文章目录
- 前言
- [一、Hive Optimization](#一、Hive Optimization)
-
- [(一)Local Mode](#(一)Local Mode)
-
- [1.为什么需要Local Mode](#1.为什么需要Local Mode)
- [2.设置参数切换Local Mode](#2.设置参数切换Local Mode)
- [(1)SET hive.exec.mode.local.auto=true](#(1)SET hive.exec.mode.local.auto=true)
- [(2) set the maximum total size](#(2) set the maximum total size)
- [(3)sets maximum number of input files](#(3)sets maximum number of input files)
- [(二)JVM Reuse](#(二)JVM Reuse)
- [(三)Parallel Execution](#(三)Parallel Execution)
- [(四)Map and Reduce Quantity Optimization](#(四)Map and Reduce Quantity Optimization)
- [(五)Using EXPLAIN for Diagnostics](#(五)Using EXPLAIN for Diagnostics)
- 2.设置参数
- [(六)Query Optimization Techniques](#(六)Query Optimization Techniques)
-
- [1.common join](#1.common join)
- [2.Map join](#2.Map join)
- [3.Bucket map join](#3.Bucket map join)
- [4.Sort Merge Bucket (SMB) join](#4.Sort Merge Bucket (SMB) join)
- [5.Sort merge bucket map (SMBM) join](#5.Sort merge bucket map (SMBM) join)
- [6.Skew join](#6.Skew join)
- 总结:Summary
- 核心易考点总结
- [7.Sorting Behavior Optimization](#7.Sorting Behavior Optimization)
-
- [(1)ORDER BY](#(1)ORDER BY)
- [(2)SORT BY](#(2)SORT BY)
- [(3)CLUSTER BY](#(3)CLUSTER BY)
- [(4)use partition](#(4)use partition)
- [二、Execution engines in Hive](#二、Execution engines in Hive)
- [三、Hive Security](#三、Hive Security)
-
- [(一)Default Authorization Mode](#(一)Default Authorization Mode)
- [(二)Storage-Based Authorization Mode](#(二)Storage-Based Authorization Mode)
- [(三)SQL Standards-Based Authorization Mode](#(三)SQL Standards-Based Authorization Mode)
- [(四)Managing Access through SQL](#(四)Managing Access through SQL)
- 总结
前言
虽然Hive是为了处理大数据而构建的,但我们仍然不能忽视性能的重要性。 大多数时候,一个更好的Hive查询可以依赖于智能查询优化器来找到最佳执行策略,以及从供应商包中缺省设置的最佳实践。 但是,作为经验丰富的用户,我们应该更多地了解Hive中性能调优的理论和实践,特别是在基于性能的项目或环境中工作时。 在本章中,我们将从Hive中可用的实用程序开始,找到导致性能低下的潜在问题。 然后,我们将介绍在设计、文件格式、压缩、存储、查询和作业等领域的性能考虑的最佳实践。
一、Hive Optimization
Hive用户面临的最大挑战之一是运行临时查询的最终用户所经历的慢响应时间。
One of the biggest challenges Hive users face is the slow response time experienced by end users who are running ad hoc queries.
与传统关系数据库查询的性能相比,Hive的响应时间通常慢得令人无法接受,并且经常让您想知道如何实现最终用户习惯的性能类型。 本章提供了一个系统的方法来诊断和提高Hive查询的性能,它可以很容易地应用于大多数现有的Hive表。 每种技术都以累积的方式应用,从而使效果复合。 在整个过程中,我们将把单个Hive查询的执行时间从475秒减少到不到49秒。
Hive的优化:尽管Hive可以高效地处理大数据,但默认执行往往会导致查询响应时间过长。优化策略有助于减少不必要的开销,减少I/O操作,提高资源利用率,实现更快的执行。
Although Hive efficiently handles big data, default execution often leads to slow query response times. Optimization strategies help reduce unnecessary overhead, minimize I/O operations, improve resource utilization, and achieve faster execution.
(一)Local Mode
1.为什么需要Local Mode
Hadoop可以在独立、伪分布式和完全分布式模式下运行。 大多数时候,我们需要配置Hadoop以完全分布式模式运行。但是当数据量较小时,在分布式集群上运行会因为启动延迟而浪费时间 。Hive支持通过设置将作业自动切换为本地模式允许Hive在机器本身上运行作业 ,而不是跨多个节点运行。本地模式在以下情况下可以避免集群开销,这非常适合轻量级的即席查询。
When data volume is small, running on a distributed cluster wastes time due to start-up latency. Local Mode lets Hive run the job on the machine itself, not across multiple nodes. Local Mode avoids cluster overhead if:
- 输入大小低于
hive.exec.mode.local.auto.inputbytes.max - Input size is below the configured threshold
- map任务的总数小于
hive.exec.mode.local.auto.input.files.max - Few map tasks are needed
- 没有reduce任务或只有1个reduce任务
- No reduce task or only 1 reduce task
2.设置参数切换Local Mode
sql
SET hive.exec.mode.local.auto=true;
--default false
SET hive.exec.mode.local.auto.inputbytes.max=50000000;
SET hive.exec.mode.local.auto.input.files.max=5;
--default 4(1)SET hive.exec.mode.local.auto=true
默认情况下是false,代表使用分布式,改为true表示设定为本地模式
(2) set the maximum total size
sql
SET hive.exec.mode.local.auto.inputbytes.max=50000000;这设置了本地模式下 输入数据的最大总大小。如果输入数据小于50 MB,作业可以在本地运行
(3)sets maximum number of input files
sql
SET hive.exec.mode.local.auto.input.files.max=5;如果输入文件总数小于5个(默认为4个),Hive可以在本地运行
(二)JVM Reuse
(1)概念
JVM重用是一个Hadoop调优参数,它与Hive性能非常相关 ,特别是在难以避免小文件和有很多任务的场景下,大多数执行时间都很短。 Hadoop的默认配置通常会在分叉的JVM中启动map或reduce任务。 JVM启动可能会产生很大的开销,特别是在启动具有数百或数千个任务的作业时。 重用允许为同一作业重用JVM实例最多N次。
(2)实例
假设一个查询需要:50个map任务+10个reduce任务
然后Hive将分别启动60个JVM程序。启动JVM需要时间和系统资源 。重用JVM允许同一个JVM运行多个任务,从而减少与进程初始化相关的成本。最适用于有许多短时间运行任务的工作负载。
Imagine a Query needs:50 map tasks+10 reduce tasks
Then Hive will start 60 JVM programs separately. Starting a JVM takes time and system resources. JVM reuse allows the same JVM to run multiple tasks, reducing cost associated with process initialization. Best applied for workloads with many short-running tasks.
(3)参数设置
SET mapred.job.reuse.jvm.num.tasks=10;- 或者在Hadoop的mapred-site.xml(在$HADOOP_HOME/conf中)中设置:
sql
<property>
<name>mapred.job.reuse.jvm.num.tasks</name>
<value>10</value>
</property>(三)Parallel Execution
1.Concept
Hive查询通常被转换成多个阶段,这些阶段按默认顺序执行。 这些阶段并不总是相互依赖的。 相反,它们可以并行运行以节省总体作业运行时间。 当系统资源没有被充分利用时,效率会提高。
2.实例
sql
INSERT OVERWRITE TABLE sales_summary
SELECT region, SUM(amount)
FROM sales
GROUP BY region;
INSERT OVERWRITE TABLE product_summary
SELECT product_id, SUM(amount)
FROM sales
GROUP BY product_id;这是一个查询中的两个insert语句,都从同一个sales表中读取数据。如果不并行执行,则:
-
创建sales_summary
-
完成后,创建product_summary
总时间=第一次插入时间+第二次插入时间,增加了时间开销成本。
3.如何设置参数启用并行执行
我们可以通过以下设置启用此功能:
sql
SET hive.exec.parallel=true;
SET hive.exec.parallel.thread.number=2;现在Hive做了什么:任务1读取销售数据并计算区域汇总;任务2阅读销售数据并计算产品摘要。**现在两者同时独立运行,节约了近一半的时间。**接下来启动并行执行
sql
SET hive.exec.parallel=true;
# Hive can run up to 16 tasks in parallel at the same time inside a single query.
SET hive.exec.parallel.thread.number=16;注:并行执行将增加集群利用率。 如果集群的利用率已经非常高,那么并行执行在整体性能方面不会有太大帮助。
(四)Map and Reduce Quantity Optimization
1.介绍
Hive会根据数据量自动确定reducer的数量 ,但调优reducer的数量可以通过以下方式提升性能:
Hive determines reducer count automatically based on data volume but tuning reducer count improves performance by:
-
防止一个reducer接收大部分数据时发生倾斜
-
Preventing skew where one reducer receives a majority of the data
-
减少因过度创建reducer而导致的开销
-
Reducing excessive reducer creation that leads to overhead
-
这种微调对于大型聚合和连接工作负载至关重要。
-
This fine-tuning is vital for large aggregation and join workloads.
2.设置参数
sql
# Controls data size per reducer.
hive.exec.reducers.bytes.per.reducer ---default 1 G
# Maximum number of reducers allowed
hive.exec.reducers.max --- default 999reducer个数计算公式:N = min(参数2,总输入数据量/参数1)
(五)Using EXPLAIN for Diagnostics
1.介绍
学习Hive工作原理的第一步(在阅读本书之后...)是使用EXPLAIN特性来学习Hive如何将查询转换为MapReduce作业。
EXPLAIN可以在不运行查询的情况下洞察执行计划 。它揭示了:逻辑操作符(scan、select、group)、任务分解(map vs reduce)、阶段依赖关系和序列,这对于诊断不必要的I/O、shuffle操作或结构不合理的联结非常重要。
EXPLAIN provides insight into execution plans without running queries. It reveals:
Logical operators (scan, select, group)、Task breakdown (map vs reduce)、Stage dependencies and sequence.This is essential for diagnosing unnecessary I/O, shuffle operations, or poorly structured joins.
2.设置参数
sql
hive> EXPLAIN SELECT SUM(number) FROM onecol;(六)Query Optimization Techniques
以下都是join的相关内容
1.common join
普通连接也称为简化侧连接。 它是Hive中的一个基本连接,在大多数情况下都是有效的。 对于普通连接,我们需要确保大表位于最右侧或指定。
The common join is also called reduce side join. It is a basic join in Hive and works for most of the time. For common joins, we need to make sure the big table is on the right most side or specified by hit.
2.Map join
当其中一张联结表小到内存可以容纳时,就会使用映射联结,因此它的速度非常快,但有局限性。从Hive 0.7.0开始,Hive可以通过以下设置自动转换map连接。
sql
SET hive.auto.convert.join=true; --default false
SET hive.mapjoin.smalltable.filesize=600000000;
--default 25M
SET hive.auto.convert.join.noconditionaltask=true;--default false. Set to
true so that map join hint is not needed
SET hive.auto.convert.join.noconditionaltask.size=10000000;
--The default value controls the size of table to fit in memory启用autoconvert后,Hive会自动检查较小的表文件大小是否大于hive.mapjoin.smalltable.filesize设置的值,然后Hive会将该连接转换为普通连接。
如果文件小于这个阈值,它将尝试将普通连接转换为映射连接。 一旦启用了自动转换连接,就不需要在查询中提供映射连接提示。
3.Bucket map join
Bucket map连接是在桶表上进行的一种特殊的map连接。要启用桶映射连接,需要启用以下设置:
Bucket map join is a special type of map join applied on the bucket tables. To enable bucket map join, we need to enable the following settings:
sql
SET hive.auto.convert.join=true; --default false
SET hive.optimize.bucketmapjoin=true; --default false在bucket map连接中,所有的连接表都必须是桶表 ,并且在buckets列上进行连接。此外,较大表的桶数必须是小表的桶数的倍数。
In bucket map join, all the join tables must be bucket tables and join on buckets columns. In addition, the buckets number in bigger tables must be a multiple of the bucket number in the small tables.
4.Sort Merge Bucket (SMB) join
SMB是在具有相同排序、桶和连接条件列的桶表上 执行的连接。这是一种连接优化技术,适用于两个表都很大,但分桶和排序方式相同的情况。
SMB is the join performed on the bucket tables that have the same sorted, bucket, and join condition columns. It is a join Optimization technique, Used when both table are large, but bucketed and sorted in the same way.
启用这种连接的要求:
- 表是分桶的:Tables are bucketed
- 表具有相同数量的桶:Tables have the same number of buckets
- 连接键中的桶列:Bucketing column in the join key.
- 表按联结键排序:Tables are sorted on the join key.
它从两个桶表中读取数据,并在桶表上执行常见的连接(触发map和reduce)。 我们需要启用以下属性才能使用SMB:
sql
SET hive.input.format= org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
SET hive.auto.convert.sortmerge.join=true;
SET hive.optimize.bucketmapjoin=true;
SET hive.optimize.bucketmapjoin.sortedmerge=true;
SET hive.auto.convert.sortmerge.join.noconditionaltask=true;5.Sort merge bucket map (SMBM) join
SMBM连接是一种特殊的桶连接 ,但只触发映射端连接 。 它可以避免像map join那样在内存中缓存所有行。 要执行SMBM连接,连接表必须具有相同的桶、排序和连接条件列。 要启用这种连接,我们需要启用以下设置:
sql
SET hive.auto.convert.join=true;
SET hive.auto.convert.sortmerge.join=true
SET hive.optimize.bucketmapjoin=true;
SET hive.optimize.bucketmapjoin.sortedmerge=true;
SET hive.auto.convert.sortmerge.join.noconditionaltask=true;
SET hive.auto.convert.sortmerge.join.bigtable.selection.policy=
org.apache.hadoop.hive.ql.optimizer.TableSizeBasedBigTableSelectorForAutoSMJ;6.Skew join
当key分布不均匀时,启用倾斜检测,将重密钥分配给额外的reducer。当一个键有太多记录时(数据倾斜)。这减少了shuffle和不必要的reducer负载。
When key distribution is uneven, enable skew detection to redistribute heavy keys to additional reducers. When one key has too many records (data skew). These reduce shuffle and unnecessary reducer load.
sql
SET hive.optimize.skewjoin=true;--If there is data skew in join, set it to true. Default is false.
SET hive.skewjoin.key=100000;
--This is the default value. If the number of key is bigger than
--this, the new keys will send to the other unused reducers.总结:Summary
以下是对Hive中各类连接方式的整理对比表格,重点标注了核心特性及易考点:
| 连接类型 | 触发条件/特性 | 是否需分桶 | 是否需排序 | 触发阶段 | 适用场景 | 典型配置 |
|---|---|---|---|---|---|---|
| Common Join | 大表靠右或显式指定 (易考点:数据倾斜时性能差) | 否 | 否 | Reduce阶段 | 通用场景 | 无需特殊配置 |
| Map Join | 小表可装入内存 (易考点:自动转换阈值hive.mapjoin.smalltable.filesize) |
否 | 否 | 仅Map阶段 (核心优势) | 小表+大表 | SET hive.auto.convert.join=true; SET hive.auto.convert.join.noconditionaltask=true; |
| Bucket Map Join | 所有表分桶 大表桶数=小表桶数整数倍 (易考点:分桶一致性要求) | 是 | 否 | 仅Map阶段 | 分桶表且桶数匹配 | SET hive.optimize.bucketmapjoin=true; |
| SMB Join | 桶数相同+排序列=连接键 (易考点:严格三要素:分桶、排序、连接键对齐) | 是 | 是 | Map+Reduce阶段 | 两大表且分桶排序一致 (核心场景) | SET hive.optimize.bucketmapjoin.sortedmerge=true; SET hive.input.format=org.apache...BucketizedHiveInputFormat; |
| SMBM Join | 桶数相同+排序列=连接键 | 是 | 是 | 仅Map阶段 | 分桶排序严格一致的大表 | SET hive.auto.convert.sortmerge.join.bigtable.selection.policy=...; |
| Skew Join | 数据倾斜(单key记录数>阈值) (易考点:hive.skewjoin.key默认值10万) |
否 | 否 | Reduce阶段优化 | 存在热点Key | SET hive.optimize.skewjoin=true; SET hive.skewjoin.key=100000; |
核心易考点总结
-
连接阶段
- 仅Map阶段:Map Join、Bucket Map Join、SMBM Join(避免Reduce瓶颈)
- 需Reduce阶段:Common Join、SMB Join、Skew Join
-
特殊条件
- 分桶要求:Bucket Map Join、SMB Join、SMBM Join
- 排序要求:SMB Join、SMBM Join(必须与连接键对齐)
- 自动转换阈值 :Map Join的
hive.mapjoin.smalltable.filesize(默认25MB)
-
数据倾斜处理
- Skew Join :通过
hive.skewjoin.key重分配热点Key(需显式开启) - Common Join:大表靠右可缓解非倾斜场景的性能问题
- Skew Join :通过
7.Sorting Behavior Optimization
(1)ORDER BY
实现全局排序,一次减少实现,效率低。 Global sort, single reducer, slow
(2)SORT BY
实现是部分有序的。 单个reduce的输出是有序且高效的。 它通常与DISTRIBUTE BY关键字一起使用(DISTRIBUTE BY关键字可以指定从map到reduce的分布键)。
Partial sort; efficient for large datasets
(3)CLUSTER BY
相当于DISTRIBUTE BY col1 SORT BY col1,基于同一列 进行排序和分发,非常适合ETL管道
Sorts and distributes based on same column, ideal for ETL pipelines
(4)use partition
Hive中的每个分区对应HDFS中的一个目录,分区列不是表中的一个实际字段,而是一个或多个伪列,这些伪列并不实际保存分区列信息和表数据文件中的数据。 在Partition关键字中,第一个主Partition(只有一个)后面跟着第二个Partition。
Each partition in Hive corresponds to a directory on HDFS, and the partition column is
not an actual field in the table, but one or more pseudo-columns that don't actually hold the partition column information and data in the table's data file. In the Partition keyword, the first primary Partition (only one) is followed by the second Partition.
- Static partitioning requires specifying values explicitly
- Dynamic partitioning automatically assigns partitions during load when enabled
二、Execution engines in Hive
(一)MapReduce
MapReduce执行引擎将Hive查询作为传统的MapReduce作业来运行。 它是原始的执行引擎,如果使用其他执行引擎之一执行查询失败,它也是最安全的备用选项。 您可以通过设置hive.execution.engine=mr的值来选择执行引擎。
(二)Tez
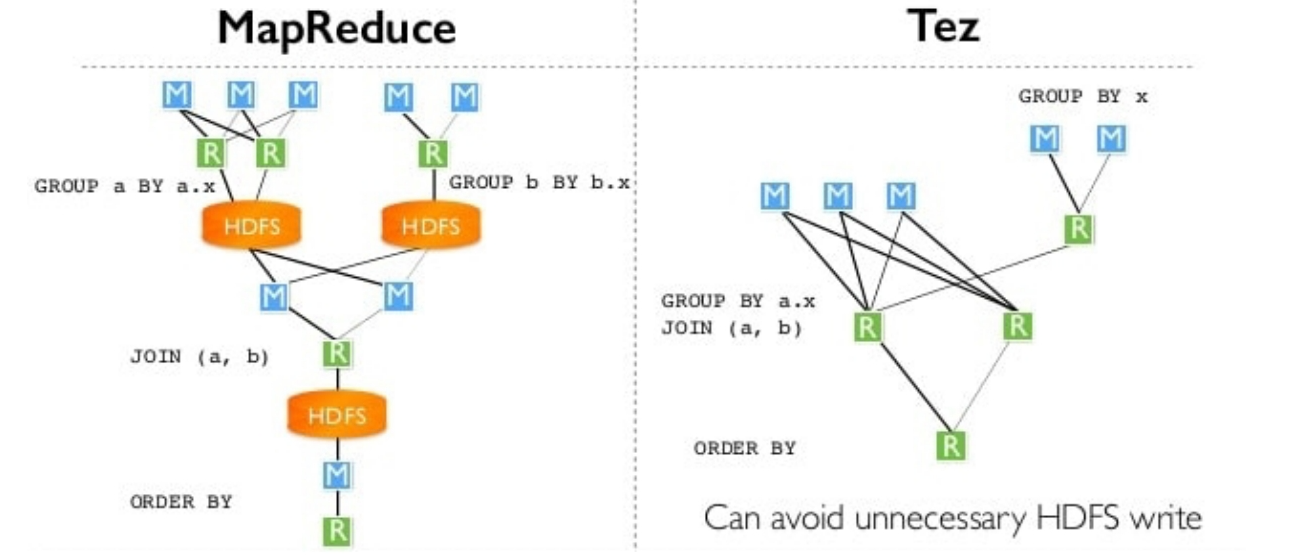
Apache Tez提供了比MapReduce执行引擎更有效的处理,通过减少操作和限制写入磁盘的中间数据量 ,如下图所示,传统的MapReduce执行引擎有几个步骤,其中来自reducer的中间数据被写回HDFS,这会导致磁盘I/O的性能损失。 将此与右侧显示的Tez执行引擎的数据流进行对比,在Tez执行引擎中,减速器的中间数据直接传递给执行计划中的下一个减速器,并且绕过了将数据写入磁盘的开销。
让我们通过将hive.execution.engine属性的值设置为tez来衡量这个执行引擎的性能,即:
sql
hive.execution.engine=tez
hive.prewarm.enabled =true
hive.prewarm.numcontainers=10(三)比较
表格比较:
| Engine | Use Case | Performance Behavior |
|---|---|---|
| MapReduce | Legacy fallback | Writes intermediate output to disk; slower |
| Tez | Modern default | Minimizes disk I/O by passing intermediate data in memory |
三、Hive Security
(一)Default Authorization Mode
默认情况下,当用户在这种模式下创建表时,不会向创建表的人授予任何特权。 通过修改hive.security.authorization的值使能该授权模式。 在hive-site.xml文件中启用为true, 如下所示。
sql
<property>
<name>hive.security.authenticator.manager</name>
<value>org.apache.hadoop.hive.ql.security.ProxyUserAuthenticator</value>
</property>
<property>
<name>hive.security.authorization.enabled</name>
<value>true</value>
</property>
<property>
<name>hive.security.authorization.manager</name>
<value>org.apache.hadoop.hive.ql.security.authorization.plugin.sqlstd.
SQLStdConfOnlyAuthorizerFactory</value>
</property>这种模式非常类似于RDBMS风格的授权。 在用户、组和角色等不同级别上管理访问。 这种授权模式还具有一些属性,用于控制用户、组和角色在创建新表时将获得的默认特权。
(二)Storage-Based Authorization Mode
Hive后续版本增加了基于存储的授权方式。 它依赖于Hadoop的文件系统HDFS的权限模型。 在这种类型的安全模型中,HDFS的权限作为一个单一的事实来源,H**ive只是依赖于这个单一的事实来源来决定是否应该授予用户请求访问权限。 当用户试图访问表时,Hive检查文件系统上底层目录的权限,**以控制Hive对象的安全性。 通过在hive-site.html中设置以下属性,可以启用基于存储的授权模式。
(三)SQL Standards-Based Authorization Mode
这种授权模式提供了一种比基于存储的授权更精细的访问控制方式。 如果Hive用户连接HiveServer2,并且只需要通过SQL访问数据,则推荐使用这种授权方式。 在这种模式下,您可以控制对列的访问。
一般的最佳实践是只允许用户通过HiveServer2进行访问,并限制可以运行的用户代码和非sql命令。 当用户提交请求时,检查权限,但实际查询是作为Hive服务器用户执行的。 您还应该在HDFS级别锁定对实际数据的访问权限,只将权限授予Hive服务器用户。 如果有其他用户不需要通过SQL访问,但只需要在HDFS级别访问这些文件,您可以为他们创建acls。
(四)Managing Access through SQL
就像使用标准SQL一样,您可以在Hive中使用特权、用户、角色和对象来管理访问控制。 权限被授予用户和角色。 用户属于一个或多个角色,可以启用一个角色。 Hive中可以授予的一些权限是ALTER, DROP, INDEX, LOCK, SELECT, INSERT, UPDATE, DELETE, CREATE, ALL。 如果您熟悉标准SQL,您会发现在Hive中管理特权的命令非常相似。
| 模式 | 描述 |
|---|---|
| Default Authorization Mode | 基本控制(如果用户有权访问HDFS位置,他们就可以读取Hive表) |
| Storage-Based Authorization Mode | 基于HDFS目录(如果你没有权限读取HDFS中的表文件夹,Hive将不允许查询) |
| SQL Standards-Based Authorization Mode | 细粒度的SQL级别访问。它类似于普通数据库中的安全性: - GRANT SELECT ON table TO user; - REVOKE SELECT ON table FROM user; |
| Managing Access through SQL | GRANT/REVOKE roles Role = Group of permissions(角色 = 权限组) |
总结
在本章中,你学习了:VM重用是一个与Hive性能非常相关的Hadoop调优参数,特别是在难以避免小文件和任务很多的场景下,大多数执行时间都很短。 当Hive没有指定减速器的个数时,Hive会猜测并确定减速器的个数。 当其中一个连接表小到足以容纳内存时,使用映射连接,所以它非常快,但有局限性。 桶映射连接是应用于桶表的一种特殊类型的映射连接。 SMB是对具有相同排序条件、桶条件和连接条件列的桶表执行的连接。 SMBM连接是一种特殊的桶连接,但只触发映射侧连接。 当处理高度不均匀分布的数据时,数据倾斜可能会以这样的方式发生,即少数计算节点必须处理大量计算。 Hive中的每个分区对应HDFS中的一个目录,分区列不是表中的一个实际字段,而是一个或多个伪列,这些伪列并不实际保存表数据文件中的分区列信息和数据。 MapReduce执行引擎将Hive查询作为传统的MapReduce作业来运行。 通过减少操作和限制写入磁盘的中间数据量,Tez提供了比MapReduce执行引擎更有效的处理。