Nano Banana Pro 是 Google DeepMind 在 LMSYS 竞技场盲测中的代号,其实体为 Gemini 3 Pro Image Preview ,底层由 Imagen 3 引擎驱动。

该模型在视觉排行榜上通过 ELO 分数 压制了 gpt-image-1.5、seedream-4.5。其核心技术护城河在于 Zero-shot Consistency(零样本一致性) ------依托原生多模态架构(Native Multimodal),它无需 LoRA 训练或 ControlNet 介入,仅凭上下文提示词(In-Context Prompting)即可在多轮对话中实现特征向量级的人物 ID 锁定与精准重绘。
一、技术溯源:为什么 "Nano Banana" 能在 LMSYS 实现降维打击?
在 AI 图像生成领域,LMSYS Chatbot Arena 的盲测机制(Blind Test)被视为去除品牌滤镜后的"绝对实力"试金石。
代号 "Nano Banana Pro" 的横空出世,实际上是 Google 在视觉生成领域从"追赶者"转向"领跑者"的标志性事件。
1. 技术本体解析:原生多模态 vs 拼接式架构
经过技术社区的逆向工程与官方白皮书验证,Nano Banana Pro 并非单一的图像模型,而是 Gemini 3 Pro 的多模态预览版。
- • 架构差异 : Gemini 3 Pro 采用 Native Multimodal(原生多模态) 架构。这意味着"视觉 Token"与"文本 Token"在同一个 Transformer 空间内进行端到端训练。
- • 优势体现:模型并非"翻译"你的指令去画图,而是直接"理解"图像与文本的深层语义关联。这解释了为何它能处理复杂的逻辑合成(如空间透视、光影一致性)而不会经常忽略细节。
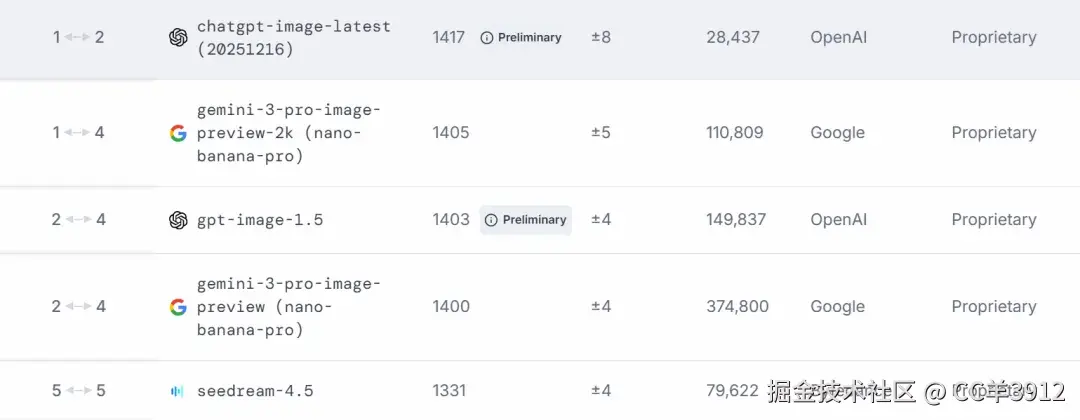
2. 市场表现:LMSYS 视觉模型 ELO 分数梯队
根据 LMSYS Vision Leaderboard 的数据趋势,我们可以通过下表清晰看到 Nano Banana Pro 的市场站位:
| Rank Spread (排名范围) | Model (模型名称) | Score (分数) | 95% CI (±) (置信区间) | Votes (投票数) | Organization (所属机构) |
|---|---|---|---|---|---|
| 1 ↔ 4 | gemini-3-pro-image-preview-2k (nano-banana-pro) | 1405 | ±5 | 110,809 | |
| 2 ↔ 4 | gpt-image-1.5 | 1403 Preliminary | ±4 | 149,837 | OpenAI |
| 2 ↔ 4 | gemini-3-pro-image-preview (nano-banana-pro) | 1400 | ±4 | 374,800 | |
| 5 ↔ 5 | seedream-4.5 | 1331 | ±4 | 79,622 | Bytedance |
列举的这三款模型代表了Google、OpenAI和字节跳动(ByteDance)在图像生成领域的旗舰水平。
如下:Nano Banana Pro(Google Gemini 3 Pro Image)、GPT-Image-1.5 (OpenAI)与 Seedream-4.5(ByteDance)的核心优势对比分析。
| 维度 | Nano Banana Pro (Google) | GPT-Image-1.5 (OpenAI) | Seedream-4.5 (ByteDance) |
|---|---|---|---|
| 核心架构/引擎 | 基于 Gemini 3.0 Pro 的推理引擎,具备"先规划后绘图"的深度推理能力 | OpenAI 最新旗舰生成模型,深度集成于 ChatGPT 生态 | 字节跳动自研新一代模型,主打高审美 与物理世界一致性 |
| 画质与分辨率 | 原生 4K 输出,极高解析度,细节锐利,支持复杂光照物理模拟 | 约 1.5K 分辨率,画质清晰但在超高分细节上略逊于另外两者 | 电影级 4K,主打胶片感、颗粒感和艺术质感,视觉冲击力强 |
| 文本渲染能力 | 行业最强,支持多语言长文本精准渲染,可直接生成完美的信息图表、海报文字 | 显著提升,能处理短语和标题,但在密集文本或排版复杂性上稍弱 | 优秀,尤其擅长处理画面中的招牌、Logo及小字体文本的自然融合 |
| 指令遵循与推理 | 极高 (S+) :能理解极复杂的逻辑约束(如"左边红猫戴蓝帽,右边蓝狗戴红帽"),很少出现逻辑错误 | 高 (S) :擅长理解自然语言对话中的细微修改指令,适合多轮对话调整 | 高 (A+) :空间理解力强,擅长处理画面构图关系,但在极度复杂的逻辑题上略逊 |
| 一致性与编辑 | 角色一致性 (5人) :支持 lightbox 精准控制,多图融合编辑能力强 | 局部重绘之王:依托 ChatGPT 的多轮对话,能精准修改画面某一处而不破坏整体 | 长线一致性 (14人) :在角色面部、服装、风格的跨图保持上表现最佳,适合做分镜故事 |
| 生成速度 | 极快(号称 <10秒),优化了Token解码效率 | 快,比 DALL-E 3 提升显著,但在高负荷下可能稍慢 | 较快,且强调"一次成图率",减少抽卡次数 |
| 独特杀手锏 | Grounding (搜索接地) :可联网获取实时数据(如天气、股票)生成准确的实时信息图 | 生态整合:与 ChatGPT 无缝衔接,适合创意风暴和普通用户的日常修改需求 | World-Aware (世界感知) :物理光影、反射、透视极其自然,适合生成写实摄影和电影画面 |
| 最佳适用场景 | 专业设计、商业海报、复杂逻辑图示、需要准确文字的素材 | 日常创意、社交媒体配图、需要反复微调修改的场景 | 影视分镜、角色设计、电商产品图、摄影级写实艺术创作 |
3. 核心护城河:Zero-shot Consistency (零样本一致性)
这是该模型对传统工作流最大的颠覆。

- • 定义:在不进行任何额外训练(SFT)或插件辅助(ControlNet)的情况下,仅通过自然语言上下文维持主体特征不变的能力。
- • 技术原理 :模型在处理长上下文(Long Context)时,能够将第一轮生成的图像作为"视觉锚点(Visual Anchor)",在后续推理中提取其高维特征向量(如面部几何、虹膜颜色、服装纹理),并将其"注射"到新图像的生成过程中。
二、部署矩阵:开发者与用户的分层接入指南
针对不同技术背景的用户,Google 提供了多维度的接入方案,以及备受用户喜爱的灵芽AI方案,下表对比了各渠道的核心参数与适用场景:
| 接入渠道 | Google AI Studio | Google Gemini 官网 (Advanced) | 灵芽 AI 创意工坊 |
|---|---|---|---|
| 定位 | 开发者/极客 (Dev) | 通用用户 (C-End) | 垂直设计/国内直连 (Vertical) |
| 模型版本 | gemini-3-pro-image-preview |
Gemini Advanced (Backend) | Nano Banana Pro (API Encapsulated) |
| 参数可调性 | 高 (Temp, Top-K, Seed) | 低 (仅 Prompt) | 中 (比例, 画质, 联网) |
| 网络环境 | 需特定地区 IP | 需特定地区 IP | 国内直连 (CN Direct) |
| 特色功能 | Raw Prompt (无系统提示词干扰) | 交互式修改 | 4K Upscale, 任意比例 |
1. 极客通道深度操作 (AI Studio)
-
• 参数建议 :对于追求极致写实感的图像,建议将
Temperature调低至 0.2 - 0.4 ,以减少随机幻觉;若进行创意风暴,可调至 0.8+ 。 -
• Seed 控制 :在 AI Studio 中固定
Seed值,是进行单一变量测试(如仅改变光照方向)的关键。

2. 国内直连通道 (灵芽AI创意工坊)
- • 地址 :https://draw.lingyaai.cn
- • 工具流优势 :解决了原生接口价格高、界面不友好、频繁网络异常,无法主动调整尺寸输出的痛点。该平台在 API 之上挂载了超分模型,支持直接输出 16:9 (电影感) 、4:5 (小红书与ins流媒体)或 9:16 (社媒) 比例,1K/2K/4K分辨率,搭载联网,并自动执行去噪与锐化处理。
三、深度评测:垂直场景下的技术表现
3.1 极致渲染:物理级光影 (PBR) 与次表面散射
在 Text-to-Image 任务中,Gemini 3 Pro 的强项在于对物理规律的模拟。
- • 次表面散射 (SSS) :在生成逆光人像时,模型能精准计算光线穿透耳廓、鼻翼软骨时的红色透光效果,彻底告别了 AI 绘图常见的"蜡像感"。
- • 宽容度测试:与 DALL-E 动辄触发 "Unsafe" 拦截不同,Gemini 3 Pro 能够区分"艺术"与"se情内容"。例如输入 "Marble statue of David" 或 "Fashion photography of sheer fabric",它能准确生成艺术作品而非拒绝执行。
3.2 生产力革命:ID 一致性技术路线对比
在保持人物一致性方面,Nano Banana Pro 开启了第三条技术路线:
| 技术方案 | LoRA (Stable Diffusion) | Reference Net / IP-Adapter | Gemini 3 (Context Awareness) |
|---|---|---|---|
| 原理 | 训练特定权重的微调模型 | 图像编码器提取特征注入 | 原生上下文理解与特征锁定 |
| 成本 | 高 (需数十张图+GPU训练) | 中 (需插件配合) | 零 (仅需一句话/一张图) |
| 灵活性 | 低 (换风格需重训) | 中 | 极高 (即时响应,多风格切换) |
| 效果 | 极高还原度 | 较好还原度 | 高还原度 + 极佳融合性 |
实测案例:
上传一张亚洲女性参考图,输入 Prompt:"Photo of this woman as a cyberpunk hacker, neon lights background, 80s retro filter"。模型不仅保留了五官特征,还自动适配了赛博朋克风格的妆容(如发光眼线),实现了特征与风格的深层融合。
(以下第一张图为上传图片,第二章为生成图)


3.3 工业流应用:正交投影与三视图
对于 3D 建模师,Gemini 3 Pro 是目前最强的资产辅助生成器。
- • Prompt 技巧:使用关键词 "Orthographic projection" (正交投影), "Three-view drawing" (三视图), "T-pose" (T型姿态)。
- • 输出质量:生成的角色正、侧、背视图在骨骼结构上高度对齐,直接导入 Maya/Blender 作为贴图参考的可用率高达 90% 以上,解决了以往模型"侧面图脸部崩坏"的顽疾。
四、进阶工作流:构建 AI 辅助生态链 (Toolchain)
单打独斗不如生态协同。利用 Nano Banana Pro 的高质量底图,可以串联起以下高级工具链:
-
- 无限画布 (Infinite Canvas) - 构图修正
-
- • 原理:利用 In-painting 算法修复生成图中的微小瑕疵(如手指结构)。
- • 操作:在 Gemini 生成底图后,使用 Canvas 工具框选局部,输入 "Fix the hand structure, holding a coffee cup naturally",利用其语义理解能力进行像素级修复。
-
- 姿态控制专家 (PoseMy.Art) - 骨架驱动
-
- • 痛点:自然语言难以描述复杂的瑜伽或格斗动作。
- • 解决方案:
-
-
- 在 PoseMy.Art 调整 3D 假人姿态并截图。
-
- 将截图作为 Gemini 的 Prompt 图片输入。
-
- 指令:"Generate a character in this exact pose, wearing samurai armor"。
-
- • 效果:完美复刻肢体角度,解决了 ControlNet OpenPose 部署难的问题。
-
- 视频化 (Google Veo 3) - 动态演绎
-
- • 生态联动:Gemini 3 Pro 生成的静态图具有极高的分辨率和细节,是 Image-to-Video 模型的最佳输入源。将其喂给 Google Veo 3,可以生成长达 6 秒的电影级运镜视频,且角色面部不崩坏。
五、总结与展望
Nano Banana Pro (Gemini 3 Pro) 的出现,证明了 通用多模态大模型 (LMM) 在垂直视觉任务上已经具备了超越专用模型(如 SDXL)的潜力。
无论是通过 Google AI Studio 探索参数极限,还是通过 灵芽 AI 快速产出商业素材,掌握这一工具的使用逻辑,已成为 2026 年后技术创作者的必备技能。
本文名词解释 (Explanation)
LMSYS Chatbot Arena (大模型竞技场) :
这是一个全球公认的 AI 模型"角斗场"。它不依赖复杂的代码测试,而是让两个匿名的 AI 模型针对同一个问题进行回答,由人类裁判盲测投票谁更好。
Blind Test (盲测) :
指在评测时不告知用户正在使用的是哪个厂商的模型(例如不告诉你这是 GPT-5.2 还是 Gemini),完全凭生成结果的质量来投票,以确保排名的公正性。
Elo Score (Elo 等级分) :
源自国际象棋的评分系统。在 AI 领域,如果一个模型赢了强对手,它加分就多;赢了弱对手,加分就少。这个分数反映了模型的相对实力排名。
Native Multimodal (原生多模态) :
通俗理解 :像人类一样,天生就能同时理解文字和图片。
技术含义:传统的 AI 往往是"拼凑"的(一个大脑看图,一个大脑写字,中间用胶水连起来)。原生多模态则是从一开始训练时,就在同一个神经网络里同时学习文本和图像,因此它们之间的联系更紧密,理解更深刻。
Zero-shot Consistency (零样本一致性) :
通俗理解 :不需要提前"补课"或"特训",看一眼就能照着画出来。
技术含义:指模型不需要针对特定人物进行专门的数据训练,仅凭你提供的一张参考图或一段描述,就能在后续的生成中一直保持这个人物长得一样,不会画着画着变了样。
LoRA (Low-Rank Adaptation) :
通俗理解 :一种"轻量级补丁"或"外挂"。
技术含义:如果要让 AI 学会画特定的画风或人物,传统的微调(Fine-tuning)很贵很慢。LoRA 是一种只训练模型中很小一部分参数的技术,像给游戏打个小补丁,就能快速学会新角色。
ControlNet :
通俗理解 :给 AI 戴上"镣铐"或画好"骨架"。
技术含义:一种用于控制 AI 生成图像结构的插件。比如你可以给 AI 一张火柴人骨架图,强制 AI 生成的人物必须摆出这个姿势,而不能随意发挥。
SFT (Supervised Fine-Tuning / 有监督微调) :
指在模型训练的第二阶段,人工整理高质量的"问题-答案"数据喂给模型,教它如何像人类一样规范地回答问题。
Subsurface Scattering (SSS / 次表面散射) :
通俗理解 :皮肤的"通透感"。
技术含义:光线射入半透明物体(如皮肤、玉石、蜡烛)后,在内部发生散射再射出的物理现象。在 AI 绘图中,如果 SSS 模拟得好,人像的耳朵在逆光下会透红,皮肤会有肉质感,而不是像塑料或蜡像。
PBR (Physically Based Rendering / 基于物理的渲染) :
一种模拟真实世界光线物理行为的渲染技术。它能让金属看起来像金属,皮革看起来像皮革,光影反射符合物理规律。
Orthographic Projection (正交投影) :
通俗理解 :没有"近大远小"透视效果的平面图。
技术含义:在工业设计和建模中使用的视图,物体无论远近大小都一致。常用于生成三视图(正面、侧面、背面),方便 3D 建模师直接作为参考底图。
In-painting (内补) / Out-painting (外扩) :
In-painting :挖掉图片中间的一块(比如把闭着的眼睛涂掉),让 AI 重新画这一块(画成睁开眼)。
Out-painting:把图片画布变大,让 AI 根据原有画面内容,自动补全画面边缘以外的景色。
Temperature (温度) :
控制 AI 回答或生成的"随机性"。
温度低(如 0.2):AI 变得保守、严谨,每次生成的图差不多。
温度高(如 0.9):AI 变得疯狂、有创意,容易出现意想不到的结果(也容易出错)。
Top-K :
一种采样策略。AI 在生成下一个内容时,会从概率最高的 K 个选项里挑。调小这个数值,AI 说话/画图会更稳;调大这个数值,词汇/元素会更丰富。
Seed (种子值) :
一张图的"身份证号"。在 AI 绘画中,如果你固定了 Seed 值,只要提示词和参数不变,生成的画面就会一模一样。这常用于微调画面细节。
本文权威参考资源 (References)
为了便于读者进行技术验证与深度学习,以下列出本文引用的核心数据来源与工具地址:
1.LMSYS Chatbot Arena Leaderboard - 数据来源 包含 ELO 分数排名与 Elo 评分计算机制详解。
URL: chat.lmsys.org
2.Google DeepMind Research - 技术白皮书 Gemini 1.5/3 Technical Report 及 Imagen 3 扩散模型架构论文。
3.Google AI Studio API Docs - 开发者文档 包含 API 调用参数、Token 计费标准及安全过滤器设置。
URL: ai.google.dev/docs
4.灵芽 AI 创意工坊 - 工具平台 基于 Gemini 架构的中文直连版接入端。
URL: draw.lingyaai.cn
5.PoseMy.Art - 辅助工具 在线 3D 姿态编辑器与骨架生成工具。
URL: posemy.art