Sharding-JDBC介绍
Sharding-JDBC定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架的使用。
- 适用于任何基于Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 基于任何第三方的数据库连接池,如:DBCP, C3P0, Druid, HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer和PostgreSQL。
Sharding-JDBC主要功能:
-
数据分片
- 分库分表
- 读写分离
- 分片策略
- 分布式主键
-
分布式事务
- 标准化事务接口
- XA强一致性事务
- 柔性事务
-
数据库治理
- 配置动态化
- 编排治理
- 数据脱敏
- 可视化链路追踪
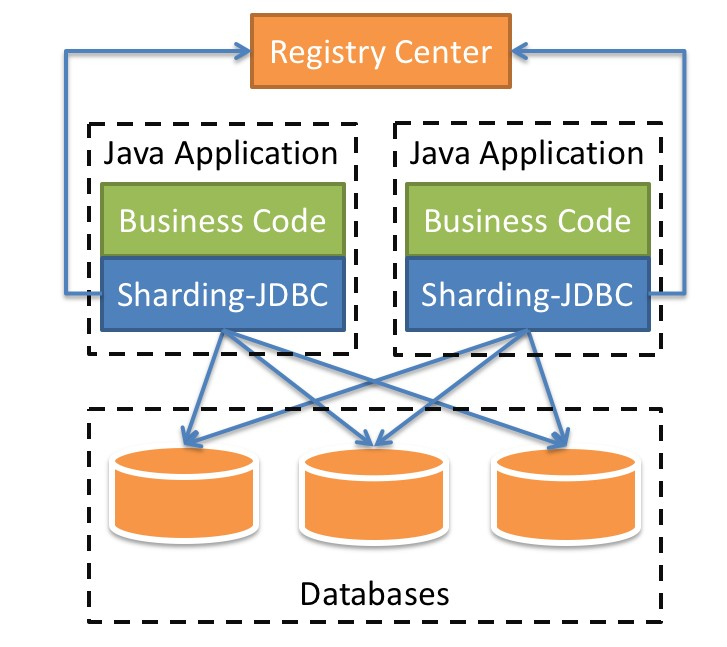
Sharding-JDBC 内部结构:
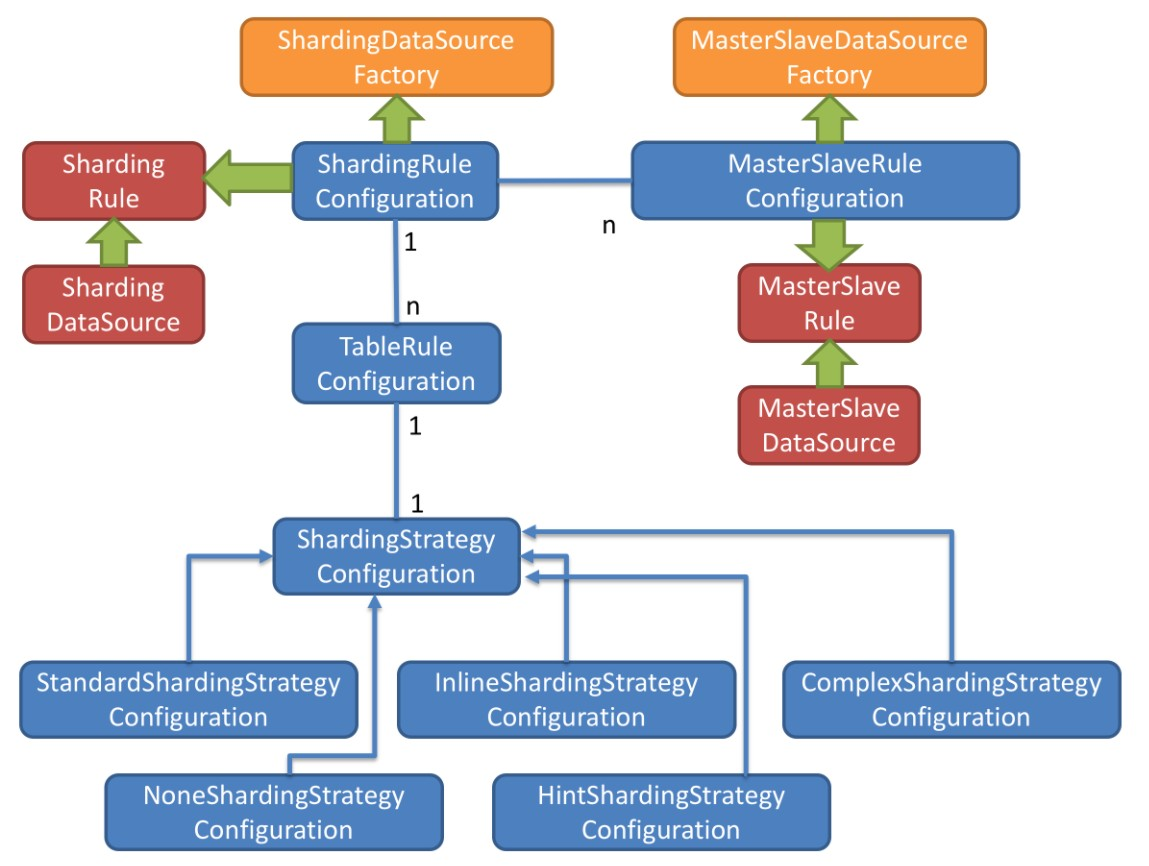
- 图中黄色部分表示的是Sharding-JDBC的入口API,采用工厂方法的形式提供。 目前有ShardingDataSourceFactory和MasterSlaveDataSourceFactory两个工厂类。
- ShardingDataSourceFactory支持分库分表、读写分离操作
- MasterSlaveDataSourceFactory支持读写分离操作
- 图中蓝色部分表示的是Sharding-JDBC的配置对象,提供灵活多变的配置方式。 ShardingRuleConfiguration是分库分表配置的核心和入口,它可以包含多个TableRuleConfiguration和MasterSlaveRuleConfiguration。
- TableRuleConfiguration封装的是表的分片配置信息,有5种配置形式对应不同的Configuration类型。
- MasterSlaveRuleConfiguration封装的是读写分离配置信息。
- 图中红色部分表示的是内部对象,由Sharding-JDBC内部使用,应用开发者无需关注。Sharding-JDBC通过ShardingRuleConfiguration和MasterSlaveRuleConfiguration生成真正供ShardingDataSource和MasterSlaveDataSource使用的规则对象。ShardingDataSource和MasterSlaveDataSource实现了DataSource接口,是JDBC的完整实现方案。
1.数据分片详解与实战
1.1 核心概念
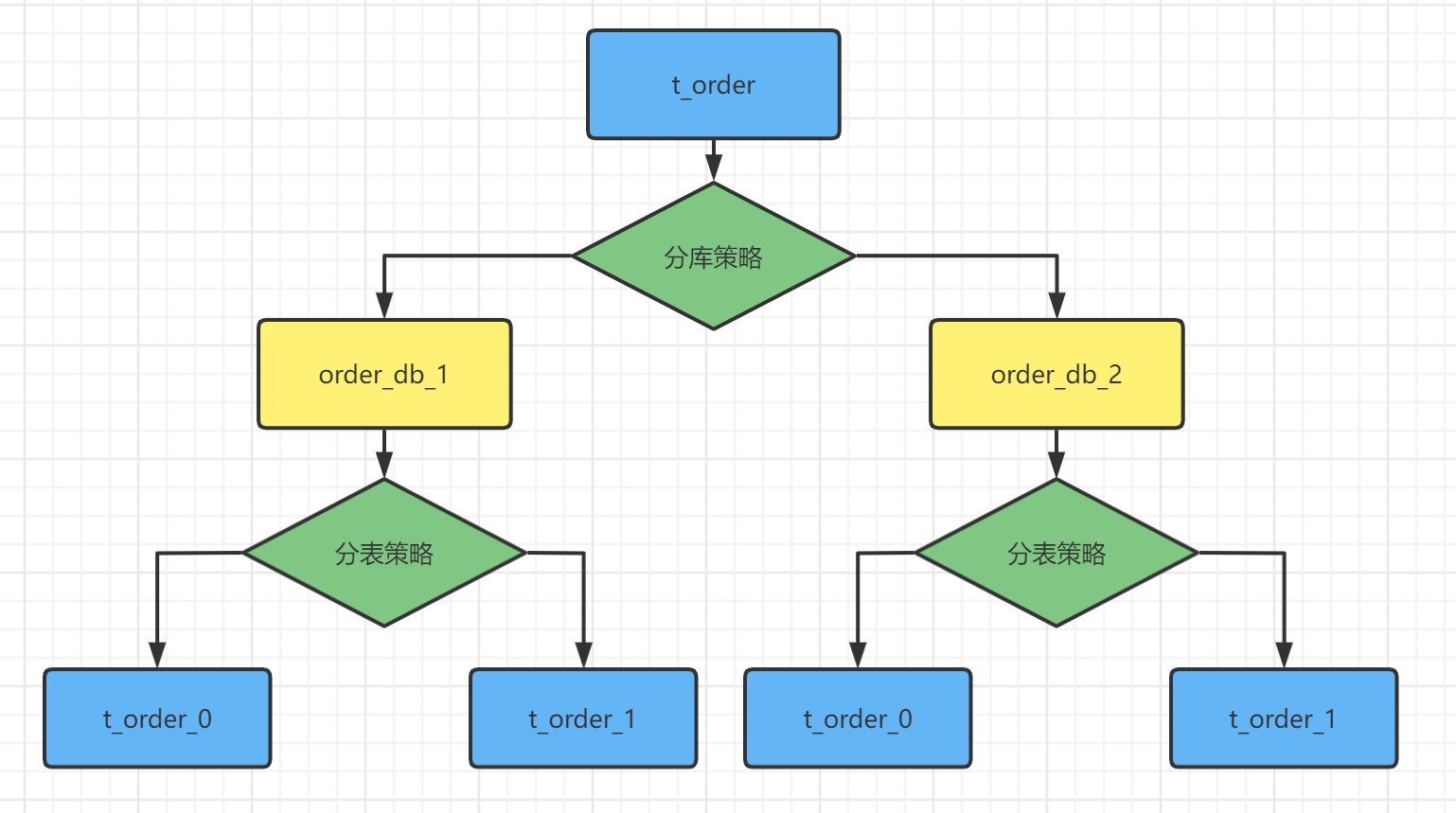
对于数据库的垂直拆分一般都是在数据库设计初期就会完成,因为垂直拆分与业务直接相关,而我们提到的分库分表一般是指的水平拆分,数据分片就是将原本一张数据量较大的表t_order拆分生成数个表结构完全一致的小数据量表t_order_0、t_order_1...,每张表只保存原表的部分数据.
1.1.1 表概念
-
逻辑表
水平拆分的数据库(表)的相同逻辑和数据结构表的总称。 比如的订单表 t_order ---> t_order_0 ...t_order _9.
拆分后t_order表 已经不存在了,这个时候t_order表就是上面拆分的表单的逻辑表.
-
真实表
数据库中真实存在的物理表。 t_order_0 ...t_order _9
-
数据节点
在分片之后,由数据源和数据表组成。比如: t_order_db1.t_order_0
-
绑定表
绑定表是指具有相同分片规则的一组关联表(如主表与子表),例如
t_order与t_order_item均按order_id进行分片。当这些表中order_id相同的数据落在相同的分片上时,它们即构成绑定表关系。绑定表之间的多表关联查询不会产生笛卡尔积,从而显著提升查询效率。sql# t_order:t_order0、t_order1 # t_order_item:t_order_item0、t_order_item1 select * from t_order o join t_order_item i on o.order_id=i.order_id where o.order_id in (10,11);由于分库分表以后这些表被拆分成N多个子表。如果不配置绑定表关系,会出现笛卡尔积关联查询,将产生如下四条SQL。
sqlselect * from t_order0 o join t_order_item0 i on o.order_id=i.order_id where o.order_id in (10,11); select * from t_order0 o join t_order_item1 i on o.order_id=i.order_id where o.order_id in (10,11); select * from t_order1 o join t_order_item0 i on o.order_id=i.order_id where o.order_id in (10,11); select * from t_order1 o join t_order_item1 i on o.order_id=i.order_id where o.order_id in (10,11);
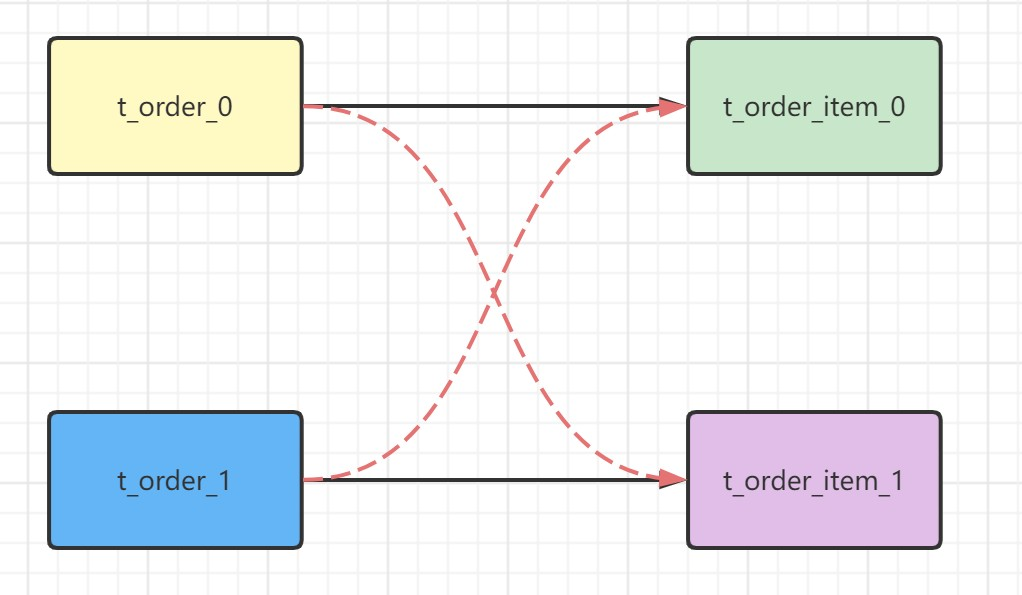
如果配置绑定表关系后再进行关联查询时,只要对应表分片规则一致产生的数据就会落到同一个库中,那么只需 t_order_0和 t_order_item_0 表关联即可。
sql
select * from t_order0 o join t_order_item0 i on o.order_id=i.order_id
where o.order_id in (10,11);
select * from t_order1 o join t_order_item1 i on o.order_id=i.order_id
where o.order_id in (10,11);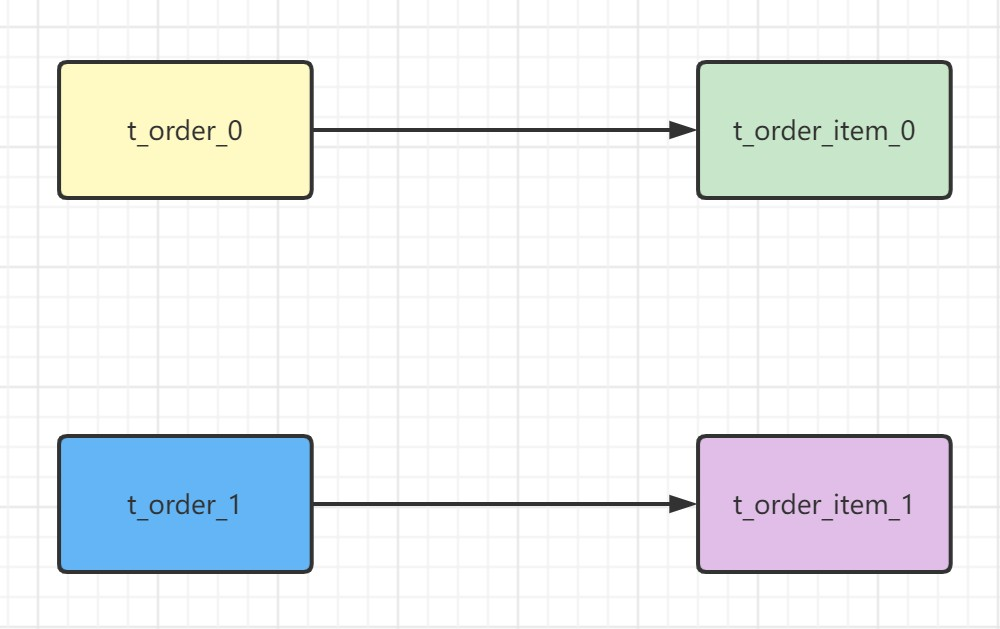
-
广播表
在使用中,有些表没必要做分片,例如字典表、省份信息等,因为他们数据量不大,而且这种表可能需要与海量数据的表进行关联查询。广播表会在不同的数据节点上进行存储,存储的表结构和数据完全相同。
-
单表
指所有的分片数据源中只存在唯一一张的表。适用于数据量不大且不需要做任何分片操作的场景。
1.1.2 分片键
用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。
例:将订单表中的订单主键取模分片,则订单主键为分片字段。 SQL 中如果无分片字段,将执行全路由(去查询所有的真实表),性能较差。 除了对单分片字段的支持,Apache ShardingSphere 也支持根据多个字段进行分片。
1.1.3 分片算法
由于分片算法(ShardingAlgorithm) 和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。目前提供4种分片算法。
-
精确分片算法
用于处理使用单一键作为分片键的=与IN进行分片的场景。
-
范围分片算法
用于处理使用单一键作为分片键的BETWEEN AND、>、<、>=、<=进行分片的场景。
-
复合分片算法
用于处理使用多键作为分片键进行分片的场景,多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。
-
Hint分片算法
Hint 分片算法适用于分片键无法从 SQL 语句中直接获取,而需依赖外部上下文(如用户身份、会话信息等)动态确定的场景。当数据库表结构中不包含实际用于分片的字段时,可通过 SQL Hint 在执行时显式传递分片值,从而实现精确的数据路由。
典型应用场景包括:内部系统按员工登录 ID 进行分库,但业务表中并未存储该字段。此时,借助 Hint 机制,可在不修改表结构的前提下完成分片逻辑。
1.1.4 分片策略
分片策略(ShardingStrategy) 包含分片键和分片算法,真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。目前提供5种分片策略。
-
标准分片策略 StandardShardingStrategy
只支持单分片键,提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。
PreciseShardingAlgorithm是必选的,RangeShardingAlgorithm是可选的。但是SQL中使用了范围操作,如果不配置RangeShardingAlgorithm会采用全库路由扫描,效率低。
-
复合分片策略 ComplexShardingStrategy
支持多分片键。提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。
-
行表达式分片策略 InlineShardingStrategy
只支持单分片键。使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发。如: t_user_$->{u_id % 8} 表示t_user表根据u_id模8,而分成8张表,表名称为t_user_0到t_user_7。
-
Hint分片策略HintShardingStrategy
通过Hint指定分片值而非从SQL中提取分片值的方式进行分片的策略。
-
不分片策略NoneShardingStrategy
不分片的策略。
1.1.5 分布式主键
数据分片后,不同数据节点生成全局唯一主键是非常棘手的问题,同一个逻辑表(t_order)内的不同真实表(t_order_n)之间的自增键由于无法互相感知而产生重复主键。
尽管可通过设置自增主键初始值和步长的方式避免ID碰撞,但这样会使维护成本加大,缺乏完整性和可扩展性。如果后期需要增加分片表的数量,要逐一修改分片表的步长,运维成本非常高,所以不建议这种方式。
ShardingSphere不仅提供了内置的分布式主键生成器,例如UUID、SNOWFLAKE,还抽离出分布式主键生成器的接口,方便用户自行实现自定义的自增主键生成器。
内置主键生成器:
-
UUID
采用UUID.randomUUID()的方式产生分布式主键。
-
SNOWFLAKE
在分片规则配置模块可配置每个表的主键生成策略,默认使用雪花算法,生成64bit的长整型数据。
1.2 搭建基础环境
1.2.1 安装环境
-
jdk: 要求jdk必须是1.8版本及以上
-
MySQL: 推荐mysql5.7版本
-
搭建两台MySQL服务器
mysql-server1 192.168.116.128 mysql-server2 192.168.116.129
1.2.2 创建数据库和表
- 在mysql01服务器上, 创建数据库 payorder_db,并创建表pay_order
sql
CREATE DATABASE payorder_db CHARACTER SET 'utf8';
CREATE TABLE `pay_order` (
`order_id` bigint(20) NOT NULL AUTO_INCREMENT,
`user_id` int(11) DEFAULT NULL,
`product_name` varchar(128) DEFAULT NULL,
`COUNT` int(11) DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB AUTO_INCREMENT=12345679 DEFAULT CHARSET=utf8- 在mysql02服务器上, 创建数据库 user_db,并创建表users
sql
CREATE DATABASE user_db CHARACTER SET 'utf8';
CREATE TABLE `users` (
`id` int(11) NOT NULL,
`username` varchar(255) NOT NULL COMMENT '用户昵称',
`phone` varchar(255) NOT NULL COMMENT '注册手机',
`PASSWORD` varchar(255) DEFAULT NULL COMMENT '用户密码',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户表'1.2.3 创建SpringBoot程序
1) 创建项目
环境说明:
SpringBoot2.3.7+MyBatisPlus+ShardingSphere-JDBC 5.1+Hikari+MySQL 5.7
Spring脚手架: http://start.aliyun.com

- 引入依赖
xml
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.7.RELEASE</version>
<relativePath/>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.1.1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>- 创建实体类
java
@TableName("pay_order") //逻辑表名
@Data
@ToString
public class PayOrder {
@TableId
private long order_id;
private long user_id;
private String product_name;
private int count;
}
@TableName("users")
@Data
@ToString
public class User {
@TableId
private long id;
private String username;
private String phone;
private String password;
}- 创建Mapper
java
@Mapper
public interface PayOrderMapper extends BaseMapper<PayOrder> {
}
@Mapper
public interface UserMapper extends BaseMapper<User> {
}1.3 实现垂直分库
1.3.1 配置文件
使用sharding-jdbc 对数据库中水平拆分的表进行操作,通过sharding-jdbc对分库分表的规则进行配置,配置内容包括:数据源、主键生成策略、分片策略等。
application.properties
-
基础配置
properties# 应用名称 spring.application.name=shardingsphere-jdbc-table -
数据源
properties# 应用名称 spring.application.name=shardingsphere-jdbc-table # 定义多个数据源 spring.shardingsphere.datasource.names = db1,db2 #数据源1 spring.shardingsphere.datasource.db1.type = com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db1.driver-class-name = com.mysql.jdbc.Driver spring.shardingsphere.datasource.db1.url = jdbc:mysql://192.168.116.128:3306/payorder_db?characterEncoding=UTF-8&useSSL=false spring.shardingsphere.datasource.db1.username = root spring.shardingsphere.datasource.db1.password = 123456 #数据源2 spring.shardingsphere.datasource.db2.type = com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db2.driver-class-name = com.mysql.jdbc.Driver spring.shardingsphere.datasource.db2.url = jdbc:mysql://192.168.116.129:3306/user_db?characterEncoding=UTF-8&useSSL=false spring.shardingsphere.datasource.db2.username = root spring.shardingsphere.datasource.db2.password = 123456 #配置数据节点 # 标准分片表配置 # 由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持 inline 表达式。 spring.shardingsphere.rules.sharding.tables.pay_order.actual-data-nodes=db1.pay_order spring.shardingsphere.rules.sharding.tables.users.actual-data-nodes=db2.users mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl -
配置数据节点
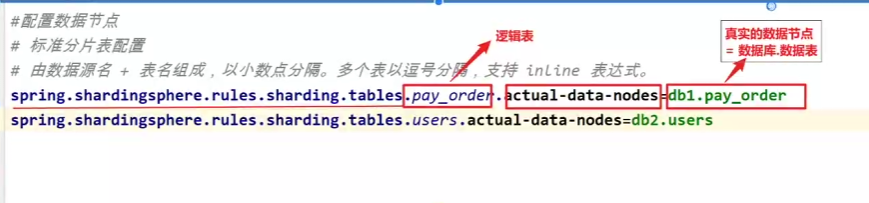
properties
# 标准分片表配置
# 由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持 inline 表达式。
spring.shardingsphere.rules.sharding.tables.pay_order.actual-data-nodes=db1.pay_order
spring.shardingsphere.rules.sharding.tables.users.actual-data-nodes=db2.users-
打开sql输出日志
propertiesmybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
1.3.2 垂直分库测试
java
@SpringBootTest
class ShardingJdbcApplicationTests {
@Autowired
private UserMapper userMapper;
@Autowired
private PayOrderMapper payOrderMapper;
@Test
public void testInsert(){
User user = new User();
user.setId(1002);
user.setUsername("大远哥");
user.setPhone("15612344321");
user.setPassword("123456");
userMapper.insert(user);
PayOrder payOrder = new PayOrder();
payOrder.setOrder_id(12345679);
payOrder.setProduct_name("猕猴桃");
payOrder.setUser_id(user.getId());
payOrder.setCount(2);
payOrderMapper.insert(payOrder);
}
@Test
public void testSelect(){
User user = userMapper.selectById(1001);
System.out.println(user);
PayOrder payOrder = payOrderMapper.selectById(12345678);
System.out.println(payOrder);
}
}
数据插入情况:
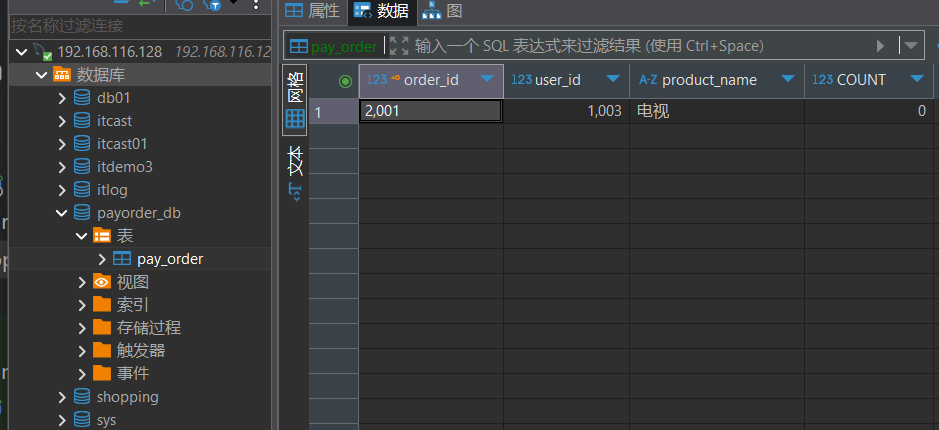

可以看到User数据就插入到了129的服务器,PayOrder数据就插入到了128服务器。这就实现了一个简单的垂直分库的情况,不同的表分布在不同的服务器上
1.4 实现水平分表
1.4.1 数据准备
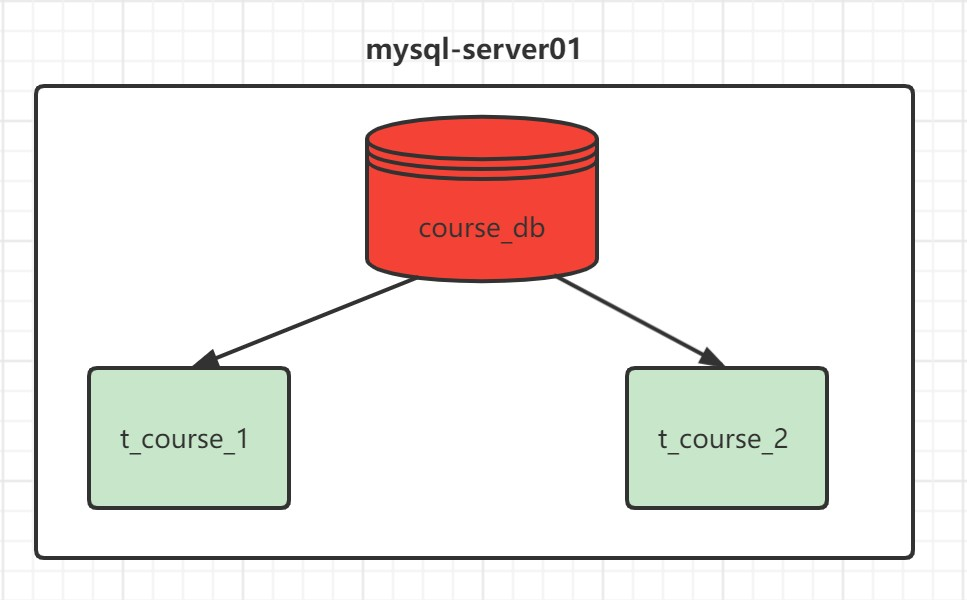
需求说明:
- 在mysql-server01服务器上, 创建数据库 course_db
- 创建表 t_course_1 、 t_course_2
- 约定规则:如果添加的课程 id 为偶数添加到 t_course_1 中,奇数添加到 t_course_2 中。
水平分片的id需要在业务层实现,不能依赖数据库的主键自增
sql
CREATE TABLE t_course_1 (
`cid` BIGINT(20) NOT NULL,
`user_id` BIGINT(20) DEFAULT NULL,
`cname` VARCHAR(50) DEFAULT NULL,
`brief` VARCHAR(50) DEFAULT NULL,
`price` DOUBLE DEFAULT NULL,
`status` INT(11) DEFAULT NULL,
PRIMARY KEY (`cid`)
) ENGINE=INNODB DEFAULT CHARSET=utf8
CREATE TABLE t_course_2 (
`cid` BIGINT(20) NOT NULL,
`user_id` BIGINT(20) DEFAULT NULL,
`cname` VARCHAR(50) DEFAULT NULL,
`brief` VARCHAR(50) DEFAULT NULL,
`price` DOUBLE DEFAULT NULL,
`status` INT(11) DEFAULT NULL,
PRIMARY KEY (`cid`)
) ENGINE=INNODB DEFAULT CHARSET=utf81.4.2 配置文件
1) 基础配置
properties
# 应用名称
spring.application.name=sharding-jdbc
# 打印SQl
spring.shardingsphere.props.sql-show=true2) 数据源配置
properties
#===============数据源配置
#配置真实的数据源
spring.shardingsphere.datasource.names=db1
#数据源1
spring.shardingsphere.datasource.db1.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db1.url = jdbc:mysql://192.168.116.128:3306/course_db?characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.db1.username = root
spring.shardingsphere.datasource.db1.password = 1234563) 数据节点配置
先指定t_course_1表试试
properties
#1.配置数据节点
#指定course表的分布情况(配置表在哪个数据库,表名是什么)
spring.shardingsphere.rules.sharding.tables.t_course.actual-data-nodes=db1.t_course_1 4) 完整配置文件
properties
# 应用名称
spring.application.name=shardingsphere-jdbc-table
# 打印SQl
spring.shardingsphere.props.sql-show=true
# 定义多个数据源
spring.shardingsphere.datasource.names = db1
#数据源1
spring.shardingsphere.datasource.db1.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db1.url = jdbc:mysql://192.168.116.128:3306/course_db?characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.db1.username = root
spring.shardingsphere.datasource.db1.password = 123456
#配置数据节点
# 标准分片表配置
# 由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持 inline 表达式。
spring.shardingsphere.rules.sharding.tables.t_course.actual-data-nodes=db1.t_course_1
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl1.4.3 测试
- course类
java
@TableName("t_course")
@Data
@ToString
public class Course implements Serializable {
@TableId
private Long cid;
private Long userId;
private String cname;
private String brief;
private double price;
private int status;
}- CourseMapper
java
@Mapper
public interface CourseMapper extends BaseMapper<Course> {
}
java
//水平分表测试
@Autowired
private CourseMapper courseMapper;
@Test
public void testInsertCourse(){
for (int i = 0; i < 3; i++) {
Course course = new Course();
course.setCid(10086L+i);
course.setUserId(1L+i);
course.setCname("Java经典面试题讲解");
course.setBrief("课程涵盖目前最容易被问到的10000道Java面试题");
course.setPrice(100.0);
course.setStatus(1);
courseMapper.insert(course);
}
}
插入数据情况
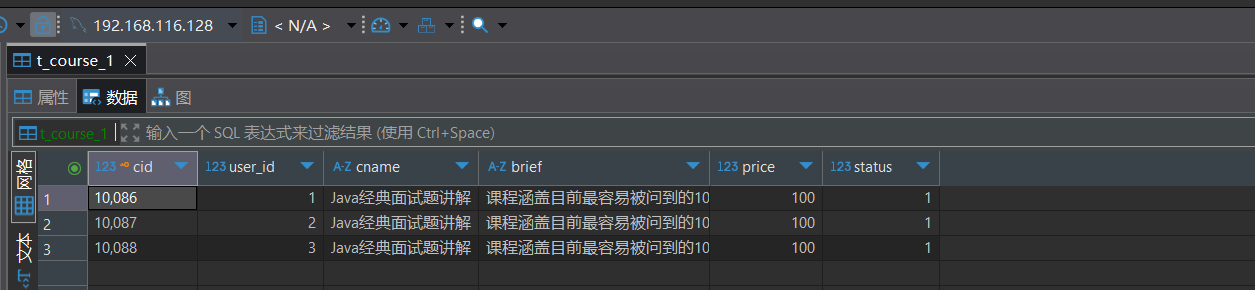
1.4.4 行表达式
对上面的配置操作进行修改, 使用inline表达式,灵活配置数据节点
行表达式的使用: https://shardingsphere.apache.org/document/5.1.1/cn/features/sharding/concept/inline-expression/)
properties
spring.shardingsphere.rules.sharding.tables.t_course.actual-data-nodes=db1.t_course_$->{1..2}表达式 db1.t_course_$->{1..2}
会被 大括号中的 `{1..2}` 所替换, `{begin..end}` 表示范围区间
会有两种选择: db1.t_course_1 和 db1.t_course_2
1.4.5 配置分片策略
分片策略包括分片键和分片算法.
分片规则,约定cid值为偶数时,添加到t_course_1表,如果cid是奇数则添加到t_course_2表
- 配置分片策略
properties
#1.配置数据节点
#指定course表的分布情况(配置表在哪个数据库,表名是什么)
spring.shardingsphere.rules.sharding.tables.t_course.actual-data-nodes=db1.t_course_$->{1..2}
##2.配置分片策略(分片策略包括分片键和分片算法)
#2.1 分片键名称: cid
spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-column=cid
#2.2 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-algorithm-name=table-inline
#2.3 分片算法类型: 行表达式分片算法(标准分片算法下包含->行表达式分片算法)
spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.type=INLINE
#2.4 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.props.algorithm-expression=t_course_$->{cid % 2 + 1}测试:
完整配置文件
properties
# 应用名称
spring.application.name=shardingsphere-jdbc-table
# 打印SQl
spring.shardingsphere.props.sql-show=true
# 定义多个数据源
spring.shardingsphere.datasource.names = db1
#数据源1
spring.shardingsphere.datasource.db1.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db1.url = jdbc:mysql://192.168.116.128:3306/course_db?characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.db1.username = root
spring.shardingsphere.datasource.db1.password = 123456
#1.配置数据节点
#指定course表的分布情况(配置表在哪个数据库,表名是什么)
spring.shardingsphere.rules.sharding.tables.t_course.actual-data-nodes=db1.t_course_$->{1..2}
##2.配置分片策略(分片策略包括分片键和分片算法)
#2.1 分片键名称: cid
spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-column=cid
#2.2 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-algorithm-name=table-inline
#2.3 分片算法类型: 行表达式分片算法(标准分片算法下包含->行表达式分片算法)
spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.type=INLINE
#2.4 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.props.algorithm-expression=t_course_$->{cid % 2 + 1}
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
java
@Test
public void testInsertCourse(){
for (int i = 0; i < 20; i++) {
Course course = new Course();
course.setCid(10086L+i);
course.setUserId(1L+i);
course.setCname("Java经典面试题讲解");
course.setBrief("课程涵盖目前最容易被问到的10000道Java面试题");
course.setPrice(100.0);
course.setStatus(1);
courseMapper.insert(course);
}
}数据分布情况:
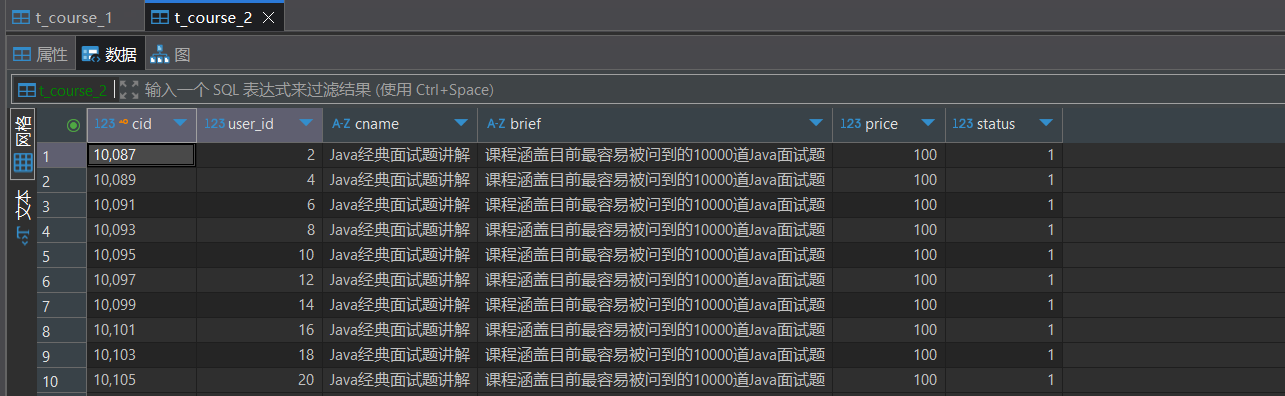
1.4.6 分布式序列算法
在水平分表中由于数据会存储到多个表中,每个表有独立的主键,也就是说有可能会发生主键重复的情况,所以就不能使用MySQL默认的主键自增应该使用分布式ID作为主键值,确保每个主键都是唯一的
雪花算法:
https://shardingsphere.apache.org/document/5.1.1/cn/features/sharding/concept/key-generator/
水平分片需要关注全局序列,因为不能简单的使用基于数据库的主键自增。
这里有两种方案:一种是基于MyBatisPlus的id策略;一种是ShardingSphere-JDBC的全局序列配置。
- 基于MyBatisPlus的id策略:将Course类的id设置成如下形式
java
@TableName("t_course")
@Data
@ToString
public class Course imp {
@TableId(value = "cid",type = IdType.ASSIGN_ID)
private Long cid;
private Long userId;
private String cname;
private String brief;
private double price;
private int status;
}- 基于ShardingSphere-JDBC的全局序列配置:和前面的MyBatisPlus的策略二选一
properties
#3.分布式序列配置
#3.1 分布式序列-列名称
spring.shardingsphere.rules.sharding.tables.t_course.key-generate-strategy.column=cid
#3.2 分布式序列-算法名称
spring.shardingsphere.rules.sharding.tables.t_course.key-generate-strategy.key-generator-name=alg_snowflake
#3.3 分布式序列-算法类型
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=SNOWFLAKE
# 分布式序列算法属性配置,可以先不配置
#spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.props.xxx=此时,需要将实体类中的id策略修改成以下形式:
java
//当配置了shardingsphere-jdbc的分布式序列时,自动使用shardingsphere-jdbc的分布式序列
//当没有配置shardingsphere-jdbc的分布式序列时,自动依赖数据库的主键自增策略
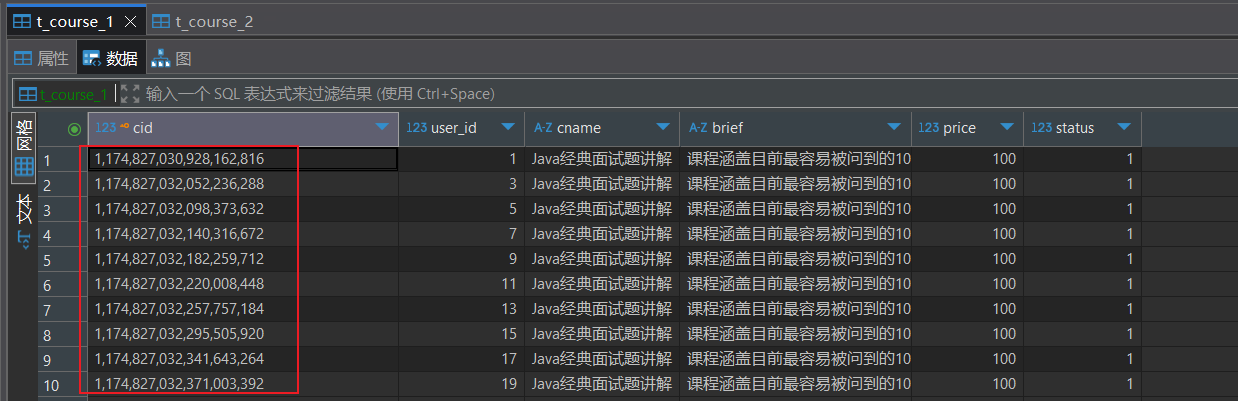
@TableId(type = IdType.AUTO)测试:
java
@Test
public void testInsertCourse(){
for (int i = 0; i < 20; i++) {
Course course = new Course();
course.setUserId(1L+i);
course.setCname("Java经典面试题讲解");
course.setBrief("课程涵盖目前最容易被问到的10000道Java面试题");
course.setPrice(100.0);
course.setStatus(1);
courseMapper.insert(course);
}
}
1.5 实现水平分库
水平分库是把同一个表的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器上。接下来看一下如何使用Sharding-JDBC实现水平分库
1.5.1 数据准备
- 创建数据库
在mysql-server01服务器上, 创建数据库 course_db0, 在mysql-server02服务器上, 创建数据库 course_db1
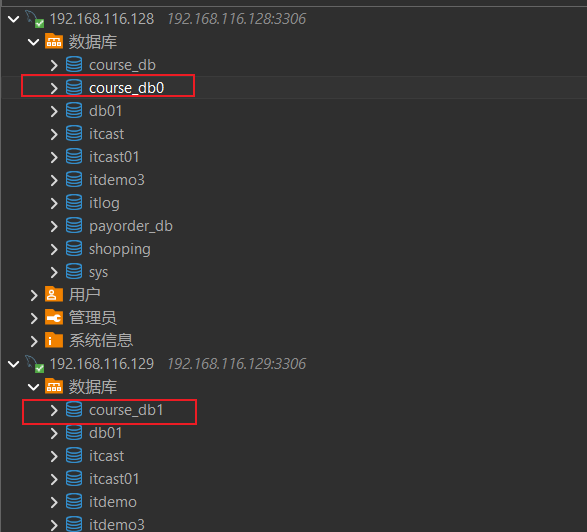
- 分别在course_db0和course_db1中创建表t_course_0
sql
CREATE TABLE `t_course_0` (
`cid` bigint(20) NOT NULL,
`user_id` bigint(20) DEFAULT NULL,
`corder_no` bigint(20) DEFAULT NULL,
`cname` varchar(50) DEFAULT NULL,
`brief` varchar(50) DEFAULT NULL,
`price` double DEFAULT NULL,
`status` int(11) DEFAULT NULL,
PRIMARY KEY (`cid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8-
实体类
原有的Course类添加一个
corder_no即可.
如果使用了ShardingJDBC的分布式序列,ShardingJDBC会自动生成id,如果没有配置就自动依赖mybatisplus设置的主键自增IdType.AUTO
java
@TableName("t_course")
@Data
@ToString
public class Course implements Serializable {
@TableId(value = "cid",type = IdType.AUTO)
private Long cid;
private Long userId;
private Long corderNo;
private String cname;
private String brief;
private double price;
private int status;
}1.5.2 配置文件
1) 数据源配置
properties
# 定义多个数据源
spring.shardingsphere.datasource.names = db0,db1
#数据源1
spring.shardingsphere.datasource.db0.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db0.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db0.url = jdbc:mysql://192.168.116.128:3306/course_db0?characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.db0.username = root
spring.shardingsphere.datasource.db0.password = 123456
#数据源2
spring.shardingsphere.datasource.db1.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db1.url = jdbc:mysql://192.168.116.129:3306/course_db1?characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.db1.username = root
spring.shardingsphere.datasource.db1.password = 1234562) 数据节点配置
先测试水平分库, 数据节点中数据源是动态的, 数据表固定为t_course_0, 方便测试
- db$->{0...1}.t_course_0,表示数据库是动态的,db由db0、db1组成,表就是t_course_0一个表
properties
spring.shardingsphere.rules.sharding.tables.t_course.actual-data-nodes=db$->{0..1}.t_course_03) 水平分库之分库策略配置
分库策略: 以user_id为分片键,分片策略为user_id % 2,user_id为偶数操作db0数据源,否则操作db1数据源。
properties
#===============水平分库-分库策略==============
##2.配置分片策略(分片策略包括分片键和分片算法)
#2.1 分片键名称: user_id
spring.shardingsphere.rules.sharding.tables.t_course.database-strategy.standard.sharding-column=user_id
#2.2 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_course.database-strategy.standard.sharding-algorithm-name=table-inline
#2.3 分片算法类型: 行表达式分片算法(标准分片算法下包含->行表达式分片算法)
spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.type=INLINE
#2.4 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.props.algorithm-expression=db$->{user_id % 2}4) 分布式主键自增
properties
#3.分布式序列配置
#3.1 分布式序列-列名称
spring.shardingsphere.rules.sharding.tables.t_course.key-generate-strategy.column=cid
#3.2 分布式序列-算法名称
spring.shardingsphere.rules.sharding.tables.t_course.key-generate-strategy.key-generator-name=alg_snowflake
#3.3 分布式序列-算法类型
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=SNOWFLAKE5) 测试
完成配置文件
properties
# 应用名称
spring.application.name=shardingsphere-jdbc-table
# 打印SQl
spring.shardingsphere.props.sql-show=true
# 定义多个数据源
spring.shardingsphere.datasource.names = db0,db1
#数据源1
spring.shardingsphere.datasource.db0.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db0.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db0.url = jdbc:mysql://192.168.116.128:3306/course_db0?characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.db0.username = root
spring.shardingsphere.datasource.db0.password = 123456
#数据源2
spring.shardingsphere.datasource.db1.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db1.url = jdbc:mysql://192.168.116.129:3306/course_db1?characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.db1.username = root
spring.shardingsphere.datasource.db1.password = 123456
#1.配置数据节点
#指定course表的分布情况(配置表在哪个数据库,表名是什么)
spring.shardingsphere.rules.sharding.tables.t_course.actual-data-nodes=db$->{0..1}.t_course_0
##2.配置分片策略(分片策略包括分片键和分片算法)
#2.1 分片键名称: user_id
spring.shardingsphere.rules.sharding.tables.t_course.database-strategy.standard.sharding-column=user_id
#2.2 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_course.database-strategy.standard.sharding-algorithm-name=table-inline
#2.3 分片算法类型: 行表达式分片算法(标准分片算法下包含->行表达式分片算法)
spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.type=INLINE
#2.4 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.props.algorithm-expression=db$->{user_id % 2}
#3.分布式序列配置
#3.1 分布式序列-列名称
spring.shardingsphere.rules.sharding.tables.t_course.key-generate-strategy.column=cid
#3.2 分布式序列-算法名称
spring.shardingsphere.rules.sharding.tables.t_course.key-generate-strategy.key-generator-name=alg_snowflake
#3.3 分布式序列-算法类型
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=SNOWFLAKE
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
java
/**
* 水平分库 --> 分库插入数据
*/
@Test
public void testInsertCourseDB(){
for (int i = 0; i < 10; i++) {
Course course = new Course();
course.setUserId(1001L+i);
course.setCname("Java经典面试题讲解");
course.setBrief("课程涵盖目前最容易被问到的10000道Java面试题");
course.setPrice(100.0);
course.setStatus(1);
courseMapper.insert(course);
}
}数据分布情况:可以看到偶数都分布到了course_db0上

6) 水平分库之分表策略配置
可以分库和分表的分片策略同时设置
分库规则:以user_id为分片键,分片策略为user_id % 2,user_id为偶数操作db0数据源,否则操作db1数据源。
分表规则:t_course 表中 cid 的哈希值为偶数时,数据插入对应服务器的t_course_0表,cid 的哈希值为奇数时,数据插入对应服务器的t_course_1。
- 修改数据节点配置,数据落地到dn0或db1数据源的 t_course_0表 或者 t_course_1表.
properties
spring.shardingsphere.rules.sharding.tables.t_course.actual-data-nodes=db$->{0..1}.t_course_$->{0..1}- 分别在两个库中再创建一个t_course_1表
sql
CREATE TABLE `t_course_1` (
`cid` bigint(20) NOT NULL,
`user_id` bigint(20) DEFAULT NULL,
`corder_no` bigint(20) DEFAULT NULL,
`cname` varchar(50) DEFAULT NULL,
`brief` varchar(50) DEFAULT NULL,
`price` double DEFAULT NULL,
`status` int(11) DEFAULT NULL,
PRIMARY KEY (`cid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8- 分表策略配置 (对id进行哈希取模)
properties
#===============水平分库-分表策略==============
#----分片列名称----
spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-column=cid
##----分片算法配置----
##分片算法名称
spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-algorithm-name=inline-hash-mod
#分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.inline-hash-mod.type=INLINE
#分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.inline-hash-mod.props.algorithm-expression=t_course_$->{Math.abs(cid.hashCode()) % 2}完整配置文件
properties
# 应用名称
spring.application.name=shardingsphere-jdbc-table
# 打印SQl
spring.shardingsphere.props.sql-show=true
# 定义多个数据源
spring.shardingsphere.datasource.names = db0,db1
#数据源1
spring.shardingsphere.datasource.db0.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db0.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db0.url = jdbc:mysql://192.168.116.128:3306/course_db0?characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.db0.username = root
spring.shardingsphere.datasource.db0.password = 123456
#数据源2
spring.shardingsphere.datasource.db1.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db1.url = jdbc:mysql://192.168.116.129:3306/course_db1?characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.db1.username = root
spring.shardingsphere.datasource.db1.password = 123456
#1.配置数据节点
#指定course表的分布情况(配置表在哪个数据库,表名是什么)
spring.shardingsphere.rules.sharding.tables.t_course.actual-data-nodes=db$->{0..1}.t_course_$->{0..1}
##2.配置分片策略(分片策略包括分片键和分片算法)
#2.1 分片键名称: user_id
spring.shardingsphere.rules.sharding.tables.t_course.database-strategy.standard.sharding-column=user_id
#2.2 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_course.database-strategy.standard.sharding-algorithm-name=table-inline
#2.3 分片算法类型: 行表达式分片算法(标准分片算法下包含->行表达式分片算法)
spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.type=INLINE
#2.4 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.props.algorithm-expression=db$->{user_id % 2}
#3.分布式序列配置
#3.1 分布式序列-列名称
spring.shardingsphere.rules.sharding.tables.t_course.key-generate-strategy.column=cid
#3.2 分布式序列-算法名称
spring.shardingsphere.rules.sharding.tables.t_course.key-generate-strategy.key-generator-name=alg_snowflake
#3.3 分布式序列-算法类型
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=SNOWFLAKE
#4===============水平分库-分表策略==============
#4.1----分片列名称----
spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-column=cid
##----分片算法配置----
##4.2分片算法名称
spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-algorithm-name=inline-hash-mod
#4.3分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.inline-hash-mod.type=INLINE
#4.4分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.inline-hash-mod.props.algorithm-expression=t_course_$->{Math.abs(cid.hashCode()) % 2}
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl官方提供分片算法配置
https://shardingsphere.apache.org/document/current/cn/dev-manual/sharding/

properties
#----分片列名称----
spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-column=cid
#----分片算法配置----
#分片算法名称 -> 取模分片算法
spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-algorithm-name=table-hash-mod
#分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.table-hash-mod.type=HASH_MOD
#分片算法属性配置-分片数量,有两个表值设置为2
spring.shardingsphere.rules.sharding.sharding-algorithms.table-hash-mod.props.sharding-count=21.5.3 水平分库测试
- 测试插入数据
java
//水平分库 --> 分表策略
@Test
public void testInsertCourseTable(){
for (int i = 100; i < 150; i++) {
Course course = new Course();
course.setUserId(1L+i);
course.setCname("Java面试题详解");
course.setCorderNo(1000L+i);
course.setBrief("经典的10000道面试题");
course.setPrice(100.00);
course.setStatus(1);
courseMapper.insert(course);
}
}
@Test
public void testHashMod(){
//cid的hash值为偶数时,插入对应数据库的t_course_0表,为奇数插入对应数据库的t_course_1
Long cid = 1175196313105465345L; //获取到cid
int hash = cid.hashCode();
System.out.println(hash);
System.out.println("===========" + Math.abs(hash % 2) ); //获取针对cid进行hash取模后的值
}两台服务器中的两个表都已经有数据
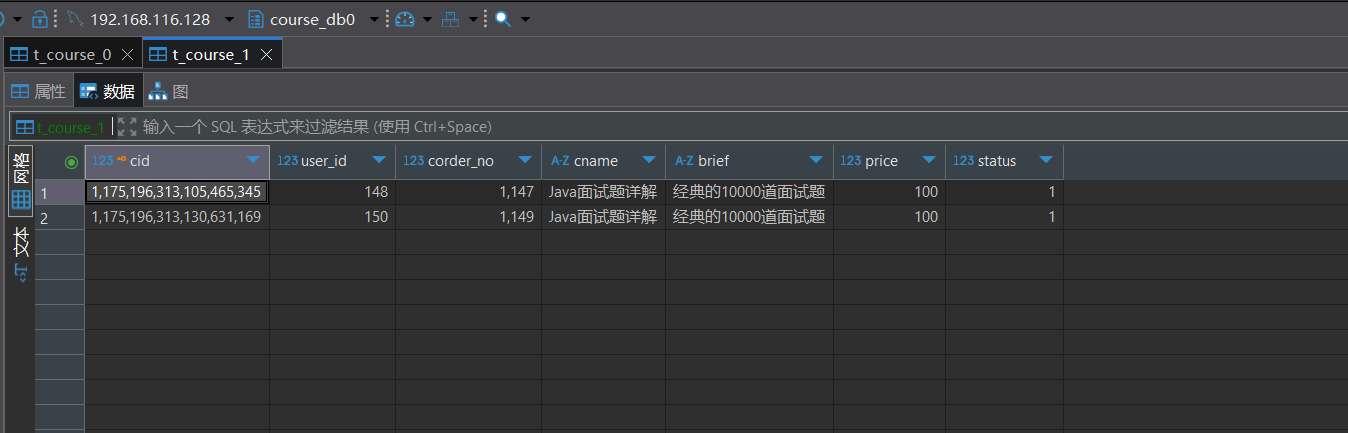
1.5.4 水平分库查询
下边来测试查询,看看shardingjdbc是怎么把多个表的数据汇总查询出来的
java
//查询所有记录
@Test
public void testShardingSelectAll(){
List<Course> courseList = courseMapper.selectList(null);
courseList.forEach(System.out::println);
}- 查看日志: 查询了两个数据源,每个数据源中使用UNION ALL连接两个表

java
//根据user_id进行查询
@Test
public void testSelectByUserId(){
QueryWrapper<Course> courseQueryWrapper = new QueryWrapper<>();
courseQueryWrapper.eq("user_id",2L);
List<Course> courses = courseMapper.selectList(courseQueryWrapper);
courses.forEach(System.out::println);
}- 查看日志: 查询了一个数据源,使用UNION ALL连接数据源中的两个表

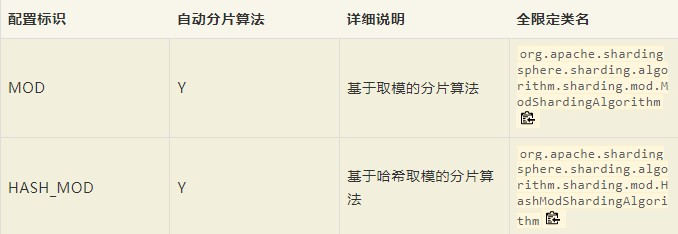
1.5.5 分片算法HASH_MOD和MOD
HASH_MOD和MOD是shardingjdbc中自带的分片算法
上边水平分库使用的是**t_course_KaTeX parse error: Expected '}', got 'EOF' at end of input: ...MOD,就和t_course_->{Math.abs(cid.hashCode()) % 2}分片规律差不多
分表的策略db$->{user_id % 2}可以用shardingjdbc中的MOD来替代,效果都是一样
HASH_MOD配置文件内容:
properties
#----分片列名称----
spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-column=cid
#----分片算法配置----
#分片算法名称 -> 取模分片算法
spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-algorithm-name=table-hash-mod
#分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.table-hash-mod.type=HASH_MOD
#分片算法属性配置-分片数量,有两个表值设置为2
spring.shardingsphere.rules.sharding.sharding-algorithms.table-hash-mod.props.sharding-count=2MOD配置文件内容:
properties
###2.配置分片策略(分片策略包括分片键和分片算法)
##2.1 分片键名称: user_id
spring.shardingsphere.rules.sharding.tables.t_course.database-strategy.standard.sharding-column=user_id
##2.2 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_course.database-strategy.standard.sharding-algorithm-name=table-mod
#2.3 --分片算法
spring.shardingsphere.rules.sharding.sharding-algorithms.table-mod.type=MOD
spring.shardingsphere.rules.sharding.sharding-algorithms.table-mod.props.sharding-count=2完整配置文件内容:
properties
# 应用名称
spring.application.name=shardingsphere-jdbc-table
# 打印SQl
spring.shardingsphere.props.sql-show=true
# 定义多个数据源
spring.shardingsphere.datasource.names = db0,db1
#数据源1
spring.shardingsphere.datasource.db0.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db0.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db0.url = jdbc:mysql://192.168.116.128:3306/course_db0?characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.db0.username = root
spring.shardingsphere.datasource.db0.password = 123456
#数据源2
spring.shardingsphere.datasource.db1.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db1.url = jdbc:mysql://192.168.116.129:3306/course_db1?characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.db1.username = root
spring.shardingsphere.datasource.db1.password = 123456
#1.配置数据节点
#指定course表的分布情况(配置表在哪个数据库,表名是什么)
spring.shardingsphere.rules.sharding.tables.t_course.actual-data-nodes=db$->{0..1}.t_course_$->{0..1}
###2.配置分片策略(分片策略包括分片键和分片算法)
##2.1 分片键名称: user_id
spring.shardingsphere.rules.sharding.tables.t_course.database-strategy.standard.sharding-column=user_id
##2.2 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_course.database-strategy.standard.sharding-algorithm-name=table-mod
#2.3 --分片算法
spring.shardingsphere.rules.sharding.sharding-algorithms.table-mod.type=MOD
spring.shardingsphere.rules.sharding.sharding-algorithms.table-mod.props.sharding-count=2
#3.分布式序列配置
#3.1 分布式序列-列名称
spring.shardingsphere.rules.sharding.tables.t_course.key-generate-strategy.column=cid
#3.2 分布式序列-算法名称
spring.shardingsphere.rules.sharding.tables.t_course.key-generate-strategy.key-generator-name=alg_snowflake
#3.3 分布式序列-算法类型
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=SNOWFLAKE
#----分片列名称----
spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-column=cid
#4===============水平分库-分表策略==============
#4.1----分片列名称----
spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-algorithm-name=table-hash-mod
###----分片算法配置----
#4.2分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.table-hash-mod.type=HASH_MOD
#4.3分片算法属性配置-分片数量,有两个表值设置为2
spring.shardingsphere.rules.sharding.sharding-algorithms.table-hash-mod.props.sharding-count=2
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl测试:
java
@Test
public void testInsertCourseTable() throws InterruptedException {
for (int i = 100; i < 150; i++) {
Thread.sleep(10);
Course course = new Course();
course.setUserId(1L+i);
course.setCname("Java面试题详解");
course.setCorderNo(1000L+i);
course.setBrief("经典的10000道面试题");
course.setPrice(100.00);
course.setStatus(1);
courseMapper.insert(course);
}
}1.5.6 水平分库总结
水平分库包含了分库策略和分表策略.
- 分库策略 ,目的是将一个逻辑表 , 映射到多个数据源
properties
#===============水平分库-分库策略==============
#----分片列名称----
spring.shardingsphere.rules.sharding.tables.t_course.database-strategy.standard.sharding-column=user_id
#----分片算法配置----
#分片算法名称 -> 行表达式分片算法
spring.shardingsphere.rules.sharding.tables.t_course.database-strategy.standard.sharding-algorithm-name=table-inline
#分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.type=INLINE
#分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.props.algorithm-expression=db$->{user_id % 2}- 分表策略, 如何将一个逻辑表 , 映射为多个 实际表
properties
#===============水平分库-分表策略==============
#----分片列名称----
spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-column=cid
##----分片算法配置----
#分片算法名称
spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-algorithm-name=inline-hash-mod
#分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.inline-hash-mod.type=INLINE
#分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.inline-hash-mod.props.algorithm-expression=t_course_$->{Math.abs(cid.hashCode()) % 2}1.6 实现绑定表
先来回顾一下绑定表的概念: 指的是分片规则一致的关系表(主表、子表),例如t_order和t_order_item,均按照order_id分片,则此两个表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,可以提升关联查询效率。
注: 绑定表是建立在多表关联的基础上的.所以我们先来完成多表关联的配置
1.6.1 数据准备
先在两个服务器中分别创建shardingjdbc这个数据库,具体库和表如下
server01:
server02:

-
创建表
在
server01服务器上的shardingjdbc0数据库 和server02服务器上的shardingjdbc1数据库分别创建t_order和t_order_item表 ,表结构如下:sqlCREATE TABLE `t_order_0` ( `order_id` bigint NOT NULL COMMENT '订单ID', `user_id` int NOT NULL COMMENT '用户ID', `product_name` varchar(255) NOT NULL COMMENT '商品名称', `total_price` decimal(10,2) NOT NULL COMMENT '总价', `status` varchar(50) DEFAULT 'CREATED' COMMENT '订单状态', `create_time` datetime DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`order_id`) ); CREATE TABLE `t_order_1` ( `order_id` bigint NOT NULL COMMENT '订单ID', `user_id` int NOT NULL COMMENT '用户ID', `product_name` varchar(255) NOT NULL COMMENT '商品名称', `total_price` decimal(10,2) NOT NULL COMMENT '总价', `status` varchar(50) DEFAULT 'CREATED' COMMENT '订单状态', `create_time` datetime DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`order_id`) ); CREATE TABLE `t_order_item_0` ( `item_id` bigint NOT NULL COMMENT '订单项ID', `order_id` bigint NOT NULL COMMENT '订单ID', `product_name` varchar(255) NOT NULL COMMENT '商品名称', `price` decimal(10,2) NOT NULL COMMENT '单价', `user_id` int NOT NULL COMMENT '用户ID', `quantity` int NOT NULL COMMENT '数量', `total_price` decimal(10,2) NOT NULL COMMENT '小计', `create_time` datetime DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`item_id`) ); CREATE TABLE `t_order_item_1` ( `item_id` bigint NOT NULL COMMENT '订单项ID', `order_id` bigint NOT NULL COMMENT '订单ID', `product_name` varchar(255) NOT NULL COMMENT '商品名称', `price` decimal(10,2) NOT NULL COMMENT '单价', `user_id` int NOT NULL COMMENT '用户ID', `quantity` int NOT NULL COMMENT '数量', `total_price` decimal(10,2) NOT NULL COMMENT '小计', `create_time` datetime DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`item_id`) );
1.6.2 创建实体类
java
@TableName("t_order")
@Data
@ToString
public class TOrder {
@TableId
private Long orderId;
private Integer userId;
private String productName;
private BigDecimal totalPrice;
private String status;
private LocalDateTime createTime;
}
java
@TableName("t_order_item")
@Data
@ToString
public class TOrderItem {
@TableId
private Long itemId;
private Long orderId;
private String productName;
private BigDecimal price;
private Integer quantity;
private Integer userId;
private BigDecimal totalPrice;
private LocalDateTime createTime;
}1.6.3 创建mapper
java
@Mapper
public interface TOrderMapper extends BaseMapper<TOrder> {
}
java
@Mapper
public interface TOrderItemMapper extends BaseMapper<TOrderItem> {
}1.6.4 配置多表关联
t_order的分片表、分片策略、分布式序列策略和t_order_item保持一致
- 数据源
properties
# 定义多个数据源
spring.shardingsphere.datasource.names = db0,db1
#数据源1
spring.shardingsphere.datasource.db0.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db0.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db0.url = jdbc:mysql://192.168.116.128:3306/shardingjdbc0?characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.db0.username = root
spring.shardingsphere.datasource.db0.password = 123456
#数据源2
spring.shardingsphere.datasource.db1.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db1.url = jdbc:mysql://192.168.116.129:3306/shardingjdbc1?characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.db1.username = root
spring.shardingsphere.datasource.db1.password = 123456- 数据节点
properties
#1.配置数据节点
#指定course表的分布情况(配置表在哪个数据库,表名是什么)
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=db$->{0..1}.t_order_$->{0..1}
spring.shardingsphere.rules.sharding.tables.t_order_item.actual-data-nodes=db$->{0..1}.t_order_item_$->{0..1}- 分库策略
properties
#2.=========水平分库-分库策略========
## t_order 分库策略
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-column=user_Id
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=table-mod
# ----t_course_section分库策略
spring.shardingsphere.rules.sharding.tables.t_order_item.database-strategy.standard.sharding-column=user_Id
spring.shardingsphere.rules.sharding.tables.t_order_item.database-strategy.standard.sharding-algorithm-name=table-mod- 分表策略
properties
#================水平分库-分表策略
## t_order 分表策略
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-column=order_Id
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name=table-hash-mod
## t_order_item 分表策略
spring.shardingsphere.rules.sharding.tables.t_order_item.table-strategy.standard.sharding-column=order_Id
spring.shardingsphere.rules.sharding.tables.t_order_item.table-strategy.standard.sharding-algorithm-name=table-hash-mod- 分片算法
properties
#3.=========分片算法========
spring.shardingsphere.rules.sharding.sharding-algorithms.table-mod.type=MOD
spring.shardingsphere.rules.sharding.sharding-algorithms.table-mod.props.sharding-count=2
spring.shardingsphere.rules.sharding.sharding-algorithms.table-hash-mod.type=HASH_MOD
spring.shardingsphere.rules.sharding.sharding-algorithms.table-hash-mod.props.sharding-count=2完整配置文件
properties
# 应用名称
spring.application.name=shardingsphere-jdbc-table
# 打印SQl
spring.shardingsphere.props.sql-show=true
# 定义多个数据源
spring.shardingsphere.datasource.names = db0,db1
#数据源1
spring.shardingsphere.datasource.db0.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db0.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db0.url = jdbc:mysql://192.168.116.128:3306/shardingjdbc0?characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.db0.username = root
spring.shardingsphere.datasource.db0.password = 123456
#数据源2
spring.shardingsphere.datasource.db1.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db1.url = jdbc:mysql://192.168.116.129:3306/shardingjdbc1?characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.db1.username = root
spring.shardingsphere.datasource.db1.password = 123456
#1.配置数据节点
#指定course表的分布情况(配置表在哪个数据库,表名是什么)
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=db$->{0..1}.t_order_$->{0..1}
spring.shardingsphere.rules.sharding.tables.t_order_item.actual-data-nodes=db$->{0..1}.t_order_item_$->{0..1}
#2.=========水平分库-分库策略========
## t_order 分库策略
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-column=user_Id
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=table-mod
# ----t_course_section分库策略
spring.shardingsphere.rules.sharding.tables.t_order_item.database-strategy.standard.sharding-column=user_Id
spring.shardingsphere.rules.sharding.tables.t_order_item.database-strategy.standard.sharding-algorithm-name=table-mod
#================水平分库-分表策略
## t_order 分表策略
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-column=order_Id
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name=table-hash-mod
## t_order_item 分表策略
spring.shardingsphere.rules.sharding.tables.t_order_item.table-strategy.standard.sharding-column=order_Id
spring.shardingsphere.rules.sharding.tables.t_order_item.table-strategy.standard.sharding-algorithm-name=table-hash-mod
#3.=========分片算法========
spring.shardingsphere.rules.sharding.sharding-algorithms.table-mod.type=MOD
spring.shardingsphere.rules.sharding.sharding-algorithms.table-mod.props.sharding-count=2
spring.shardingsphere.rules.sharding.sharding-algorithms.table-hash-mod.type=HASH_MOD
spring.shardingsphere.rules.sharding.sharding-algorithms.table-hash-mod.props.sharding-count=2
#3.分布式序列配置
#3.1 分布式序列-列名称
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.column=cid
#3.2 分布式序列-算法名称
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.key-generator-name=alg_snowflake
#3.分布式序列配置
#3.1 分布式序列-列名称
spring.shardingsphere.rules.sharding.tables.t_order_item.key-generate-strategy.column=item_id
#3.2 分布式序列-算法名称
spring.shardingsphere.rules.sharding.tables.t_order_item.key-generate-strategy.key-generator-name=alg_snowflake_item
#3.3 分布式序列-算法类型
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=SNOWFLAKE
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
spring.shardingsphere.rules.sharding.binding-tables[0]=t_order,t_order_item1.6.5 测试插入数据
java
@Test
public void createOrderAndItems() {
for (int j = 0; j < 10; j++) {
// 1. 创建订单主表记录
TOrder order = new TOrder();
order.setUserId(1+j);
order.setProductName("iPhone 15 Pro");
order.setTotalPrice(new BigDecimal("8999.00"));
order.setStatus("CREATED");
order.setCreateTime(LocalDateTime.now());
// 插入主表
orderMapper.insert(order);
System.out.println("主单已插入: " + order);
// 2. 创建订单项(多个商品)
for (int i = 1; i <= 2; i++) {
TOrderItem item = new TOrderItem();
item.setOrderId(order.getOrderId());
item.setProductName("配件" + i);
item.setPrice(new BigDecimal("99.00"));
item.setQuantity(1);
item.setUserId(order.getUserId());
item.setTotalPrice(new BigDecimal("99.00"));
item.setCreateTime(LocalDateTime.now());
orderItemMapper.insert(item);
System.out.println("订单项已插入: " + item);
}
}
}1.6.6 配置绑定表
需求说明: 查询每个订单的订单号和订单名称和购买数量
- 根据需求编写SQL
sql
SELECT t_order.order_Id,t_order.product_name,t_order_item.quantity FROM t_order INNER join t_order_item on t_order.order_Id = t_order_item.order_Id- 创建DTO类
java
@Data
public class TOrderDTO {
@TableId
private Long orderId;
private String productName;
private Integer quantity;
}- 添加Mapper方法
java
@Mapper
public interface TOrderMapper extends BaseMapper<TOrder> {
@Select("SELECT t_order.order_Id,t_order.product_name,t_order_item.quantity FROM t_order INNER join t_order_item on t_order.order_Id = t_order_item.order_Id ")
List<TOrderDTO> findItemNamesByOrderId();
}- 进行关联查询
java
@Test
public void findItemNamesByOrderId(){
List<TOrderDTO> tOrderDTOS = orderMapper.findItemNamesByOrderId();
tOrderDTOS.forEach(System.out::println);
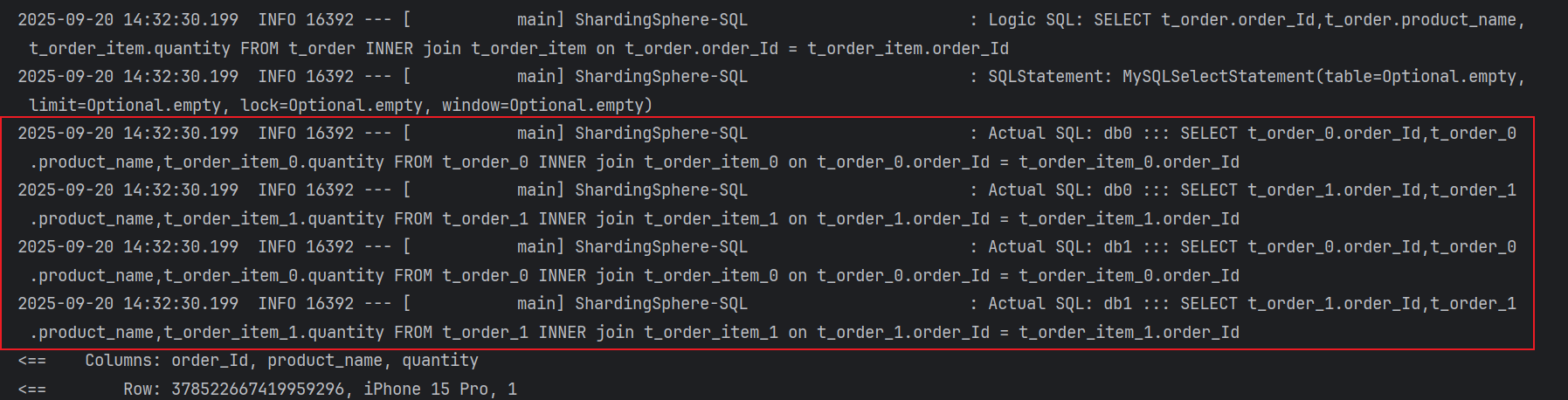
}- 如果不配置绑定表:测试的结果为8个SQL。多表关联查询会出现笛卡尔积关联。
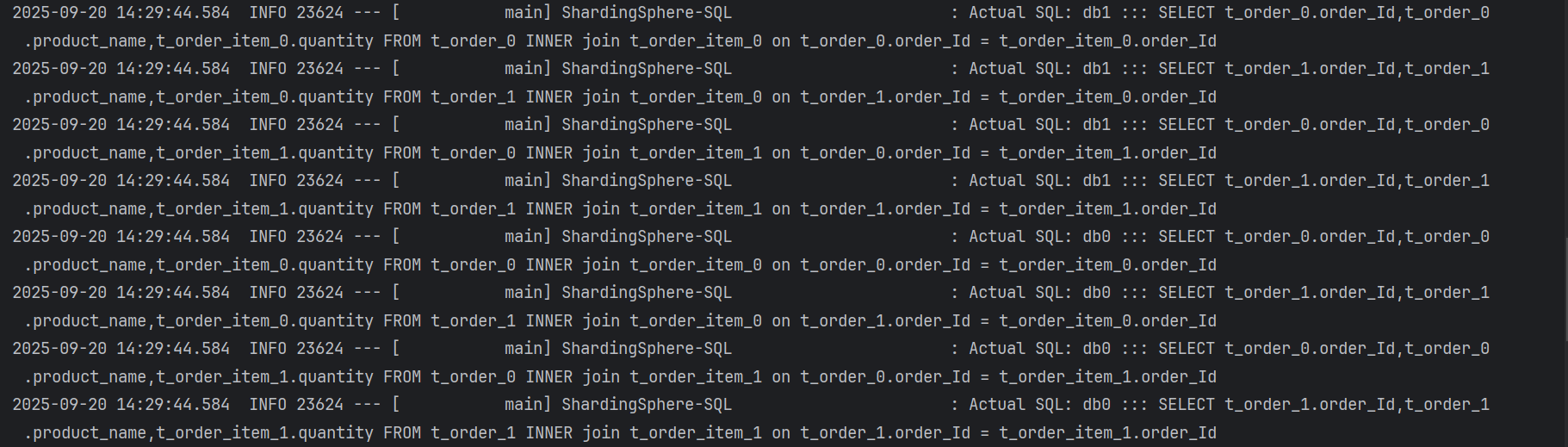
- 配置绑定表
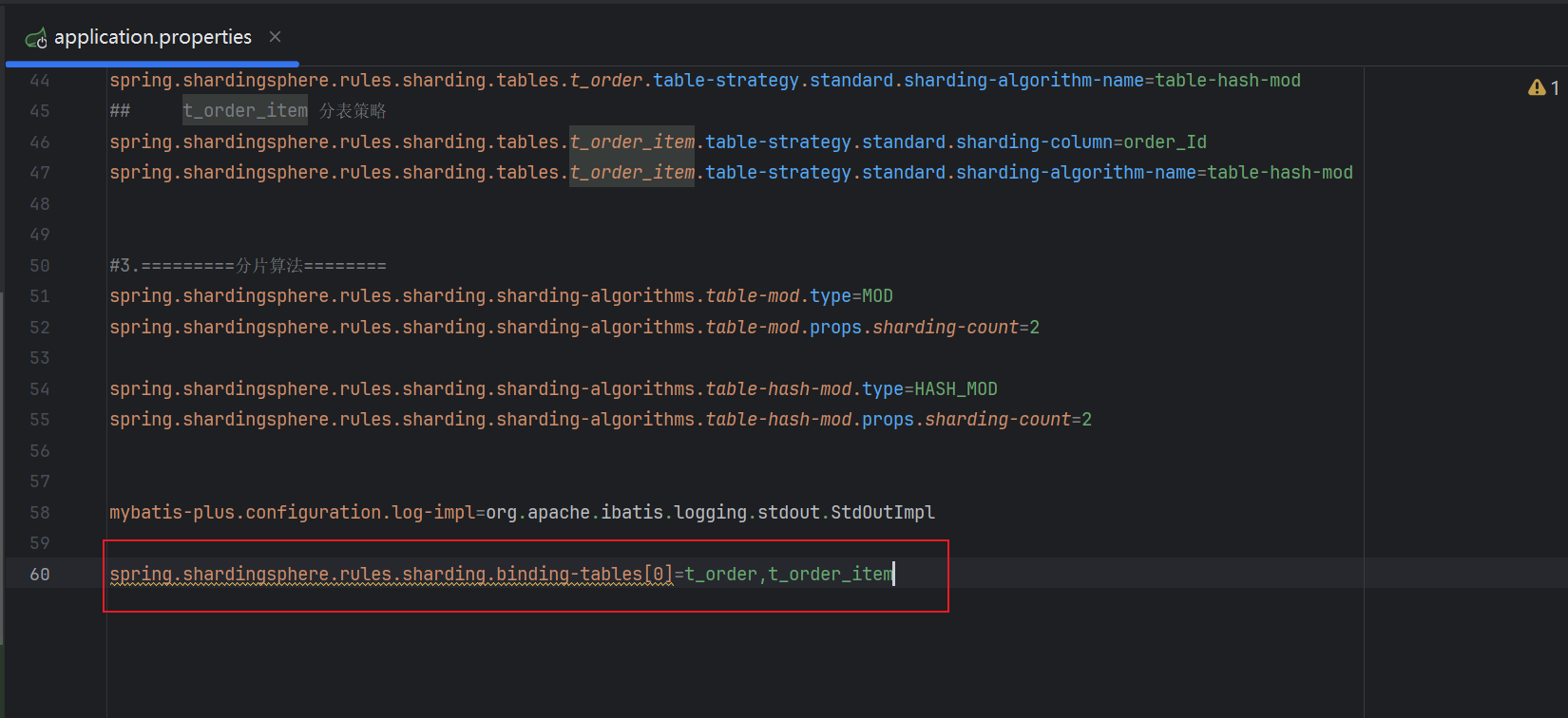
properties
#======================绑定表
spring.shardingsphere.rules.sharding.binding-tables[0]=t_course,t_course_section- 如果配置绑定表:测试的结果为4个SQL。 多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。
1.6.7 总结
以 order 表和 order_item 表为例,它们在每个数据库中都存在多个分片表。如果两者的分片策略完全一致(即使用相同的分片键和分片算法),必须将它们配置为绑定表(Binding Tables)。否则,在执行多表 JOIN 查询时,ShardingSphere-JDBC 无法确定哪些具体的分片表之间存在对应关系,只能对所有分片组合进行笛卡尔积式的关联,导致查询性能急剧下降,甚至引发不必要的全节点扫描。
1.7 实现广播表(公共表)
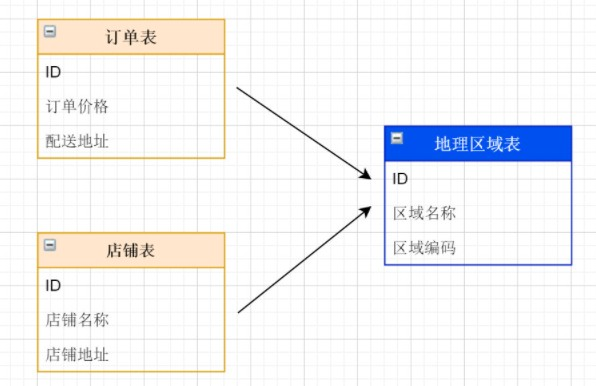
1.7.1 公共表介绍
公共表属于系统中数据量较小,变动少,而且属于高频联合查询的依赖表。参数表、数据字典表等属于此类型。
可以将这类表在每个数据库都保存一份,所有更新操作都同时发送到所有分库执行。接下来看一下如何使用Sharding-JDBC实现公共表的数据维护。
1.7.2 代码编写
1) 创建表
分别在 msb_course_db0 , msb_course_db1 ,msb_user_db 都创建 t_district表
sql
-- 区域表
CREATE TABLE t_district (
id BIGINT(20) PRIMARY KEY COMMENT '区域ID',
district_name VARCHAR(100) COMMENT '区域名称',
LEVEL INT COMMENT '等级'
);2) 创建实体类
java
@TableName("t_district")
@Data
public class District {
@TableId(type = IdType.ASSIGN_ID)
private Long id;
private String districtName;
private int level;
}3) 创建mapper
java
@Mapper
public interface DistrictMapper extends BaseMapper<District> {
}1.7.3 广播表配置
- 数据源
properties
# 应用名称
spring.application.name=shardingsphere-jdbc-table
# 打印SQl
spring.shardingsphere.props.sql-show=true
# 定义多个数据源
spring.shardingsphere.datasource.names = db0,db1
#数据源1
spring.shardingsphere.datasource.db0.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db0.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db0.url = jdbc:mysql://192.168.116.128:3306/shardingjdbc0?characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.db0.username = root
spring.shardingsphere.datasource.db0.password = 123456
#数据源2
spring.shardingsphere.datasource.db1.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db1.url = jdbc:mysql://192.168.116.129:3306/shardingjdbc1?characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.db1.username = root
spring.shardingsphere.datasource.db1.password = 123456
#数据节点可不配置,默认情况下,向所有数据源广播
spring.shardingsphere.rules.sharding.tables.t_district.actual-data-nodes=db$->{0..1}.t_district
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl- 广播表配置
properties
#------------------------广播表配置
# 广播表规则列表
spring.shardingsphere.rules.sharding.broadcast-tables[0]=t_district1.7.4 测试广播表
java
//广播表: 插入数据 两个数据源中都会插入
@Test
public void testBroadcast(){
District district = new District();
district.setDistrictName("昌平区");
district.setLevel(1);
districtMapper.insert(district);
}
//查询操作,只从一个节点获取数据, 随机负载均衡规则
@Test
public void testSelectBroadcast(){
List<District> districtList = districtMapper.selectList(null);
districtList.forEach(System.out::println);
}1.7.5 总结
由于 ShardingSphere-JDBC 不支持跨数据库实例(即跨数据源)的 JOIN 操作 ,所有关联查询必须在同一个数据库节点内完成。当 SQL 中涉及分片表与非分片表(如字典表)的 JOIN 时,若该非分片表未被配置为 广播表(Broadcast Table) ,ShardingSphere 将无法确定其所在的数据节点,导致路由失败并抛出异常。因此,此类公共表必须显式配置为广播表,使其在每个数据库实例中都存在完整副本,从而确保 JOIN 查询能在单个节点内正确执行。