- 实验内容任务描述
利用sklearn库或category_encoders,完成4种以上类型的类型变量编码,并完整地进行模型训练与测试。
选用四种类型变量编码分别为:OneHot Encoding、Helmert Encoding、Label Encoding、Target Encoding.
使用模型:随机森林(RandomForestClassifier)、决策树分类器(DecisionTreeClassifier)
分类性能指标:准确率(accuracy)、精确率(precision)、召回率(recall)
- 实验数据描述
- 数据集一:乳腺癌威斯康星数据集(Wisconsin Breast Cancer)
数据来源:该数据集来源于威斯康星大学麦迪逊分校的威廉・H・沃尔伯格博士等人对乳腺癌病例的研究。他们通过对乳腺肿块的细针穿刺活检所获取的细胞样本进行分析整理出了相应的数据。
数据条数:569个样本病例
数据特征:30个
|----------------------------------|---------|
| Mean Radius | 平均半径 |
| Mean Texture | 平均纹理 |
| Mean Perimeter | 平均周长 |
| Mean Area | 平均面积 |
| Mean Smoothness | 平均光滑度 |
| Mean Density | 平均密度 |
| Mean Concavity | 平均核尖度 |
| Mean Concave Points | 平均平滑度 |
| Mean Symmetry | 平均对称性 |
| Mean Fractal Dimension | 平均分形维数 |
| Minimum Radius | 最小半径 |
| Minimum Texture | 最小纹理 |
| Minimum Perimeter | 最小周长 |
| Minimum Area | 最小面积 |
| Minimum Smoothness | 最小光滑度 |
| Minimum Density | 最小密度 |
| Minimum Concavity | 最小核尖度 |
| Minimum Concave Points | 最小平滑度 |
| Minimum Symmetry | 最小对称性 |
| Minimum Fractal Dimension | 最小分形维数 |
| Standard Error Radius | 标准差半径 |
| Standard Error Texture | 标准差纹理 |
| Standard Error Perimeter | 标准差周长 |
| Standard Error Area | 标准差面积 |
| Standard Error Smoothness | 标准差光滑度 |
| Standard Error Density | 标准差密度 |
| Standard Error Concavity | 标准差核尖度 |
| Standard Error Concave Points | 标准差平滑度 |
| Standard Error Symmetry | 标准差对称性 |
| Standard Error Fractal Dimension | 标准差分形维数 |
使用类型变量编码:Helmert Encoding
- 数据集二:葡萄酒数据集(load_wine)
数据来源:来源于对意大利同一地区但产自三个不同品种的葡萄酒进行的化学分析,这些分析旨在通过酒中含有的各种化学成分来区分不同品种的葡萄酒。
数据条数:178条
数据特征:13个
|------------------------------|--------------------|
| alcohol | 酒精 |
| malic acid | 苹果酸 |
| ash | 灰分 |
| alkalinity of ash | 碱度 |
| magnesium | 镁 |
| total phenols | 总酚 |
| flavonoids | 类黄酮 |
| nonflavonoid phenols | 非类黄酮酚 |
| proanthocyanins | 原花青素 |
| color intensity | 颜色强度 |
| hue | 色调 |
| OD280/OD315 of diluted wines | 稀释葡萄酒的 OD280/OD315 |
| proline | 脯氨酸 |
使用类型变量编码:Label Encoding
- 数据集三:鸢尾花数据集(load_iris)
数据来源:该数据集源于对鸢尾花的植物学测量数据,收集了三种不同种类鸢尾花的相关特征信息,旨在通过花朵的一些形态特征来区分不同种类的鸢尾花。
数据条数:150条
数据特征:4个
|--------------|------|
| sepal length | 花萼长度 |
| sepal width | 花萼宽度 |
| petal length | 花瓣长度 |
| petal width | 花瓣宽度 |
使用类型变量编码:OneHot Encoding、Target Encoding
- 方法描述
-
Helmert encoding分类原理:Helmert主要是为了将分类变量转化为数值变量。Helmert 的核心原理在于通过一种有序的对比方式,将多分类变量转化为多个数值型对照变量(编码变量),以此来合理表征原分类变量中各类别之间的关系,使得转化后的变量能够更好地应用于各类需要数值输入的统计分析和机器学习模型中,同时捕捉到类别间差异对目标变量产生的影响。
-
Label Encoding分类原理:Label主要是将分类变量中的不同类别标签转换为数值形式。核心思路是为每个类别分配一个唯一的整数标识符,以此建立起类别与数字之间的映射关系。
-
OneHot encoding分类原理:One-Hot的核心分类原理在于以一种完全离散且相互独立的方式,将分类变量的每个类别转化为一个唯一的二进制向量表示。该向量的维度等于所有可能类别的数量,并且每个向量中只有一个位置是1,其他位置都是0。这种表示方法使得每个类别都是相互独立的,并且没有顺序关系。
-
Taget Encoding分类原理:Target的核心思想是利用目标变量的信息,对分类变量的各个类别进行数值编码,使得编码后的数值能够在一定程度上反映该类别与目标变量之间的关联关系,进而帮助机器学习模型更好地捕捉特征与目标之间的规律,提升分类等任务的性能。
-
分类结果可视化方法------混淆矩阵结合matplotlib绘图
混淆矩阵以表格的形式清晰且全面地呈现了分类模型在各个类别上的预测准确程度以及误分类情况。无论是二分类还是多分类任务,通过查看矩阵中的各个元素,能够直接知晓哪些类别容易被混淆、哪些类别预测准确率较高等细节信息。
混淆矩阵可直接调用sklearn.metrics的 comfusion_matrix函数
|---------------------------------------------------------------------------------------------------------------------------------------------------------|
| from sklearn.metrics import confusion_matrix #sklearn.metrics 模块中导入 confusion_matrix 函数 cm = confusion_matrix(y_true, y_pred) #生成混淆矩阵 print(cm) #输出混淆矩阵 |
结合matplotlib可以绘制混淆矩阵,可自定义矩阵颜色,分类结果更加清晰、生动。
- 模型训练
|------------------------------------------------------------------------------------------------------------|
| # 使用随机森林 model = RandomForestClassifier(random_state=42) #random_state是随机数生成种子 model.fit(X_train, y_train) |
| #使用决策树 model = DecisionTreeClassifier() #构建一个决策树分类器 model.fit(X_train, y_train) |
model.fit(X_train, y_train)调用了随机森林分类器/决策树分类器模型对象(model)的fit方法,用于使用给定的训练数据对模型进行训练。
y_train是与X_train对应的目标标签,通常是一维数组,其元素数量与X_train中的样本行数相同,每个元素对应表示一个样本的真实类别标签。
(7)使用matplotlib绘图时注意添加plt.rcParams'font.sans-serif' = 'SimHei'
在图表信息中,若出现汉字等特殊字符,matplotlib会显示错误。
plt.rcParams:它是matplotlib库用于配置全局绘图参数的一个字典对象。通过修改这个字典中的键值对,可以改变matplotlib绘图的各种默认设置
当然可以选用其他字体,不只是"SimHei"(黑体)。
(8)classification_report的使用
classification_report是sklearn库提供的一个用于展示分类模型评估结果的实用函数。
|--------------------------------------------------------------|
| report = classification_report(y_true, y_pred) print(report) |
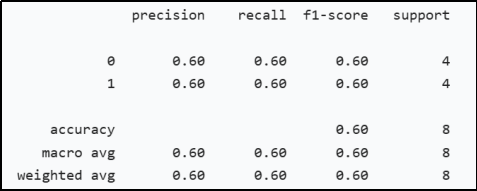
输出类似详细分类报告
在分类报告中,我们主要关注precision、recall、accuracy。
- precision(精确率):针对每个类别分别计算,表示在预测为该类别的所有样本中,真正属于该类别的样本所占的比例。
- recall(召回率):同样针对每个类别计算,体现的是实际属于该类别的样本中,被
- accuracy(准确率):表示模型整体预测正确的样本占总样本数的比例,也就是预测结果与真实结果一致的样本数量除以总样本数量。
(9)train_test_split()方法
train_test_split()用于将我们的数据集划分为训练集和测试集。数据量不大时,可按照train:test=7:3进行划分;若数据量较大时,可按照train:test=8:2进行划分(常用)
- 实验结果
- 对乳腺癌威斯康星数据集使用Helmert Encoding
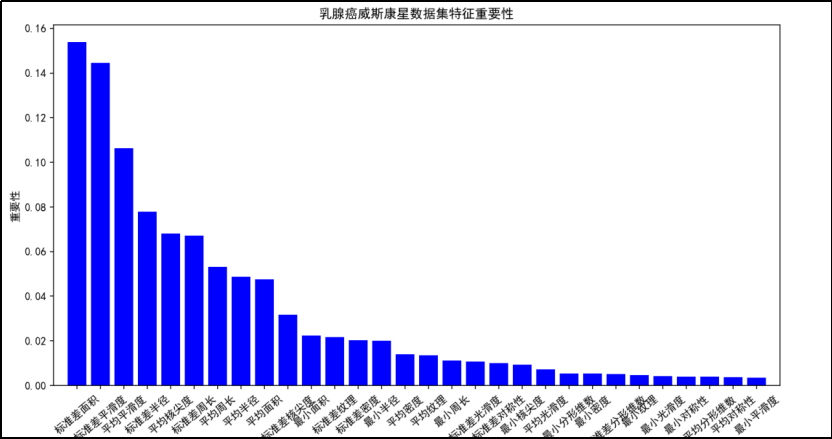
乳腺癌威斯康星数据集特征重要性图的作用:
从图中可以看到不同特征的重要性值。特征重要性图可以帮助识别出哪些特征对模型的预测能力贡献最大。图中"标准差面积"特征的重要性最高,这意味着该特征在预测乳腺癌的良恶性时起到重要作用,同时前面几个特征的重要性之和对良恶性分类有非常大的影响。
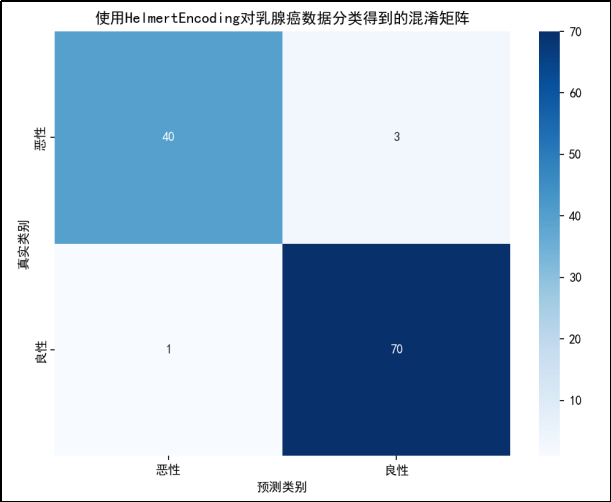
由混淆矩阵可得:
·真阳性(TP):模型正确地将样本预测为良性(良性 - 良性),有 70 个样本。
·真阴性(TN):模型正确地将样本预测为恶性(恶性 - 恶性),有 40 个样本。
·假阳性(FP):模型错误地将恶性样本预测为良性(恶性 - 良性),有3个样本。
·假阴性(FN):模型错误地将良性样本预测为恶性(良性 - 恶性),有1个样本。
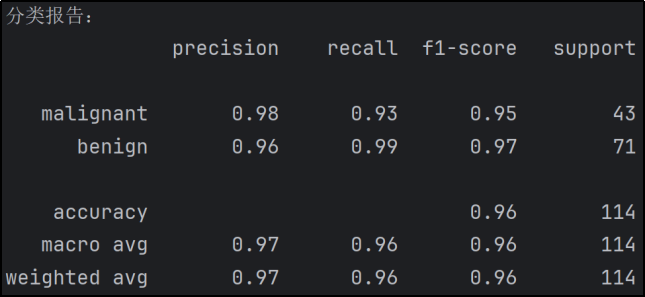
分类报告显示:
· 模型在对良性样本的识别上具有较高的召回率(0.99),这意味着很少有良性样本被误判为恶性,这在医学诊断中是非常重要的,因为误判良性样本为恶性会导致不必要的医疗干预。
· 模型对恶性样本的召回率(0.93)也较高,但相对低于对良性样本的召回率,表明有一小部分恶性样本可能被误判为良性,在实际应用中需要注意这一情况,因为漏判恶性样本可能会延误治疗。
· 整体准确率(0.96)和 F1 - score(恶性为 0.95,良性为 0.97,宏平均和加权平均为 0.96)都表明模型具有较好的分类性能。
- 对葡萄酒数据集(load_wine)使用Label Encoding
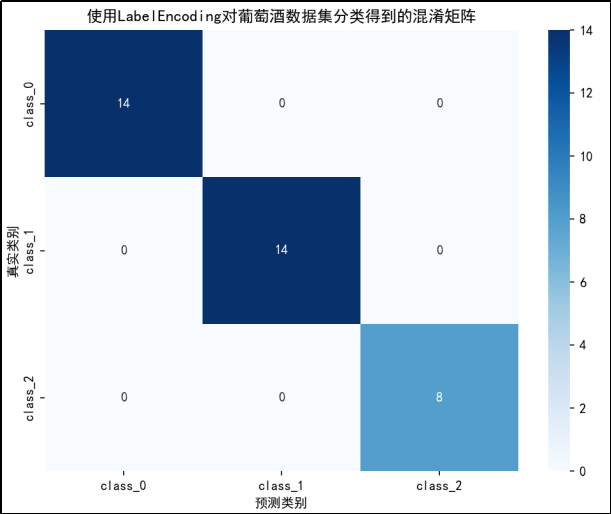
由混淆矩阵可得:
· class_0:真实类别为class_0的样本有 14 个。其中,14 个样本被正确预测为class_0(对角线上的值),没有样本被误判为其他类别。
· class_1:真实类别为class_1的样本有 14 个。其中,14 个样本被正确预测为class_1,没有样本被误判为其他类别。
·class_2:真实类别为class_2的样本有 8 个。其中,8 个样本被正确预测为class_2,没有样本被误判为其他类别。
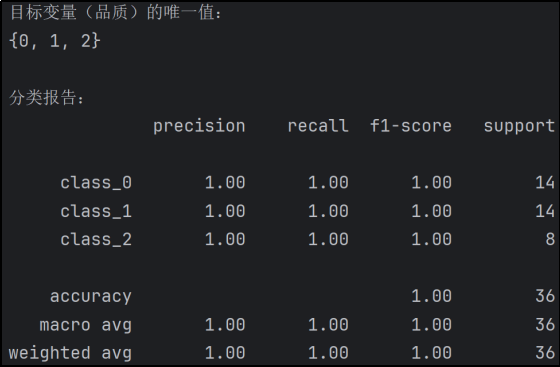
分类报告:
模型在对三个类别的分类上都达到了非常高的精确率、召回率和 F1 - score,且整体准确率为 100%。这表明该模型在这个数据集上表现极其出色,几乎没有出现误分类的情况。
不过,模型具有这么完美的分类结果的主要因素是使用的数据量不是很大,葡萄酒的类别比较少,只有三类,即便参数不是最优的情况下,模型也能有不错的分类性能。
- 对sklearn的鸢尾花数据集使用OneHot Encoding、Target Encoding


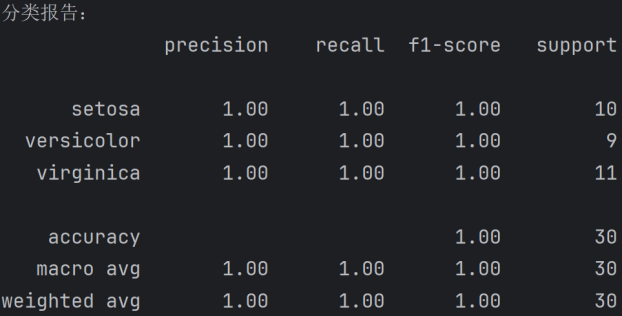
从混淆矩阵来看,使用 OneHot Encoding 和 Target Encoding 对鸢尾花数据集进行编码后,得到的模型在这个数据集上的分类准确率都是 100%。
这表明在这个特定数据集和分类任务中,两种编码方法都能很好地处理数据,并且模型能够准确地对鸢尾花进行分类。
但是,还是前面提到的问题,当数据量不大,分类类别也不是特别多的情况下,分类性能肯定比较好,但是数据量一但增大,像乳腺癌威斯康星数据集那样或者更多时,分类性能可能就会有所下降。
- 实验结果分析与结论
(一)总体分类性能
·Helmert Encoding(乳腺癌数据集)
总体准确率约为 96.5%,模型表现良好,但存在一定误判情况,特别是有 3 个恶性样本被误判为良性,这在医疗场景中较为关键。
·Label Encoding(葡萄酒数据集)
无论是使用 RandomForestClassifier 得到的分类报告还是混淆矩阵,都显示出 100% 的准确率,模型在该数据集上表现极其出色,没有误分类情况。
·OneHot Encoding 和 Target Encoding(鸢尾花数据集)
两种编码方法在鸢尾花数据集上都达到了 100% 的准确率,模型对鸢尾花的分类非常准确,没有出现误分类。
(二)各类别分类表现
·Helmert Encoding(乳腺癌数据集)
良性样本:召回率约为 98.6%,模型在预测良性样本时表现很好,很少将良性样本误判为恶性。
恶性样本:特异性约为 93.0%,存在一定比例(3 个样本)的恶性样本被误判为良性。
·Label Encoding(葡萄酒数据集)
对于三个类别(class_0、class_1、class_2),精确率、召回率和 F1 - score 均为 1.00,模型在每个类别上的分类表现都非常完美。
·OneHot Encoding 和 Target Encoding(鸢尾花数据集)
对于三种鸢尾花类别(setosa、versicolor、virginica),在两种编码方法下所有样本都被正确分类,没有出现类别之间的混淆。
(三)模型评估指标分析
·Helmert Encoding(乳腺癌数据集)
精确率、召回率和 F1 - score 等指标在良性和恶性样本上有一定差异,表明模型在两类样本上的表现不均衡。
·Label Encoding(葡萄酒数据集)
宏平均和加权平均的精确率、召回率和 F1 - score 均为 1.00,说明模型在整体和各类别权重考虑下都表现出色。
·OneHot Encoding 和 Target Encoding(鸢尾花数据集)
由于准确率达到 100%,各类评估指标都达到了最优值。
(四)编码方法的影响
·Helmert Encoding
在乳腺癌数据集上,虽然模型有较高准确率,但仍有改进空间,可能需要进一步优化特征处理或模型参数来减少恶性样本的误判。
·Label Encoding
在葡萄酒数据集上表现完美,但需注意在其他数据集上可能因数据特性不同而表现不同,例如如果数据集存在顺序关系,Label Encoding 可能会引入不合理的顺序信息。
·OneHot Encoding 和 Target Encoding
在鸢尾花数据集上表现相同且优秀,但在实际应用中:
OneHot Encoding 可能会导致高维数据问题,特别是处理高基数分类变量时会增加数据维度。
Target Encoding 可能存在数据泄露风险,需要合理处理训练集和测试集的编码过程。
(五)综合结论
不同的编码方法在不同数据集上的表现各异。在选择编码方法时,需要综合考虑数据集的特点、模型的需求。同时,对于表现良好的模型,也需要进一步验证其泛化能力,避免过拟合等问题。
实验不足:几种类型变量编码选用的数据集的数据量都不是很大,展现出这几种类型变量编码类型的差异性较小。