STM32(基于 ARM Cortex-M 内核)中函数调用栈帧的开辟 / 销毁过程
核心是理解 ARM Cortex-M 的栈机制(满递减栈)和关键寄存器(SP/LR/PC)的协作
先明确核心前提
- STM32 的栈是向下生长的(栈指针 SP 从高地址向低地址移动),采用 ARM 标准的「满递减栈(Full Descending)」:SP 始终指向最后一个压入栈的有效数据,压栈(PUSH)时 SP 先减,再存数据;弹栈(POP)时先取数据,SP 再加。
- 核心寄存器(函数调用的关键):
SP(Stack Pointer):栈指针,指向当前栈帧的栈顶;
LR(Link Register):链接寄存器,存储函数调用的返回地址(调用函数后要回到的指令地址);
PC(Program Counter):程序计数器,存储当前执行的指令地址;
R0-R3:通用寄存器,用于传递函数参数(ARM AAPCS 调用规范);
R4-R11:保存寄存器,函数调用时需备份(避免被覆盖)。 - 栈帧:每个函数调用对应一段独立的栈空间,包含「参数、返回地址、寄存器备份、局部变量」,称为栈帧(Stack Frame)。
一、单个函数调用:栈帧的开辟与销毁(以 Cortex-M4 为例)
假设主函数main()调用func(a, b),参数a=1、b=2,func有局部变量c,返回a+b+c。以下是完整步骤:
阶段 1:函数调用前(main 准备调用 func)
- 传递函数参数:按 ARM AAPCS 规范,前 4 个参数优先用R0-R3传递(超过 4 个才压栈)。这里a=1存入R0,b=2存入R1。
- 执行 BL 指令(Branch with Link):
先将PC+4(func执行完后要回到的main下一条指令地址)存入LR寄存器;
再将PC跳转到func的入口地址,开始执行func。
阶段 2:进入 func,开辟栈帧(栈帧创建)
plaintext
高地址 → main的栈帧
-------------------
| func返回地址 | ← BL指令压入(实际先存LR,进入func后压栈)
-------------------
| R4-R11备份 | ← 可选(编译器决定,如-O0优化会备份)
-------------------
| 局部变量c | ← 开辟局部变量空间
------------------- ← SP(当前栈顶)
低地址 →具体步骤:
- 备份保存寄存器:编译器自动生成PUSH {R4-R11, LR}指令(根据优化等级,可能只备份部分寄存器),将R4-R11和LR(返回地址)压入栈,SP 相应递减(如备份 8 个寄存器 + LR,SP -= 36 字节,因为每个寄存器 4 字节)。
- 开辟局部变量空间:调整 SP,为局部变量分配栈空间(如c是 int 型,SP -= 4),此时 SP 指向栈帧的最底部(局部变量的起始地址)。
- 执行 func 函数体:计算c=3,最终返回1+2+3=6,返回值存入R0(ARM 规范:返回值优先用 R0 传递)。
阶段 3:func 执行完毕,销毁栈帧(栈帧释放)
- 清理局部变量:无需主动操作,只需恢复 SP 即可(局部变量存在栈中,SP 上移后会被后续压栈覆盖)。
- 恢复保存寄存器:执行POP {R4-R11, PC}指令:
从栈中弹出之前备份的R4-R11,恢复到寄存器;
弹出原本存在栈中的LR值(返回地址),直接写入PC(核心!)。 - SP 恢复:弹栈后 SP 自动递增,回到调用func前的栈位置,func的栈帧被销毁。
- 回到 main 函数:PC被设置为返回地址,main从调用func的下一条指令继续执行,从R0中读取func的返回值(6)。
函数嵌套调用:栈帧的层层压入与反向弹出
假设调用链:main() → A() → B(),核心逻辑是栈帧层层压栈,返回时反向层层弹栈,每个函数的返回地址保存在各自的栈帧中,确保 "原路返回"。
步骤拆解(简化版)
plaintext
初始状态:SP指向main的栈帧顶部
1. main调用A:
- R0传A的参数 → BL指令将main→A的返回地址存入LR → 进入A;
- A压栈LR(main返回地址)+ 备份寄存器 → 开辟A的局部变量 → SP下移,A的栈帧压在main栈帧下方;
2. A调用B:
- R0传B的参数 → BL指令将A→B的返回地址存入LR → 进入B;
- B压栈LR(A返回地址)+ 备份寄存器 → 开辟B的局部变量 → SP继续下移,B的栈帧压在A栈帧下方;
此时栈结构(高→低):
main栈帧 → A的返回地址 → A的寄存器备份 → A的局部变量 → B的返回地址 → B的寄存器备份 → B的局部变量 ← SP返回过程(反向弹出)
plaintext
1. B执行完毕:
- POP恢复寄存器 → 将B的返回地址(A的下一条指令)写入PC → SP上移,B的栈帧销毁;
- PC跳回A,A从调用B的下一条指令继续执行;
2. A执行完毕:
- POP恢复寄存器 → 将A的返回地址(main的下一条指令)写入PC → SP上移,A的栈帧销毁;
- PC跳回main,main从调用A的下一条指令继续执行;
最终:SP回到main的栈帧顶部,所有嵌套栈帧全部销毁。三、关键细节与避坑点
- 栈溢出问题:
嵌套调用层级过深(如递归函数无终止条件)、局部变量过多(如大数组),会导致栈帧超出 STM32 配置的栈大小(在启动文件startup_stm32xxx.s中配置Stack_Size),触发 HardFault 硬故障。
解决:减少局部变量大小(改用全局 / 静态变量)、增大栈大小、优化递归为循环。 - 编译器优化对栈帧的影响:
-O0(无优化):栈帧最完整,会备份所有保存寄存器,便于调试;
-O2/-O3(优化):可能省略寄存器备份、复用寄存器、甚至消除无意义的局部变量,栈帧更小。 - 中断对栈帧的影响:
STM32 中断发生时,硬件会自动压栈xPSR、PC、LR、R12、R0-R3(称为 "异常栈帧"),中断服务函数(ISR)的栈帧基于主栈(MSP),嵌套中断会继续压栈,需保证栈大小足够。 - LR 寄存器的特殊处理:
函数返回时,若未压栈 LR,可直接执行BX LR指令(将 LR 写入 PC);若已压栈 LR,则通过POP {..., PC}恢复,效果等价。
问题 1:R4-R11 和 LR 压栈的数量,是否由编译器优化等级决定?
核心结论:是,且不仅是优化等级,还受「函数是否使用这些寄存器」「ARM AAPCS 调用规范」双重影响。
详细拆解:
- ARM AAPCS 规范的基础约束
ARM 的函数调用规范(AAPCS)明确划分了寄存器的角色,这是编译器处理的前提:
✅ 临时寄存器(R0-R3、R12):调用方(如 main)不保证这些寄存器的值在函数调用后不变,被调用方(如 func)可以随意使用,无需备份;
✅ 保存寄存器(R4-R11):被调用方(如 func)如果要使用这些寄存器,必须备份到栈中,函数返回前必须恢复原值(否则会破坏调用方的寄存器数据);
✅ LR 寄存器:用于存储返回地址,是否压栈取决于函数是否有「嵌套调用」(比如 func 内部又调用了其他函数,会覆盖 LR,因此必须先压栈保存)。 - 编译器优化等级的核心影响
优化等级直接决定编译器是否 "按需备份",而非 "无脑全备份":
-O0(无优化,调试模式):编译器为了调试方便,会默认备份所有 R4-R11 + LR(即使函数没用到这些寄存器),栈帧最大,调试时能看到完整的寄存器状态;
-O1/-O2/-O3(优化模式,发布模式):编译器会 "按需备份"------ 只有函数实际用到的 R4-R11 才会被压栈,没用到的直接跳过;如果函数内部没有嵌套调用(不覆盖 LR),甚至可能不压栈 LR,直接用BX LR返回。
举例:
无优化(-O0):func 即使只用到 R4,编译器也会压栈 R4-R11+LR(共 10 个寄存器,40 字节);
优化(-O2):func 只用到 R4 和 R5,编译器仅压栈 R4、R5+LR(共 3 个寄存器,12 字节),栈帧更小。
SP 弹栈是指弹回到 main 的栈帧的栈底?备份的寄存器值会被恢复?
SP 弹栈是回到「调用子函数前的 SP 位置」;备份的寄存器(R4-R11)会被精准恢复,LR 的返回地址会写入 PC 实现返回。
STM32 的栈是满递减栈(高地址→低地址),每个栈帧的:
栈底:栈帧的最高地址(固定不变,比如 main 栈帧的栈底是调用 func 前的 SP 位置);
栈顶:栈帧的最低地址(SP 实时指向,开辟栈帧时 SP 下移,销毁时 SP 上移)。
func 销毁栈帧:
- 第一步:先释放局部变量(无需主动操作,只要 SP 上移即可,因为局部变量存在栈中,SP 上移后会被后续压栈覆盖);
- 第二步:执行POP {R4-R11, PC}:
✅ 从栈中依次弹出之前压入的 R4-R11 值,精准恢复到对应的寄存器(比如压栈时先存 R4,弹栈时先恢复 R4);
✅ 弹出原本压栈的 LR 值(返回地址),直接写入 PC 寄存器(而非恢复到 LR); - 第三步:SP 自动递增,回到调用 func 前的位置(即 main 栈帧的当前栈顶)------ 不是 main 栈帧的 "栈底",而是调用前的 SP 位置(main 栈帧的栈顶可能随 main 的局部变量变化,这个位置是动态的)就是main的栈顶。
传参的通用寄存器R0-R3去哪了
传参用的 R0-R3 作为「临时寄存器」,核心特点是不会被压栈、被调用方可随意修改、调用方不保证其值保留,下面我把 R0-R3 的完整生命周期和 "去向" 讲透:

一、R0-R3 的完整生命周期(以 main 调用 func 为例)
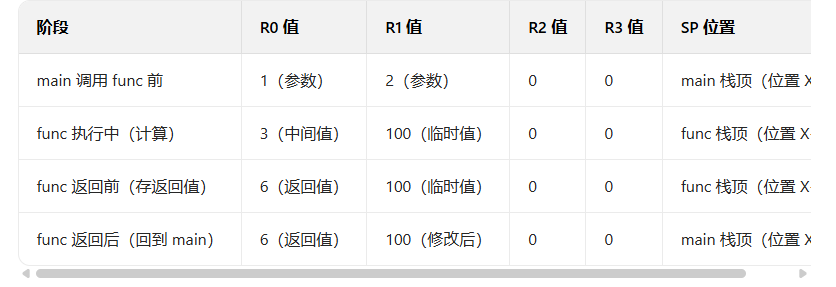
假设场景:main()调用func(1,2),参数 1→R0,参数 2→R1;func 执行后返回 6,返回值存入 R0。
阶段 1:main 调用 func 前(传参)
main 按规范将参数依次放入 R0、R1(前两个参数),此时 R0=1,R1=2,R2/R3 无值(空);
此时 R0-R3 的值是 main 主动设置的,目的是给 func 传递参数,main如果后续还要用 R0-R3 的原值,需要自己提前备份(比如压入 main 的栈帧)------ 但规范不要求 func 帮 main 保护这些值。
阶段 2:func 执行过程中(修改 R0-R3)
func 拿到 R0=1、R1=2 后,可直接使用这两个值计算,也可以随意修改 R0-R3(比如用 R0 存中间变量c=3,R1 存临时值100);
因为 R0-R3 是临时寄存器,func 无需将其压栈备份(压栈的只有 R4-R11 这类保存寄存器);
最终 func 计算出返回值 6,按规范将返回值存入R0(覆盖之前的 1),此时 R0=6,R1=100(已被修改)。
阶段 3:func 返回后(R0-R3 的 "去向")
func 执行POP {R4-R11, PC}返回 main,此时:
✅ R0:保留 func 的返回值 6(这是规范要求,也是 main 唯一关心的);
✅ R1-R3:值已经被 func 修改(比如 R1=100),原来的参数值(2)已经丢失;
✅ 全程 R0-R3 没有被压栈,也没有被恢复 ------ 它们的 "去向" 就是:要么被覆盖为返回值(R0),要么被修改为随机的临时值(R1-R3)。
main 接收到返回后:
从 R0 中读取返回值 6(这是 main 调用 func 的核心目的);
如果 main 后续还需要用调用前 R1 的原值(2),必须在调用 func 前自己备份(比如PUSH {R1}压入 main 的栈帧,返回后POP {R1}恢复),否则原值永远丢失。
二、直观示例(寄存器值变化)
三、关键补充(为什么 R0-R3 不压栈?)
- 性能优化:减少压栈 / 弹栈的指令和栈空间开销 ------ 如果每个函数都要备份 R0-R3,栈帧会变大,函数调用的耗时也会增加;
- 规范设计:前 4 个参数用 R0-R3 传递,返回值用 R0 传递,是 ARM 为了高效调用设计的(超过 4 个参数才会压栈);
- 调用方责任:如果 main 需要保留 R0-R3 的原值,由 main 自己负责备份(压栈),而非 func 的责任 ------ 这符合 "谁使用、谁保护" 的设计逻辑。