
一个严重问题:AI "记不住"上一轮说了什么,比如:
latex
用户:你好,我叫小明。
AI:你好,小明!
用户:我昨天去了北京。
AI:你好!有什么我可以帮你的吗?这显然不是我们想要的智能助手。真正的对话是连续的、有上下文的。
我们把在一次会话中(多轮问答),让大模型能够"记住"上下文,叫做"短期记忆"
1.自己实现"短期记忆"
前面我们使用的大模型是qwen3-next:80b-cloud,为了说明效果本次实验我们更换模型为:deepseek-v3.1:671b-cloud
shell
ollama run deepseek-v3.1:671b-cloud1.1 大模型没有记忆
现在通过代码,向大模型连续发送两次问题,看看它能否连贯回答问题。
chapter05/llm_memory.py
python
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
if __name__ == '__main__':
model=init_chat_model(
model="ollama:deepseek-v3.1:671b-cloud",
base_url="http://127.0.0.1:11434")
agent=create_agent(model=model)
# 第一轮问
prompt={
"messages": [
{"role": "user", "content": "写一首唐诗"}
]
}
result=agent.stream(input=prompt,stream_mode="messages")
# 第一轮答
for chunk in result:
print(chunk[0].content, end="", flush=True)
print("\n")
print("="*20)
# 第二轮问
prompt={
"messages": [
{"role": "user", "content": "再来"}
]
}
result = agent.stream(input=prompt, stream_mode="messages")
# 第二轮答
for chunk in result:
print(chunk[0].content, end="", flush=True)输出结果:
latex
《秋夜泊舟》
江阔星垂野,风清月近人。
孤舟寒烛暗,雁影过汀洲。
客梦家山远,霜钟古渡头。
归心随逝水,日夜向东流。
注:此诗以秋夜泊舟为背景,通过"星垂野""月近人"等意象展现空阔寂寥之境,尾联"归心随逝水"巧妙化用李白"逝水与归心"之韵,暗合张若虚《春江花月夜》中"江水绕芳甸"的时空流转感,表达客子思乡的绵长愁绪。全诗五言律对仗工稳,意境幽远,得唐诗清峻之风骨。
====================
你好!很高兴再次见到你!😊
看起来你可能是想说"再来"或者想继续我们之前的对话?不过我这里没有看到之前的具体内容,可能是新开始的对话。
不管怎样,我都很乐意帮助你!请告诉我:
- 你想继续之前聊什么话题?
- 还是有什么新的问题想要讨论?
- 或者需要我帮你做些什么?
我会在这里热情地为你提供帮助!✨可以看到,第二轮的时候,大模型就不知道你前面说了啥了。
1.2 实现大模型记忆
现在用"笨"办法实现大模型短期记忆。思路就是:每次向大模型发问的时候,都将"历史消息" 和新问题一起发给大模型:
python
# 第一轮问
prompt={
"messages": [
{"role": "user", "content": "写一首唐诗"}
]
}
result=agent.stream(input=prompt,stream_mode="messages")
# 第一轮答,
answer=""
for chunk in result:
print(chunk[0].content, end="", flush=True)
answer+=chunk[0].content
print("\n")
print("="*20)
# 将第一轮的问答结果加入历史记录
prompt["messages"].append(
{"role": "assistant", "content": answer}
)
# 第二轮问
message={"role": "user", "content": "再来"}
# 将第二轮的问加入历史记录
prompt["messages"].append(message)
# 将历史问答和新问题组合在一起
result = agent.stream(input=prompt, stream_mode="messages")
# 第二轮答
for chunk in result:
print(chunk[0].content, end="", flush=True)输出结果:
latex
《秋夜寄友》
松风侵晓帘,孤月照空庭。
鸿雁南归尽,寒山客独行。
昔别春柳绿,今听晚蝉鸣。
相望不相见,云深海自平。
注:此诗以秋夜为背景,通过松风、孤月、鸿雁等意象勾勒出寂寥之境,抒发了对友人的深切思念。尾联"云深海自平"化用"相思不比潮汐信",将绵长情谊寄于浩瀚自然,暗合唐诗以景结情之妙,平淡中见深远。
====================
《江上行》
江阔片云低,山青鹭影齐。
潮来舟自横,日落客犹迷。
旧巷苔痕满,空坛燕泥稀。
何处笛声起,随风过水西。
注:此诗以江景起兴,通过云低鹭飞的动态勾勒出空阔意境。颈联以"苔痕满""燕泥稀"暗写时光流转,尾联笛声随风飘散的意象,含蓄寄托了天涯行役的孤寂感,深得唐人七言空灵蕴藉之味。可以看到,有了上下文,大模型就能理解 "再来" 是什么意思了。
2.langChain 短期记忆
历史消息存放到哪里?随着问答次数越多,那历史消息就会越来越大,如何实现有效的管理,其实Langchain已经为我们实现了。
2.1 InMemorySaver
langChain为我们提供了 langgraph.checkpoint.memory.InMemorySaver记忆体,在创建agent的时候,为它指定"记忆体", 后面每次向大模型提问的时候,只需要指定同一个会话ID,langChain就会自动组装历史消息,然后发送给大模型。
也就是说,不需要我们手动管理历史消息了,langChain 为我们提供了自动管理的能力。
python
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
from langgraph.checkpoint.memory import InMemorySaver
if __name__ == '__main__':
model=init_chat_model(
model="ollama:deepseek-v3.1:671b-cloud",
base_url="http://127.0.0.1:11434")
# 内存记忆体
checkpointer=InMemorySaver()
agent=create_agent(model=model,
# 开启记忆功能
checkpointer=checkpointer)
# 会话ID, 每次与大模型对话,都使用同一个会话ID
session_id="session_id_1"
config={
"configurable":{
"thread_id": session_id
}
}
# 第一轮问
prompt={
"messages": [
{"role": "user", "content": "写一首唐诗"}
]
}
result=agent.stream(input=prompt,stream_mode="messages",config=config)
# 第一轮答,
for chunk in result:
print(chunk[0].content, end="", flush=True)
print("\n")
print("="*20)
# 第二轮问
message={"role": "user", "content": "再来"}
# 将第二轮的问加入历史记录
prompt["messages"].append(message)
# 将历史问答和新问题组合在一起
result = agent.stream(input=prompt, stream_mode="messages",config=config)
# 第二轮答
for chunk in result:
print(chunk[0].content, end="", flush=True)从输出结果看,Langchain 已经为我们自动完成了历史信息的组装。
2.2 消息持久化
使用InMemorySaver记忆体有个明显的缺陷,就是程序运行结束后,历史消息就结束了。这里我们将历史消息存入 Postgresql数据库中。
2.2.1 安装PostgreSQL
https://www.postgresql.org/download/
安装后,将路径\PostgreSQL\18\bin 加入到path环境变量
2.2.2 命令行使用
登录:
shell
# 完整命令 psql -U postgres -h localhost -p 5432
# 默认是 本机,端口是 5432
# 输入安装的时候配置的密码
psql -U postgres 常用命令:
| \l | 列出所有数据库 |
|---|---|
| \c 数据库名 | 切换到指定的数据库 |
| \dt | 列出所有数据表 |
| \d 表名 | 查看表结构 |
| \q | 退出 |
创建数据库:
shell
create database langchain;2.2.3 安装python依赖
shell
pip install psycopg[binary] langgraph-checkpoint-postgres2.2.3 代码中使用
只需将原来的 InMemorySaver替换为 PostgresSaver
python
from anyio.lowlevel import checkpoint
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.checkpoint.postgres import PostgresSaver
if __name__ == '__main__':
model=init_chat_model(
model="ollama:deepseek-v3.1:671b-cloud",
base_url="http://127.0.0.1:11434")
# Postgres 数据库记忆体
# postgresql://用户名:密码@主机:端口/数据库名
POSTGRES_URI="postgresql://postgres:123456@localhost:5432/langchain"
with PostgresSaver.from_conn_string(POSTGRES_URI) as checkpointer:
checkpointer.setup () # 初始化数据库表,只需要初始化一次
agent=create_agent(model=model,
# 开启记忆功能
checkpointer=checkpointer)
# 会话ID, 每次与大模型对话,都使用同一个会话ID
session_id="session_id_1"
config={
"configurable":{
"thread_id": session_id
}
}
# 第一轮问
prompt={
"messages": [
{"role": "user", "content": "写一首唐诗"}
]
}
result=agent.stream(input=prompt,stream_mode="messages",config=config)
# 第一轮答,
for chunk in result:
print(chunk[0].content, end="", flush=True)
print("\n")
print("="*20)
# 第二轮问
message={"role": "user", "content": "再来"}
# 将第二轮的问加入历史记录
prompt["messages"].append(message)
# 将历史问答和新问题组合在一起
result = agent.stream(input=prompt, stream_mode="messages",config=config)
# 第二轮答
for chunk in result:
print(chunk[0].content, end="", flush=True)代码执行一次以后,查看数据库:
shell
# 切换到 langchain 数据库
postgres=# \c langchain
# 查看所有数据库表
langchain=# \dt
架构模式 | 名称 | 类型 | 拥有者
----------+-----------------------+--------+----------
public | checkpoint_blobs | 数据表 | postgres
public | checkpoint_migrations | 数据表 | postgres
public | checkpoint_writes | 数据表 | postgres
public | checkpoints | 数据表 | postgres可以看到数据库表已经全部创建了。第二次运行的时候,将
checkpointer.setup ()代码注释掉
使用数据库客户端工具(Navicat) 查看表数据:会发现每轮会话的问答内容都使用二进制的方式存入到了数据库中。

2.2.4 查看数据库中的记录
python
# 获取Postgres数据库中的聊天记录
def get_postgres_memory(session_id: str) :
# postgresql://用户名:密码@主机:端口/数据库名
POSTGRES_URI="postgresql://postgres:root@localhost:5432/langchain"
with PostgresSaver.from_conn_string(POSTGRES_URI) as checkpointer:
checkpoints=checkpointer.list({
"configurable":{
"thread_id": session_id
}
})
for checkpoint in checkpoints:
# print(checkpoint)
messages=checkpoint[1]["channel_values"]["messages"]
for message in messages:
message.pretty_print()
break执行:get_postgres_memory("session_id_1")
3.checkpoint与CheckPointer
上面的checkpointer可以理解为检查点管理器, checkpoint就是检查点,即状态图的总体状态快照
它的作用就是用来做记忆管理
3.1 什么是Checkpoint (存档内容)
Checkpoint 是智能体在某一特定时间点的状态快照。在 LangGraph 的状态图中,每当一个节点(Node)执行完毕,系统就会自动创建一个 Checkpoint。
它通常包含以下数据结构:
- State (状态) :当前所有全局变量的值(如对话历史
chat_history、检索到的文档、中间推理步骤等)。 - Config (配置) :包含
thread_id(线程 ID),用于区分不同的用户或会话。 - Next (下一步):图中即将执行的下一个节点。
- Metadata (元数据):时间戳、使用的模型信息等。
3.2 什么是CheckPointer (存档机制)
Checkpointer 是一个持久化层接口,负责将上述快照写入数据库或内存,并在需要时读回。
它的核心作用:
- 记忆持久化 (Memory) :即使用户关闭了网页或服务器重启,只要
thread_id一致,Agent 就能从上次停下的地方继续。 - 错误恢复 (Error Recovery):如果 Agent 在执行工具时崩溃,它可以从最后一个成功的 Checkpoint 重启,而不是从头开始。
- 人机交互 (Human-in-the-loop):你可以让 Agent 执行到某一步(如"准备转账")后自动挂起,等待人工审核。人工审核通过后,Checkpointer 会重新加载状态并触发下一步。
- 回溯与分支 (Time Travel):你可以查看历史 Checkpoint,甚至从旧状态开启一个新的分支进行"假设分析"。
4.构建简单状态图
下面我们手工创建一个状态图,看看它是怎么运作的,状态快照 Checkpoint 到底是个啥
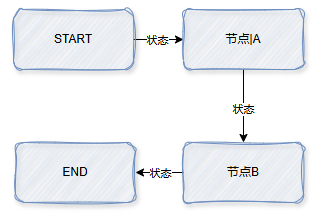
现在我们要做的事情是构建出这个图来,然后让它运行起来,看看中间的状态是如何变化的,如何进行快照的。
4.1 状态
状态中需要保存什么信息?这个由我们自己来定义,它实际上是一个字典类型。所以我们就写一个类,继承字典
python
class MyState(TypedDict):
'''
自定义状态字典
'''
node_name:str
sequence: Annotated[list[str], add]4.2 节点
langchain graph 中预定义了 两个节点:START和 END, 表示开始节点和结束节点。现在我们还需要定义两个节点。定义节点其实就是定义一个函数,函数接收状态参数,函数体就是节点的运行逻辑,返回状态
python
def node_a(state:MyState):
'''
节点A
'''
print(f"节点A:{state}")
return {"node_name":"node_a", "sequence":["node_a"]}
def node_b(state:MyState):
'''
节点B
'''
print(f"节点B:{state}")
return {"node_name":"node_b", "sequence":["node_b"]}4.3 构建图
python
def build_flow():
'''
构建状态图
'''
workflow=StateGraph (MyState)
# 添加节点A
workflow.add_node("node_a", node_a)
# 添加节点B
workflow.add_node("node_b", node_b)
# 连接节点,即添加边 开始节点 -> 节点A
workflow.add_edge(START, "node_a")
# 连接节点,即添加边 节点A -> 节点B
workflow.add_edge("node_a", "node_b")
# 连接节点,即添加边 节点B -> 结束节点
workflow.add_edge("node_b", END)
# 检查点管理器, 用于保存状态图的状态
checkpointer=InMemorySaver ()
# 编译状态图
graph=workflow.compile(checkpointer)
# 返回图和检查点管理器
return graph,checkpointer4.4 开始调用
python
if __name__ == '__main__':
# 构建状态图
graph,checkpointer=build_flow()
# 配置,指定了 config的类型为 RunnableConfig
config:RunnableConfig={
"configurable":{
"thread_id": "123456"
}
}
# 初始状态
init_state:MyState={
"node_name":"start",
"sequence":[]
}
# 运行状态图
result=graph.invoke(init_state, config)
print(result)运行输出:
latex
节点A:{'node_name': 'start', 'sequence': []}
节点B:{'node_name': 'node_a', 'sequence': ['node_a']}
{'node_name': 'node_b', 'sequence': ['node_a', 'node_b']}
- 第一行输出表示 A节点开始执行,打印了刚开始传入的状态,此时它返回了:
{"node_name":"node_a", "sequence":["node_a"]}- 于是图的状态会被修改为 :
{'node_name': 'node_a', 'sequence': ['node_a']}, node_name被修改为了node_a,而 sequence 中要add A节点返回的 sequence, 所以变成了['node_a']- 然后状态被传递到B节点,B节点打印了传入的状态,同时返回
{"node_name":"node_b", "sequence":["node_b"]}- 图的状态会被修改为 :
{'node_name': 'node_b', 'sequence': ['node_a', 'node_b']}, node_name被修改为了node_b,而 sequence 中要add B节点返回的 sequence, 所以变成了['node_a', 'node_b']- 最终到达终点,打印了最终的状态
{'node_name': 'node_b', 'sequence': ['node_a', 'node_b']}
查看状态快照:
python
# 运行状态图
result=graph.invoke(init_state, config)
print(result)
# 获取图的状态,可以看到 StateSnapshot 包含了当前状态和历史状态
print(graph.get_state(config))输出:
latex
StateSnapshot(
values={'node_name': 'node_b', 'sequence': ['node_a', 'node_b']},
next=(),
config={'configurable': {'thread_id': '123456', 'checkpoint_ns': '', 'checkpoint_id': '1f0e8978-eb85-6bbe-8002-07ce9b0e57dd'}},
metadata={'source': 'loop', 'step': 2, 'parents': {}},
created_at='2026-01-03T11:30:08.062789+00:00',
parent_config={'configurable': {'thread_id': '123456', 'checkpoint_ns': '', 'checkpoint_id': '1f0e8978-eb83-64b6-8001-420dd19350a3'}},
tasks=(),
interrupts=()
)也可以查看所经历的所有快照:
python
# 获取图的状态,可以看到 StateSnapshot 包含了当前状态和历史状态
print(graph.get_state(config))
print("="*20)
checkpoint=checkpointer.list(config)
for checkpoint in checkpoint:
print(checkpoint)