进入项目的目录:
新建一个目录,目录名为job_info:因为要暂停爬虫,所以需要保存许多中间状态,这个目录就是为了保存状态
打开命令行cmder
进入虚拟环境
因为要暂停爬虫,所以需要保存许多中间状态
以lagou爬虫为例:
第一点:不同的spider是不能共用同一个spider的,所以要在job_info 下新建一个文件夹,名为001
第二点:不同的spider在run的时候也不能共用同一个目录
cmd
scrapy crawl cnblogs -s JOBDIR=job_info/001执行命令后启动指定爬虫,且记录状态到指定目录
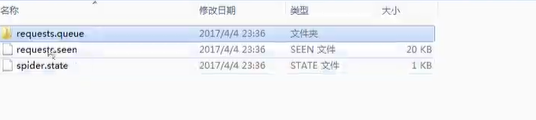
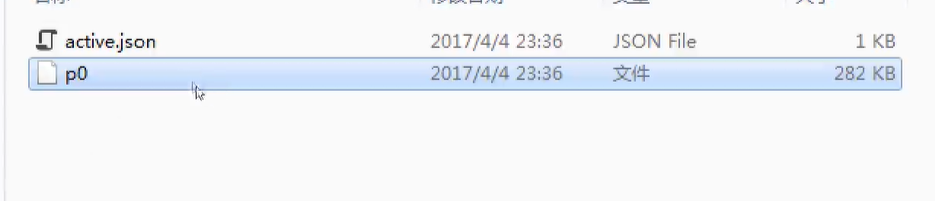
爬虫现已运行,能按键盘上的Ctrl+C停止爬虫,停止后再看看记录文件夹,会多出3个文件,其中的requests.queue文件夹里的p0文件就是url记录文件,有该文件就表示还有没有完成的url,在全部url完成后会自动删除该文件
再重新执行命令:
cmder
scrapy crawl cnblogs -s JOBDIR=zant/001 时爬虫会按照p0文件从停止的地方开始再次爬取。