目录
1. 系统概述
1.1 调度器定位
本调度器是基于 Redis 的分布式爬虫任务调度系统,核心职责包括:
- 任务存储:将待抓取 URL(种子)持久化存入 Redis
- 任务去重:按 UID 去重,避免同一任务重复入队与抓取
- 优先级调度:多级优先队列 + 加权随机,高优先级任务更易被调度
- 流量削峰:通过 refresh 将大批量任务在时间轴上打散,避免瞬时压力
- 公平调度:按 cgroup/tag 分组,保证不同来源、类型任务都有调度机会
1.2 为什么需要调度器
大规模爬虫场景下的典型问题与调度器方案对照如下:
|-------|-------------------|--------------------|
| 挑战 | 没有调度器的问题 | 调度器的解决方案 |
| 任务量巨大 | 内存无法容纳所有任务 | Redis 持久化存储,支持海量任务 |
| 任务重复 | 同一 URL 被重复抓取,浪费资源 | 基于 UID 的去重机制 |
| 优先级需求 | 紧急任务无法优先处理 | 多级优先队列,权重调度 |
| 瞬时流量 | 批量任务同时触发,压垮目标网站 | refresh 参数实现流量削峰 |
| 多爬虫协作 | 多个爬虫争抢任务,效率低下 | cgroup 分组,任务隔离 |
| 故障恢复 | 爬虫崩溃后任务丢失 | Redis 持久化 + 请求缓存 |
1.3 系统组成
系统由三个核心模块构成,职责清晰、协作完成「入队 → 调度 → 出队」全链路:
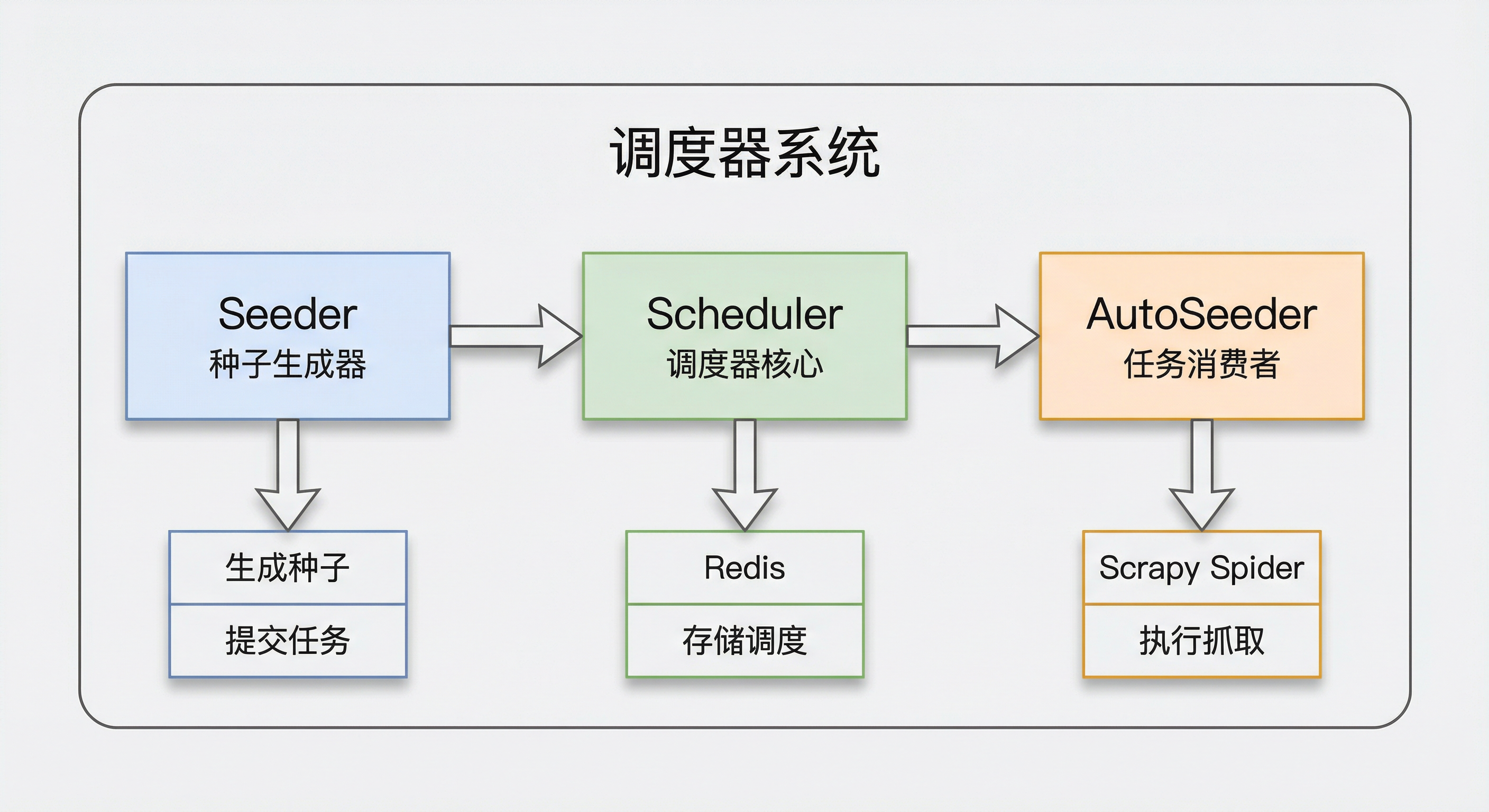
模块职责说明:
|----------------|----------------------------------|
| 模块 | 核心职责 |
| Seeder | 接收外部请求,生成标准化的种子数据,批量提交到调度器 |
| Scheduler | 调度器核心,负责种子存储、去重、优先级排序、任务分发 |
| AutoSeeder | Scrapy 扩展,监听爬虫空闲状态,从调度器获取任务并驱动爬虫 |
2. 整体架构
2.1 架构分层图
2.2 数据流向详解
整个系统的数据流向如下图所示(包含入队和出队流程):
3. 核心设计原理
3.1 两级优先队列架构
调度器采用两级优先队列作为核心数据结构:第一级为 CGroup 队列(按优先级选组),第二级为 Url 队列(按组存具体任务 uid)。
为何需要两级?
单一全局队列会带来:
- 某 cgroup 任务过多时,其他组被饿死
- 无法按组做公平调度
- 单队列过大导致插入与查询性能下降
两级设计通过「先选组、再取组内任务」解决上述问题:
两级队列的工作机制:
- 入队时:
-
- 种子被添加到对应的 URL 队列(第二级)
- 同时更新 CGroup 队列(第一级)的分数,使其等于该组最早任务的调度时间
- 出队时:
-
- 先从 CGroup 队列(第一级)获取分数最小(最早)的 cgroup
- 再从该 cgroup 的 URL 队列(第二级)获取具体的任务
- 出队后更新 CGroup 队列的分数
3.2 基于时间戳的调度机制
Redis Sorted Set 以时间戳为 score,实现延时调度与流量削峰:
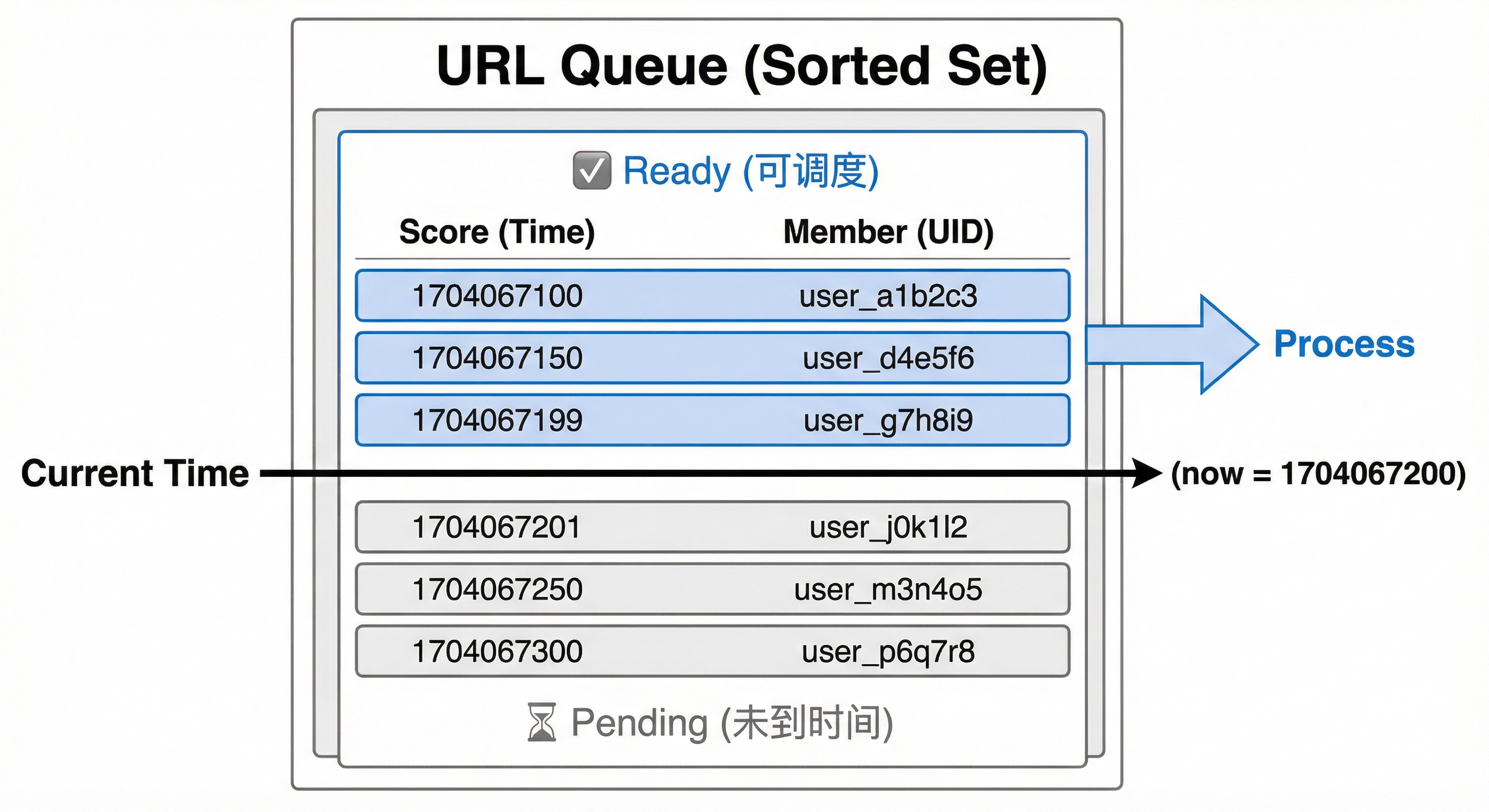
调度时机判断(伪代码):
从 Url 队列中弹出所有「score ≤ 当前时间戳」的成员;
最多弹出 max_batch_size 个;
返回这些成员对应的 uid 列表。这种设计的优势:
- 延时调度:任务可以设定在未来某个时间点执行
- 流量削峰:批量任务分散到不同时间点
- 高效查询:Redis Sorted Set 的 ZRANGEBYSCORE 是 O(log(N)+M) 复杂度
3.3 refresh 参数与流量削峰(重要)
refresh 的含义 :不是「定时刷新」,而是流量削峰------把瞬时大批量任务的调度时间摊开到一段时间内。
典型场景:若 10000 个 YouTube 视频详情页同时入队且同时被调度,会对目标站造成瞬时压力:
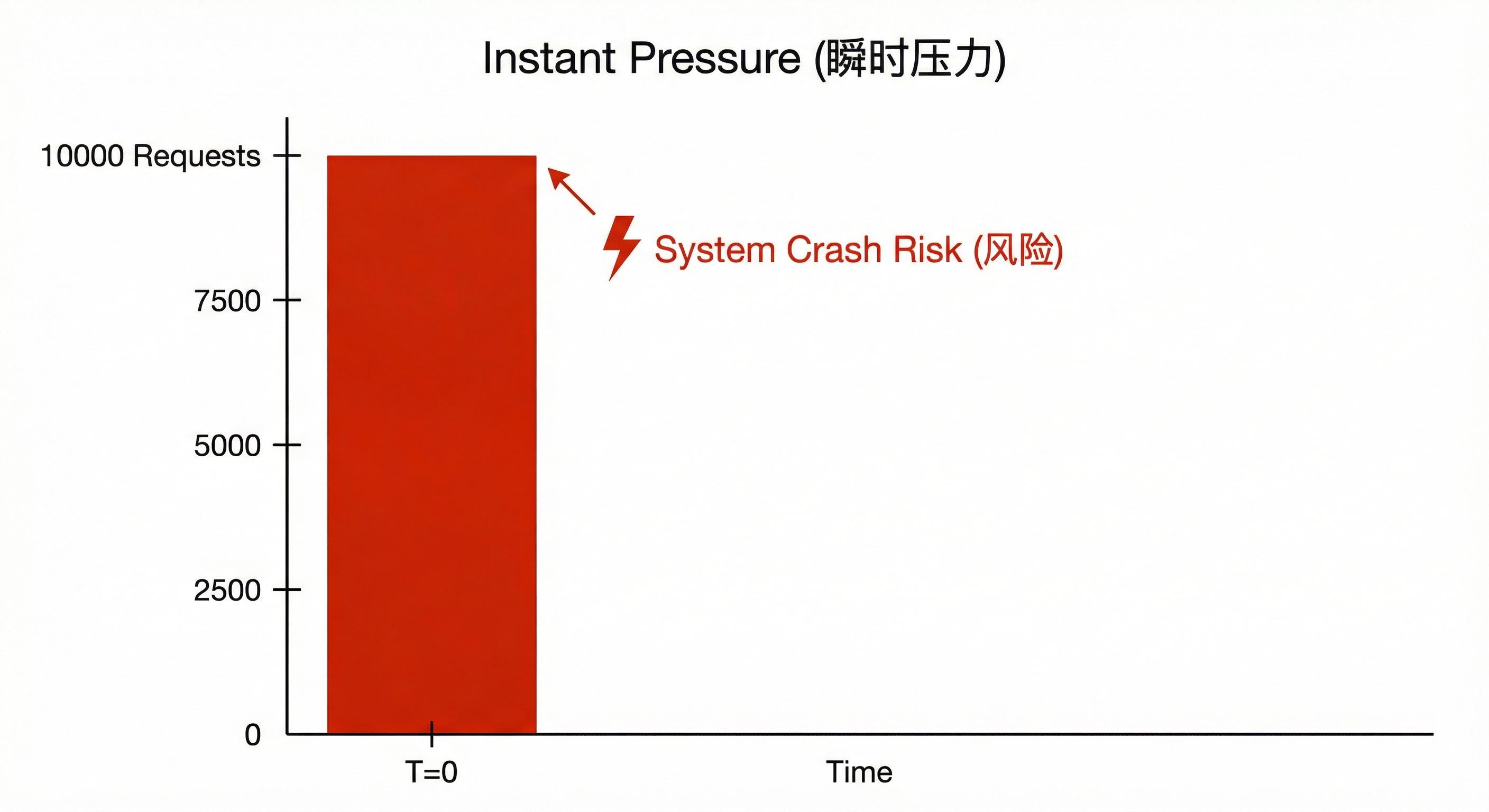
refresh 的解决方案:
设置 refresh = 3600(1 小时)时,入队时将调度时间打散到未来一小时内完成(伪代码):
score ← 当前时间 + seed.refresh × [0, 1) 的随机数;
若 refresh = 3600,则 score 落在 [now, now + 3600] 内均匀分布。打散效果示意:
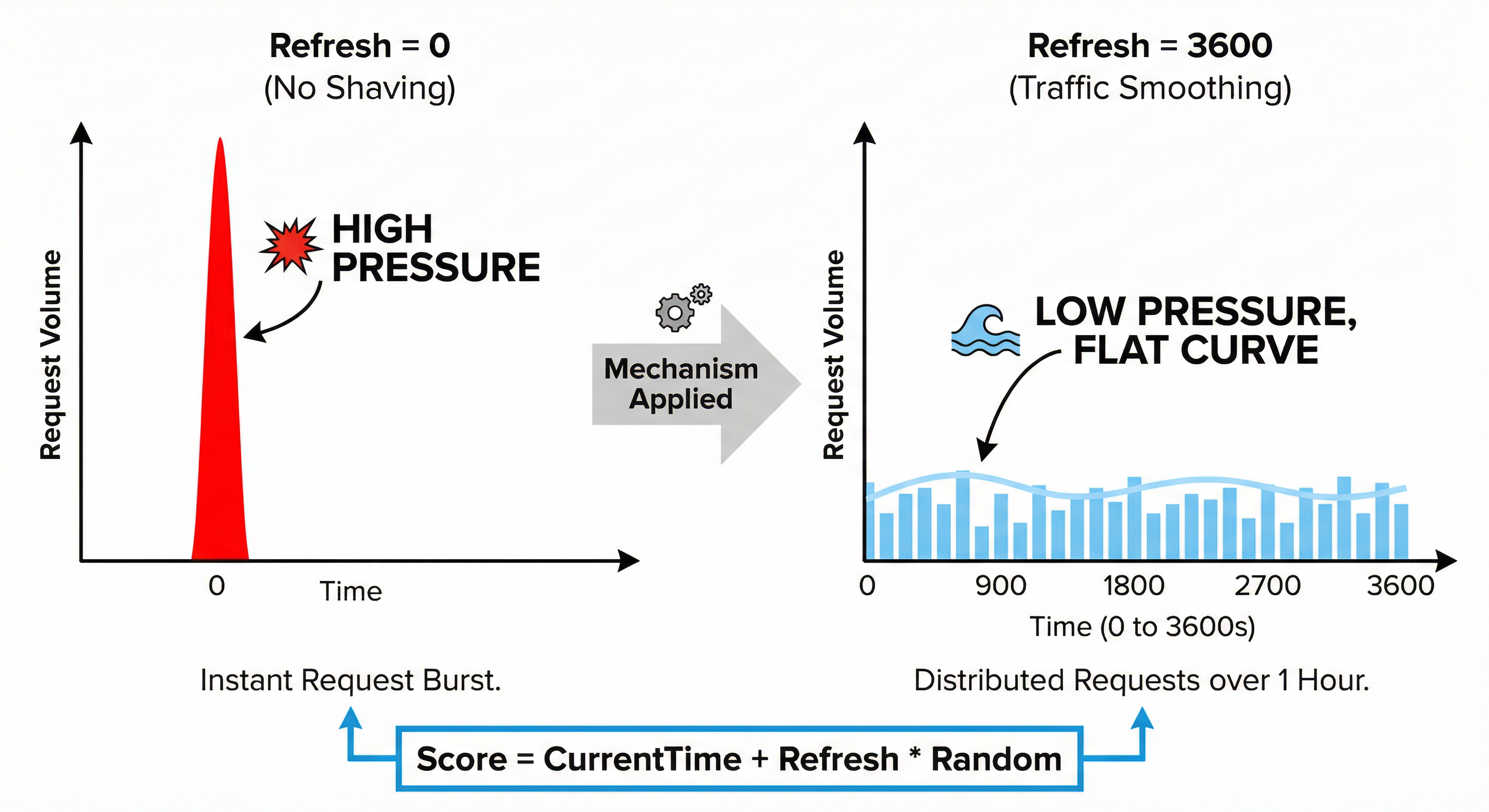
数值示例(refresh = 3600,当前时间 00:00:00):
|-----|-----------------|----------|
| 任务 | score 计算 | 调度时刻 |
| 任务1 | now + 3600×0.15 | 00:09:00 |
| 任务2 | now + 3600×0.42 | 00:25:12 |
| 任务3 | now + 3600×0.67 | 00:40:12 |
| 任务4 | now + 3600×0.23 | 00:13:48 |
| 任务5 | now + 3600×0.91 | 00:54:36 |
按 score 排序后,调度顺序为:任务1 → 任务4 → 任务2 → 任务3 → 任务5,从而在 1 小时内均匀分散。
refresh 参数设置建议:
|------|------------|-------------|----------------|
| 场景 | 任务量 | refresh 建议值 | 说明 |
| 单个任务 | 1 | 0 | 立即执行,无需削峰 |
| 小批量 | < 100 | 0 或 60 | 影响不大,可立即或分散1分钟 |
| 中批量 | 100-1000 | 300-600 | 分散5-10分钟 |
| 大批量 | 1000-10000 | 1800-3600 | 分散30分钟到1小时 |
| 超大批量 | > 10000 | 3600-7200 | 分散1-2小时 |
与 count 参数的配合:
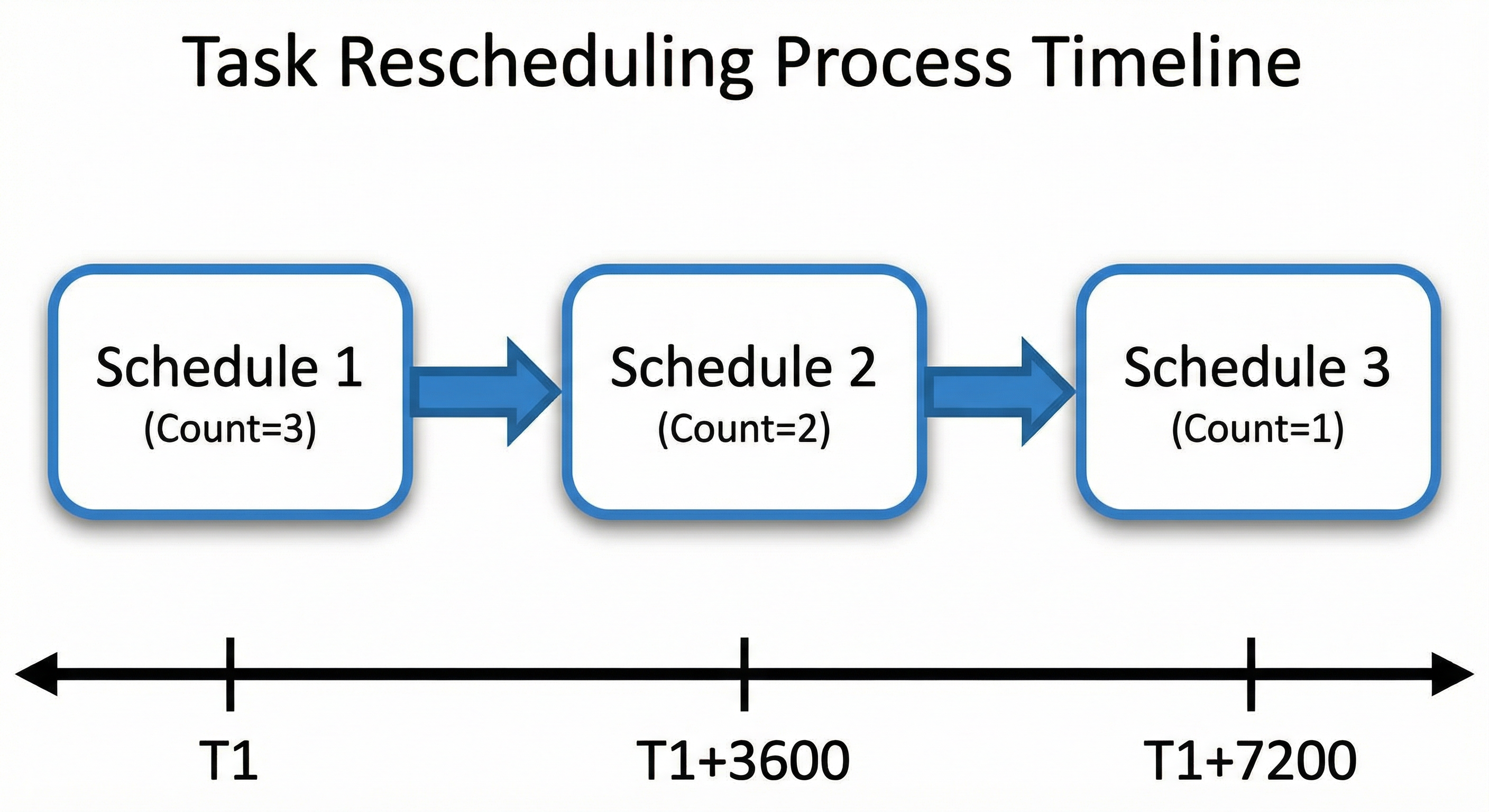
当 count > 1 时,任务会被重复调度。每次出队后,在 get_batch 的 finally 中更新该 uid 的 score 与 count(伪代码):
函数 更新Url分数(uid):
将 Url Info 中该 uid 的 count 减 1;
读取该 uid 的 url, score, refresh, count;
若 url 为空 或 refresh ≤ 0 或 count ≤ 0:
返回 空(表示不再调度,后续从队列与 Hash 中删除);
若 原 score > 当前时间:
new_score ← 原 score; // 保持未到点的任务时间不变
否则若 原 score + refresh ≥ 当前时间:
new_score ← 原 score + refresh;
否则:
new_score ← 当前时间 - 2; // 已过期很久,放到当前附近
将 Url Info 中该 uid 的 score 更新为 new_score;
返回 new_score(用于回写 Url 队列,或返回空表示删除)。重复调度示意:
3.4 优先级权重调度算法
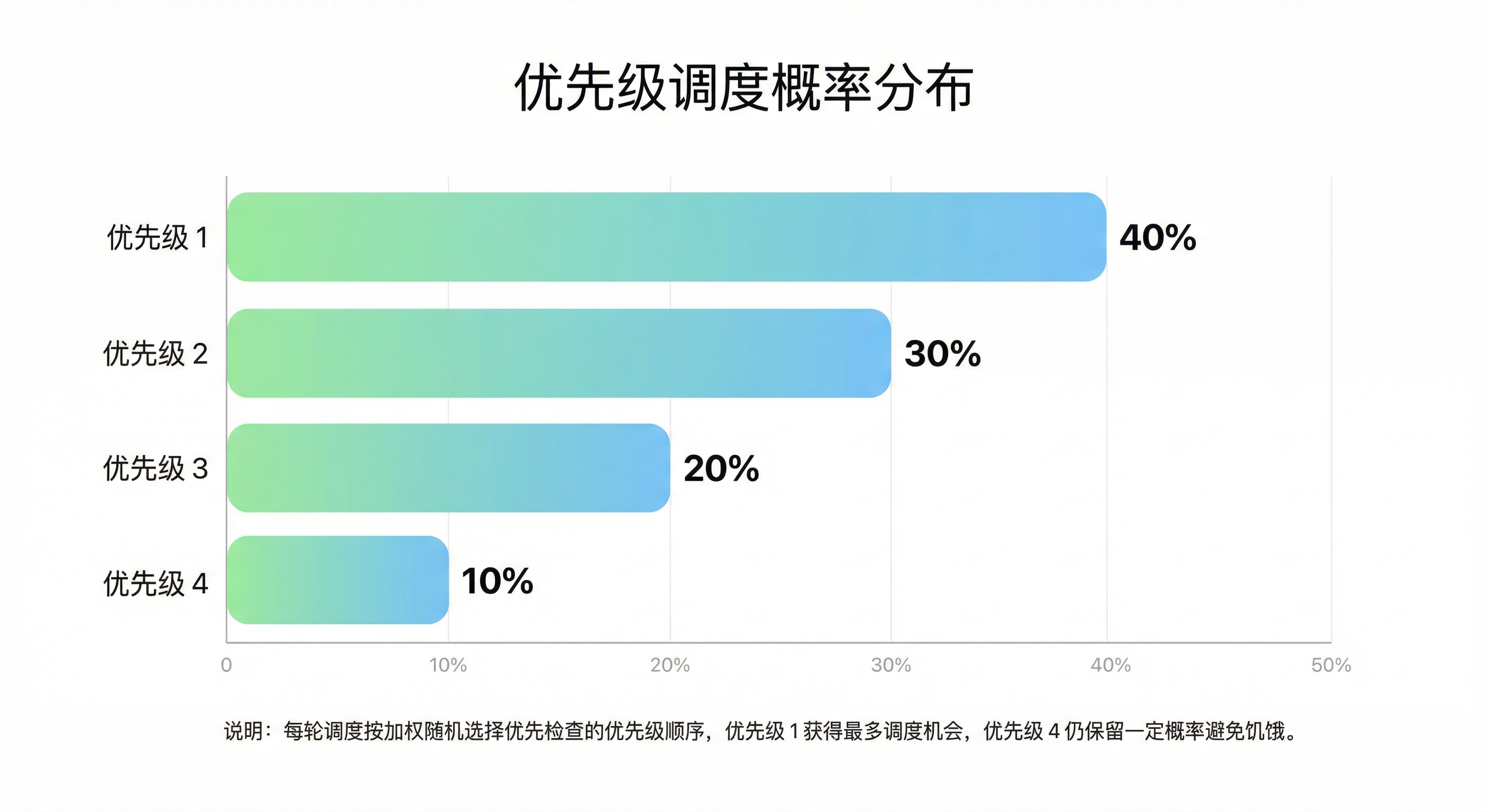
系统支持 5 个优先级(0--4),使用加权随机决定本轮优先检查的优先级顺序(伪代码):
函数 获取优先级顺序():
生成 [0, 100) 的随机数 rand;
若 rand < 40: 返回 [1, 2, 3, 4]; // 40% 概率优先处理优先级 1
若 rand < 70: 返回 [2, 3, 4, 1]; // 30% 概率优先处理优先级 2
若 rand < 90: 返回 [3, 4, 1, 2]; // 20% 概率优先处理优先级 3
否则: 返回 [4, 1, 2, 3]。 // 10% 概率优先处理优先级 4权重分布:
设计要点:
- 高优先级获得更多机会(如优先级 1 约 40% 概率被优先轮询)
- 低优先级不会饿死(优先级 4 仍有约 10% 概率)
- 软优先级:按概率轮询,而非严格 0→1→2→3→4 顺序
- 长期看各优先级都能获得合理调度比例
为何不用严格优先级? 严格按 0→1→2→3→4 会导致低优先级饥饿:高优先级任务持续涌入时,低优先级永远得不到执行。加权随机在保证高优优势的同时,为低优任务保留机会。
3.5 URL 去重机制
为避免同一 URL 被重复入队与抓取,系统按 UID 去重。UID 的生成规则(伪代码):
函数 生成UID(task, url):
若 task ≠ "default": 返回 对 (task, url) 的稳定哈希(如 get_sid);
否则: 返回 对 url 的稳定哈希。去重逻辑:
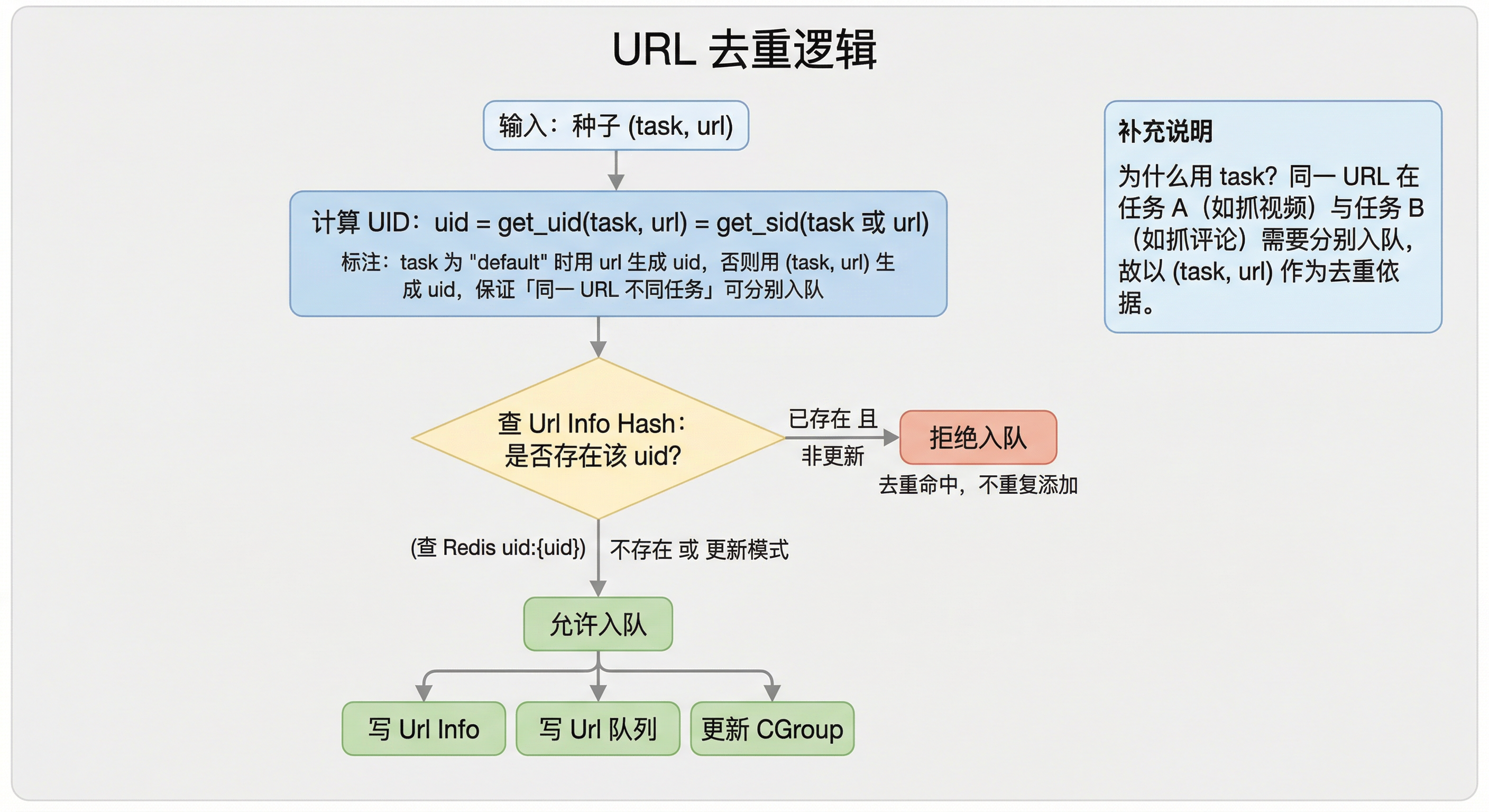
为何用 task 参与 UID?
同一 URL 在不同业务任务下可能需要分别抓取(例如任务 A 抓视频信息、任务 B 抓同一页评论)。UID 由 (task, url) 生成时,同一 URL 在不同任务下会得到不同 uid,从而可分别入队、互不影响。
4. Redis 数据结构
4.1 存储结构总览
4.2 CGroup 队列详解
Key 命名规则 :cgroup_queue:priority:{priority}
示例:cgroup_queue:priority:1(高优先级)、cgroup_queue:priority:2(普通优先级)。
数据结构:

cgroup_hash 生成规则(伪代码):
函数 生成CgroupHash(cgroup, tag, source):
若 source 为 "online": 返回 "cgroup:" + cgroup + ":tgroup:" + tag;
否则: 返回 "cgroup:" + cgroup + ":tgroup:" + tag + ":test"。
例:(youtube, video, online) → "cgroup:youtube:tgroup:video"
(youtube, video, test) → "cgroup:youtube:tgroup:video:test"score 含义 :该组中最早待调度任务的时间戳,用于在 CGroup 队列中快速选出「当前最该被调度的组」。
4.3 URL 队列详解
Key 命名规则 :uid_queue:{cgroup_hash}:priority:{priority}
示例:uid_queue:cgroup:youtube:tgroup:video:priority:2、uid_queue:cgroup:spotify:tgroup:track:priority:1。
数据结构:
score 含义 :该任务应被调度的时间戳;仅当 score ≤ 当前时间时才会被出队,是延时调度与流量削峰的基础。
4.4 URL 信息 Hash 详解
Key 命名规则 :uid:{uid}
示例:uid:a1b2c3d4e5f6g7h8i9j0k1l2m3n4o5p6。
数据结构:
字段详细说明:
|----------|--------|---------------------------------------------|
| 字段 | 类型 | 说明 |
| url | string | 内部格式 原始URL?::cgroup?::task,还原时取 ?:: 前部分 |
| priority | int | 优先级 0--4,0 最高 |
| cgroup | string | 爬虫组,决定由哪类爬虫处理 |
| task | string | 任务 ID,参与 UID 去重与追踪 |
| tag | string | 任务标签,细分类型 |
| source | string | 来源:online / test |
| type | string | 任务类型,业务自定义 |
| refresh | int | 刷新间隔(秒),用于计算下次 score |
| count | int | 剩余执行次数,每次出队减 1,为 0 时删除 |
| score | float | 下次调度时间戳 |
| way | string | 入队方式,如 SEEDER |
| extend | string | 扩展参数,JSON,业务自定义 |
URL 内部存储格式(伪代码):
- 写入 :将原始 URL 与 cgroup、task 拼接为
原始URL?::cgroup?::task再存入 Hash 的url字段。
示例:原始https://www.youtube.com/watch?v=abc123→ 存为https://www.youtube.com/watch?v=abc123?::youtube?::task_001。 - 还原 :从存储的 url 中取
?::前的子串即为真实 URL。
过期时间:每条 Url Info 的 Redis key 设置 TTL 为 604800 秒(7 天),到期自动删除。
4.5 数据关系图