JVM学习
文章目录
##字节码
- 一些有趣的问题
- 反射能否获取到方法的参数名称:https://fangshixiang.blog.csdn.net/article/details/99112603
- 原理:编译后的字节码方法表包含方法参数名称
- 获取:1.jdk1.8通过javac -parameters XXX.java 2.借助ASM操作JVM的汇编指令级别获取
- 反射能否获取到方法的参数名称:https://fangshixiang.blog.csdn.net/article/details/99112603
类加载器
- 参考:https://blog.csdn.net/yangcheng33/article/details/52464898
- 自己写个Object加载会报错:SecurityException,因为这个禁止使用的包名java.lang
###加载
- ClassLoader:有个parent字段,类加载是通过双亲委派,先通过父加载器进行加载,1.保证安全性 2.类隔离
- 自定义类加载器的实现-可以实现加载网络的class文件
- 不破坏双亲委派直接实现findClass方法
- 想破坏双亲委派实现loadClass方法
- URLClassLoader
- URLClassLoader 是AppClassLoader和ExtClassLoader的父类,是SecureClassLoader的子类
- 而URLClassLoader可以加载任意路径下的类,支持从file、网络、jar加载资源,根据url来进行选择loader
java
//URLClassPath.getLoader
private Loader getLoader(final URL url)
{
String s = url.getFile();
// 以"/"结尾时,若url协议为"file"则使用FileLoader加载本地文件
// 否则使用默认的Loader加载网络url
if(s != null && s.endsWith("/"))
{
if("file".equals(url.getProtocol()))
return new FileLoader(url);
else
return new Loader(url);
} else {
// 非"/"结尾则使用JarLoader
return new JarLoader(url, jarHandler, lmap);
}
}-
上下文类加载器TCCL->ThreadContextClassLoader(注意:不是类名)
- 破坏了双亲委派模式,指定TCCL加载,参考
java//入口 DriverManager.getConnection() public static <S> ServiceLoader<S> load(Class<S> service) { ClassLoader cl = Thread.currentThread().getContextClassLoader(); return ServiceLoader.load(service, cl); }- TCCL在哪赋值呢?--》答案看下面的系统类加载器
-
系统类加载器-》java.lang.ClassLoader#getSystemClassLoader
java
public static ClassLoader getSystemClassLoader() {
//源码可以发现其实质上是通过sun.misc.Launcher实例获取返回其成员变量loader的。那这个loader是何时赋值的呢?我们来看下它的构造函数
initSystemClassLoader();
if (scl == null) {
return null;
}
SecurityManager sm = System.getSecurityManager();
if (sm != null) {
checkClassLoaderPermission(scl, Reflection.getCallerClass());
}
return scl;
}
public Launcher()
{
ExtClassLoader extclassloader;
try
{
// 创建并初始化扩展类加载器ExtClassLoader
extclassloader = ExtClassLoader.getExtClassLoader();
}
catch(IOException ioexception)
{
throw new InternalError("Could not create extension class loader");
}
try
{
// 创建并初始化系统类加载器AppClassLoader,设置其父类加载器为ext,最后传给loader
loader = AppClassLoader.getAppClassLoader(extclassloader);
}
catch(IOException ioexception1)
{
throw new InternalError("Could not create application class loader");
}
// 默认将线程上下文类加载器设置为AppClassLoader
Thread.currentThread().setContextClassLoader(loader);
}链接
- 验证-验证字节码的合法性
- 准备-为类变量赋初始值,在初始化的时候才赋真正的值
- 解析-把类、接口、方法、字段的符号引用替换为直接引用
初始化
- 用于初始化类的变量,所有的类变量和静态代码库会放到cinit方法中,在首次主动使用该类时会调用cinit方法
- 首次主动主动使用的6种情况
- new、调用静态方法、操作非常量的静态字段、反射调用、子类、作为jvm的启动类
- 被动使用
- 子类或子接口引用父类的字段,属于被动引用,子类不会初始化但会触发父类初始化
- 静态的常量字段
Java对象布局
对象布局
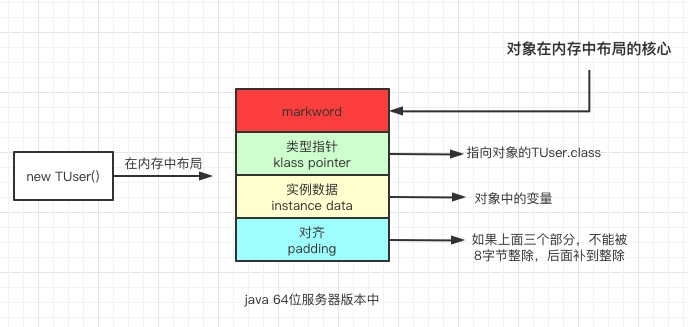
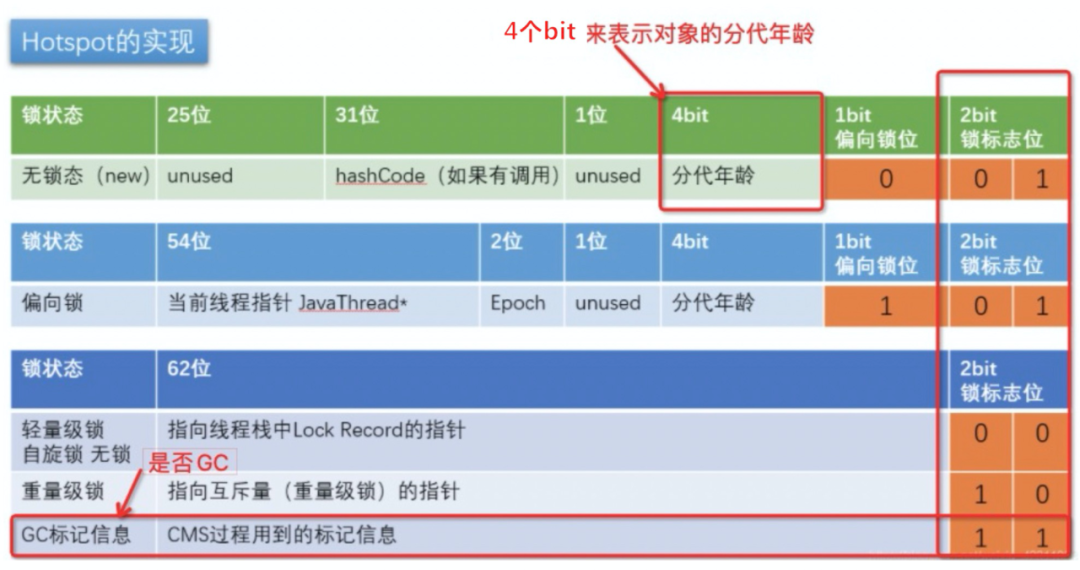
- 对象头:MarkWord(8B)+Klass pointer(4)+Array length(数组对象才有)
- 根据锁的标记+偏向锁标记决定具体的布局格式
- 用了4个bit去表示分代年龄,那么能表示的最大范围就是0-15。所以这也就是为什么设置新生代的年龄不能超过15
- 根据锁的标记+偏向锁标记决定具体的布局格式
- 实例数据:
- 对齐数据:按照8的倍数对齐,为了让字段都在CPU的同一个缓存行中,提升计算机的寻址
锁原理Synchonized
- 锁:对象的资源被多个线程访问时提供原子性保障,实现是在对象头MarkWord中记录锁的标志位
- 通过两个jvm的指令monitorenter和monitorexit实现,如果异常会自动的释放
锁升级过程
-
为什么需要锁升级
- 因为直接向操作系统内核申请锁的成本比较搞,而其实大部分情况一般只有一个线程去获取锁,jvm自身就可以处理不用交给操作系统去做,提升性能
-
无锁
-
偏向锁:
- 偏向的意义在于:第一个线程拿到锁,将自己的线程信息标记在锁上,下次进来就不需要在拿去拿锁验证了,如果超过1个线程去抢锁,那么偏向锁就会撤销,升级为轻量级锁
- 在jvm启动4秒后会自动开启偏向锁,单线程synchronized加锁不会升级为轻量锁
- 在jvm启动4秒内,单线程加锁会直接升级为轻量锁
- 关闭偏向锁: -XX:-UseBiasedLocking = false , jdk15之后默认已经禁用了偏向锁
-
轻量锁:线程采取CAS的自旋方式尝试获取锁
- 从一个线程抢占资源(偏向锁)到多线程抢占资源升级为轻量级锁
- 10次自旋或等待cpu调度的线程数超过cpu核数的一半,自动升级为重量级锁
-
重量锁:mark word中的指针指向的是monitor对象
- 每个对象有一个监视器锁(monitor)
- 多个线程并发获取锁,会升级为重量锁
- 通过两个jvm的指令monitorenter和monitorexit实现
jvm垃圾收集GC
参考资料
- 7 种 JVM 垃圾收集器:https://cloud.tencent.com/developer/article/1592943
并行和并发
- 并行(Parallel):指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
- 并发(Concurrent):指用户线程与垃圾收集线程同时执行(但不一定是并行的,可能会交替执行),用户程序在继续运行。而垃圾收集程序运行在另一个CPU上。
吞吐量(Throughput)
高吞吐量则可用高效率地利用CPU时间,尽快完成程序的运算任务,主要适合在后台运算而不需要太多交互的任务
吞吐量就是CPU用于运行用户代码的时间与CPU总消耗时间的比值,即
吞吐量 = 运行用户代码时间 /(运行用户代码时间 + 垃圾收集时间)。
假设虚拟机总共运行了100分钟,其中垃圾收集花掉1分钟,那吞吐量就是99%。
垃圾收集器

-
新生代收集器
- Serial收集器-XX:+UseSerialGC
- 简单而高效(与其他收集器的单线程相比), 适用于Client模式下的虚拟机
- 它是一个单线程收集器,必须暂停其他所有的工作线程,直至Serial收集器收集结束为止("Stop The World")
- ParNew 收集器-XX:+UseParNewGC 使用多个GC线程实现的复制收集,区别于"Parallel Scavenge"在于它与CMS可搭配使用
- Parallel Scavenge 收集器-XX:+UseParallelGC 使用多个GC线程实现复制收集
- Serial收集器-XX:+UseSerialGC
-
老年代收集器
-
Serial Old收集器:使用单个线程进行mark-sweep-compact(标志-清扫-压缩) 收集
-
Parallel Old收集器-XX:+UseParallelOldGC,是一种使用多个GC线程压缩收集。
-
CMS收集器-XX:+UseConcMarkSweepGC,被标记的对象是不可回收的
- CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器,基于"标记-清除"算法实现的,CMS收集器的内存回收过程是与用户线程一起并发执行的
-
CMS收集器工作的整个流程:GCRoot、记忆集(卡表:解决对象的跨代引用问题,扫描整个老年代)、STW、安全点(区)即对象引用关系不会发生变化、三色标记
- 初始标记(CMS initial mark):仅仅只是标记一下GC Roots能直接关联到的对象,速度很快,需要"Stop The World"。
- 并发标记(CMS concurrent mark):接着初始标记的根对象继续往下标记,这个阶段是最耗时的,所以是与用户线程并发执行的
- 重新标记(CMS remark):为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,通过增量更新解决漏标记。此阶段也需要"Stop The World"。
- 并发清除(CMS concurrent sweep)
- CMS收集器整个过程中耗时最长的并发标记和并发清除过程收集器线程都可以与用户线程一起工作
- CMS收集器缺点
- CMS并发清理阶段用户线程还在运行着,会产生浮动垃圾
- CMS是一款基于"标记-清除"算法实现的收集器,这意味着收集结束时会有大量空间碎片产生
- CMS面向并发设计的程序都对CPU资源比较敏感
-
G1收集器-XX:+UseG1GC,漏标:通过原始快照处理
- 把堆内存分成若干个Region(区域),每次收集的时候,只收集其中几个区域,以此来控制垃圾回收产生的STW。G1垃圾回收器和传统的垃圾回收器的最大区别就在于,弱化了分代概念,引入了分区的思想
- G1中每代的存储地址都不是连续的,而是使用了不连续的大小相同的Region。除此之外G1中还多了一个H,H代表Humongous,用于存储巨大对象(humongous object),当对象大小大于等于region一半的对象,就直接分配到了老年代,防止了反复拷贝移动
-
JVM分析工具
命令行
-
jmap
- dump出java内存对象
-
Jstatus
-
jstack
- jstack 1 | grep -A20 ' nid=0x13 '
-
jcmd:
- 用于查看NMT日志,分析堆外内存,重点观察 total 中的 committed
- jcmd pid VM.native_memory detail
- jcmd 1 VM.native_memory summary scale=MB
- jcmd 1 VM.native_memory detail scale=MB
-
Arthas:推荐
- https://arthas.aliyun.com/doc/quick-start.html
- thread -n 10分析线程堆栈
-
操作系统命令
- top -H -p 1:分析进程中的线程占用
- cat /proc/1/status VmRSS对应的值就是物理内存占用
- Pmap: pmap -x 1 | sort -n -k3 查看进程的内存分配情况
- cat /proc/1/smaps > smaps.log 可以找到内存块地址
- gdb
shellcat /proc/24173/smaps > smaps.log gdb attach 24173 dump memory /tmp/0xc1800000-0x100ee0000.dump 0xc1800000 0x100ee0000 strings -10 /tmp/0xc1800000-0x100ee0000.dump -
查看进程是否使用了 Swap交换内存
shell#!/bin/bash # Get current swap usage for all running processes # Erik Ljungstrom 27/05/2011 # Modified by Mikko Rantalainen 2012-08-09 # Pipe the output to "sort -nk3" to get sorted output # Modified by Marc Methot 2014-09-18 # removed the need for sudo SUM=0 OVERALL=0 for DIR in `find /proc/ -maxdepth 1 -type d -regex "^/proc/[0-9]+"` do PID=`echo $DIR | cut -d / -f 3` PROGNAME=`ps -p $PID -o comm --no-headers` for SWAP in `grep VmSwap $DIR/status 2>/dev/null | awk '{ print $2 }'` do let SUM=$SUM+$SWAP done if (( $SUM > 0 )); then echo "PID=$PID swapped $SUM KB ($PROGNAME)" fi let OVERALL=$OVERALL+$SUM SUM=0 done echo "Overall swap used: $OVERALL KB"
可视化
- Mat:
- 下载地址:https://www.eclipse.org/mat/downloads.php
- 安装教程:https://cloud.tencent.com/developer/article/1574123
- 实战:通过Leak Suspects观察可能内存泄漏和Top consumers观察占用的大对象
- 使用教程:
在线平台
- gceasy:用于分析GC日志
- https://gceasy.io/gc-index.jsp
- 观察对象创建速率、观察吞吐量和回收时间、观察GC原因
- fastthread:用于分析线程堆栈信息
*
JVM调优总结
调优参数配置
java -jar -Xss512k -Xms1000m -Xmx1000m -Xmn600m -XX:SurvivorRatio=5
//输出GC日志
-verbose:gc -XX:+PrintGCDateStamps -XX:+PrintGCDetails -Xloggc:/alidata1/admin/subao-proxy-saas/logs/gc.log -XX:-UseAdaptiveSizePolicy
//内存溢出输出堆栈信息
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/alidata1/admin/subao-proxy-saas/logs/heapdump.hprof
//NMT输出配置,可用于分析堆外内存
-XX:NativeMemoryTracking=detail
//配置元空间大小
-XX:MaxMetaspaceSize=150m -XX:CompressedClassSpaceSize=100m -XX:MetaspaceSize=150m
//观察类加载和卸载信息
-XX:+TraceClassLoading -XX:+TraceClassUnLoading
//配置堆外大小
-XX:MaxDirectMemorySize=200m
subao-proxy-saas.jar
//环境变量限制内存分配区 Arena
MALLOC_ARENA_MAX 2 或 ENV MALLOC_ARENA_MAX 2(docker配置)
调优经验
- 观察GC日志:
- -XX:+PrintGCDateStamps -XX:+PrintGCDetails -Xloggc:/alidata1/admin/subao-proxy-saas/logs/gc.log
- 观察GC原因gc cause
- System.gc(): 手动触发GC操作
- **Allocation Failure:**一般是没有足够的内存空间分配给新的对象了
- Promotion Failure: Old 区没有足够的空间分配给 Young 区晋升的对象(即使总可用内存足够大,因为可能内存块不连续)
- CMS: CMS GC 在执行过程中的一些动作,重点关注 CMS Initial Mark 和 CMS Final Remark 两个 STW 阶段
- **Concurrent Mode Failure并发模式失败:**一般由于并发 Background CMS GC 正在执行,同时又有 Young GC 晋升的对象要放入到了 Old 区中,而此时 Old 区空间不足造成的
- GCLocker Initiated GC: JNI 引发的 GC 问题
- 观察GC的回收比例
- old区回收比例大,可能是Young区对象过早的晋升到了old区,可以适当缩小old区增加young区
- old区回收比例小,可以适当增加old区大小,可能需要增加jvm堆大小
- 观察GC的频次
- 观察GC的STW时间
GC问题分析和解决方案
-
MetaSpace 区 OOM
- 现象
- MetaSpace 的已使用大小在持续增长,同时每次 GC 也无法释放,调大 MetaSpace 空间也无法彻底解决
- 原因
- 一般原因就是 ClassLoader 不停地在内存中 load 了新的 Class ,一般这种问题都发生在动态类加载等情况上
- 解决:
- 找到加载最多的class
- 现象
-
过早晋升到Old区
- 现象
- GC 日志中出现"Desired survivor size 107347968 bytes, new threshold 1(max 6)"等信息,说明此时经历过一次 GC 就会放到 Old 区
- Full GC 比较频繁 ,且经历过一次 GC 之后 Old 区的变化比例非常大
- 原因
- **Young/Eden 区过小:**查看jvm堆Young配置
- 分配速率过大: 可以观察出问题前后 Mutator 的分配速率,如果有明显波动可以尝试观察网卡流量、存储类中间件慢查询日志等信息,看是否有大量数据被加载到内存中
- 解决
- **Young/Eden 区过小:**缩小old区增加Young区,一般情况下 Old 的大小应当为活跃对象的 3 倍左右
- **分配速率过大:**优化代码逻辑或调整gc收集器
- 现象
-
堆外内存 OOM
-
参考
-
现象
- 内存使用率不断上升,甚至开始使用 SWAP 内存,同时可能出现 GC 时间飙升,线程被 Block 等现象,通过 top 命令发现 Java 进程的 RES 甚至超过了
-Xmx的大小。出现这些现象时,基本可以确定是出现了堆外内存泄漏。
- 内存使用率不断上升,甚至开始使用 SWAP 内存,同时可能出现 GC 时间飙升,线程被 Block 等现象,通过 top 命令发现 Java 进程的 RES 甚至超过了
-
原因
- **主动申请未释放:**通过
UnSafe#allocateMemory,ByteBuffer#allocateDirect主动申请了堆外内存而没有释放,常见于 NIO、Netty 等相关组件。 - **通过 JNI 申请的内存未释放:**代码中有通过 JNI 调用 Native Code 申请的内存没有释放。
- **主动申请未释放:**通过
-
解决
total 中的 committed 和 top 中的 RES 相差不大,则应为主动申请的堆外内存未释放造成的,如果相差较大,则基本可以确定是 JNI 调用造成的
- **主动申请未释放:**配置-XX:MaxDirectMemorySize=size,如果有-XX:+DisableExplicitGC则去掉
- 通过 JNI 申请的内存未释放: Google perftools + Btrace 等工具,帮助我们分析出问题的代码在哪里
-
CPU占用100%分析和解决
-
先jstat -gccause 1 和 jstat -gc 1 看下是否GC频繁
-
top -b Hp 1结合jstack -F 1 > jstack.log 分析那个线程占用高
-
jmap -dump:format=b,file={dumpFileName} {pid}生成dump文件线下分析或jmap -histo:live ${pid} | head -10
-
-XX:NativeMemoryTracking=detail 开启NMT, 用于查看( 堆内内存、Code区域或者使用unsafe.allocateMemory和DirectByteBuffer申请的堆外内存)但是不包含其他Native Code(C代码)申请的堆外内存 jcmd 1 VM.native_memory summary scale=MB查看结果
reserved memory:预订内存,不表示实际使用,最主要的是申请了一批连续的地址空间;(OS 角度)
commited memory:实际使用的。(OS 角度)
火焰图
- perf采集cpu调用栈-》生成火焰图-》查看顶部和宽度
JMM内存模型
我的理解是java多线程对共享变量的访问时保证原子性、顺序性、可见性的约定。
volatile保障可见性
volatile修饰的变量在访问前增加了总线锁Lock
总线锁
多核cpu只有获取到总线锁的cpu核才能访问内存,导致其他核不能访问内存,效率差
MESI缓存一致性协议
消息发布机制:总线读、总线本地写、总线写回
总线嗅探、总线裁决
1.工作内存1读取变量a,会发送总线读消息,状态为E-》S
2.工作内存2读取变量a,会发送总线读消息,状态为S-》I
3.工作内存1赋值变量a,会发送总线本地写,状态为E->S->M