Part 8. Model,Optimizer,Scheduler初始化和调用

Megatron-LM优化器初始化在pretrain函数中,调用setup_model_and_optimizer函数进行模型、优化器、学习率调度器的初始化,进一步调用get_model
- get model根据pipeline 并行设置 pre_process / post_process,只在该 rank 构建自己负责的段;如开启虚拟 pipeline,会为本 rank 的多个 virtual stage 分别构建对应段。
- 构建后会为所有参数设置/修复 tensor-parallel 属性,可以看到会从列表中取出所有的模型分段,GPTModel->LanguageModel->MegatronModule->Torch.nn.Module,自动会有.parameters()属性。默认情况下,没有设置过tensor parallel的都会把属性设置为False。
- 然后再做 DDP/FSDP 包装。只有当 tensor_model_parallel_size=1 且 pipeline_model_parallel_size=1 时,每个 rank 才是完整模型。
- 最后把parameters在DP组内广播
这里Megatron实现了自己的DDP。DDP负责了不同DP副本之间的梯度同步,也会负责处理和EP相关的内容。使用DDP.module可以做到unwrap获取到原本的模型。
- DDP使用了bucket模式。反向传播的时候,不是所有的参数梯度都算完才同步,而是设置一个桶,反向参数算好梯度就装进桶里,桶满了就立刻开始规约同步。这样重叠了梯度计算和通信时间。
- DDP中会注册grad buffer,并把param.main_grad指向该切片。参数的局部param.grad计算完成后会累加到main_grad中,清空param.grad,按照要求选择触发reduce scatter或者all reduce
- EP size是MoE专家分到几个GPU上。比如32卡16专家模型,DP=8,TP=4,EP=4。则每8张卡有相同的模型和不同的数据。EP=4,则16个专家分到4张卡上,每张卡4个专家。在DP=8的基础上,EP又可以并行,即EDP,此时8个DP卡中,每两张卡有相同的4个专家。
- 补充说明CP:CP其实是切的更细的DP,因为他们的模型权重都是一样的。
终于初始化好模型了,现在回来初始化optimizer。调用get_megatron_optimizer.
- 这个函数会返回一个MegatronOptimizer类的优化器,在torch实现或者Transformer Engine的optimizer的基础上做了一些封装,支持自定义的梯度同步等。在MegatronOptimizer上有MixedPrecision Optimizer和进一步的FP16optimizer,以及FP32全精度Optimizer。
一个Optimizer初始化的时候,相对来说比较简单,主要就是把一些参数准备好,以及准备好一些可用函数
-
全精度FP32直接用模型参数做更新,不做主副本;step 时仅把 param.main_grad 绑定回 param.grad 再 optimizer.step(),不涉及精度转换;main_grad时Megatron自己维护的梯度缓冲指针,可以指向一个大号的连续buffer切片,能够做梯度积累与all reduce等,提高通信和内存效率
-
混合精度训练,优化器会在初始化时为所有FP16、BF16参数创造一份FP32的 main param参数,把optimizer里指向的内容替换成main_param,同时让原本的param指向main_param。最后对于有state的optimizer,还要把state(动量等)中的原本参数的state换成main param的。

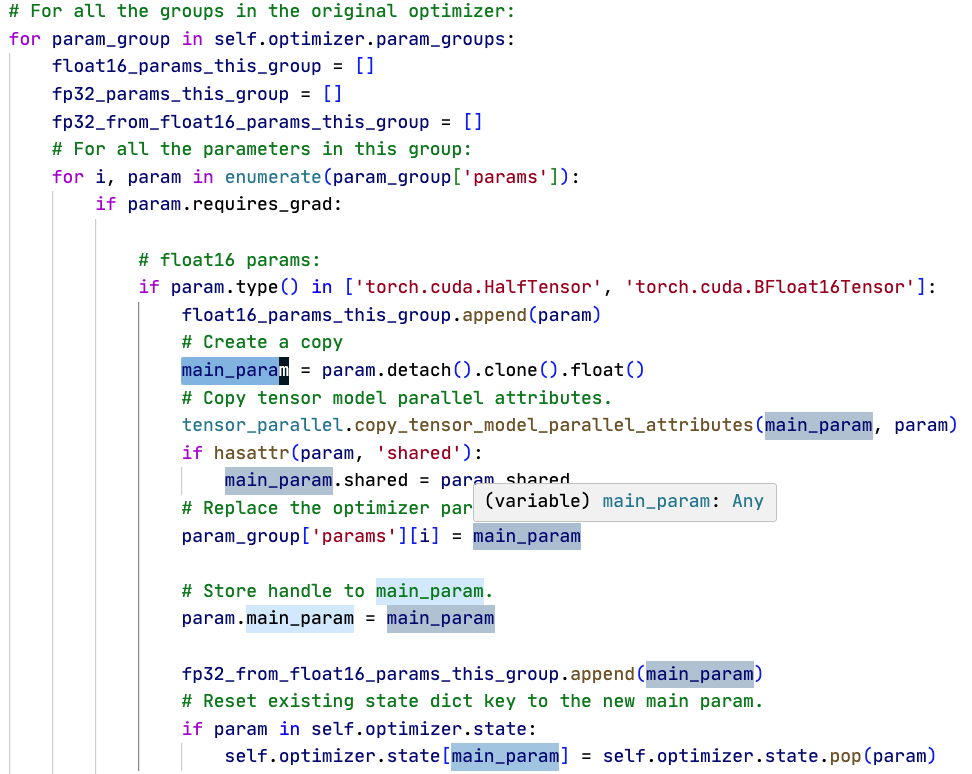
-
在保存检查点的时候,只会额外保存一份fp16格式参数。
-
原本的model的param,有自己的main_grad和grad。其中grad用于反向传播给优化器用,main_grad用于累积和通信用。在混合精度优化器中,半精度参数由于有一份新的单精度副本main_param,因此main_param有自己的grad用于给优化器更新。
-
提供reload和同步参数功能。reload把外部参数改变同步到优化器内部,_copy_main_params_to_model_params()把更新后的参数同步给外部模型
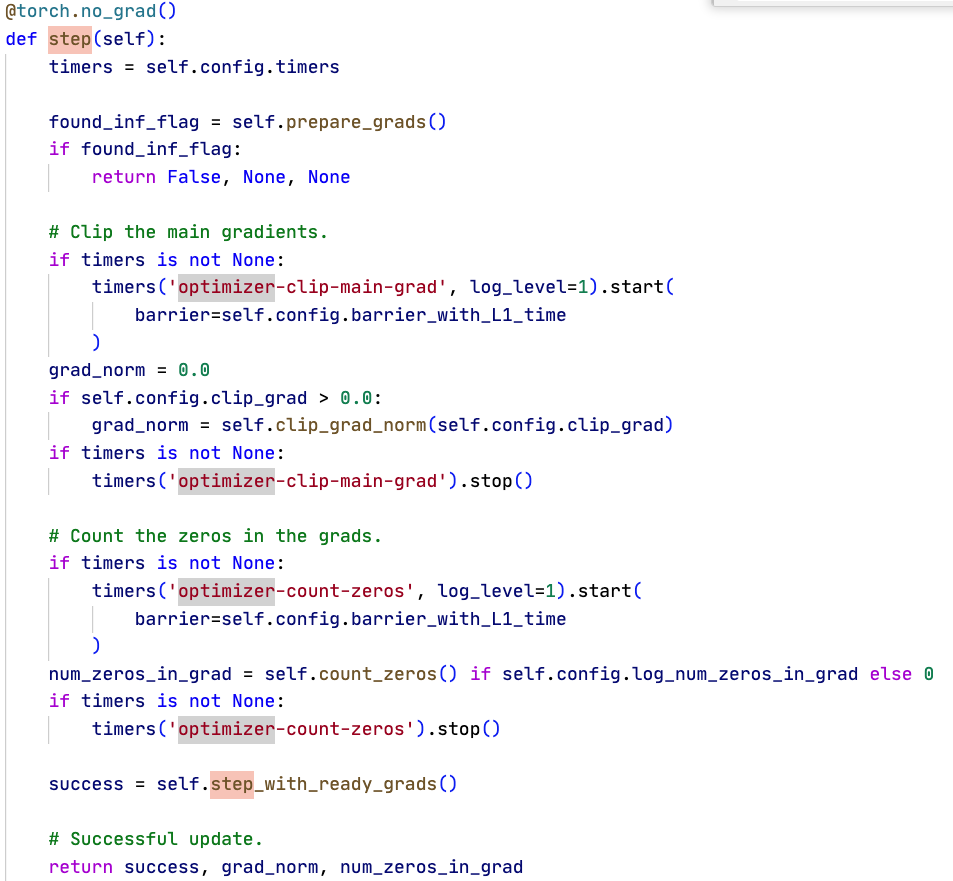
optimizer最重要的职责就是step。一个step大致是这样的:
- 准备梯度prepare_grads,主要是把main_grad交给grad,以及检查可能的inf/nan,用于给scaler使用;然后是可选的clip_grad_norm,计算所有参数的norm并按比例缩放等;数一下grad里有多少个0,最后step_with_ready_grads,内部有optimizer那就让他step就好了,最后把FP32主参数同步给可能有的外部半精度参数 _copy_main_params_to_model_params()
- FP32 Optimizer中,不需要做什么特别的额外处理;在半精度optimizer中,如果找到了inf,就直接返回step失败
- 半精度Optimizer有grad_scaler,是MegatronGradScaler类。它主要就是维护scale数值。scale控制loss大小,从而同步控制梯度大小。loss不能太小否则下溢,也不能太大否则上溢。因此,scaler监测到inf或者nan的时候就按比例缩小scale,反之当连续若干步没有溢出,按比例放大scale。如果检测到Nan,则step失败,训练循环中会直接跳过这个iteration,后续训练基于更新后的scale进行。
在计算参数p范数的时候是需要涉及到通信的。如果有DP则跨DP求和norm^p次方,之后跨grad_stats_parallel_group求和。后者在非分布式优化器的场景下就是TP/PP等模型并行集合,分布式情况下是所有的rank。因为分布式优化器相当于用上了ZeRO,状态被进一步切分,即使是有相同模型参数的DP内也被分到了不同的grad。
state_dict:传统的单体(非分片)状态,直接透传底层 optimizer.state_dict(),混精时再附带 grad_scaler 与 fp32 主参数列表。经典单机/单 rank 或未使用 Megatron 分布式检查点工具时,用 torch.save/torch.load 保存/加载优化器;或与旧版/第三方流程兼容。即使是用了TP/PP也是可以用的。
sharded_state_dict:面向分布式检查点的分片格式,基于模型的 ShardedStateDict,把参数和优化器状态映射成可分片/可并行保存的结构(含 shard 元数据、common_step 等),便于 ZeRO/FSDP/张量并行场景按 rank 拆分和重组。使用 Megatron 的分布式检查点(dist_checkpointing)路径时调用,用于分片保存/加载(每个 rank 写/读自己的 shard,再按映射重组);也支撑 tensor/pipeline/data parallel 以及 FSDP/Zero 场景。要use_dist_ckpt参数启用
get_megatron_optimizer按所有的model 模块轮流赋予optimizer。如果没有虚拟流水线那就只有一块,否则就有多块。总体上来说,先获取param groups与对应的buffer。因为不同的参数可能有自己不同的weight decay、lr mult设定等。通过分组能够统一调整有相同参数的组。另外MoE和Dense也有自己的通信路径。optimizer管理每个group的lr,weight_decay,wd_mult,max_lr,min_lr等。整理好group后,再设置好dense和moe的optimizer组成一个列表。这个列表被包装成ChainedOptimizer并返回,其实就是对多个Optimizer做for循环操作,没啥特别的,比较简单。
set_up_model_and_optimizer之后进行param scheduler调度。传入optimizer,返回一个OptimizerParamScheduler类。
- Scheduler主要就一个step。step中会get_wd、get_lr。step就是遍历optimizer的param groups,赋予新的学习率和权重衰减
- get_lr就很简单,没啥特别的,增加减小,warmup cosine linear exponetial等等。
- 在core_r0.12.1版本中,貌似所有参数都用相同的wd策略。尽管之前说了optimizer的param group会有按照wd分组,不过并没有像lr那样细到per group调整。可能是因为大部分时候也用不上对WD调整那么多吧

最后set_up_model_and_optimizer也会额外导入bert模型的权重,转换可能的检查点格式(传统的torch pt和dist checkpoint的互相转换),返回初始化好的model optimizer和opt_param_scheduler三员大将。
在train step中,每一步:
- Optimizer.zero_grad(),把param的grad和main_grad_buffer都清空
- forward_backward_func,用前向函数和模型做forward以及backward,获取losses_reduced
- 三个操作,forward_step和backward_step后,finalize_model_grads_func()会准备好梯度
- 在DP之间all reduce梯度,准备layernorm的grads(SP使用),以及embedding流水线头尾的grads,最后把gradient按token数scaling
- 在backward函数中间,会用config.grad_scale_func,也就是optimizer里的scale_loss,直接loss_scale * loss(真是好大一大圈麻烦)
- optimizer.step(),调用前面所说的准备梯度,检查和更新grad_scaler,等等
- scheduler.step(),更新学习率