接上一篇:yolov8n训练
一、导论
rk3399 运行yolov8n 运行的效率太低了,所以想到了剪枝,裁剪了试试能否达到我们目前的标准。
没有裁剪前的模型参数如下:
模型总参数量 : 3006038
模型GFLOPs: 8.0863
RK3399的FP32(单精度浮点)理论峰值算力约为14.3 GFLOPS
之前模型每秒耗时计算:
大概 8.08G/ 14.3G =0.565秒,约为600ms,理论值,没有算上加速啥的,之前用ncnn部署大概300ms以上。
需要实现目标:(大约100ms内)
如果100ms算力大概要求:14.3G x 0.01秒 = 1.43G
按理论值大约要1.4G,估计很难,那大约裁剪到4G左右,加上加速量化试试能否到100ms内吧。
下面就记录下裁剪过程吧
二、准备
2.1 数据准备
跟之前的训练过程一样,准备一些数据大概2000张左右各种图片,数据集准备这里不再描述。
images/
└── train/
├── 0001.jpg
├── 0002.jpg
└── ...
labels/
└── train/
├── 0001.txt
├── 0002.txt
└── ...
配置文件也准备好
2.2 约束训练(Constrained Training)
这里使用的L1正则化进行稀疏化训练 ,使模型参数变得稀疏,剪枝的论文大家可以看看https://openaccess.thecvf.com/content_ICCV_2017/papers/Liu_Learning_Efficient_Convolutional_ICCV_2017_paper.pdf
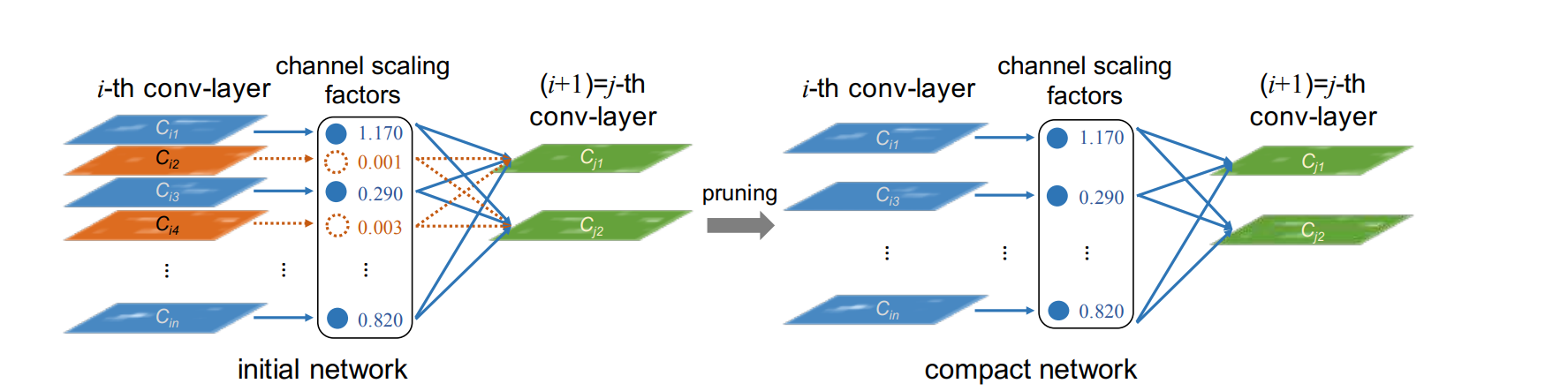
就是CNN模型中很多通道是冗余的,大概率用不上,这就占率了内存和计算,发现把这些通道删除不会影响最终的结果,这就是剪枝的由来了。
我们这里采用结构化剪枝,非结构化剪枝这里不涉及。
那如何剪枝了,比如我们的yolov8 的结构,里面最多的就是Conv卷积,而且剪枝基本针对也是Conv,那如何计算Conv哪些可以裁剪了,就是通过他后面的BN层,BN层记录了conv层的权重,通过他可以比较直接的计算哪些容易丢弃,下面看yolov8的结构
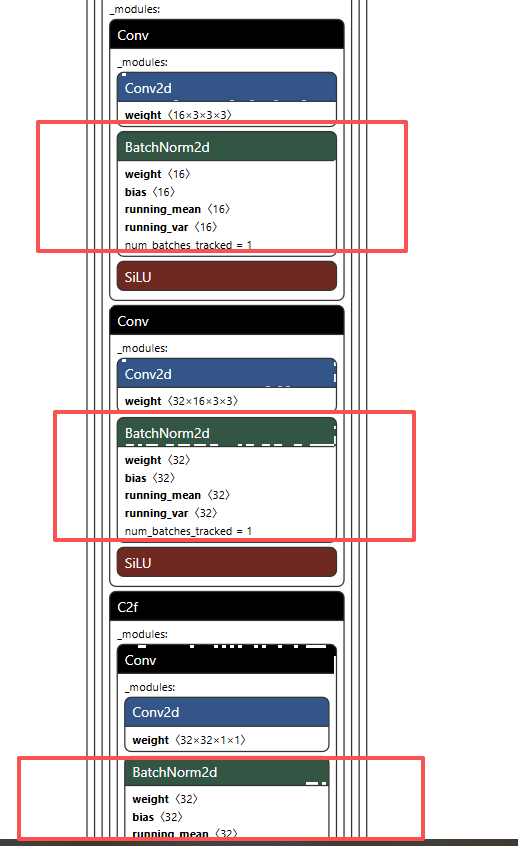
基本每个CONV后面都带BN层,那么方便我们裁剪了。
有两种裁剪方式,一种是先进行约束训练,就是在训练过程中对BN层进行L1正则化,使其接部分低权重的数值近于0,这样方便后续裁剪。
另外一种就是直接裁剪,直接裁剪20%,30%,通过权重排序,找到对应的概率值,低于此值的全部裁剪掉。
好了,这里先进行稀疏化训练
2.2.1 设置约束条件L1正则化
需要下载源码,在源码里面修改训练值。
在代码目录ultralytics\engine\trainer.py
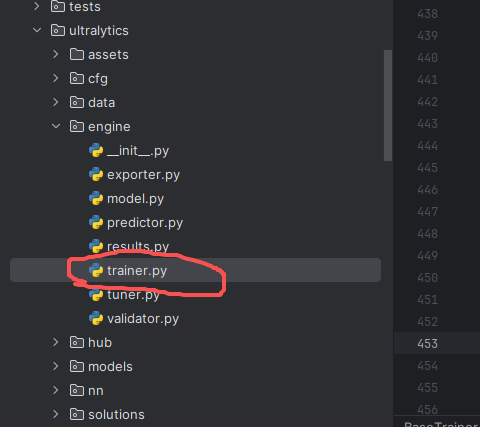
在代码 self.scaler.scale(self.loss).backward() 后面添加如下代码:
# 对BN层进行L1正则化,约束训练时启用,正常训练时注释掉
#初始L1正则化强度(10⁻²)如果不收缩可以加大值具体看模型,衰减系数(随训练轮次增加而增大)初期强约束促进稀疏化,后期减弱避免过度稀疏影响精度
l1_lambda = 1e-2 * (1 - 0.9 * epoch / self.epochs)
for k, m in self.model.named_modules():
if isinstance(m, nn.BatchNorm2d):#确保只对BN层进行操作,避免影响其他层
m.weight.grad.data.add_(l1_lambda * torch.sign(m.weight.data))
m.bias.grad.data.add_(1e-2 * torch.sign(m.bias.data))添加后如下
记得一定要在这边加上,刚好反向传播完成,后面step梯度没有清理执行。
2.3 训练代码
上述约束条件和数据准备完成后,开始添加训练代码
创建train_prune_pretrain.py 代码,具体如下:
import math
import os
import platform
import cv2
import torch
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image, UnidentifiedImageError
from torch import nn
from typing import Optional, Tuple # 兼容Python<3.8的类型注解
from ultralytics.utils import LOGGER
from pathlib import Path
from ultralytics.data import YOLODataset
from ultralytics import YOLO
# ===================== 1. 重写图片读取(解决Corrupt JPEG退出) =====================
def custom_load_image(self, i: int, rect_mode: bool = True) -> Tuple[np.ndarray, Tuple[int, int], Tuple[int, int]]:
"""完全对齐原生load_image逻辑,兼容Python<3.8"""
# 1. 优先读取缓存(原生逻辑)
im, f, fn = self.ims[i], self.im_files[i], self.npy_files[i]
if im is not None:
return self.ims[i], self.im_hw0[i], self.im_hw[i]
# 2. 缓存不存在:尝试读取npy或图片
if fn.exists():
try:
im = np.load(fn)
except Exception as e:
LOGGER.warning(f"{self.prefix}Removing corrupt *.npy image file {fn} due to: {e}")
Path(fn).unlink(missing_ok=True)
im = self._safe_imread(f)
else:
im = self._safe_imread(f)
# 3. 图片读取失败:抛出异常
if im is None:
raise FileNotFoundError(f"Image Not Found {f}")
# 4. 原生resize逻辑
h0, w0 = im.shape[:2]
if rect_mode:
r = self.imgsz / max(h0, w0)
if r != 1:
w, h = (min(math.ceil(w0 * r), self.imgsz), min(math.ceil(h0 * r), self.imgsz))
im = cv2.resize(im, (w, h), interpolation=cv2.INTER_LINEAR)
elif not (h0 == w0 == self.imgsz):
im = cv2.resize(im, (self.imgsz, self.imgsz), interpolation=cv2.INTER_LINEAR)
# 5. 灰度图转3通道
if im.ndim == 2:
im = im[..., None]
# 6. 缓存处理
if self.augment:
self.ims[i], self.im_hw0[i], self.im_hw[i] = im, (h0, w0), im.shape[:2]
self.buffer.append(i)
if 1 < len(self.buffer) >= self.max_buffer_length:
j = self.buffer.pop(0)
if self.cache != "ram":
self.ims[j], self.im_hw0[j], self.im_hw[j] = None, None, None
return im, (h0, w0), im.shape[:2]
def _safe_imread(self, f: str) -> Optional[np.ndarray]:
"""安全读取图片,兼容Python<3.10"""
try:
with Image.open(f) as img:
img = img.convert("RGB")
im = np.array(img)[:, :, ::-1] # RGB→BGR
return im
except (UnidentifiedImageError, IOError, OSError):
LOGGER.warning(f"{self.prefix}Corrupt JPEG file {f}, skip reading")
return None
# 绑定图片读取方法
YOLODataset._safe_imread = _safe_imread
YOLODataset.load_image = custom_load_image
# ===================== 2. 自定义钩子(核心:修复batch属性) =====================
class PruneTrainHook:
"""整合L1正则化+BN分析+提前停止的钩子类"""
def __init__(self, total_epochs: int, check_interval: int = 5, stop_threshold: float = 90.0):
self.total_epochs = total_epochs # 最大训练轮数
self.check_interval = check_interval # BN分析间隔
self.stop_threshold = stop_threshold # 停止阈值(可剪枝+核心通道占比)
self.l1_base_lambda = 1e-2 # L1基础系数
self.stop_training = False # 提前停止标记
self.hook_triggered = False # 调试:标记钩子是否触发
self.current_epoch = 0
def showConstrained_train(self, trainer):
# 获取真实训练模型(绕过 EMA 和 DDP)
model = trainer.model
# 如果启用了 EMA,trainer.model 可能是 EMA 模型!
# 真实训练模型通常存储在 trainer._orig_model 或通过其他方式
# 但在 Ultralytics 中,更可靠的方式是:在训练阶段,使用 trainer.model 但确保不是 EMA
# ⭐ 关键:YOLOv8 在训练循环中会临时禁用 EMA,
# 所以在 on_train_epoch_end 中,trainer.model 通常是原始模型
# 但为了 100% 安全,我们检查是否有 .module(DDP)
real_model = model.module if hasattr(model, 'module') else model
# 收集所有 BN gamma (weight)
all_gammas = []
for name, m in real_model.named_modules():
if isinstance(m, nn.BatchNorm2d):
# 确保我们读取的是当前值(非 EMA)
all_gammas.append(m.weight.data.abs().detach().cpu())
if not all_gammas:
print("[Pruning Analysis] No BN layers found.")
return
all_gammas = torch.cat(all_gammas)
total_channels = all_gammas.numel()
ratio_lt_1e4 = (all_gammas < 1e-4).float().mean().item() * 100
ratio_lt_1e3 = (all_gammas < 1e-3).float().mean().item() * 100
avg_gamma = all_gammas.mean().item()
print(f"\n[Pruning Analysis - TRAIN MODEL] Epoch {trainer.epoch}:")
print(f" Total BN channels: {total_channels}")
print(f" |γ| < 1e-4: {ratio_lt_1e4:.2f}%")
print(f" |γ| < 1e-3: {ratio_lt_1e3:.2f}%")
print(f" Avg |γ|: {avg_gamma:.5f}\n")
def on_train_batch_end(self, trainer):
"""每个epoch结束后执行:BN层分析+提前停止判断"""
current_epoch = trainer.epoch + 1 # 转为人类可读的epoch(从1开始)
if (self.current_epoch != trainer.epoch):
self.showConstrained_train(trainer)
self.current_epoch = trainer.epoch
# 每隔check_interval个epoch分析BN层
if current_epoch % self.check_interval == 0:
LOGGER.info(f"\n===== Epoch {current_epoch} 结束,开始BN层分析 =====")
stop_condition = self.analyze_bn_weight(trainer.model, current_epoch)
if stop_condition:
# self.stop_training = True
# trainer.stop = True
LOGGER.info(f"\n🛑 提前停止训练:Epoch {current_epoch} 满足停止条件!")
# assert ('已经满足条件停止训练')
def analyze_bn_weight(self, model, epoch):
"""分析BN层weight分布,返回是否满足停止条件"""
real_model = model.module if hasattr(model, 'module') else model
# 收集所有BN层weight绝对值
bn_weights = []
for _, m in real_model.named_modules():
if isinstance(m, nn.BatchNorm2d):
weight_abs = m.weight.data.abs().cpu().numpy()
bn_weights.extend(weight_abs.flatten().tolist())
if not bn_weights:
LOGGER.warning("⚠️ 未找到BN层,跳过分析")
return False
# 统计各区间比例
bn_weights = np.array(bn_weights)
total_num = len(bn_weights)
prunable_ratio = np.sum(bn_weights < 1e-4) / total_num * 100
core_ratio = np.sum(bn_weights > 0.1) / total_num * 100
total_valid_ratio = prunable_ratio + core_ratio
# 打印统计结果
print(f"📊 BN层Weight分布统计(Epoch {epoch}):")
print(f" 总数量: {total_num}")
print(f" 可剪枝通道(|w|<1e-4): {prunable_ratio:.2f}%")
print(f" 核心通道(|w|>0.1): {core_ratio:.2f}%")
print(f" 有效通道占比: {total_valid_ratio:.2f}% (阈值: {self.stop_threshold}%)")
# 可视化分布
plt.figure(figsize=(10, 6))
plt.hist(bn_weights, bins=50, color='skyblue', edgecolor='black')
plt.axvline(x=1e-4, color='red', linestyle='--', label='剪枝阈值(1e-4)')
plt.axvline(x=0.1, color='orange', linestyle='--', label='核心通道阈值(0.1)')
plt.xlabel("BN层|weight|值")
plt.ylabel("数量")
plt.title(f"Epoch {epoch} BN层Weight绝对值分布")
plt.legend()
plt.savefig(os.path.join("bn_weight_analysis", f"bn_dist_epoch_{epoch}.png"))
plt.close()
# 返回是否满足停止条件
return total_valid_ratio >= self.stop_threshold
# ===================== 3. 主训练函数(核心:移除重复train调用) =====================
def train_prune_pretrain():
"""剪枝预训练主函数(基于ultralytics原生钩子)"""
# 1. 配置参数
model_path = "yolovn_0105best.pt"
total_epochs = 20
check_interval = 5
stop_threshold = 90.0
Base_Path = r"F:\work\code\python\yolov8\ultralytics-train\ultralytics"
datayaml = os.path.join(Base_Path, "data", "prune.yaml") # 安全拼接路径
os.makedirs("bn_weight_analysis", exist_ok=True) # 提前创建BN分析目录
# 2. 初始化模型
model = YOLO(model_path)
# 3. 补充overrides(避免KeyError)
model.overrides.update({
"model": os.path.abspath(model_path),
"data": os.path.abspath(datayaml)
})
# 4. 初始化自定义钩子
prune_hook = PruneTrainHook(
total_epochs=total_epochs,
check_interval=check_interval,
stop_threshold=stop_threshold
)
# ========== 绑定钩子事件 ==========
LOGGER.info("📌 注册钩子事件:on_train_batch_end + on_epoch_end")
model.add_callback("on_train_batch_end", prune_hook.on_train_batch_end)
workers = 0 if platform.system() == "Windows" else 8
# 6. 训练配置(仅保留有效参数)
train_config = {
"data": datayaml,
"epochs": total_epochs,
"batch": 16,
"imgsz": 320,
"workers": workers, # Windows必设0
"lr0": 0.01, # 初始学习率
"weight_decay": 0.0005, # 权重衰减
"device": "cpu" if not torch.cuda.is_available() else "cuda", # 自动选择设备
"verbose": True # 打印详细训练日志
}
# 7. 启动训练(核心:移除重复的model.train()调用)
try:
# 直接调用model.train(**train_config),无需提前调用model.train()
results = model.train(**train_config)
LOGGER.info("\n✅ 剪枝预训练完成!")
except KeyError as e:
# 兜底修复:补充缺失的键
missing_key = str(e)
if missing_key in ["model", "data"]:
fill_value = model_path if missing_key == "model" else datayaml
model.overrides[missing_key] = os.path.abspath(fill_value)
results = model.train(**train_config)
except Exception as e:
LOGGER.error(f"\n❌ 训练报错:{str(e)}")
raise e
# 8. 保存最终模型
model.save("yolov8n_prune_pretrain1_end.pt")
LOGGER.info(f"\n💾 剪枝预训练模型已保存至:{os.path.abspath('yolov8n_prune_pretrain_end.pt')}")
# ===================== 5. 执行训练 =====================
if __name__ == "__main__":
# 切换工作目录到脚本所在路径
os.chdir(os.path.dirname(os.path.abspath(__file__)))
# 打印环境信息(调试用)
LOGGER.info(f"📌 Python版本:{os.sys.version}")
LOGGER.info(f"📌 Ultralytics版本:{YOLO.__version__ if hasattr(YOLO, '__version__') else '未知'}")
LOGGER.info(f"📌 CUDA可用:{torch.cuda.is_available()}")
# 执行训练
train_prune_pretrain()把如下参数修改成自己的参数,基于哪个模型训练,配置文件的路径和配置名称
训练大概10多轮就可以了,如果一直不为0,那么就把 l1_lambda = 1e-2 * (1 - 0.9 * epoch / self.epochs)里面的1e-2 增加。
修改好后就可以开始训练了。
2.4 、开始训练
执行train_prune_pretrain.py,会得到一个模型yolov8n_prune_pretrain1_end.pt 模型。
可以用这个模型用来裁剪。
三、开始剪枝
上面已经得到了稀疏化的模型,那么就需要编写剪枝代码,通过BN层的权重,把对应的CONv的对应层删除,那么需要修改对应的输入和输出。参考博客(https://zhuanlan.zhihu.com/p/13362757767)大家可以直接去看
创建剪枝代码如下:analyze_pruning_new.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
YOLOv8 模型通道剪枝脚本(基于BN层权重)
核心流程:
1. 加载稀疏训练后的YOLOv8模型
2. 统计所有BN层权重,计算全局剪枝阈值(保留指定比例的通道)
3. 核心剪枝逻辑:
- 剪枝Bottleneck模块内的卷积层
- 剪枝模型主干模块间的卷积层
- 剪枝检测头(Detect)的卷积层
- 同步更新前后连接层的通道数,保证模型结构一致性
4. 保存剪枝后模型并导出ONNX格式
注意事项:
- 稀疏训练阶段需为BN层添加L1正则约束(lambda≈1e-2)
- 剪枝后微调时需移除L1约束,避免过度稀疏
- 剪枝时保证至少保留8个通道,避免Nvidia GPU利用率过低
"""
# ============================== 导入依赖库 ==============================
import sys
import torch
from ultralytics import YOLO
from ultralytics.nn.modules import Bottleneck, Conv, C2f, SPPF, Detect
from thop import profile # 预留计算量接口,当前未使用
# ============================== 全局配置 ==============================
# 模型路径
MODEL_PATH = "yolov8n_prune_pretrain1best.pt"
# 通道保持率(保留权重最大的80%通道)
KEEP_FACTOR = 0.8
# 颜色输出配置(用于终端高亮显示最小值)
RED = "\033[91m"
RESET = "\033[0m"
# ============================== 加载模型 ==============================
# 加载稀疏训练后的YOLOv8模型
yolo = YOLO(MODEL_PATH)
model = yolo.model
# ============================== 计算剪枝阈值 ==============================
# 收集所有BN层的权重和偏置绝对值(用于计算全局阈值)
bn_weights = [] # 存储所有BN层权重绝对值
bn_biases = [] # 存储所有BN层偏置绝对值
print("=" * 80)
print("BN层权重/偏置极值统计(最小值高亮显示):")
print("=" * 80)
for module_name, module in model.named_modules():
if isinstance(module, torch.nn.BatchNorm2d):
# 提取BN层权重/偏置(detach避免影响计算图)
weight_abs = module.weight.abs().detach()
bias_abs = module.bias.abs().detach()
bn_weights.append(weight_abs)
bn_biases.append(bias_abs)
# 打印当前BN层的权重/偏置极值
print(
f"BN层名称: {module_name: <50} "
f"权重最大值: {weight_abs.max().item():.10f} "
f"权重最小值: {RED}{weight_abs.min().item():.10f}{RESET} "
f"偏置最大值: {bias_abs.max().item():.10f} "
f"偏置最小值: {RED}{bias_abs.min().item():.10f}{RESET}"
)
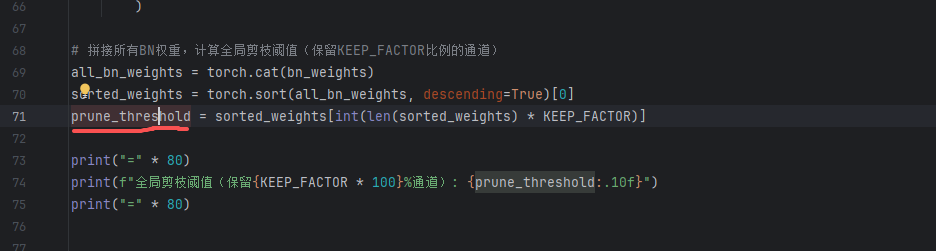
# 拼接所有BN权重,计算全局剪枝阈值(保留KEEP_FACTOR比例的通道)
all_bn_weights = torch.cat(bn_weights)
sorted_weights = torch.sort(all_bn_weights, descending=True)[0]
prune_threshold = sorted_weights[int(len(sorted_weights) * KEEP_FACTOR)]
print("=" * 80)
print(f"全局剪枝阈值(保留{KEEP_FACTOR * 100}%通道): {prune_threshold:.10f}")
print("=" * 80)
# ============================== 核心剪枝函数 ==============================
def prune_conv(conv1: Conv, conv2: Conv or list):
"""
核心卷积层剪枝函数:剪枝前层conv1的输出通道,同步更新后层conv2的输入通道
保证前后层通道数匹配,避免结构不一致
Args:
conv1: 待剪枝的卷积层(前层,剪枝其输出通道)
conv2: 与conv1连接的后续卷积层(后层,需同步更新输入通道),支持单个或列表
"""
# 提取conv1的BN层权重和偏置(用于判断保留哪些通道)
gamma = conv1.bn.weight.data.detach()
beta = conv1.bn.bias.data.detach()
keep_indices = []
local_threshold = prune_threshold.clone()
# 逐步降低阈值,确保至少保留8个通道(避免GPU利用率过低)
while len(keep_indices) < 8:
# 筛选出权重绝对值≥当前阈值的通道索引
keep_indices = torch.where(gamma.abs() >= local_threshold)[0]
local_threshold *= 0.5 # 阈值减半,扩大保留范围
# 保留的通道数
keep_channel_num = len(keep_indices)
print(f"保留通道数/原始通道数: {keep_channel_num}/{len(gamma)} ({keep_channel_num / len(gamma) * 100:.2f}%)")
# -------------------------- 更新前层conv1(输出通道剪枝) --------------------------
# 更新BN层参数
conv1.bn.weight.data = gamma[keep_indices]
conv1.bn.bias.data = beta[keep_indices]
conv1.bn.running_var.data = conv1.bn.running_var.data[keep_indices]
conv1.bn.running_mean.data = conv1.bn.running_mean.data[keep_indices]
conv1.bn.num_features = keep_channel_num # 更新BN层通道数
# 更新卷积层参数
conv1.conv.weight.data = conv1.conv.weight.data[keep_indices]
conv1.conv.out_channels = keep_channel_num # 更新输出通道数
if conv1.conv.bias is not None: # 若存在偏置,同步更新
conv1.conv.bias.data = conv1.conv.bias.data[keep_indices]
# -------------------------- 更新后层conv2(输入通道同步) --------------------------
# 统一格式为列表,方便批量处理
if not isinstance(conv2, list):
conv2 = [conv2]
for item in conv2:
if item is not None:
# 兼容C2f/SPPF等复合模块的卷积层提取
conv = item.conv if isinstance(item, Conv) else item
# 更新输入通道数(与conv1输出通道一致)
conv.in_channels = keep_channel_num
# 剪枝卷积核的输入通道维度
conv.weight.data = conv.weight.data[:, keep_indices]
def prune(prev_module, next_module):
"""
复合模块剪枝适配函数:处理C2f/SPPF等复合模块的卷积层提取,调用核心剪枝函数
Args:
prev_module: 前序模块(C2f/Bottleneck/Conv等)
next_module: 后续模块(C2f/SPPF/Conv等),支持单个或列表
"""
# 提取C2f模块的输出卷积层(cv2)
if isinstance(prev_module, C2f):
prev_module = prev_module.cv2
# 统一格式为列表,方便批量处理
if not isinstance(next_module, list):
next_module = [next_module]
# 提取复合模块的输入卷积层(cv1)
for idx, item in enumerate(next_module):
if isinstance(item, C2f) or isinstance(item, SPPF):
next_module[idx] = item.cv1
# 调用核心剪枝函数
prune_conv(prev_module, next_module)
# ============================== 分模块执行剪枝 ==============================
print("\n" + "=" * 80)
print("开始执行模型剪枝:")
print("=" * 80)
# 1. 剪枝C2f模块中Bottleneck的卷积层
print("\n[Step 1/3] 剪枝Bottleneck模块内卷积层:")
for module_name, module in model.named_modules():
if isinstance(module, Bottleneck):
prune_conv(module.cv1, module.cv2)
# 2. 剪枝模型主干序列中指定模块间的卷积层
print("\n[Step 2/3] 剪枝模型主干模块间卷积层:")
model_backbone = model.model # 获取模型主干序列
for idx in range(3, 9):
if idx in [6, 4, 9]: # 跳过指定层(避免破坏模型结构)
continue
prune(model_backbone[idx], model_backbone[idx + 1])
# 3. 剪枝检测头(Detect)相关卷积层
print("\n[Step 3/3] 剪枝检测头卷积层:")
detect_head: Detect = model_backbone[-1] # 获取检测头模块
# 检测头输入层配置
detect_inputs = [model_backbone[15], model_backbone[18], model_backbone[21]]
detect_secondary = [model_backbone[16], model_backbone[19], None]
# 遍历检测头的cv2/cv3分支,逐层剪枝
for input_module, secondary_module, cv2_branch, cv3_branch in zip(
detect_inputs, detect_secondary, detect_head.cv2, detect_head.cv3
):
# 剪枝输入层到检测头分支的连接
prune(input_module, [secondary_module, cv2_branch[0], cv3_branch[0]])
# 剪枝cv2分支内部
prune(cv2_branch[0], cv2_branch[1])
prune(cv2_branch[1], cv2_branch[2])
# 剪枝cv3分支内部
prune(cv3_branch[0], cv3_branch[1])
prune(cv3_branch[1], cv3_branch[2])
# ============================== 模型后处理 ==============================
print("\n" + "=" * 80)
print("剪枝完成,重置参数梯度状态并保存模型:")
print("=" * 80)
# 重置所有参数为可训练状态(加载模型后部分参数可能被设为不可训练)
for param_name, param in yolo.model.named_parameters():
param.requires_grad = True
# 保存剪枝后的模型权重
torch.save(yolo.ckpt, "prune.pt")
print("✅ 剪枝后模型已保存为: prune.pt")
# 导出ONNX格式(简化版)
yolo.export(format="onnx", simplify=True)
print("✅ 剪枝后模型已导出为ONNX格式(简化版)")
print("\n🎉 剪枝流程全部完成!")此剪枝代码,支持两种剪枝方式,一种是直接剪枝百分之多少,如0.2百分之20,还有一种就是自己设置阈值比如低于多少的阈值全部剪掉。
这里是设置保留百分比阈值,保留80%
阈值修改,可以直接设置值,不需要获取出来,那么就是低于此阈值的全部裁剪
两种方式都行,一种精细化裁剪,一种粗略裁剪。
裁剪过后,会输出 prune.pt 裁剪后的模型,注意哈,裁剪后的模型,需要微调才会恢复,不然直接使用,可能没有结果。
四、微调
微调就是直接可以在之前的训练集上面,跑40~50轮,恢复精度。
记住不能直接训练,由于剪枝了,那么结构变化了,yolov8 默认代码会通过配置文件恢复结构,所以直接这么训练那么白剪枝了,还是会恢复成老样子。所以需要修改一下代码
4.1 修改结构
具体如下:
在代码ultralytics\engine下面model.py 文件里面修改,把加载的模型结构赋值回去,禁止修改
具体如下:
在如下代码后
self.trainer.model = self.trainer.get_model(weights=self.model if self.ckpt else None, cfg=self.model.yaml)添加
self.trainer.model.model = self.model.model # 新增 prune need
self.model = self.trainer.model具体如下:

对了还有记得把之前约束代码也要禁用掉,就是2.2.1节添加的代码,如下

4.2 微调
然后开始执行训练,可以用https://blog.csdn.net/p731heminyang/article/details/156423483
这一节的内容执行训练,把训练轮数降低就行。
比如自己发现精度已经达标了,或者开始降低了就可以停止掉了,模型跟上节一样

4.3 查询模型信息
获取到了最好的模型,那么就查询下模型的参数是否变化了
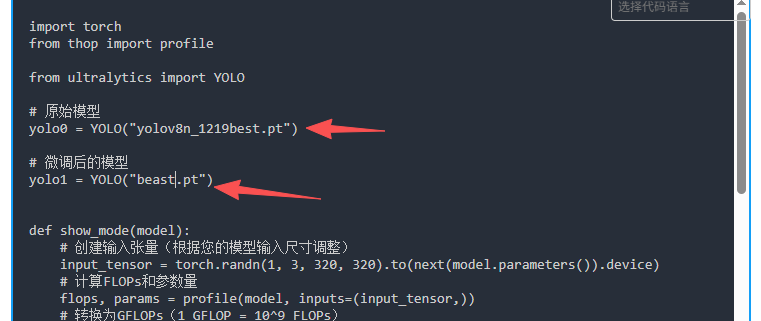
查询代码:show_model_info.py
import torch
from thop import profile
from ultralytics import YOLO
# 原始模型
yolo0 = YOLO("yolov8n_1219best.pt")
# 微调后的模型
yolo1 = YOLO("beast.pt")
def show_mode(model):
# 创建输入张量(根据您的模型输入尺寸调整)
input_tensor = torch.randn(1, 3, 320, 320).to(next(model.parameters()).device)
# 计算FLOPs和参数量
flops, params = profile(model, inputs=(input_tensor,))
# 转换为GFLOPs(1 GFLOP = 10^9 FLOPs)
gflops = flops / 1e9
print(f"模型FLOPs: {flops}")
print(f"模型GFLOPs: {gflops:.4f}")
print(f"模型参数量: {params}")
def get_model_info(model):
"""获取模型的总参数量、精度和GFLOPs(正确计算FLOPs)"""
# 1. 确保模型已融合(YOLOv8默认融合,但显式操作更安全)
model = model.fuse()
# 2. 获取总参数量
total_params = sum(p.numel() for p in model.parameters())
# 3. 获取精度
dtype = next(model.parameters()).dtype
# 4. 获取GFLOPs(关键:thop返回的是MACs,需乘以2得到FLOPs)
input_size = (1, 3, 640, 640) # YOLOv8标准输入尺寸
input = torch.randn(input_size).to(next(model.parameters()).device)
flops, _ = profile(model, inputs=(input,))
# 重要修正:FLOPs = 2 × MACs
gflops = (flops * 2) / 1e9 # 转换为GFLOPs # 打印结果
print(f"模型总参数量: {total_params}")
print(f"模型精度: {dtype}")
print(f"模型GFLOPs: {gflops:.4f}")
return {
'total_params': total_params,
'precision': dtype,
'gflops': gflops
}
def get_model_layer_info(model):
"""
获取模型各层的详细信息(名称、类型、参数量、精度等)
:param model: PyTorch模型
:return: 各层信息列表
"""
layers_info = []
for name, module in model.named_modules():
# 只关注有参数的层
if len(list(module.parameters())) > 0:
# 获取层的参数量
params = sum(p.numel() for p in module.parameters())
# 获取层的精度
dtype = next(module.parameters()).dtype
layers_info.append({
'layer_name': name,
'layer_type': module.__class__.__name__,
'params': params,
'precision': dtype
})
# 打印各层信息
print("\n各层详细信息:")
for layer in layers_info:
print(
f"层: {layer['layer_name']}, 类型: {layer['layer_type']}, 参数量: {layer['params']}, 精度: {layer['precision']}")
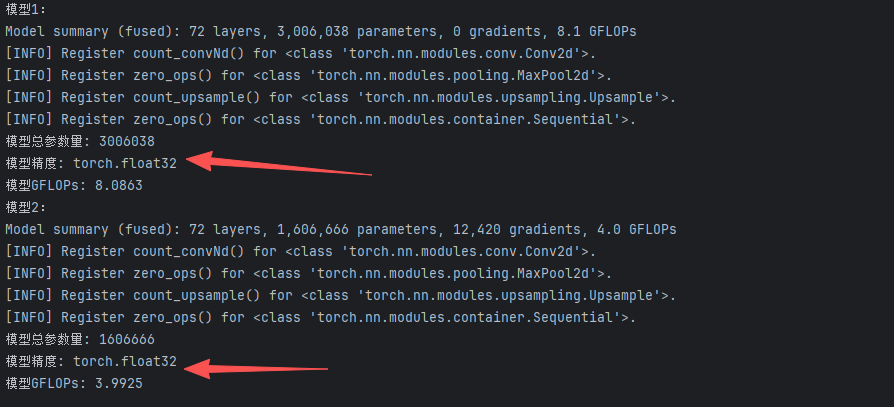
print("模型1:")
# get_model_layer_info(yolo0.model)
model_info=get_model_info(yolo0.model)
print("模型2:")
# get_model_layer_info(yolo1.model)
model_info=get_model_info(yolo1.model)修改两个模型的名称
执行后发现,参数量和算力都降低了很多,如果精度也达标那么我们的模型已经ok。
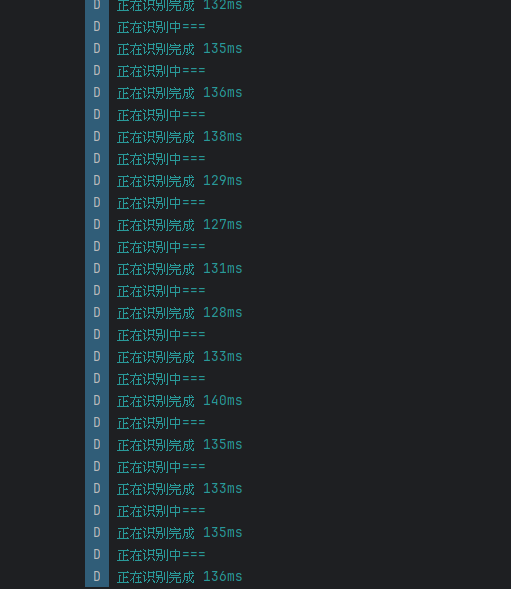
后续就是放入到rk3399 试试效果了,转换为ncnn模型和之前一样,这里不讲了。
最终效果:从300ms最终降低到100多ms,还可以继续裁剪,下面试试量化了
裁剪总结:
我这边裁剪是进行稀疏化之后再进行剪枝,我采用的是多次剪枝这样达到的精确度会比较好。
1、每次剪枝10%,保留90%的通道
2、微调模型后,然后再执行第一步剪枝
3、直到精度下降厉害或者算力达到标准,停止执行
参考文档:https://blog.csdn.net/p731heminyang/article/details/156423483