集成学习
不是只用一个模型,而是训练多个模型,然后把它们的结果"集成"起来,得到一个更强的模型。
分类
同质(homogeneous,Bagging+Boosting)、异质(heterogeneous,Stacking+Voting)
-
Bagging(Bootstrap Aggregating,并联策略):
-
思想:通过对训练数据进行多次有放回的采样,生成多个训练子集,每个子集用于训练一个独立的模型,然后对这些模型的预测结果进行投票(分类任务)或平均(回归任务)。
-
代表方法:随机森林(Random Forest)、Bagging算法。
-
-
Boosting(串联策略):
-
思想:通过训练一系列模型,每个模型都对前一个模型错误分类的样本给予更多的权重。最终的预测结果是多个模型预测结果的加权平均。
-
代表方法:AdaBoost(Adaptive Boosting)、Gradient Boosting、XGBoost、LightGBM。
-
-
Stacking(Stacked Generalization,混联策略):
-
思想:将多个模型的输出作为新的特征输入到一个新模型(通常是线性模型或其他模型),通过新模型学习如何将这些基础模型的预测结果进行组合(二次学习的过程)。
-
代表方法:Stacking算法。
-
-
Voting(并联):
-
思想:将多个独立的分类器(或回归器,KNN、SVM、决策树等)的预测结果进行合成,通常是通过多数投票(分类任务)或平均(回归任务)来决定最终预测结果。
-
代表方法:投票
-
代码实现(Voting)
数据准备
python
import numpy as np
import matplotlib.pyplot as plt
# make_moons 可以生成一个二维数据集,数据分布呈月亮形状(两个半月形状的数据点)
from sklearn.datasets import make_moons
## 构造半圆形数据集
x,y = make_moons(
n_samples=1000,
noise=0.4,
random_state=20
)
plt.scatter(x[:,0],x[:,1],c=y,s=10)
plt.show()
sklearn实现集成学习
python
from sklearn.ensemble import VotingClassifier
clf = [
KNeighborsClassifier(n_neighbors=3),
LogisticRegression(),
GaussianNB()
]
# 硬投票:每个分类器都会给出一个预测类标签,最终的预测标签是由所有分类器的投票结果决定的,那个类别多选哪个
# 假设有三个分类器(clf1、clf2、clf3),对于一个样本,它们的预测结果如下:
# clf1:预测为类 0
# clf2:预测为类 1
# clf3:预测为类 1
# 那么在硬投票中,类 1 得到了 2 票,类 0 得到 1 票。因此,最终的预测结果是类 1。
vclf = VotingClassifier(
estimators=[
('knn',clf[0]),
('lr',clf[1]),
('gnb',clf[2])
],
voting='hard', # 硬投票
n_jobs=-1 # 设置并行执行
)
vclf.fit(x_train,y_train)
vclf.score(x_test,y_test)
# 软投票:每个分类器会给出每个类别的预测概率,然后根据这些概率来决定最终的预测结果
# 假设有三个分类器(clf1、clf2、clf3),并且它们分别输出以下概率(假设是二分类问题):
# clf1:类 0 的概率为 0.3,类 1 的概率为 0.7
# clf2:类 0 的概率为 0.6,类 1 的概率为 0.4
# clf3:类 0 的概率为 0.4,类 1 的概率为 0.6
# 那么,最终的预测是对每个类别的概率进行加权平均:
# 类 0 的平均概率:(0.3 + 0.6 + 0.4) / 3 = 0.43
# 类 1 的平均概率:(0.7 + 0.4 + 0.6) / 3 = 0.57
# 最终预测结果为 类 1,因为类 1 的平均概率最高。
vclf = VotingClassifier(
estimators=[
('knn',clf[0]),
('lr',clf[1]),
('gnb',clf[2])
],
voting='soft', # 软投票
n_jobs=-1 # 设置并行执行
)
vclf.fit(x_train,y_train)
vclf.score(x_test,y_test)Bagging、OOB
- 使用同一种模型
- 随机抽取训练集进行训练
数据抽取策略:
- 有放回Bagging(转盘抽奖,相互独立)
- 无放回Pasting(抽奖箱抽奖,不相互独立)
python
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bagging = BaggingClassifier(
estimator=DecisionTreeClassifier(), #使用的模型
n_estimators=100, # 使用模型的数量
bootstrap=True, # True有放回取样,False无放回取样
max_samples=500, # 每个模型取样的数量,训练时使用的样本数量
n_jobs=-1,
random_state=20
)
bagging.fit(x_train,y_train)
bagging.score(x_test,y_test)OOB(out-of-bag)
前提:有放回抽样
从 N个样本中抽 N次,某个样本 一次都没被抽到 的概率:
当N很大的时候:
核心思想:
- 36.8%的样本没有被抽到
- 不区分训练集和测试集
- 用没有被抽到的数据作为测试集
python
# OOB策略不用再区分训练集和测试集,传入全集
# 注意:bootstrap要设置为True
oob = BaggingClassifier(
estimator=DecisionTreeClassifier(), #使用的模型
n_estimators=100, # 使用模型的数量
bootstrap=True, # True有放回取样,False无放回取样
max_samples=500, # 每个模型取样的数量,训练时使用的样本数量
oob_score=True, # 使用oob策略
n_jobs=-1,
random_state=20
)
oob.fit(x,y)
oob.oob_score_特征的随机取样(参数:bootstrap_features)
python
bagging = BaggingClassifier(
estimator=DecisionTreeClassifier(), #使用的模型
n_estimators=100, # 使用模型的数量
bootstrap=True, # 对"样本"做随机取样,True有放回取样,False无放回取样
max_samples=500, # 每个模型取样的数量,训练时使用的样本数量
oob_score=True,
bootstrap_features=True, # 对"特征"做随机抽样
max_features=1, # 模型训练时使用的特征数量,此时每次只用 1 个特征
n_jobs=-1,
random_state=20
)
bagging.fit(x,y)
bagging.oob_score_随机森林
- Bagging + 基学习器(Base Estimator - > Decision Tree 决策树)
- 构建决策树时,提供了更多的随机性(随机特征子集划分)
python
## 拥有决策树的一些参数可以设置max_leaf_nodes,max_depth....
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier(
n_estimators=100, # 决策树的数量
oob_score=True,
max_leaf_nodes=16,
max_samples=500,
n_jobs=-1,
random_state=20
)
rf_clf.fit(x,y)
rf_clf.oob_score_提取特征的重要性
python
# 返回每个特征对模型预测贡献的相对重要性权重
# 分析:第 1 个特征:≈ 45.66%第 2 个特征:≈ 54.34%
# 结果:第二个特征更重要
rf_clf.feature_importances_鸢尾花数据集 ---> 随机森林
python
## 鸢尾花数据集
from sklearn import datasets
iris = datasets.load_iris()
x = iris.data
y = iris.target
rf_clf = RandomForestClassifier(
n_estimators=100, # 决策树的数量
oob_score=True,
max_leaf_nodes=16,
n_jobs=-1,
random_state=20
)
rf_clf.fit(x,y)
# 结果:[0.09674332, 0.02771735, 0.43857879, 0.43696054]
# 分析:第三个特征权重最大,最重要
rf_clf.feature_importances_
labels = np.array(iris.feature_names) # 取出特征的名称
importances = rf_clf.feature_importances_ # 每个特征的重要性
indices = np.argsort(importances)[::-1] # 对特征进行排序(降序),取出特征索引
# x.shape -> (样本数,特征数) x.shape[1]:x 的特征数(列数)
plt.bar(range(x.shape[1]),importances[indices],color='lightblue',align='center')
# 设置 x 轴刻度和特征名 rotation=70:特征名太长,旋转 70°,防止重叠
plt.xticks(range(x.shape[1]),labels[indices],rotation=70)
# 设置 x 轴范围
plt.xlim([-1,x.shape[1]])
plt.tight_layout()
plt.show()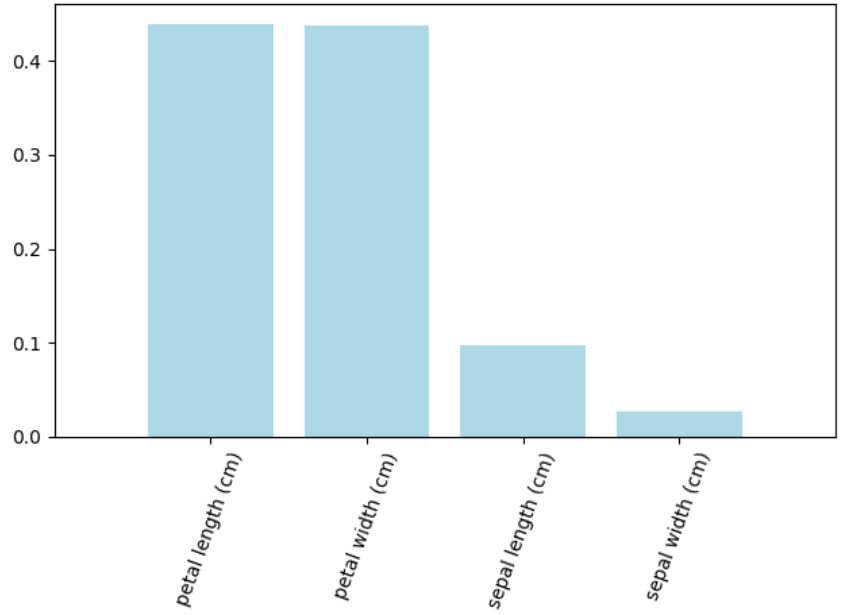
Extra-Trees
- 随机森林的一个扩展变体
- 使用随机的特征和随机的阈值进行节点划分
- 进一步提高模型随机性
- 训练速度更快
python
from sklearn.ensemble import ExtraTreesClassifier
et_clf = ExtraTreesClassifier(
n_estimators=100,
max_samples=500,
bootstrap=True,
oob_score=True,
n_jobs=-1,
random_state=20
)
et_clf.fit(x,y)
et_clf.oob_score_Boosting
AdaBoost
不断关注"分错的样本",让后面的模型重点学习这些难样本,最后把多个弱分类器加权组合成一个强分类器。
python
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
ada_clf = AdaBoostClassifier(
estimator=DecisionTreeClassifier(max_leaf_nodes=16),
n_estimators=100
)
ada_clf.fit(x_train,y_train)
ada_clf.score(x_test,y_test)Gradient Boosting
残差
残差= 真实值 − 模型预测值
含义:模型在某一个样本上的"预测偏差"
目标:提高训练准确度,最小化残差
步骤:
- 初始学习器预测结果
,产生残差
- 针对
- 针对
- 迭代
- 最终模型结果
python
## 已经指定基学习器-->决策树,所以不需要设置estimator
from sklearn.ensemble import GradientBoostingClassifier
gb_clf = GradientBoostingClassifier(n_estimators=100)
gb_clf.fit(x_train,y_train)
gb_clf.score(x_test,y_test)Stacking
Stacking 是一种两层(或多层)集成学习方法:
用多个不同模型的预测结果作为新特征,再训练一个"元模型"进行最终预测。
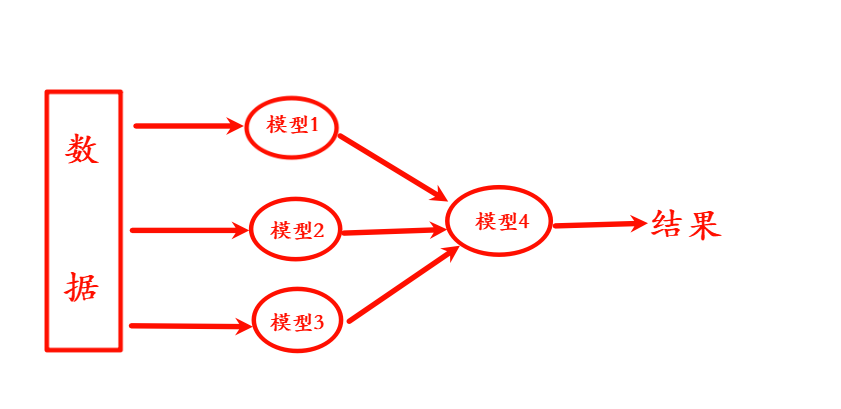
集成学习的优缺点和适用条件
|--------------|--------------------------------|-------------------------------------|
| 方法 | 优点 | 缺点 |
| Voting | 少数服从多数,简单高效 降低方差,提高鲁棒性 | 软投票法与硬投票结果可能不一致 所有子模型对预测的贡献均等 |
| Bagging | 减少方差 降低模型预测误差 | 增加时间开销 需要模型具备多样性 并行训练需要较大计算资源 |
| 随机森林 | 准确率高 不容易过拟合,抗噪能力强 高维数据 | 噪音较大时容易过拟合 取值划分较多的属性影响大 黑盒模型,可解释性低 |
| Boosting | 更加巧妙鲁棒 减少偏差 | 容易过拟合 |
| Ababoost | 二分类或多分类场景 灵活,简单,不易过拟合 精度高,无需调参 | 弱分类器数目不太好设定 数据不平衡分类精度下降 训练比较耗时,易受干扰 |
| Stacking | 效果好,鲁棒性高 有可能将集成的知识迁移 有效对抗过拟合 | 二次学习更加复杂 注意leak情况,产生过拟合 |