一、pytorch如何保存训练模型
最初pytorch用pickle模块进行临时保存程序中的对象(比如训练好的模型、中间计算结果),方便后续直接加载使用。pickle是 Python 的序列化 / 反序列化模块,核心作用是把 Python 对象(比如字典、列表、类实例等)转换成字节流(序列化,称为 "pickling"),或者把字节流恢复成原来的 Python 对象(反序列化,称为 "unpickling")。
但是pickle进行模型临时保存会面临一些明显的安全问题,恶意构造的 pickle 数据在反序列化(unpickle)时会执行任意代码,如下图所示:
因此,weights_only参数被引入,以限制反序列化的内容,仅允许加载张量(torch.Tensor)、基本数据类型(int/float/str 等)、简单容器(dict/list/tuple),禁止加载自定义类、函数、复杂对象等可能包含可执行代码的内容。作为对比,

二、weights_only为什么有效
这里我们解释为什么weights_only为什么有效之前,需要先说明为什么pickle不安全,pickle 里最危险的两类能力GLOBAL和REDUCE,GLOBAL可以引用任意模块里的任意对象(函数/类),例如 os.system、subprocess.Popen、builtins.eval,REDUCE可以调用一个函数(或可调用对象)并传入参数来"构造对象"。这个"函数"如果被引用成 os.system 之类,就等于反序列化过程中直接执行命令。
所以普通的 torch.load()(weights_only=False 的老逻辑)在读取恶意 .pt/.pth 时,会把这些 pickle 指令照做,导致典型的 反序列化 RCE。
而weights_only的有效机制也是主要禁用这两个函数,如下图所示,如果pickle指令里面有'sys','os','posix','nt' 这种高危模块黑名单,就会直接raise UnpicklingError。如果利用白名单机制则可以进一步限制危险函数。

三、TorchScript 的风险
weights_only看似杜绝了pytorch在加载模型时存在反序列化漏洞的风险,但是通过分析torch.load()函数,能够发现这里有一个分流的逻辑,如果不是 TorchScript zip,才直接轮到 weights_only 起作用。而如果 zip 被识别为 TorchScript(JIT)格式,会先直接执行torch.jit.load(),并不执行weights_only的安全限制。

所以如果我们能够构建一个TorchScript zip 文件,通过 _is_torchscript_zip() 的格式检测,但内部包含可被 pickle / Python 反序列化处理的恶意结构,就能实现反序列化漏洞利用。
那么首先我们要说明什么是TorchScript ,TorchScript 是 PyTorch 为跨语言、无 Python 环境执行而设计的中间表示(IR),其初衷是避免 Python 动态执行与 pickle 风险。如下图所示
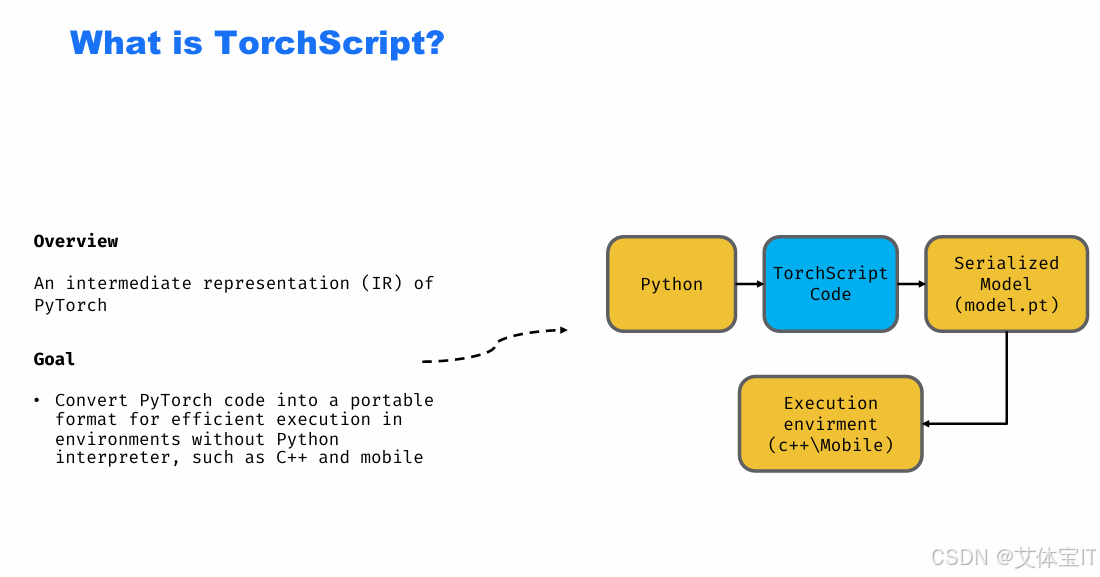
为了构建这样恶意的TorchScript zip文件,我们首先要了解TorchScript长什么样。从原始的python代码到最后TorchScript的IR图,大概需要经过四步:
1.python代码->python AST的转化:Python 解释器会先把代码解析成Python 的抽象语法树(AST),这是 Python 对代码结构的 "结构化表示",这里能看到函数定义、参数、条件分支、返回语句等内容,但不是pytorch JIT能直接用的格式。
2.python AST->JIT AST(TorchScript 的中间表示):这是 PyTorch 专用的结构化表示,包含了 JIT 能理解的 "函数定义""参数""变量类型""运算逻辑" 等信息,转换后,JIT 可以对这段代码做编译优化、跨平台部署
3.JIT AST->original IR graph:从 "语法结构" 到 "计算执行图" 的翻译,核心步骤是遍历 AST 解析语法 → 生成 IR 节点和数据流 → 处理控制流 → 填充类型信息
4.original IR graph->optimized IR graph:PyTorch JIT 的优化器会对原始 IR 做静态分析 + 代码简化,消除了冗余的变量加载 / 存储,简化了控制流逻辑,保留核心计算逻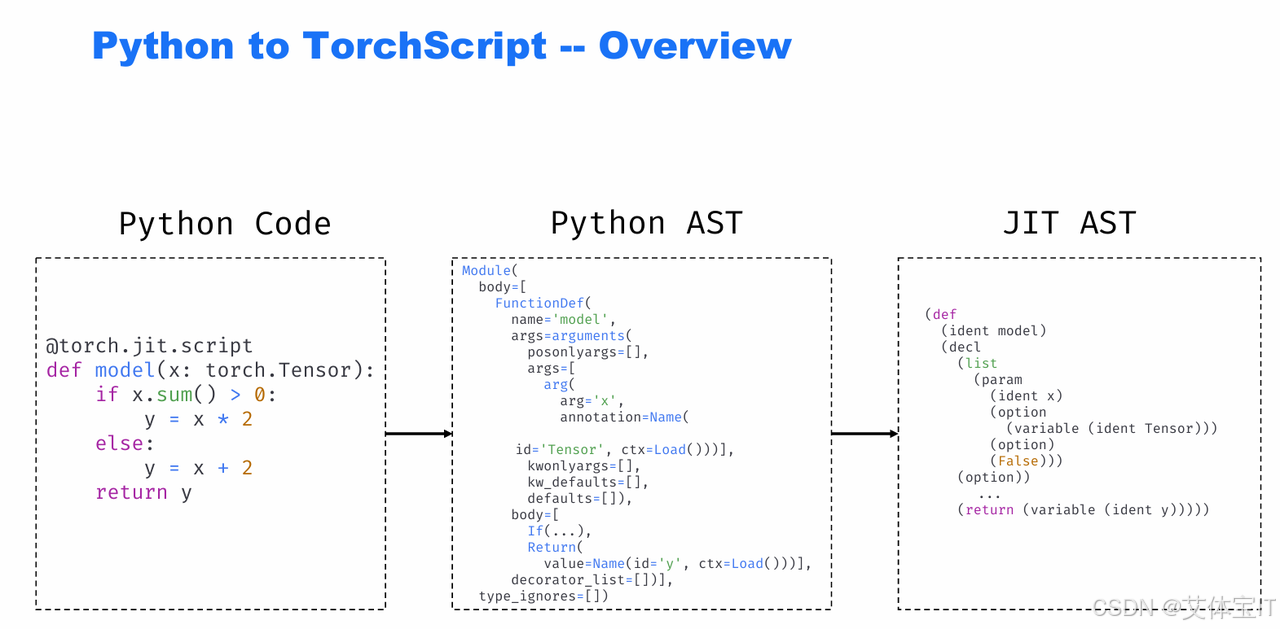

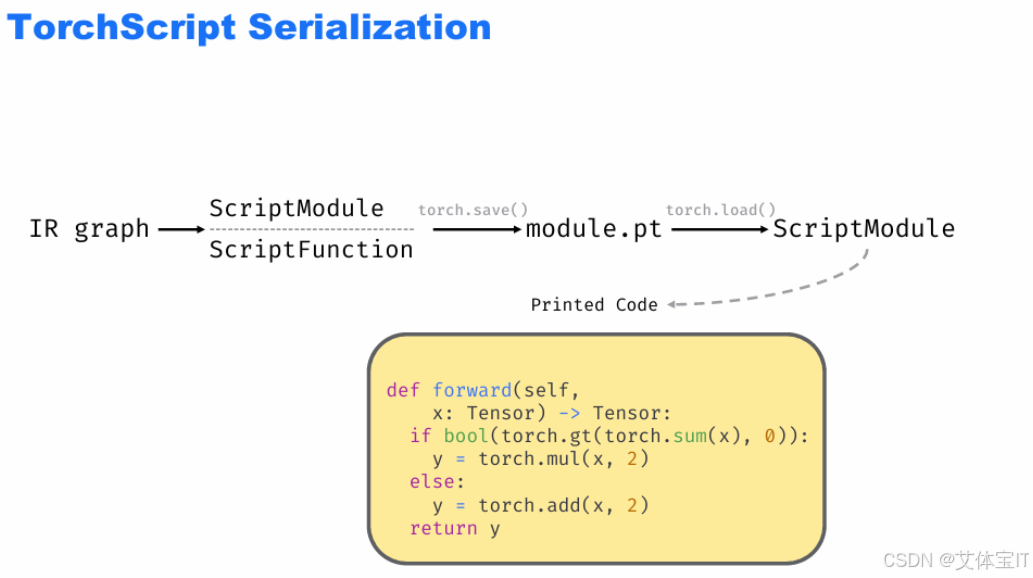
TorchScript 的序列化流程,即把编译好的模型(IR、函数)保存为文件,方便后续加载 / 部署的过程。首先是"IR / 函数 → 保存为文件 → 恢复为模型" 的闭环,
-
输入:已经编译好的IR graph(中间表示)、ScriptFunction(TorchScript 函数);
-
封装:这些内容会被打包成ScriptModule(TorchScript 的模块对象);
-
保存:通过torch.save()把ScriptModule存为文件(如module.pt);
-
加载:之后用torch.load()可以把文件恢复为ScriptModule,直接使用;
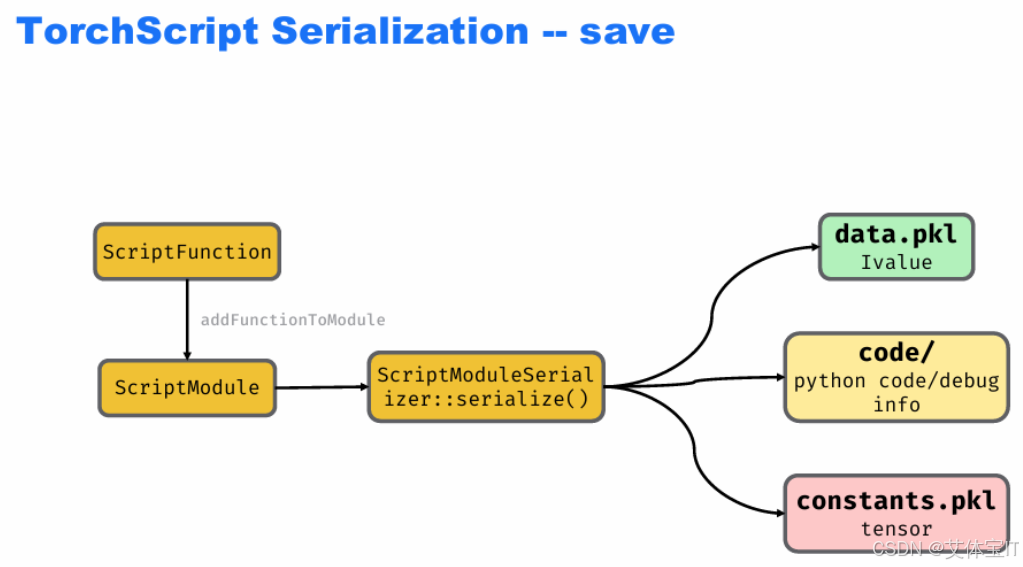
在执行torch.save()时,会有操作如下:
-
ScriptFunction(函数)添加到ScriptModule中;
-
通过ScriptModuleSerializer::serialize()(序列化器),把ScriptModule拆分为 3 部分存储:
-
data.pkl:保存模型的值信息(用IValue表示,是 TorchScript 中统一的 "值" 类型);
-
code/目录:保存Python 代码 / 调试信息(方便后续导出可读代码);
-
constants.pkl:保存模型中的常量张量(比如代码里的固定参数)
-
那么后续在执行torch.load()操作时,会有重新反序列化的操作,核心逻辑是通过调用ScriptModuleDeserializer::deserialize 这个方法,调用 readArchive 方法进行反序列化,读取 constants.pkl、data.pkl 文件

在之前TorchScript构建的说明时,从最后的optimized IR graph也能看出,里面的核心计算逻辑不再是python函数,而是torch.add, torch.mul, aten::add, prim::If 此类Operator(算子),由 C++ / ATen / JIT runtime 实现,在 TorchScript IR 里以 OP 指令的形式出现,Operators 通过 RegisterOperators 注册。这意味着所有 TorchScript 可用算子必须 显式注册,注册时绑定到具体 C++ 实现。JIT 在执行 IR 时,只能调用已注册算子,不能随意调用 Python 函数。
这种通过原子方式调用看似安全,但是细究就能发现存在风险点,本次的漏洞主要出现在aten::save和aten::from_file两个原子方式上。aten::save用于在 TorchScript 中保存 tensor / object,而aten::from_file则用于从文件加载数据(tensor / storage)
为了调用这两个方法,我们利用torch.from_file和torch.save两个函数即可。通过在torchscript进行这两个函数的调用,我们可以即可实现RCE等漏洞。

五、艾体宝Mend.io价值
从此次漏洞事件来看,AI项目中的许多安全漏洞源于第三方库,尤其是深度学习框架(如 PyTorch、TensorFlow)和数据处理工具(如 Pandas、NumPy)。Mend.io 可以深入分析项目中的所有第三方依赖,识别其中的已知漏洞和安全隐患。通过自动化漏洞扫描和依赖分析,Mend.io 能帮助开发团队及时发现并修复潜在的安全风险。