Paper Card
论文标题 :Knowledge Insulating Vision-Language-Action Models: Train Fast, Run Fast, Generalize Better
作者/机构 :Physical Intelligence (Danny Driess, et al.)
发布时间 :2025年5月
项目主页 :https://pi.website/research/knowledge_insulation
keywords:VLA, Flow Matching, Knowledge Insulation, Co-training, PaliGemma
1. 摘要
本文提出了一种新的 VLA 模型训练范式,称为 "Knowledge Insulation" (知识隔离) 。核心思想是在微调 VLM 主干进行机器人控制时,阻断从连续动作头(Action Expert)回传到 VLM 主干的梯度,同时引入离散动作预测作为辅助任务来训练主干表征。目的是不要让未经训练的连续的动作头的梯度破坏 VLM 预训练的知识。作者通过 Stop-Gradient 配合 离散动作辅助任务,既保留了 VLM 的语义理解能力,又实现了 Flow Matching 的高精度控制,且训练速度比纯 Flow Matching 方法快得多。
2. 背景与痛点
背景:VLA 模型试图将 VLM 中的预训练知识转移到机器人控制中。目前的趋势是结合 VLM 的语义能力与扩散模型/Flow Matching 的连续动作生成能力。
现有痛点:
- 推理速度慢:自回归生成离散动作 token(如 RT-2, OpenVLA)在推理时非常慢(<2Hz),难以满足高频控制需求。
- 知识遗忘与干扰:将随机初始化的连续动作头(如 Diffusion Head)"嫁接"到 VLM 上进行微调时,来自该头部的梯度流会破坏 VLM 原有的语义表征,导致语言指令遵从能力大幅下降。
- 训练收敛慢:基于 Flow Matching 或 Diffusion 的 VLA 训练效率较低,需要更多的 step 才能收敛。
本文动机:设计一种架构和训练策略,既能像自回归模型那样训练快、泛化好,又能像 Flow Matching 模型那样推理快、动作平滑,同时解决"灾难性遗忘"问题。
3. 核心方法
3.1 模型架构
作者基于 PaliGemma 构建模型,采用了 Mixture-of-Experts (MoE) 风格的解耦设计:
- VLM Backbone (3B):负责处理图像、语言指令和机器人状态(State),输出高层表征。
- Action Expert (300M):一个较小的 Transformer 模块,专门通过 Flow Matching 生成连续动作块(Action Chunks)。
- 关键机制:知识隔离 (Knowledge Insulation) :如 Figure 1 所示,模型在 Action Expert 和 VLM Backbone 之间实施了 Stop Gradient 操作 。
- Attention Masking:Action Expert 可以 attend 到 Backbone 的特征,但 Backbone 不能 attend 到 Action Expert 的 token,实现了单向信息流 。
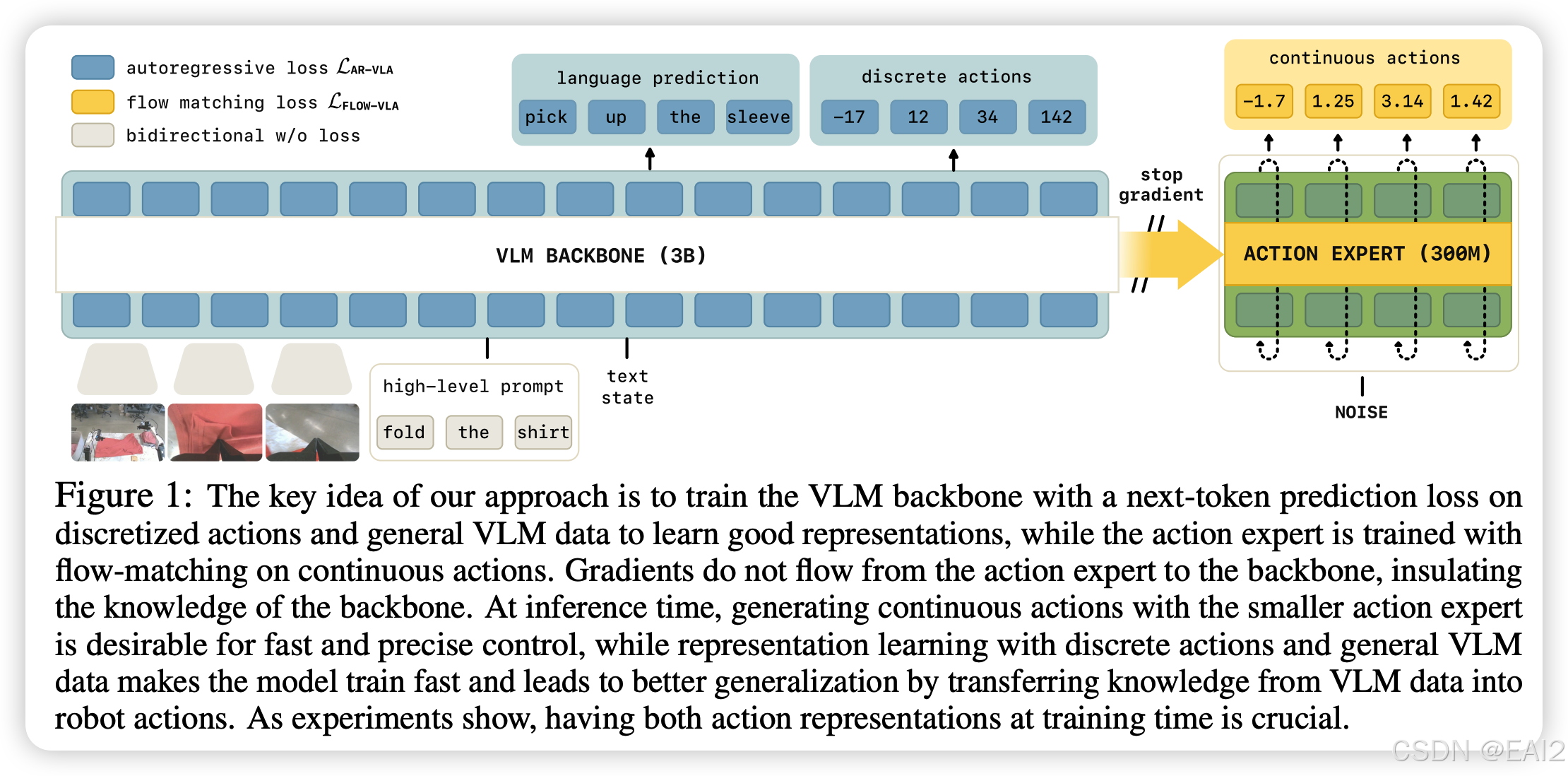
3.2 训练策略
为了在切断梯度的情况下仍能有效训练 Backbone 适应机器人任务,作者提出了 Joint-Training 策略,同时优化两个损失函数:
Backbone 表征学习 (离散动作损失):
- 使用 FAST Tokenizer 将连续动作离散化为 tokens。
- Backbone 通过标准的 Next-token Prediction (Cross-Entropy Loss) 预测这些离散动作 tokens。
- 为 Backbone 提供监督信号,使其学习机器人相关的视觉-动作表征,而不依赖于 Action Expert 的梯度 。
Action Expert 动作生成 (连续动作损失):
- Action Expert 基于 Backbone 的(detached)embedding,通过 Flow Matching 损失进行训练 。
- 损失函数定义如 Eq (4),其中, Action Expert 的梯度不会传回 Backbone。
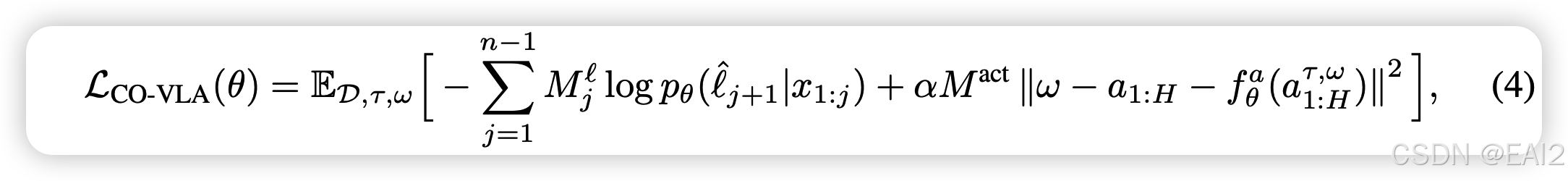
3.3 数据构建
为了进一步确保存储在 Backbone 中的通用知识不丢失,采用大规模的 Co-training 策略:
机器人数据:包含 OXE 数据集和 Physical Intelligence 内部采集的高质量数据(单臂、双臂、移动底盘等)。
VLM 通用数据:
- Image Captioning (CapsFusion, COCO)
- Visual Question Answering (Cambrian-1, VQAv2)
- Object Localization (Bounding box prediction)
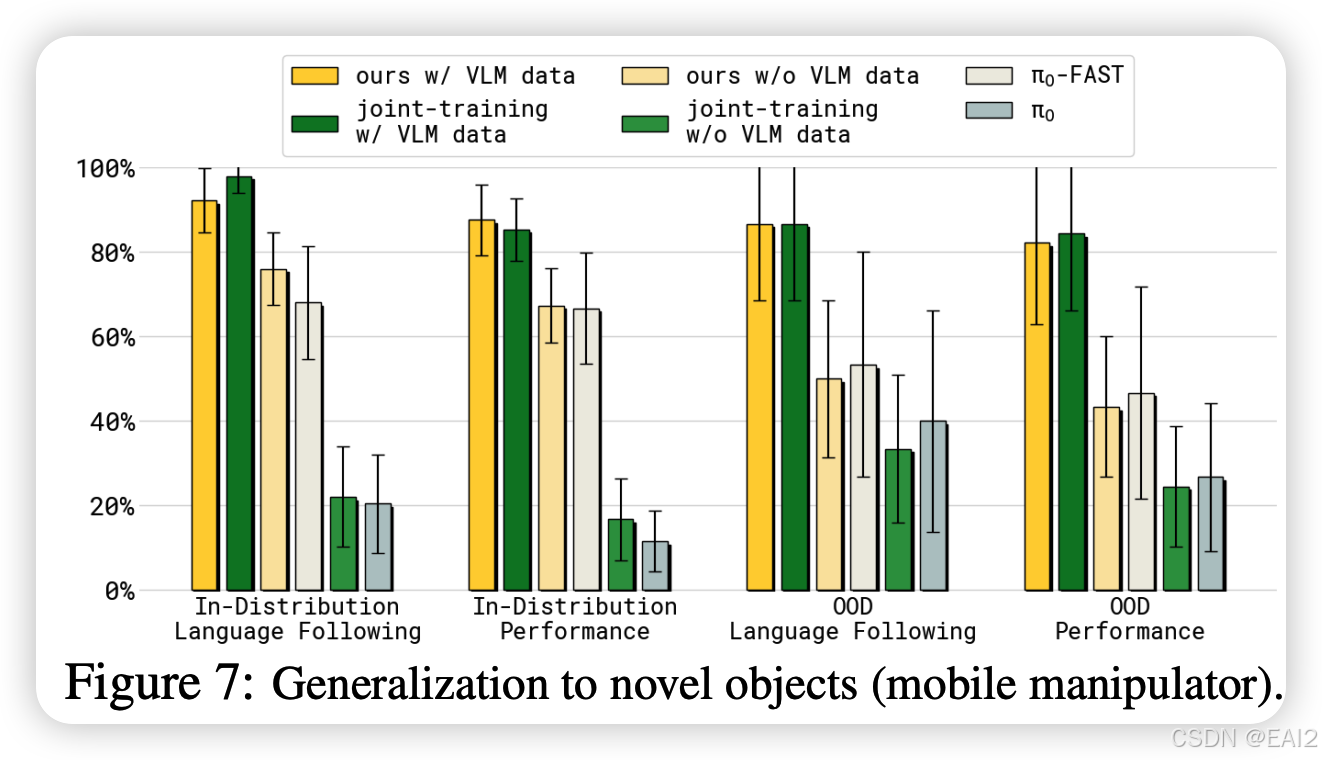
- 在训练 VLA 时,混合这些非动作数据与机器人数据一起训练。实验证明这对保持模型的通用泛化能力(特别是对新物体的处理)至关重要 。
4. 实验与评测
4.1 评测环境
真机实验:包括 "Items in drawer"(物体放入抽屉)、"Table bussing"(餐桌清理)、"Shirt folding"(叠衬衫)等长程任务。使用了不同形态的机器人(单臂 Franka/UR5、双臂移动操作机器人)。
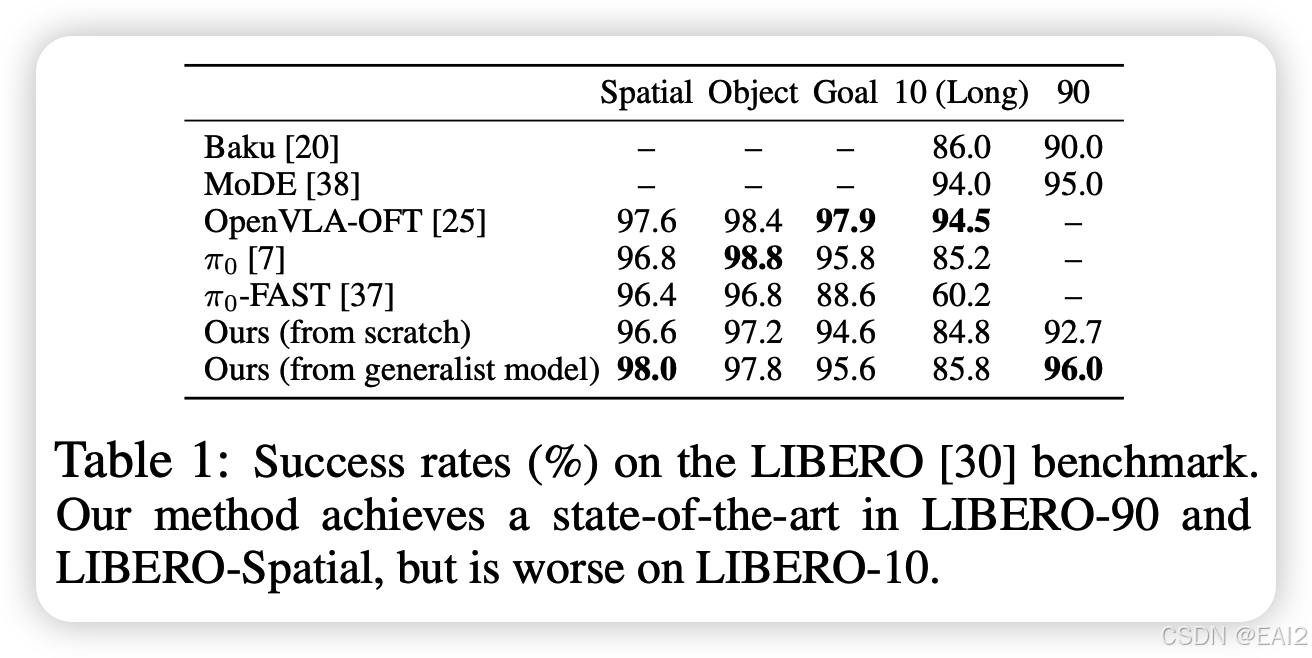
仿真实验 :LIBERO benchmark (Spatial, Object, Goal, Long) 。

基线对比:对比了 (Flow-only), -FAST (Discrete-only), HybridVLA, OpenVLA-OFT 等 。
4.2 主要结果
任务成功率与语言遵循:
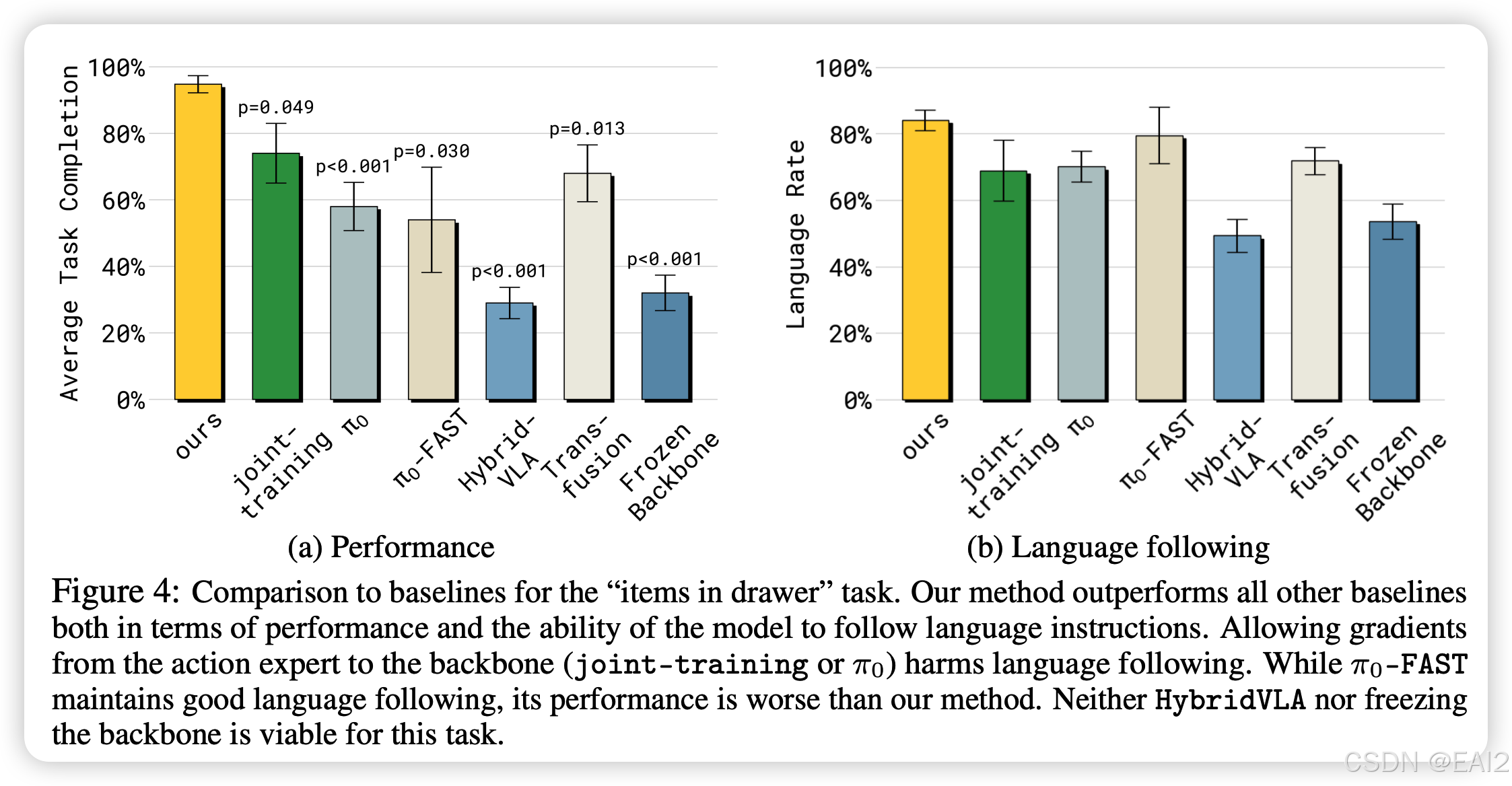
- 在 "Items in drawer" 任务中(需要理解语言指令并进行精细操作),显著优于所有基线(Figure 4a)。
- 在 "Table bussing" 任务中,实现了最高的成功率,且推理速度远快于 -FAST(Figure 5)。
- Figure 4b 显示,阻断梯度(Insulation)对于保持高水平的 Language Following Rate 至关重要(80%+ vs HybridVLA/ 的 ~50%)。
训练与推理速度:
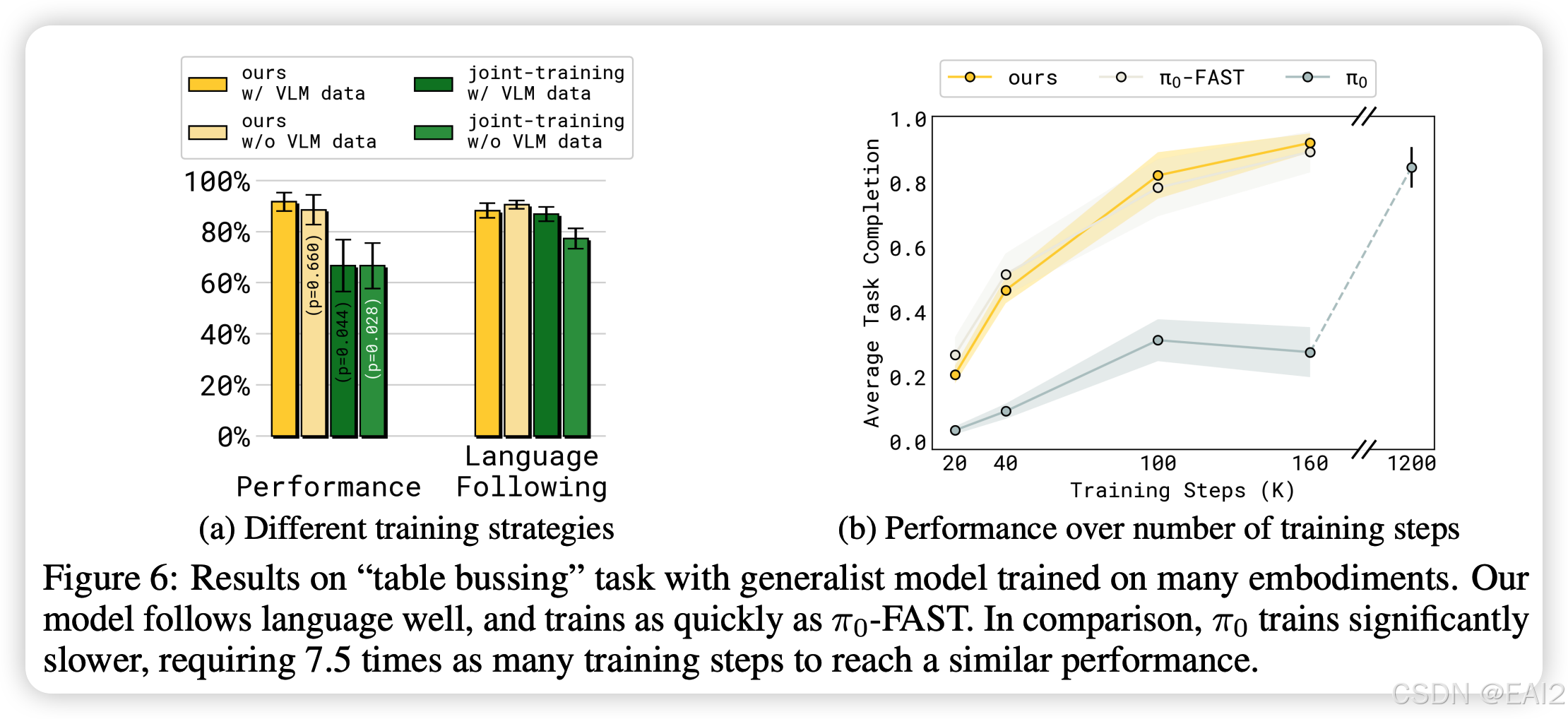
- 训练速度 :Figure 6b 展示了收敛速度与离散模型(FAST)一样快,远快于纯 Flow Matching 的 ( 需要 7.5 倍的步数才能达到相似性能)。
- 推理速度 :由于 Action Expert 较小且采用 Flow Matching,推理延迟远低于自回归模型(Figure 2)。

泛化性:
- 在 LIBERO-90 和 LIBERO-Spatial 上达到了新的 SOTA(Table 1)。
- 在移动机器人未见物体(OOD)测试中,Co-training VLM 数据显著提升了成功率(Figure 7)。
4.3 消融实验 (Ablation Studies)
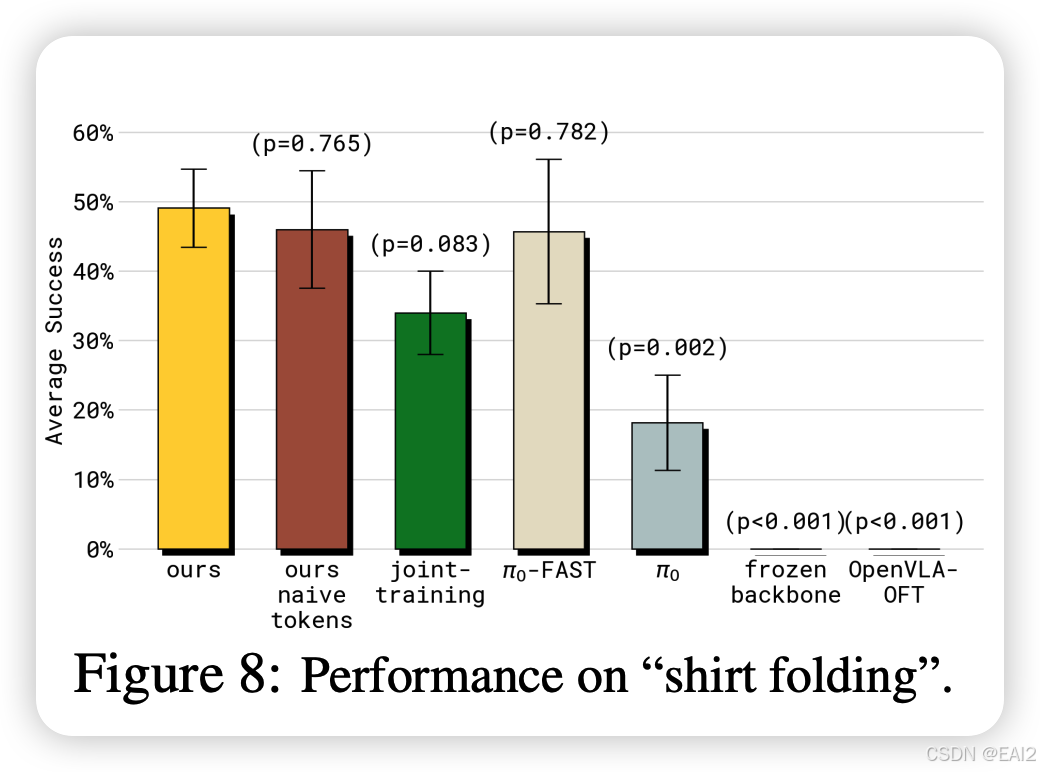
Insulation 的作用 :如果不阻断梯度(即 Joint-training),语言遵循能力和任务成功率都会下降(Figure 4b, Figure 8)。
VLM 数据的作用:去掉 VLM Co-training 数据会导致在未见场景和长程任务中的表现下降,尤其是在 Joint-training 设定下(Figure 6a)。
离散 Tokenizer 的选择:使用 FAST tokenizer 比简单的 naive binning 效果更好,证明了高质量的离散表征对 Backbone 的学习很重要(Figure 5 "naive tokens")。
5. 结论与思考
5.1 关键结论
本文最有价值的发现是揭示了 "Gradient Interference" (梯度干扰) 是阻碍 VLA 发展的核心因素之一。通过解耦 "Representation Learning" (由离散信号驱动的主干训练) 和 "Action Generation" (由连续信号驱动的头部训练),可以在不牺牲 VLM 通用智能的前提下,获得高性能的机器人控制策略。
5.2 局限性
计算成本增加:由于需要同时预测离散 token 和连续流,训练时的计算成本增加了约 20% 。
语言遵循仍非完美:尽管有显著提升,但仍未达到 100%,作者推测这是训练数据中的相关性(correlations)导致的过拟合 。
State 表示:虽然探索了 Text state vs Continuous state,但并未得出那种表示绝对占优的定论,尽管 Text state 更符合 VLM 直觉(Figure 10)。
5.3 未来方向
Scaling Law:这种 Insulation 架构在更大参数量(如 70B+ 模型)上的表现值得探索,大模型可能对梯度干扰更敏感。
Tokenizer 改进:既然离散信号主要用于表征学习,是否可以设计专门针对机器人 State-Action 压缩的 Tokenizer,而不仅仅是像 FAST 那样做 DCT 压缩?
架构融合:目前的 Action Expert 还是一个独立的 Transformer,未来是否可以利用 LoRA 或 Adapter 的形式实现更轻量级的 Insulation?
PyTorch 实现伪代码
根据论文第 5.2 节(Knowledge Insulation & Gradient Flow)的描述,特别是公式 (5) 和 (6) ,Knowledge Insulation 的核心是在 Action Expert(动作专家网络)对 VLM Backbone(主干网络)进行 Attention 操作时,切断反向传播的路径。
在 PyTorch 中,这主要通过 .detach() 方法来实现。
核心原理
论文中的公式 (5) 将 Attention Logits 分解为:
Logits = ( Q b K b T − ∞ Q a sg ( K b T ) Q a K a T ) \text{Logits} = \begin{pmatrix} Q_b K_b^T & -\infty \\ Q_a \text{sg}(K_b^T) & Q_a K_a^T \end{pmatrix} Logits=(QbKbTQasg(KbT)−∞QaKaT)
其中 sg (stop gradient) 操作符对应 PyTorch 中的 .detach()。这意味着当 Action Expert 的 Query ( Q a Q_a Qa) 去"查询" Backbone 的 Key ( K b K_b Kb) 时,我们将 K b K_b Kb 视为常数,不计算其梯度。
伪代码
这通常有两种实现范式:一种是作为两个独立的 Transformer 模块(Backbone 和 Expert),另一种是作为一个拼接序列的单一模型。鉴于论文中提到 Backbone 和 Expert 参数量不同(3B vs 300M),分离模块 + 交叉注意力(或带 Mask 的拼接注意力) 是最合理的工程实现。
以下代码展示了最清晰的 "Detached KV Cache" 范式,这也是绝大多数类似架构(如 Flamingo, Blip-2)采用的方法:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class KnowledgeInsulatedVLA(nn.Module):
def __init__(self, vlm_backbone, action_expert):
super().__init__()
self.vlm_backbone = vlm_backbone # e.g., PaliGemma (3B)
self.action_expert = action_expert # e.g., Smaller Transformer (300M)
# 论文提到两者通过 attention 交互,需要维度投影到一致
[cite_start]# [cite: 119] "dimensions of those projections are the same"
self.expert_proj = nn.Linear(vlm_backbone.hidden_size, action_expert.hidden_size)
def forward(self, images, text_input, noisy_actions, action_timesteps):
# =========================================================
# 1. VLM Backbone Forward (Standard)
# =========================================================
# Backbone 处理图像和文本,计算离散动作的表征
# 输出: backbone_features (Batch, Seq_Len_B, Dim_B)
backbone_outputs = self.vlm_backbone(images, text_input)
backbone_features = backbone_outputs.last_hidden_state
# [cite_start]计算离散动作预测 Loss (用于表征学习) [cite: 122]
# 这部分的梯度是允许传回 Backbone 的
loss_discrete = self.compute_discrete_loss(backbone_outputs.logits, text_input)
# =========================================================
# 2. Knowledge Insulation (The Core Trick)
# =========================================================
# 关键步骤:在传递给 Action Expert 之前,切断梯度流
# [cite_start]对应论文 Eq (5) 中的 sg(...) 操作 [cite: 200]
context_features = backbone_features.detach()
# 注意:这里必须使用 .detach()。
# 这样一来,Action Expert 的 Loss 对 context_features 的导数为 0,
# 梯度就不会继续回传到 self.vlm_backbone 的权重中。
# 维度对齐投影 (如果需要)
context_features = self.expert_proj(context_features)
# =========================================================
# 3. Action Expert Forward (Flow Matching)
# =========================================================
# Action Expert 接收 Noisy Actions 作为输入 Query,
# 并将 detached 的 backbone features 作为 Key/Value 进行 Cross-Attention
# 或者拼接在序列前方进行 Masked Self-Attention
# [cite_start]论文 Appendix B [cite: 678] 提到:
# "Embeddings from the action expert attend to the prefix (backbone)..."
flow_prediction = self.action_expert(
query_states=noisy_actions, # Q_a
timesteps=action_timesteps,
encoder_hidden_states=context_features # K_b, V_b (Detached!)
)
# [cite_start]计算 Flow Matching Loss [cite: 126]
# 这个 Loss 的梯度只会更新 action_expert,会在 context_features 处停止
loss_flow = F.mse_loss(flow_prediction, target_flow)
# =========================================================
# 4. Total Loss
# =========================================================
# [cite_start]联合训练 [cite: 177]
total_loss = loss_discrete + alpha * loss_flow
return total_loss
def compute_discrete_loss(self, logits, targets):
# 标准的 Cross Entropy Loss 实现
pass