在过去十年里,"深度学习"几乎成为人工智能的代名词:图像识别、语音识别、机器翻译、大模型,离不开深度神经网络。与此同时,"强化学习"也因为 AlphaGo、机器人控制、自动驾驶决策而频繁出圈。
很多人会产生疑问:
强化学习是不是深度学习的一种?
如果强化学习里也用神经网络,那它和深度学习到底有什么本质区别?
这篇文章将从"学习目标""数据来源""训练方式""算法结构"等角度,把两者的差异讲清楚,并建立一种更工程化、更可迁移的理解方式。
1. 一句话区分:它们解决的问题类型不同
深度学习(DL):主要解决"从数据中拟合函数"的问题
给定大量标注数据(输入 → 输出),学习一个映射函数。
强化学习(RL):主要解决"如何通过交互学到一个策略,让长期收益最大"的问题
智能体与环境互动,尝试动作并获得奖励,以最大化长期收益。
换句话说:
-
深度学习更多是 "学习一个模型"
-
强化学习更多是 "学习怎么做决策"
2. 学习目标不同:误差最小 vs 回报最大
深度学习的目标:最小化预测误差
典型监督学习(Supervised Learning)中,深度学习优化目标是:
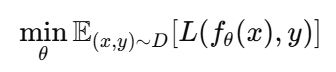
例如:
-
图像分类:交叉熵损失最小
-
回归预测:MSE最小
-
翻译模型:负对数似然最小
它的核心是:
预测值与标签越接近越好。
强化学习的目标:最大化累积奖励(长期收益)
强化学习的目标通常是:
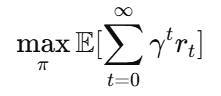
其中:
-
π是策略(policy)
-
r t是每一步获得的奖励
-
γ 是折扣因子
核心是:
不是每一步的奖励最大,而是长期总回报最大。
这带来强化学习最关键的难点:
当前的动作可能不会立刻有奖励,但会影响未来。
3. 数据来源不同:固定数据集 vs 动态交互生成
深度学习:依赖静态数据集
深度学习通常有一个固定数据集:
-
ImageNet
-
COCO
-
语料库
-
企业业务日志
训练流程如下:
-
数据采样 mini-batch
-
计算 loss
-
反向传播更新参数
在这种场景中,数据分布往往是相对稳定的。
强化学习:数据是"边训练边生成"的
强化学习需要智能体与环境交互产生轨迹:
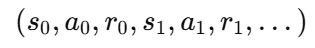
也就是说:
-
数据分布不固定
-
数据质量取决于当前策略
-
策略更新后,数据分布又变了
因此 RL 的训练很像:
一边学习,一边改变你看到的世界。
这直接导致强化学习训练更不稳定,更难调参。
4. 反馈信号不同:即时明确 vs 延迟稀疏
深度学习的监督信号:明确、密集
每个样本都有标签 y,损失立即可算,梯度稳定。
例如:
输入一张猫图,模型预测狗,立刻知道错了。
强化学习的奖励信号:延迟、稀疏、不完整
强化学习的奖励可能:
-
很稀疏:玩一局游戏直到赢才给 +1
-
很延迟:动作影响很久后才体现
-
不一定正确表达目标:奖励设计不好会出现投机行为(reward hacking)
例如:
-
训练机器人走路:摔倒一次就归零
-
训练自动驾驶:安全到达才奖励
这意味着 RL 训练中"误差反传链条"非常长,也更依赖估计(value estimation)。
5. 核心挑战不同:拟合 vs 探索与信用分配
深度学习:主要挑战是泛化与表示学习
-
如何构造更强的网络结构
-
如何让模型泛化到未见样本
-
如何减少过拟合/数据偏差
强化学习:主要挑战是探索与信用分配
强化学习核心困难主要是两点:
(1) 探索-利用(Exploration vs Exploitation)
-
你要试新动作(探索)才能发现更好回报
-
但试太多又浪费时间甚至导致损失
这是一类决策问题,在深度学习中几乎不存在。
(2) 信用分配(Credit Assignment)
最终奖励来自很多步动作的共同作用:
哪一步做对了?哪一步做错了?
RL 需要通过价值函数、策略梯度等方法去估计每个动作对未来收益的贡献。
6. 输出形式不同:预测结果 vs 行动策略
深度学习输出:通常是静态预测
给定输入 xxx,输出:
-
类别概率
-
坐标位置
-
文本序列
-
embedding 表示
这属于"感知/认知任务"。
强化学习输出:动作选择策略
强化学习输出通常是:
-
一个策略函数:π(a∣s)
-
或 Q 函数:Q(s,a)
它属于"控制/决策任务"。
7. 关系是什么?强化学习≠深度学习,但可以结合
一个常见误区是:
强化学习是深度学习的一种
更准确的说法是:
-
强化学习是一种学习范式(学习如何决策)
-
深度学习是一种函数逼近工具(用神经网络表示函数)
所以强化学习可以使用:
-
表格(Tabular)
-
线性函数
-
决策树
-
深度神经网络(Deep RL)
深度强化学习(Deep Reinforcement Learning) 就是强化学习 + 深度神经网络。
AlphaGo 的核心就是:
-
用 CNN 表示策略和价值函数(深度学习)
-
用 MCTS + RL 优化策略(强化学习)
8. 工程实现差异:RL 更难"落地"
这是很多人实践 RL 会遇到的现实问题:
深度学习工程链路成熟
-
数据采集
-
标注与清洗
-
训练与推理
-
线上监控与迭代
可控性强、可复现性好。
强化学习工程链路复杂
强化学习需要额外解决:
-
环境仿真器开发(Sim2Real)
-
reward 设计与调优
-
训练不稳定、容易崩
-
safety constraint(安全约束)
-
policy 线上探索风险大
所以实际工业界更多 RL 成功案例在:
-
游戏
-
广告竞价优化
-
资源调度
-
推荐系统的长期目标优化
-
自动化策略调参
而不是"随便用 RL 做机器人"。
9. 一个清晰的对比表(建议收藏)
| 维度 | 深度学习(DL) | 强化学习(RL) |
|---|---|---|
| 目标 | 最小化误差 | 最大化长期回报 |
| 数据 | 静态数据集 | 交互动态生成 |
| 反馈 | 标签明确、密集 | 奖励稀疏、延迟 |
| 输出 | 预测/表示 | 策略/动作 |
| 核心难点 | 表示学习、泛化 | 探索、信用分配 |
| 稳定性 | 相对稳定 | 不稳定、敏感 |
| 工程成本 | 相对可控 | 环境与奖励成本高 |
| 使用神经网络 | 必须 | 可选(深度 RL 才必需) |
10. 什么时候用 DL,什么时候用 RL?
适合用深度学习的场景:
-
你有大量标注数据
-
你要做分类/检测/回归/生成
-
目标明确,可用 loss 直接定义
一句话:预测任务就用 DL。
适合用强化学习的场景:
-
你要做多步决策
-
行为会影响未来状态
-
目标是长期效果(例如留存/收益/安全)
-
很难得到正确标签(only reward)
一句话:长期决策任务才用 RL。
结语:两者的差异是"问题范式",不是"模型结构"
最后总结一下:
-
深度学习是 学习函数映射(学习"是什么")
-
强化学习是 学习决策策略(学习"怎么做")
如果任务是:"我知道正确答案是什么,模型只要学会预测" → 用深度学习
如果任务是:"我不知道正确答案,模型必须通过试错学会怎么做" → 用强化学习
强化学习并不是深度学习的"升级版",它更多是一种完全不同的学习方式;深度学习只是强化学习中一种常用的函数逼近工具。
当你理解了这一点,你就不会再困惑于"强化学习是不是深度学习的一部分",而会更清晰地从"任务特性"来选方法。