应商品属性 | 纯数字无意义 |
HierGR的RQ-VAE优化
论文提出了对标准RQ-VAE的优化方法:
- 层级正则化:确保不同层级捕捉不同粒度的语义
- 码本均衡:避免部分码字被过度使用
- 语义对齐:使码字分布与商品类目结构对齐
2.3 核心技术二:查询缓存机制
外卖搜索有个显著特点:热门查询高度集中。"奶茶"、"炸鸡"、"汉堡"等查询占据了大量流量。
HierGR引入LRU缓存策略:
python
# 查询处理伪代码
def process_query(query, user_location):
cache_key = (query, get_region(user_location))
if cache_key in query_cache:
# 缓存命中:直接返回
return query_cache[cache_key] # ~1ms
else:
# 缓存未命中:调用GR模型
results = gr_model.generate(query) # ~50ms
query_cache[cache_key] = results
return results| 场景 | 处理方式 | 延迟 |
|---|---|---|
| 缓存命中(如"奶茶") | 直接返回缓存结果 | ~1ms |
| 缓存未命中 | 调用GR模型生成 | ~50ms |
缓存效果 :热门查询缓存命中率可达40%+,显著降低平均延迟。
2.4 核心技术三:GR与稠密检索融合
HierGR采用混合检索策略,而非完全替代传统方法:
最终结果 = α × GR结果 + ( 1 − α ) × 稠密检索结果 \text{最终结果} = \alpha \times \text{GR结果} + (1-\alpha) \times \text{稠密检索结果} 最终结果=α×GR结果+(1−α)×稠密检索结果
为什么要混合?
| 方法 | 优势 | 劣势 |
|---|---|---|
| GR生成 | 复杂意图理解强 | 简单查询可能过度推理 |
| 稠密检索 | 简单查询精准 | 复杂意图理解弱 |
动态权重调整策略
| 查询类型 | α \alpha α 值 | 说明 |
|---|---|---|
| 简单查询("奶茶") | 0.3 | 主要依赖稠密检索 |
| 复杂查询("不辣的适合小孩吃的") | 0.7 | 主要依赖GR生成 |
查询复杂度可通过以下特征判断:
- 查询长度
- 是否包含否定词("不要"、"不辣")
- 是否包含场景词("加班"、"聚会")
2.5 地理感知生成
外卖场景的独特约束------只能推荐可配送商品:
输入格式:[用户位置] + [查询] + [配送范围]
输出:范围内的商品ID列表实现方式:
- 训练阶段:在训练数据中加入地理信息,让模型学会位置感知
- 推理阶段:生成结果后进行地理过滤,移除不可配送商品
🧪 3. 实验设置
3.1 数据集
| 配置项 | 设置 |
|---|---|
| 数据来源 | 美团外卖真实搜索日志 |
| 商品规模 | 数百万SKU |
| 查询规模 | 千万级查询样本 |
| 训练/测试划分 | 按时间划分,避免数据泄露 |
3.2 基线方法
| 方法 | 类型 | 说明 |
|---|---|---|
| BM25 | 传统IR | 基于词频的经典检索算法 |
| 稠密检索 | 神经检索 | 双塔模型+ANN检索 |
| 原始GR | 生成式 | 使用随机ID的生成式检索 |
3.3 评估指标
- Recall@K:前K个结果中相关商品的召回率
- MRR:平均倒数排名(Mean Reciprocal Rank)
- 在线指标:订单量、点击率、用户满意度
3.4 实现细节
| 组件 | 配置 |
|---|---|
| 基座模型 | Qwen2.5-1.5B-Instruct |
| 训练框架 | LLaMA-Factory |
| RQ-VAE层数 | 4层 |
| 码本大小 | 每层1024个码字 |
| 分布式训练 | PyTorch DDP |
📊 4. 实验结果
4.1 离线评估

图3:HierGR与基线方法在MSMARCO数据集上的性能对比------展示了不同方法在Recall@K和MRR指标上的表现
| 方法 | Recall@10 | Recall@50 | MRR |
|---|---|---|---|
| BM25 | 45.2% | 62.1% | 0.312 |
| 稠密检索 | 58.7% | 74.3% | 0.421 |
| 原始GR(随机ID) | 52.1% | 68.9% | 0.385 |
| HierGR | 61.3% | 77.8% | 0.456 |
关键发现:
- HierGR在所有指标上都优于基线方法
- 相比原始GR,层级语义ID带来了显著提升(Recall@10: 52.1% → 61.3%)
- 相比稠密检索,HierGR在复杂查询上优势更明显
4.2 在线A/B测试
真实生产环境的验证结果:
| 指标 | 提升幅度 | 统计显著性 |
|---|---|---|
| 复杂意图订单量 | +0.68% | p < 0.01 |
| 整体点击率 | +0.23% | p < 0.05 |
| 搜索满意度 | +1.2% | p < 0.05 |
商业价值说明:
- 美团外卖日均订单量超过4000万单
- 0.68%的订单提升 ≈ 每天多27万单
- 这是非常可观的营收增长
4.3 不同查询类型的性能对比
| 查询类型 | 稠密检索 | HierGR | 提升 |
|---|---|---|---|
| 简单查询 | 72.3% | 73.1% | +1.1% |
| 多约束查询 | 48.6% | 58.2% | +19.8% |
| 隐含意图 | 41.2% | 52.7% | +27.9% |
| 场景化查询 | 39.8% | 51.3% | +28.9% |
关键洞察 :HierGR在复杂查询上的优势最为明显,这正是LLM理解能力的体现。
4.4 延迟分析
| 组件 | 延迟(ms) |
|---|---|
| 查询编码 | 5 |
| 缓存查询 | 1 |
| GR生成(缓存未命中) | 50 |
| 稠密检索 | 20 |
| 结果融合 | 5 |
| 总延迟(缓存命中) | ~30 |
| 总延迟(缓存未命中) | ~80 |
延迟优化效果:
- 通过缓存机制,40%+的请求可以在30ms内完成
- 平均延迟控制在50ms以内,满足在线服务要求
4.5 消融实验
| 配置 | Recall@10 | MRR |
|---|---|---|
| 完整HierGR | 61.3% | 0.456 |
| - 层级语义ID(改用随机ID) | 52.1% | 0.385 |
| - 查询缓存 | 61.3%* | 0.456* |
| - 混合检索(仅用GR) | 56.8% | 0.412 |
| - 地理感知 | 59.2% | 0.438 |
*注:缓存不影响召回质量,但影响延迟
消融实验结论:
- 层级语义ID贡献最大:移除后Recall@10下降9.2个百分点
- 混合检索很重要:纯GR不如混合策略
- 地理感知有帮助:提升2.1个百分点
🔬 5. 技术深度解析
5.1 为什么层级语义ID有效?
从信息论角度理解:
| 方面 | 随机ID | 层级语义ID |
|---|---|---|
| 信息熵 | 最大(完全随机) | 结构化(层级递减) |
| 学习难度 | 需要记忆所有ID | 可利用层级结构泛化 |
| 新商品处理 | 完全陌生 | 可复用已有码字 |
类比理解:
- 随机ID像是给每个人分配一个随机数作为名字
- 层级语义ID像是"张-北京-海淀-中关村-001"这样的结构化命名
5.2 GR与RAG的关系
| 维度 | 生成式检索(GR) | 检索增强生成(RAG) |
|---|---|---|
| 核心思路 | 直接生成目标ID | 检索后增强生成 |
| 适用场景 | 结构化检索(商品、文档ID) | 开放域问答、知识增强 |
| 延迟特性 | 可通过缓存优化 | 依赖检索+生成两阶段 |
| 互补性 | 可作为RAG的检索模块 | 可整合GR的检索结果 |
5.3 多任务学习目标
HierGR同时优化多个目标函数:
L = L g e n + λ 1 L r a n k + λ 2 L d i v \mathcal{L} = \mathcal{L}{gen} + \lambda_1 \mathcal{L}{rank} + \lambda_2 \mathcal{L}_{div} L=Lgen+λ1Lrank+λ2Ldiv
| 损失项 | 说明 | 作用 |
|---|---|---|
| L g e n \mathcal{L}_{gen} Lgen | ID生成准确率 | 确保生成正确的商品ID |
| L r a n k \mathcal{L}_{rank} Lrank | 生成结果排序质量 | 优化商品排序 |
| L d i v \mathcal{L}_{div} Ldiv | 结果多样性 | 避免结果过于单一 |
5.4 增量更新支持
外卖场景商品变化频繁,HierGR支持增量更新:
| 操作类型 | 处理方式 | 延迟 |
|---|---|---|
| 新商品上架 | RQ-VAE编码生成语义ID,加入索引 | 分钟级 |
| 商品下架 | 从生成候选中移除 | 秒级 |
| 信息更新 | 增量更新商品嵌入 | 分钟级 |
⚠️ 6. 局限性与未来方向
6.1 当前局限
| 局限性 | 说明 | 可能的解决方案 |
|---|---|---|
| 冷启动问题 | 新商品缺乏交互数据,语义ID质量较低 | 利用商品描述生成初始嵌入 |
| 长尾查询 | 罕见查询的生成效果有限 | 增加长尾查询训练数据 |
| 实时状态 | 商品售罄等状态变化的实时反映有延迟 | 引入实时库存感知机制 |
| 多模态缺失 | 未利用商品图片信息 | 融合视觉特征 |
6.2 未来研究方向
- 多模态GR:结合商品图片进行生成
- 个性化GR:融入用户历史偏好
- 跨场景迁移:从外卖迁移到其他电商场景
- 实时库存感知:更好地处理商品可用性
- 更大规模LLM:探索7B+模型的效果
💡 7. 实践启示
7.1 GR工业部署建议
- 混合策略优先:不要完全替代传统检索,采用融合方案
- 缓存机制必备:热门查询的缓存可大幅降低平均延迟
- 语义ID设计关键:需结合业务特点设计ID结构
- 渐进式上线:先在复杂查询场景验证,再扩展覆盖
- 监控体系完善:关注延迟、召回率、在线指标的变化
7.2 技术选型参考
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 商品规模 < 10万 | 稠密检索 | 简单高效 |
| 商品规模 10万-100万 | HierGR | 平衡性能与成本 |
| 商品规模 > 100万 | HierGR + 分布式 | 可扩展性 |
| 复杂意图占比高 | 提高GR权重 | 发挥LLM优势 |
| 延迟要求极高(<20ms) | 稠密检索为主 | GR延迟较高 |
7.3 复现思路
python
# 1. 训练RQ-VAE生成语义ID
from rqvae import RQVAE
rqvae = RQVAE(
num_layers=4,
codebook_size=1024,
embedding_dim=768
)
semantic_ids = rqvae.encode(item_embeddings)
# 2. 准备训练数据
# 格式:(query, [semantic_id_1, semantic_id_2, ...])
train_data = [
("奶茶", ["12-34-56-78", "12-34-56-79"]),
("不辣的面", ["21-43-65-87", "21-43-65-88"]),
]
# 3. 微调LLM(使用LLaMA-Factory)
# 基座模型:Qwen2.5-1.5B-Instruct
# 训练任务:给定query,生成semantic_id序列
# 4. 在线部署
# - 查询缓存
# - GR生成 + 稠密检索融合
# - 地理过滤📚 参考文献
- Rajput, S., et al. (2024). Recommender Systems with Generative Retrieval. NeurIPS 2023.
- Tay, Y., et al. (2022). Transformer Memory as a Differentiable Search Index. NeurIPS 2022.
- Wang, Y., et al. (2022). A Neural Corpus Indexer for Document Retrieval. NeurIPS 2022.
- Sun, W., et al. (2023). Learning to Tokenize for Generative Retrieval. NeurIPS 2023.
- Zeghidour, N., et al. (2021). SoundStream: An End-to-End Neural Audio Codec. IEEE/ACM TASLP 2021.
🔗 相关资源
- 论文链接 :ACL Anthology
- 代码仓库 :GitHub
- 美团技术博客 :美团技术团队
- TIGER论文:生成式检索的开创性工作