前面我们演示的都是通过现成的客户端,来进行AI行为,如聊天、生图等。如果现在要我们自己写一个AI应用来实现相关AI行为,则需要我们自行接入LLM。
常见的原生 LLM 接入方式有三种:【API远程调用】、【开源模型本地部署】和【SDK和官方客户端库】。
一、API接入
这是目前最主流、最便捷的接入方式,尤其适用于快速开发、集成到现有应用以及不想管理硬件资源的场景。
通过 HTTP 请求(通常是RESTful API)直接调用模型提供商部署在云端的模型服务。
典型流程就是:
**1.注册账号并获取API Key:**再模型提供商的平台上注册,获取用于身份验证的密钥。
**2.查阅API文档:**了解请求的端点、参数(如模型名称、提示词、温度、最大生成长度等)和返回的数据格式。
**3.构建 HTTP 请求:**在你的代码中,使用HTTP客户端库(如Python的requests)构建一个包含API Key (通常在Header中)和请求体(Json格式,包含你的提示和参数)的请求。
**4.发送请求并处理响应:**将请求发送到提供商指定的API地址,然后解析返回的Json数据,提取生成的文本。
以OpenAI为例,官⽹地址:https://platform.openai.com/(魔法上网)
接入流程参考:https://platform.openai.com/docs/quickstart
API参考:https://platform.openai.com/docs/api-reference/introduction
二、本地接入
大模型本地部署,这种方式就是将开源的大型语言模型(如Llama,CharGLM,Qwen 等)部署在你自己的硬件环境(本地服务器或私有云等)中,核心概念就是,将下载模型的文件(权重和配置文件),使用专门的推理框架在本地服务器或GPU上加载并运行模型,然后通过类似API的方式进行交互。
典型流程就是:
**1. 获取模型:**从Hugging Face(国外)、魔塔社区(国内)等平台下载开源模型的权重。
**2. 准备环境:**配置具有足够显存(如NVIDIV GPU)的服务器,安装必要的驱动和推理框架。
**3. 选择推理框架:**选择专为生产环境设计的框架来部署模型,例如:
vLLM:特别注重高吞吐量的推理服务,性能极佳。
TGI:Hugging Face 推出的推理框架,功能全面。
Ollama:非常用户友好,可以一键拉取和运行模型,适合快速入门和本地开发。
LM Studio:提供图形化界面,让本地运行模型像使用软件一样简单。
**4. 启动服务并调用:**框架会启动一个本地 API 服务器(如 http://localhost:8000),你可以像调用云端 API 一样向这个本地地址发送请求。
以 Ollama 为例,下面我们来演示下具体过程。
2.1 下载并安装Ollama
Ollama 是一款专为本地部署和运行大型语言模型(LLM)设计的开源工具,旨在简化大型语言模型(LLM)的安装、运行和管理。它支持多种开源模型(如Qwen、deepseek、LLaMA),并提供简单的 API 接口,方便开发者调用,适合开发者和企业快速搭建私有化 AI 服务。
Ollama官网:https://ollama.ai

下载之后一步步安装即可。
安装之后,Ollama 默认会启动。访问 http://127.0.0.1:11434
或者使用 cmd 访问 ollama --version

Ollama 可以管理和部署模型,我们使用之前,需要先拉取模型
2.2 修改模型存储路径
模型默认安装在C盘个人目录下 C:\Users\xxx\.ollama, 可以修改 ollama 的模型存储路径,使得每次下载的模型都在指定的目录下。有这两种方式:
-
配置系统环境变量
变量名: OLLAMA_MODELS
变量值: ${⾃定义路径} -
通过 Ollama 界面来进行设置
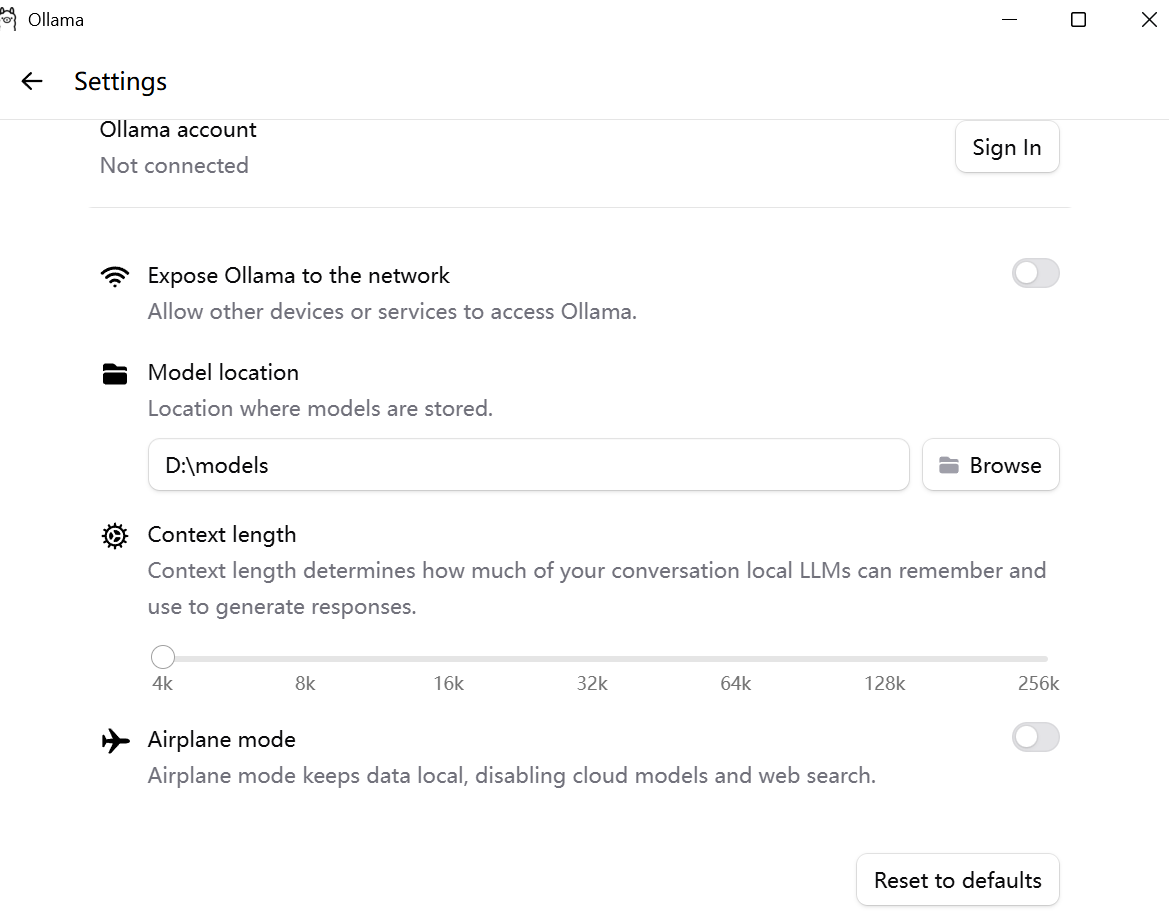
设置完成后重启Ollama。
2.3 拉取模型
查找模型:https://ollama.com/search
以 DeepSeek-R1为例,DeepSeek-R1 是一系列开放推理模型,其性能接近 O3 和 Gemini 2.5 Pro等领先模型。DeepSeek-R1 有不同的版本,我们需要根据自己机器的配置以及需求来选择相应的版本。
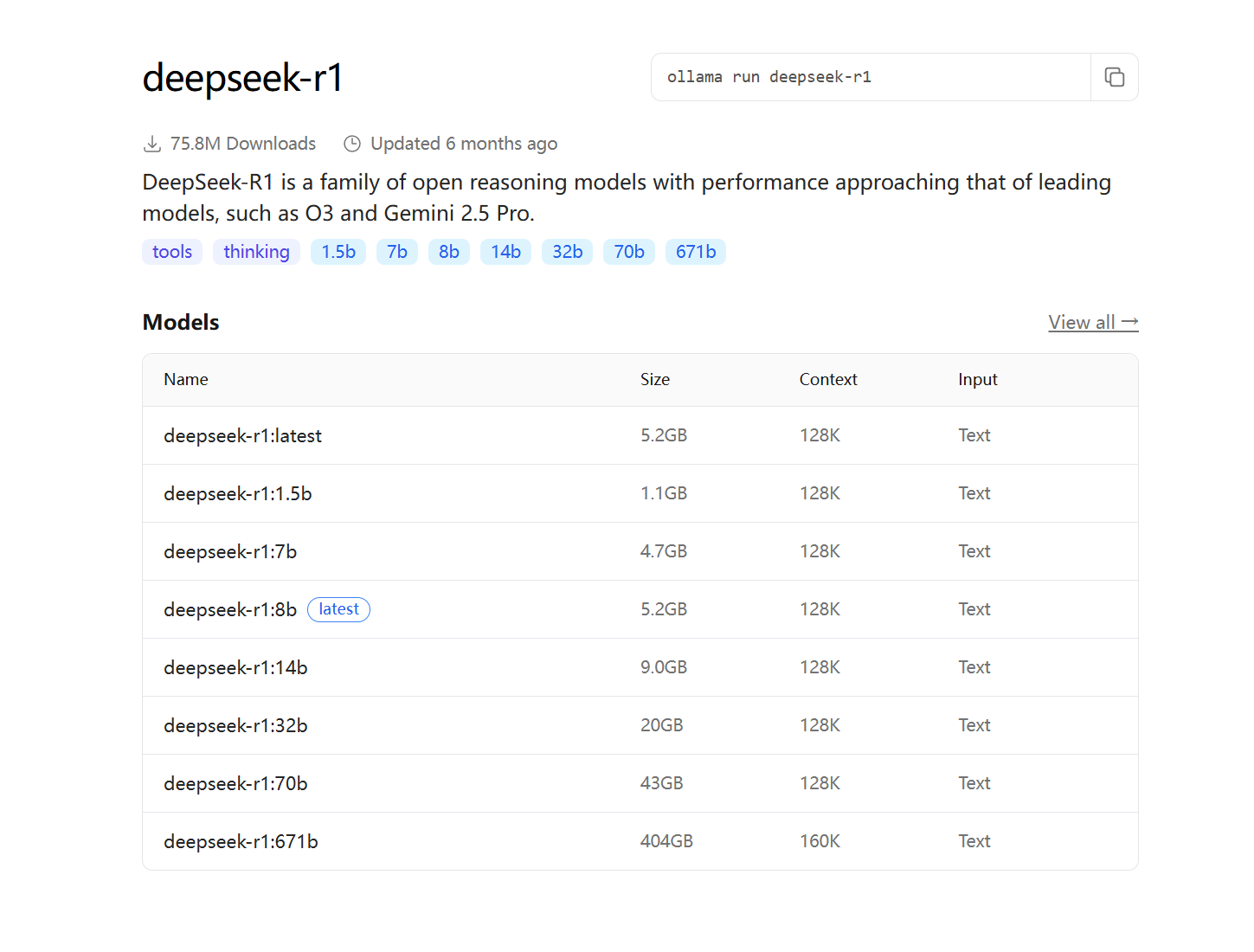
分为 1.5b, 7b,8b 等,"b" 是"Billion"(十亿)的缩写,代表模型的 参数量级。671b 表示"满血"版本,其他版本称为 "蒸馏" 版本。
参数越多 -> 模型"知识量越大" -> 处理复杂任务的能力越强,硬件需求也越高。
根据需求及电脑配置,选择合适的模型版本,以 1.5b 为例:
ollama run deepseek-r1:1.5b
第一次使用需要下载,下载完成之后就可以通过命令行进行 AI 对话。
三、SDK接入
这并非一种独立的接入方式,而是对第一种 API 接入的封装和简化。模型提供商通常会发布官方编程语言 SDK,为我们封装好了底层的 HTTP 请求细节,提供一个更符合编程习惯的、语言特定的函数库。
典型流程(以 OpenAI Python SDK 为例):
安装库:
pip install openai安装 OpenAI SDK 后,可以创建一个名为 example.py 的文件并将示例代码复制到其中:
python
from openai import OpenAI
client = OpenAI(api_key="your-api-key")
response = client.responses.create(
model="gpt-5",
input="介绍⼀下你⾃⼰。"
)
print(response.output_text)相比直接构造 HTTP 请求,代码更简洁、更易读、更易维护。