**【本节概要】**在知识图谱的基础上,我们进一步考虑如何有效抽取和表达实体。
目录
[1.1 命名实体识别概述](#1.1 命名实体识别概述)
[1.2 命名实体识别方法](#1.2 命名实体识别方法)
[1.3 实体消歧](#1.3 实体消歧)
[4.1 关系抽取方法](#4.1 关系抽取方法)
[4.2 远程监督方法](#4.2 远程监督方法)
[4.3 开放关系抽取](#4.3 开放关系抽取)
一、实体抽取任务
1.1 命名实体识别概述
**命令实体识别(NER),指的是识别出文本中的人名、地名等专有名称,和有意义的时间、日期等数量短语等,并加以归类。**命令实体识别主要包含两个子任务:判别实体边界(实体在文本的哪里),判别实体类型。
命名实体识别的内容一般按照MUC-7的定义,分为3大类,7小类。
- 实体类:人名、地名、机构名
- 时间类:日期、时间
- 数值类:货币、百分比
这里举一些较为特殊的实体识别任务:
- 数值识别与检测任务

- 时间表达识别与检测任务

命名实体识别的难点与分词的难点十分相似,不断有新的命名实体涌现,已存在的命名实体之间不断出现歧义,部分实体的构成结构非常复杂,并且实体的类型多样。
**如何对命名实体识别的性能进行评价?**这里与检索任务大致相同,采用Precision / Recall / F-value加以衡量。
1.2 命名实体识别方法
本节介绍一些命名实体的识别方法。
- 基于词典
基于词典的识别方法,每次只需要更新词典就行了,很方便,与具体的语境/领域无关,但大部分情况下很难枚举所有的命名实体名,并且构建和维护词典的代价较大,难以有效处理实体歧义。
- 基于规则
基于规则的识别方法,采用手工构造规则模板,对符合规则的实体进行识别。选用特征(用来帮助确定文本片段是否是目标实体的判断依据)包括统计信息、标点符号、关键字、指示词和方向词、位置词 (如尾字)、中心词等。
举个例子:以模式和字符串相匹配为主要手段

该类方法的局限性明显:不同句式意味着不同的模板,导致规则库极其庞大,使用不便。简而言之就是代价太大,系统建设周期长、移植性差而且需要建立不同领域知识库。但优点是当提取的规则能较精确地反映语言现象时,性能较好。
- 基于统计
基于统计的命名实体识别方法是当下的主流方法。
基于统计的命名实体识别方法具有以下特点:对特征选取的要求较高,需要从文本中选择对NER有影响的特征来构建特征向量(尤其是早期工作,深度学习技术发展后相对要求降低)。通常做法是对训练语料所包含的语言信息进行统计和分析,从中挖掘出特征。对语料的依赖也较大,目前缺少通用的大规模语料,对深度学习技术影响尤甚,特定专业领域影响最为明显,大部分技术仍需要进行人工标注训练数据。
1.3 实体消歧
实体消歧(Entity Disambiguation),本质在于一个单词很可能有多个意思。这就意味着,在不同的上下文中所表达的含义可能不太一样。例如,介绍查询意图的歧义问题时提及的"苹果"。
解决实体歧义问题,首先需要获取实体的各种不同含义。对不同的含义抽取其相关内容,如描述文本,并建立关键词表。其次,通过对关键词表的语义分析,从中抽取和归并相应的"概念"。例如,苹果(水果)可能对应"富士"、"烟台"等,而苹果(手机)可能对应"iPhone" 、"刘海屏" 等。最终,对关键词进行语义表征,得到不同语义的表征向量。
由此,可以通过语义相似性(如余弦相似度)判断究竟属于哪种语义的实体。
二、实体对齐
实体对齐(Entity Alignment),也称实体匹配(Entity Matching)。指对于异构数据源知识库中的各个实体,找出属于现实世界中的同一实体。例如,不同药物可能在不同数据库中采用不同的名称。一般而言,利用实体的属性信息判定不同源实体是否可对齐。
实体消歧旨在消除一词多义的歧义现象。实体对齐旨在表征同一对象的多个实体之间构建对齐关系,丰富实体信息。
近来,针对跨知识图谱(KGs)的实体对齐任务,研究者提出并改进了多种基于表征(Embedding)的模型。不仅利用实体的属性和语义信息,还利用实体间的关系,要求KGs的表征(包括关系表征和实体表征)落在同一个向量空间。换言之,这些模型更关注于关系三元组(relationship triple)。
那么如何使关系表征拥有统一的向量空间?可以利用相似性合并。首先,找到部分相似的谓词,例如,bornIn(KG1)与wasBornIn(KG2),并用统 一的命名方案(例如,bornIn)重新命名,将KG1和KG2合并为KG1_2。接着,合并后的图KG1_2被分割成关系三元组Tr和属性三元组Ta,用于表征学习。

三、实体链接
如何将文本中的提及,链接到知识库中的实体上。这就是实体链接要解决的问题。二者也是知识库问答等一系列功能的刚需。但在此过程中,会遇到各种各样的挑战,比如说语言的多样性,语言的歧义性。
整个流程分 3 步,我用例子(文本里出现 "Scott Young")拆解:
- 第一步:提及识别
- 本质:从文本里找出 "可能对应实体的词 / 短语"(类似 "找名字")。
- 例子:从文本 "Scott Young 出席了活动" 里,识别出 "Scott Young" 是要链接的 "提及(Mention)"。
- 第二步:候选实体生成
- 本质:根据 "提及的字面意思",从知识图谱里找出所有可能对应的实体(粗筛,只看名字像不像)。
- 例子:"Scott Young" 对应的候选实体可能有 3 个:
- 作家 Scott Young
- 美国橄榄球运动员 Scott Young
- 威尔士足球运动员 Scott Young
- 第三步:候选实体排序(核心)
- 本质:通过 "语义分析"(结合文本上下文),给候选实体打分,选出最匹配的那个。
- 例子:文本上下文是 "Scott Young 写了某本书",就会给 "作家 Scott Young" 打高分,最终确定它是正确实体。

四、关系抽取
4.1 关系抽取方法
关系抽取的概念是1988年在MUC大会上提出的,是信息抽取的基本任务之 一,旨在识别出文本实体中的目标关系,是构建知识图谱的重要技术环节。

基本的关系抽取方法可大致分为以下三类:基于规则的关系抽取 ,纯手工定制规则,通过匹配从文本中寻找关系;基于模式的关系抽取 ,从种子关系中获得模式,再由模式寻找更多种子,迭代优化;基于机器学习的关系抽取,将关系抽取问题转化为分类问题,通过训练模型加以求解。
1. 基于规则的关系抽取
根据欲抽取关系的特点,首先基于已有知识,手工设定一些词法、句法和语 义模式规则,然后再从自由文本中寻找相匹配的关系实例类。
基于规则的关系抽取,需要从文本中寻找体现特定含义的规则:例如:<X, IS_A, Y> 关系抽取(同义词/上下位词关系)中 Dog is a member of canid.(狗是犬科家族的一员)
描述前述的关系,可采用以下规则
Rule 1: "Y such as X":Universities such as MIT and CMU ......
Rule 2: "X or other Y":Apples or other fruits ......
Rule 3: "Y including X":Machine learning methods including SVM and CRF......
Rule 4: "Y, especially X":Most students, especially Ph.D. candidates ......
这样的方法无需训练实现简单,结合包含位置信息拓展的倒排表使用很不错,并且人工规则的准确度高,在小规模数据集上很容易实现。但是部分任务可能很难制定规则。基于手工规则的方法需要领域专家构筑大规模的知识库,这不但需要有专业技能的专家,也需要付出大量劳动,因此这种方法的代价很大。并且知识库构建完成后,对于特定领域的抽取具有较好的准确率,但移植到 其他领域十分困难,效果往往较差。
2. 基于模式的关系抽取
首先由种子关系生成关系模式,然后基于关系模式抽取新的关系,得到新关系后,从中选择可信度高的关系作为新种子,再寻找新的模式和新的关系。如此不断迭代,直到没有新的关系或新的模式产生。
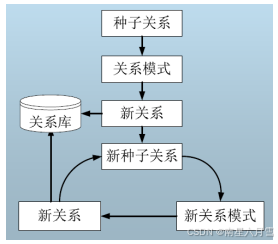
基于模式抽取的动机在于文本在表示三元组时,存在着某种重复的"模式"。这里介绍两种代表性方法:
代表性方法1:DIPRE
双重迭代模式关系提取(Dual Iterative Pattern Relation Extraction),由谷歌联合创始人Sergey Brin于1998年提出。其大致思路在于先给定一些已知关系类型的种子实体对,找到出现了这 些实体对的Occurrences,再学习Occurrences的模式(Pattern)。 进而,根据学到的模式,寻找更多符合该模式的数据,并加入到种子集 合中,不断迭代这个过程以实现关系抽取。
举个例子,元组:表示关系实例,如 <Foundation, Isaac Asimov> --- <Title, Author>,对应的模式包含常量和变量,例如 ?x, by ?y 的形式(可表示 title by author)。
它的基本假设是元组往往广泛存在于各个网页源中,元组的各个部分往往在位置上是接近的,在表示这些元组时,存在着某种重复的"模式"。


代表性方法2:Snowball
基本思想在于对DIPRE算法的提升,仅信任支持度和置信度较高的模式,从而保证模式质量。这里说一下支持度与置信度的计算方式:
- 支持度(Support),即满足每个模式的元组的数量,将少于一定数量元组支持的模式予以删除。
- 置信度(Confidence),按照如下公式计算,即考虑符合该模式的元组,确实符合相应关系的概率。


不同算法的差异主要在于模式生成方法和匹配方法。 适合某种特定的具体关系的抽取,如校长关系、首都关系。基于字面的匹配,没有引入更深层次的信息,如词性、句法、语义信息等。难以确保模式的可靠性,需要人工复核。 移植性差,必须为每一个具体的关系生成自己的识别模式。
3. 基于机器学习的关系抽取
采用机器学习方法关系抽取模型,先通过标注语料库训练得到一个判别模型, 再利用该模型对自由文本中出现的关系实例进行识别。
往往将关系抽取问题变换为一个分类问题(二分类或者多分类),然后采用机器学习中常用的分类器来解决。
通常采用基于特征或基于核函数的方法加以解决。
**基于特征的方法:**基于特征向量,然后使用SVM 、最大熵(ME )等进行分类。关键在于特征集的确定而不是机器学习方法,难点在于如何找出适合关系抽取的、有效的词汇、句法或语义特征。


基于人工特征的方法存在若干缺陷,对于缺少NLP处理工具和资源的语言,无法提取文本特征,并且 NLP 处理工具会引入 "错误累积",人工设计的特征不一定适合当前任务。
基于深度学习技术,可以在一定程度上摆脱对于人工特征的依赖。基于CNN技术学习文本语义特征,同时保持句子级别的结构信息。
**基于核函数的方法:**不需要构建特征向量,而是使用核函数来计算两个关系实例的相似性。核函数的概念是某些样本在低维空间时线性不可分,通过非线性映射将其映射到高维空间的时候则线性可分,但非线性映射的形式、参数等难以确定。核函数的目的,在于将高维空间下的内积运算转化为低维空间下的核函数计算,从而避免高维空间可能遇到的 "维度灾难" 问题。
4.2 远程监督方法
面向文本的关系抽取方法,最大的难点在于获取足够数量的、高质量的标注。人工标注开支过高,且存在主观性问题;而算法标注可能有累积误差。
远程监督的思想就在于,如果某个实体对之间具有某种关系,那么,所有包含这个实体对的句子都是用于描述这种关系。例如,我们已知"马云"和"阿里巴巴"之间是创始人/董事长关系,那么,我们默认以下包含这一实体对的句子,均描述这一关系。
- "马云再谈悔创阿里巴巴:再有一次机会,尽量不把公司做这么大"
- "马云:不当阿里巴巴董事长,但绝不等于我不创业了 "
接下来,我们将这些语料打包,从中训练用于关系识别的模型,并进而用于 判断更多的实体对之间的关系。某种意义上,这一迭代思路类似于前面介绍的DIPRE算法。
从上面的例子中我们可以看到,这一过程具有非常明显的局限性。**语义漂移(Semantic Draft)现象:不是所有包含该实体对的句子都表达该关系,错误模板会导致关系判断错误,并通过不断迭代放大错误。**解决的方法有,可通过人工校验,在每一轮迭代中观察挑出来的句子,把不包含这种关系的句子剔除掉,但开支实在过高。
这里给两个远程监督的优化方法:
1. 动态转移矩阵
尽管噪音数据不可避免,但是对噪音数据模式进行统一描述是可能的。例如,一个人的工作地点和出生地点很有可能是同一个地点,这种情形下远程监督就很有可能把born-in和work-in这两个关系标签打错。
解决方案:引入一个动态转移矩阵,描述各个类之间相互标错的概率。在利用算法得到的关系分布的基础上乘以这一转移矩阵,即可得到相对更为准确的关系分类结果。然而,采用这种方式随机性较高,并不能完全保障其可靠性。
2. 规则学习
远程监督试图通过使用知识库作为监督来源,从文本中提取实体之间的关系。 这种启发式方法因噪声的存在可能会导致一些句子被错误地标记。
针对这一问题提出一个新的生成模型,直接模拟远程监督的启发式标签过程。其中,设计相应的否定模式列表NegPat(r),专门用于去除错误的标签, 即某些关系的判断是否为错误。对于单一关系的判断,可以通过这种方式进行比较高效的复检。但规则的生成成本较高。
3. 注意力机制
即使是被打入同一个包里的句子,不同句子对于训练关系判别模型的贡献度也不相同,这一贡献度可以采用注意力模型加以衡量。
采用深度学习技术,获取对于整个句子的表示。进而,通过注意力机制,将最能表达这种关系的句子们挑选出来。这是最为有效的办法,但依赖于一个高质量的样本集合。
4.3 开放关系抽取
前面所介绍的关系抽取任务,往往针对预先定义好的关系。然而,海量网络文本资源往往包含着更为复杂、丰富的实体关系类型,预先定义的模板关系已无法涵盖。同时,现有关系抽取研究受到关系类型与训练语料的双重限制。 突破封闭的关系类型限定与训练语料约束,从海量的网络文本中抽取更为丰富的实体关系三元组,已成为当下的热门需求。
一种思路是通过Wikipedia等结构化知识库,从文本中抽取关系信息。着重利用Wikipedia中的InfoBox,抽取已知的关系信息,基于关系信息,对维基百科条目文本进行标注,产生训练语料。
另一种思路,通过识别表达语义关系的短语,可以来抽取实体之间的关系。可以采用类似DIPRE算法的思路,从抽取出的语料中提炼模式。对于抽取出来的三元组,可通过句法和统计数据等来实现过滤。关系短语应当是一个以动词为核心的短语,关系短语应当匹配多个不同实体对(只有一个实体的短语不可用)。
五、事件抽取
事件是信息的一种表现形式,其定义为特定的人、物,在特定时间和特定地点相互作用所产生的客观事实。例如,可对应先前所说的5W1H基本要素。呈现方式为句子甚至段落级别(相比之下,关系往往表现为短语级别)。
通常而言,事件往往包含以下基本要素:
- 事件触发词,表示事件发生的核心词,多为动词或名词。相应的,事件触发词的检测与分类是事件抽取的基本任务。

- 事件类型:与触发词相对应,往往可以通过触发词分类加以识别。例如,前例中的触发词Pass away对应着"死亡"的事件类型
- 事件元素:事件的参与者,主要由实体、时间等组成。例如,前例中的Henry是事件的主体。
- 事件元素角色:事件元素在事件中充当的角色。 例如,前例中的Henry在事件中是一个"受害者"的角色。
通过触发词识别和分类,判定事件及其类型后,可以借助模板实现抽取。我们曾提到过模板元素TE,其目的在于更加清楚、完整地描述实体。其中,模板元素通过槽(Slots)描述了命名实体的基本信息。槽的内容可包括名称、类别、种类等,不同类型的事件,对应的模板也不尽相同。通过事件元素与元素角色的识别,将元素填入模板合适的槽,即完成了事件抽取。
案例:刚才有个朋友问我,马老师发生甚么事了?
元素/描述:人物(朋友),时间(刚才), 事件(提问发生了甚么事)
限定域事件抽取通常采用类似预定义关系抽取的方法,即预先定义好目标事 件的类型及每种类型的具体结构(包含哪些具体的事件元素)。 因此,限定域事件抽取可以采用基于模式匹配的方法实现。可以采用完全规则的方法实现,即完全通过人工标注方式获得模式,也可以采用弱监督的模式匹配,即不需要对语料进行完全标注,只需要人工对语料进行一定的预分类或者制定少量种子模式,类似于前述的DIPRE方法,迭代式获得更完善的语料和模板。
同样的,限定域事件抽取也可采用基于机器学习的方法实现。例如,采用有监督学习方式,将事件抽取转化为一个多分类问题。基于特征工程的方法:将事件实例转换成分类器可以接受的特征向量;基于神经网络的方法:自动从文本中获取特征进而完成事件抽取。
限定域事件与预定义关系面临相似的问题:种类有限,维护困难。 如何在开放域环境下,自动识别未知结构与类型的事件?一种思路是采用无监督方法(从而摆脱对于标注语料的依赖),通过聚类找到潜在的事件簇。另一种解决方法:与开放关系抽取中的"知识监督"方案类似: