Python爬虫(Scrapy框架)
1、Scrapy介绍
Scrapy是一个为了爬取网站数据,提取结构化数据二编写的应用框架,其可以应用在包括数据挖掘挖掘,信息处理或存储历史数据等一系列的程序中。
2、安装Scrapy
在pycharm的控制台中需要手动安装scrapy库来进行操作即可。
pip install scrapy3、Scrapy框架讲解
1)Scrapy项目的搭建及运行
一:项目结构的介绍
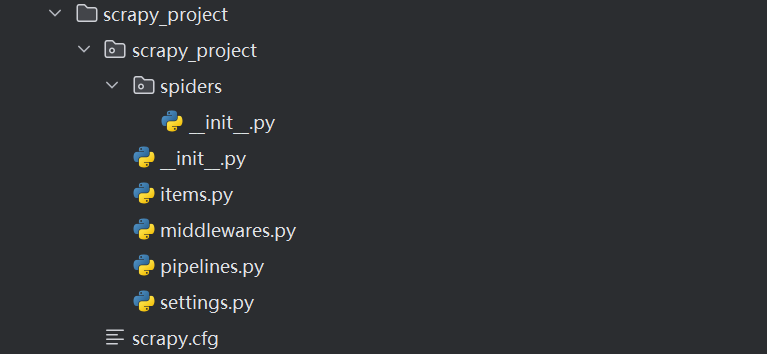
项目名称
项目名称
spiders文件夹(存储的是【爬虫文件】)
_init_.py
自定义的爬虫文件 【核心功能文件】
_init_.py
items.py 定义数据结构文件=> 爬取数据包含哪些
middlewares.py 中间件 => 一般用于 代理机制
pipelines.py 管道 => 用于处理下载的数据
settings.py 配置文件 => 含有 robots协议,User-Agent定义等二:爬虫文件的结构介绍
python
import scrapy
class BaiduSpider(scrapy.Spider):
name = "baidu" # 运行爬虫文件时使用的名字【爬虫名称】
allowed_domains = ["www.baidu.com"] # 爬虫允许访问的域名:若非此url之下的域名会被过滤掉
start_urls = ["https://www.baidu.com"] # 爬虫的起始url地址
# 解析数据的回调函数,其中response = requests.get()
def parse(self, response):
# 编写内容三:项目初始化(1)👍
1、创建爬虫项目
注意:项目名字不允许使用数字开头,也不能包含中文
shell# 在终端进行操作:scrapy startproject 项目名称 scrapy startproject scrapy_project2、创建爬虫文件
步骤一:要在spriders文件夹中去创建爬虫文件
shell# cd 项目名称/项目名称/spiders cd scrapy_project/scrapy_project/spiders步骤二:创建爬虫文件
sh# scrapy genspider 爬虫文件名称 要爬取的网页 scrapy genspider baidu https://www.baidu.combaidu.py爬虫文件内容:
pythonimport scrapy class BaiduSpider(scrapy.Spider): # 爬虫名称:运行爬虫时使用的值 name = "baidu" # 允许访问的域名 allowed_domains = ["www.baidu.com"] # 起始的url地址 start_urls = ["https://www.baidu.com"] # response = requests.get() def parse(self, response): submit = response.xpath('//input[@type="submit"]/@value') print(submit) print(submit.extract()) # 返回所有符合条件的元素集合3、运行爬虫代码
步骤一:将settings中的robots协议注释掉
步骤二:在控制台输入命令进行爬取
shell# scrapy crawl 爬虫名称 scrapy crawl baidu结果展示:
[<Selector query='//input[@type="submit"]/@value' data='百度一下'>] ['百度一下']
四:response基本方法
python
1、content1 = response.text # 获取的是网页源码(utf-8的字符串数据)
2、content2 = response.body # 获取的是网页源码(二进制的数据)
3、content3 = response.xpath【推荐】 # 可直接xpath方法来解析,返回一个selector列表对象
content3.extract():返回所有匹配XPath表达式的元素集合,若找到则返回列表,若未找到则返回空列表。
content3.extract_first():返回第一个匹配Xpath的结果。若找到则返回该元素;若未找到,则返回None。爬虫文件car.py:爬取"汽车之家"中某一页的汽车的名字
python
import scrapy
class CarSpider(scrapy.Spider):
name = "car"
allowed_domains = ["www.autohome.com.cn"]
start_urls = ["https://www.autohome.com.cn/price"]
def parse(self, response):
name_list = response.xpath('//div[@class="tw-mt-1 tw-px-4"]//a/text()')
for i in range(len(name_list)):
name = name_list[i].extract() # 返回所有符合条件的元素集合
print(name)
----------------------------------------------
秦L
小米SU7
奥迪A6L
享界S9
秦PLUS
Model Y
帕萨特
迈腾
奔驰E级
理想L6
奥迪Q5L
凯美瑞
宋PLUS新能源
宋L DM-i
问界M7
奥迪A4L
途观L
朗逸
奔驰C级
问界M9
宝马3系
RAV4荣放
汉
林肯Z
宝马5系
海鸥
奔驰GLC
雅阁
宝马X5
航海家
----------------------------------------------2)Scrapy架构组成
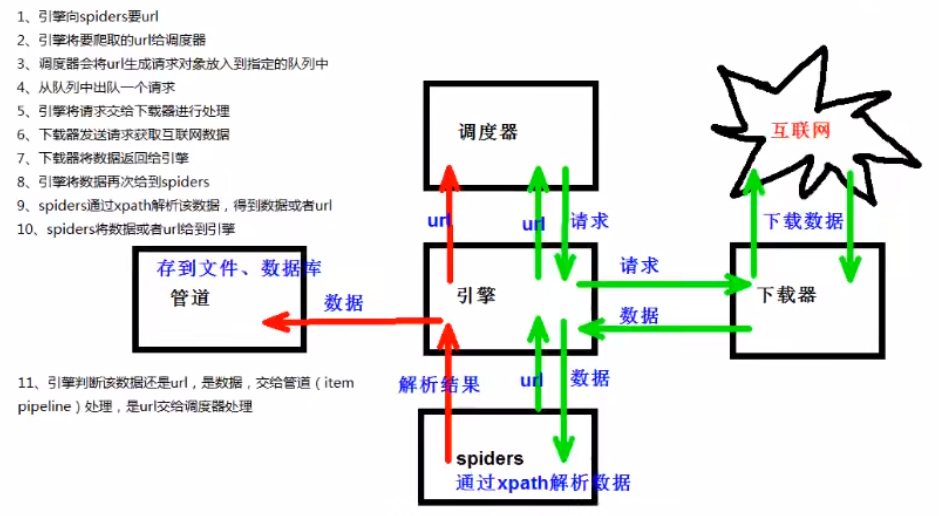
(1)引擎:自动运行,无需关注,会自动组织所有的请求对象,分发给下载器
(2)下载器:从引擎处获取请求对象后,请求数据
(3)spiders:spiders类定义了如何爬取某个(或某些)网站和分析网页。
(4)调度器:有自己的调度规则,无需关注
(5)管道(item pipeline):最终处理数据的管道,会预留接口供我们处理数据
补充:当Item在Spiders中被收集后,它将会被传递给Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。每个Item Pipeline组件是实现了简单方法的python类。它们接受到Item并通过它执行一些行为,同时也决定此Item是否通过pipeline,或者被丢弃而不再进行处理。
以下为item pipeline典型应用:
1. 清理HTML数据
2. 验证爬取的数据(检验item包含某些字段)
3. 查重(并丢弃)
4. 将爬取结构存储到数据库中3)Scrapy工作原理图
4、Scrapy Shell【了解】
- 什么是scrapy shell?
scrapy终端,是一个交互终端,供您在未启动spider的情况下尝试及调试您的爬取代码。其本意是用来测试提取数据的代码,不过您可以将其作为正常的python终端,在上面测任何的python代码。该终端是用来测试Xpath或css表达式,查看他们的工作方式及从爬取的网页中提取的数据。在编写您的spider时,一旦熟悉了scrapy终端后,您会发现其在开发和调试spider时发挥的最大作用。
- 安装ipython
在pycharm的控制台中需要手动安装ipython库来进行操作即可。
shpip install ipython安装ipython后,scrapy终端将使用ipython代替python终端,ipython终端与其他相比更为强大,提供智能的自动补全,高亮输出及其他特性。
- scrapy shell应用
首先在终端输入命令,如以下命令所示:
shell# scrapy shell url域名 scrapy shell https://www.baidu.com会自动跳转到ipython页面,如下图:
在以上命令的返回内容中有response,可以直接使用这个response
如下所示:可以调试返回的结果:



- response相关语法:
python(1)response对象: response.body # 返回网页源码(二进制) response.text # 返回网页源码(utf-8) response.url # 返回url域名 response.status # 返回状态,正常状态为200 (2)response解析: response.xpath() 【推荐】 使用xpath路径查询特定元素,返回一个selector列表对象 response.css() 【不推荐使用,此处就不过多介绍】
5、管道封装(2)👍
必备知识
熟悉yield
基本含义:带有yield的函数不再是一个普通函数,而是一个生成器generator,可用于迭代。yield是一个类似return的关键字,迭代一次遇到yield时就返回yield后面(右边)的值。重点是:下一次迭代时,从上一次迭代器遇到的yield后面的代码(下一行)开始执行。
简单理解:yield就是return返回一个值,并且记住这个返回的位置,下次迭代就从这个位置后(下一行)开始。yield充当一个传递功能的一个工具。
基本使用:
python
from scrapy_dangdang.items import ScrapyDangdangItem
# 构造item对象
book = ScrapyDangdangItem(src=src,name=name,price=price)
# 获取一个book就将book交给pipelines
yield book1)单管道使用
此处,我们会以小型的完整案例的形式来讲单管道的使用!
案例需求:爬取"当当"网页中的某页的产品名称,价格,图片等信息,并保存在本地【单页数据】。
步骤一:项目初始化
1、创建爬虫项目
注意:项目名字不允许使用数字开头,也不能包含中文
shell# 在终端进行操作:scrapy startproject 项目名称 scrapy startproject scrapy_project2、创建爬虫文件
步骤一:要在spriders文件夹中去创建爬虫文件
shell# cd 项目名称/项目名称/spiders cd scrapy_project/scrapy_project/spiders步骤二:创建爬虫文件
sh# scrapy genspider 爬虫文件名称 要爬取的网页 # 中国古典小说网址:http://category.dangdang.com/cp01.03.32.00.00.00.html scrapy genspider dang http://category.dangdang.com/cp01.03.32.00.00.00.html
步骤二:定义item文件
通过定义item文件来指定需要获取的信息内容(需要下载哪些内容)。
python
import scrapy
class ScrapyProjectItem(scrapy.Item):
# 图片
src = scrapy.Field()
# 名字
name = scrapy.Field()
# 价格
price = scrapy.Field()步骤三:爬取图片、名字、价格
-
图片爬取:
拿到图片的xpath:
//ul[@class="bigimg"]//a//img/@src。由于图片具有懒加载的特性,因此对于在处于懒加载中的图片应当获取的是data-original属性。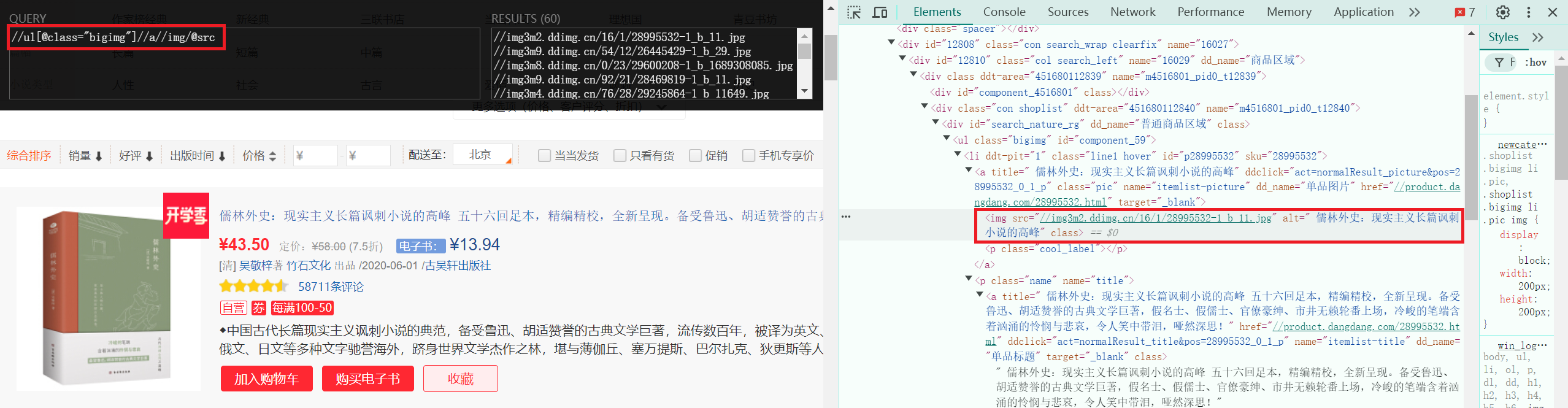
-
名字爬取:
拿到标题的xpath:
//ul[@class="bigimg"]//p[@class="name"]/a/@title。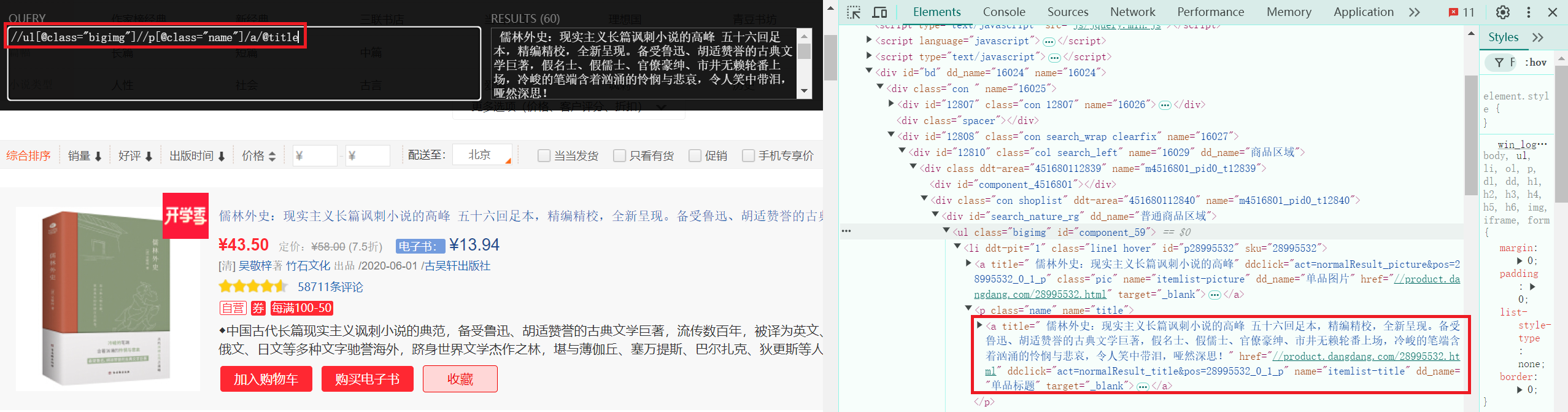
-
价格爬取:
拿到价格的xpath:
//ul[@class="bigimg"]//p[@class="price"]//span[@class="search_now_price"]/text()。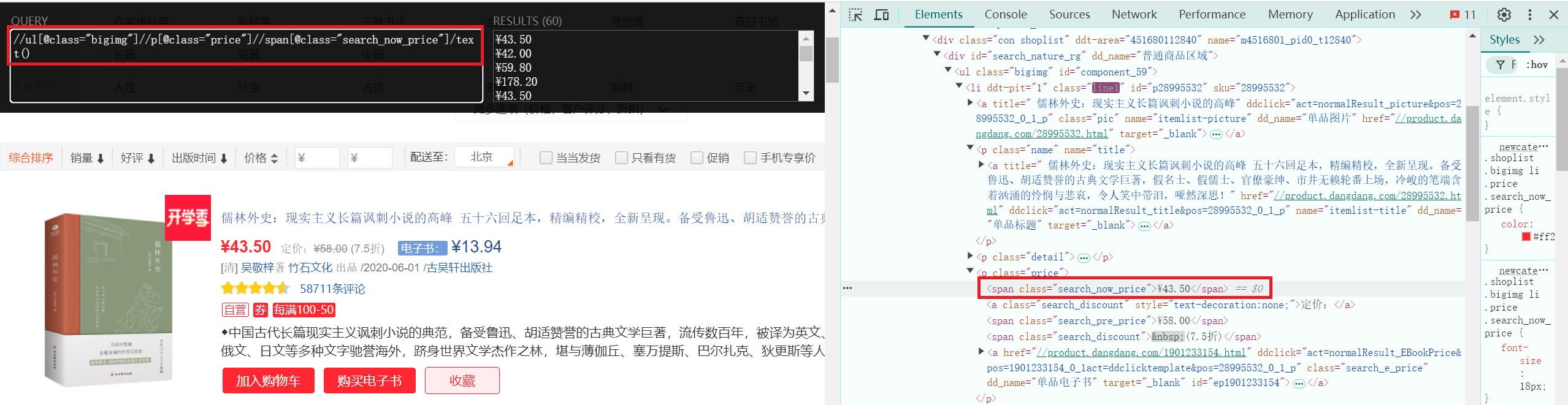
爬虫文件(dang.py):
python
import scrapy
from scrapy_project.items import ScrapyProjectItem
class DangSpider(scrapy.Spider):
name = "dang"
allowed_domains = ["category.dangdang.com"]
start_urls = ["http://category.dangdang.com/cp01.03.32.00.00.00.html"]
def parse(self, response):
# src = //ul[@class="bigimg"]/li//a//img/@src
# name = //ul[@class="bigimg"]/li//p[@class="name"]/a/@title
# price = //ul[@class="bigimg"]/li//span[@class="search_now_price"]/text()
front_path = response.xpath('//ul[@class="bigimg"]/li')
for path in front_path:
src = path.xpath('.//a//img/@data-original').extract_first()
# 第一张图片和其他的图片的标签的属性是不一样的
# 第一张图片的src是可以使用的 其他的图片的地址是data-original
if src:
src=src
else:
src = path.xpath('.//a//img/@src').extract_first()
name = path.xpath('.//p[@class="name"]/a/@title').extract_first()
price = path.xpath('.//span[@class="search_now_price"]/text()').extract_first()
# yield封装:构造item对象
book = ScrapyProjectItem(src=src,name=name,price=price)
# 获取item对象,并将item对象交给pipelines处理(下载等操作)
yield book步骤四:管道文件处理(单管道)
-
在settings.py中开启pipeline:
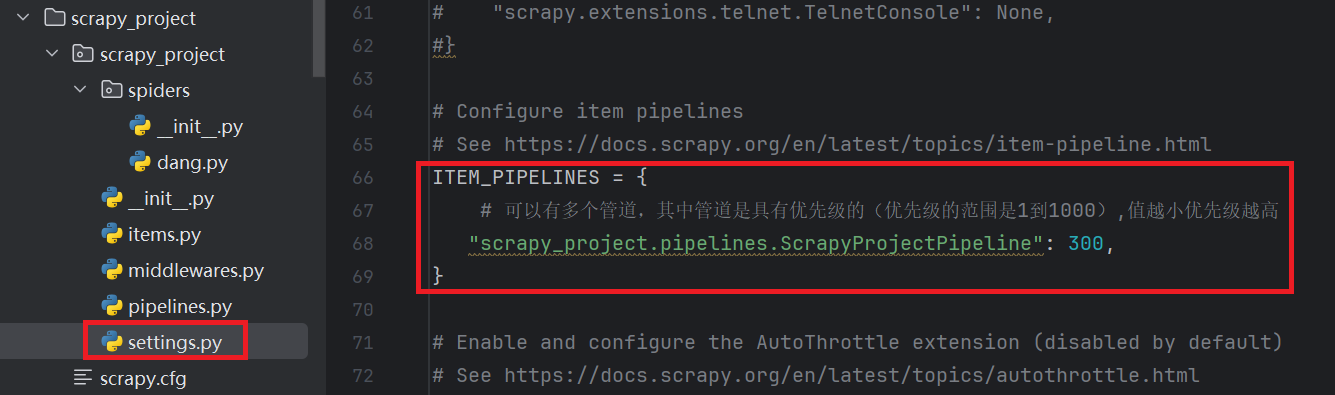
-
python
# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html # useful for handling different item types with a single interface from itemadapter import ItemAdapter class ScrapyProjectPipeline: # 爬虫文件执行之前(初始化操作):打开文件、数据库连接、或者初始化某些资源。 def open_spider(self, spider): self.fp = open('book.json', 'w', encoding='utf-8') # 爬虫文件执行过程:处理每一个被Spider爬取并返回的Item(数据清洗、验证或存储等操作) def process_item(self, item, spider): self.fp.write(str(item)) self.fp.write('\n') return item # 在爬虫文件执行完之后: 文件资源被释放 def close_spider(self, spider): self.fp.close()
步骤五:执行,查看写入的json文件
将settings中的robots协议注释掉:

在控制台输入命令进行爬取:
python
# scrapy crawl 爬虫名称
scrapy crawl dang2)多管道使用
在单管道中只能干一件事情,因此我们可以使用多管道的机制来同时完成多个事情,如:一条管道完成json数据下载,另一条管道完成图片的下载,另一个管道完成视频下载等等。
基本步骤:
以上述的小型的完整案例(爬取"当当"网页中的某页产品名称,价格,图片等信息,并保存在本地)进行一定修改,使得其成为一个多管道的小型案例【单页数据】。
(1)pipelines.py定义管道类
python
from itemadapter import ItemAdapter
import urllib.request
# 下载基本信息的管道(名字,图片地址,价格)
class ScrapyProjectPipeline:
# 爬虫文件执行之前(初始化操作):打开文件、数据库连接、或者初始化某些资源。
def open_spider(self, spider):
self.fp = open('book.json', 'w', encoding='utf-8')
# 爬虫文件执行过程:处理每一个被Spider爬取并返回的Item(数据清洗、验证或存储等操作)
def process_item(self, item, spider):
self.fp.write(str(item))
self.fp.write('\n')
return item
# 在爬虫文件执行完之后: 文件资源被释放
def close_spider(self, spider):
self.fp.close()
# 下载图片的管道【定义管道类】
class DownloadPicPiepline:
def process_item(self, item, spider):
# 获取对象值:item.get()
url = 'http:' + item.get('src')
# 注意:尽量写完整路径
filename = 'D:/phase/third_phase/books/' + item.get('name') + '.png'
# 下载图片
urllib.request.urlretrieve(url=url,filename=filename)
return item(2)settings.py开启管道
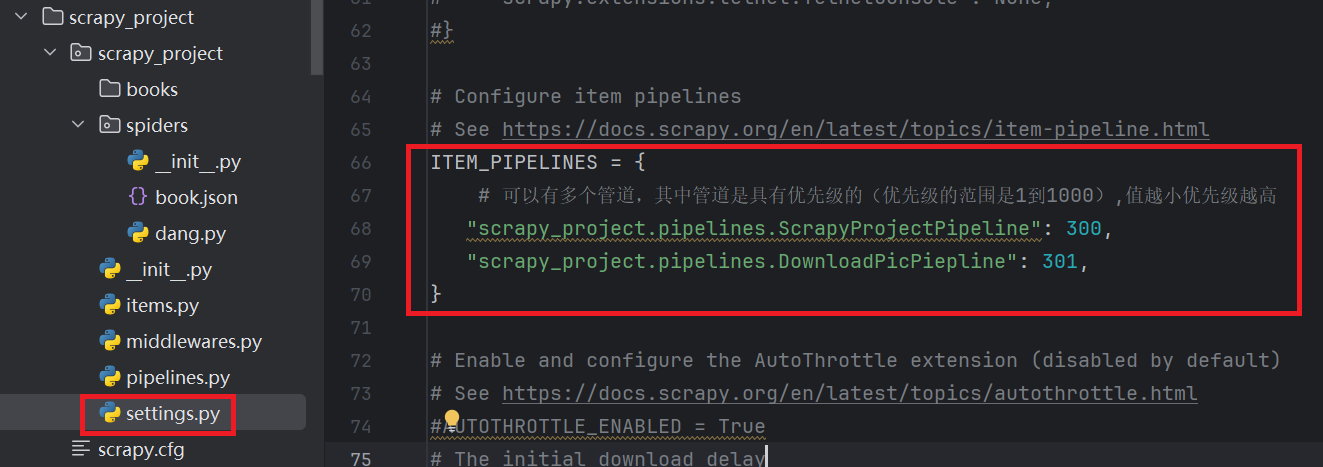
恭喜,完成改造!
6、不同(多)页数据获取(3)👍
1)必备知识
熟悉scrapy.Request(GET请求)
含义:scrapy.Request相当于scrpay的get请求
基本格式 :scrapy.Request(url[,callback=None[,meta='GET']])
scrapy.Request常用参数讲解:
url:传入的url
callback:指定传入的url交给哪个解析函数去处理
meta:现在不同的解析函数中传递数据,meta默认会携带部分信息,比如下载延迟,请求深度(页码,详情页...)等2)案例讲解
此处我们会以一个完整的小型案例来讲解不同(多)页数据获取。
案例需求:爬取电影天堂不同页面的数据
1、效果
- 获取电影天堂,【列表页面】的电影名:
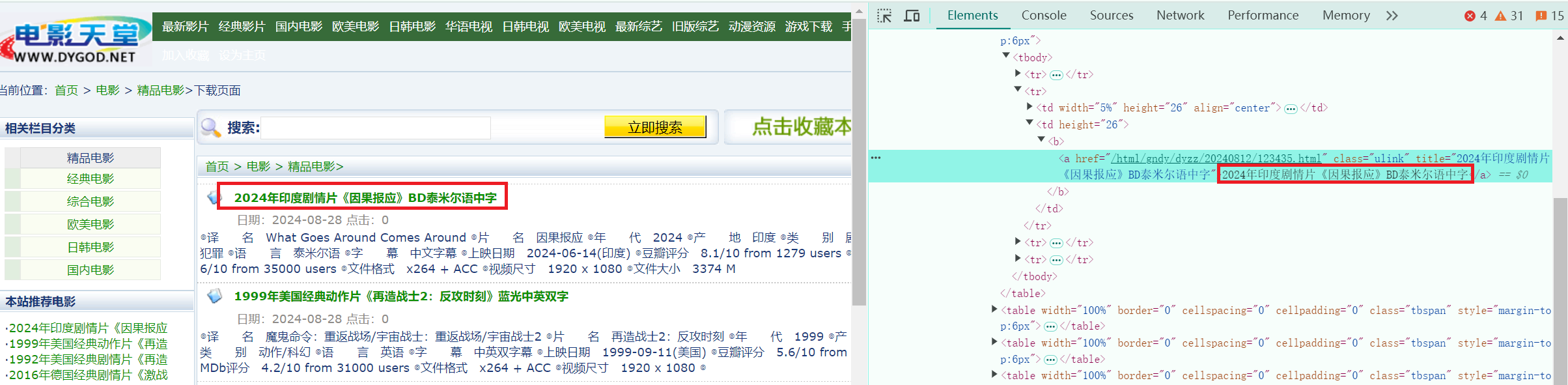
- 然后点击进入电影【详情页面】,再从第二页获取到详情中的图片:
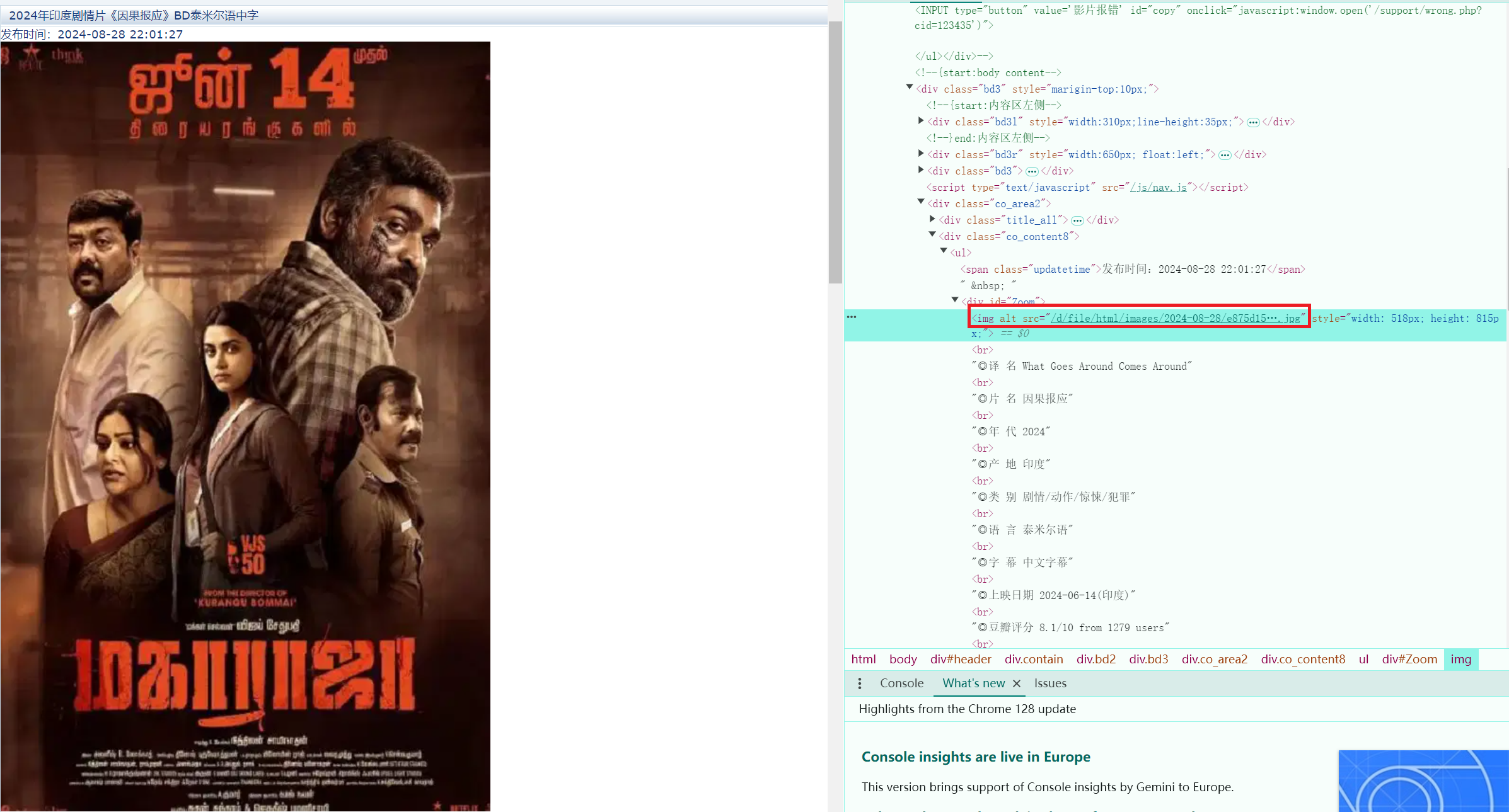
2、具体代码
步骤一:项目初始化
1、创建爬虫项目
注意:项目名字不允许使用数字开头,也不能包含中文
shell# 在终端进行操作:scrapy startproject 项目名称 scrapy startproject scrapy_project2、创建爬虫文件
步骤一:要在spriders文件夹中去创建爬虫文件
shell# cd 项目名称/项目名称/spiders cd scrapy_project/scrapy_project/spiders步骤二:创建爬虫文件
sh# scrapy genspider 爬虫文件名称 要爬取的网页 # 电影天堂:https://www.dygod.net/html/gndy/china/index.html scrapy genspider mv https://www.dygod.net/html/gndy/china/index.html
步骤二:定义item文件
通过定义item文件来指定需要获取的信息内容(需要下载哪些内容)。
python
import scrapy
class ScrapyProjectItem(scrapy.Item):
# 图片
src = scrapy.Field()
# 名字
name = scrapy.Field()步骤三:爬取列表页,详情页数据
爬虫文件(mv.py)【核心代码】:
python
import scrapy
from scrapy_project.items import ScrapyProjectItem
class MvSpider(scrapy.Spider):
name = "mv"
allowed_domains = ["www.dygod.net"]
start_urls = ["https://www.dygod.net/html/gndy/china/index.html"]
# 列表页
def parse(self, response):
# 要列表页中的名字 和 详情页中的图片
a_list = response.xpath('//div[@class="co_content8"]//td[2]//a[2]')
for a in a_list:
# 获取列表页的name 和 要点击的链接
name = a.xpath('./text()').extract_first()
href = a.xpath('./@href').extract_first()
# 详情页的地址是
url = 'https://www.dygod.net' + href
# 对详情页的链接发起访问 并将name参数传入,交给parse_second进行处理
yield scrapy.Request(url=url, callback=self.parse_second, meta={'name': name})
# 详情页
def parse_second(self, response):
src = response.xpath('//div[@id="Zoom"]//img/@src').extract_first()
# 接受到请求的那个meta参数的值
name = response.meta['name']
# 将数据封装至item并传给pipeline进行最终处理
movie = ScrapyProjectItem(src=src, name=name)
yield movie步骤四:管道文件处理
-
在settings.py中开启pipeline:
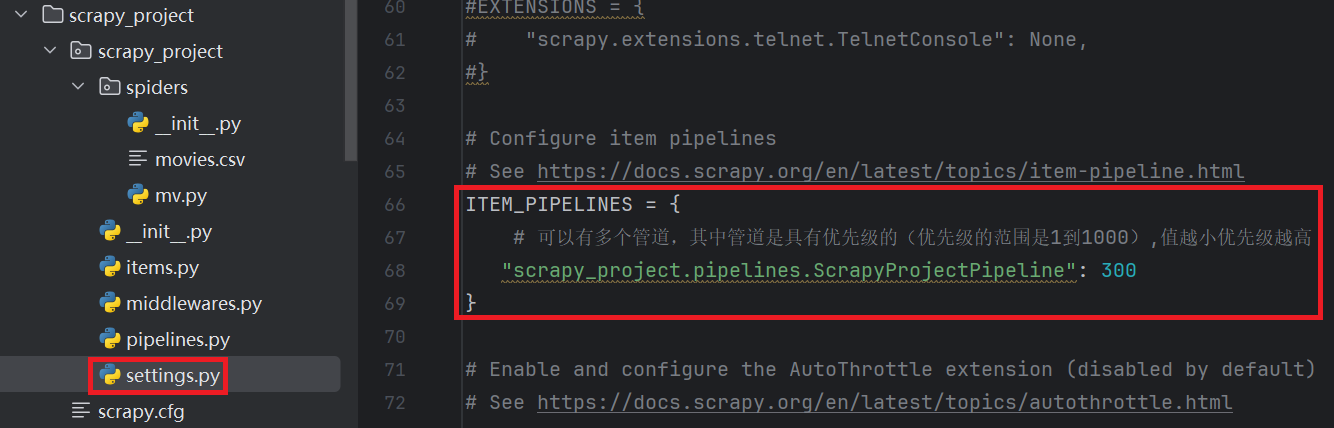
-
python
# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html # useful for handling different item types with a single interface from itemadapter import ItemAdapter class ScrapyProjectPipeline: # 爬虫文件执行之前(初始化操作):打开文件、数据库连接、或者初始化某些资源。 def open_spider(self, spider): self.fp = open('movies.json', 'w', encoding='utf-8') # 爬虫文件执行过程:处理每一个被Spider爬取并返回的Item(数据清洗、验证或存储等操作) def process_item(self, item, spider): self.fp.write(str(item)) self.fp.write('\n') return item # 在爬虫文件执行完之后: 文件资源被释放 def close_spider(self, spider): self.fp.close()
步骤五:执行,查看写入的csv文件
将settings中的robots协议注释掉:
在控制台输入命令进行爬取:
python
# scrapy crawl 爬虫名称
scrapy crawl mv7、日志信息和日志等级
(1)日志级别:
CRITICAL: 严重错误
ERROR: 一般错误
WARNING: 警告
INFO: 一般信息
DEBUG: 调试信息
默认的日志级别是DEBUG,出现了DEBUG后DEBUG以上级别日志,这些日志信息都会别打印出来
(2)settings.py文件设置:
默认的日志级别是DEBUG,会显示上面的所有信息。
修改级别配置:
LOG_FILE: 将屏幕显示的信息全部记录在文件中,屏幕不显示,注意【文件后缀名必须为.log】 👍
LOG_LEVEL: 设置文件显示的级别,即:显示哪些,不显示哪些。在settings.py文件中手动添加:
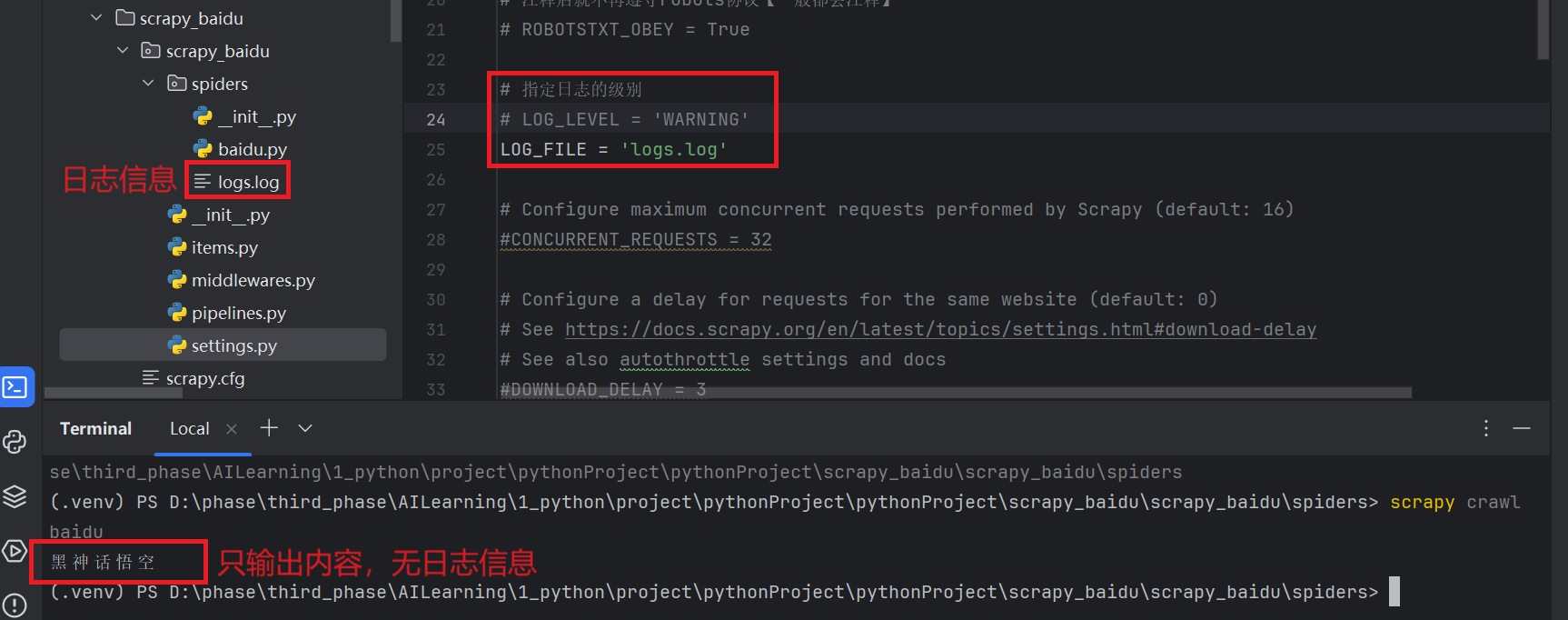
8、Scrapy的post请求
1)熟悉scrapy.FormRequest(POST请求)
scrapy.FormRequest(url=url,formdata=data,callback=self.parse_second,headers=headers) 参数讲解: url:要发送的post地址 formdata:post所携带的数据,这是一个字典 callback:回调函数 headers:定制请求头信息
2)案例讲解
此处以百度翻译为例讲述POST请求。首先,在Network中寻找完整的POST发送信息(eye)的文件,如下图所示:
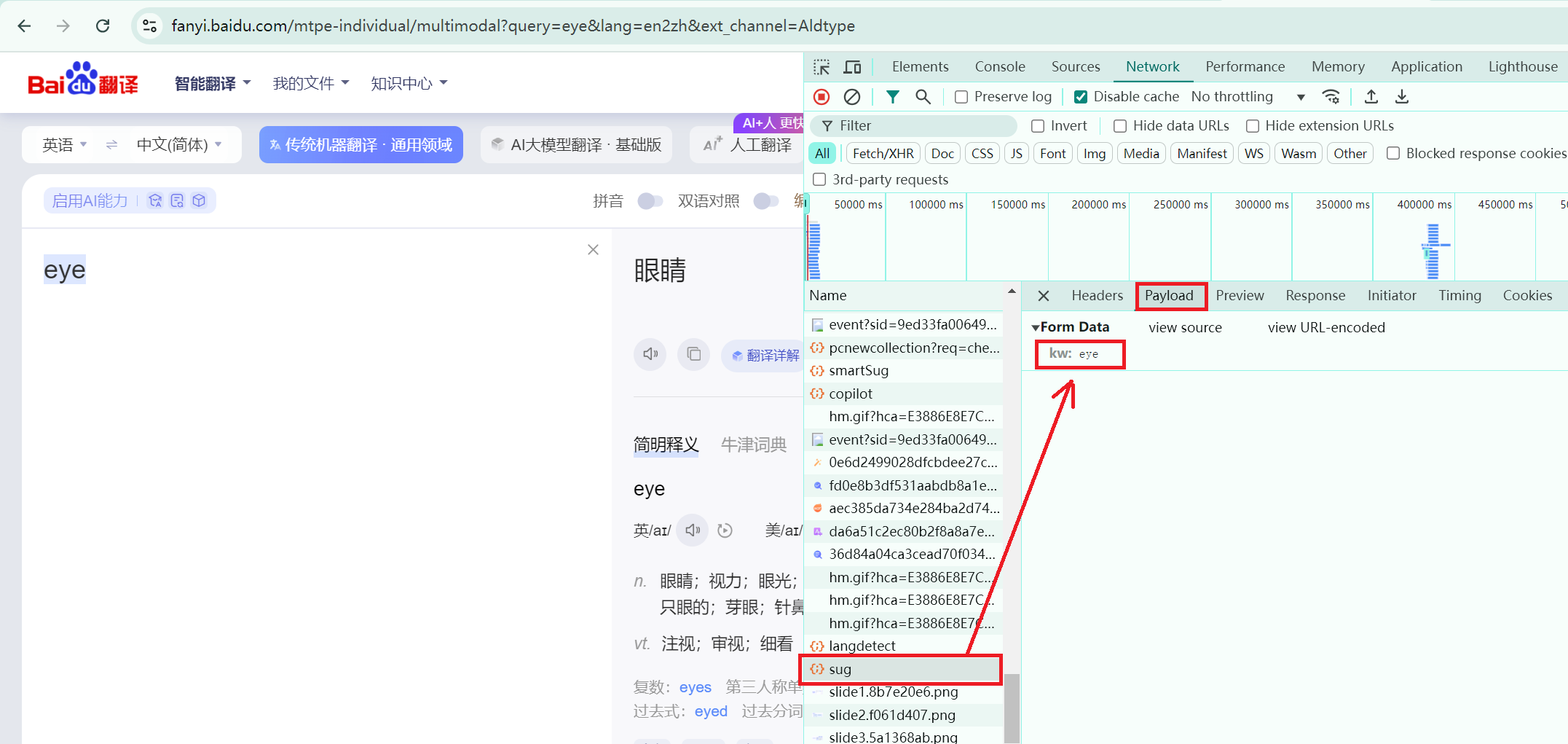
然后,对Headers中的url路径进行爬取操作:
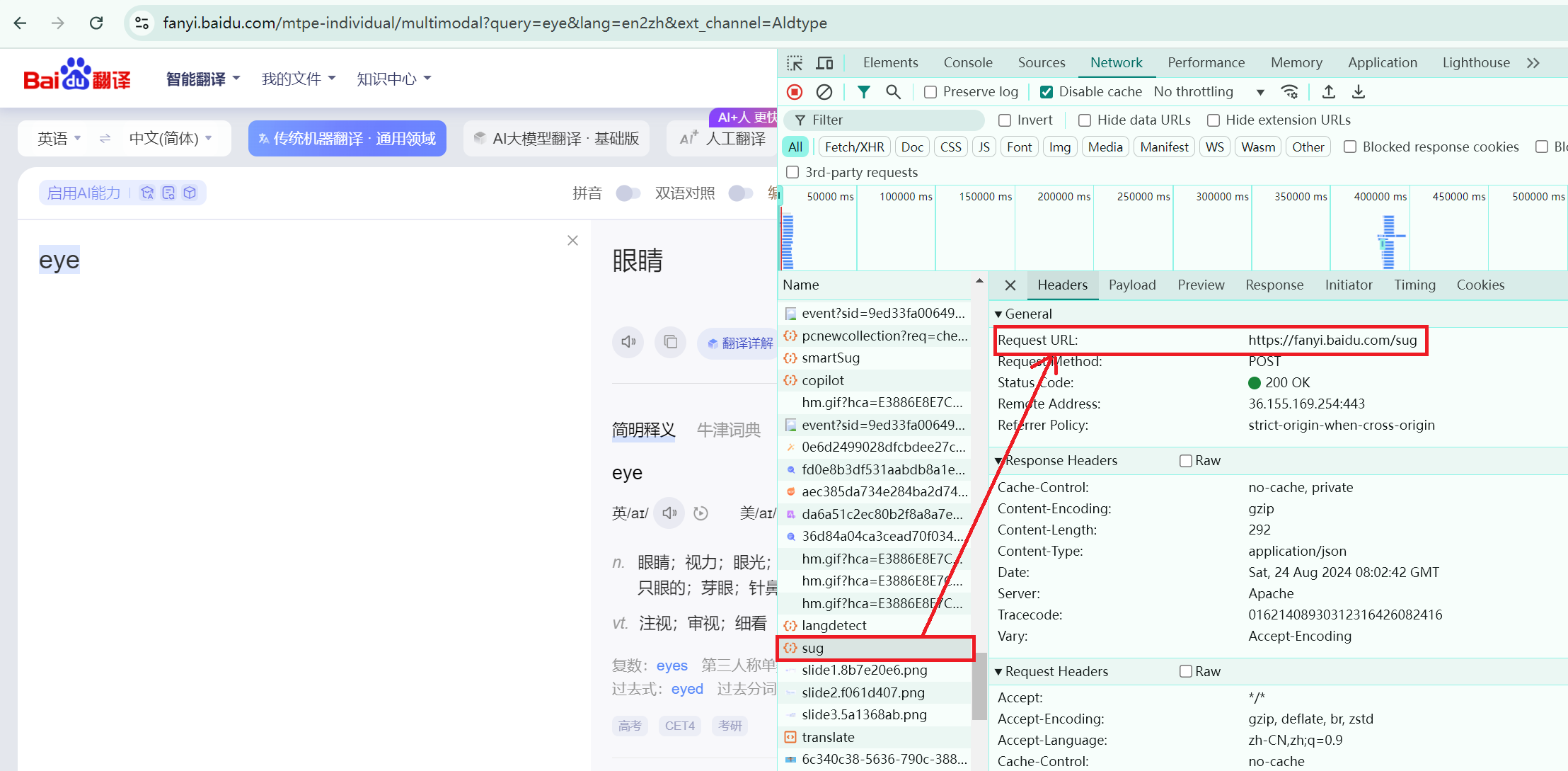
主要的代码部分【爬虫文件fanyi.py】:发送带有请求参数的POST请求
python
import json
import scrapy
class FanyiSpider(scrapy.Spider):
name = "fanyi"
allowed_domains = ["fanyi.baidu.com"]
# post请求【固定写法】
def start_requests(self):
url = 'https://fanyi.baidu.com/sug'
# 参数
data = {
'kw': 'eye'
}
# scrapy中post请求用FormRequest表示
yield scrapy.FormRequest(url=url,formdata=data,callback=self.parse_second)
# 接受post请求返回的数据并进行处理
def parse_second(self,response):
# 获取网页内容
content = response.text
obj = json.loads(content)
print(obj)