2026 年程序员自救指南
引言:谁在抽谁的鞭子?
所有与 AI 共事的开发者都害怕遇到这样的情形:同样的模型,同样的时间,同样的项目,甚至同样复杂度的问题,不同用户却得到截然不同的结果。有人得到伴随着幻觉的差强人意的答案,有人却收获超出预期的产出。
Hacker News 上曾有一篇高赞帖子提到:"AI is a floor raiser, not a ceiling raiser."(AI 提升的是底线,而不是天花板。)这意味着随着大模型能力的提升,即使在不健全的上下文或模糊的提问下,AI 也能提供越来越好的产出。
但这是一把双刃剑------不同使用水平的用户在使用同一模型时,产出结果的差距会随着模型水平的提升而越来越大。
我时常跟我同事打趣的说
与其说是我拿着鞭子去抽 AI, 不如说是 AI 拿着鞭子在抽我------ 逼着我学会如何更清晰、更高质量地提供信息。

在下半年我用的比较常见的提示词只有两个,一个是给我用中文解释!!,另外就是就是以下这一段:
查看本次 / 上次 / 历史会话中 我的思路、决策、判断、输入方式 有哪些亮点?有哪些可以改进和优化?
这背后反映的并不是"玄学调参",而是一个现实:AI 受限于你赋予它的Context(背景|上下文)。
AI-native 时代:我们必须适应的现实
说起来前段时间我了解到一个很有趣的词,叫AI-native,他的对应面是Human-native。
作为程序员,我更像是在通过代码与 AI 协作------就像两个人共同操控一台机器。 在 AI-native 的协作模式中,AI 是主控执行者,而人的角色并非直接操作系统,而是为 AI 提供完备的信息、清晰的问题边界与可推理的上下文。整个过程的核心成本,在于人是否能够将真实但混乱的问题,整理成 AI 可接受、可计算的表达形式,本质上是人去适应 AI 的认知与归纳方式。
相对地,Human-native 系统则反其道而行之:它们原生支持人的倾诉式表达,通过自然语言理解、需求挖掘与语义推断,将模糊的"大白话"逐步转化为有效产出。其目标并不是要求人学会如何精确表达问题,而是让系统具备足够的能力,去理解低质量输入背后的真实需求,从而使即使是经验较少的操作者,也能获得高质量的结果。
现阶段仍处于各大模型厂商的军备竞赛中,LLM Leaderboard 的排名风水轮流转。在这种背景下,现在大多数成功的产品,本质上都还是 AI-native 的 。相信以下的梗图大家应该都经常看到过。
 也许未来会出现更多 Human-native 产品,它们能够接受人们的倾诉,通过大白话发掘和确定需求,并转换为有效产出。
也许未来会出现更多 Human-native 产品,它们能够接受人们的倾诉,通过大白话发掘和确定需求,并转换为有效产出。
但对于奋斗在一线的开发者和 vibe coding 实践者来说,我们等不到那个时候------我们需要在当下养活自己。
那个 Human-native 的时代也许我们等不到,甚至某一天到来时我们已无法适应。但在此之前,我们需要进化出配合 AI-native产品所需的能力。(有时候真的很羡慕那些不以code为生的职业)
幻觉的本质:向量的"平权"陷阱
为什么同一个模型,有时候是神,有时候是人工智障?
答案通常在于 Context 的缺失。
以我们常用的 Cursor 为例,它的索引机制 (Codebase Indexing) 这里简单抽象为 3 步:
- 分片 (Chunking): 把你的代码拆成函数、类、逻辑块。
- 向量化 (Embedding): 用模型生成语义"指纹"。
- 存储与检索: 当你提问时,它去向量数据库里捞取"长得最像"的代码片段。
问题就出在这里:在向量数据库的视角里,代码没有"层级",只有"相似度",所有的代码片段在架构层级上是"平权"的。无论是核心架构设计,还是边缘的工具函数,在Cursor 眼里只是距离长短不同的向量而已。建立完索引库后,Cursor 对所有模块一视同仁
在不提供特殊信息的情况下,隐藏的上下文太多,Agent 面对问题容易陷入幻觉。我们经常需要不断迭代------@files 或 @某个特定的代码片段------直到 AI 明白我们的意图。对于刚接手大型项目的新人,这样的过程可能重复 3-5 次甚至更多。
更有趣的是"向量权重"现象:在 AI 合作的过程中,它会利用嵌入模型不断增加某一模块的向量权重。这会让你在频繁操作某模块时有"越用越顺"的感觉,但突然篡改一个已有模块时,却感知它"降智"了。这都可归纳为 Context 缺失产生幻觉的结果。
真正的差距,不在工具,而在你脑中的那张图
这是一张各家旗舰模型的 LLM Leaderboard
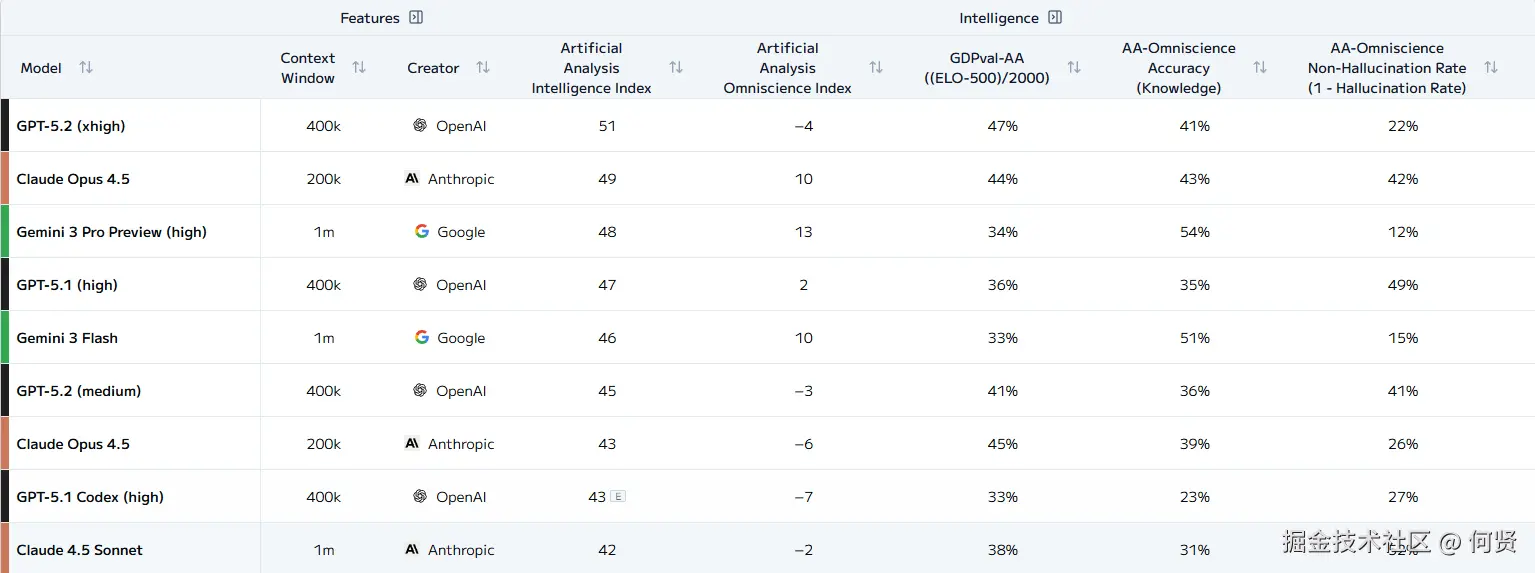
可能有人会说,我是用的是 XXX 模型,他就是不如 XXX。但实际上各家旗舰模型在各个测试环节并没有被拉开太大的差距
AI 对每个人的提升效果非常割裂:
有人觉得 AI 只能加快一点 coding 速度,而面对复杂项目时的代码产出则是:一杯茶、一包烟,一段代码 agent 跑一天。
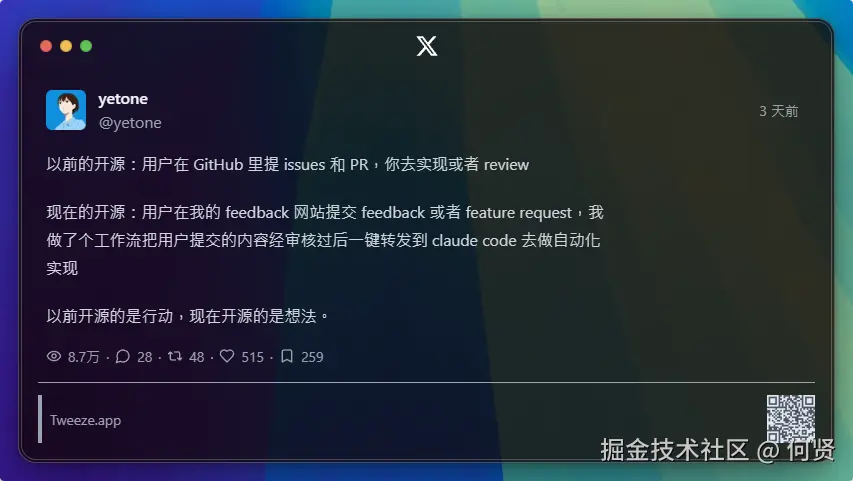
而有的人已经在考虑将大众提交的 feedback(issue、feature request)经过审核和规范输入后,一键转发到 Claude Code 去做自动化实现------构建一种可以被命名为「许愿式开发」的工作流。
但这并不代表前者不够优秀。我遇到过很多优秀的程序员,他们对自己构建和维护的项目有一份存在大脑中的 HIGH LEVEL VIEW(知道哪些模块负责哪些功能、承担哪些责任、存在哪些隐秘雷点)。但他们难以将这份内容在文档中构建并阐述给模型。

更糟的是,仅仅通过类似对 AI 提问:"帮我总结出这个项目结构并输出 md 文档",有时反而会加重模型的幻觉------这些对 AI 来说莫名其妙的文档最终成为噪声,干扰着解决问题的进度。
这就是为什么在维护代码时,将脑中的HIGH LEVEL VIEW转换为一份清晰的 Intent Layer 至关重要 。(Intent Layer 是 Intent-system提出的概念,帮助解决程序员如何将脑内图景转换为可被 AI 接受的信息,我就不做搬运工了,感觉把别人文章翻译一下粘过来怪怪的)。这里给大家推荐两个地址
不再卷框架,而是去读"说明书"
回想 2023 年之前,作为一个合格的前端或全栈工程师,我们的学习精力分配大致是这样的:
- 40%:研究框架的新特性 (React Hooks、Vue Composition API、Server Components)
- 40%:各种生态与工具链 (状态管理、路由、构建工具)
- 20%:业务逻辑与算法
这一套逻辑在当时是完全成立的------个人对框架源码的掌控度 ≈ 个人生产力上限。
现在的游戏规则变了
现在的 AI 模型(例如 Claude Opus 4.5、GPT 5.2),在配合 Context7 MCP Server 对主流框架和 API 的熟悉程度,已经远远超过绝大多数开发者。 当我想让它写一个「带 Virtual Scroll 的 Vue 3 表格组件」,它不仅写得比我快,很多时候还更规范。
于是,真正的分水岭出现了:
个人的竞争力,不再是他记得多少 API, 而是这个人能否让他的 IDE 发挥出上限。
而这件事,远不只是"会不会写提示词"。
理解手中的工具
当我们开始依赖 Claude、Cursor、Trae 这类工具时,本质上已经进入了一个新的抽象层:
你不再是直接写代码的人,而是在配置一个"智能体运行环境"。
这时再去无休止地追逐新框架,性价比已经极低。 那部分精力,更值得投入到比如 Claude Docs、Trae Blog 、各类 Agent / Skill / Subagent 的设计说明。
这件事本身其实并不陌生。
以前我们写 JavaScript,本质上是: JS → 编译 → C / LLVM → 浏览器执行
现在只是换了一条链路: 自然语言 → IDE Agent → 代码 → 编译 → 执行
中间多出来的,是一个你必须理解的"黑箱"。
Claude 的 Subagent 与 Skill
以 Claude 为例: 虽然我个人并不认同 Anthropic 对国区的态度,也不喜欢他们的行事风格,但不得不承认:他们在生态设计上提出了一些非常超前、且极具通用性的概念。
其中最关键的两个是:
- Subagent:用于隔离上下文
- Skill:通过逐步披露,节省并保护上下文
Subagent以极为有效的方式隔离上下文,而 Skill依靠逐步披露的方式进一步简单粗暴的保护 & 节省上下文。
在 Claude docs 文档中明确表示,最初 Skill 仅仅展示给 Claude 的内容只有如:
bash
---
name: code-reviewer
description: Review code for quality and best practices
skills: pr-review, security-check
---这意味着什么?
- Context 并不是一次性灌给模型的
- 能力是按需、逐步"解锁"的
- 单个 Subagent 可以在特定场景下,被临时"放大"为一种近似 MoE(Mixture of Experts) 的行为模式
我非常确信: 这种机制在不久的将来,会引发大量开发者参与,形成一个类似早期 MCP Server 的 Skill 生态,甚至与 MCP 联动。
而且几乎可以确定------ Cursor、Trae 很快都会出现类似的设计。
它们解决的,其实是同一个问题
无论是 Subagent、Skill,还是 MCP,本质上都在做一件事:
帮助我们更高效地,把 High-Level View 映射到可执行的 Intent Layer。
2026年的自救,本质上是一场职能跃迁: 我们必须从"代码工人"转型为"配置智能体运行环境的架构师"。
写在最后
本文并不是在希望之后每个人都是 24 小时盯着各家模型厂商的文档更新过日子。
但至少,值得问自己一个问题:
我是真的理解"现在正在发生什么", 还是只是在短视频里听过一个模糊的概念?
很多时候,没有什么比那些正在维护、正在研发这些系统的人亲自写下的文档,更能准确描述当下的现实。