汇编
1. 第一章序言
编译器: 用于将汇编语言源程序转化为机器语言。
链接器: 它把汇编器生成的单个文件(目标模块)组合 为一个可执行文件。
源程序 -> 目标模块 -> 可执行文件
寄存器: CPU中的存储位置。(保存操作的中间结果)
Q: 为什么要学汇编语言?
A: 汇编语言:以花费大量时间进行调试为代价,换来 访问底层 数据(内存)
,从自由访问底层,优化速度,代码体积小,和实际嵌入式或驱动开发需要分析
L0 : 计算机可以用电子电路来执行机器语言(l0由数字组成)的每条 指令,这种语言称为L0。
L1: 程序员可以自由编写的语言(L1)
2. x86处理架构
2. 基本组成与总线
时钟: CPU内部操作与系统其它组件进行同步。
控制单位(CU): 协调参与机器指令执行的步骤序列
算术逻辑单元(ALU): 执行算术、逻辑运算。
内存存储单元 :程序运行时保存指令及数据
总线: 一组并行线,将数据从计算机的一个部分传到另一部分。
数据总线: 在内存和CPU之间传递指令和数据。
控制总线: 用二进制信号对所有连接在总线上的设备的行为进行同步。
地址总线: 保持指令和数据的地址。
I/O总线: 在系统输入/输出设备和CPU之间传输数据。
指令执行步骤:取指、译码、执行
2.2 寄存器分类
了解下面分类即可
处理器内部的高速存储单元
用于暂时存放程序执行过程中的代码和数据
透明寄存器 : 对应用人员不可见、不能编程直接控制
可编程(Programmable)寄存器: 具有引用名称、供编程使用
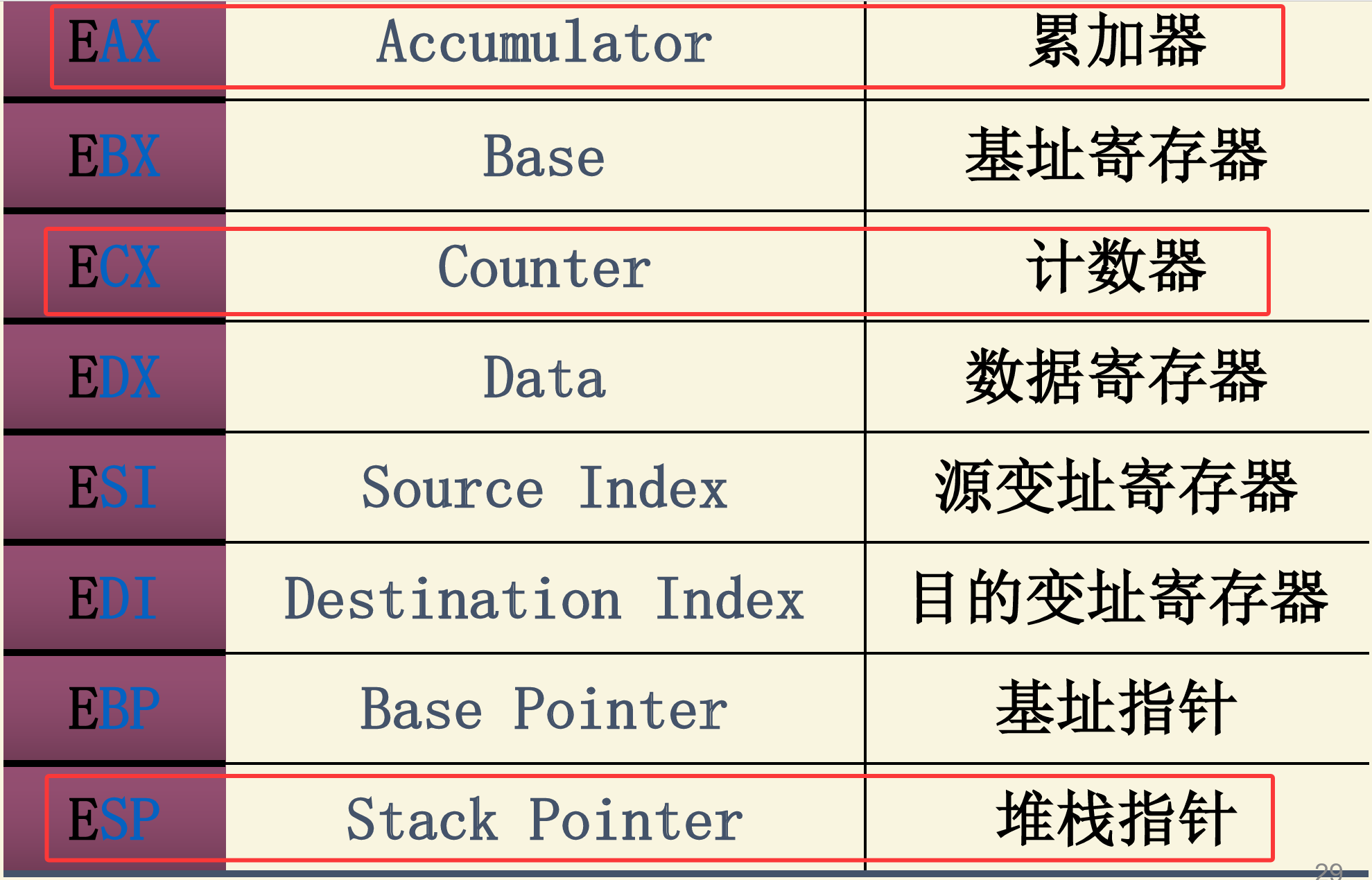
通用寄存器(General-Purpose Register) 具有多种用途 数量较多、使用频度较高
专用寄存器 各自只用于特定目的
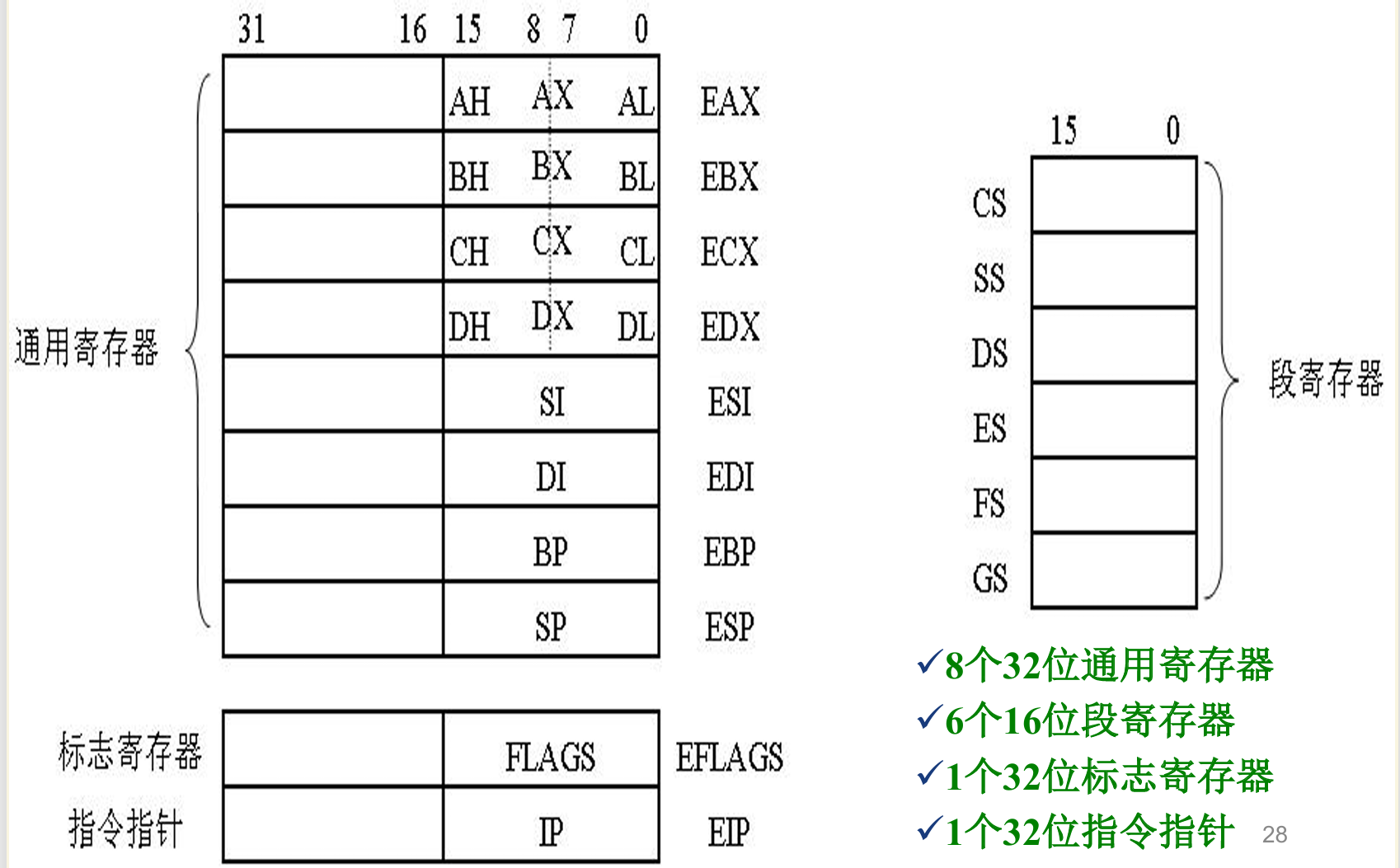
EIP是专用寄存器: 顺序执行时自动增量(加上该指令的字节数),指 向下一条指令 。在分支、调用等操作时,执行控制转移指令修改,引起程序转移到指定的指令执行,出现中断或异常时被处理器赋值而相应改变
段 是用于安排相关代码或数据的一个主存区域,分为 代码段 (存放程序中指令代码 ), 数据段 (存放当前运行程序所用数据), 堆栈段 (指明程序使用的堆栈区域)
下面是常用的通用寄存器寄存器的作用,EAX 应用在做加法运算上,ECX 应用在循环的计数上,ESP 是当前地址的堆栈指针
3.汇编语言基础
3.1 基础定义
先看一个简单的例子,这里有数据段,用来存放数据,代码段,用来存放程序,在这里需要程序的入口,调用退出函数,程序的结尾
assembly
.386 ;这是一个32位程序
.model flat , stdcall ;选择flat内存模式,确认子程序调用规范(stdcall规范)
.stack 4096 ;堆栈保留4096字节存储空间
ExitProcess PROTO, dwExitCode:DWORD ;给windows系统的返回值
.data
sum DWORD 0
.code
main PROC ;main声明
mov eax , 5
add eax , 6
INVOKE ExitProcess , 0
main ENDP下面是其中涉及到量的说明:
整数常量: 需要说明相应的进制,十进制(d),十六进制(h)
整数常量表达式: 需符合相应的运算顺序
字符/字符串常量: 单双引号都可
标识符: 程序员自定义名称,注意不与保留字相同
伪指令: 不在运行时执行,但可以用来定义变量、宏;为内存段分配名称,就是前面的.data 之类的,还有后面的 WORD之类的
指令:(一般就是指令助记符 + 操作数)
标号:可选
指令助记符:必须 ,汇编语言操作 数的个数是0-3
操作数:通常必须
注释:可选,单行注释,用分号(;)开始,多注释:COMMENT ! 注释内容 !
3.2 数据定义
有下面的数据类型
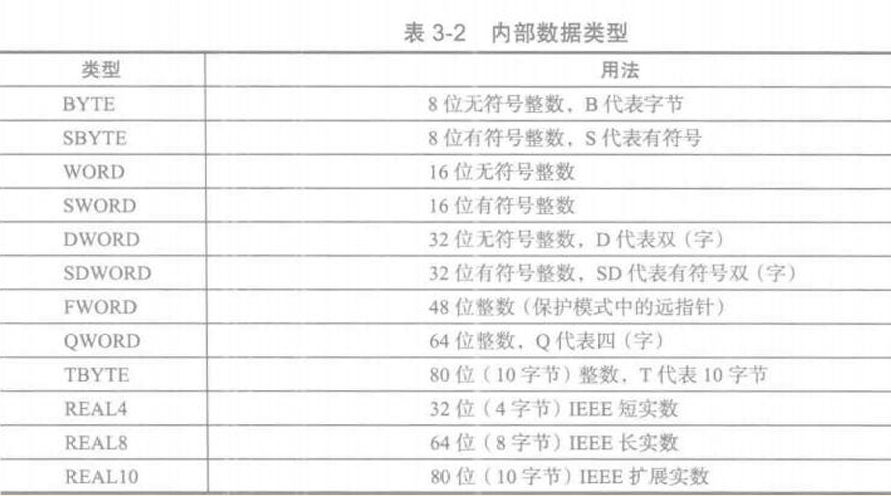
定义数据的格式如下:
名字 伪指令 初始值
初始值必须至少1个,可以是 ?
多个数据定义示例 : list1 BYTE 10,20,30,40
定义字符串:greeting1 BYTE "Good afternoon", 0
在最后一行使用 \ 可以把多行进行拼接
申请空间 DUP
可以重复的申请指定的空间
下面就是名字为count的 双字类型的 重复40次 申请 1,2,3,4,5
asm
count DW 40 DUP(1,2,3,4,5)小端: 低位数据存储在低地址,低位指定是右边开始
地址计数器$
这个表达当前的偏移量,可以用来计算数据的大小
asm
list BYTE 10,20,30,40
ListSize =($-list)4. 数据传送、寻址和算术运算
**操作数有三种类型: ** 立即数,寄存器操作数,内存操作数
4.1 MOV指令

我们发现,不能内存到内存

最后总结主要一下几点:
- 两个操作数必须是同样的大小
- 两个操作数不能同时为内存操作数
- 指令指针寄存器(IP、EIP或RIP)不能作为目标操作数
当我们把较小的值赋值到较大的值,需要涉及拓展
无符号拓展: MOVZX
有符号拓展: MOVSX (就是使用最高位补全)
4.2 状态标志保存
状态标志位(EFLAGS)与低8位寄存器(AH),通过寄存器保存标志位,如下示范

4.3 其余操作数
XCHG: 指令交换两个操作数的内容
偏移量操作数: 通过加上偏移量来进行寻址,像数组访问一样,注意单次偏移大小和数据类型有关
OFFSET运算符: 得到数据标号的偏移量,单位字节
ALIGN伪指令: 对其偶数内存地址。原因:偶数地址更快
PTR运算符: 强制转换
type运算符: 返回变量单个元素的大小,单位:字节
lengthof运算符: 计算数组中元素的个数,不关心每个元素的大小
sizeof运算符: = type * lengthof
4.4 加法减法指令集
4.4.1 自增自减
inc (自增)和dec(自减):寄存器或内存加1减1,不会影响进位标准位(CF)
4.4.2 加减法
add:源操作数不变,相加之和存在目的操作数中
sub:目的操作数减去源操作数
neg: 把符号进行取反
4.5 标志位
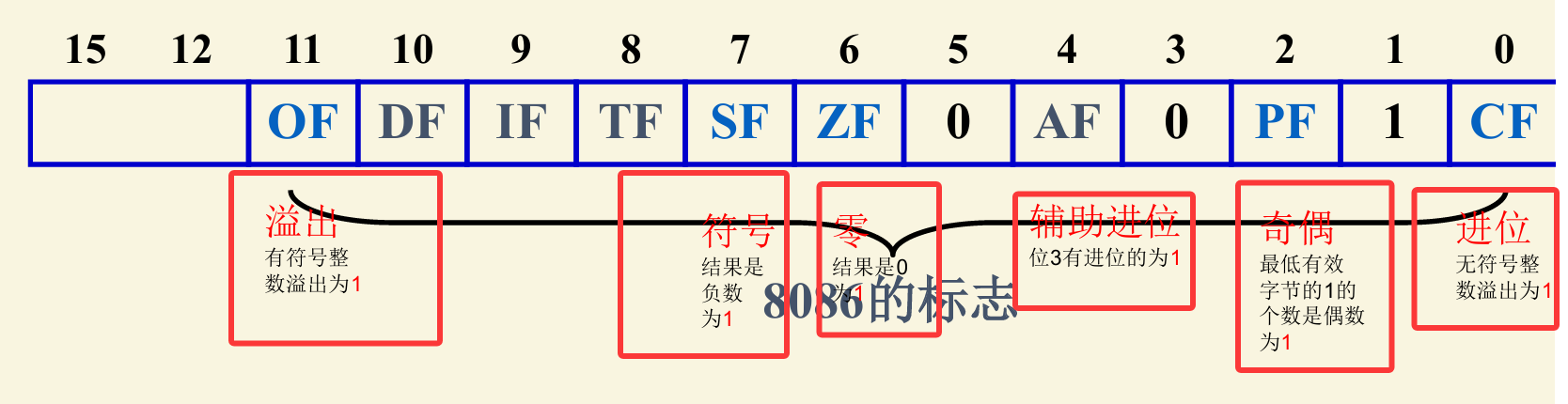
对于有符号和无符号来说,区别除了符号位外,区别最大的是,无符号数溢出时是CF位置1,但是对于有符号来说,OF表示溢出,CF表示进位
4.6 寻址
直接寻址: 直接通过数组类似的方式访问
asm
.data
arrayB Byte 10h, 20h, 30h, 40h
.code
mov al, arrayB+0
mov bl, [arrayB+1]
mov cl, [arrayB+2]间接寻址: 通过偏移量地址进行访问
下面这段代码自增的是 10,
asm
.data
arrayB Byte 10h, 20h, 30h
.code
mov esi, offset arrayB
mov al, [esi]
inc [esi]
;报错:系统不知道操作数的大小。
inc BYTE PTR [esi]下面是通过改变esi的方法实现偏移
注意:因为是byte,所以esi增加1,就可以寻到下一个,如果是其余类型,移动一位需要增减相应数据类型的字节数
asm
.data
arrayB Byte 10h, 20h, 30h
.code
mov esi, offset arrayB
mov al, [esi]
方法1:inc自增
inc esi
mov al ,[esi]
inc esi
mov al , [esi]法二:使用变址操作数,通用注意数据类型
asm
.data
arrayB Byte 10h, 20h, 30h
.code
;方法2:变址操作数(寄存器+常数)
mov esi 0
mov al , arrayB[esi]
mov al , arrayB[esi+1]
mov al , arrayB[esi+2]4.7 指针
前面我们知道了可以通过offset得到地址,所以可以自定义指针,来完成保存某个地址,如下:


4.8 跳转
跳转分为jmp 和 loop 两类,前者是根据标志位进行条件跳转,后者是通过ecx进行计算跳转
jmp:去看书上的跳转指令表
loop: 到达这会执行下面的步骤
- ECX减1。
- ECX与0比较,不等于0的话调到标号处。
- 如果ECX=0,不发生跳转,执行循环后面的指令。
如果内部还有循环,需要先把ecx的值保存在变量,或者压栈,内部循环结束后,再进行恢复
5. 过程
栈: 先进后出的一种结构体
入栈出栈指令:
asm
;入栈指令:push
PUSH reg/mem16
PUSH reg/mem32
PUSH imm32
;出栈指令:pop
POP reg/mem16
POP reg/mem32衍生指令: 看看就行
asm
;入栈指令:pushfd(将标志寄存器压入堆栈)
pushad ;(按照顺序将所有的32位通用寄存器压入堆栈)
pusha ;(按照顺序将所有的16位通用寄存器压入堆栈)
;出栈指令:popfd(将桟中的内容弹回标志寄存器)
popad ;(按照相反的顺序将所有的32位通用寄存器弹出堆栈)
popa ;(按照相反的顺序将所有的16位通用寄存器弹出堆栈)定义子程序:
通过 PROC 和 ENDF 定义
asm
sample PROC
..
ret
sample ENDPCall/ret
完成函数的跳转,分别体会call和ret是什么作用
call:
1.将调用call的函数的call的下一条指令地址压入堆栈
2.将子程序的地址给EIP
就是我本来马上执行call,call执行了该执行call的下一条,这个时候先保存下一条的位置,然后执行call的时候,跑到call里函数的位置了
ret:
1.将主程序里下一条指令地址给EIP
call里执行完成之后,使用ret,得到调用call的函数的下一条指令位置,给EIP
给子程序传递参数
需要保证原来的数不改变,所以通过入栈和出栈进行保护
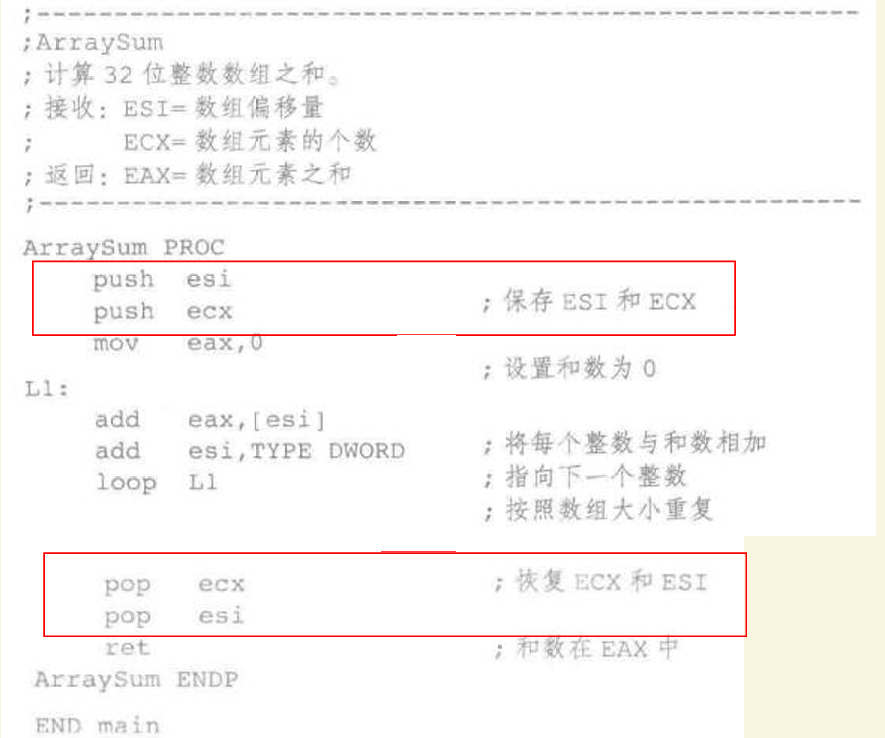
当然可以使用
USES运算符
-
列出要修改的寄存器
-
子程序开始时自动调用push、子程序结束时自动调用pop指令
和上面的等价

6.条件分支与跳转
布尔指令: and(test) ,or, not, xor
比较指令: cmp
test 与 and的不同之处不改变目标操作
cmp:目的操作数减去源操作数,查看结果的ZF,CF,OF标志位
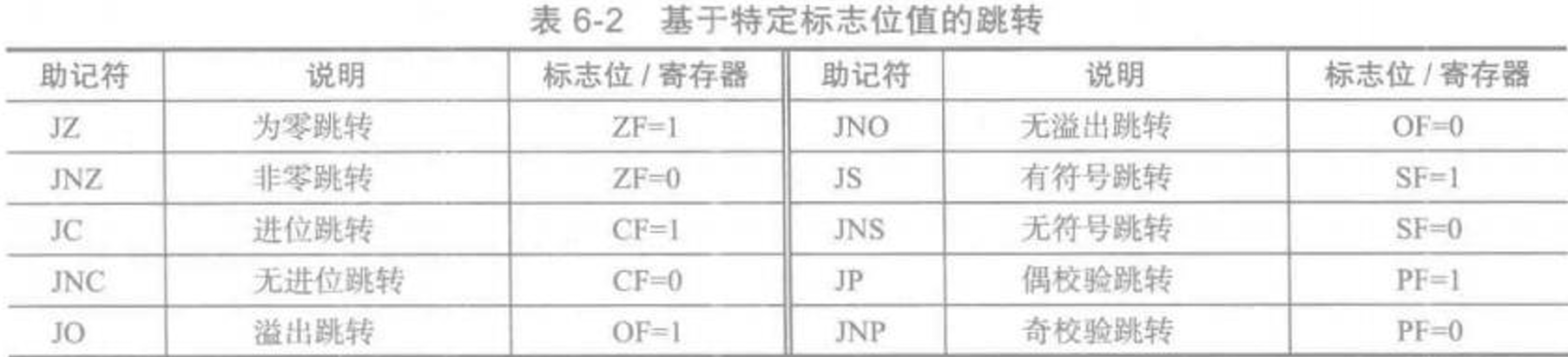
6.1 条件跳转
分为了以下四大类:
-
基于特定标志位的值跳转。(零标志位、进位标志位、奇偶标志位等)
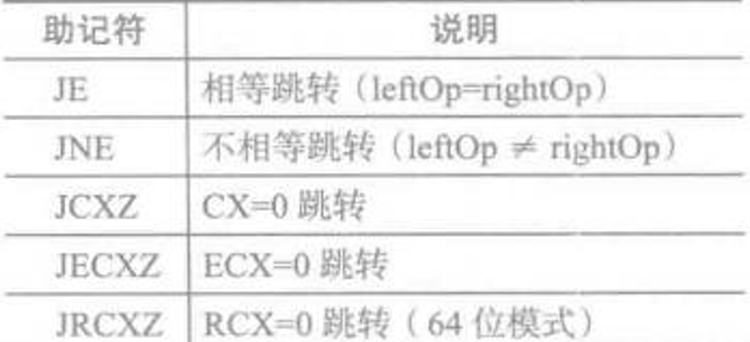
-
基于两数是否相等,或是否等于ECX寄存器的值跳转
-
基于无符号操作数的比较跳转

-
基于有符号操作数的比较跳转

loopz、loope(为零时跳转,相等时跳转)
loopnz、loopne(不为零时跳转,不相等时跳转)
下面是一个例子,通过条件跳转实现短路求值

下面是来实现switch,有点难
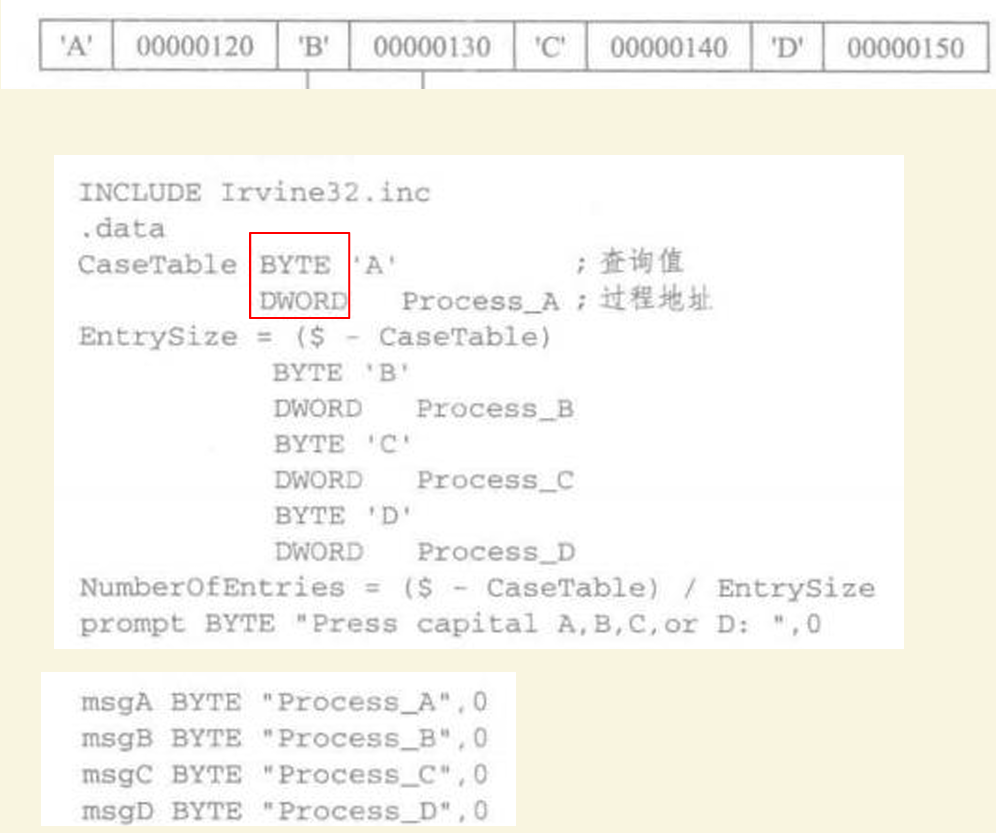
7.整数运算
7.1 移位
下面先看所有的移位指令

SHL左移
就是向左移动一位,注意CF标志,如果移位的那一位是1的话,会置位CF标志位
SHR右移
就是向右移动一位,注意CF标志,是把最低位移给CF,最高位补零
SAL指令(算术左移)
和逻辑移位的区别在于带了符号(+、-)
SAR指令(算术右移)
和逻辑移位的区别在于带了符号(+、-),SHR前面补0,遇到负数右移的情况下前面补1
循环移位

循环进位移位

双精度移位
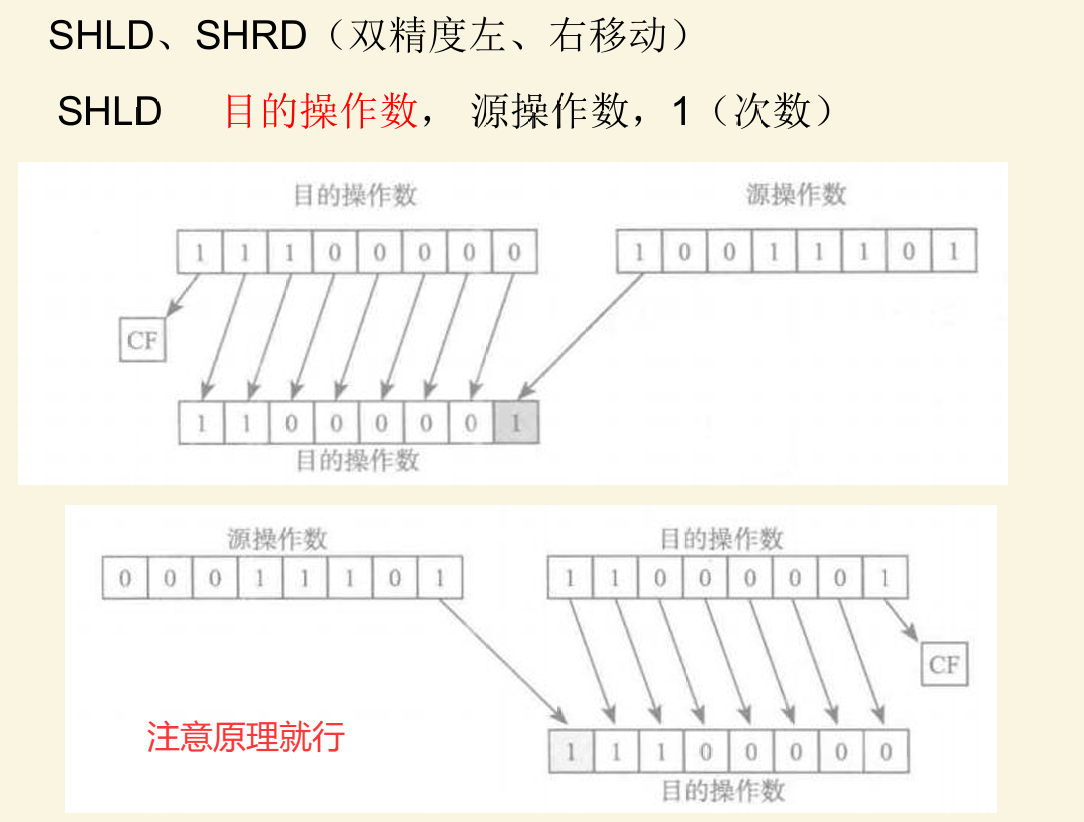
注意右移:目的操作数的最高位,来源于源操作数的低位
小结:
各种移位的差别就是,移走的,和移来的,怎么处理,算术位移要补符号位,循环位移的移来的位,来源于移走的位,双精度位移,移来的位来源于另一个
7.2 乘法
先看下面的表
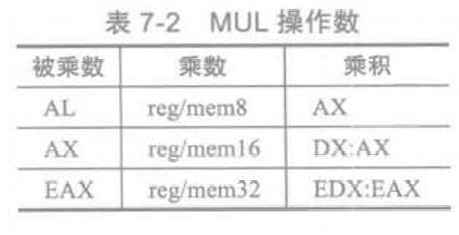
1、乘积是被乘数与乘数大小的2倍。(为了结果不溢出)
2、要用到CF(进位)标志寄存器(乘积的高半部分不为零,则会把CF设置为1.)
3、乘数和被乘数的大小一样
有符号乘法
使用的是imul,和MUL指令的区别为:如果乘积的高半部分不是其低半部分符 号的扩展,则CF=1、OF=1
7.3 除法
DIV(无符号)

iDIV指令(有符号数除法)
执行该指令前必须进行符号扩展(把数的高位复制所有高位中)
CBW、CWD、CDQ 是有符号拓展指令,中间那位是数据类型
7.4 拓展加减法
ADC是拓展加法,SBB是拓展减法
ADC指令执行逻辑: 目的操作数 = 目的操作数 + 源操作数 + 进位标志位的值
SBB指令执行逻辑: 目的操作数 =目的操作数 - 源操作数 - 进位标志位的值
asm
mov edx,100h
mov eax,8000 0000h
sub eax, 9000 0000h
sbb edx,0 ;最后得到0x100 - 1(来源于进位) = 0x0ff8.堆栈
8.1 寄存器传参数与堆栈传参数
寄存器传递参数: 将参数值复制到寄存器
寄存器传递参数的缺点:可能无法恢复寄存器,使代码混乱,让系统无法正常运行。
载体是寄存器

堆栈传参数:
把参数压入堆栈,这里有值传递和引用传递,引用传递本质上是offset后得到的地址
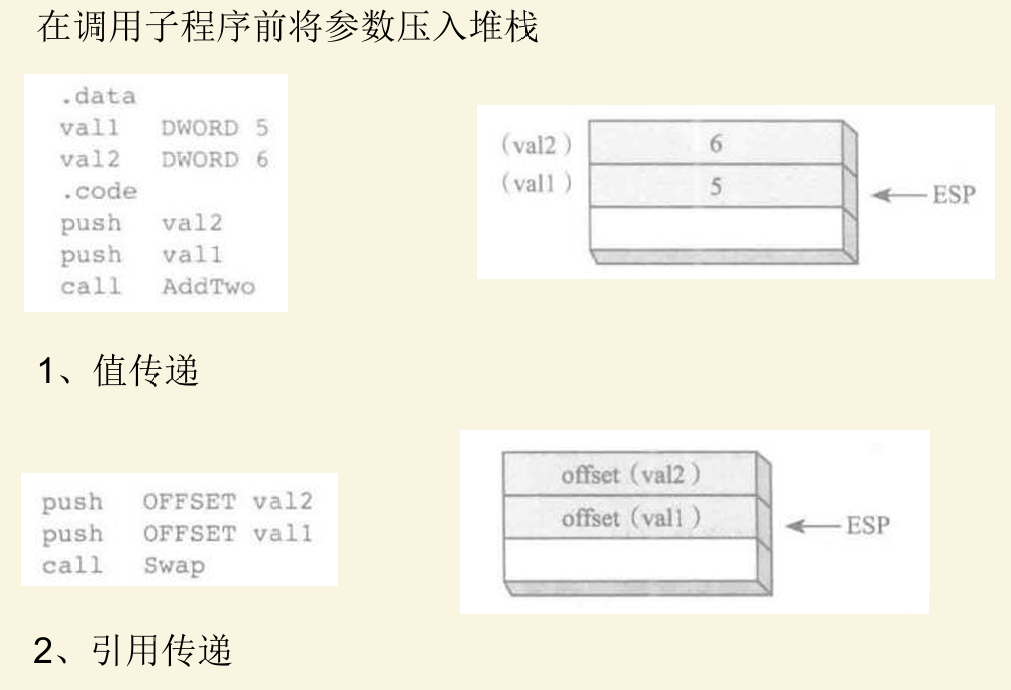
堆栈传递离不开堆栈帧,创建如下
1)被传递的实际参数。如果有,压入堆栈。
2)当子程序被调用时,使该子程序的返回值压入堆栈。
3)子程序开始执行时,EBP(扩展帧指针寄存器)压入堆栈。
4)设置EBP等于ESP。(基址的设立)。
5)如果有局部变量,修改ESP,(在堆栈中为变量留空间)。
6)如果有另外的寄存器要保存,压入堆栈
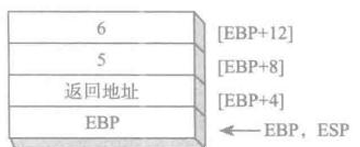
核心最后是通过基址来完成访问
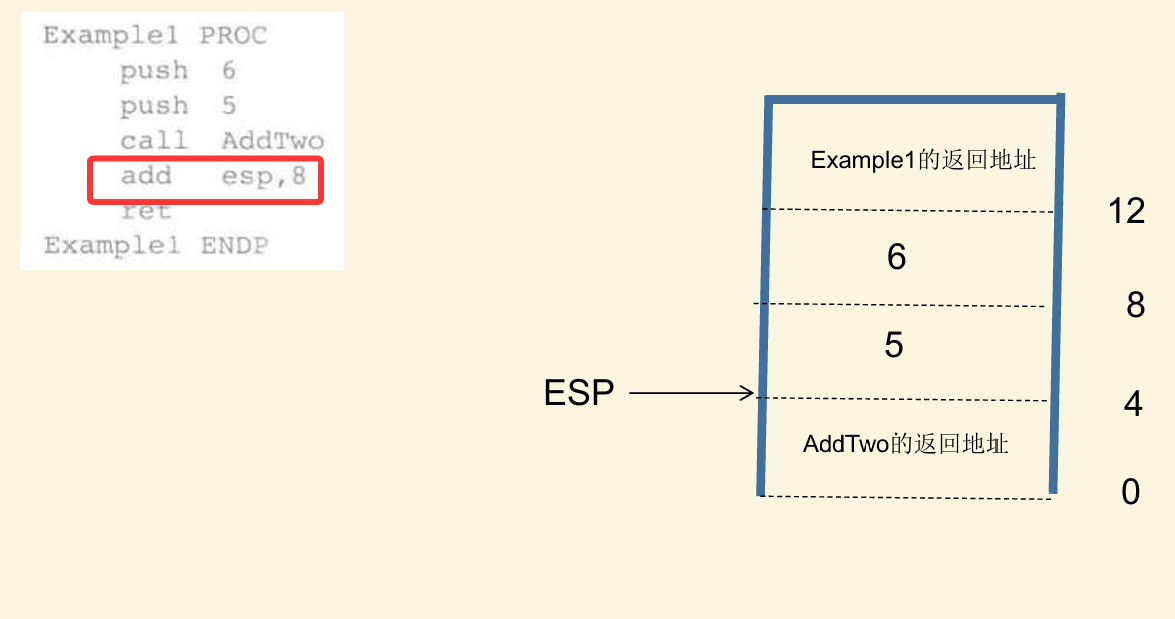
注意:堆栈清除
如下图,当ret时,会弹出下条要执行指令的地址,如果不进行清除,就会去找地址为5的下一条指令

解决办法:
如下,把esp指针更新位置就行,这样就能返回正确的下一条指令
当然下面这样也是一样的

对于5,6点,也是在后面存储到堆栈里,更改esp指针
如下图,最后也会进行回收,保证不影响esp
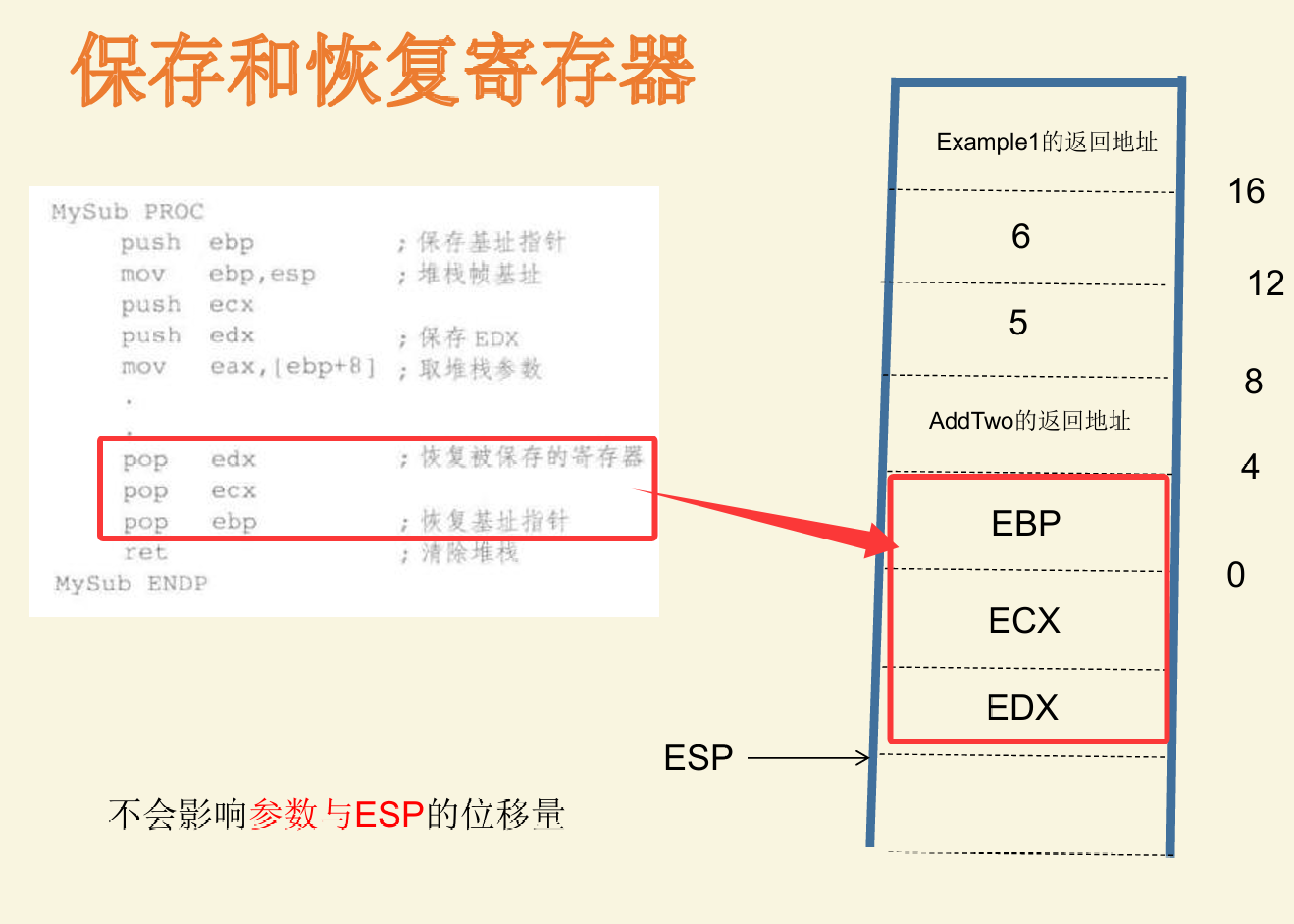
如下,添加了变量,也可以复原esp指针

9.字符串和数组
下面是字符串的指令:
-
MOVSB、MOVSW和MOVSD:移动字符串数据指 令,将由ESI寻址的内存地址处的数据复制到EDI寻址的 内存地址处
-
CMPSB、CMPSW和CMPSD:比较字符串,比较由 ESI和EDI寻址的两个内存地址处的值
-
SCASB、SCASW和SCASD:扫描字符串,比较累加 器与EDI寻址的内存地址处的内容
-
STOSB、STOSW和STOSD:存储字符串数据,存储 累加值的内容至EDI寻址的内存地址处 LODSB、LODSW和LODSD:字符串装入累加器,加 载ESI寻址的内存地址处的数据至累加器
下面是指令特点:
- 源串指针为ESI,目的串指针为EDI
- 串长度在ECX中
- 指针与计数器自动修改
- 加减由DF确定:CLD、STD
- 修改长度 B=BYTE、W=WORD、D=DWORD
- 重复前缀有REP、REPE/REPZ、 REPNE/REPNZ
- 允许源和目的操作数都是存储单元
操作流程:
执行串操作之前,应先设置:
(1)源串首地址(末地址)→ ESI
(2)目的串首地址(末地址)→ EDI
(3)串长度 → ECX
(4)建立方向标志(CLD或STD)
执行串操作指令后,ESI和EDI已经越界或 超过目标
MOVSB、MOVSW和MOVSD
- B:BYTE、W:WORD、D:DWORD
- 三条指令会自动修改ESI和EDI的值
- 自动设置增加还是减小的数值的多少
- 连续的字符串移动指令使用方法
- 设置ESI和EDI的方向:增加或者减少
- CLD:清除方向标值位,也就是正向,ESI和EDI增加
- STD:设置方向标值位,也就是反向,ESI和EDI减小
- 设置ECX寄存器内容为要复制的字符串的数量
- 设置源字符串偏移ESI和目的字符串偏移EDI两个寄存器
- 使用重复前缀指令rep设置重复执行的指令(三条指令之一)
- rep的使用类似于loop,会按照ECX的值重复执行指令
- 设置ESI和EDI的方向:增加或者减少



STOSB、STOSW和STOSD
-
分别将AL、AX或EAX中的值存储到EDI寻址的目标内存单元中
-
特别适用于用填充字符串或者数组
LODSB、LODSW和LODSD
- 从ESI寻址的内存单元中将对应尺寸的内容复制到AL、 AX或EAX寄存器中