1 rag工作流
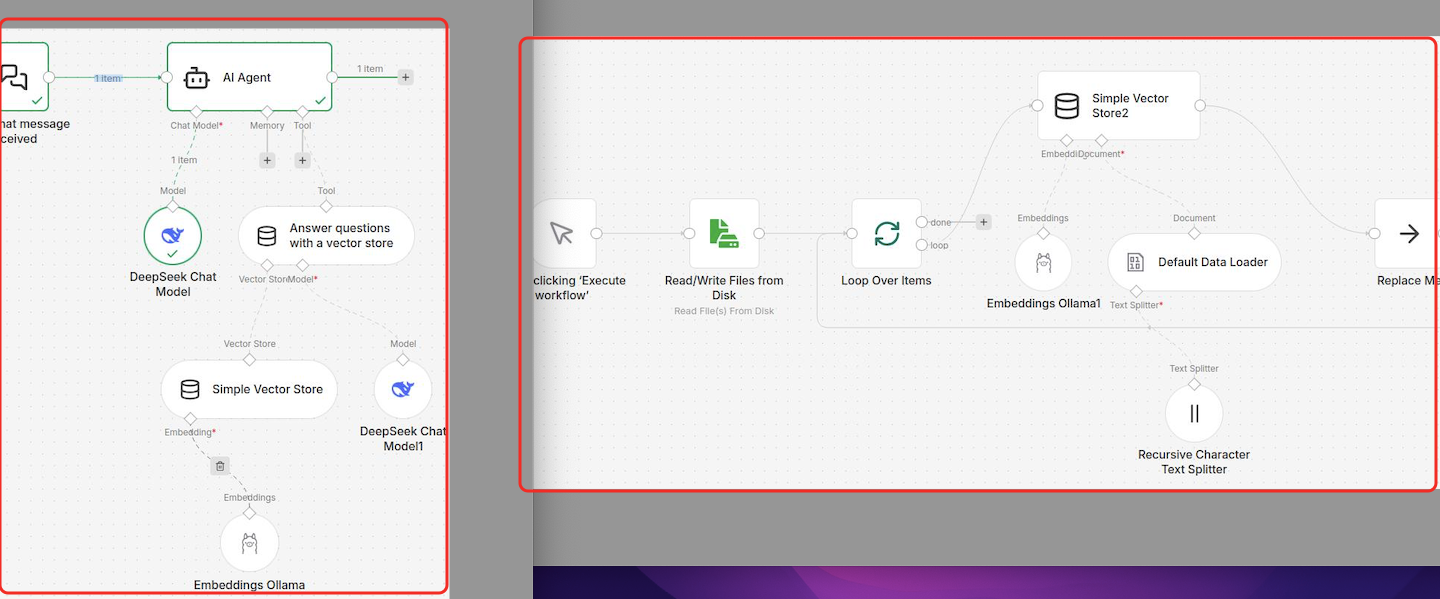
1.1 右侧为向量库
点击触发,首先读取文件夹下的文件,循环读取文件,选择simple vector store(有很多数据可以选择),连接ollama服务的embedding,文档链接Default Data Loader,连接文档切分方式
1.2 左侧为检索
对话框启动,连接ai agent,它的模型选择任意的llm,工具选择answer question with a vector,这个工具连接向量库(确保key值与1.1中的key值一样),向量库连接embedding服务,向量库也需要一个llm
1.3 embedding模型
用ollama下载embedding模型(ollama pull qwen3-embedding:0.6b,选个小模型用于测试),挑选embedding模型的时候,选择ollama的embedding
测试: ollama run qwen3-embedding:0.6b "你好", 可以看到生成的向量。
ollama list, ollama run 模型名 "question",可以看到ollma模型的输出
2 钉钉机器人发消息
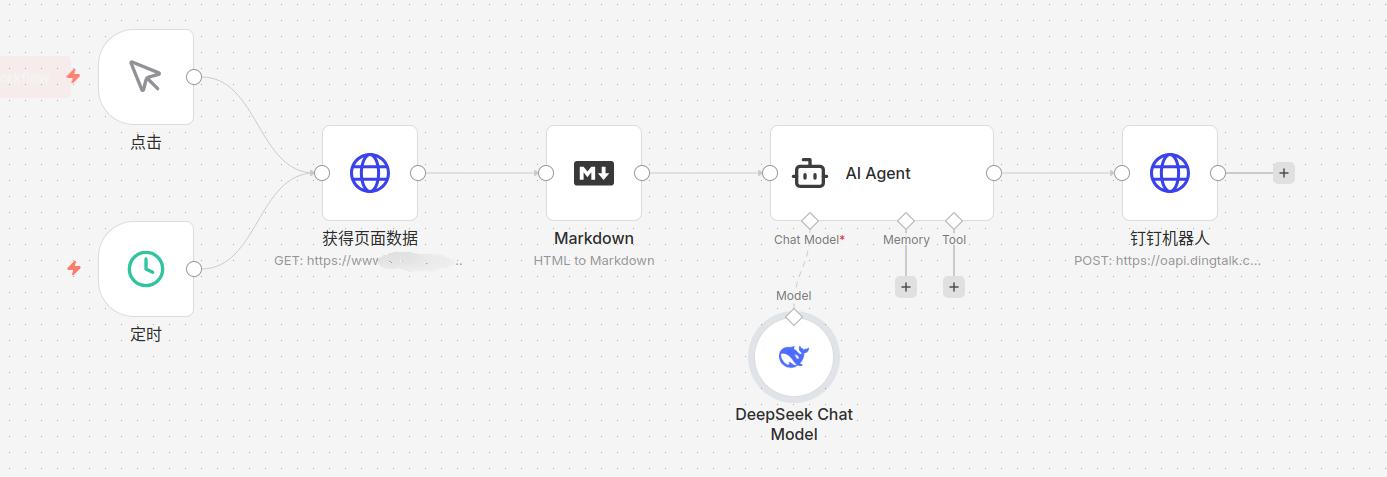 1. 触发方式,可以点击、可以定时
1. 触发方式,可以点击、可以定时
-
http节点,get方法,获得网页的内容
-
markdown节点,将html转为markdown格式
-
ai agent节点,填入提示词,例如这里的system message:你是一个新闻助手,分析网页内容,获得最新文章下的标题,链接和简要总结,返回markdown格式,按顺序列出并带有索引
-
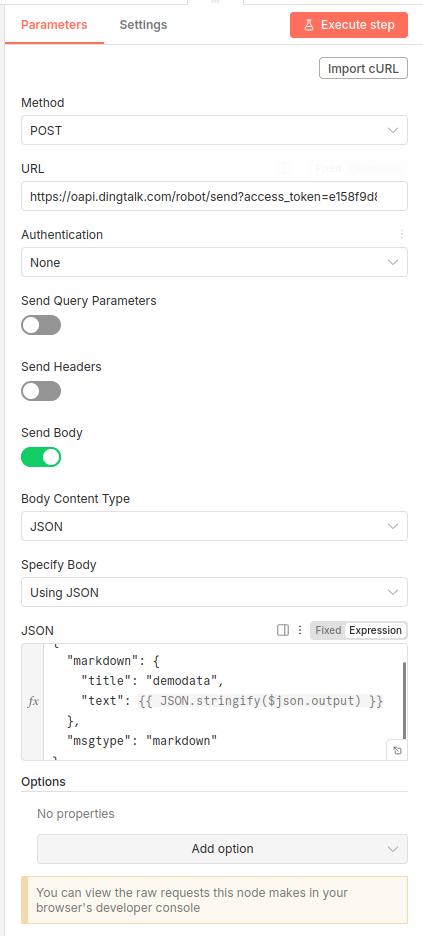
http节点,post,查询自己的钉钉机器人的情况,如下所示,填入自己的access_token,
下面的参数选择markdown形式(钉钉群识别markdown格式),JSON.stringify()为javascript的方法,可以转换字符,避免json识别失败。
python
{
"markdown": {
"title": "demodata",
"text": {{ JSON.stringify($json.output) }}
},
"msgtype": "markdown"
}