Python后端开发之旅(三)
- Python进阶------LangChain
-
- [✅ 1. LangChain 0.1.x vs 1.0:版本演进与主要区别](#✅ 1. LangChain 0.1.x vs 1.0:版本演进与主要区别)
- [✅ 2. 快速入门 LangChain(1.0)](#✅ 2. 快速入门 LangChain(1.0))
-
- [📦 1. 安装](#📦 1. 安装)
- [🧩 2. 核心概念图谱(类比 Java)](#🧩 2. 核心概念图谱(类比 Java))
- [🧱 3. 基础组件详解](#🧱 3. 基础组件详解)
-
- [✅ 3.1 LLM(大语言模型)](#✅ 3.1 LLM(大语言模型))
-
- [使用 OpenAI(最常见)](#使用 OpenAI(最常见))
- [自定义 LLM 类(高级用法)------invoke()](#自定义 LLM 类(高级用法)——invoke())
- [✅ 3.2 提示模板(PromptTemplate)](#✅ 3.2 提示模板(PromptTemplate))
- [✅ 3.3 工具(Tools)和工具包(Toolkits)](#✅ 3.3 工具(Tools)和工具包(Toolkits))
-
- [自定义工具(类似 Java 的 Service)](#自定义工具(类似 Java 的 Service))
- 工具包(Toolkit)
- [✅ 3.4 消息(Messages)与历史记录(Memory)](#✅ 3.4 消息(Messages)与历史记录(Memory))
- [✅ 3.5 输出解析(Output Parsing)](#✅ 3.5 输出解析(Output Parsing))
-
- [目标:让模型返回结构化数据(如 JSON)](#目标:让模型返回结构化数据(如 JSON))
- [✅ 3.6 回调处理(Callbacks)](#✅ 3.6 回调处理(Callbacks))
- [✅ 3.7 LCEL(LangChain Expression Language)](#✅ 3.7 LCEL(LangChain Expression Language))
-
- [示例:一个简单的 LCEL 流程](#示例:一个简单的 LCEL 流程)
- 更复杂的例子:带条件判断
- [✅ 3. 调用方式区别(https://blog.csdn.net/cooldream2009/article/details/153470815)](#✅ 3. 调用方式区别)
- [✅ 4. 项目实战:构建一个智能问答助手](#✅ 4. 项目实战:构建一个智能问答助手)
-
- [🎯 功能:](#🎯 功能:)
- [🛠️ 代码结构](#🛠️ 代码结构)
- Python进阶------动态导入机制
- [Python进阶------Protobuf (gRPC)服务通信](#Python进阶——Protobuf (gRPC)服务通信)
-
- [🌟 Protobuf (gRPC) 服务通信](#🌟 Protobuf (gRPC) 服务通信)
-
- [✅ 什么是 Protobuf?](#✅ 什么是 Protobuf?)
- [✅ 什么是 gRPC?](#✅ 什么是 gRPC?)
- 实际案例
-
- [🔧 步骤一:安装依赖](#🔧 步骤一:安装依赖)
- [📄 步骤二:编写 `.proto` 文件](#📄 步骤二:编写
.proto文件) - [🛠️ 步骤三:生成 Python 代码](#🛠️ 步骤三:生成 Python 代码)
- [🧪 步骤四:实现服务端(Server)](#🧪 步骤四:实现服务端(Server))
- [🧩 步骤五:实现客户端(Client)](#🧩 步骤五:实现客户端(Client))
- [✅ 运行顺序](#✅ 运行顺序)
- [✅ 优点 & 场景](#✅ 优点 & 场景)
- [Python进阶------Celery 处理异步任务调度](#Python进阶——Celery 处理异步任务调度)
-
- [🌟 Celery 处理异步任务调度](#🌟 Celery 处理异步任务调度)
-
- [✅ 什么是 Celery?](#✅ 什么是 Celery?)
- [🧰 步骤一:准备消息中间件(推荐用 Redis 或 RabbitMQ)](#🧰 步骤一:准备消息中间件(推荐用 Redis 或 RabbitMQ))
-
- [方法一:使用 Redis(简单)](#方法一:使用 Redis(简单))
- [方法二:使用 RabbitMQ](#方法二:使用 RabbitMQ)
- [📦 步骤二:安装 Celery](#📦 步骤二:安装 Celery)
- [🧪 步骤三:定义任务(task.py)](#🧪 步骤三:定义任务(task.py))
- [🛠️ 步骤四:启动 Celery Worker](#🛠️ 步骤四:启动 Celery Worker)
- [🧪 步骤五:调用任务(main.py)](#🧪 步骤五:调用任务(main.py))
- [⏱️ 步骤六:定时任务(Cron 任务)](#⏱️ 步骤六:定时任务(Cron 任务))
- [✅ 优势与使用场景](#✅ 优势与使用场景)
- [Python进阶------Celery + Web](#Python进阶——Celery + Web)
-
- [✅ 第一部分:Flask + Celery 示例](#✅ 第一部分:Flask + Celery 示例)
-
- [📦 准备工作](#📦 准备工作)
-
- [1. 安装依赖](#1. 安装依赖)
- [2. 启动 Redis(本地运行)](#2. 启动 Redis(本地运行))
- [🧪 步骤一:创建核心文件结构](#🧪 步骤一:创建核心文件结构)
- [🧩 步骤二:定义 Celery 任务(tasks.py)](#🧩 步骤二:定义 Celery 任务(tasks.py))
- [🧩 步骤三:编写 Flask 主程序(app.py)](#🧩 步骤三:编写 Flask 主程序(app.py))
- [🧠 关键点解析](#🧠 关键点解析)
-
- [🔹 `app = Flask(name)`](#🔹
app = Flask(__name__)) - [🔹 `app.config'CELERY_BROKER_URL'`](#🔹
app.config['CELERY_BROKER_URL']) - [🔹 `app.config'CELERY_RESULT_BACKEND'`](#🔹
app.config['CELERY_RESULT_BACKEND']) - [🔹 `CORS(app)`](#🔹
CORS(app)) - [🔹 `make_celery(app)` 函数](#🔹
make_celery(app)函数)
- [🔹 `app = Flask(name)`](#🔹
- [🧪 启动方式](#🧪 启动方式)
- [📡 测试接口](#📡 测试接口)
-
- [1. 提交任务](#1. 提交任务)
- [2. 查询任务状态](#2. 查询任务状态)
- [✅ 第二部分:FastAPI + Celery 示例](#✅ 第二部分:FastAPI + Celery 示例)
-
- [📦 依赖安装](#📦 依赖安装)
- [🧩 文件结构](#🧩 文件结构)
- [🧩 任务定义(tasks.py)同上 ✅](#🧩 任务定义(tasks.py)同上 ✅)
- [🧩 FastAPI 主程序(main.py)](#🧩 FastAPI 主程序(main.py))
- [🧠 关键点解析](#🧠 关键点解析)
-
- [🔹 `app = FastAPI()`](#🔹
app = FastAPI()) - [🔹 `app.state.celery`](#🔹
app.state.celery) - [🔹 `BackgroundTasks`](#🔹
BackgroundTasks) - [🔹 `CORSMiddleware`](#🔹
CORSMiddleware)
- [🔹 `app = FastAPI()`](#🔹
- [🚀 启动测试](#🚀 启动测试)
- [🎯 总结对比表](#🎯 总结对比表)
- [✅ 最佳实践建议](#✅ 最佳实践建议)
-
- [✅ 1. 环境变量管理(推荐)](#✅ 1. 环境变量管理(推荐))
- [✅ 2. 日志记录与监控](#✅ 2. 日志记录与监控)
- [✅ 3. 任务重试机制](#✅ 3. 任务重试机制)
- [📘 下一步提升](#📘 下一步提升)
Python进阶------LangChain

✅ 1. LangChain 0.1.x vs 1.0:版本演进与主要区别
LangChain 的第一个稳定版本 ,即 LangChain 0.1.0,于 2024 年 1 月 8 日正式发布,这是一个值得庆祝的里程碑,也是 LangChain 项目的一个新的起点
LangChain 的版本号由三个部分组成,即主版本号、次版本号和修订号,分别表示 LangChain 的大的、中等的和小的更新。例如,LangChain 0.1.0 表示 LangChain 的第 0 个主版本,第 1 个次版本,第 0 个修订版本
| 特性 | LangChain 0.1.x(旧版) | LangChain 1.0(新版) |
|---|---|---|
| 发布时间 | 2024 年 1 月 8 日 | 2025年10月23日 |
| 核心理念 | 模块松散,流程不统一 | 统一、可组合、强类型 |
🔍 关键总结:
- 0.1.x → 多个独立类(如
LLMChain,AgentExecutor)- **1.0 → 统一
Runnable接口,所有组件都是Runnable,模块重组,代码也得改变
✅ 2. 快速入门 LangChain(1.0)
📦 1. 安装
bash
pip install langchain langchain-openai # 以 OpenAI 为例💡 你也可以用其他 LLM 提供商,如 Anthropic、Cohere、Claude、Google Vertex AI ,DeepSeek等
🧩 2. 核心概念图谱(类比 Java)
| LangChain 概念 | 类比 Java 开发 | 说明 |
|---|---|---|
LLM |
RestTemplate / FeignClient |
调用大模型 API |
PromptTemplate |
String.format() + @Value |
动态生成提示词 |
Runnable |
Function<T, R> / Supplier<T> |
所有组件都实现此接口 |
Chain |
Service + Controller |
逻辑处理 链 |
Tool |
@Component + @Autowired |
工具函数,用于 Agent |
Memory |
Session / Cache |
记忆历史对话 |
LCEL |
Spring Expression Language | 链式表达式语法 (` |
Callback |
Interceptor / AOP |
日志、监控、追踪 |
promet,llm,parser
- Conversational(Agent):用于与用户进行自然对话,并接收用户提出的问题,根据提问内容选择具体使用的处理工具
- RetrievalQA(Retriever):用于从自定义资料集中检索相关内容。
DuckDuckGoSearchRun(tool): 用于访问DuckDuckGoSearch搜索API- Prompts & Structured output parser(ModelIO):用于定义接收对话的模板以及结构化搜索引擎查询到的结果并生成一个简洁和准确的回答。
SequentialChain(Chain):用于按照顺序执行以上组件,并将每个组件的输出作为下一个组件的输入- ConversationBufferMemory(Memory):用于在对话中记住以前的交互置,以便在后续的对话中使用。
StdOutCallbackHandler:标准输出用于进行日志记录。
🧱 3. 基础组件详解
✅ 3.1 LLM(大语言模型)
使用 OpenAI(最常见)
python
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4-turbo", temperature=0.7)📝 你可以通过
os.getenv("OPENAI_API_KEY")读取密钥
自定义 LLM 类(高级用法)------invoke()
python
from langchain_core.runnables import Runnable
class CustomLLM(Runnable):
def invoke(self, input: str, config: dict = None):
# 实现自己的大模型调用逻辑
return f"Custom response to: {input}"
# 使用
custom_llm = CustomLLM()
result = custom_llm.invoke("Hello")
print(result)✅ 这样就可以把你的私有模型或本地模型接入 LangChain!
✅ 3.2 提示模板(PromptTemplate)
使用format()进行填入
python
from langchain_core.prompts import PromptTemplate
prompt = PromptTemplate.from_template(
"You are a helpful assistant. Answer the question: {question}"
)
# 生成最终提示
formatted_prompt = prompt.format(question="What is Python?")
print(formatted_prompt)
# 输出: You are a helpful assistant. Answer the question: What is Python?✅ 支持变量替换,可用于动态生成提示
✅ 3.3 工具(Tools)和工具包(Toolkits)
自定义工具(类似 Java 的 Service)
python
from langchain_core.tools import tool
import requests
@tool
def get_weather(city: str) -> str:
"""获取指定城市的天气"""
url = f"https://api.weather.com/forecast?city={city}"
response = requests.get(url)
return response.json()["temperature"] if response.ok else "Error"工具包(Toolkit)
python
from langchain_community.tools import DuckDuckGoSearchRun
search_tool = DuckDuckGoSearchRun()✅ 工具可以被 Agent 调用,实现"查询互联网"功能
✅ 3.4 消息(Messages)与历史记录(Memory)
消息格式(类似聊天上下文)
-
消息是LangChain中对话交互的基本单元,分为两类:
- HumanMessage:表示用户输入(如提问或指令)
- AIMessage:表示AI模型的响应
python
from langchain_core.messages import HumanMessage, AIMessage
messages = [
HumanMessage(content="Hello"),
AIMessage(content="Hi! How can I help?")
]记忆机制(Memory)
-
记忆模块用于持久化存储和管理对话历史,常见类型包括:
- ConversationBufferMemory:完整保存所有对话记录
- ConversationBufferWindowMemory:仅保留最近N轮对话
- ConversationSummaryMemory:用LLM摘要压缩长对话
python
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
memory.chat_memory.add_user_message("Hello")
memory.chat_memory.add_ai_message("Hi! How can I help?")- 保存对话历史供后续调用(如多轮对话上下文)
- 支持通过
memory.load_memory_variables()读取历史
✅ 类似 Session,但持久化更灵活
✅ 3.5 输出解析(Output Parsing)
目标:让模型返回结构化数据(如 JSON)
python
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
parser = JsonOutputParser()
prompt = PromptTemplate(
template="Answer only in JSON format: {question}",
input_variables=["question"]
)
chain = prompt | llm | parser
result = chain.invoke({"question": "Who is the CEO of Tesla?"})
print(result)
# 输出: {"name": "Elon Musk"}✅ 避免模型返回自由文本,提升结构化能力
✅ 3.6 回调处理(Callbacks)
用于日志、追踪、调试
python
from langchain.callbacks import StdOutCallbackHandler
callbacks = [StdOutCallbackHandler()]
llm.invoke("Hello", callbacks=callbacks)✅ 可扩展为:
LangChainTracer、LangSmithCallbackHandler(企业级追踪)
LangChain 借助LangSmith提供了更好的日志、可视化、播放和跟踪功能,以便监控和调试 LLM 应用。LangSmith 是一个基于 Web 的工具,用于可视化和控制 LangChain 的链和代理,能够查看和分析 细化到class的输入和输出
✅ 3.7 LCEL(LangChain Expression Language)
用
|链接模块,像流水线一样执行就像
unix的管道机制
示例:一个简单的 LCEL 流程
python
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnableLambda, RunnableSequence
# 1. 提示模板
prompt = PromptTemplate.from_template("Translate this to English: {text}")
# 2. Lambda 函数:转成大写
uppercase = RunnableLambda(lambda x: {"text": x["text"].upper()})
# 3. 链接:先转大写,再翻译
chain = uppercase | prompt | llm
# 执行
result = chain.invoke({"text": "你好世界"})
print(result.content)- RunnableLambda:将普通 Python 函数包装为 LangChain 可执行的组件
- RunnableBranch 是 LangChain 中用于根据条件选择不同执行路径的组件
- RunnableBranch 接受多个条件判断对
(condition, component)以及一个默认的 fallback 函数 - 每个条件判断对的结构是:
(condition, component),其中:- condition 是一个函数,用于判断输入是否满足某个条件。
- component 是一个可执行的组件(如 RunnableLambda),如果条件满足,则会执行该组件。
- 如果所有条件都不满足,则执行最后一个 fallback 函数
- RunnableBranch 接受多个条件判断对
更复杂的例子:带条件判断
python
from langchain_core.runnables import RunnableBranch
branch = RunnableBranch(
(lambda x: x["text"].startswith("hello"), lambda x: "Hello!"),
(lambda x: x["text"].startswith("hi"), lambda x: "Hi!"),
lambda x: "Unknown greeting"
)
result = branch.invoke({"text": "hello world"})✅ 3. 调用方式区别
- invoke():一次性同步调用,等待完整输出后返回。
- stream():流式异步调用,边生成边返回。就是流式响应!!!
- LangChain会将这些结果作为生成器 逐步返回,开发者可在接收到每个分片(chunk)时进行实时处理或显示

- LangChain会将这些结果作为生成器 逐步返回,开发者可在接收到每个分片(chunk)时进行实时处理或显示
- 有时我们既想实时输出,又想保存完整结果:
python
chunks = []
for chunk in llm.stream("请解释RAG的原理。"):
print(chunk.content, end="", flush=True)
chunks.append(chunk.content)
full_output = "".join(chunks)✅ 4. 项目实战:构建一个智能问答助手
🎯 功能:
- 接收用户问题
- 使用 LLM 生成回答
- 支持简单工具(如搜索)
- 保留聊天历史
🛠️ 代码结构
python
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough, RunnableSequence
from langchain_core.messages import HumanMessage, AIMessage
from langchain_openai import ChatOpenAI
from langchain_community.tools import DuckDuckGoSearchRun
from langchain_community.utilities import WikipediaAPIWrapper
from langchain_core.output_parsers import StrOutputParser
# 1. 初始化 LLM
llm = ChatOpenAI(model="gpt-4-turbo")
# 2. 定义工具
search_tool = DuckDuckGoSearchRun()
wikipedia = WikipediaAPIWrapper()
# 3. 创建提示模板
prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant."),
("human", "{question}")
])
# 4. 构建 LCEL 流程
chain = (
{
"question": RunnablePassthrough(),
"context": RunnableLambda(lambda x: search_tool.invoke(x["question"]))
}
| prompt
| llm
| StrOutputParser()
)
# 5. 运行
result = chain.invoke({"question": "Who is Elon Musk?"})
print(result)- 使用 LangChain 表达式语言(LCEL)构建处理流程:
- 接收输入问题并原样传递(
RunnablePassthrough) - 使用搜索工具获取问题相关上下文
- 将问题和上下文传递给提示模板
- 将模板输出传递给LLM
- 最后使用字符串输出解析器
- 接收输入问题并原样传递(
- 使用
LangChain构建一个结合外部搜索的问答系统。 - 检索到的信息会作为上下文提供给LLM,帮助生成更准确的回答
Python进阶------动态导入机制
通过反射机制
import
getattr
Python进阶------Protobuf (gRPC)服务通信
🌟 Protobuf (gRPC) 服务通信
💡 目标:使用
.proto文件定义接口,通过 gRPC 实现跨语言的服务调用(如 Python → Python 或 Python → Go/Java 等)
✅ 什么是 Protobuf?
Protobuf(Protocol Buffers)是 Google 开发的一种数据序列化协议,类似于 JSON 或 XML,但更高效、更紧凑。
- 它允许你用
.proto文件描述数据结构。 - 然后通过工具生成对应语言(Python、Java、Go 等)的类。
- 常用于微服务之间的通信。
⚠️ 注意:Protobuf 是"数据格式",而 gRPC 是基于它的"通信框架"。
✅ 什么是 gRPC?
gRPC 是一个高性能、开源的远程过程调用(RPC)框架,由 Google 发起,它:
- 使用 HTTP/2 协议
- 基于 Protobuf 定义服务接口
- 支持多种语言(Python、Java、Go、C++ 等)
- 支持双向流、单向流、请求-响应等模式
💡 类比:就像 REST API 用 JSON 传数据,gRPC 用 Protobuf 传数据,并且支持更复杂的通信方式。
- Official support versions------python 3.8+
- 服务端开发:继承生成的 Servicer 类实现业务逻辑
- 客户端调用:通过 Stub 类发起 RPC 请求,调用服务端的方法
实际案例
🔧 步骤一:安装依赖
bash
pip install grpcio grpcio-tools protobuf📄 步骤二:编写 .proto 文件
创建文件 helloworld.proto:
protobuf
syntax = "proto3";
package helloworld;
// 定义消息类型
message HelloRequest {
string name = 1;
}
message HelloResponse {
string message = 1;
}
// 定义服务
service Greeter {
rpc SayHello (HelloRequest) returns (HelloResponse);
}解释:
syntax = "proto3";:使用 Protobuf 第三版语法package helloworld;:命名空间,防止冲突message:定义数据结构service:定义可以被调用的方法(类似接口)rpc SayHello (HelloRequest) returns (HelloResponse);:表示这个服务有一个方法叫SayHello,接收HelloRequest返回HelloResponse
🛠️ 步骤三:生成 Python 代码
使用 protoc 编译器生成 Python 代码。
bash
# 生成 Python 代码
python -m grpc_tools.protoc -I. --python_out=. --grpc_python_out=. helloworld.proto生成文件:
helloworld_pb2.py(消息类)
helloworld_pb2_grpc.py(服务接口)
核心参数说明
-
-I.或--proto_path=.- 作用 :指定
.proto文件的搜索路径(当前目录为.)。 - 示例 :若文件在
src/protos目录下,需改为-Isrc/protos。
- 作用 :指定
-
--python_out=.- 作用 :生成 Protobuf 消息类的 Python 代码(
*_pb2.py),输出到当前目录。 - 文件内容:包含消息的序列化/反序列化方法和字段定义
- 作用 :生成 Protobuf 消息类的 Python 代码(
-
--grpc_python_out=.- 作用 :生成 gRPC 服务接口的 Python 代码(
*_pb2_grpc.py),输出到当前目录。 - 文件内容 :包含服务端
Servicer基类和客户端Stub类
- 作用 :生成 gRPC 服务接口的 Python 代码(
-
helloworld.proto- 作用 :指定输入的 Protocol Buffers 文件。支持通配符(如
*.proto)批量编译[1][5]。
- 作用 :指定输入的 Protocol Buffers 文件。支持通配符(如
- 依赖安装 :需提前通过
pip install grpcio-tools安装编译工具
helloworld_pd2.py(消息类)
它被用来创建 请求 和 响应 消息对象
python
class HelloRequest:
def __init__(self):
self.name = ""
class HelloReply:
def __init__(self):
self.message = ""
# 序列化和反序列化方法
def SerializeToString(self):
# 序列化逻辑
pass
def ParseFromString(self, data):
# 反序列化逻辑
pass- 定义消息类:
- 包含了proto文件中定义的所有消息类型,这些消息类型被转换为Python类
- 序列化和反序列化:
- 提供了将消息对象序列化为字节流(用于网络传输)和从字节流反序列化为消息对象的功能
helloworld_pd2_grpc.py(服务接口)
由proto文件中的服务定义生成的,用于定义gRPC服务的接口和实现
-
服务接口类
GreeterServicer:- 包含了proto文件中定义的服务接口(service),并为每个服务方法生成了抽象类,自己写的服务端需要实现GreeterServicer类
- 例如,Greeter服务会生成一个
GreeterServicer抽象类,其中包含SayHello方法的定义。
-
服务注册函数add_GreeterServicer_to_server:
- 提供了将服务实现绑定到gRPC服务器的方法。例如,
add_GreeterServicer_to_server方法用于将服务实现注册到服务器。
- 提供了将服务实现绑定到gRPC服务器的方法。例如,
-
客户端存根类GreeterStub:
- 为客户端生成了服务的存根(Stub),用于调用服务端的方法。例如,
GreeterStub类允许客户端调用SayHello方法
- 为客户端生成了服务的存根(Stub),用于调用服务端的方法。例如,
python
class GreeterServicer:
def SayHello(self, request, context):
raise NotImplementedError()
def add_GreeterServicer_to_server(servicer, server):
# 注册服务到服务器的逻辑
pass
class GreeterStub:
def SayHello(self, request):
# 调用服务端方法的逻辑
pass🧪 步骤四:实现服务端(Server)
python
import grpc
from concurrent import futures
import helloworld_pb2
import helloworld_pb2_grpc
# 实现服务
class Greeter(helloworld_pb2_grpc.GreeterServicer):
def SayHello(self, request, context):
# 接收 client 的 name,返回问候语
return helloworld_pb2.HelloReply(message=f"Hello, {request.name}!")
# 启动服务器
def serve():
# 创建线程池(最大10个工作线程)
server = grpc.server(futures.ThreadPoolExecutor(max_workers=10))
# 注册服务实现
helloworld_pb2_grpc.add_GreeterServicer_to_server(Greeter(), server)
server.add_insecure_port('[::]:50051') # 监听地址
print("Server started on port 50051")
server.start()
try:
server.wait_for_termination()
except KeyboardInterrupt:
server.stop(0)
if __name__ == '__main__':
serve()🔍 模拟客户端调用前先运行此服务!
from concurrent import futures:导入concurrent.futures模块,用于创建线程池。gRPC服务器需要一个线程池来处理并发请求- request:客户端发送的HelloRequest对象,包含name字段
- context:提供RPC上下文信息(如超时、元数据等)
- 返回值必须是HelloReply类型,与Protobuf定义一致
- ':::50051'表示监听所有网络接口的50051端口。insecure表示不使用加密(仅用于本地测试)
- start():启动服务器,开始监听客户端请求。
- server.wait_for_termination():阻塞主线程,直到服务器被关闭。这通常用于保持服务器运行
- server.stop(0):如果捕获到KeyboardInterrupt(如用户按下Ctrl+C),则停止服务器。0表示立即停止
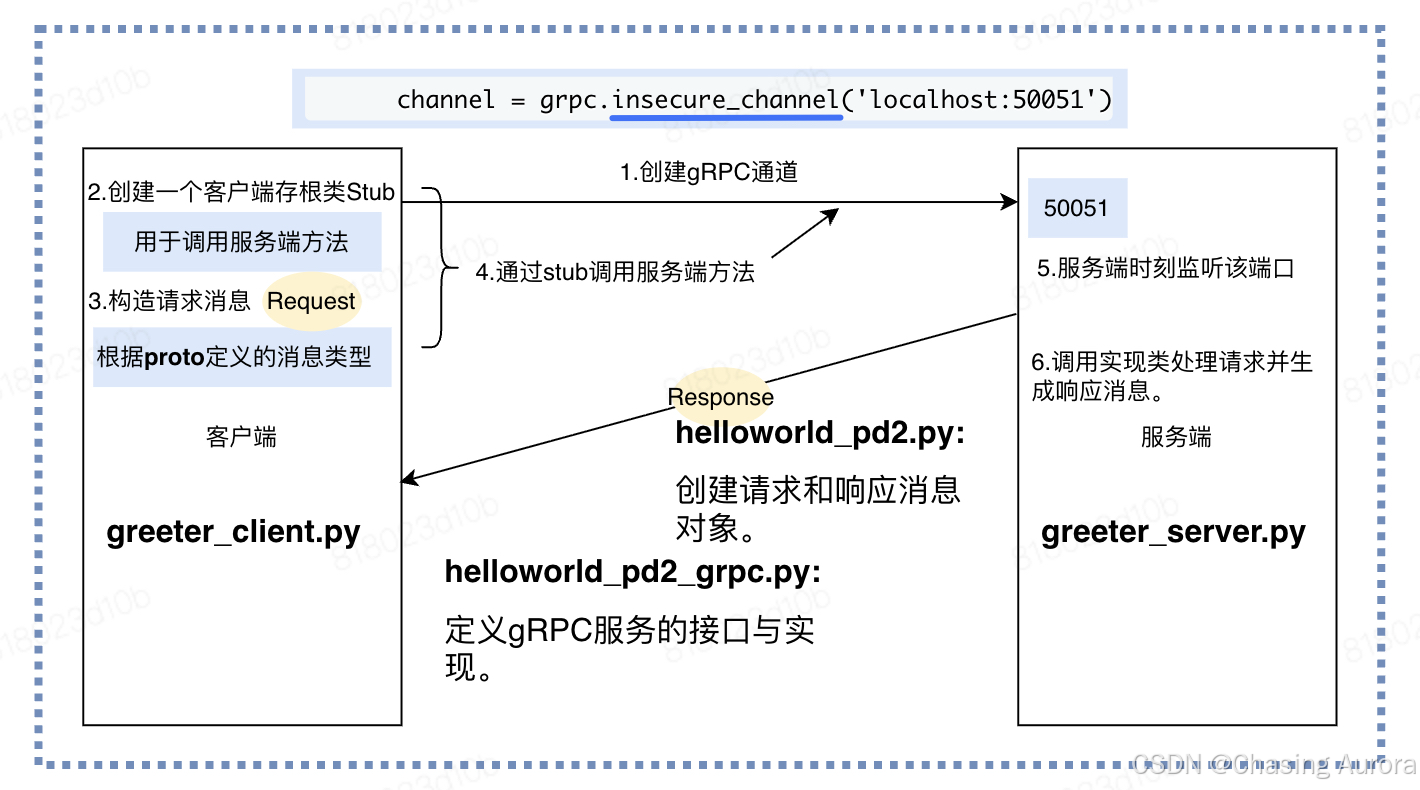
🧩 步骤五:实现客户端(Client)
python
import grpc
import helloworld_pb2
import helloworld_pb2_grpc
def run():
with grpc.insecure_channel('localhost:50051') as channel:
stub = helloworld_pb2_grpc.GreeterStub(channel)# 创建一个GreeterStub对象,它是客户端代理,用于调用服务端定义的Greeter服务。
request = helloworld_pb2.HelloRequest(name='World')# 创建一个HelloRequest消息对象,并设置name字段为"World"。这是客户端发送给服务端的请求数据。
response = stub.SayHello(request)# 调用服务端的SayHello方法,将request对象作为参数传递。服务端处理后返回一个HelloReply消息对象。
print("Greeter client received: " + response.message)# 打印服务端返回的响应消息中的message字段。
if __name__ == '__main__':
run()- 创建一个gRPC通道,连接到运行在localhost:50051的服务端
- insecure_channel表示不使用加密连接(仅用于本地测试)
✅ 运行顺序
-
先运行服务端脚本(
server.py) -
再运行客户端脚本(
client.py) -
输出:
Server started on port 50051 Received: Hello, Alice!
✅ 优点 & 场景
| 特性 | 说明 |
|---|---|
| 高性能 | 序列化快,二进制传输,比 JSON 快很多 |
| 跨语言 | 可以用 Python、Java、Go 互相调用 |
| 流式支持 | 支持双向流(适合实时聊天、日志收集) |
| 接口清晰 | 所有接口都在 .proto 里明确定义 |
🚀 典型用途:微服务间通信、API 网关、分布式系统调用
Python进阶------Celery 处理异步任务调度
🌟 Celery 处理异步任务调度
💡 目标:将耗时任务(如发送邮件、处理图片)放入队列,由后台 worker 异步执行,不阻塞主程序
✅ 什么是 Celery?
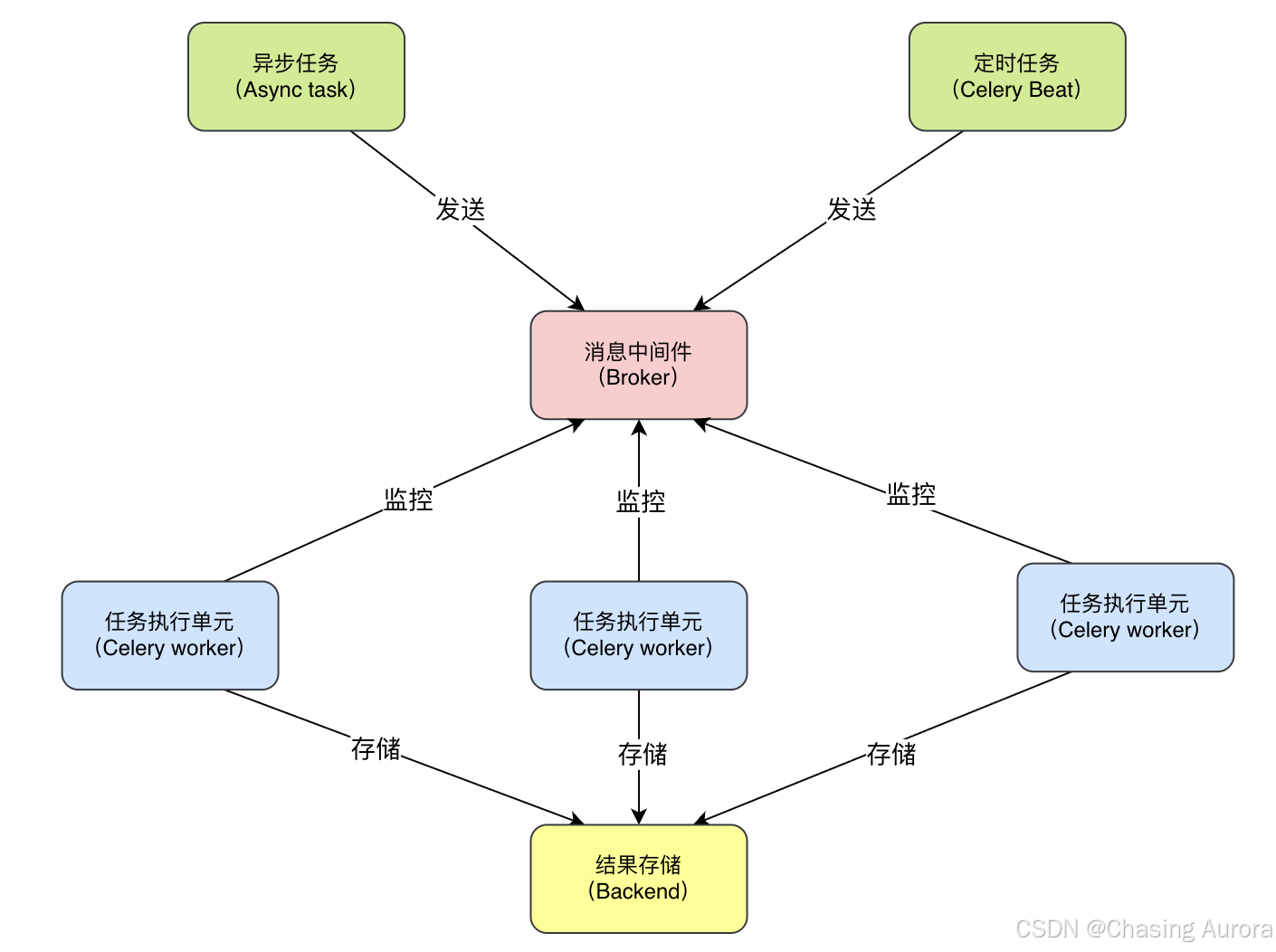
Celery 是一个分布式任务队列系统,常用于:
- 异步任务执行(如发送邮件、生成报表)
- 定时任务(定时清理缓存)
- 分布式任务处理(多个 worker 并行工作)
核心组件:
| 组件 | 作用 |
|---|---|
| Broker(消息中间件) | 存储任务,比如 RabbitMQ、Redis |
| Worker | 消费任务并执行 |
| Result Backend | 保存任务结果(可选) |
🔄 工作流程:
主程序 → 发送任务到 Broker → Worker 拿取 → 执行 → 结果返回(可选)
- Version Requirements
- Celery本身不支持Windows,因此可能会遇到 挺多的问题的呢!
celery本身不具备任务存储的能力,做不到任务存储的功能,因此在使用Celery时还需要搭配一些具备存储、访问的工具,如消息队列,Redies等等。(Tower线上:broker用RabbitMQ、Backend用redies|线下都用redies)
如果没有配置 backend,那么获取结果的时候会报错
🧰 步骤一:准备消息中间件(推荐用 Redis 或 RabbitMQ)
方法一:使用 Redis(简单)
bash
# 启动 Redis 服务(本地)
redis-server方法二:使用 RabbitMQ
bash
# 安装 RabbitMQ(macOS)
brew install rabbitmq
rabbitmq-server📦 步骤二:安装 Celery
bash
pip install celery[redis] # 如果用 Redis
# 或者用 RabbitMQ
pip install celery amqp🧪 步骤三:定义任务(task.py)
python
from celery import Celery
import time
# 创建 Celery 应用实例
app = Celery('tasks', broker='redis://localhost:6379/0', backend='redis://localhost:6379/0')
@app.task
def add(x, y):
"""这是一个耗时任务"""
time.sleep(5) # 模拟耗时操作
return x + y
@app.task
def send_email(to, subject):
print(f"Sending email to {to}, subject: {subject}")
time.sleep(3)
return f"Email sent to {to}"💡
@app.task装饰器表示这是一个可被 Celery 执行的任务
🛠️ 步骤四:启动 Celery Worker
在终端运行:
bash
celery -A task.app worker --loglevel=info-
-A task.celery_app-A或--app指定 Celery 应用模块的路径。这里的task.celery_app表示从task.py模块中加载名为app的 Celery 应用实例
-
worker- 启动 Celery 的工作进程(Worker),用于执行异步任务。Worker 是任务执行的核心单元,负责从消息队列中获取并处理任务
- 在 5.0 之前我们可以写成
celery worker -A app ...,也就是把所有的参数都放在子命令celery worker的后面。 - 但从 5.0 开始这种做法就不允许了,必须写成
celery -A app worker ...,因为 -A 变成了一个全局参数,所以它不应该放在 worker 的后面,而是要放在 worker 的前面
-
--loglevel=info- 设置日志级别为
info,控制日志输出的详细程度。info级别会记录常规的运行信息(如任务接收、执行完成等),适合生产环境调试。其他常见级别包括:debug:最详细,包含内部调试信息warning/error:仅记录警告或错误
- 设置日志级别为
输出示例:
[2024-04-05 10:00:00,000: INFO/ForkPoolWorker-1] Task add[xxx] received🧪 步骤五:调用任务(main.py)
python
from task import add, send_email
# 同步调用(等待结果)
result = add.delay(4, 5) # 异步执行
print("Task ID:", result.id)
print("Result:", result.get()) # 获取结果(会阻塞直到完成)
# 异步发送邮件
task = send_email.delay("user@example.com", "Welcome!")
print("Email task sent with ID:", task.id)🔁
delay()是异步发起任务,不会立即执行。
get()会阻塞直到任务完成并返回结果。
- 注意: 不要直接调用 task, 因为那样的话就在本地执行了, 我们的目的是将任务发送到队列里面去
- 我们需要调用它的 delay 方法,调用 delay 之后, 就会创建一个任务,然后发送到队列里面去,然后让监听队列的 worker 从队列里面取任务并执行
- 至于参数, 普通调用的时候怎么传, 在 delay 里面依旧怎么传
- 调用 delay 方法是不会阻塞的,花费的那 0.12 秒是用在了其它地方,比如连接 Redis 发送任务等等
直接查询任务执行信息
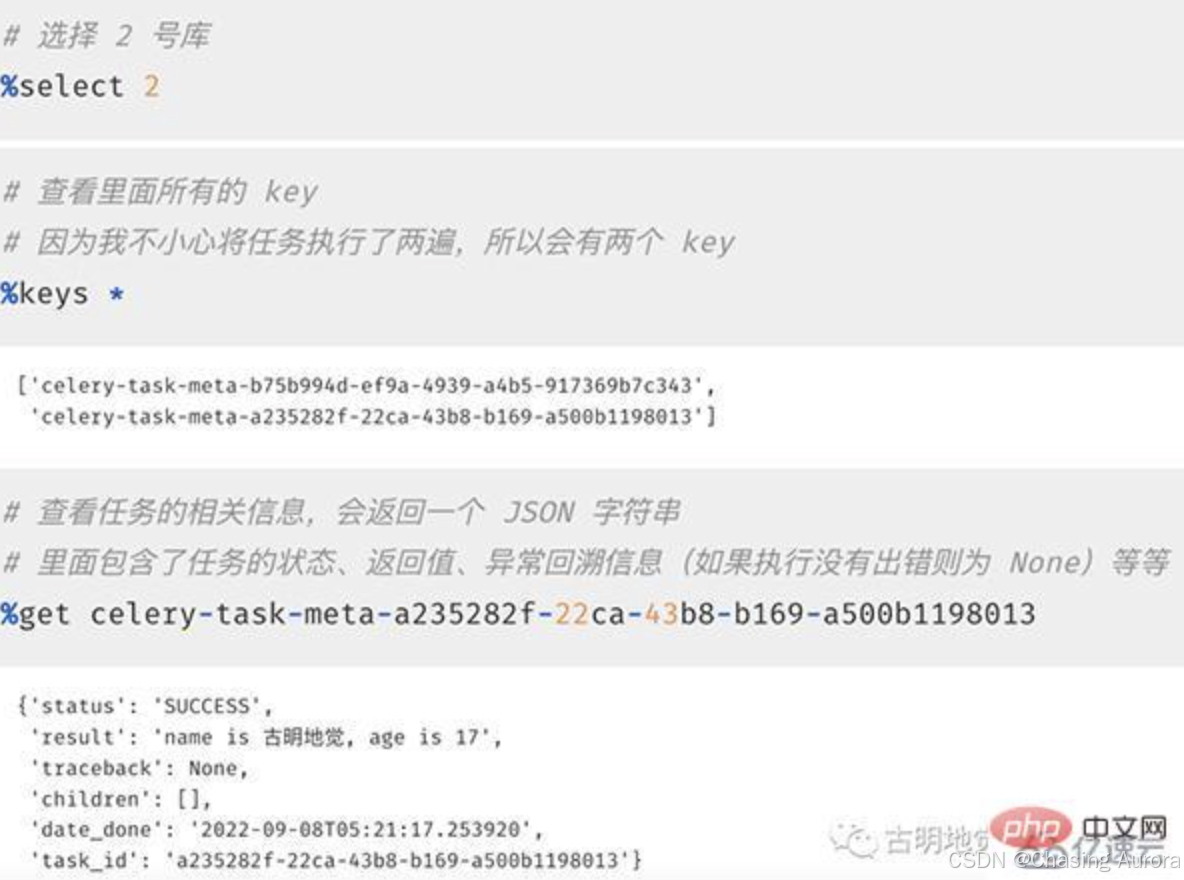
python
from app import task
res = task.delay("古明地觉", 17)
print(type(res))
""""""
# 直接打印,显示任务的 id
print(res)
"""
4bd48a6d-1f0e-45d6-a225-6884067253c3
"""
# 获取状态, 显然此刻没有执行完
# 因此结果是PENDING, 表示等待状态
print(res.status)
"""
PENDING
"""
# 获取 id,两种方式均可
print(res.task_id)
print(res.id)
"""
4bd48a6d-1f0e-45d6-a225-6884067253c3
4bd48a6d-1f0e-45d6-a225-6884067253c3
"""
# 获取任务执行结束时的时间
# 任务还没有结束, 所以返回None
print(res.date_done)
"""
None
"""
# 获取任务的返回值, 可以通过 result 或者 get()
# 注意: 如果是 result, 那么任务还没有执行完的话会直接返回 None
# 如果是 get(), 那么会阻塞直到任务完成
print(res.result)
print(res.get())
"""
None
name is 古明地觉, age is 17
"""
# 再次查看状态和执行结束时的时间
# 发现 status 变成SUCCESS
# date_done 变成了执行结束时的时间
print(res.status)
# 但显示的是 UTC 时间
print(res.date_done)
"""
SUCCESS
2022-09-08 06:40:34.525492
"""
# 1. ready():查看任务状态,返回布尔值
# 任务执行完成返回 True,否则为 False
# 那么问题来了,它和 successful() 有什么区别呢?
# successful() 是在任务执行成功之后返回 True, 否则返回 False
# 而 ready() 只要是任务没有处于阻塞状态就会返回 True
# 比如执行成功、执行失败、被 worker 拒收都看做是已经 ready 了
print(res.ready())
"""
False
"""
# 2. wait():和之前的 get 一样, 因为在源码中写了: wait = get
# 所以调用哪个都可以, 不过 wait 可能会被移除,建议直接用 get 就行
print(res.wait())
print(res.get())
"""
name is 古明地觉, age is 17
name is 古明地觉, age is 17
"""
# 3. trackback:如果任务抛出了一个异常,可以获取原始的回溯信息
# 执行成功就是 None
print(res.traceback)
"""
None
"""⏱️ 步骤六:定时任务(Cron 任务)
也可以设置定时任务(每分钟执行一次):
python
@app.task
def every_minute_task():
print("This runs every minute!")
# 在 main.py 中配置定时任务
from celery.schedules import crontab
app.conf.beat_schedule = {
'every-minute': {
'task': 'task.every_minute_task',
'schedule': crontab(minute='*'), # 每分钟执行
},
}
# 启动 beat 服务
# celery -A task.celery_app beat --loglevel=info✅ 优势与使用场景
| 场景 | 说明 |
|---|---|
| 发送邮件 | 用户注册后发送欢迎邮件,不卡页面 |
| 图片处理 | 用户上传图片 → 后台压缩/加水印 |
| 数据分析 | 大量数据计算,避免前端等待 |
| 定时任务 | 清理日志、统计报表生成 |
| 分布式部署 | 多个 worker 并行处理任务 |
Python进阶------Celery + Web
✅ 第一部分:Flask + Celery 示例
📦 准备工作
1. 安装依赖
bash
pip install flask celery[redis] redis2. 启动 Redis(本地运行)
bash
redis-server如果你用的是远程 Redis,请确保地址正确
🧪 步骤一:创建核心文件结构
project/
│
├── app.py # Flask 主程序
├── tasks.py # Celery 任务定义
└── requirements.txt🧩 步骤二:定义 Celery 任务(tasks.py)
python
from celery import Celery
import time
import random
# 创建 Celery 应用实例
celery_app = Celery('tasks', broker='redis://100.25.69.56:6379/0', backend='redis://100.25.69.56:6379/0')
@celery_app.task
def send_email(to, subject):
"""模拟发送邮件"""
print(f"Sending email to {to} with subject: {subject}")
time.sleep(5) # 模拟耗时操作
success = random.choice([True, False])
if success:
return f"Email sent successfully to {to}"
else:
raise Exception("Failed to send email")
@celery_app.task
def long_process(data):
"""长时间处理任务"""
time.sleep(10)
return f"Processed: {data.upper()}"💡 注意:
celery_app = Celery(...)是标准做法broker:Redis 地址(消息中间件)backend:用于保存任务结果(可选但推荐)
🧩 步骤三:编写 Flask 主程序(app.py)
python
from flask import Flask, jsonify, request
from tasks import celery_app, send_email, long_process
from celery.result import AsyncResult
from datetime import datetime
import uuid
# 初始化 Flask 应用
app = Flask(__name__)
# 配置 Celery
app.config['CELERY_BROKER_URL'] = 'redis://10.25.69.56:6379/0'
app.config['CELERY_RESULT_BACKEND'] = 'redis://10.25.69.56:6379/0'
# 配置 CORS(允许跨域访问)
from flask_cors import CORS
CORS(app)
# 注册 Celery 到 Flask 上下文
def make_celery(app):
celery = Celery(
app.import_name,
backend=app.config['CELERY_RESULT_BACKEND'],
broker=app.config['CELERY_BROKER_URL']
)
celery.conf.update(app.config)
return celery
# 使用自定义函数绑定 Celery
celery = make_celery(app)
# ================================
# API 接口定义
# ================================
@app.route('/api/send-email', methods=['POST'])
def send_email_task():
data = request.get_json()
to = data.get('to')
subject = data.get('subject', 'Welcome!')
if not to:
return jsonify({'error': 'Missing "to" field'}), 400
# 提交任务到 Celery
task = send_email.delay(to, subject)
return jsonify({
'task_id': task.id,
'status': 'PENDING',
'message': 'Email task submitted!'
})
@app.route('/api/check-task/<task_id>', methods=['GET'])
def check_task(task_id):
"""检查任务状态"""
result = AsyncResult(task_id, app=celery)
status = result.status
if status == 'SUCCESS':
return jsonify({
'task_id': task_id,
'status': status,
'result': result.result
})
elif status == 'PENDING':
return jsonify({
'task_id': task_id,
'status': status,
'message': 'Task is still running...'
})
elif status == 'FAILURE':
return jsonify({
'task_id': task_id,
'status': status,
'error': str(result.info)
})
else:
return jsonify({
'task_id': task_id,
'status': status,
'message': 'Unknown status'
})
@app.route('/api/long-process', methods=['POST'])
def long_process_task():
data = request.get_json()
task = long_process.delay(data.get('text', 'default'))
return jsonify({
'task_id': task.id,
'status': 'PENDING',
'message': 'Long process started!'
})
# ================================
# 启动服务
# ================================
if __name__ == '__main__':
app.run(debug=True, host='0.0.0.0', port=5000)🧠 关键点解析
🔹 app = Flask(__name__)
Flask(__name__):创建 Flask 应用对象__name__是当前模块名(通常为app.py),用于定位资源路径- 这是 Flask 的"入口"------所有路由都挂载在这个对象上
🔹 app.config['CELERY_BROKER_URL']
- 指定 消息队列服务器地址
- 必须和
.py中的broker一致 - 格式:
redis://host:port/db或amqp://user:pass@host:port/vhost
🔹 app.config['CELERY_RESULT_BACKEND']
- 用来存储任务结果的地方(必须支持读写)
- Redis 是最常用的(也可用数据库、RabbitMQ 等)
- 作用:当你调用
result.get()获取返回值时,就是从这里拿数据 - Flask应用和Celery是两个独立的实例,但它们可以共享配置
- Flask的app.config是一个字典对象,用于存储应用程序配置,这是一种配置集中化管理的最佳实践
- Celery实例创建时从app.config读取相关配置
🔹 CORS(app)
- 来自
flask_cors包 - 允许浏览器跨域请求(否则前端会报错)
- 举个例子:前端在
http://localhost:3000访问http://localhost:5000就会被阻止 → 加上 CORS 即可解决
🔹 make_celery(app) 函数
- 解决 Flask 与 Celery 的集成问题
- 因为 Celery 需要知道如何加载它的配置(比如 Broker URL)
- 我们把 Flask 的 config 传给 Celery 实例
🧪 启动方式
- 启动 Redis(确保能连接)
- 启动 Celery Worker(单独终端)
bash
# 启动 Worker
celery -A tasks.celery_app worker --loglevel=info &> ./logs/celery.log &- 启动 Flask 服务
bash
python app.py📡 测试接口
使用 Postman 或 curl 测试:
1. 提交任务
bash
curl -X POST http://localhost:5000/api/send-email \
-H "Content-Type: application/json" \
-d '{"to": "test@example.com", "subject": "Hello"}'响应:
json
{
"task_id": "a1b2c3d4-e5f6-789g-hijk-lmnopqrstuv",
"status": "PENDING",
"message": "Email task submitted!"
}2. 查询任务状态
bash
curl http://localhost:5000/api/check-task/a1b2c3d4-e5f6-789g-hijk-lmnopqrstuv响应(等5秒后):
json
{
"task_id": "a1b2c3d4-e5f6-789g-hijk-lmnopqrstuv",
"status": "SUCCESS",
"result": "Email sent successfully to test@example.com"
}✅ 第二部分:FastAPI + Celery 示例
FastAPI 更现代,性能强,适合微服务架构。
📦 依赖安装
bash
pip install fastapi uvicorn celery[redis] redis🧩 文件结构
project/
│
├── main.py # FastAPI 主程序
├── tasks.py # Celery 任务
└── requirements.txt🧩 任务定义(tasks.py)同上 ✅
不需要改!
🧩 FastAPI 主程序(main.py)
python
from fastapi import FastAPI, HTTPException, BackgroundTasks
from typing import Dict, Any
from tasks import celery_app, send_email, long_process
from celery.result import AsyncResult
import uuid
import asyncio
app = FastAPI(title="FastAPI + Celery Demo")
# 配置 Celery
app.state.celery = celery_app
# 添加 CORS 支持
from fastapi.middleware.cors import CORSMiddleware
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # 允许所有 origin(生产环境建议限制)
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# ================================
# API 接口
# ================================
@app.post("/api/send-email")
async def send_email_task(to: str, subject: str = "Welcome"):
if not to:
raise HTTPException(status_code=400, detail="Missing 'to' field")
# 提交任务
task = send_email.delay(to, subject)
return {
"task_id": task.id,
"status": "PENDING",
"message": "Email task queued"
}
@app.get("/api/check-task/{task_id}")
async def check_task(task_id: str):
result = AsyncResult(task_id, app=app.state.celery)
if result.ready():
if result.successful():
return {
"task_id": task_id,
"status": "SUCCESS",
"result": result.result
}
else:
return {
"task_id": task_id,
"status": "FAILURE",
"error": str(result.info)
}
else:
return {
"task_id": task_id,
"status": "PENDING",
"message": "Task still running..."
}
@app.post("/api/long-process")
async def long_process_task(text: str = "default"):
task = long_process.delay(text)
return {
"task_id": task.id,
"status": "PENDING",
"message": "Long process started!"
}
# ================================
# 启动服务(可选)
# ================================
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)🧠 关键点解析
🔹 app = FastAPI()
- 与 Flask 类似,但更简洁、自动文档化(Swagger UI)
- 自带 JSON 请求体解析、路径参数、类型提示
🔹 app.state.celery
- FastAPI 使用
state字典共享全局对象 - 把 Celery 实例放进
app.state.celery方便其他地方访问
🔹 BackgroundTasks
- 有时我们会用它来添加后台任务(非阻塞)
- 但在本例中我们直接使用 Celery,所以没用到
🔹 CORSMiddleware
- FastAPI 的方式,比 Flask 更灵活
allow_origins=["*"]表示允许任何域名访问(开发时可用)
🚀 启动测试
- 启动 Redis
- 启动 Celery Worker:
bash
celery -A tasks.celery_app worker --loglevel=info &> ./logs/celery.log &- 启动 FastAPI:
bash
uvicorn main:app --reload --port 8000- 前端访问:
http://localhost:8000/docs→ 查看 Swagger 文档- 调用
/api/send-email接口
🎯 总结对比表
| 特性 | Flask + Celery | FastAPI + Celery |
|---|---|---|
| 是否支持异步 | ❌(需手动处理) | ✅(内置 async) |
| 开发速度 | 快(简单) | 较快(带类型提示) |
| 文档生成 | 需要额外工具 | 内置 Swagger UI |
| 并发处理 | 一般 | 强大(基于 Starlette) |
| 错误处理 | 手动写 | 更规范 |
| 适合场景 | 小型项目、传统后端 | 微服务、高性能 API |
✅ 最佳实践建议
✅ 1. 环境变量管理(推荐)
避免硬编码 Redis 地址:
python
import os
broker_url = os.getenv('CELERY_BROKER_URL', 'redis://localhost:6379/0')
result_backend = os.getenv('CELERY_RESULT_BACKEND', 'redis://localhost:6379/0')
celery_app = Celery('tasks', broker=broker_url, backend=result_backend)然后创建 .env 文件:
env
CELERY_BROKER_URL=redis://10.25.69.56:6379/0
CELERY_RESULT_BACKEND=redis://10.25.69.56:6379/0使用 python-dotenv 加载。
✅ 2. 日志记录与监控
- 在
worker启动时加上日志输出 - 使用
flower监控 Celery(图形界面)
bash
pip install flower
celery -A tasks.celery_app flower --port=5555访问:http://localhost:5555
✅ 3. 任务重试机制
在 tasks.py 中添加重试:
python
@celery_app.task(bind=True, max_retries=3, default_retry_delay=5)
def send_email(self, to, subject):
try:
# ... 发送邮件逻辑
pass
except Exception as exc:
self.retry(countdown=5, exc=exc)📘 下一步提升
如果你想深入:
- 将 Redis 替换为 RabbitMQ(适合高吞吐)
- 使用 Docker 部署整个系统
- 结合 Flask/FastAPI + WebSockets 实现实时通知
- 学习 Celery 多队列、优先级调度