随着深度学习的发展,模型规模越来越大。当前主流的 CNN / Transformer 模型,往往拥有千万甚至上亿级参数 ,并且通常是在 ImageNet-1K / 11K / 21K 等超大规模数据集上训练得到的。
然而,在真实业务场景中,我们往往只有几千到几万样本。如果在这种数据规模下,从零开始训练一个大型模型,几乎必然会遇到以下问题:
- 模型参数量巨大 → 严重过拟合
- 收敛缓慢甚至无法收敛
- 训练成本高、效果不稳定
这就引出了一个核心思想:
能否复用别人已经学到的"知识",而不是从零开始?
一、为什么需要模型微调(Fine-tuning)?
假设一个实际需求: 从图像中识别不同种类的椅子,并向用户推荐购买链接
一种"理想但不现实"的方案是:
- 为 100 种椅子
- 每种拍摄 1000 张图片
- 构建一个 10 万规模的数据集
- 从零训练一个深度网络
但现实是:
- 数据采集和标注成本极高
- 数据规模仍远小于 ImageNet
- 复杂模型极易过拟合
1.数据不够,是深度学习的常态
ImageNet的构建耗费了数百万美元和多年人力成本 。
在大多数应用场景下,数据不足是默认前提,而不是例外。
2.知识是可以迁移的
以 CNN 为例:
- 底层卷积核:学习边缘、角点、纹理
- 中层:学习形状、局部结构
- 高层:学习语义组合(物体部件、整体)
在 ImageNet 上训练得到的模型,虽然分类目标不同,但其低层与中层特征具有极强的通用性。
👉 模型参数(权重)本质上就是模型学到的"知识"
👉 迁移学习 = 把这些知识迁移到新任务中
二、Model Finetune:模型的迁移学习
模型微调(Fine-tuning)是迁移学习最常见、也最实用的一种形式。
核心思想 非常简单:
不从零训练模型,而是在一个"已经学会通用特征"的模型基础上,针对新任务进行再训练。
在 PyTorch 中,我们通常直接使用官方提供的预训练模型。
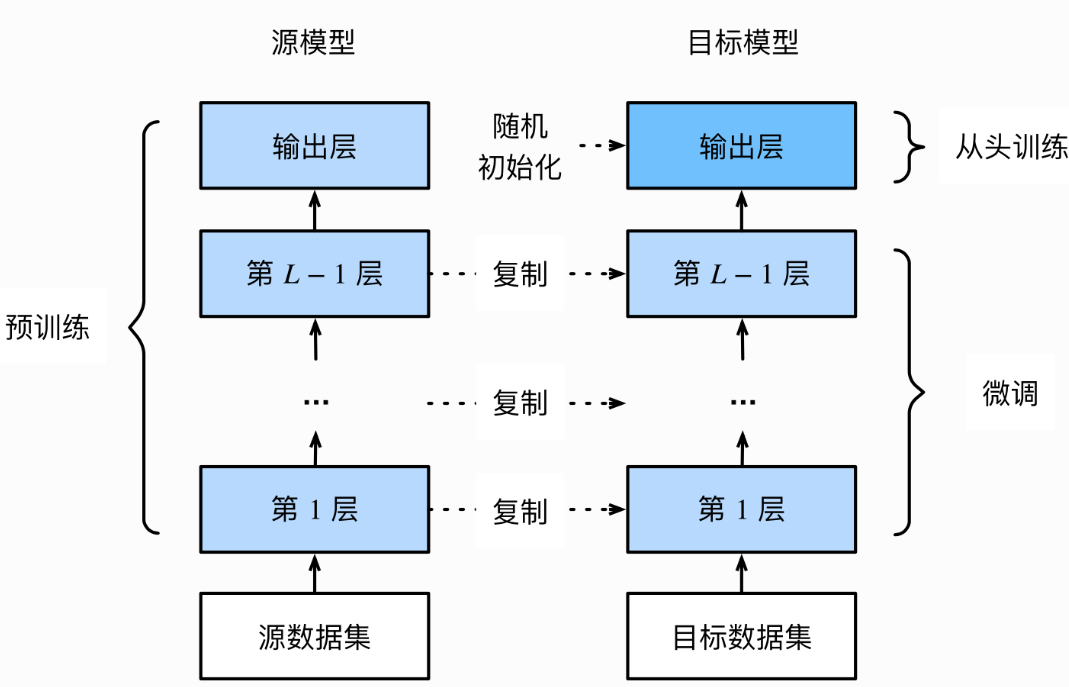
三、模型微调的流程
step1:加载源模型(预训练模型)
- 源模型是在大规模数据集(如 ImageNet)上训练好的模型
step2:构建目标模型
- 保留源模型的特征提取部分
- 移除或替换原来的输出层
step3:添加新的输出层
- 输出维度 = 目标数据集类别数
- 参数随机初始化
step4:在目标数据集上训练
- 在目标数据集上训练目标模型
- 从头训练输出层,而其余层的参数都是基于源模型的参数冻结/微调得到的
三、模型微调训练方法
在 PyTorch 中,模型微调本质上就是 "如何加载预训练模型 + 如何控制哪些参数参与训练"。根据是否更新特征提取层(backbone),微调方式大致可以分为两类:
- 仅训练新加入的分类层(特征提取)
- 在预训练权重基础上整体微调(Fine-tuning)
1.使用已有模型结构
PyTorch 的 torchvision.models 提供了大量在 ImageNet 等大型数据集上训练好的模型结构与权重,常用于迁移学习任务。
python
import torchvision.models as models
resnet18 = models.resnet18(pretrained=True)
alexnet = models.alexnet(pretrained=True)
vgg16 = models.vgg16(pretrained=True)
squeezenet = models.squeezenet1_0(pretrained=True)
densenet = models.densenet161(pretrained=True)
mobilenet_v2 = models.mobilenet_v2(pretrained=True)传递pretrained参数
pretrained=True:加载官方提供的预训练权重(微调最常用)pretrained=False:仅加载网络结构,参数随机初始化(等价于从头训练)
⚠️ 注意事项:
- 权重文件首次加载时会自动下载
- 默认缓存路径:
- Linux / macOS:
~/.cache/torch/hub/checkpoints - Windows:
C:\Users\<username>\.cache\torch\hub\checkpoints
- Linux / macOS:
- 下载完成后,后续加载不会重复下载
- 一般情况下预训练模型的下载会比较慢,我们也可以手动下载权重并加载:
python
self.model = models.resnet50(pretrained=False)
self.model.load_state_dict(torch.load('./model/resnet50-19c8e357.pth'))2.训练特定层
在迁移学习中,最常见、也是最稳妥的做法是:冻结预训练模型的特征提取层,仅训练新加入的分类层
① 冻结参数(关闭梯度计算)
在默认情况下,参数的属性.requires_grad = True,我们需要通过设置requires_grad = False来冻结部分层。在PyTorch官方中提供了这样一个例程。
python
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
for param in model.parameters():
param.requires_grad = False② 修改输出层(适配新任务)
以 ResNet18 为例,将 ImageNet 的 1000 类改为 10 类:
注意我们先冻结模型参数的梯度,再对模型输出部分的全连接层进行修改,这样修改后的全连接层的参数就是可计算梯度的。
python
import torchvision.models as models
feature_extract = True
model = models.resnet18(pretrained=True)
# 冻结backbone
set_parameter_requires_grad(model, feature_extract)
# 修改模型
num_features = model.fc.in_features
model.fc = nn.Linear(in_features=num_features, out_features=10, bias=True)之后在训练过程中,反向传播仍会执行完整计算图,但是参数更新则只会发生在fc层(requires_grad=True的层)。通过设定参数的requires_grad属性,我们完成了指定训练模型的特定层的目标,这对实现模型微调非常重要。
3.添加新的层
除了直接修改分类头外,还可以通过在预训练模型的基础上添加一层来实现微调。这种方式同样可以利用预训练模型的特征提取能力,同时通过新增层来适配新的分类任务。
① 添加新层
使用add_module()方法
以VGG16为例,假设原始模型是1000分类任务,现在需要将其改为10分类任务。可以在原始分类头的基础上添加一层Linear(1000, 10),将1000个输出映射到10个类别上。
python
import torchvision.models as models
import torch.nn as nn
# 加载预训练的VGG16模型
vgg16_true = models.vgg16(pretrained=True)
# 冻结backbone(可选)
set_parameter_requires_grad(model, feature_extract=True)
# 添加新层
model.classifier.add_module("linear_layer", nn.Linear(1000, 10))
print(vgg16_true)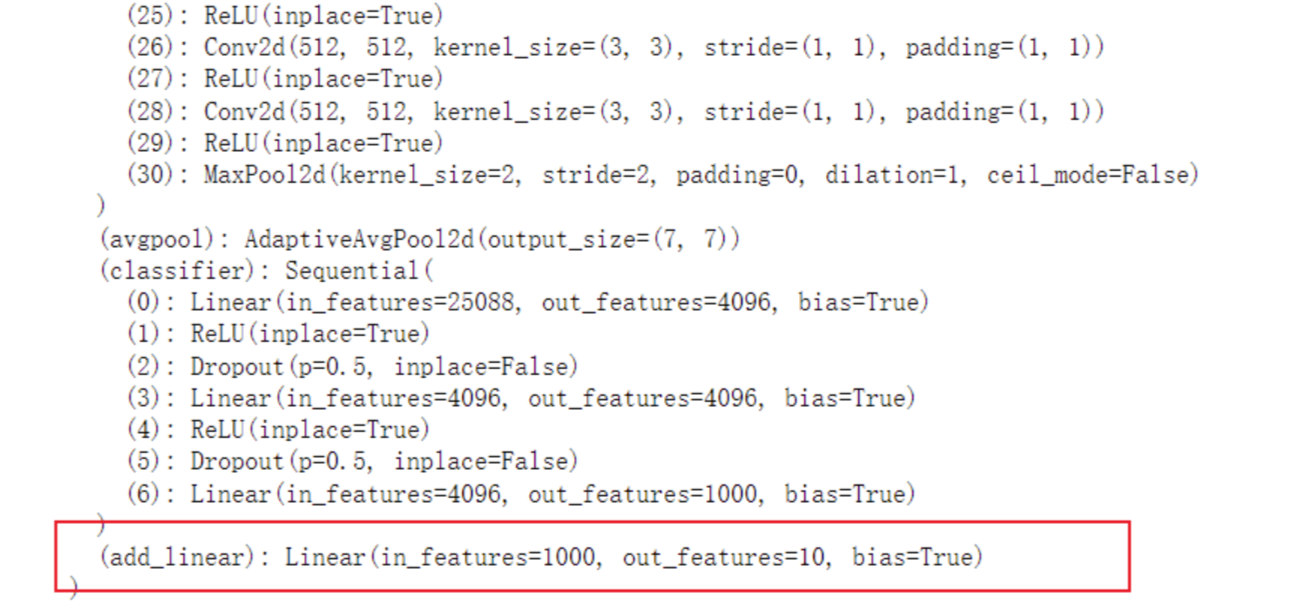
将添加的线性层加在classifier中
python
import torchvision.models as models
import torch.nn as nn
# 加载预训练的VGG16模型
vgg16_true = models.vgg16(pretrained=True)
# 冻结backbone(可选)
set_parameter_requires_grad(model, feature_extract=True)
# 添加新层在classifier中
vgg16_true.classifier.add_module('add_linear', nn.Linear(1000,10))
print(vgg16_true)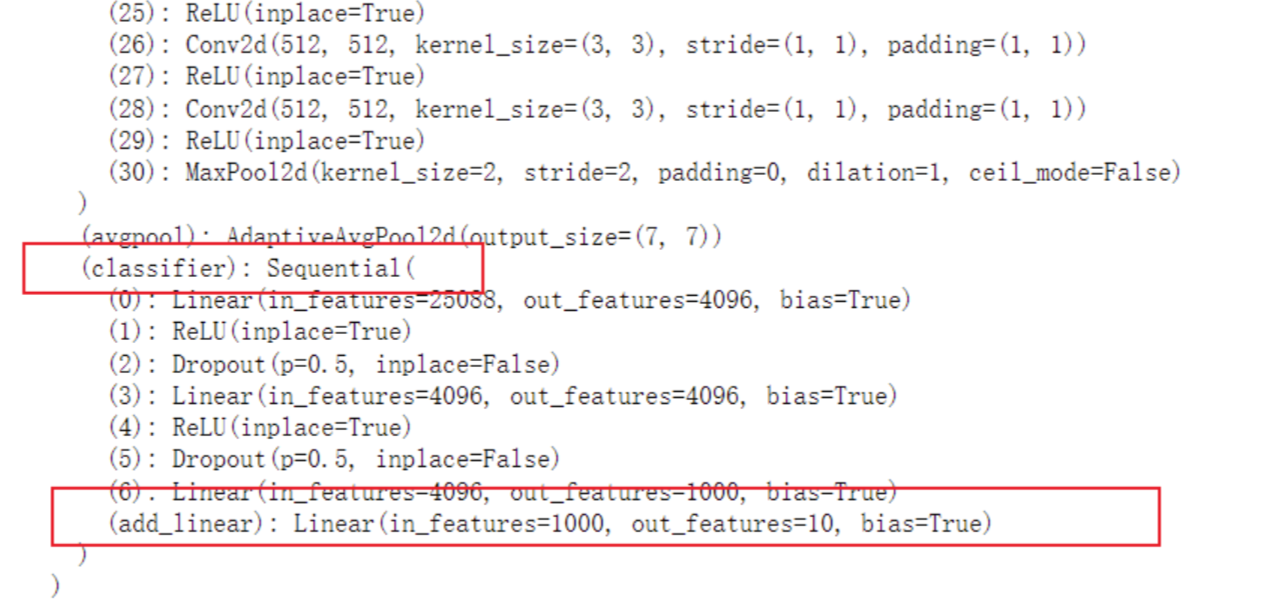
② 训练新层
在训练过程中,新增的linear_layer层的参数会参与更新,而其他层的参数(如Backbone)可以根据是否冻结来决定是否更新。
- 冻结Backbone :如果冻结了Backbone,那么只有新增的
linear_layer层的参数会更新。这种方式可以快速适应新任务,同时避免对预训练模型的特征提取能力进行过多调整。 - 不冻结Backbone:如果选择不冻结Backbone,那么整个模型的参数都会参与更新。这种方式可能会进一步优化模型的性能,但需要更多的训练资源和时间。
总结
1.预训练模型 = 可迁移的知识
2.微调的核心是:加载权重 + 控制梯度
3.小数据场景下,优先选择:冻结 backbone + 只训练分类层
4.如果数据量较大,可以尝试:不冻结 Backbone,进行整体微调