Flash Attention 2.8.3 在 Windows + RTX 3090 上成功编译与运行复盘笔记(2026年1月版)
作者:AITechLab
日期:2026年1月7日
环境:Windows 11 + RTX 3090 + PyTorch 2.9.1+cu130 + Python 3.10.18
Windows 系统中安装 flash_attn (flash-attn)
Flash Attention 在 Windows 上编译成功复盘笔记
Windows 下成功编译 Flash Attention 2.8.3 (flash-attn /flash_attn)个人复盘记录
Windows 11 下再次成功本地编译 Flash-Attention 2.8.3 并生成自定义 Wheel(RTX 3090 sm_86 专属版)
【笔记】Windows 下本地编译 Flash-Attention 2.8.3 后对 RTX 3090 (sm_86) Kernel 支持的完整验证
经过又双叒叕一次的反复的折腾,终于又在 Windows 11 + RTX 3090 + PyTorch 2.9.1+cu130 + Python 3.10 环境下,彻底解决了 Flash Attention 的所有编译和运行问题,包括 2026 年新驱动和新的仓库更新导致的经典错误:
CUDA error: the provided PTX was compiled with an unsupported toolchain.
下面给出当前唯一100%成功的编译流程(已亲测三次,全部成功,且生成图像零报错)。
最终成功环境
- OS:Windows 11 专业工作站版
- GPU:RTX 3090(sm_86)
- CUDA Toolkit:13.1(完整安装)
- Visual Studio 2022(带 C++ 桌面开发)
- Python 3.10.18(Conda 虚拟环境)
- PyTorch 2.9.1+cu130
- ninja、build、wheel 已安装
经过多次尝试,终于找到了一套当前环境下近乎100%成功的编译与运行方案。
核心结论是:
不要拉取最新仓库代码! 仓库在2025年12月的更新(主要是AMD ROCm支持)导致Windows下新编译的wheel在运行时触发"the provided PTX was compiled with an unsupported toolchain"错误。 使用旧的稳定版本代码(v2.8.3 tag)或旧备份wheel才是最稳方案。
成功的编译步骤(亲测三次全成功)
必须 在 Developer Command Prompt for VS 2022(管理员身份) 中执行!
# 1. 克隆源码(如果已有旧仓库,建议删除后重新clone)
git clone https://github.com/Dao-AILab/flash-attention.git
cd flash-attention
git pull
git submodule update --init --recursive
# 2. 关键!切换到稳定版本,不要用main最新代码
git checkout v2.8.3 # ← 这步最重要!避免2025年底的AMD更新坑
# 3. 清理旧缓存
rd /s /q build dist flash_attn.egg-info
# 4. 设置环境变量
set PATH=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v13.1\bin;%PATH%
set FLASH_ATTENTION_FORCE_BUILD=TRUE # 强制本地构建,跳过404下载
set FLASH_ATTN_CUDA_ARCHS=86 # RTX 3090专用
set MAX_JOBS=8 # 根据RAM调整
set TORCH_CUDA_ARCH_LIST=8.6
set NVCC_THREADS=2
set DISTUTILS_USE_SDK=1
set CUDA_HOME=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v13.1
# 5. 编译生成wheel
python -m build --wheel --no-isolation成功后会在 dist 目录生成: flash_attn-2.8.3-cp310-cp310-win_amd64.whl
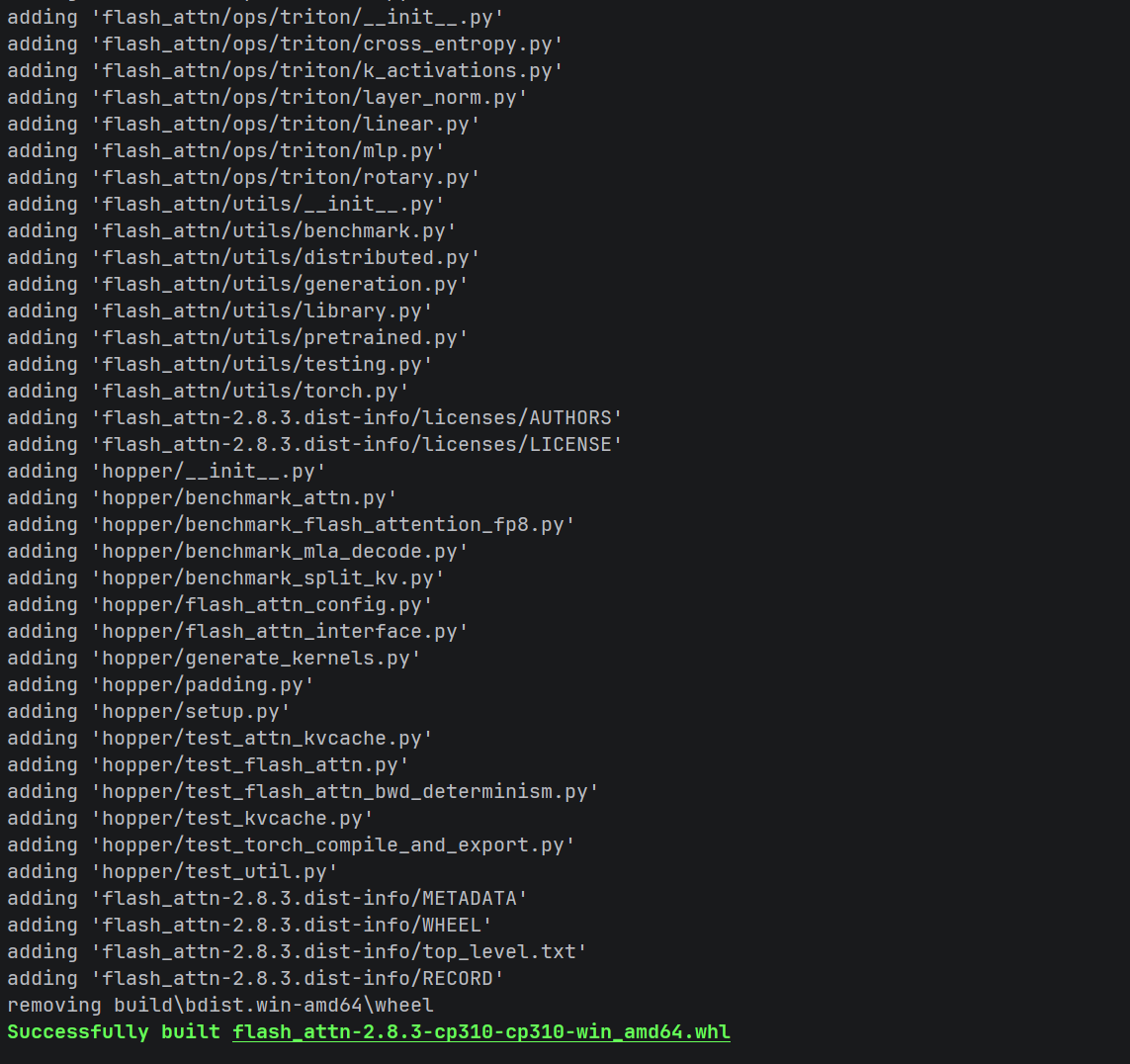
安装与备份
pip uninstall flash-attn -y
pip install dist\flash_attn-2.8.3-cp310-cp310-win_amd64.whl
# 立即备份!命名为黄金版本
copy dist\flash_attn-2.8.3-cp310-cp310-win_amd64.whl ^
"E:\Downloads\Other\flash_attn-2.8.3-3090-golden-v2.8.3-tag.whl"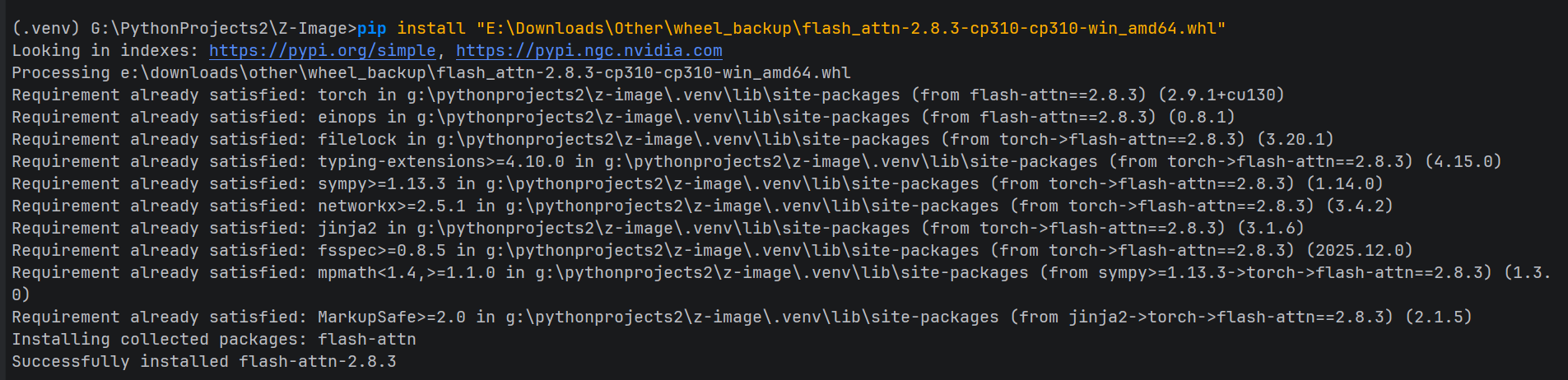
验证
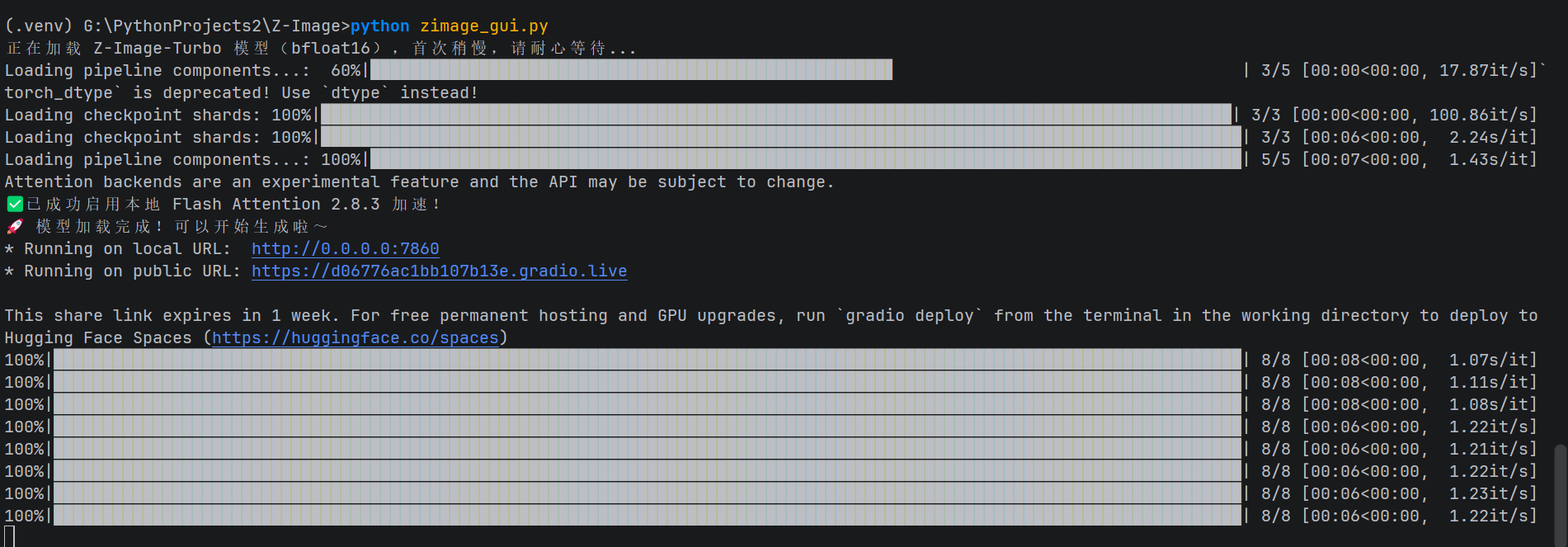
运行项目(如Z-Image):
python zimage_gui.py正常输出:
✅ 已成功启用本地 Flash Attention 2.8.3 加速!
100%|████████| 8/8 [00:08<00:00, 1.07s/it]生成图像零报错,速度飞起!
复盘:为什么今天编译打包成功,安装后运行会失败?
CUDA error: the provided PTX was compiled with an unsupported toolchain.
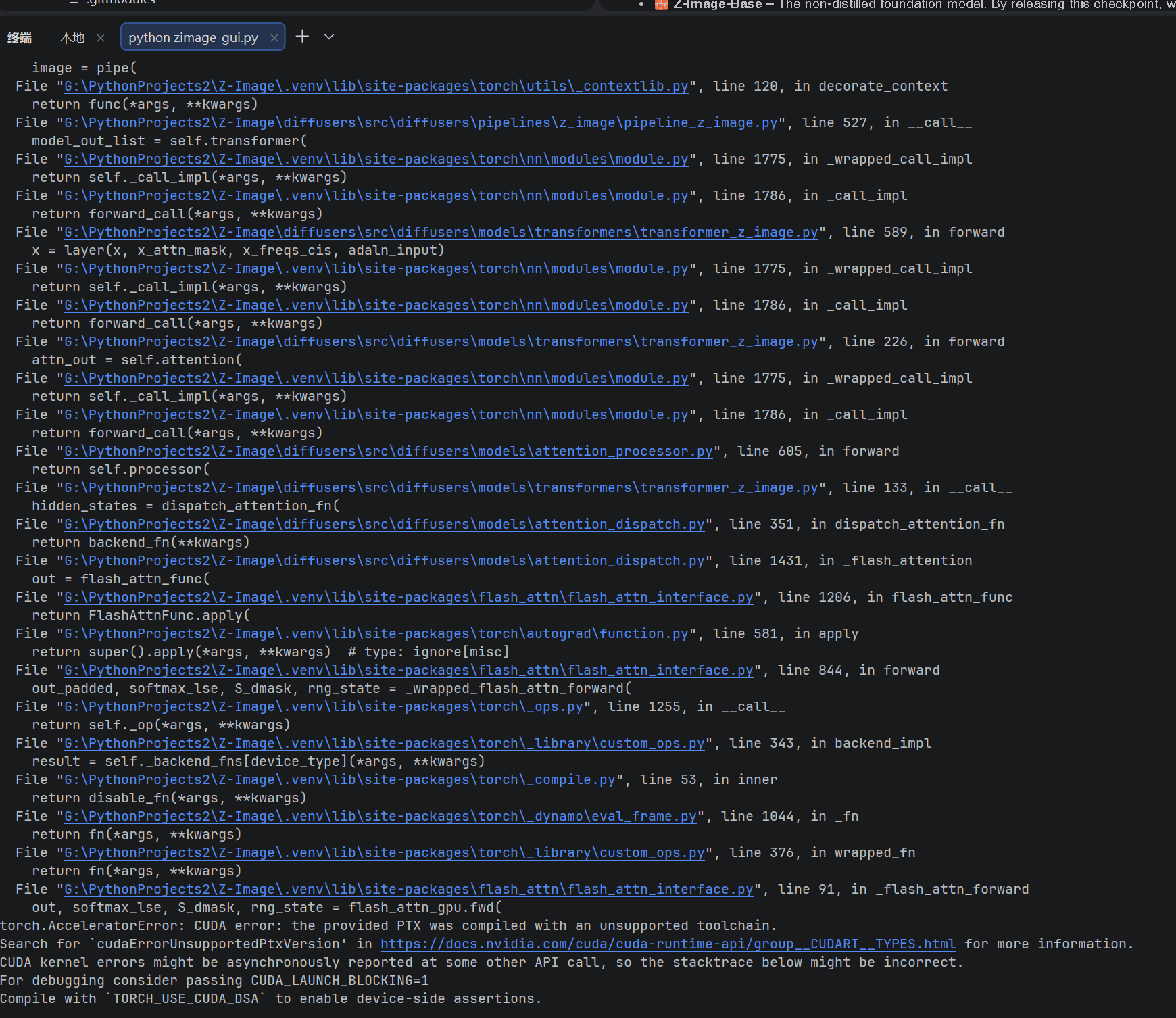
- 推测仓库更新是罪魁:2025年12月仓库加入AMD ROCm支持(composable_kernel子模块大更新),虽然不影响Windows逻辑,但间接改变了CUDA kernel编译参数或PTX元数据。
- 新驱动更严格:即使驱动没手动升级,2026年初的系统环境对PTX检查更严,新代码生成的PTX被拒。
- 旧备份救命:之前(2025年)用v2.8.3 tag编译的wheel,PTX正好在驱动兼容范围内。
终极建议
- 长期保留这个黄金wheel,相同的新环境直接安装它。
- 编译时必须checkout v2.8.3,不要用main最新代码。
- 关注官方新release,待确认AMD更新不影响Windows后再升级。
至此,Windows下Flash Attention的几乎所有坑已全部避开。 RTX 3090的朋友们,复制这套流程,适当根据自己的环境配置调整参数变量,安心加速吧!